Материалы по тегу: grace
|
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000.
18.04.2024 [13:23], Сергей Карасёв
Eviden и CEA анонсировали второй суперкомпьютер EXA1 — HE на базе Arm-суперчипов NVIDIA Grace HopperКомпания Eviden (дочерняя структура Atos) и Комиссариат по атомной и альтернативным видам энергии Франции (СЕА) объявили о реализации второй фазы суперкомпьютерной программы EXA1. Она предусматривает ввод в эксплуатацию НРС-комплекса EXA1 HE (High Efficiency) на платформе Eviden BullSequana XH3000. Первая очередь системы — EXA1 HF (High-Frequency) — была запущена в 2021 году. Основой послужила платформа BullSequana XH2000. Изначально машина включала 12 960 процессоров AMD EPYC 7763 (64C/128T, 2,45 ГГц), а её производительность на момент анонса составляла 23,2 Пфлопс. Комплекс EXA1 HE использует 477 вычислительных узлов на базе суперчипов NVIDIA Grace Hopper. Применяется жидкостное охлаждение тёплой водой. Заявленная производительность в тесте Linpack составляет приблизительно 60 Пфлопс, а пиковое быстродействие достигает 104 Пфлопс. Задействован фирменный интерконнект BXI (BullSequana eXascale Interconnect). Сеть основана на топологии DragonFly и состоит из 156 коммутаторов. Отмечается, что суперкомпьютер EXA1 соответствует требованиям оборонных программ, реализуемых военным отделом CEA. 
Источник изображения: Eviden Отметим, что в марте нынешнего года компания Eviden заключила соглашение о модернизации французского НРС-комплекса Jean Zay. Суперкомпьютер получит 1456 ускорителей NVIDIA H100 в дополнение к 416 картам NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. В результате, пиковая производительность Jean Zay поднимется с нынешних 36,85 до 125,9 Пфлопс.
16.04.2024 [16:20], Сергей Карасёв
Завершено строительство Arm-суперкомпьютера Venado на базе суперчипов NVIDIA Grace HopperЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США объявила о завершении сборки НРС-комплекса Venado, предназначенного для решения сложных ресурсоёмких задач в области ИИ. В создании системы приняли участие компании HPE и NVIDIA. Проект Venado был анонсирован в мае 2022 года. Система смонтирована в Центре моделирования и симуляции Николаса К. Метрополиса (Nicholas C. Metropolis) в составе LANL. В церемонии открытия комплекса приняли участие представители Министерства энергетики США, Администрации по национальной ядерной безопасности США и других организаций. Venado — первый в США суперкомпьютер, построенный на суперчипах NVIDIA Grace и Grace Hopper с ядрами Arm. Суперкомпьютер построен на платформе HPE Cray EX. В общей сложности задействованы 2560 гибридных суперчипов Grace Hopper с прямым жидкостным охлаждением: эти изделия объединяют ядра Arm v9 и ускорители на архитектуре Hopper. Кроме того, в состав НРС-системы входят 920 суперчипов Grace. Узлы объединены интерконнектом HPE Slingshot 11. 
Источник изображений: LANL На суперкомпьютере используется специализированное ПО HPE Cray, которое, как утверждается, позволяет оптимизировать рабочие нагрузки по моделированию и симуляции. Систему планируется использовать в таких областях, как материаловедение, возобновляемые источники энергии, астрофизика и пр. ИИ-производительность системы (FP8) составит около 10 Эфлопс. Машина также получит Lustre-хранилище.  «Являясь первым в США суперкомпьютером на базе NVIDIA Grace Hopper, система Venado обеспечивает революционную производительность и энергоэффективность для ускорения научных открытий», — говорит Ян Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA. При этом Venado относится к классу экспериментальных суперкомпьютеров и будет использоваться для переноса и оптимизации имеющихся кодов, а также для создания нового ПО и проверки различных концепций.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 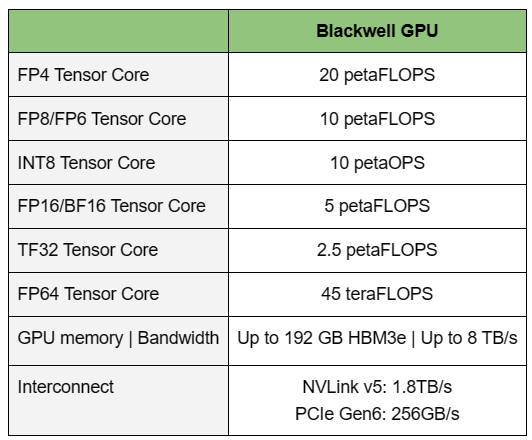 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 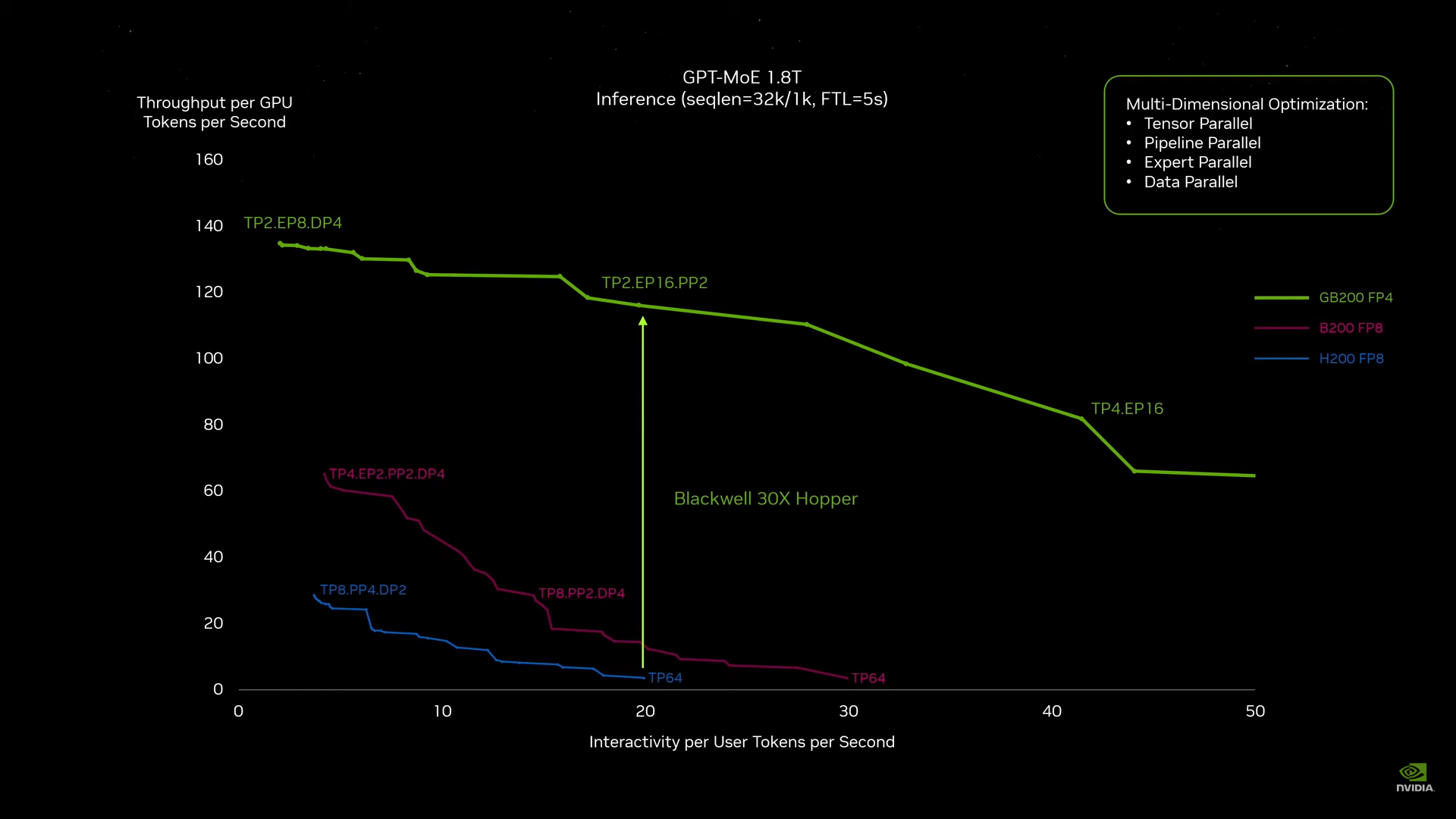 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 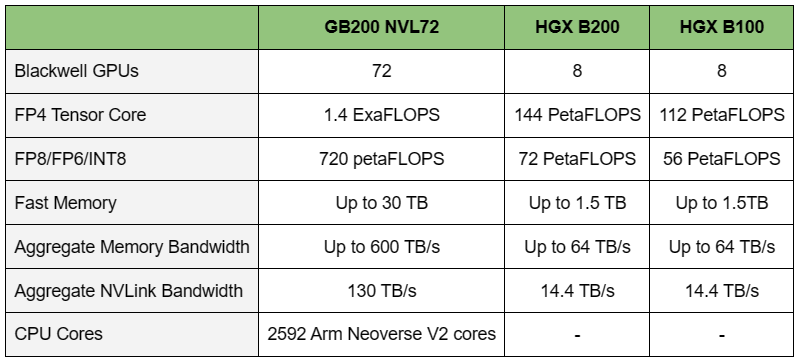 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
27.02.2024 [21:44], Сергей Карасёв
Gigabyte представила новые серверы для ИИ, 5G и периферийных вычисленийКомпания Gigabyte Technology на MWC 2024 анонсировала новые серверы для ИИ-задач, 5G-сетей, облачных и периферийных вычислений. Дебютировали модели на процессорах AMD и Intel, оснащённые мощными ускорителями.  В частности, представлены серверы G593-ZX1/ZX2, оборудованные восемью картами AMD Instinct MI300X для ресурсоёмких вычислений. Кроме того, демонстрируются сервер высокой плотности H223-V10 с поддержкой суперчипа NVIDIA Grace Hopper, модель G383-R80 с четырьмя APU AMD Instinct MI300A и сервер серии G593, оснащённый восемью ускорителями NVIDIA HGX H100.  Ещё одна новинка — сервер хранения S183-SH0. Он допускает использование 32 SSD формата E1.S (NVMe), благодаря чему подходит для обработки сложных рабочих нагрузок, таких как большие языковые модели (LLM). Эти серверы также могут быть интегрированы в суперкомпьютерные кластеры и инфраструктуру 5G.  На edge-сегмент рассчитан сервер E263-S30 с модульной архитектурой: он может быть адаптирован под различные сценарии использования путём установки необходимых аппаратных компонентов. А модель R163-P32 комплектуется процессором AmpereOne с архитектурой Arm (до 192 ядер Arm с частотой до 3,0 ГГц), что обеспечивает высокую энергетическую эффективность.
На ИИ-приложения и облачные периферийные вычисления ориентированы серверы R243-EG0 и R143-EG0, которые оснащены чипами AMD EPYC 8004 Siena. Для сегмента малого и среднего бизнеса Gigabyte предлагает серверы R113-C10 и R123-X00, наделённые процессорами AMD Ryzen 7000 и Intel Xeon E-2400: эти модели подходят для веб-хостинга, создания гибридных облаков и хранилищ данных.
27.02.2024 [16:08], Сергей Карасёв
Supermicro анонсировала ИИ- и телеком-серверы на базе AMD EPYC Siena, Intel Xeon Emerald Rapids и NVIDIA Grace Hopper
5g
amd
emerald rapids
epyc
gh200
grace
hardware
intel
mwc 2024
nvidia
siena
supermicro
ии
периферийные вычисления
сервер
Компания Supermicro представила на выставке мобильной индустрии MWC 2024 в Барселоне (Испания) новые серверы для телекоммуникационной отрасли, 5G-инфраструктур, задач ИИ и периферийных вычислений. Дебютировали модели с процессорами AMD EPYC 8004 Siena, Intel Xeon Emerald Rapids и с суперчипами NVIDIA GH200 Grace Hopper.  В частности, анонсирована стоечная система ARS-111GL-NHR высокой плотности в форм-факторе 1U на базе GH200. Устройство наделено двумя слотами PCIe 5.0 x16, восемью фронтальными отсеками для накопителей E1.S NVMe и двумя коннекторами для модулей M.2 NVMe. Сервер предназначен для работы с генеративным ИИ и большими языковыми моделями (LLM). На периферийные 5G-платформы ориентировано решение SYS-211E ультрамалой глубины — 298,8 мм. Модель рассчитана на один процессор Xeon Emerald Rapids в исполнении LGA-4677. Есть восемь слотов для модулей DDR5-5600 общей ёмкостью до 2 Тбайт и до шести слотов PCIe 5.0 в различных конфигурациях для карт расширения. Модификация SYS-211E-FRDN13P для сетей Open RAN предлагает 12 портов 25GbE и поддерживает технологию Intel vRAN Boost.  Ещё одна новинка — сервер AS-1115S-FWTRT формата 1U с возможностью установки одного процессора EPYC 8004 Siena (до 64 ядер). Реализована поддержка до 576 Гбайт памяти DDR5-4800 (шесть слотов), двух портов 10GbE, двух слотов PCIe 5.0 x16 FHFL и одного слота PCIe 5.0 x16. Решение предназначено для edge-приложений.
Представлены также многоузловая платформа SYS-211SE-31D/A и система высокой плотности SYS-221HE: обе модели выполнены в формате 2U на процессорах Xeon Emerald Rapids. Второй из этих серверов допускает монтаж до трёх двухслотовых ускорителей NVIDIA H100, A10, L40S, A40 или A2. Наконец, анонсирован сервер AS-1115SV типоразмера 1U с поддержкой процессоров EPYC 8004 Siena, 576 Гбайт памяти DDR5, трёх слотов PCIe 5.0 x16 и 10 накопителей SFF.
27.02.2024 [13:24], Сергей Карасёв
ASRock Rack представила MECAI-GH200 — самый компактный в мире сервер с суперчипом NVIDIA GH200Компания ASRock Rack продемонстрировала сервер MECAI-GH200: это, как утверждается, самая компактная в мире система, оснащённая гибридным суперчипом NVIDIA GH200 Grace Hopper с 72-ядерным Arm-процессором NVIDIA Grace и ускорителем NVIDIA H100 с 96 Гбайт памяти HBM3. Новинка выполнена в 2U-корпусе небольшой глубины. Доступны два посадочных места для накопителей формата E1.S (PCIe 5.0 х4), два коннектора для модулей М.2 (PCIe 5.0 х4) и два слота для карт расширения FHFL с интерфейсом PCIe 5.0 х16. Питание обеспечивают два блока мощностью 1600 Вт. Глубина MECAI-GH200 составляет 450 мм. Сервер предназначен для решения ИИ-задач на периферии. Прочие характеристики сервера пока не раскрываются.  «В ASRock Rack мы стремимся обеспечить возможность повсеместного использования ИИ. Для достижения этой цели мы создаём надёжные серверные решения в различных форм-факторах и для различных сценариев», — говорит вице-президент компании Хантер Чен (Hunter Chen).  ASRock Rack также представила на выставке MWC 2024 новые barebone-системы и материнские платы для процессоров Intel, AMD и Ampere. Например, впервые демонстрируется плата SIENAD8UD-2L2Q с поддержкой чипов AMD EPYC 8004 Siena и двумя сетевыми портами 25GbE SFP28.
24.02.2024 [03:08], Сергей Карасёв
Arm-суперчипы NVIDIA Grace помогут Nokia создать 5G-сети с ИИКомпания Nokia объявила о сотрудничестве с NVIDIA в рамках проекта по созданию передовых решений для сетей радиодоступа (RAN), использующих технологии ИИ. Предполагается, что инициатива позволит изменить ландшафт телекоммуникационной инфраструктуры и повысить качество услуг в области мобильной связи. Nokia намерена заняться разработкой решений Cloud RAN (сеть радиодоступа на основе облака) на оборудовании NVIDIA. Речь, в частности, идёт о применении Arm-суперчипов NVIDIA Grace. Кроме того, Nokia задействует собственную энергоэффективную технологию ускорения In-Line Layer 1 (L1) и специализированный софт. В составе платформы будут также применяться ускорители NVIDIA. Всё это откроет путь для реализации концепции AI-RAN — сеть радиодоступа с ИИ-подкреплением. Отмечается, что сотрудничество с NVIDIA является частью концепции Nokia AnyRAN, которая предполагает возможность использования любой специализированной, гибридной или облачной среды RAN. Подход помогает ускорить развёртывание и начало эксплуатации сервисов Cloud RAN. При этом высокопроизводительная система Nokia In-Line может быть интегрирована с облачными или серверными инфраструктурами. Ранее Nokia успешно протестировала сквозные соединения 5G (Layer 3) для высокоскоростной передачи данных на оборудовании нескольких поставщиков, в том числе с Arm-чипами Ampere. 
Источник изображения: Nokia Ожидается, что применение чипов NVIDIA в составе платформ Nokia поможет в создании более производительных и энергоэффективных решений Cloud RAN. При этом внедрение ИИ даст возможность повысить операционную эффективность. Примечательно, что и Nokia, и Ericsson при поддержке Intel стали развивать оборудование на базе общедоступных платформ, впоследствии добавив поддержку решений других вендоров. Сама Intel предлагает для 5G-систем специализированные процессоры Xeon EE.
23.02.2024 [19:07], Сергей Карасёв
Австралийский суперкомпьютерный центр внедрит суперчипы NVIDIA Grace Hopper для квантовых исследованийАвстралийский суперкомпьютерный центр Pawsey начнёт использовать решение NVIDIA CUDA Quantum — открытую платформу для интеграции и программирования CPU, GPU и квантовых компьютеров (QPU). Ожидается, что это поможет ускорить развитие перспективного направления квантовых вычислений. Pawsey развернёт в своём Национальном центре инноваций в области суперкомпьютеров и квантовых вычислений восемь узлов с суперчипами NVIDIA GH200. Эти изделия содержат 72-ядерный Arm-процессор Grace и ускоритель H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с. Сообщается, что узлы проектируемой системы будут использовать модульную архитектуру NVIDIA MGX, которая предназначена для построения HPC-систем и комплексов ИИ. Предполагается, что высокопроизводительная гибридная платформа с CPU, GPU и QPU позволит выполнять высокоточные и гибко масштабируемые квантовые симуляции. В рамках проекта будет применяться специализированное ПО NVIDIA cuQuantum для разработки квантовых решений. 
Источник изображения: NVIDIA Национальное научное агентство Австралии (CSIRO) оценивает размер внутреннего рынка квантовых вычислений в $2,5 млрд в год с потенциалом создания до 10 тыс. новых рабочих мест к 2040-му. Для достижения таких показателей необходимо внедрение квантовых вычислений в различных областях, включая астрономию, науки о жизни, медицину, финансы и пр. |
|


