Материалы по тегу: risc-v
|
11.12.2025 [01:30], Владимир Мироненко
Qualcomm купила разработчика серверных RISC-V процессоров Ventana Micro SystemsQualcomm объявила о приобретении стартапа Ventana Micro Systems, специализирующегося на разработке серверных процессоров на основе архитектуры RISC-V. Как пояснила компания, это свидетельствует о её приверженности развитию RISC-V, открытой альтернативы Arm и x86. По словам Qualcomm, сделка расширит её возможности в разработке чипов на базе RISC-V и кастомных процессоров Oryon за счёт интеграции имеющегося у Ventana опыта в этом направлении. Qualcomm делает ставку на Oryon в деле завоевания новых рынков, в том числе серверного, в рамках продолжающейся диверсификации бизнеса. Компания получила ядра Oryon, совместимые с Arm, вместе с приобретением стартапа Nuvia за $1,4 млрд в 2021 году. Oryon уже прописались в процессорах Snapdragon X Series. Теперь же Qualcomm намерена предпринять ещё одну попытку разработки серверных процессоров. Прошлая попытка с процессорами Centriq 2400 завершилась неудачей. В этом году эти усилия были подкреплены наймом бывшего главного архитектора Intel Xeon и сделкой по приобретению Alphawave Semi за 2,4 млрд, пишет CRN. Qualcomm, которая уже использует архитектуру RISC-V в некоторых продуктах за пределами рынков ПК и серверов, заявила, что вклад Ventana укрепит ее «технологическое лидерство в эпоху ИИ во всех сферах бизнеса», указывая на большие надежды, возлагаемые на это приобретение: «Мы считаем, что ISA RISC-V имеет потенциал для продвижения технологий процессоров, обеспечивая инновации во всех продуктах. Приобретение Ventana Micro Systems знаменует собой важный шаг на нашем пути к предоставлению передовых в отрасли технологий процессоров на базе RISC-V для всех продуктов». 
Источник изображения: Ventana Micro Systems Ventana Micro Systems, базирующаяся в Купертино (Cupertino), была основана в 2018 году. Как сообщается на сайте компании, разработанная ею технология изготовления процессоров на базе RISC-V, обеспечивает «производительность, сопоставимую с новейшими процессорами на Arm и x86 для ЦОД». Эта технология доступна в виде многоядерных UCIe-чиплетов, а также может быть интегрирована другими компаниями в собственные SoC. И первое, и второе поколение процессоров Ventana Veyron предлагало до 192 ядер RISC-V. Свои разработки Ventana рассчитывает использовать в различных сферах, включая облачные вычисления, корпоративные ЦОД, системы гиперскейлеров, 5G, периферийные вычисления, ИИ и машинное обучение, а также автомобильную промышленность. По некоторым оценкам, годовая выручка Ventana составляет $37,4 млн. Так что ей в каком-то смысле повезло, поскольку даже достаточно заметные разработчики решений на базе RISC-V часто не могут конкурировать с крупными игроками и готовы или продаться кому-нибудь, или вынуждены сокращать штат, или закрываться целиком. Сообщение о покупке Ventana последовало после того, как Qualcomm в сентябре заявила о «полной победе» в судебном споре с Arm, которая добивалась прекращения продаж и уничтожения всех чипов Qualcomm, содержащих ядра Oryon, из-за предполагаемых нарушений лицензий на архитектуру Arm со стороны Qualcomm и Nuvia. Любопытно, что в 2022 году Ventana объявила о стратегическом партнёрстве с Intel в рамках IFS. Последняя годом позже закрыла программу Pathfinder for RISC-V.
10.12.2025 [09:24], Владимир Мироненко
Евросоюз опять захотел занять 20 % рынка полупроводников, но Китай и США уже «улетели в стратосферу»Реализация планов Европейского союза по ускорению движения к технологическому суверенитету вступает во вторую, критически важную фазу, пишет ресурс EE Times. «Европейский закон о чипах» (European Chips Act), принятый в апреле 2023 года с целью ускорения развития новых технологий и увеличения доли Европы на мировом рынке чипов до 20 % к 2030 году с нынешних 10 %, позволил мобилизовать капитал — общие обязательства по инвестициям достигли почти €69 млрд. «Закон ЕС о чипах 2.0», который находится в разработке, должен внести существенные изменения в политику ЕС и сместить акцент с производственных обязательств на обеспечение разработки следующего поколения вычислительной архитектуры и развитии кадрового потенциала. Цели ЕС также включают укрепление внутренних цепочек поставок полупроводников в Европе и стимулирование инвестиций в микросхемы для нагрузок ИИ и HPC, пишет ioplus.nl. Стратегический поворот в стратегии ЕС находит свою интеллектуальную опору в HiPEAC Vision 2025 — долгосрочной программе европейской сети HiPEAC (High Performance, Edge and Cloud computing), утверждающей, что будущая значимость Европы зависит не только от производства «кремния», но и от освоения парадигмы распределённых, устойчивых вычислений, которая сегодня требуется для развития ИИ-технологий. 
Источник изображения: Antoine Schibler/unsplash.com Эта переоценка становится неотложной необходимостью в связи с реальностью «Великого перераспределения» (Great Reallocation) США, которые с помощью агрессивной торговой политики и масштабных субсидий способствуют оттоку из Европы в США капиталов и интеллектуальной собственности, создавая сложности для развития промышленной базы Европы. Кроме того, отмечается «стратосферный рост» компаний из США и Китае на фоне отставания европейских в сфере вычислительных технологий. HiPEAC Vision, определяющее курс европейских исследований в области вычислений на следующее десятилетие, основано на концепции «Следующей вычислительной парадигмы» (Next Computing Paradigm, NCP), охватывающей высокопроизводительные экзафлопсные вычисления, облачные ЦОД и встраиваемые устройства. HiPEAC рассматривает этот сдвиг как динамичную совокупность «федеративных и распределённых сервисов». У Европы всё ещё есть сильные стороны, такие как мощный потенциал для разработки «периферийных и локальных устройств», сложных киберфизических систем (cyber-physical systems, CPS) и инструментов промышленной автоматизации. Важнейшим аспектом в NCP краткосрочной перспективе является использование и развитие «распределённого агентного ИИ» с акцентом на локальной обработке данных и федеративности с целью снижения зависимость от централизованных иностранных решений гиперскейлеров для обеспечения безопасности критически важных данных и инфраструктуры. Хотя сейчас Евросоюз готов признать, что отказаться от американских облаков «почти невозможно». При этом и гиперскейлеры признают, что уже не могут гарантировать суверенитет данных в Европе. 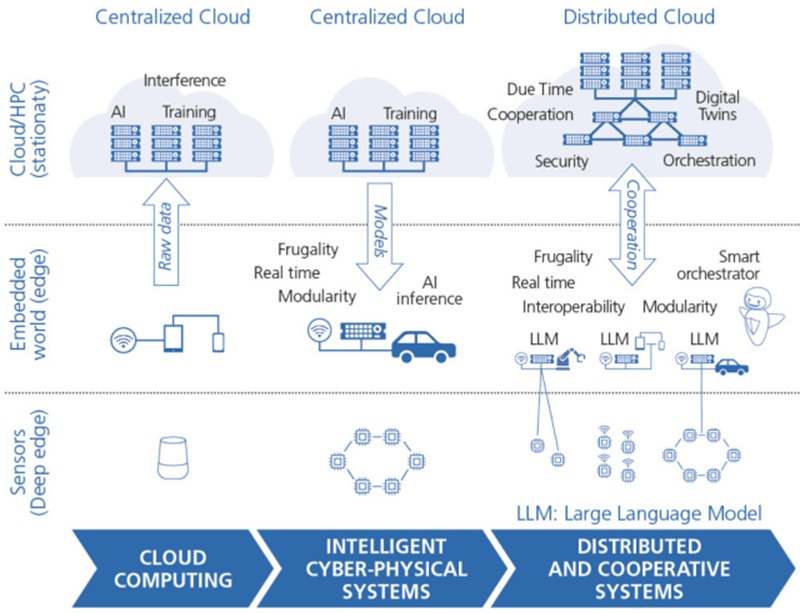
Источник изображения: HiPEAC, Denis Dutoit, CEA/EE Times Хотя «Европейский закон о чипах» позволил привлечь иностранные инвестиции, включая крупные проекты в Германии и Франции, углубленный анализ показывает «структурные ограничения, которые угрожают его долгосрочной эффективности». Также наблюдается перекос в пользу компаний, впервые реализующих инновационные технологии в реальных условиях и в коммерческом масштабе (First-of-a-Kind, FOAK), оставляя без достаточной поддержки более широкую цепочку поставок — проектные организации, производителей оборудования и поставщиков ключевых материалов. Вдобавок заявленная цель увеличить до 20 % долю на мировом рынке полупроводников к 2030 году вызывает в отрасли большие сомнения — отсутствие гарантированного рыночного спроса в Европе остаётся «главным сдерживающим фактором для инвестиций». В связи с этим SEMI Europe выступает за фундаментальное изменение инструментария стимулирования, рекомендуя, чтобы «Закон ЕС о чипах 2.0» обязывал государства-участников блока принять рамочную программу «гармонизированных налоговых льгот для НИОКР и капитальных затрат в области полупроводников», чтобы поддерживать инновации и производство на начальном этапе для дальнейшего укрепления европейской экосистемы с упором на поставщиков материалов и оборудования, проектирование и современную упаковку. Также отмечается, что налоговые льготы обеспечивают «предсказуемость и снижение административных расходов» по сравнению со сложными грантами. Они особенно эффективны для поддержки малых и средних предприятий (МСП) и модернизации существующих объектов. Согласно HiPEAC Vision, инвестиции в экосистему МСП имеют жизненно важное значение, поскольку именно МСП являются движущей силой прорывных инноваций. 
Источник изображения: Julia Fiander / Unsplash Необходимость разработки единой европейской стратегии также связана с агрессивной индустриальной политикой США, пишет EE Times. После принятия программы «Миссия Генезис» (The Genesis Mission) и угрозы введения «100-% пошлины на импортные полупроводники» правительством США ведущие технологические компании направляют миллиарды долларов инвестиций в инфраструктуру США, создавая ощутимый отток капитала из Европы. Так, Nokia уже пообещала инвестировать $4 млрд в США, а Ericsson расширила свой «умный» завод в Техасе, чтобы и далее участвовать в федеральных закупках. Чтобы Европа не стала просто рынком потребления зарубежных технологий, новый закон должен принять философские основы HiPEAC Vision: приоритет экосистемы проектирования и инструментальных средств, считают эксперты. Создание совместного предприятия по разработке чипов (Chips JU) вместо KDT JU направлено на решение этой проблемы путём развитии передовых мощностей проектирования и создании платформы виртуального проектирования (VDP). Этот процесс должен быть ускорен за счёт поддержки важнейших технологий, продвигаемых HiPEAC, таких как чиплеты и открытое аппаратное обеспечение, например, RISC-V, которые снижают барьеры для выхода на рынок и уменьшают зависимость от иностранцев. Ориентируясь в своей стратегии на фокусе на распределённом интеллекте и устойчивом развитии, сформулированном HiPEAC, и внедряя механизмы промышленной поддержки, предлагаемые SEMI Europe, Европа может превратить новый «Закон о чипах» из чрезвычайной меры в последовательную долгосрочную промышленную стратегию. Этот переход закрепляет за Европой статус не только площадки для размещения иностранных заводов, но и суверенного архитектора цифрового будущего.
24.11.2025 [15:14], Сергей Карасёв
Технологии тысячеядерного RISC-V-ускорителя Esperanto будут переданы в open sourceСтартап Ainekko, специализирующийся на разработке аппаратных и программных решений в сфере ИИ, по сообщению EE Times, приобрёл интеллектуальную собственность и некоторые активы компании Esperanto Technologies. Речь идёт о дизайне чипов, программных инструментах и фреймворке. Фирма Esperanto, основанная в 2014 году, специализировалась на создании высокопроизводительных ускорителей с архитектурой RISC-V для задач НРС и ИИ. В частности, было представлено изделие ET-SoC-1, объединившее 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Основной сферой применения чипа был заявлен инференс для рекомендательных систем, в том числе на периферии. Однако в июле нынешнего года стало известно, что Esperanto сворачивает деятельность и ищет покупателя на свои разработки — ключевых инженеров переманили крупные компании. А продать чипы Meta✴, в чём, по-видимому, и заключался изначальный план, не удалось. Как рассказала соучредитель Ainekko Таня Дадашева (Tanya Dadasheva), её компания работает с чипами Esperanto в течение примерно полугода. Изначально компания планировала использовать чипы Esperanto для запуска своего софтверного стека. В частности, удалось перенести llama.cpp up и tinygrad. Когда стало понятно, что Esperanto вряд ли выживет, было принято решение выкупить разработки стартапа. Во всяком случае, это лучше, чем просто закрыть компанию, оставив её заказчиков ни с чем, как поступила AMD с Untether AI. 
Источник изображения: Esperanto Ainekko планирует передать сообществу open source технологии Esperanto, связанные с многоядерной архитектурой RISC-V, включая RTL, референсные проекты и инструменты разработки. Предполагается, что решения Esperanto будут востребованы прежде всего в области периферийных устройств, где большое значение имеет энергоэффективность. Архитектура Esperanto, как утверждается, подходит для таких задач, как робототехника и дроны, системы безопасности, встраиваемое оборудование с ИИ-функциями и пр. Второй соучредитель Ainekko Роман Шапошник (Roman Shaposhnik) добавляет, что многоядерная архитектура Esperanto подходит не только для разработки ИИ-чипов, но и для создания «универсальной вычислительной платформы». Сама Ainekko намерена выпустить чип с восемью ядрами Esperanto и 16 Мбайт памяти MRAM, разработанной стартапом Veevx. Отмечается, что соучредитель и генеральный директор Veevx, ветеран Broadcom Даг Смит (Doug Smith), является ещё одним сооснователем Ainekko. В дальнейшие планы входит разработка процессора с 256 ядрами: по производительности он будет сопоставим с чипом Broadcom BCM2712 (4 × 64-бит Arm Cortex-A76), лежащим в основе Raspberry Pi 5, но оптимизирован для инференса.
18.11.2025 [16:55], Владимир Мироненко
d-Matrix привлекла ещё $275 млн и объявила о разработке первого ИИ-ускорителя с 3D-памятью Raptord-Matrix сообщила о завершении раунда финансирования серии C, в ходе которого было привлечено $275 млн инвестиций с оценкой рыночной стоимости компании в $2 млрд. Общий объём привлечённых компанией средств достиг $450 млн. Полученные средства будут направлены на расширение международного присутствия компании и помощь клиентам в развёртывании ИИ-кластеров на основе её технологий. Раунд C возглавил глобальный консорциум, включающий BullhoundCapital, Triatomic Capital и суверенный фонд благосостояния Сингапура Temasek. В раунде приняли участие Qatar Investment Authority (QIA) и EDBI, M12, венчурный фонд Microsoft, а также Nautilus Venture Partners, Industry Ventures и Mirae Asset. Сид Шет (Sid Sheth), генеральный директор и соучредитель d-Matrix, отметил, с самого начала компания была сосредоточена исключительно на инференсе. «Мы предсказывали, что когда обученным моделям потребуется непрерывная масштабная работа, инфраструктура не будет готова. Последние шесть лет мы потратили на разработку решения: принципиально новой архитектуры, которая позволяет ИИ работать везде и всегда. Это финансирование подтверждает нашу концепцию, поскольку отрасль вступает в эпоху ИИ-инференса», — добавил он. d-Matrix разработала ускоритель инференса Corsair на базе архитектуры с вычислениями в памяти DIMC (digital in-memory computing) — процессорные компоненты в нём встроены в память. Ускоритель предлагается вместе с сетевой картой JetStream. Также предлагается референсная архитектура SquadRack, которая упрощает создание ИИ-кластеров на базе Corsair. Она поддерживает до восьми серверов в стойке, каждая из которых содержит восемь ускорителей Corsair. Шасси SquadRack позволяет запускать ИИ-модели размером до 100 млрд параметров, хранящиеся полностью в SRAM. По данным d-Matrix, такая конфигурация обеспечивает на порядок большую производительность по сравнению с чипами с HBM. Вместе с оборудованием компания предлагает программный стек Aviator, который автоматизирует часть работы, связанной с развертыванием ИИ-моделей на ускорителе. Aviator также включает набор инструментов для отладки моделей и мониторинга производительности. 
Источник изображения: d-Matrix В следующем году d-Matrix планирует выпустить более производительный ускоритель инференса Raptor. Это первый в мире ускоритель на базе 3D DRAM. Решение разрабатывается в партнёрстве с Alchip, известной разработками в области ASIC. Благодаря сотрудничеству уже реализована ключевая технология d-Matrix 3DIMC, представленная в тестовом кристалле d-Matrix Pavehawk. По словам компаний, новинка обеспечит до 10 раз более быстрый инференс по сравнению с решениями на базе HBM4, что позволит повысить эффективность генеративных и агентных рабочих ИИ-нагрузок. Также в Raptor будет использоваться процессор AndesCore AX46MPV от Andes Technology. Компании заявили, что их сотрудничество представляет собой конвергенцию вычислений, ориентированных на память, и инноваций в области процессоров на основе открытых стандартов для рабочих ИИ-нагрузок в масштабах ЦОД. Andes AX46MPV будет отвечать за оркестрацию наргрузок, распределение памяти, векторные вычисления и функции активации. AX46MPV — 64-бит многоядерный RISC-V-процессор с поддержкой Linux. Он включает 2048-бит блок векторной обработки (RVV 1.0), высокоскоростную векторную память (HVM) и ряд других аппаратных блоков для работы с массивными вычислениями. В совокупности эти функции обеспечивают запас производительности и гибкость ПО, необходимые для систем инференса уровня ЦОД. Референсные ядра, являющиеся ключевыми для рабочих нагрузок ИИ-трансформеров и LLM, демонстрируют прирост производительности до 2,3 раза по сравнению с предшественником AX45MPV.
17.11.2025 [07:45], Владимир Мироненко
NEC и OpenСhip вместе разработают векторные ускорители на базе RISC-V и суперкомпьютеры Aurora следующего поколенияБазирующийся в Барселоне разработчик чипов OpenChip, который некоторые эксперты называют каталонской NVIDIA, и компания NEC объявили о следующем этапе сотрудничества, направленного на совместную разработку векторного процессора (VPU) нового поколения. Ранее компании выполнили технико-экономическое обоснование разработки следующего поколения векторных суперкомпьютеров Aurora с использованием аппаратного и программного стека OpenChip на базе RISC-V. Как сообщается в пресс-релизе, на начальном этапе основное внимание уделялось оценке совместимости архитектуры Aurora от NEC с ускорителями OpenChip, определению логической структуры и начальной разработке программных компонентов. В результате исследования компании пришли к выводу о технической осуществимость проекта, так что теперь компании займутся совместной разработкой следующего поколения высокопроизводительных ускорителей, а также оптимизированного программного стека. Обе компании планируют запуск пилотных развёртываний у отдельных клиентов. По словам старшего вице-президента NEC Сухуна Юна (Suhun Yun), сотрудничество NEC с OpenChip является поворотным моментом в стратегическом развитии NEC в направлении вычислительных архитектур следующего поколения. В свою очередь, OpenChip отметила, что сотрудничество направлено на достижение ряда ключевых преимуществ, в числе которых повышенная производительность критически важных рабочих нагрузок, обеспечение нового уровня вычислительной мощности для HPC, ИИ и ML, а также для таких научных приложений, как геномика и моделирование климата. 
Источник изображения: NEC В 2021 году NEC анонсировала векторные ускорителя SX-Aurora TSUBASA Vector Engine 2.0 (VE20), а в 2022 — доработанные VE30. Однако в 2023 году NEC фактически прекратила разработку новых решений в серии SX-Aurora в связи с появлением ускорителей AMD и NVIDIA, значительно превосходящих её наработки, так что обещанные VE40 и VE50 так и не появились на свет. При этом у NEC и ранее были длительные перерывы в разработке векторных ускорителей, а её суперкомпьютеры на их основе по-прежнему пользуются спросом в некоторых областях, в частности, в метеорологии и климатологии. OpenChip разрабатывает SoC, использующую несколько UCIe-чиплетов, референсные проекты для аппаратных платформ, базовые комплекты разработчиков ПО и прикладные сервисы. Как сообщает ресурс HPCwire, среди других европейских стартапов, разрабатывающих решения на базе RISV-V есть:
За последние годы было поставлено более 10 млрд ядер с архитектурой RISC-V благодаря широкому внедрению архитектуры в микроконтроллерах и встраиваемых устройствах. За последнее время RISC-V стала потенциальной альтернативой проприетарным архитектурам, включая Arm и x86, в разработке ускорителей и HPC-платформ.
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 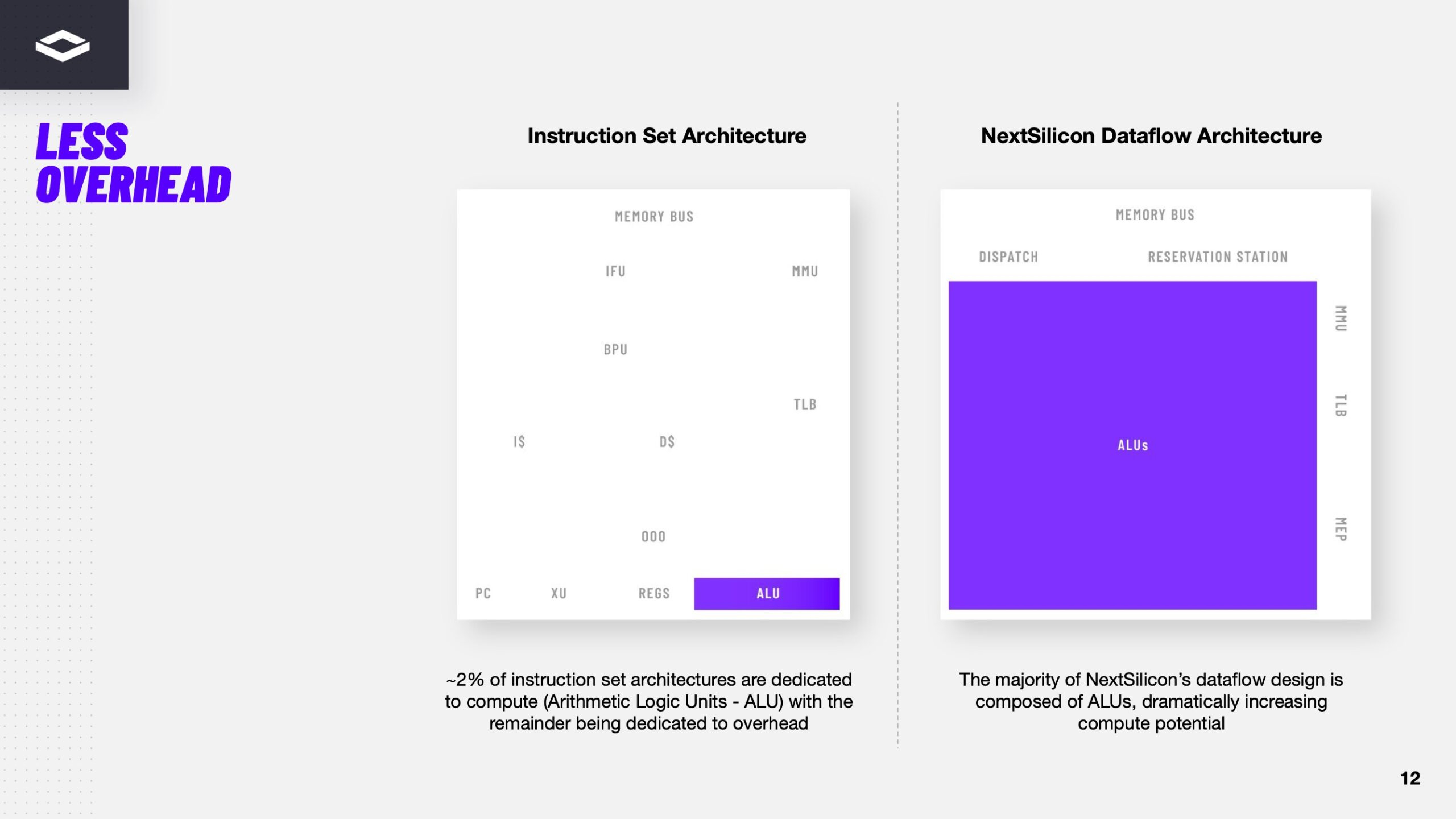
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 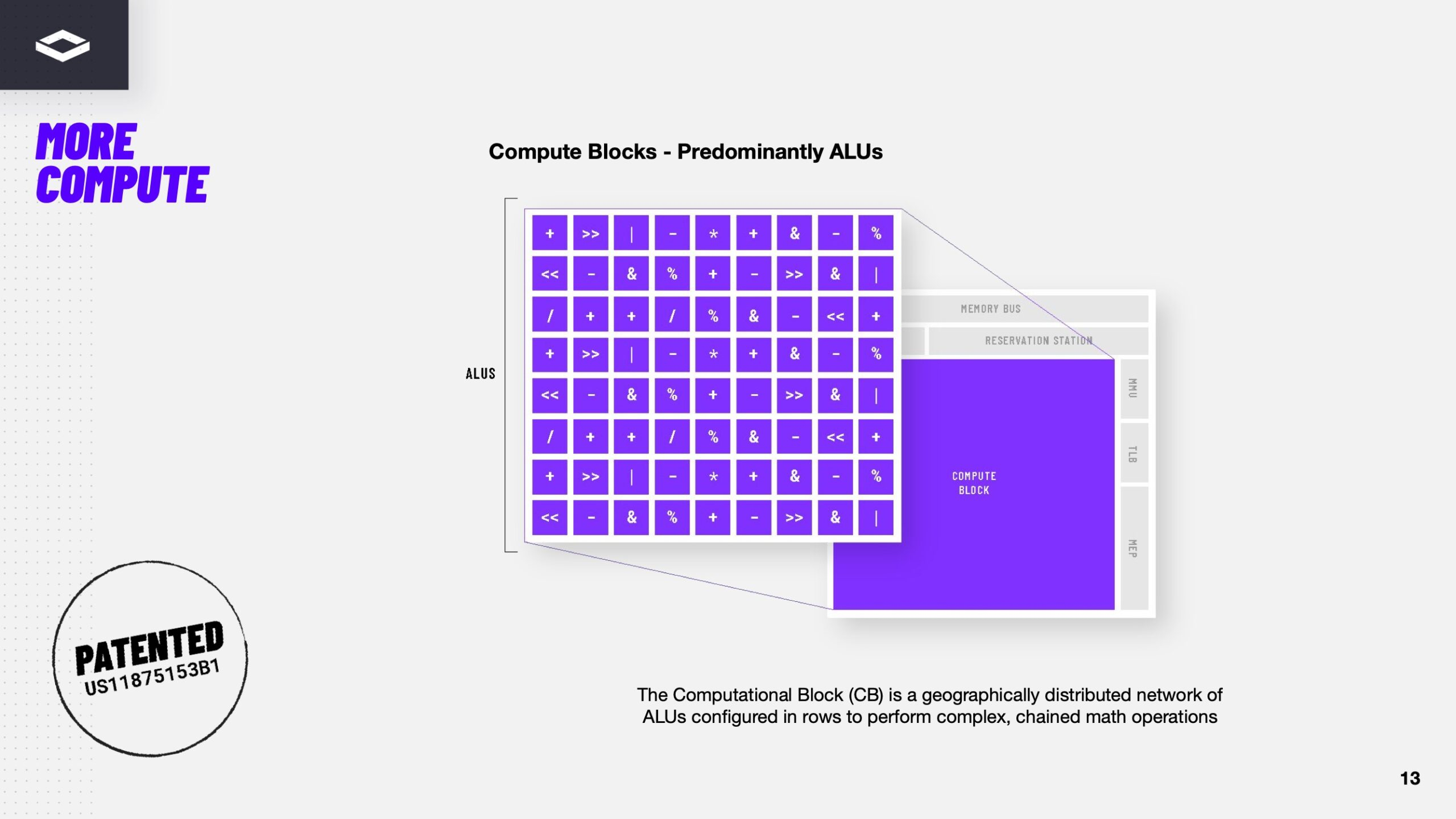 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 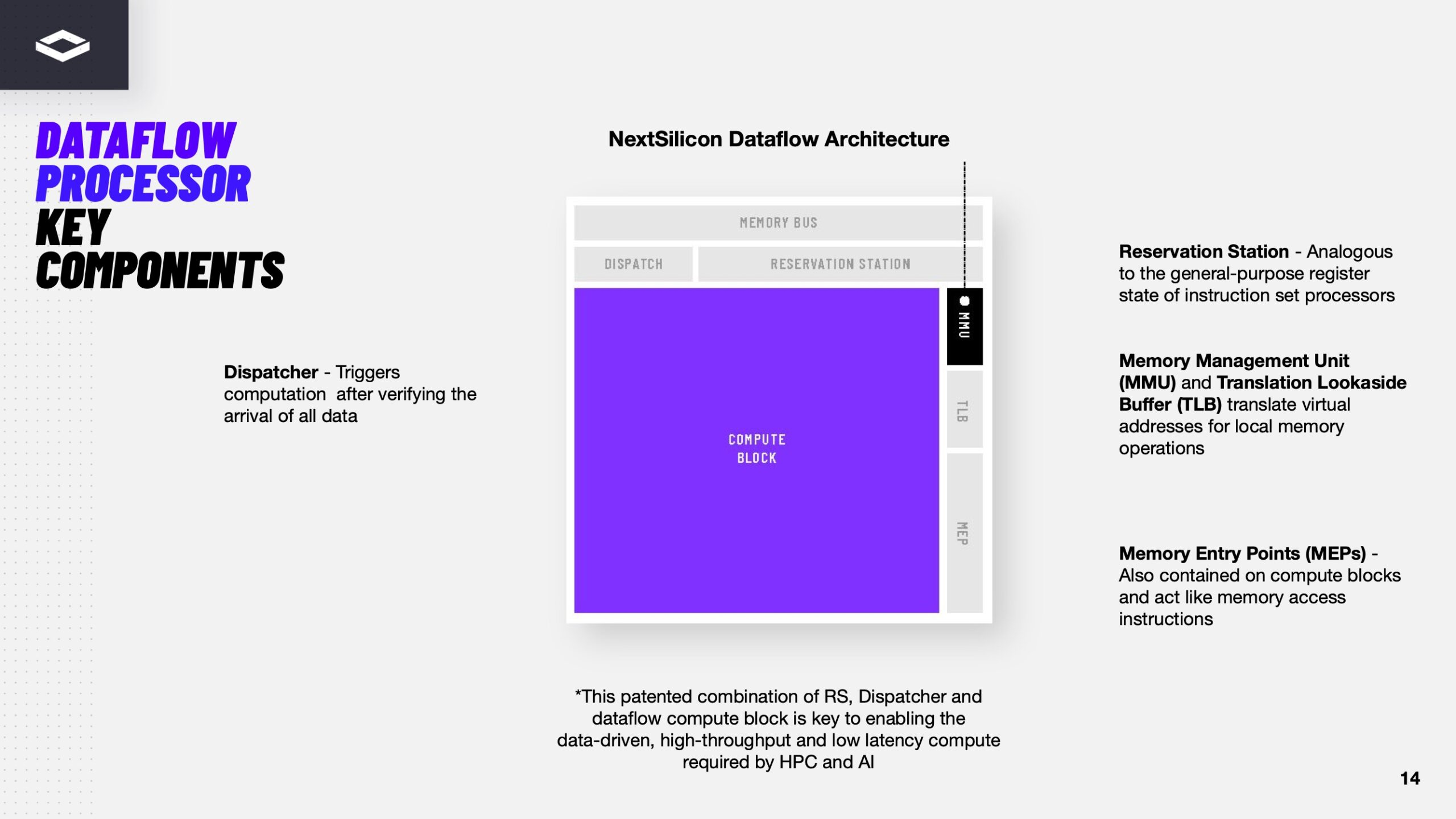 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 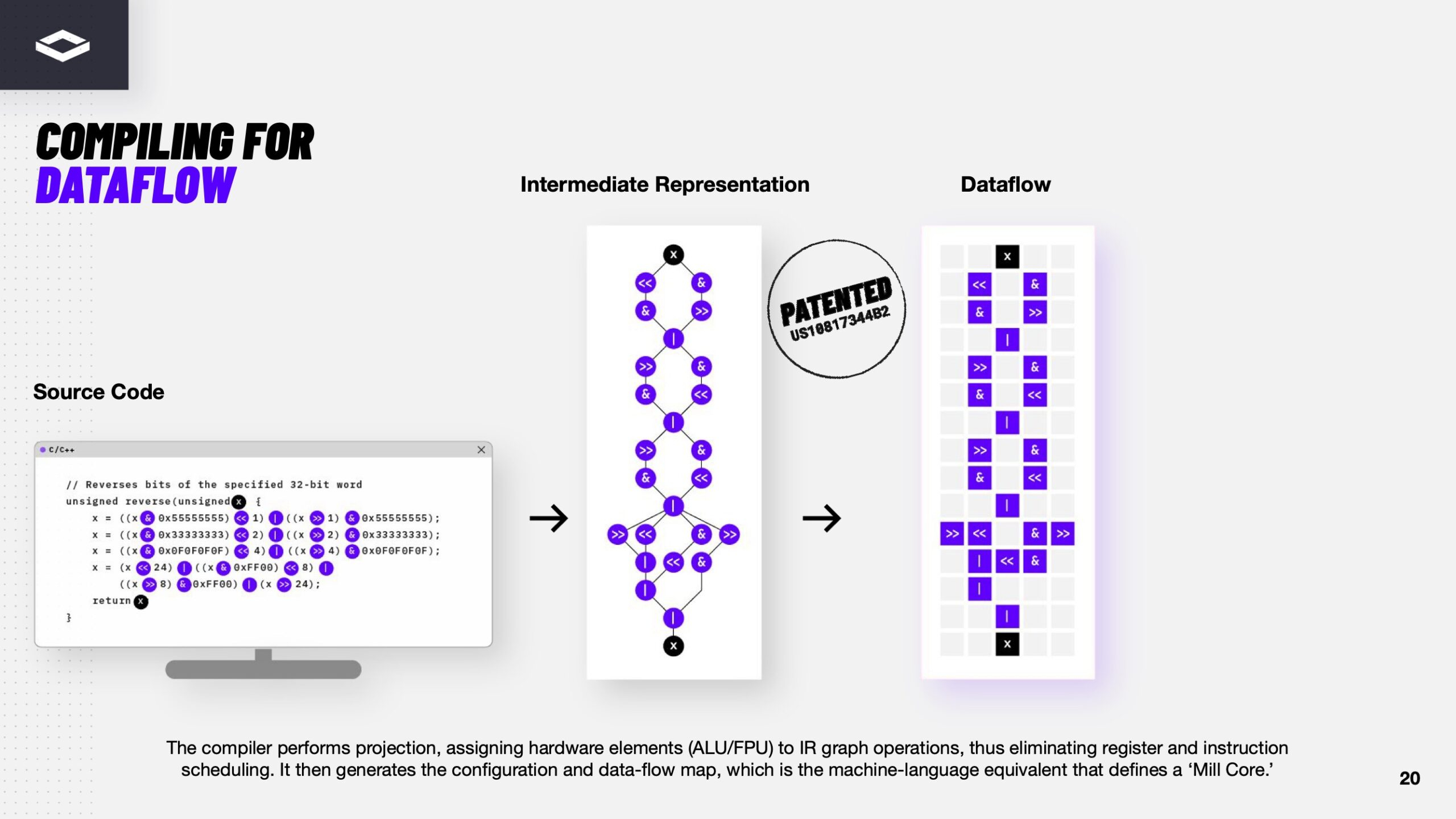 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 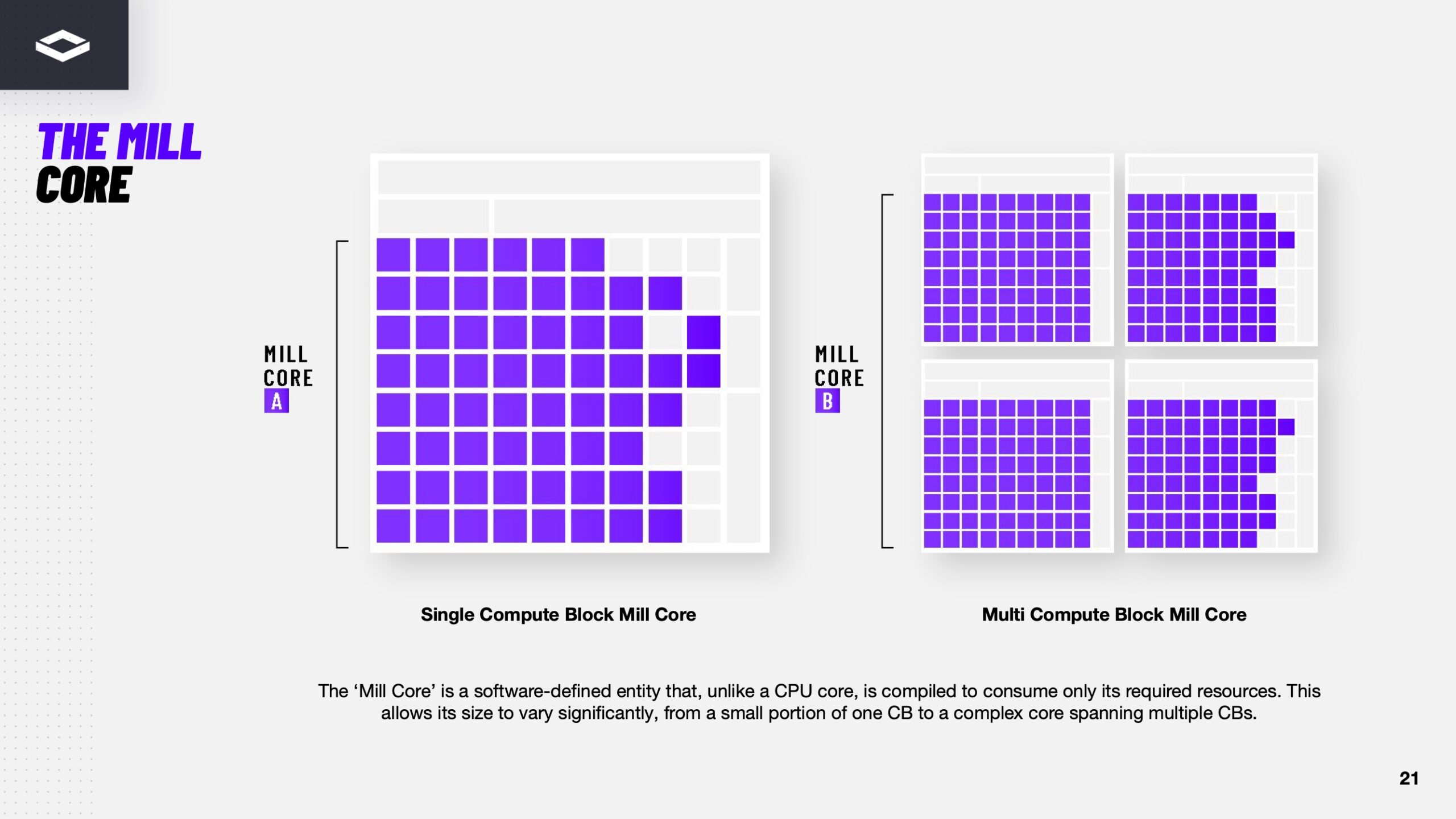 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 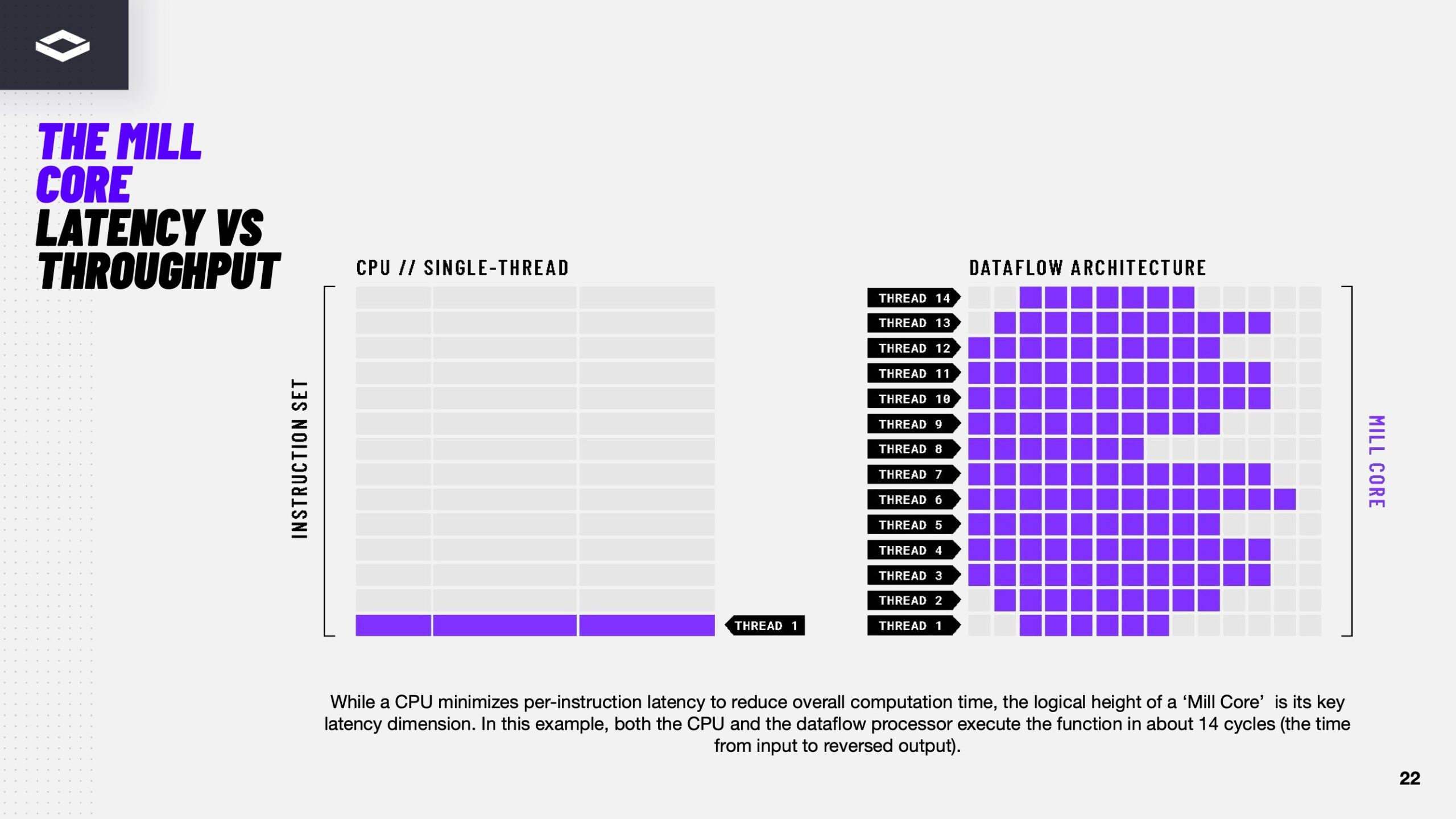 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 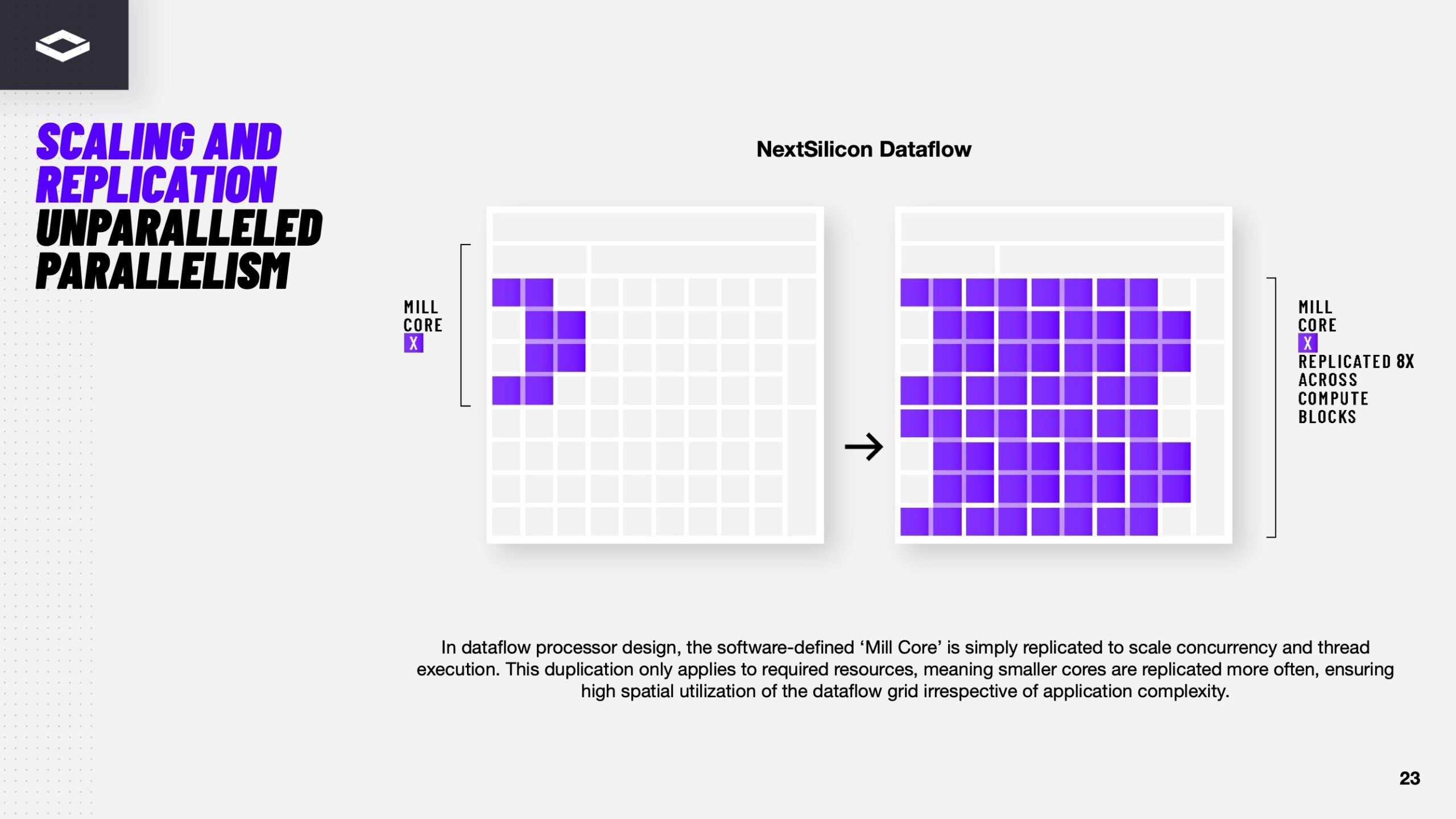 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 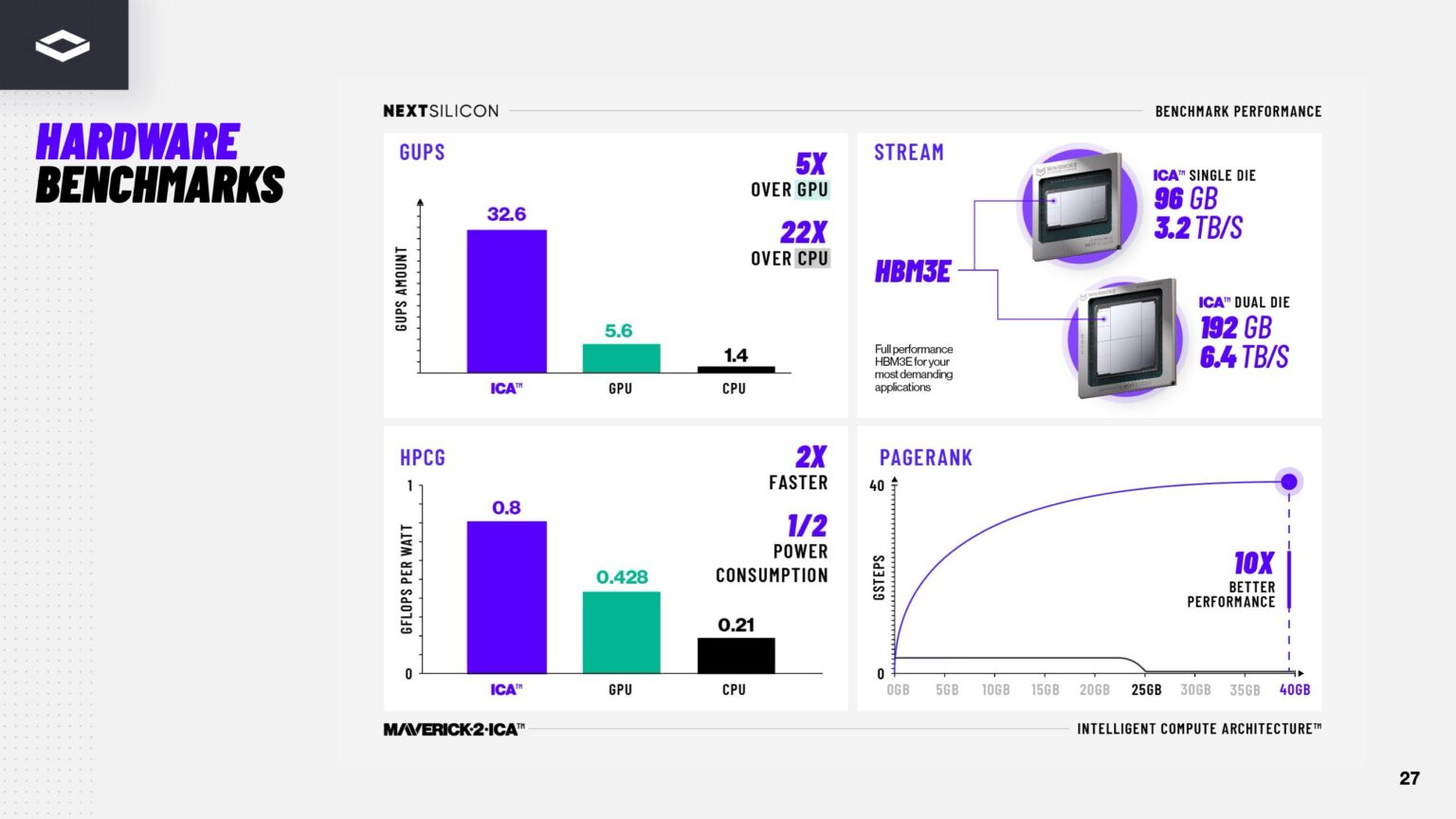 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 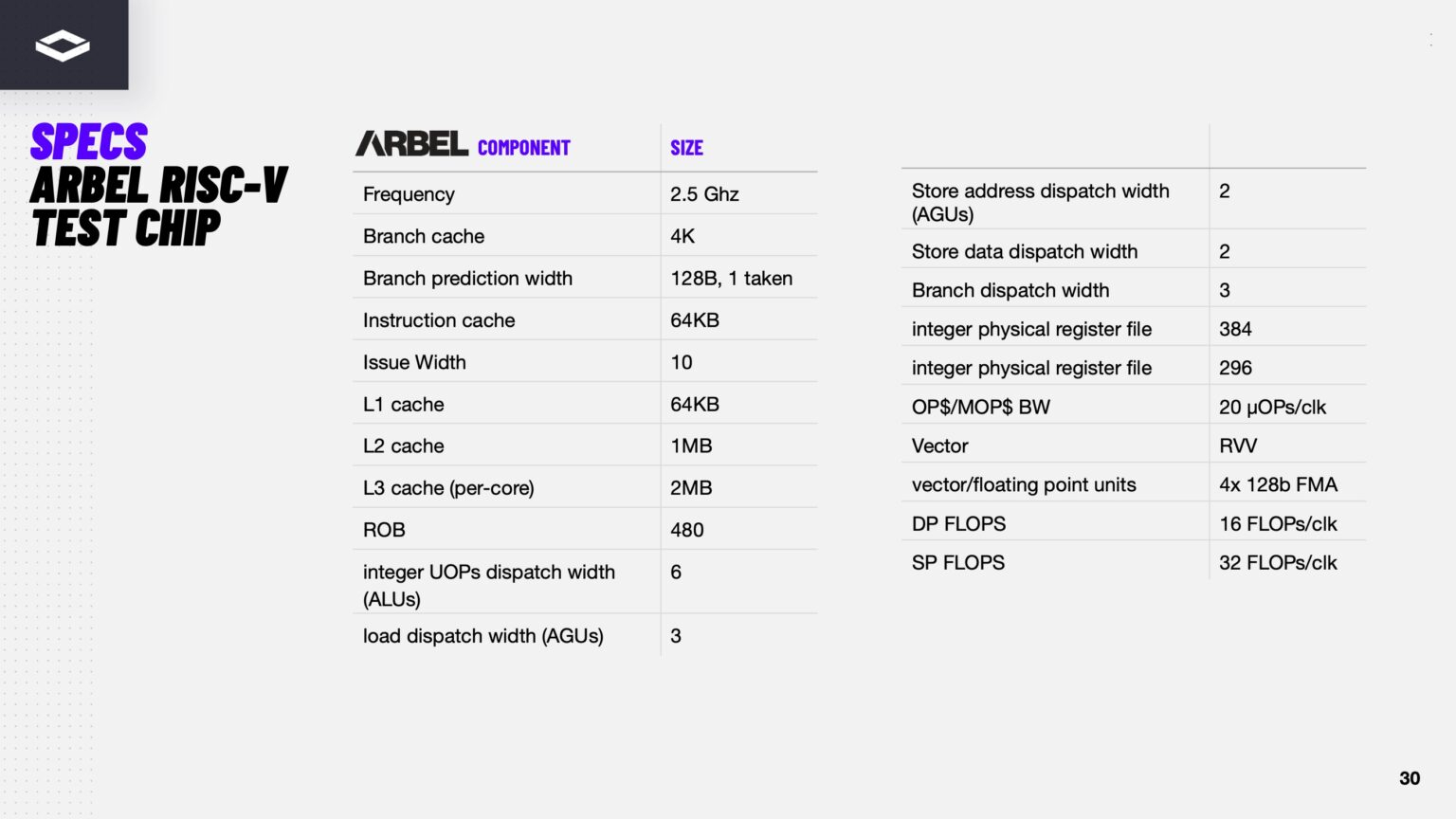 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 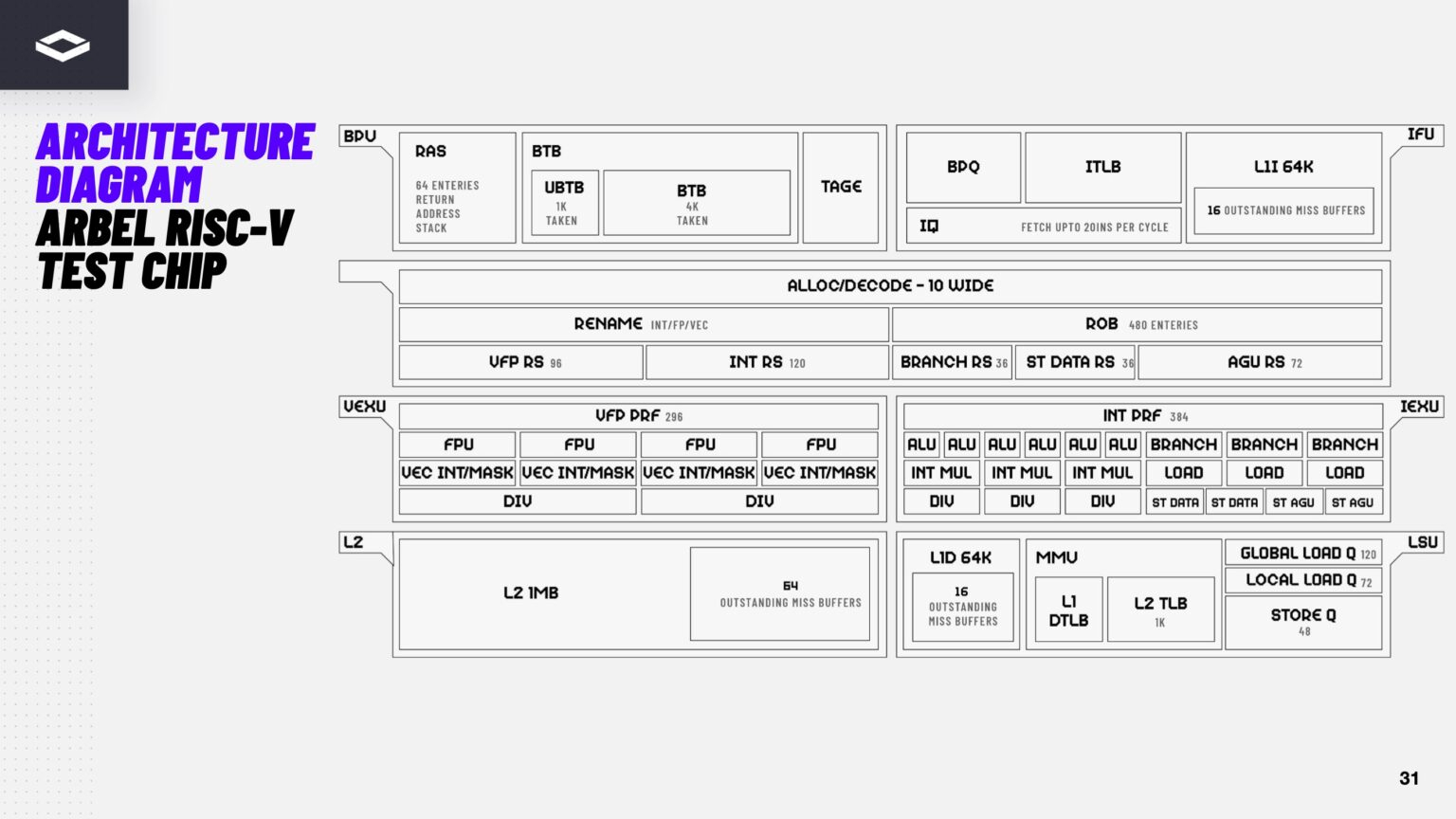 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
31.10.2025 [10:24], Сергей Карасёв
Eswin выпустила плату EBC7702 формата Mini-DTX с процессором RISC-VКомпания Eswin Computing в партнёрстве с Canonical, по сообщению CNX Software, подготовила к выпуску компактную плату для разработчиков EBC7702. Новинка подходит для работы с ИИ-задачами и приложениями, предполагающими локальную обработку данных. Решение выполнено в форм-факторе Mini-DTX с размерами 203 × 170 мм. Основой служит двухкристальная SoC Eswin EIC7702X, в состав которой входит процессор с восемью ядрами RV64GC на архитектуре RISC-V с частотой 1,4–1,8 ГГц. Предусмотрен встроенный нейропроцессорный модуль (NPU), обеспечивающий производительность до 40 TOPS на операциях INT8, до 20 TOPS в режиме INT16 и до 20 Тфлопс FP16. Графический движок обеспечивает поддержку OpenGL ES 3.2, OpenCL 1.2/2.1 EP2, Vulkan 1.2, EGL 1.4 и Android NN HAL. Возможно декодирование видеоматериалов в формате H.265 до 8K (100 к/с) или 64 потоков 1080p30, а также кодирование видео H.265 до 8K (50 к/с) или 26 потоков 1080p30. 
Источник изображения: CNX Software Плата может нести на борту 32 или 64 Гбайт памяти LPDDR5-6400. В оснащение входят флеш-модуль eMMC вместимостью 32 Гбайт, 16 Мбайт памяти SPI Flash, слот microSD, коннектор M.2 M-Key для SSD с интерфейсом SATA, порт SATA, разъём M.2 E-Key M2230 для адаптера Wi-Fi / Bluetooth и два слота PCIe 3.0 x16. Присутствуют четыре сетевых порта 1GbE и контроллер Wi-Fi 5 (802.11ac) с частотными диапазонами 2,4/5 ГГц. Модель EBC7702 получила по два порта USB 3.0 Type-A и USB 2.0 Type-A, четыре гнезда RJ45 для сетевых кабелей, два интерфейса HDMI, порт USB 2.0 Type-C, стандартные аудиогнёзда на 3,5 мм. Есть два интерфейса MIPI DSI (4 линии), четыре интерфейса MIPI CSI (4 линии) и 40-контактная колодка GPIO с поддержкой I2C, I2S, SPI, UART. Для подачи питания предусмотрены 24-контактный разъём ATX и 8-контактный разъём ARX. Плата будет поставляться с предустановленной ОС Ubuntu 24.04 LTS. Приём предварительных заказов начнётся в ближайшее время. Ориентировочная цена — $700 за вариант с 32 Гбайт ОЗУ.
27.10.2025 [11:16], Сергей Карасёв
Axelera AI представила ИИ-чип Europa с производительностью 629 TOPSНидерландский стартап Axelera AI анонсировал ИИ-ускоритель (AIPU) под названием Europa, предназначенный для таких задач, как генеративные сервисы и приложения компьютерного зрения. По заявлениям разработчиков, чип может использоваться в оборудовании разного класса — от периферийных устройств до корпоративных серверов. В состав Europa AIPU входят восемь «ядер ИИ второго поколения», которые используют векторные движки и технологию цифровых вычислений в оперативной памяти (D-IMC), разработанные специалистами Axelera. Заявленная ИИ-производительность достигает 629 TOPS на операциях INT8. Кроме того, чип содержит 16 специализированных векторных ядер с архитектурой RISC-V, сгруппированных в два кластера: они предназначены для операций пред- и постобработки, не связанных с ИИ. Пиковая производительность блока RISC-V достигает 4915 GOPS (млрд операций в секунду). Интегрированный декодер H.264/H.265 ускоряет выполнение медиазадач. 
Источник изображения: Axelera AI Процессор располагает 256-бит интерфейсом памяти LPDDR5 с пропускной способностью 200 Гбайт/с и 128 Мбайт памяти L2 SRAM. Новинка будет предлагаться в различных форм-факторах, включая компактное исполнение с размерами 35 × 35 мм и карты расширения PCIe 4.0 х4 в различных конфигурациях, в частности, с одним чипом и 16 Гбайт памяти, а также с четырьмя чипами и 256 Гбайт памяти. Разработчикам предоставляет комплект Voyager SDK, который позволяет полностью раскрыть потенциал процессора. В целом, как утверждается, новинка обеспечивает в 3–5 раз более высокую производительность в расчёте на 1 Вт и $1 по сравнению с ведущими отраслевыми решениями в той же категории. Поставки Europa AIPU и PCIe-карт начнутся в I половине 2026 года.
17.10.2025 [14:44], Сергей Карасёв
Одноплатный компьютер Orange Pi 4 Pro объединил ядра Arm и RISC-VДебютировал одноплатный компьютер Orange Pi 4 Pro, предназначенный для построения периферийных устройств с ИИ-функциями, систем промышленной автоматизации, сетевых хранилищ данных, шлюзов и пр. В основу новинки положена аппаратная платформа Allwinner. Применён процессор A733, объединяющий два ядра Arm Cortex-A76 с частотой до 2 ГГц, шесть ядер Arm Cortex-A55 с частотой до 1,8 ГГц, а также ядро реального времени XuanTie E902 RISC-V с частотой 200 МГц. Чип содержит графический блок Imagination BXM-4-64 и нейропроцессорный модуль (NPU) с производительностью до 3 TOPS на операциях INT8 (говорится также о поддержке INT16/FP16/BF16). Объём оперативной памяти LPDDR5 может составлять 4, 6, 8, 12 и 16 Гбайт. Изделие располагает коннектором M.2 M-Key для SSD с интерфейсом PCIe 3.0 (NVMe) и слотом microSD с поддержкой карт ёмкостью до 128 Гбайт, а опционально может быть добавлен накопитель eMMC вместимостью 16, 32, 64 или 128 Гбайт. Предусмотрены адаптеры Wi-Fi 6 и Bluetooth 5.4 (BLE), сетевой контроллер 1GbE (YT8531CA) с поддержкой PoE. 
Источник изображения: Orange Pi В набор разъёмов входят три порта USB 2.0 Type-A, по одному порту USB 3.0 Type-A и USB Type-C (служит для подачи питания 5 В / 3 А), гнездо RJ45 для сетевого кабеля, коннектор HDMI 2.0 и аудиогнездо на 3,5 мм. Есть интерфейс MIPI-DSI (4 линии), два интерфейса MIPI-CSI (4 и 2 линии) и 40-контактная колодка GPIO, совместимая с Raspberry Pi. Габариты составляют 89 × 56 мм, масса — 58 г. Стоимость Orange Pi 4 Pro начинается примерно с $30 в варианте с 4 Гбайт ОЗУ.
02.10.2025 [13:10], Руслан Авдеев
Meta✴ приобрела Rivos, разработчика RISC-V-ускорителей, совместимых с CUDAMeta✴ Platforms приобрела занимающийся разработкой ИИ-чипов на базе RISC-V стартап Rivos. Это должно ускорить разработку собственных полупроводников и снизить зависимость от сторонних поставщиков, сообщает Silicon Angle. Условия покупки пока неизвестны, но ключевой инвестор стартапа, Walden Catalyst, с гордостью сообщил о сделке, а нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), имевший прямое отношение к созданию и развитию стартапа, поздравил команду. Стартап был основан в 2021 году, а в 2023-м к нему присоединились около полусотни бывших инженеров Apple. Meta✴ будет использовать опыт Rivos для расширения работ над семейством собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator (MTIA). Впрочем, Rivos использовала комплексный подход, разрабатывая CPU и GPUGPU-чипы с кеш-когерентностью и унифицированным доступом к памяти (DDR и HBM), дополненные интегрированным 800G-интерконнектом на базе Ultra Ethernet. Это похоже на подход NVIDIA при создании суперускорителей. В 2025 году Rivos выпустила на TSMC тестовый чип, работающий на частоте 3,1 ГГц и программный стек, совместимый с NVIDIA CUDA. Изначальная стратегия предполагала создание энергоэффективного ИИ-ускорителя с частотой до 3,5 ГГц, совместимого с существующей экосистемой, который планировалось продавать гиперскейлерам (хотя бы одному). Первую коммерческую платформу компания собиралась выпустить в следующем году, она позволила бы перекомпилировать, а не переписывать с нуля приложения, созданные для платформ NVIDIA. Компания также принимала участие в создании RISC-V RVA23 Profile. 
Источник изображения: Rivos Хотя Meta✴ не раскрыла стоимость сделки, вероятно, речь идёт о миллиардных тратах. В августе сообщалось, что стартап вёл переговоры с инвесторами о возможном раунде финансирования в объёме $300–$400 млн, а то и $500 млн, что повысило бы оценку стоимости компании до более чем $2 млрд. ИИ-проекты Meta✴ полагаются преимущественно на сторонние аппаратные решения. Компания потратила миллиарды долларов на покупку ускорителей, в основном NVIDIA, и потратит ещё миллиарды на аренду ИИ-инфраструктуры у сторонних игроков. В частности, буквально на днях она подписала новую сделку с CoreWeave на $14,2 млрд. В этом году капзатраты могут достигнуть $72 млрд, а выпуск собственных чипов позволил бы компании сэкономить миллиарды долларов, снизив зависимость от NVIDIA и облачных операторов. 
Источник изображения: Rivos По словам Constellation Research, Meta✴ является единственным крупным ИИ-предприятием, почти полностью зависящим от инфраструктурных решений NVIDIA. Имеются данные, что компания уже взаимодействовала с Rivos некоторое время, поэтому и решила приобрести стартап целиком. Если инициатива увенчается успехом, это поможет Meta✴ снизить расходы как на обучение, так и на инференс. Также сообщается, что Meta✴ работает с TSMC над выпуском своего нового чипа, и уже отправила на производство необходимую документацию для выпуска пробных образцов для оценки их эффективности. |
|

