Материалы по тегу: nvlink
|
16.01.2026 [23:14], Владимир Мироненко
NVIDIA добралась до RISC-V: NVLink Fusion пропишется в серверных процессорах SiFiveПродолжая укреплять свои лидирующие позиции на ИИ-рынке NVIDIA не скрывает стремления построить целую экосистему ИИ-платформ с привязкой к своим решениям. Эти усилия активизировались в прошлом году с анонсом технологии NVLink Fusion, позволяющей использовать NVLink в чипах сторонних производителей. Как стало известно, вслед за Arm, Intel и AWS, присоединившимися к программе в прошлом году, экосистема NVLink Fusion пополнилась первым поставщиком чипов на архитектуре RISC-V — компанией SiFive, которая объявила о планах внедрить NVLink Fusion в свои будущие чипы для ЦОД. SiFive отметила, что ИИ-вычисления вступают в фазу, когда архитектурная гибкость и энергоэффективность так же важны, как и пиковая пропускная способность. Нагрузки обучения и инференса растут быстрее, чем энергетические бюджеты, заставляя операторов ЦОД переосмыслить способы подключения и управления CPU, GPU и ASIC. Теперь производительность на Вт и эффективность перемещения данных стали первостепенными ограничениями при проектировании чипов. Патрик Литтл (Patrick Little), президент и генеральный директор SiFive заявил, что ИИ-инфраструктура больше не строится из универсальных компонентов, а разрабатывается совместно с нуля: «Интегрируя NVLink Fusion с высокопроизводительными вычислительными подсистемами SiFive, мы предоставляем клиентам открытую и настраиваемую платформу CPU, которая легко интегрируется с ИИ-инфраструктурой NVIDIA, обеспечивая исключительную эффективность в масштабах ЦОД». 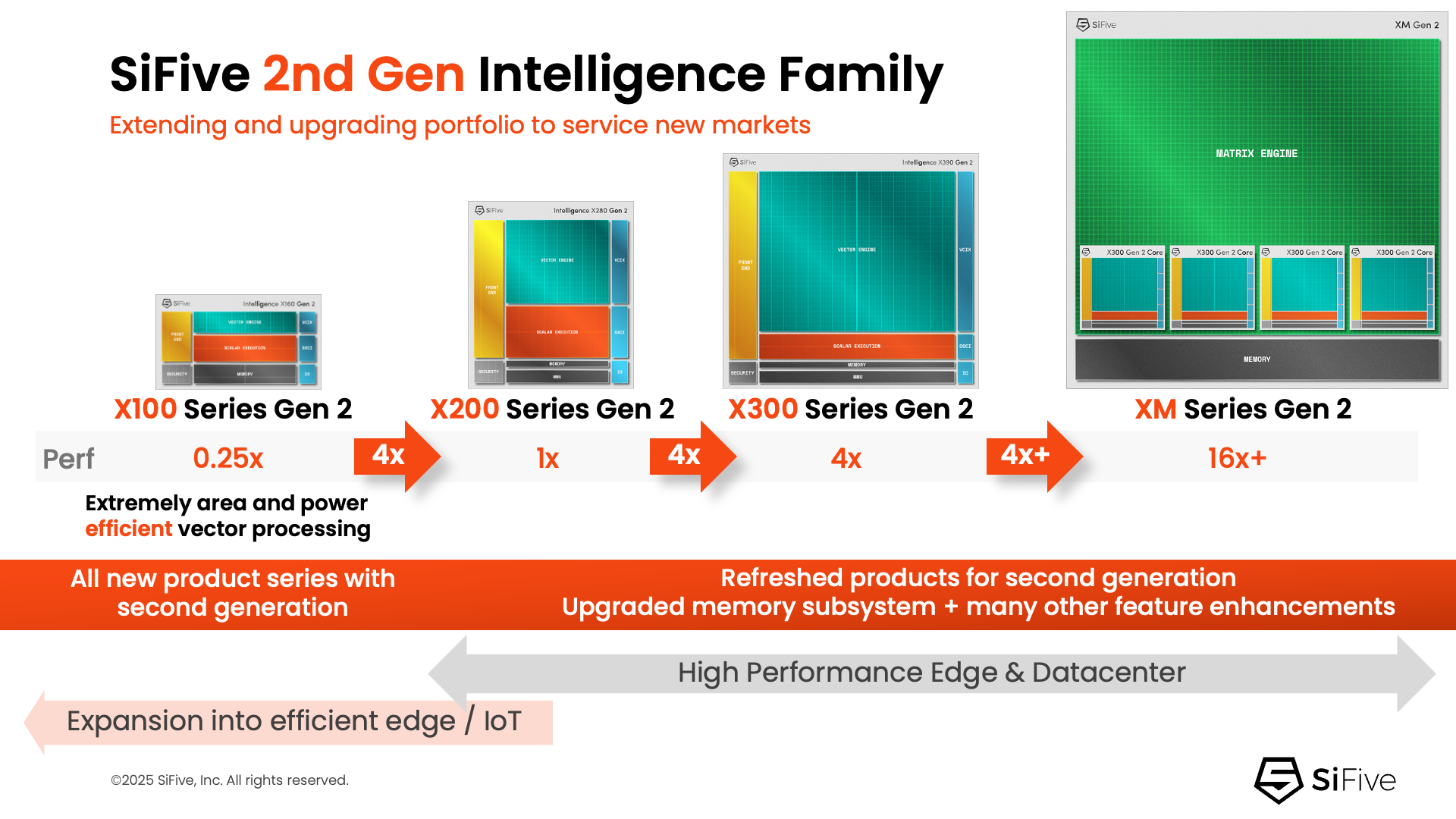
Источник изображения: SiFive Пресс-релиз SiFive не содержит каких-либо конкретных планов по продуктам, кроме сообщения о добавления поддержки NVLink к «высокопроизводительным решениям для ЦОД» SiFive. Предположительно, речь идёт о чипах платформы Vera Rubin или более поздних, т.е. о NVLink 6. Для SiFive — как поставщика IP-блоков RISC-V CPU — интерес заключается в использовании интерконнекта NVLink-C2C, который обеспечивает высокоскоростную, полностью кеш-когерентную связь между CPU и GPU, и это предпочтительный способ подключения к ускорителям NVIDIA в высокоинтегрированных системах. В рамках экосистемы NVLink Fusion NVIDIA предлагает NVLink-C2C в качестве лицензируемого IP-ядра, что упростит интеграцию шины в будущие чипы SiFive. Для SiFive это может стать конкурентным преимуществом. Кроме того, NVIDIA объявила о поддержке RISC-V — на эту архитектуру портируют CUDA и драйверы, что со временем откроет для компании новые рынки.
03.12.2025 [01:28], Владимир Мироненко
AWS «сдалась на милость» NVIDIA: анонсированы ИИ-ускорители Trainium4 с шиной NVLink FusionAWS готовит Arm-процессоры Graviton5, которые составят компанию ИИ-ускорителям Trainium4 с интерконнектом NVLink Fusion, фирменными EFA-адаптерам и DPU Nitro 6 с движком Nitro Isolation Engine. Но что более важно, все они будут «упакованы» в стойки стандарта NVIDIA MGX. Amazon и NVIDIA объявили о долгосрочном партнёрстве, в рамках которого ИИ-ускорители Trainium4 получит шину NVIDIA NVLink Fusion шестого поколения (по-видимому, 3,6 Тбайт/с в дуплексе), которая позволит создать стоечную платформу нового поколения, причём, что интересно, на базе архитектуры NVIDIA MGX, которая передана в OCP. Пикантность ситуации в том, что AWS годами практически игнорировала OCP, самостоятельно создавая стойки, их компоненты, включая СЖО, и архитектуру ИИ ЦОД в целом. Даже в нынешнем поколении стоек с GB300 NVL72 отказалась от референсного дизайна NVIDIA. NVIDIA же напирает на то, что для гиперскейлерам крайне трудно заниматься кастомными решениями — циклы разработки стоечной архитектуры занимают много времени, поскольку помимо проектирования специализированного ИИ-чипа, гиперскейлеры должны озаботиться вертикальным и горизонтальным масштабированием, интерконнектами, хранилищем, а также самой конструкцией стойки, включая лотки, охлаждение, питание и ПО. 
Источник изображения: NVIDIA Вместе с тем управление цепочкой поставок отличается высокой сложностью, так как требуется обеспечить согласованную работу десятков поставщиков, ответственных за десятки тысяч компонентов. И даже одна задержка поставки или замена одного компонента может поставить под угрозу весь проект. Платформа NVIDIA если не устраняет целиком, то хотя бы смягчает эти проблемы, предлагая готовые стандартизированные решения, которые могут поставлять множество игроков рынка. 
Источник изображения: NVIDIA По словам NVIDIA, в отличие от других подходов к масштабированию сетей, NVLink — проверенная и широко распространённая технология. В сочетании с фирменным ПО NVLink Switch обеспечивает увеличение производительности и дохода от ИИ-инференса до трёх раз, объединяя 72 ускорителя в одном домене. Пользователи, внедрившие NVLink Fusion, могут использовать любую часть платформы — каждый компонент может помочь им быстро масштабироваться для удовлетворения требований интенсивного инференса и обучения моделей агентного ИИ, говорит NVIDIA. 
Источник изображения: AWS Что касается самих ускорителей Trainium4, то в сравнении с Trainium3 они будут вшестеро быстрее в FP4-расчётах, втрое быстрее в FP8-вычислениях, а пропускная способность памяти будет увеличена вчетверо. Впрочем, пока собственные ускорители Amazon не всегда могут составить конкуренцию чипам NVIDIA. Любопытно и то, что в рассказе о Trainium3 компания отметила о переходе от PCIe к UALink в коммутаторах NeuronSwitch для фирменного интерконнекта NeuronLink, объединяющего до 144 чипов Trainium. Однако после крупных инвестиций NVIDIA в Synopsys развитие UALink как открытой альтернативы NVLink теперь под вопросом.
18.11.2025 [23:59], Владимир Мироненко
Arm добавила Neoverse поддержку NVIDIA NVLink FusionArm объявила о расширении возможностей платформы Neoverse с помощью NVIDIA NVLink Fusion в рамках партнёрства с NVIDIA, обеспечивая всей экосистеме ту же производительность, пропускную способность и эффективность, которые впервые были реализованы на платформах Grace Hopper и Grace Blackwell. «NVLink Fusion — это связующее звено эпохи ИИ, объединяющее все CPU, GPU и ускорители в единую архитектуру стоечного масштаба», — заявил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. Как сообщается в пресс-релизе, два года назад Arm и NVIDIA представили платформу Grace Hopper, в которой технология NVLink обеспечила согласованную интеграцию CPU и GPU. NVLink Fusion обеспечивает компаниям возможность подключать вычислительные системы на базе Arm к предпочитаемым ими ускорителям через согласованный интерфейс с высокой пропускной способностью. 
Источник изображения: NVIDIA Устойчивый спрос на Grace Blackwell способствует распространению NVLink Fusion во всей экосистеме Neoverse, позволяя партнёрам создавать дифференцированные, энергоэффективные ИИ-системы на базе Arm, отвечающие современным требованиям к производительности и масштабируемости. Arm отметила, что на текущий момент развёрнуто более чем 1 млрд ядер Neoverse и уверенно движется к достижению 50 % доли рынка среди ведущих гиперскейлеров к 2025 году. Все крупные провайдеры — AWS, Google, Microsoft, Oracle и Meta✴ — используют Neoverse, а ИИ ЦОД следующего поколения, такие как проект Stargate, используют Arm как основную вычислительную платформу. NVLink Fusion совместим с технологией AMBA CHI C2C (Coherent Hub Interface Chip-to-Chip) компании Arm, которая обеспечивает когерентное высокоскоростное соединения между CPU и ускорителями. Arm внедряет в платформу Neoverse последнюю версию протокола AMBA CHI C2C, чтобы SoC Neoverse могли беспрепятственно передавать данные между CPU Arm и ускорителями. Благодаря этому обеспечивается более быстрая интеграция, более быстрый вывод на рынок и большая гибкость для разработчиков ИИ-систем нового поколения. В свою очередь, NVIDIA работает над стандартизацией многих компонентов в этих системах для повышения надёжности и времени безотказной работы. С этой целью в CPU NVIDIA Vera следующего поколения будут использоваться кастомные ядра Arm вместо ядер Neoverse. Fujitsu также разрабатывает собственные Arm-процессоры MONAKA-X, которые тоже получат NVLink Fusion. NVLink Fusion получат и x86-процессоры Intel.
04.10.2025 [12:56], Сергей Карасёв
Fujitsu и NVIDIA создадут вычислительную ИИ-инфраструктуру нового поколенияЯпонская корпорация Fujitsu объявила о расширении стратегического сотрудничества с NVIDIA с целью создания полнофункциональной инфраструктуры ИИ следующего поколения, в состав которой войдут ИИ-агенты. Предполагается, что инициатива поможет ускорить развитие таких отраслей, как здравоохранение, производство, робототехника и др. Партнёры намерены работать по ряду направлений. В частности, Fujitsu и NVIDIA займутся созданием передовой вычислительной инфраструктуры для задач ИИ. Речь идёт об объединении серверных процессоров Fujitsu Monaka на архитектуре Arm с высокопроизводительными GPU разработки NVIDIA. Для этого будет задействована технология NVLink Fusion, позволяющая применять скоростные интерконнекты NVLink со сторонними чипами. Конечной целью является предоставление комплексной экосистемы HPC-ИИ с интегрированным софтом Fujitsu для Arm-процессоров и NVIDIA CUDA. Кроме того, сотрудничество предусматривает создание «саморазвивающейся» платформы ИИ-агентов. Она, как ожидается, обеспечит высокую производительность и безопасность. Планируется внедрение механизма, который позволит агентам и моделям ИИ развиваться автономно с возможностью оптимизации под запросы конкретных отраслей. В конечном итоге, такие агенты будут предоставляться заказчикам в виде микросервисов NVIDIA NIM. 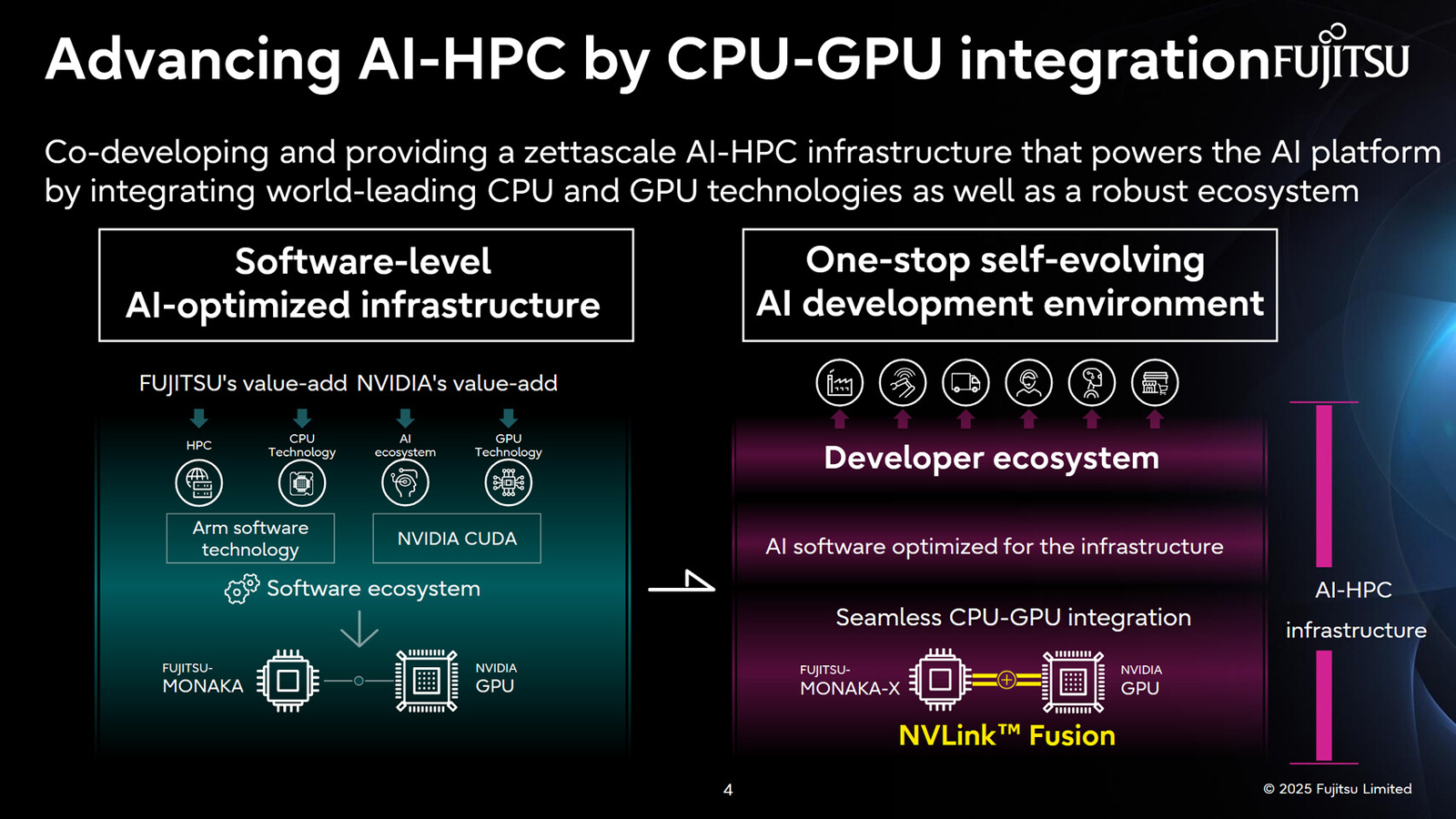
Источник изображений: Fujitsu Ещё одним направлением сотрудничества названо формирование партнёрской экосистемы для расширения использования агентов и моделей ИИ. Планируется также разработка передовых квантовых технологий, включая гибридные квантово-классические вычислительные системы на основе чипов Monaka и НРС-решений NVIDIA.  В целом, как отмечается, к 2030 году спрос на вычислительные мощности для ИИ в Японии вырастет в 320 раз по сравнению с 2020-м. На этом фоне местные компании, включая Fujitsu, SoftBank и KDDI, активно реализуют различные проекты, направленные на развитие рынка ИИ.
18.09.2025 [16:09], Владимир Мироненко
Intel разработает для NVIDIA кастомные CPU для серверов и ПК, а NVIDIA вложит в Intel $5 млрдNVIDIA и корпорация Intel заключили соглашение о сотрудничестве с целью совместной разработки специализированных чипов для ЦОД и ПК для использования гиперскейлерами, а также другими клиентами на корпоративном и потребительском рынках. Согласно пресс-релизу, компании намерены обеспечить бесшовное объединение архитектур NVIDIA и Intel с использованием NVIDIA NVLink, реализуя преимущества NVIDIA в области ИИ и ускоренных вычислений совместно с ведущими технологиями процессоров Intel и экосистемой x86 для предоставления передовых решений для клиентов. Ранее NVIDIA представила интерконнект NVLink Fusion, который как раз и позволяет объединять решения компании с чиплетами других вендоров. Одним из первых продуктов стал чип GB10, включающий GPU Blackwell и Arm-процессор MediaTek. В рамках партнёрства Intel разработает кастомные серверные x86-процессоры для ИИ-платформ NVIDIA. Для персональных компьютеров Intel разработает SoC с архитектурой x86 и GPU-чиплетами NVIDIA RTX. Новые SoC RTX на базе x86 будут использоваться в широком спектре ПК. У Intel уже был опыт интеграции GPU AMD в свои SoC, но не слишком удачный — Kaby Lake-G были заброшены через пару лет после выхода. 
Источник изображения: NVIDIA В рамках соглашения о сотрудничестве NVIDIA инвестирует в Intel $5 млрд путём приобретения на эту сумму обыкновенных акций Intel по цене $23,28 за единицу. После этого объявления акции Intel подскочили на премаркете на 33 % до примерно $33 за единицу, сообщил ресурс CNBC. Ранее SoftBank потратила $2 млрд на покупку акций Intel по $23/шт. В конце августа власти США приобрели 9,9 % долю в Intel за $8,9 млрд, получив акции по $20,47 за бумагу. «Это историческое сотрудничество тесно связывает ИИ-технологии и ускоренные вычисления NVIDIA с CPU Intel и обширной экосистемой x86 — слиянием двух платформ мирового класса. Вместе мы расширим наши экосистемы и заложим основу для следующей эры вычислений», — отметил генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). Как полагают аналитики CNBC, сотрудничество, по всей видимости, не включают производство чипов NVIDIA на производственных мощностях Intel.
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 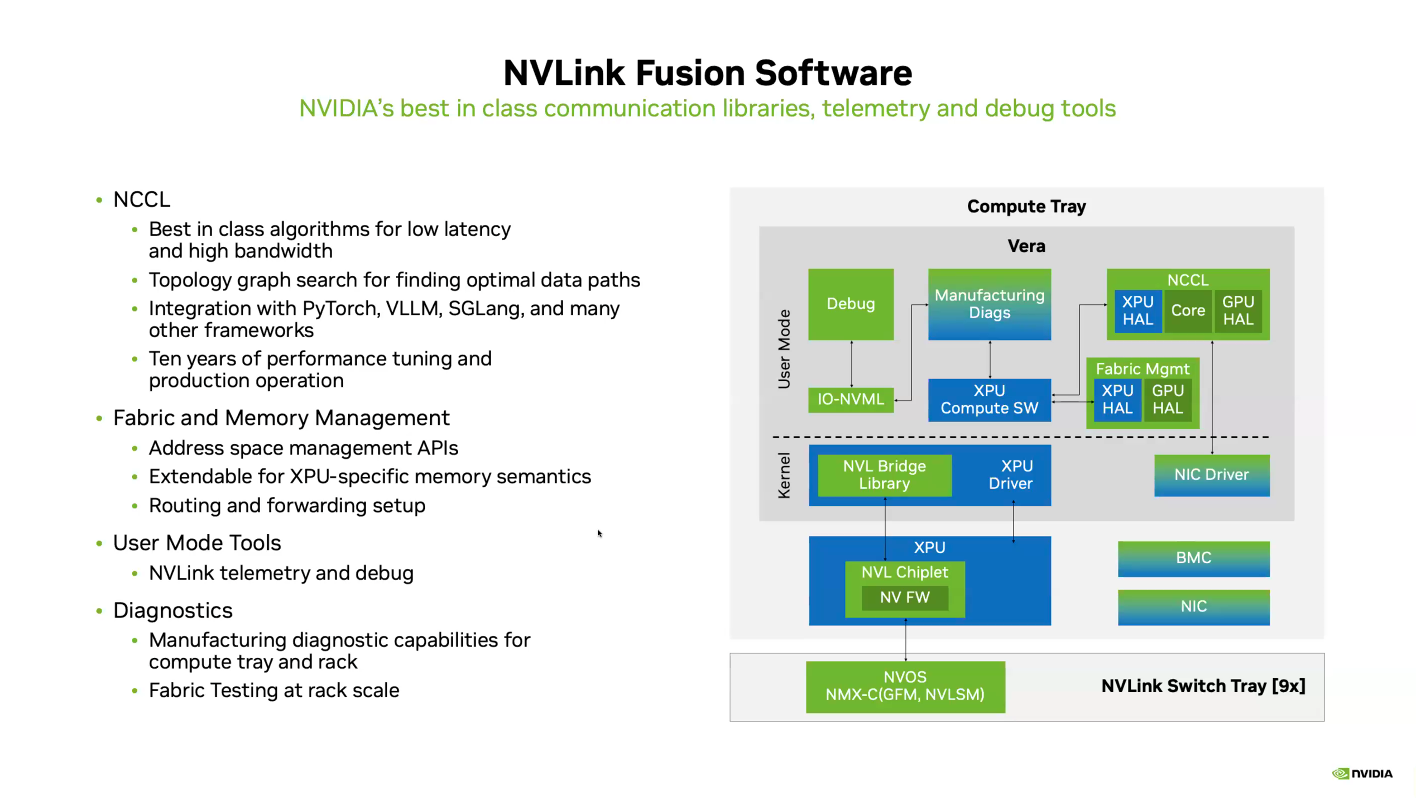 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 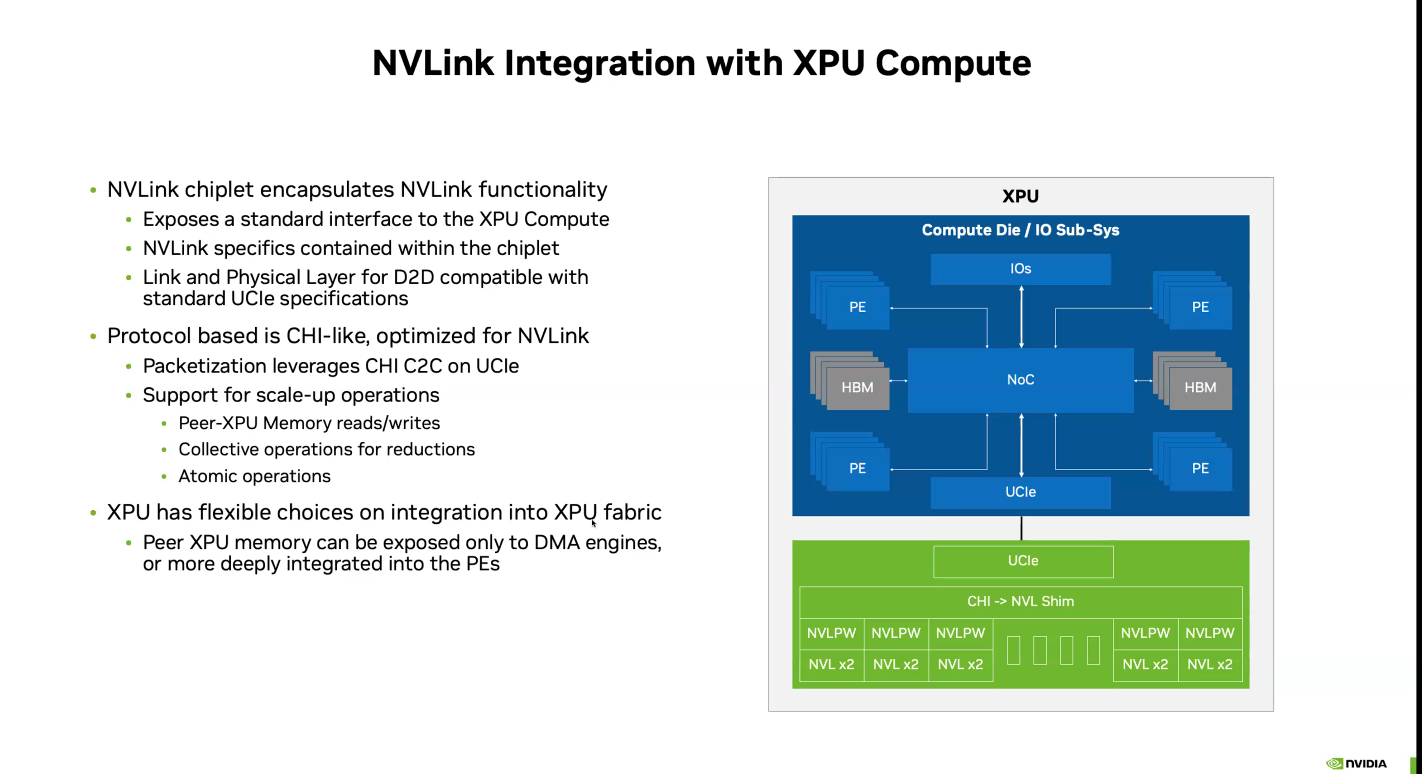 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 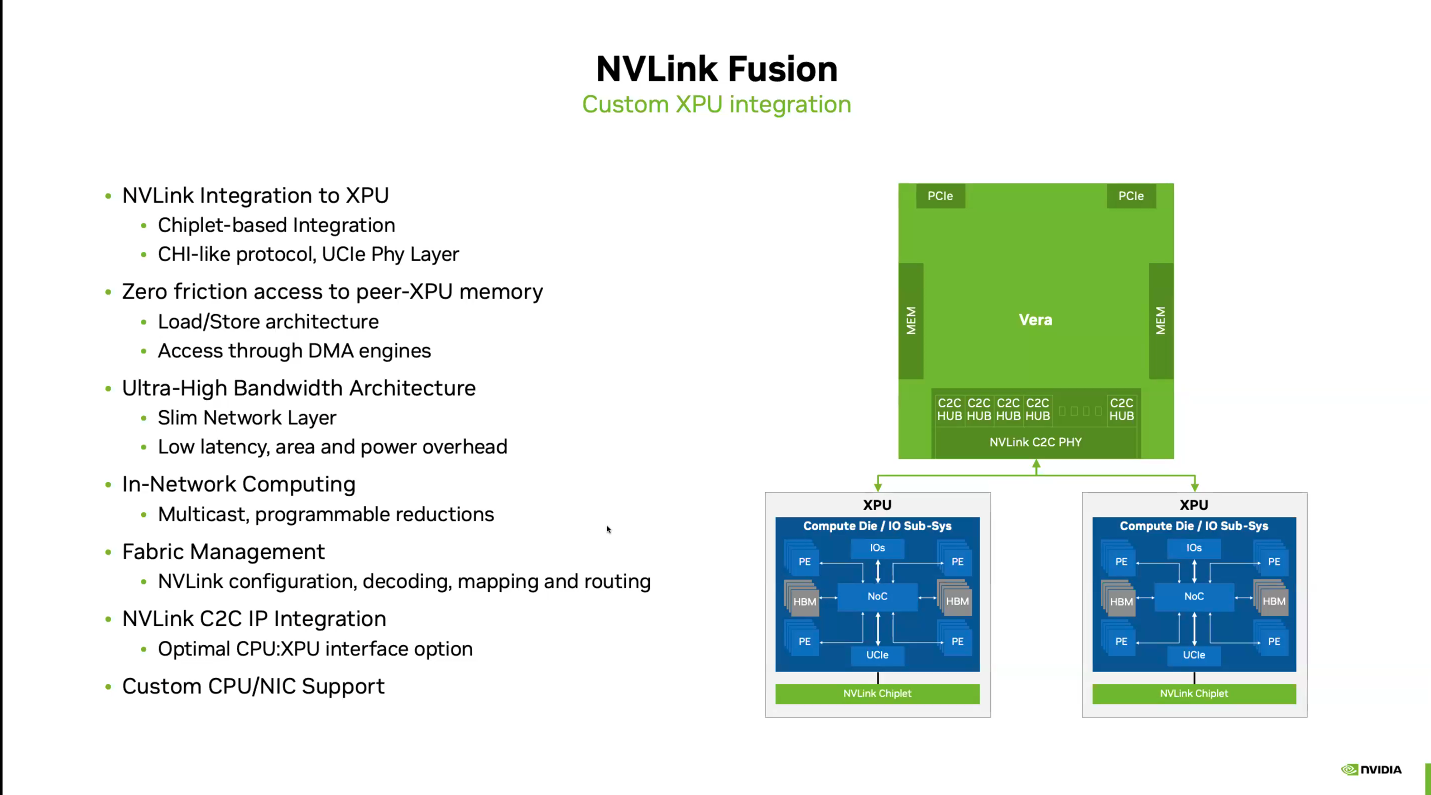 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 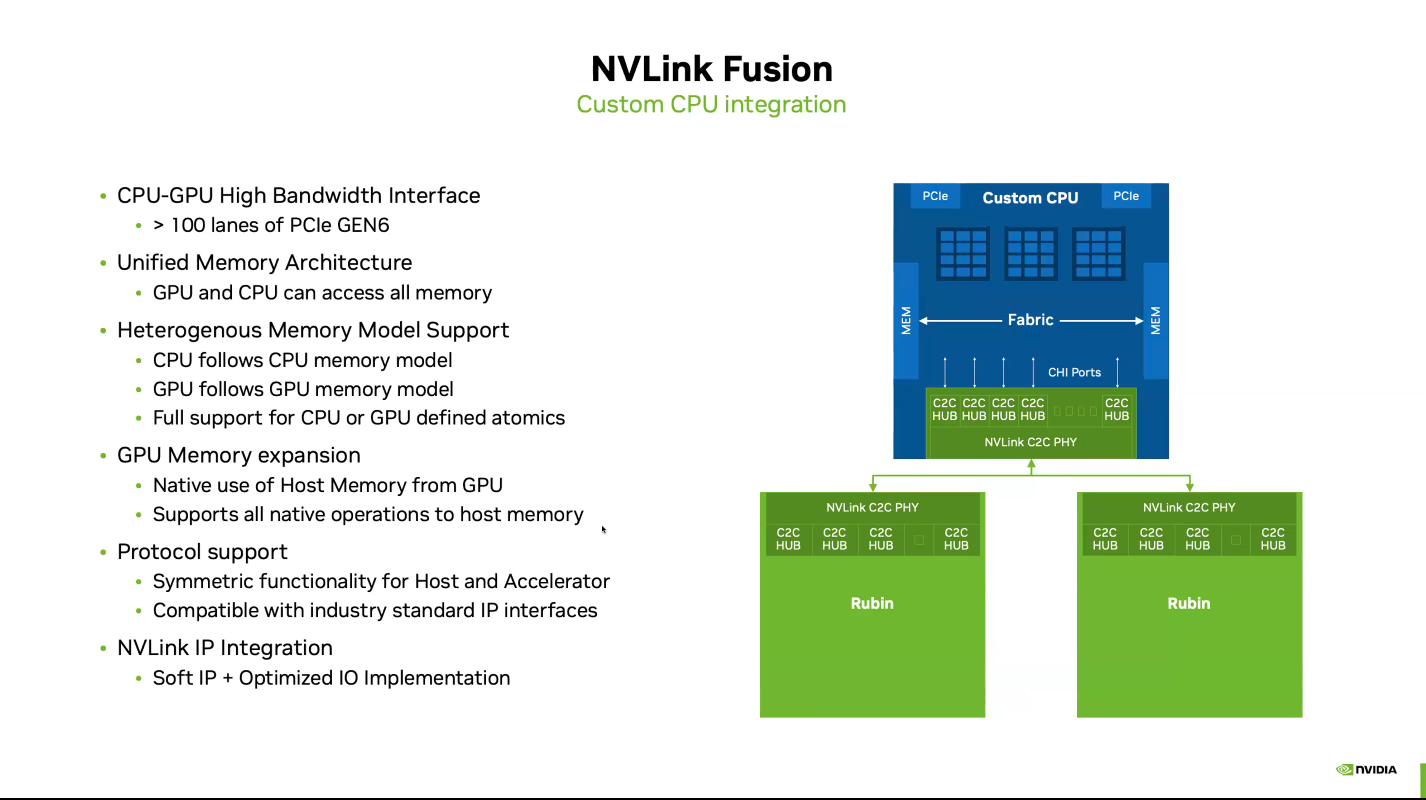 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
22.08.2025 [13:30], Алексей Разин
NVIDIA поможет японцам создать один из мощнейших суперкомпьютеров мира FugakuNEXTВ начале этого десятилетия созданный в Японии суперкомпьютер Fugaku пару лет удерживался на верхней строчке в рейтинге мощнейших систем мира TOP500, он и сейчас занимает в нём седьмое место. В попытке технологического реванша японский исследовательский институт RIKEN доверился компании NVIDIA, которая поможет Fujitsu создать суперкомпьютер Fugaku NEXT. Помимо Arm-процессоров Fujitsu MONAKA-X, в основу нового японского суперкомпьютера лягут и ускорители NVIDIA, хотя изначально планировалось обойтись без них. NVIDIA будет принимать непосредственное участие в интеграции своих компонентов в суперкомпьютерную систему, создаваемую японскими партнёрами. По меньшей мере, скоростные интерфейсы, которыми располагает NVIDIA, пригодятся для обеспечения быстрого канала передачи информации между CPU и ускорителями. Сама NVIDIA обтекаемо говорит, что для этого можно задействовать шину NVLink Fusion. С ускорителями AMD, по-видимому, эти процессоры будут общаться более традиционно, т.е. по шине PCIe. 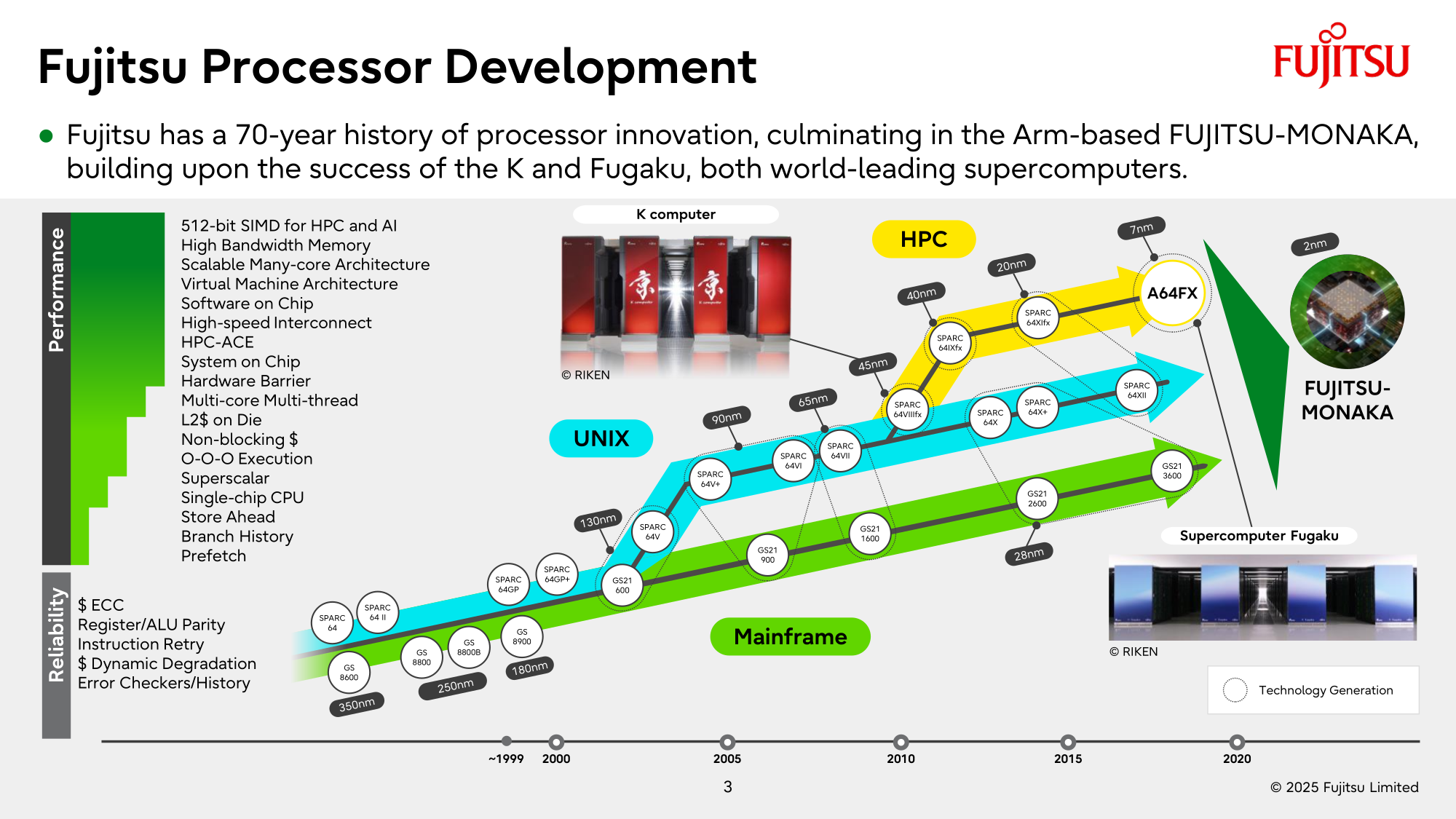
Источник изображений: Fujitsu Кроме того, NVIDIA собирается применить в составе данной системы передовые типы памяти. Применяемые при создании FugakuNEXT решения, по мнению представителей NVIDIA, смогут стать типовыми для всей отрасли в дальнейшем. Подчёркивается, что будущая платформа станет не просто техническим апгрейдом, а инвестицией в будущее страны. 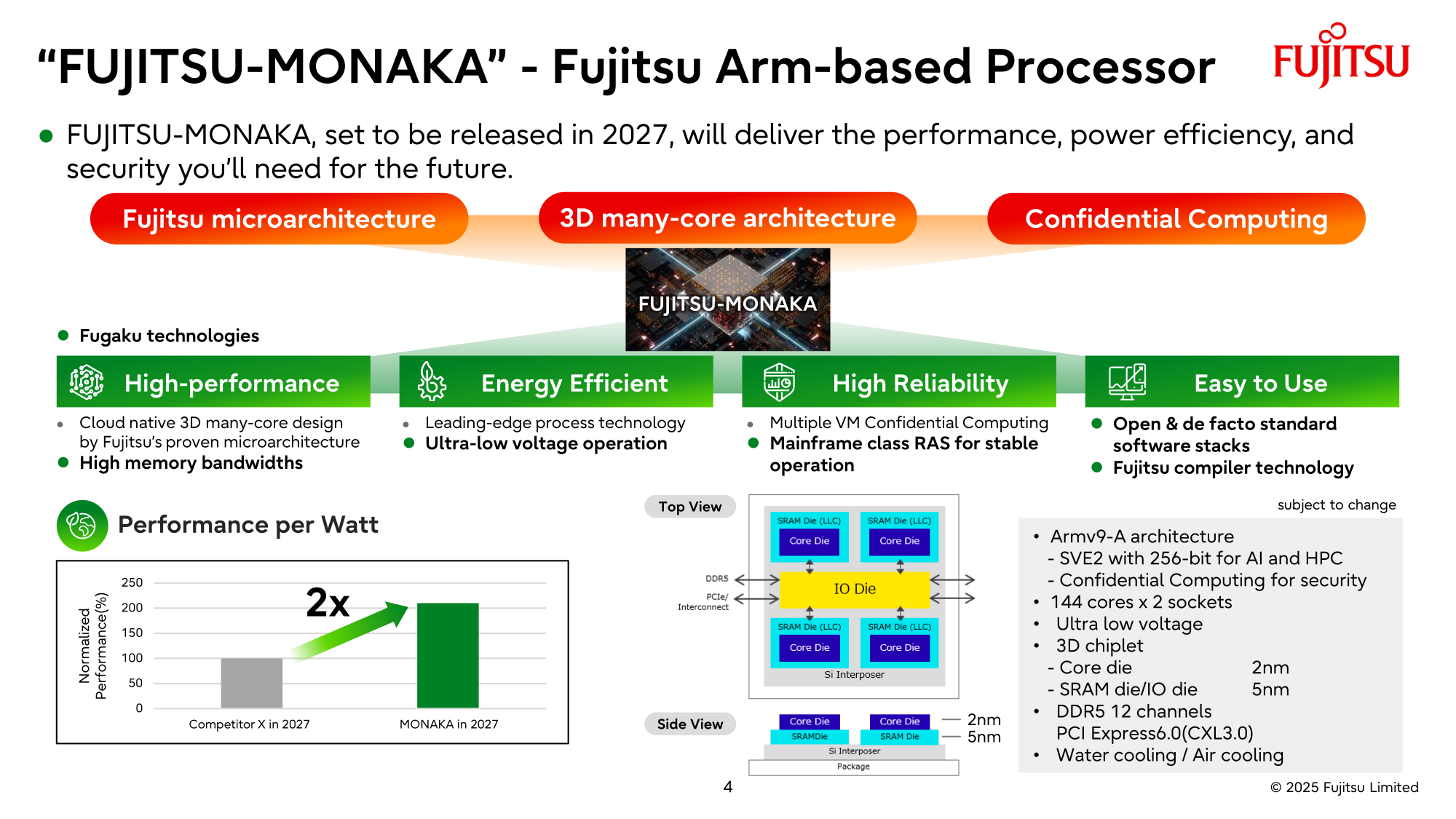 Сама архитектура системы не уточняется, поэтому сложно судить, насколько активно японские разработчики будут использовать ускорители NVIDIA, и к какому поколению они будут относиться. Создатели ставят перед собой амбициозные цели — FugakuNEXT должна стать первой системой «зетта-масштаба». Своего предшественника она должна превзойти более чем в пять раз, обеспечив быстродействие на уровне 600 Эфлопс (FP8). 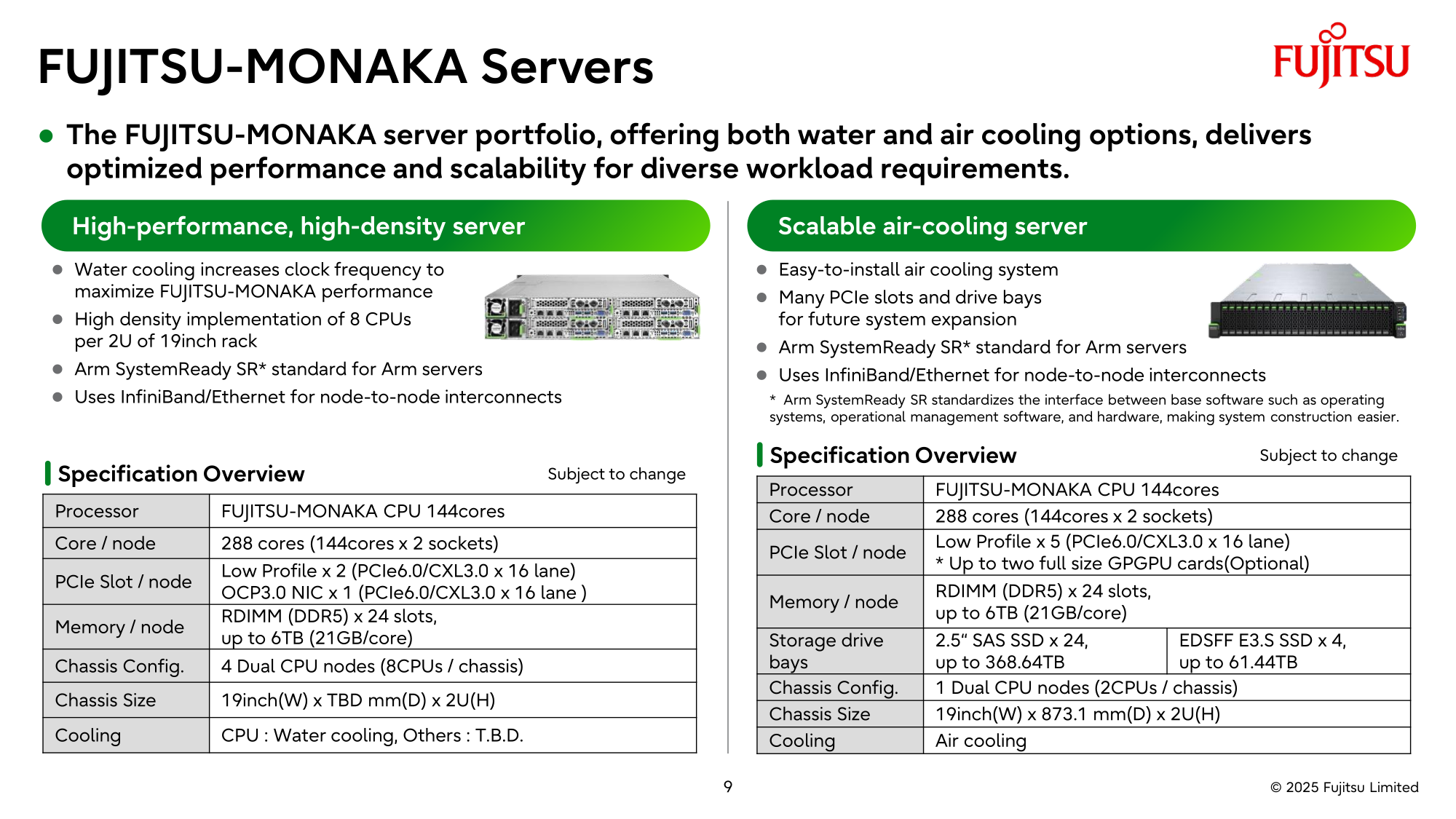 На уровне приложений прирос быстродействия может быть стократным, отмечают создатели. Новый суперкомпьютер сможет применяться для обучения больших языковых моделей. Впрочем, в строй он будет введён лишь к 2030 году, а Fujitsu ещё только предстоит выпустить свои процессоры MONAKA-X для этой системы.
19.05.2025 [16:07], Руслан Авдеев
NVLink Fusion: NVIDIA открыла фирменный интерконнект NVLink сторонним разработчикам чиповNVIDIA представила технологию NVLink Fusion, позволяющую применять скоростные интерконнекты NVLink с «полукастомными» ускорителями, включая ASIC-модули. Благодаря этому NVLink можно использовать даже с ускорителями, разработанными сторонними компаниями, сообщает The Register. NVLink 5 поколения сегодня обеспечивает пропускную способность на уровне 1,8 Тбайт/с (900 Гбайт/с в каждом направлении) на каждый ускоритель с возможностью объединения до 72 ускорителей. Ранее поддержка интерконнектов компании ограничивалась ускорителями и процессорами NVIDIA, хотя сообщалось и о сотрудничестве с MediaTek. 
Источник изображений: NVIDIA Как сообщают в NVIDIA, технологию будут предлагать в двух конфигурациях — первая предназначена для связи кастомных CPU с ускорителями NVIDIA (CPU-to-GPU), в 14 раз быстрее в сравнении с PCIe 5.0 (128 Гбайт/с). Второй, более необычный вариант предусматривает связь CPU Crace и Vera с ускорителями, разработанными не NVIDIA. Этого можно добиться, используя либо IP-блок NVLink, либо отдельный чиплет. 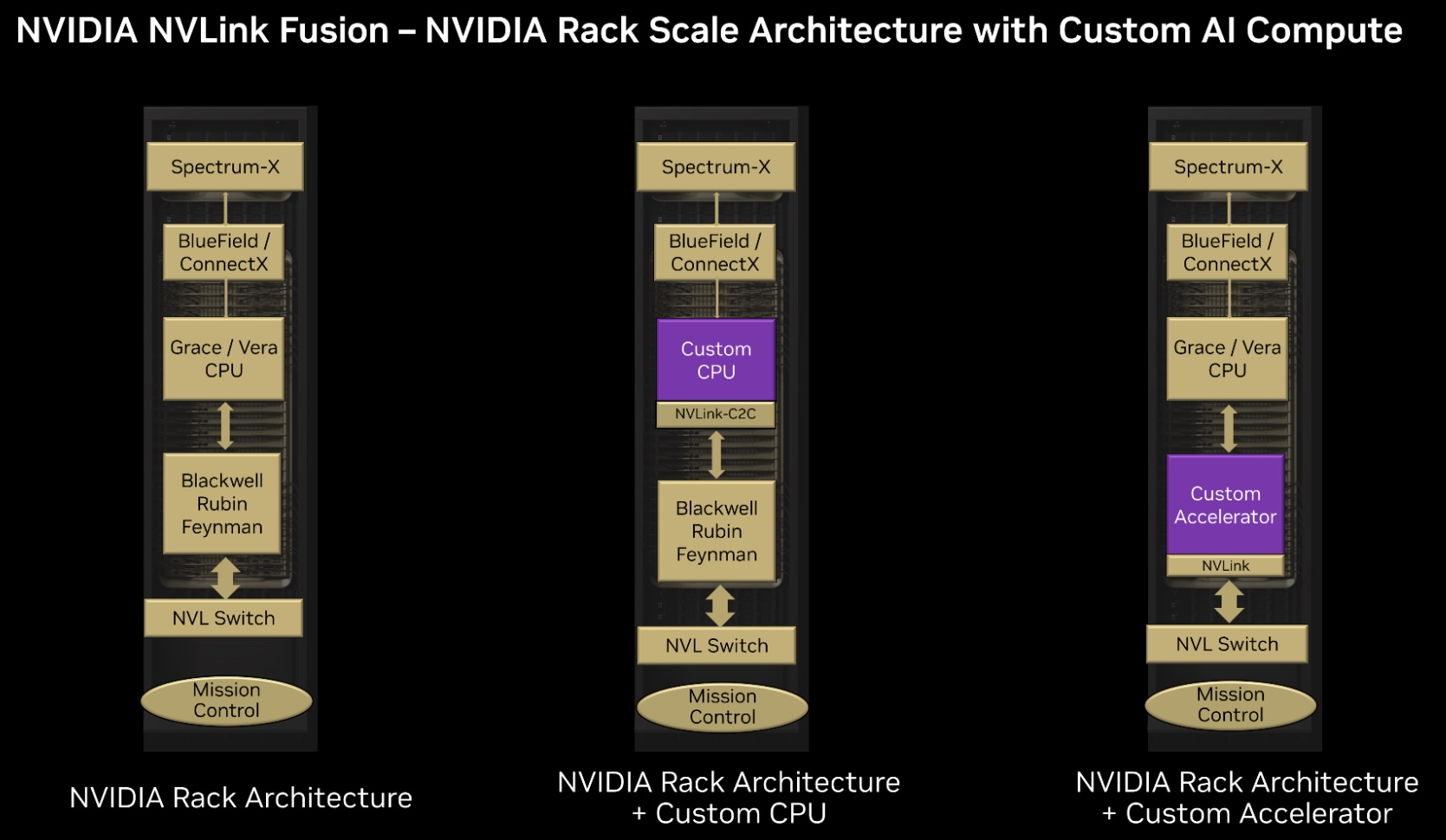 В теории это откроет возможность создания кластеров-«суперчипов» с любыми комбинациями CPU и GPU NVIDIA, AMD, Intel и др., но только с участием продуктов NVIDIA. Другими словами, объединить, например, только процессоры и ускорители Intel с помощью NVLink Fusion не выйдет. Кроме того, NVIDIA не открывает свой стандарт полностью. Как сообщает пресс-служба NVIDIA, поддержку интерконнекта уже обещали добавить MediaTek, Marvell, AIchip, Astera Labs, Synopsys и Cadence, а Fujitsu и Qualcomm планируют добавить объединить свои CPU с ускорителями NVIDIA посредством NVLink Fuison. При этом ни AMD, ни Intel в списке партнёров пока нет и, возможно, они там не появятся. Обе компании сделали ставку на Ultra Accelerator Link — открытую альтернативу NVLink. UALink первой версии предлагает всего лишь 200 Гбит/с на линию (до 800 Гбит/с на ускоритель), но позволяет объединить до 1024 ускорителей. Стандарт во много основан на AMD Infinity Fabric. Год назад AMD также приоткрыла Infinity Fabric, но в PCIe-версии, представив AFL (Accelerated Fabric Link). Intel же изначально сделала ставку на Ethernet для связи ускорителей внутри и вне узла.
26.03.2025 [01:00], Владимир Мироненко
NVIDIA поделится с MediaTek фирменным интерконнектом NVLink для создания кастомных ASICMediaTek объявила о планах расширить сотрудничество с NVIDIA, интегрировав NVLink в разрабатываемые ей ASIC, сообщил ресурс DigiTimes. В свою очередь, ресурс smbom.com пишет, что партнёры намерены совместно разрабатывать передовые решения с использованием NVLink и 224G SerDes. Аналитики предполагают, что выход NVIDIA в сектор ASIC позволит ей ускорить дальнейшее продвижение на рынке с использованием опыта MediaTek и при этом решать имеющиеся проблемы. Как ожидают аналитики, по мере развития сотрудничества двух компаний всё больше провайдеров облачных услуг будет проявлять интерес к работе с MediaTek. Внедрение NVLink в ASIC MediaTek может значительно повысить привлекательность сетевых решений NVIDIA. Объединив усилия, NVIDIA и MediaTek смогут предложить комплексную разработку кастомных ASIC, которая будет включать поддержку HBM4e, обширную библиотеку IP-блоков, передовые процессы производства и упаковки. MediaTek отдельно подчеркнула, что её SerDes-блоки является ключевым преимуществом при разработке ASIC. 
Источник изображения: MediaTek Компании расширяют сотрудничество с ведущими мировыми производствами полупроводников, ориентируясь на передовые техпроцессы. Применяя технологию совместной оптимизации проектирования (DTCO), они стремятся достичь оптимального соотношения между производительностью, энергопотреблением и площадью (PPA). Сообщается, что несколько облачных провайдеров уже изучают объединённое IP-портфолио NVIDIA и MediaTek. 
Источник изображения: MediaTek По неофициальным данным, Google уже прибегла к услугам MediaTek при разработке 3-нм TPU седьмого поколения, которое поступит в массовое производство к III кварталу 2026 года. Ожидается, что переход на 3-нм процесс принесет MediaTek более $2 млрд дополнительных поступлений. По данным источников в цепочке поставок, восьмое поколение TPU перейдёт на 2-нм процесс TSMC, что вновь укрепит позиции MediaTek. Также прогнозируется, что предстоящий выход чипа GB10 совместной разработки NVIDIA и MediaTek, и долгожданного чипа N1x, значительно улучшат бизнес-операции MediaTek и ещё больше укрепят позиции компании в полупроводниковой отрасли. Эксперты отрасли считают, что MediaTek имеет все возможности для того, что стать ключевым бенефициаром роста спроса на ИИ-технологии, особенно для малых и средних предприятий.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 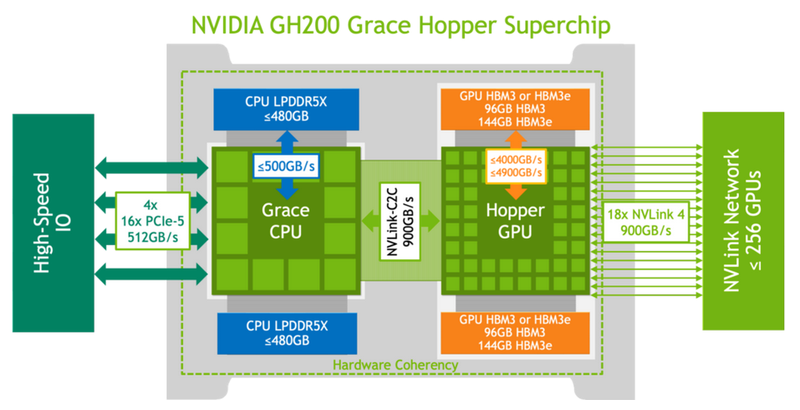
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 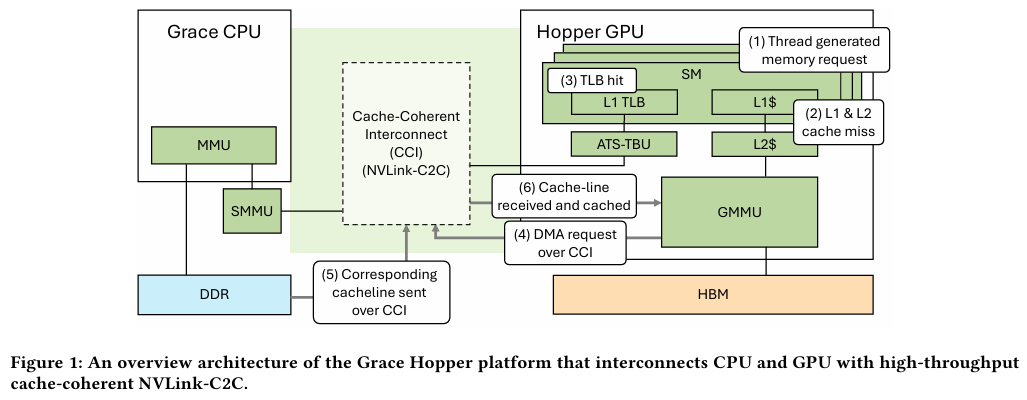
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 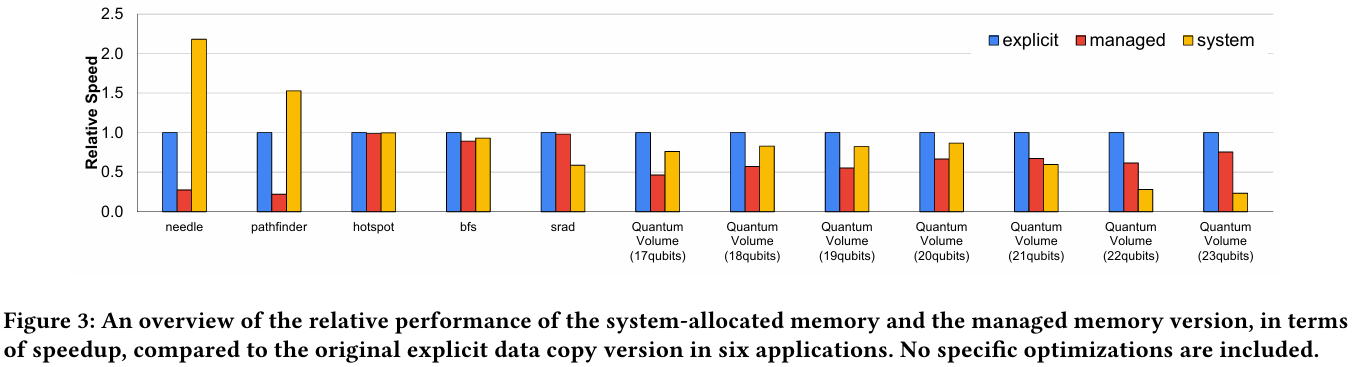
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования. |
|

