Материалы по тегу: суперкомпьютер
|
19.04.2024 [09:10], Сергей Карасёв
Tesla столкнулась с трудностями при строительстве дата-центра для ИИ-суперкомпьютера DojoКомпания Tesla, по сообщению ресурса The Information, не укладывается в намеченный график строительства ЦОД в Остине (Техас, США), в котором планируется разместить узлы ИИ-суперкомпьютера Dojo стоимостью $1 млрд. Эта площадка будет использоваться для решения сложных задач в области ИИ и машинного обучения, в частности, связанных с системами автопилотирования. К строительству дата-центра, о котором идёт речь, компания Илона Маска приступила в октябре 2023 года. Известно, что по своей конструкции этот ЦОД будет напоминать бункер. Однако, как стало известно, при возведении комплекса Tesla столкнулась с рядом трудностей. В середине апреля Маск посетил строительную площадку и «пришёл в ярость» из-за увиденного. Вопреки ожиданиям, у объекта отсутствуют большая часть первого этажа и крыша. Наблюдаются сложности с доставкой необходимых материалов, из-за чего возникают задержки при строительстве. Кроме того, ситуация усугубляется из-за того, что основанная Маском компания Boring Company должна проложить под площадкой ЦОД туннель для передвижения электрических пикапов Cybertruck, но эти работы не выполнены. Поэтому невозможно полноценное завершение возведения даже первого этажа. 
Источник изображения: Tesla После своего визита Маск уволил директора по строительной инфраструктуре проекта. После этого Tesla сократила более 14 тыс. сотрудников — свыше 10 % от своего штата, насчитывавшего около 140 тыс. человек. Кроме того, компанию покинули несколько топ-менеджеров. О сроках завершения строительства ЦОД в Остине ничего не сообщается. Возникшие задержки, как считается, отражают более широкие проблемы в автомобильной отрасли.
19.04.2024 [07:46], Сергей Карасёв
«Росэлектроника» представила ПАК для суперкомпьютеров с интерконнектом «Ангара»Холдинг «Росэлектроника», входящий в госкорпорацию «Ростех», анонсировал отечественный программно-аппаратный комплекс (ПАК) под названием «Базис», предназначенный для развёртывания облачных сервисов и платформ НРС. Система, как утверждается, может масштабироваться до нескольких сотен узлов. ПАК разработан специалистами Научно-исследовательского центра электронной вычислительной техники (НИЦЭВТ) в составе «Росэлектроники». Решение состоит из трёх серверов общего назначения, каждый из которых может насчитывать до 128 вычислительных ядер и нести на борту до 2 Тбайт оперативной памяти. Отмечается, что системные платы для серверов имеют отечественное происхождение: они спроектированы и произведены в НИЦЭВТ. Более подробно характеристики не раскрываются. Платформа «Базис» использует обновлённую версию российского интерконнекта «Ангара». Достигается пропускная способность до 75 Гбит/с. Разработчики подчёркивают, что сетевое оборудование обеспечивает высокоинтенсивный обмен данными между серверами со сверхнизкой задержкой. 
Источник изображения: «Росэлектроника» «Базис» включён в Единый реестр телекоммуникационного и радиоэлектронного оборудования российского происхождения Минпромторга России. На основе ПАК могут создаваться центры обработки и хранения данных, виртуализированные офисы, виртуальные машины, системы для обработки графических приложений, а также суперкомпьютеры для нестандартных расчётов, говорится в сообщении. Благодаря возможностям масштабирования платформа может поддерживать тысячи виртуальных рабочих мест. «Область применения нового программно-аппаратного комплекса очень широка. Например, наши технологии легко справятся с задачей создания виртуализированных инженерных рабочих мест с поддержкой аппаратной обработки 3D-графики. А высокая пропускная способность канала передачи данных и гибкая система масштабирования позволяют проводить сложнейшие вычислительные операции. Наши специалисты готовы рассчитать и адаптировать наш новый ПАК под конкретные задачи и потребности заказчика», — говорит генеральный директор НИЦЭВТ.
18.04.2024 [13:23], Сергей Карасёв
Eviden и CEA анонсировали второй суперкомпьютер EXA1 — HE на базе Arm-суперчипов NVIDIA Grace HopperКомпания Eviden (дочерняя структура Atos) и Комиссариат по атомной и альтернативным видам энергии Франции (СЕА) объявили о реализации второй фазы суперкомпьютерной программы EXA1. Она предусматривает ввод в эксплуатацию НРС-комплекса EXA1 HE (High Efficiency) на платформе Eviden BullSequana XH3000. Первая очередь системы — EXA1 HF (High-Frequency) — была запущена в 2021 году. Основой послужила платформа BullSequana XH2000. Изначально машина включала 12 960 процессоров AMD EPYC 7763 (64C/128T, 2,45 ГГц), а её производительность на момент анонса составляла 23,2 Пфлопс. Комплекс EXA1 HE использует 477 вычислительных узлов на базе суперчипов NVIDIA Grace Hopper. Применяется жидкостное охлаждение тёплой водой. Заявленная производительность в тесте Linpack составляет приблизительно 60 Пфлопс, а пиковое быстродействие достигает 104 Пфлопс. Задействован фирменный интерконнект BXI (BullSequana eXascale Interconnect). Сеть основана на топологии DragonFly и состоит из 156 коммутаторов. Отмечается, что суперкомпьютер EXA1 соответствует требованиям оборонных программ, реализуемых военным отделом CEA. 
Источник изображения: Eviden Отметим, что в марте нынешнего года компания Eviden заключила соглашение о модернизации французского НРС-комплекса Jean Zay. Суперкомпьютер получит 1456 ускорителей NVIDIA H100 в дополнение к 416 картам NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. В результате, пиковая производительность Jean Zay поднимется с нынешних 36,85 до 125,9 Пфлопс.
16.04.2024 [16:20], Сергей Карасёв
Завершено строительство Arm-суперкомпьютера Venado на базе суперчипов NVIDIA Grace HopperЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США объявила о завершении сборки НРС-комплекса Venado, предназначенного для решения сложных ресурсоёмких задач в области ИИ. В создании системы приняли участие компании HPE и NVIDIA. Проект Venado был анонсирован в мае 2022 года. Система смонтирована в Центре моделирования и симуляции Николаса К. Метрополиса (Nicholas C. Metropolis) в составе LANL. В церемонии открытия комплекса приняли участие представители Министерства энергетики США, Администрации по национальной ядерной безопасности США и других организаций. Venado — первый в США суперкомпьютер, построенный на суперчипах NVIDIA Grace и Grace Hopper с ядрами Arm. Суперкомпьютер построен на платформе HPE Cray EX. В общей сложности задействованы 2560 гибридных суперчипов Grace Hopper с прямым жидкостным охлаждением: эти изделия объединяют ядра Arm v9 и ускорители на архитектуре Hopper. Кроме того, в состав НРС-системы входят 920 суперчипов Grace. Узлы объединены интерконнектом HPE Slingshot 11. 
Источник изображений: LANL На суперкомпьютере используется специализированное ПО HPE Cray, которое, как утверждается, позволяет оптимизировать рабочие нагрузки по моделированию и симуляции. Систему планируется использовать в таких областях, как материаловедение, возобновляемые источники энергии, астрофизика и пр. ИИ-производительность системы (FP8) составит около 10 Эфлопс. Машина также получит Lustre-хранилище.  «Являясь первым в США суперкомпьютером на базе NVIDIA Grace Hopper, система Venado обеспечивает революционную производительность и энергоэффективность для ускорения научных открытий», — говорит Ян Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA. При этом Venado относится к классу экспериментальных суперкомпьютеров и будет использоваться для переноса и оптимизации имеющихся кодов, а также для создания нового ПО и проверки различных концепций.
15.04.2024 [13:58], Сергей Карасёв
В Чили запущен суперкомпьютер Geryon 3 для астрономических исследованийПапский Католический университет Чили (UC Chile) объявил о вводе в эксплуатацию НРС-комплекса Geryon 3 на аппаратной платформе Intel. Суперкомпьютер предназначен прежде всего для решения задач в области астрономии, но будет также применяться и в других сферах — от физики до биологии. Проект по созданию Geryon 3 реализован при финансовой поддержке Центра передовых исследований в области астрофизики и связанных с ней технологий (CATA). Стоимость НРС-системы составляет $367,5 тыс. Суперкомпьютер смонтирован в Институте астрофизики в Сантьяго (UC Institute of Astrophysics), где занимает площадь приблизительно 36 м2. Отмечается, что появление Geryon 3 знаменует собой важную веху в развитии вычислительных мощностей для астрофизических исследований в Чили. В состав комплекса входят 12 узлов с процессорами Xeon Gold 6448H поколения Sapphire Rapids. Чипы объединяют 32 ядра (64 потока) с тактовой частотой 2,4–4,1 ГГц. Каждый узел содержит 512 Гбайт оперативной памяти. В общей сложности задействованы 768 ядер и 6,14 Тбайт памяти. Говорится об использовании специально разработанной системы охлаждения (подробности не раскрываются) и других технических решений, включая средства стабилизации питания. 
Источник изображения: UC Chile К 2030-м годам Чили будет обладать самыми развитыми в мире возможностями астрономических наблюдений. К существующим научным инструментам добавятся новые обсерватории, такие как Гигантский Магелланов телескоп (GMT), Европейский чрезвычайно большой телескоп (E-ELT) и обсерватория Веры Рубин. Для обработки поступающих данных потребуются значительные вычислительные ресурсы. Например, обсерватория Веры Рубин получит самую мощную в мире цифровую камеру для оптической астрономии с разрешением 3200 Мп, которая будет фотографировать небо южного полушария каждые три–четыре ночи, формируя около 1000 гигантских изображений за цикл. Хотя основным предназначением Geryon 3 являются астрономические исследования, суперкомпьютер также будет применяться для обработки огромных объёмов данных в таких областях, как горное дело, возобновляемые источники энергии, биогенетика или лесное хозяйство. Ресурсы будут доступны как академическому, так и промышленному сектору.
13.04.2024 [23:00], Сергей Карасёв
«Ростех» начал поставки серверов и обновлённого интерконнекта «Ангара» для отечественных суперкомпьютеров
amd
epyc
hardware
hpc
ангара
импортозамещение
интерконнект
коммутатор
ницэвт
россия
ростех
сделано в россии
сервер
суперкомпьютер
Государственная корпорация «Ростех» объявила о начале поставок оборудования нового поколения для создания отечественных суперкомпьютеров. Речь идёт о высокопроизводительных серверах, 24-портовых коммутаторах и адаптерах интерконнекта «Ангара». В сообщении «Ростеха» говорится, что оборудование стало более компактным по сравнению с предыдущими модификациями. Адаптеры «Ангара» обеспечивают объединение серверов в единый вычислительный кластер для проведения расчётов с высокоинтенсивным обменом информацией и низкими задержками. Новинка разработана специалистами Научно-исследовательского центра электронной вычислительной техники (НИЦЭВТ) в составе холдинга «Росэлектроника» госкорпорации «Ростех». На сайте НИЦЭВТ представлено изделие ЕС8431. Это FHFL-карта с интерфейсом PCIe 2.0 x16, которая обеспечивает до шести (или до восьми при использовании платы расширения) портов для соединения с соседними узлами. Пропускная способность достигает 75 Гбит/с на порт, задержка — 130 нс на хоп. Применяются Samtec-кабели. Поддерживаются топологии сети «кольцо», 2D, 3D и 4D-тор (либо решётка), причём возможно масштабирование до 32 тыс. узлов. Энергопотребление — 30 Вт. Также доступен низкопрофильный 15-Вт адаптер ЕС8432, который по характеристикам в целом повторяет ЕС8431, но имеет только один порт (CXP). Он ориентирован на работу с коммутаторами. И НИЦЭВТ как раз предлагает такое решение — изделие ЕС8433 типоразмера 1U. Оно располагает 24 портами с пропускной способностью до 75 Гбит/с. Возможно масштабирование до 2 тыс. узлов. Энергопотребление не превышает 150 Вт. 
Источник изображений: НИЦЭВТ На мероприятии «Суперкомпьютерные дни в России 2023» НИЦЭВТ также анонсировал более компактный вариант адаптера ЕС8452.02 и 24-портовый коммутатор ЕС8453.03. В сообщении «Ростеха» не уточняется, о каких именно продуктах идёт речь. В маркетплейсе госкорпорации рекомендованная розничная цена коммутатора ЕС8433 составляет 2,8 млн руб., а адаптеров ЕС8431 и ЕС8432 — 396 тыс. руб. и 300 тыс. руб. соответственно.  В ассортименте НИЦЭВТ также значится сервер общего назначения Server-NICEVT-044 SP3 на платформе AMD. Он может оснащаться одним или двумя процессорами EPYC Naples/Rome/Milan (от 8 до 48 ядер), до 1 Тбайт RAM, двумя блоками питания с возможностью горячей замены. Возможна установка SSD суммарной вместимостью до 10 Тбайт и HDD общей ёмкостью до 80 Тбайт. Форм-фактор — 2U. Рекомендованная розничная цена составляет 1,2 млн руб.  «Мы произвели первые поставки нового поколения сетевого оборудования линейки "Ангара", разработка которого завершилась в 2023 году. Техника установлена на территории двух научно-исследовательских организаций. Устройства позволяют ещё более эффективно выполнять задачи по созданию современных российских суперкомпьютеров для решения сложных научных задач. Сегодня именно от такого оборудования во многом зависит успех и скорость научных изысканий, а значит — и развитие отечественной промышленности», — говорит генеральный директор НИЦЭВТ.
11.04.2024 [15:23], Сергей Карасёв
Студенты США первыми в мире получили собственный ИИ-суперкомпьютер NVIDIAИнженерный колледж Технологического института Джорджии (Georgia Tech) объявил о заключении соглашения о сотрудничестве с NVIDIA с целью создания первого в мире суперкомпьютерного центра ИИ, предназначенного для обучения студентов. Проект получил название AI Makerspace. Отмечается, что AI Makerspace позволит демократизировать доступ к вычислительным ресурсам, которые традиционно были доступны только исследователям и технологическим компаниям. В рамках проекта студенты смогут использовать возможности НРС-комплекса для углубления своих навыков работы с ИИ. Это поможет в выполнении курсовых работ и позволит учащимся получить ценный практический опыт. Фактически AI Makerspace — это выделенный вычислительный кластер. В создании системы приняли участие специалисты Penguin Solutions. Применяется платформа для работы с ИИ-приложениями NVIDIA AI Enterprise. На начальном этапе в составе ИИ-суперкомпьютера задействованы 20 систем NVIDIA HGX H100, насчитывающие в общей сложности 160 ускорителей NVIDIA H100. В качестве интерконнекта применяется NVIDIA Quantum-2 InfiniBand. 
Источник изображения: Georgia Tech В рамках сотрудничества с Georgia Tech компания NVIDIA окажет поддержку студентам и преподавателям Инженерного колледжа по программе NVIDIA Deep Learning Institute (Институт глубокого обучения NVIDIA). Данная инициатива предусматривает все виды практикумов по ИИ, ускоренным вычислениям, графике, моделированию и другим современным технологиям. AI Makerspace расширяет базовую теоретическую учебную программу Georgia Tech по ИИ, предлагая студентам практическую платформу для решения реальных задач, разработки передовых приложений и реализации своих идей.
11.04.2024 [14:52], Сергей Карасёв
В России растёт спрос на мощные облачные серверы для ИИ-задачКомпания iKS-Consulting обнародовала результаты исследования российского рынка облачных инфраструктур. По оценкам, в 2023 году его объём достиг 121,4 млрд руб., что на 33,9 % больше по сравнению с предыдущим годом, когда затраты оценивались в 90,6 млрд руб. При этом, как отмечается, в России растёт спрос на услуги аренды мощных серверов, предназначенных для задач ИИ и машинного обучения. Аналитики iKS-Consulting учитывают затраты в сегментах IaaS и PaaS. Говорится, что рынок облачных услуг в РФ находится на этапе бурного роста. Однако пока ещё не сложилась устоявшаяся структура спроса и предложения, а также существуют определённые опасения со стороны потенциальных клиентов. Директор по развитию бизнеса iKS-Consulting Дмитрий Горкавенко сообщил газете «Ведомости», что доля аренды серверов для обучения моделей ИИ на российском рынке облачных услуг в 2023 году составила 5,4 %. Для сравнения: годом ранее этот показатель равнялся приблизительно 4,0 %. 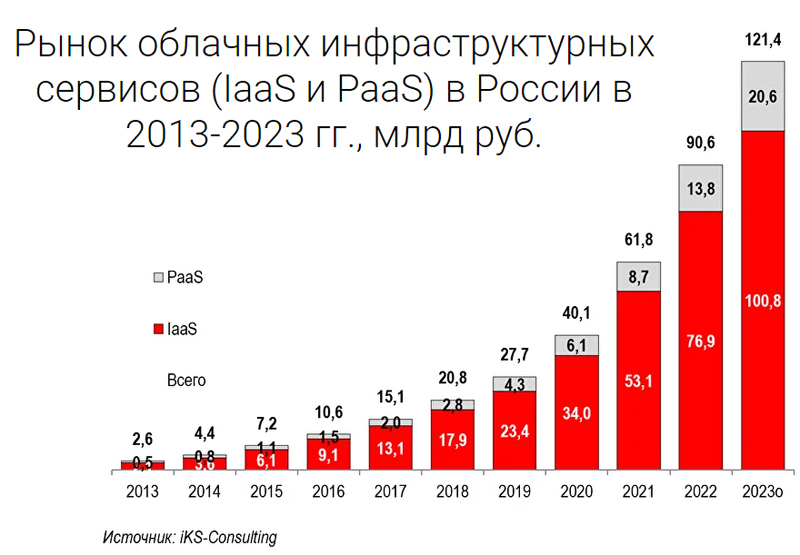
Источник изображения: iKS-Consulting Общая выручка компаний от аренды таких серверов в 2023 году составила почти 6,6 млрд руб. против 3,7 млрд руб. в 2022-м. Ключевыми игроками данного направления являются Cloud.ru, «Яндекс», «Крок», «Мегaфон», Selectel и CloudМТS. По прогнозам iKS-Consulting, к 2030 году доля выручки от услуг по аренде ИИ-серверов вырастет до 8,6 %, или до 50,3 млрд руб., при общем объёме рынка в 585,1 млрд руб. В исследовании также отмечается, что по итогам 2023 года в общем объёме выручки на рынке облачных инфраструктур около 4,8 %, или 5,9 млрд руб., пришлось на услуги вычислений на суперкомпьютерах. Годом ранее показатель был в 2,5 раза ниже — примерно 2,4 млрд руб., или 2,6% от общей выручки. Основными игроками в данном сегменте стали Cloud.ru, «Яндекс» и CloudМТS. В исследовании iKS-Consulting сказано, что сегмент B2G на российском рынке облачных услуг становится всё более значимым. Это связано с развитием государственных сервисов на базе облаков и активным переводом федеральных и региональных органов власти на единую облачную платформу.
10.04.2024 [19:53], Руслан Авдеев
Индия и Евросоюз наконец договорились о развитии совместных HPC-проектовИндия и ЕС договорились о главных этапах совместного HPC-проекта, соглашение о реализации которого было заключено почти два года назад. Однако подвижки в этой сфере наметились только сейчас, когда Евросоюз начал недвусмысленно намекать, что пора бы взяться за дело, передаёт The Register. Соответствующий пакт был подписан в ноябре 2022 года. На тот момент Индия и ЕС намеревались углубить технологическое сотрудничество в квантовых вычислениях и HPC и обозначили основные цели, включая совместное продвижение исследований в области HPC-технологий. Правда, после этого долгое время практически ничего не происходило. В феврале 2024 года Евросоюз выпустил со своей стороны призыв к развитию сотрудничества в области HPC с Индией, оптимизации и совместной разработке HPC-приложений в сферах общего интереса, а также к обмену исследователями и инженерами между регионами. 
Источник изображения: Akash Choudhary/unsplash.com В Евросоюзе рассчитывают на:
При этом в документе не указывается, какими именно способами будут достигаться названные цели. Впрочем, у Индии уже есть соображения на этот счёт. Министерство электроники и информационных технологий страны призвало исследователей предложить варианты использования HPC для анализа климатических изменений, применения в биоинформатике, для борьбы со стихийными бедствиями вроде пожаров, цунами, оползнями и землетрясениями. Также в министерстве надеются получить предложения по разработке интегрированной системы раннего предупреждения для борьбы с «каскадными» эффектами комплексных угроз. Предложения должны уделять внимание оптимизации специализированных приложений и кодов, чёткому планированию работ, учёту KPI и демонстрации убедительных результатов выгоды от сотрудничества. Претендентам рекомендуется сосредоточиться на конкретных технических задачах. В заявке должен быть чётко оговорен вклад как индийских учёных, так и их коллег из Евросоюза. В заявке следует указать сферы и методики разработки, а также потенциальных пользователей готовых продуктов в Индии и ЕС. Одобренные предложения обеспечат возможность ускоренного доступа к HPC-мощностям как в Индии, так и в Евросоюзе. Индийская Суперкомпьютерная миссия (Supercomputing Mission) располагает 28 суперкомпьютерами, но из них только семь имеют производительность более 1 Пфлопс. В рамках EuroHPC уже развёрнуто восемь суперкомпьютеров, причём одна только система LUMI имеет производительность 386 Пфлопс. Ни в Индии, ни в Евросоюзе не сообщали, когда и как именно будут реализованы одобренные предложения учёных и специалистов.
08.04.2024 [11:35], Сергей Карасёв
BSC и NVIDIA займутся совместной разработкой HPC- и ИИ-решенийБарселонский суперкомпьютерный центр (Centro Nacional de Supercomputación, BSC-CNS) и NVIDIA объявили о заключении многолетнего соглашения о сотрудничестве, целью которого является совместная разработка инновационных решений, объединяющих технологии НРС и ИИ. Договор рассчитан на пять лет с возможностью последующего продления. При этом каждые шесть месяцев стороны намерены уточнять и оптимизировать направления сотрудничества. Новое соглашение будет действовать параллельно с ранее подписанным документом, касающимся совместных исследований в области сетевых решений. Первоначально сотрудничество между BSC и NVIDIA будет сосредоточено на разработке больших языковых моделей (LLM), а также приложений для метеорологии и анализа изменений климата. Кроме того, стороны займутся адаптацией вычислительной модели цифрового двойника сердца, разработанной в рамках проекта Alya, к различным платформам. Ещё одно направление работ — программная оптимизация процессов для GPU и архитектуры NVIDIA Grace с ядрами Arm, специально разработанной для ИИ и крупномасштабных суперкомпьютерных приложений. 
Источник изображения: BSC Предполагается также, что научный потенциал BSC вкупе с технологическими достижениями и опытом NVIDIA позволят максимизировать вычислительные возможности суперкомпьютера MareNostrum 5, который был запущен в Испании в конце 2023 года. Эта система, использующая ускорители NVIDIA H100, обладает производительностью 314 Пфлопс. |
|

