Материалы по тегу: npu
|
02.04.2024 [21:13], Алексей Степин
Три в одном: AMD представила процессоры Ryzen Embedded 8000 с интегрированными NPU и GPUКомпания AMD продолжает активно развивать направление процессоров для встраиваемых систем: если в начале года она представила гибридную платформу Embedded+, сочетающую в себе архитектуру Zen и ПЛИС Versal, то сегодня анонсировала процессоры Ryzen Embedded 8000 с интегрированным ИИ-сопроцессором. Это первое решение AMD для промышленного применения, сочетающее в себе целых три архитектуры: классическую процессорную Zen 4, графическую RDNA 3 и предназначенную для ИИ-вычислений XDNA. Новые процессоры должны найти применение в системах машинного зрения, робототехнике, промышленной автоматике и многих других сценариях. 
Источник: AMD AMD говорит о производительности в ИИ-сценариях, достигающей 39 Топс, что в рамках теплопакета, не превышающего у старшей модели 54 Вт, выглядит неплохо. Но в данном случае речь идёт о совокупной производительности всех архитектур, на долю же NPU приходится только 16 Топс. В качестве памяти используется двухканальная DDR5-5600 с поддержкой ECC. Благодаря графическому ядру RDNA 3 новые Ryzen Embedded 8000 смогут выводить информацию на четыре экрана с разрешением 4K, а также обеспечивать кодирование и декодирование всех популярных видеоформатов, включая H.264, H.265 и AV1. Для связи со специфическими ускорителями или контроллерами оборудования чипы получили 20 линий PCI Express 4.0. 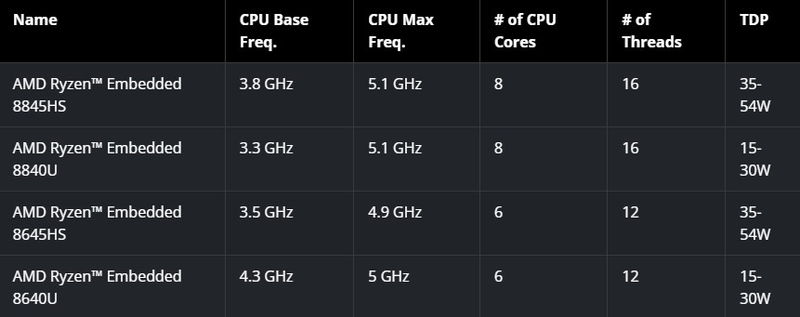 На момент анонса в серию Ryzen Embedded 8000 вошли четыре процессора — два шестиядерных (8645HS и 8640U) и два восьмиядерных (8845HS и 8840U), оба варианта поддерживают SMT и имеют тактовые частоты в диапазоне от 3,3 до 5,1 ГГц. Теплопакет у новинок конфигурируемый, в зависимости от условий охлаждения он может варьироваться либо в пределах 15–30 Вт или 35–54 Вт, что позволит обойтись пассивным теплоотводом там, где это необходимо. Новые решения AMD будут сопровождаться средствами SDK, поддерживающими Windows, а также популярные ИИ-фреймворки PyTorch и TensorFlow. В том числе анонсированы уже обученные модели, которые доступны на HuggingFace. В деле построения экосистемы для Ryzen Embedded 8000 компания тесно сотрудничает с известными производителями оборудования, в том числе с Advantech, ASRock и iBASE. Также для новых процессоров заявлен удлинённый жизненный цикл.
25.01.2024 [18:15], Сергей Карасёв
Китайская Sophgo хочет поставлять в Россию тензорные ИИ-процессорыКитайский разработчик тензорных процессоров Sophgo, по информации газеты «Коммерсантъ», намерен организовать поставку своих решений российским производителям вычислительной техники. Такие изделия могут заинтересовать компании, реализующие проекты в области нейросетей и ИИ. Sophgo занимается созданием специализированных чипов SOPHON с архитектурой RISC-V и Arm. В частности, в ассортименте компании присутствует 16-ядерное изделие SG2380 со встроенным ИИ-ускорителем. Еще одна разработка — тензорный процессор BM1684X, который обеспечивает быстродействие до 32 TOPS на операциях INT8, до 16 Тфлопс при вычислениях FP16/BF16 и до 2 Тфлопс на операциях FP32. 
Источник изображения: Sophgo По имеющимся сведениям, Sophgo хочет официально поставлять в Россию тензорные процессоры для нейронных сетей, а также CPU собственной разработки на основе RISC-V. Предполагается, что эти изделия будут применяться в том числе в серверах. Однако участники российского рынка смотрят на инициативу Sophgo скептически, передаёт «Коммерсантъ». Для использования чипов Sophgo российским производителям придётся с нуля разрабатывать совместимые компоненты, на что потребуется минимум два года и несколько миллиардов рублей инвестиций. Кроме того, решения Sophgo ориентированы прежде всего на микросерверы и сетевое оборудование. В России в такой электронике используются процессоры на базе x86 и Arm, которые уже имеют развитую экосистему. В октябре 2023 года стало известно, что российская компания «Норси-Транс» организует выпуск серверов, СХД, настольных компьютеров и ноутбуков на процессорах другой китайской компании — Loongson. Эксперты говорят, что это может создать зависимость отечественной электроники от китайской продукции. Соответствующий риск актуален и для тензорных чипов.
23.10.2023 [20:57], Алексей Степин
Новый нейроморфный ИИ-процессор IBM NorthPole на порядок превосходит современные GPUПо большей части современные нейросетевые технологии используют ускорители на базе GPU или родственных архитектур как для обучения, так и для инференса. Впрочем, разработчики альтернативных решений не дремлют. В число последних входит компания IBM, недавно сообщившая об успешном завершении испытаний нового нейроморфного процессора NorthPole. Разработкой чипов, в том или ином виде пытающихся имитировать работу живого мозга, компания занимается давно — чипы IBM TrueNorth второго поколения увидели свет более пяти лет назад. Уже тогда разработчики отошли от традиционных архитектур, отказавшись от понятия памяти как внешнего устройства. 
Источник изображений здесь и далее: IBM Research В итоге TrueNorth получил 400 Мбит (~50 Мбайт) сверхбыстрой интегрированной памяти SRAM (~100 Кбайт на ядро, всего 4096 ядер) и мог эмулировать 1 млн нейронов с 256 млн межнейронных связей. Чип моделировал бинарные нейроны, а вес каждого синапса был закодирован двумя битами. 
FPGA (слева) используется только в качестве PCIe-моста Новый 12-нм нейрочип NorthPole устроен несколько иначе: он состоит из 256 ядер, которые, впрочем, всё так же используют внутреннюю память общим объёмом 192 Мбайт. Дополнительно имеется буфер объёмом 32 Мбайт для IO-тензоров. Каждое из ядер NorthPole за такт способно выполнять 2048 операций с 8-бит точностью вычислений. В режимах 4- и 2-бит точности производительность растёт соответствующим образом. По словам IBM, новый NPU превосходит предшественника в 4000 раз и на частоте 400 МГц мог бы развивать производительность в районе 840 Топс. Из-за довольно ограниченного объёма памяти NorthPole не подходит для запуска сложных нейросетей вроде GPT-4, но его главное назначение не в этом — чип позиционируется в качестве основы систем машинного зрения, в том числе в системах автопилотов, хирургических роботов и т.п. И в этом качестве новинка, состоящая из 22 млрд транзисторов и имеющая площадь кристалла 800 мм2, проявляет себя очень хорошо. 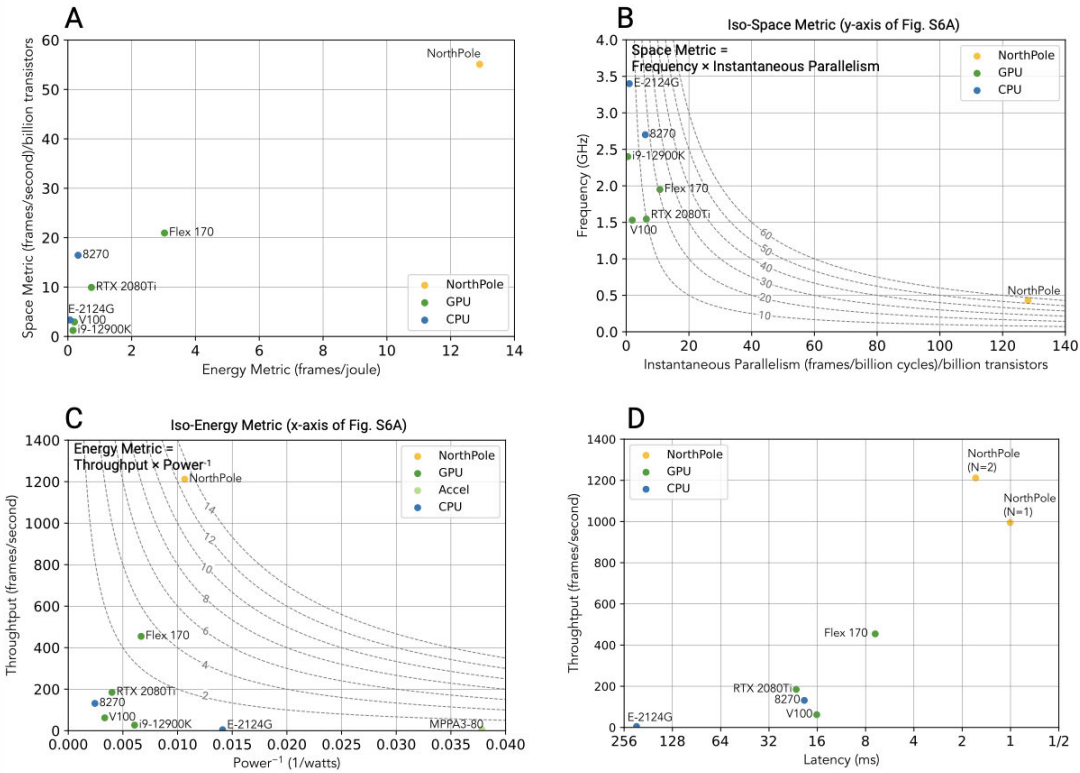
Результаты тестов на эффективность архитектуры NorthPole Так, в тестах ResNet-50 NorthPole в 25 раз превзошёл по энергоэффективности сопоставимые по техпроцессу GPU, а показатели латентности при этом оказались в 22 раза лучше. В пересчёте на транзисторную сложность IBM говорит о превосходстве даже над новейшими 4-нм решениями NVIDIA. Полные результаты тестирования доступны на science.org. К сожалению, речь всё ещё идёт об экспериментальном прототипе с довольно грубым по современным меркам 12-нм техпроцессом. По словам исследователей, производительность NorthPole благодаря более совершенным техпроцессам удалось поднять бы ещё в 25 раз. Параллельно IBM ведёт разработки в области ИИ-чипов с элементами аналоговой логики. Достигнутые в рамках 14-нм техпроцесса результаты позволяют говорить об удельной производительности в районе 10,5 Топс/Вт или 1,59 Топс/мм2.
12.10.2023 [12:44], Сергей Карасёв
SiFive представила RISC-V ядро Performance P870 и NPU-блок Intelligence X390Компания SiFive анонсировала процессорное ядро Performance P870 с архитектурой RISC-V для высокопроизводительных клиентских приложений. Кроме того, дебютировал NPU-блок Intelligence X390 для задач машинного обучения и ИИ. Решение Performance P870, как утверждается, обеспечивает прирост производительности примерно на 50 % (specINT 2006) по сравнению с ядром предыдущего поколения. Тактовая частота не раскрывается, но, по имеющимся данным, она превышает 3 ГГц. 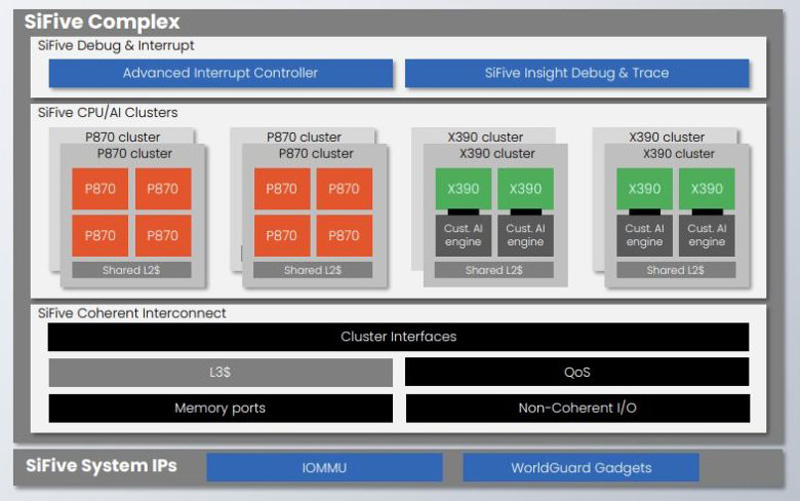
Источник изображения: SiFive В состав изделия входят два 128-бит векторных блока. На основе Performance P870 могут создаваться процессоры, насчитывающие до 32 ядер: это вдвое больше по сравнению с предшественником (Performance P670). Отмечается, что P870 может применяться для формирования гетерогонных SoC, также содержащих ядра P670 и P470. При этом каждый кластер использует общий кеш L2. Доступна и автомобильная версия Performance P870 с высокой степенью резервирования и отказоустойчивости. Новые ядра могут использоваться в сочетании с векторными процессорами в дата-центрах. В свою очередь, решение Intelligence X390, по заявлениям SiFive, обеспечивает 4-кратное увеличение быстродействия векторных вычислений по сравнению с NPU предыдущего поколения Intelligence X280. Поддерживаются 1024-битные векторные регистры (VLEN) с 512-битными путями данных (DLEN). SiFive не раскрыла поддерживаемые типы данных, но известно, что X280 поддерживает INT8, INT16, INT32, FP16, FP32 и FP64. Комбинированное решение, состоящее из P870 и X390, предоставляет разработчикам гибкую платформу для приложений генеративного ИИ.
16.09.2023 [21:40], Сергей Карасёв
Cadence представила 7-нм ИИ-ядро Neo NPU с производительностью до 80 TOPSКомпания Cadence Design Systems, разработчик IP-блоков, по сообщению CNX-Software, создала ядро Neo NPU (Neural Processing Unit) — нейропроцессорный узел, предназначенный для решения ИИ-задач с высокой энергетической эффективностью. Решение подходит для создания SoC умных сенсоров, IoT-устройств, носимых гаджетов, систем оказания помощи водителю при движении (ADAS) и пр. Утверждается, что производительность Neo NPU может масштабироваться от 8 GOPS до 80 TOPS в расчёте на ядро. В случае многоядерных конфигураций быстродействие может исчисляться сотнями TOPS. Ядро Neo NPU способно справляться как с классическими ИИ-задачами, так и с нагрузками генеративного ИИ. Говорится о поддержке INT4/8/16 и FP16 для свёрточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров. 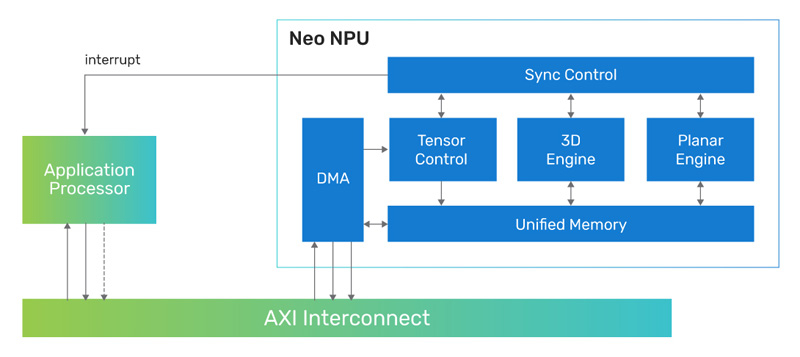
Источник изображения: Cadence Для Neo NPU предполагается применение 7-нм технологии производства. Стандартная тактовая частота — 1,25 ГГц. Утверждается, что по сравнению с ядрами первого поколения Cadence AI IP изделие Neo NPU обеспечивает 20-кратный прирост производительности. Скорость инференса в расчёте на ватт в секунду возрастает в 5–10 раз. Разработчикам будет предлагаться комплект NeuroWeave (SDK) с поддержкой TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet, JAX, а также Android Neural Network Compiler, TF Lite Delegates и TensorFlow Lite Micro. Решение Neo NPU станет доступно в декабре 2023 года.
02.10.2019 [11:22], Геннадий Детинич
Один нейропроцессор Alibaba Hanguang 800 заменяет 10 GPU-ускорителейКак мы сообщали около недели назад, компания Alibaba представила фирменный NPU Hanguang 800 для запуска нейросетей в составе облачных сервисов компании. Например, данные NPU могут обеспечить рекомендательные услуги для пользователей или анализ видео с камер наблюдения в реальном времени. В продажу Hanguang 800 не поступят. Компания намерена использовать разработку в собственных ЦОД. С одной стороны, это программа по импортозамещению. С другой ― аналогов Hanguang 800 пока нет, в чём нас уверяет Alibaba.  Итак, 12-нм NPU Hanguang 800 ― это самый большой из разработанных Alibaba чипов с 17 млрд транзисторов. Точнее, процессор разработан подразделением T-Head этой интернет-компании (ране ― Pingtouge Semi). В основе разработки лежит архитектура и набор команд RISC-V с открытым кодом. Подобное обстоятельство, как уверены в Alibaba, поможет быстрому распространению интереса к платформе со стороны независимых разработчиков. 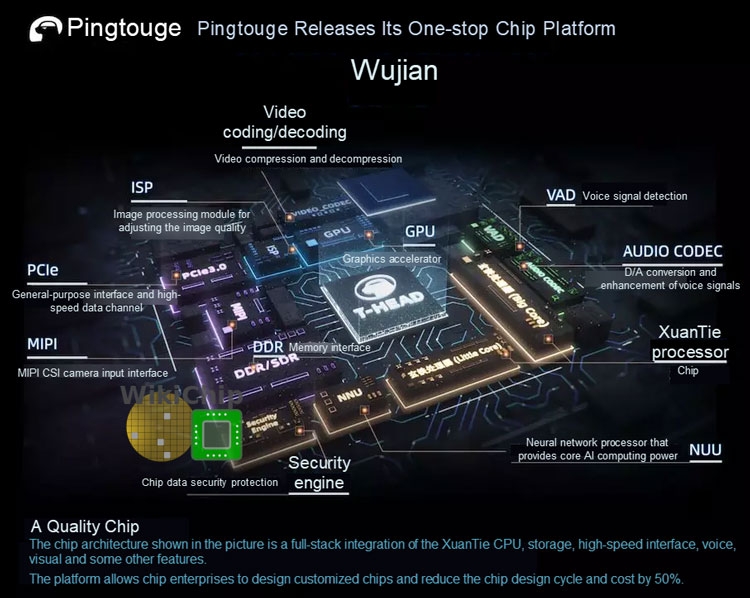 Нейропроцессор Hanguang 800 входит в семейство производительных ИИ-чипов Xuantie (Black Steel). Название платформы для ускорителя ― Wujian (Уцзян). Платформа представляет собой плату с интерфейсами и контроллерами ввода/вывода, бортовой памятью и набором необходимых кодеков. Вместе с аппаратной частью поставляется полный пакет программного обеспечения от драйверов и прошивки до операционной системы, библиотек и примеров. Бери и дерзай. Программная поддержка представляется Alibaba тем козырем, которого нет в рукаве у чисто «железячных» разработчиков. Кстати, Hanguang 800 спроектирован менее чем за год, что впечатляет.  Согласно внутренним тестам компании, инференс Hanguang 800 на стандартном тестовом наборе ResNet-50 способен обработать 78,5 тысяч изображений в секунду или 500 изображений в секунду на ватт. Это в 15 раз быстрее, чем в случае ускорителя NVIDIA T4 и в 46 раз быстрее NVIDIA P4. Даже если Alibaba преувеличила свои достижения, а независимых тестов у нас нет, результат всё равно впечатляет.  Если сравнивать возможности Hanguang 800 с компьютерной производительностью, то, по словам разработчиков, один NPU Hanguang 800 эквивалентен по результативности 10 «обычным» графическим процессорам. Эти решения, как мы отметили выше, компания будет использовать для собственных нужд, как и TPU в компании Google или AWS Inferentia в Amazon. У компании Alibaba это облачные сервисы Aliyun.  |
|

