Материалы по тегу: cpu
|
11.12.2025 [01:30], Владимир Мироненко
Qualcomm купила разработчика серверных RISC-V процессоров Ventana Micro SystemsQualcomm объявила о приобретении стартапа Ventana Micro Systems, специализирующегося на разработке серверных процессоров на основе архитектуры RISC-V. Как пояснила компания, это свидетельствует о её приверженности развитию RISC-V, открытой альтернативы Arm и x86. По словам Qualcomm, сделка расширит её возможности в разработке чипов на базе RISC-V и кастомных процессоров Oryon за счёт интеграции имеющегося у Ventana опыта в этом направлении. Qualcomm делает ставку на Oryon в деле завоевания новых рынков, в том числе серверного, в рамках продолжающейся диверсификации бизнеса. Компания получила ядра Oryon, совместимые с Arm, вместе с приобретением стартапа Nuvia за $1,4 млрд в 2021 году. Oryon уже прописались в процессорах Snapdragon X Series. Теперь же Qualcomm намерена предпринять ещё одну попытку разработки серверных процессоров. Прошлая попытка с процессорами Centriq 2400 завершилась неудачей. В этом году эти усилия были подкреплены наймом бывшего главного архитектора Intel Xeon и сделкой по приобретению Alphawave Semi за 2,4 млрд, пишет CRN. Qualcomm, которая уже использует архитектуру RISC-V в некоторых продуктах за пределами рынков ПК и серверов, заявила, что вклад Ventana укрепит ее «технологическое лидерство в эпоху ИИ во всех сферах бизнеса», указывая на большие надежды, возлагаемые на это приобретение: «Мы считаем, что ISA RISC-V имеет потенциал для продвижения технологий процессоров, обеспечивая инновации во всех продуктах. Приобретение Ventana Micro Systems знаменует собой важный шаг на нашем пути к предоставлению передовых в отрасли технологий процессоров на базе RISC-V для всех продуктов». 
Источник изображения: Ventana Micro Systems Ventana Micro Systems, базирующаяся в Купертино (Cupertino), была основана в 2018 году. Как сообщается на сайте компании, разработанная ею технология изготовления процессоров на базе RISC-V, обеспечивает «производительность, сопоставимую с новейшими процессорами на Arm и x86 для ЦОД». Эта технология доступна в виде многоядерных UCIe-чиплетов, а также может быть интегрирована другими компаниями в собственные SoC. И первое, и второе поколение процессоров Ventana Veyron предлагало до 192 ядер RISC-V. Свои разработки Ventana рассчитывает использовать в различных сферах, включая облачные вычисления, корпоративные ЦОД, системы гиперскейлеров, 5G, периферийные вычисления, ИИ и машинное обучение, а также автомобильную промышленность. По некоторым оценкам, годовая выручка Ventana составляет $37,4 млн. Так что ей в каком-то смысле повезло, поскольку даже достаточно заметные разработчики решений на базе RISC-V часто не могут конкурировать с крупными игроками и готовы или продаться кому-нибудь, или вынуждены сокращать штат, или закрываться целиком. Сообщение о покупке Ventana последовало после того, как Qualcomm в сентябре заявила о «полной победе» в судебном споре с Arm, которая добивалась прекращения продаж и уничтожения всех чипов Qualcomm, содержащих ядра Oryon, из-за предполагаемых нарушений лицензий на архитектуру Arm со стороны Qualcomm и Nuvia. Любопытно, что в 2022 году Ventana объявила о стратегическом партнёрстве с Intel в рамках IFS. Последняя годом позже закрыла программу Pathfinder for RISC-V.
09.12.2025 [22:48], Владимир Мироненко
AMD представила процессоры EPYC Embedded 2005: до 16 ядер Zen5 в BGA-форматеAMD представила серию процессоров AMD EPYC Embedded 2005 — следующее поколение встраиваемых процессоров, обеспечивающих высокую производительность, энергоэффективность, повышенную надёжность и безопасность в компактном корпусе BGA (FL1) для сетевых систем, СХД и индустриальных платформ, требующих круглосуточной работы. Новая серия дополняет существующую линейку встраиваемых процессоров AMD, включающую серию EPYC Embedded 9005. AMD выпустит три чипа EPYC Embedded 2005, которые станут доступны в I квартале 2026 года: 2435, 2655 и 2875 с 8, 12 и 16 ядрами Zen 5 (все с SMT) и TDP в размере 45, 55 и 75 Вт соответственно. Модели EPYC Embedded 2875 и EPYC Embedded 2655 имеют кеш-память L3 объёмом 64 Мбайт, а EPYC Embedded 2435 — 32 Мбайт. Поддерживается точная настройка профилей тепловыделения и энергопотребления. 
Источник изображений: AMD/ServeTheHome Поскольку эти компоненты выпускаются под брендом EPYC, они обладают всеми необходимыми функциями процессоров текущего поколения, включая поддержку ECC и полный набор функций AMD RAS. Также примечательно то, что это первая за много лет платформа EPYC Embedded в форм-факторе BGA. В последний BGA-чипы на платформе Snowy Owl были представлены ещё в 2018 году и использовали ядра Zen 1. 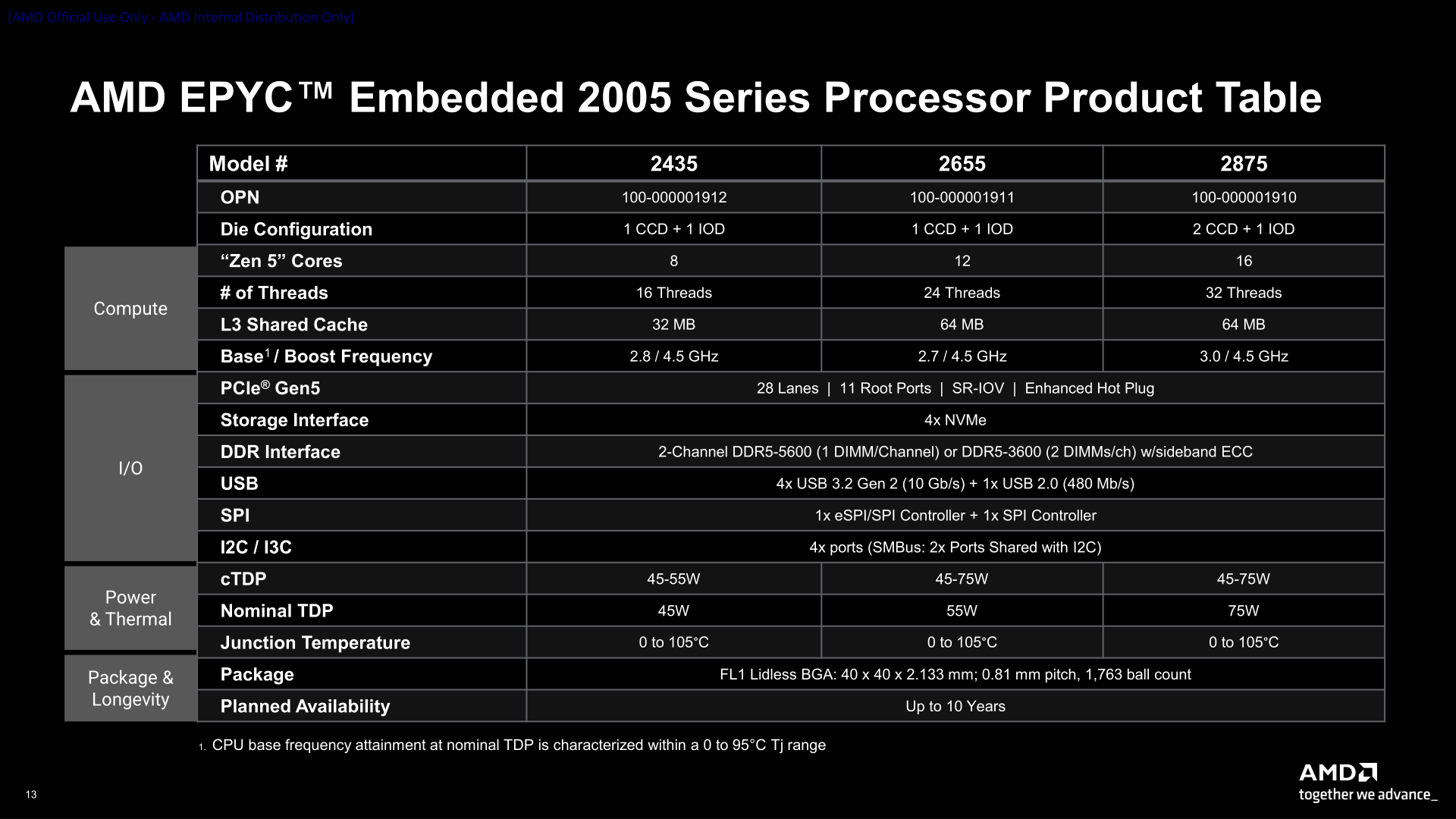 По словам AMD, BGA-корпус (40 × 40 мм) примерно в 2,4 раза меньше по площади, чем аналогичные решения Intel Xeon 6500P‑B (Granite Rapids-D), Меньший размер корпуса обеспечивает более высокую плотность компонентов на платах с ограниченными возможностями и упрощает теплоотвод системы, приближая высокоскоростные интерфейсы к сетевым картам, ускорителям и другим периферийным устройствам, говорит AMD.  По оценкам компании, 12-ядерный EPYC Embedded 2655 обеспечивает на 28 % более высокую частоту в режиме Boost и на 35 % более высокую базовую частоту, чем Xeon 6503P‑B, с вдвое меньшим при этом показателем TDP, тактично умалчивая, что данный чип Intel, самый младший в своём семействе, имеет интегрированный 100GbE-контроллер, поддержку QAT и четыре канала памяти DDR4-4800 (у более старших вплоть до DDR5-5600), тогда как все EPYC Embedded 2005 ограничены двумя каналами памяти — DDR5-3600 в случае 2DPC и DDR5-5600 в случае 1DPC.  Чипы EPYC Embedded 2005 предоставляет 28 линий PCIe 5.0 с 11 root-портами и возможностью формирования x16-подключений, а также четыре порта USB 3.1 и один порт USB 2.0. Процессоры включают функции обеспечения повышенной надёжности RAS (Reliability, Availability and Serviceability), расширенное обнаружение и исправление ошибок (EDAC), защиту памяти, горячее подключение PCIe, Multi-SPI ROM, а также функции защиты AMD Infinity Guard, включая Secure Processor3, Platform Secure Boot и Memory Guard. 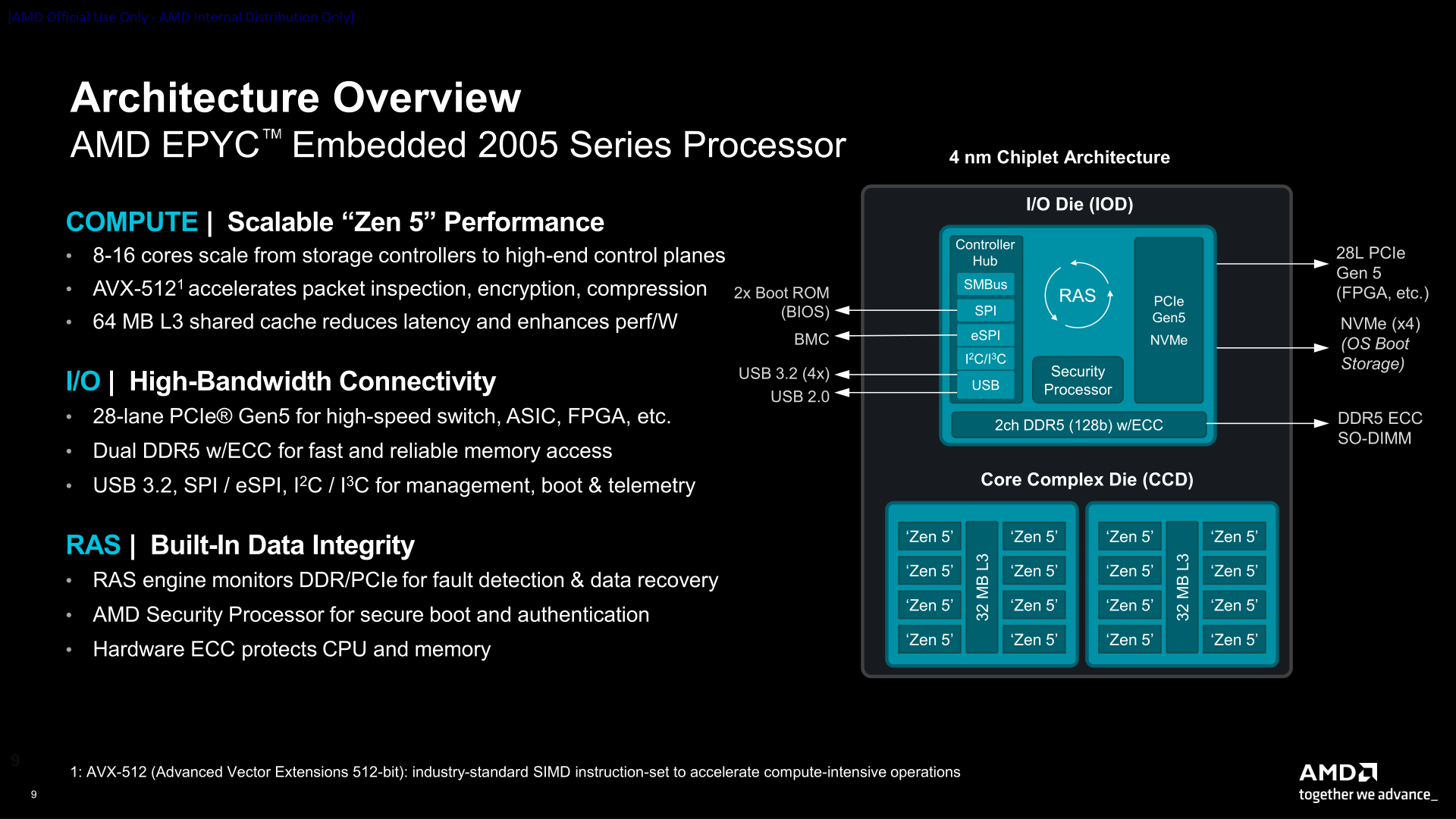 Благодаря балансу вычислительной мощности и энергоэффективности процессоры AMD EPYC Embedded 2005 идеально подходят для сетевых, хранилищ и промышленных систем с ограниченными возможностями, где каждый ватт и миллиметр имеют значение, отметила компания. EPYC Embedded 2005 рассчитаны на круглосуточную работу и длительный срок эксплуатации. AMD гарантирует поддержку до 10 лет непрерывной работы, сочетая это с долгосрочной доступностью и поддержкой: до 10 лет заказа компонентов и технической поддержки, а также 15 лет сопровождения ПО. Заявлена поддержка Yocto и EDK II (Extended Development Kit).
04.12.2025 [22:18], Владимир Мироненко
AWS анонсировала 192-ядерные серверные Arm-процессоры Graviton5AWS анонсировала свой самый мощный на сегодняшний день серверный Arm-процессор — 3-нм 192-ядерный Graviton5. Новые инстансы M9g на базе Graviton5 отличаются более высокой производительностью благодаря впятеро большему общему L3-кешу и в 2,6 раза большему объёму кеша на ядро по сравнению с Graviton4, более высокой скорости памяти и повышенной пропускной способности сетевого подключения. Также компания снизила задержку передачи данных между ядрами на треть. В Graviton5 появилась функция Nitro Isolation Engine с формальной верификацией изоляции исполняемых рабочих нагрузок друг от друга и от самой AWS. Процессоры предлагают полное шифрование памяти, расширенный предсказатель ветвлений, улучшенную подсистему предвыборки выделенные кеши для каждого vCPU и аутентификацию указателей (PAC). Кроме того, Graviton5 получили систему охлаждения на кристалле. Процессор содержит 172 млрд транзисторов. 
Источник изображений: AWS Процессор использует ядра Neoverse V3 (Poseidon) с ISA Armv9.2-A. Хотя сам чип монолитный, он разделён на два NUMA-домена для снижения задержек обращений к памяти. Каждому ядру полагается 2 Мбайт L2-кеша, а общий объём L3-кеша составляет 192 Мбайт — суммарно 576 Мбайт. Процессор имеет 12 каналов DDR5-8800, причём AWS работает с поставщиками памяти для валидации их DIMM. Также отмечено снижение задержки доступа до менее чем 100 нс. Для связи с внешним миром есть восемь контроллеров PCIe 6.0.  Как сообщается, клиенты AWS уже провели первые тесты Graviton5, показавшие прирост производительности от 25 до 60 % в зависимости от типа рабочей нагрузки. Помимо инстансов M9g в 2026 году также появятся инстансы C9g для ресурсоёмких вычислений и R9g с оптимизацией по памяти. Новые инстансы имеют в среднем на 15 % более высокую скорость сетевого подключения и на 30 % более высокую скорость доступа к EBS-томам (в том числе с шифрованием). Кроме того, они получили чипы Nitro 6, ответственные за виртуализацию, защиту и разгрузку сетевых функций и функция хранения.  Процессоры Graviton теперь обеспечивают более половины всех новых вычислительных мощностей, добавляемых в AWS третий год подряд, причем 98 % из 1000 ведущих клиентов EC2 уже используют эту архитектуру. Постепенно осваивают Arm и прямые конкуренты Amazon — Google активно портирует своё ПО на CPU Axion, у Microsoft недавно представила уже второе поколение процессоров Cobalt.
19.11.2025 [15:39], Сергей Карасёв
132 «динамических» Arm-ядра и 12 каналов памяти: Microsoft представила процессоры Cobalt 200 для облака AzureКорпорация Microsoft анонсировала процессоры Cobalt 200 на архитектуре Arm, спроектированные специально для облачных платформ. Изделия, в частности, будут применяться в составе инстансов Azure следующего поколения. Первые серверы на базе Cobalt 200 уже запущены в дата-центрах Microsoft, а более широкое внедрение намечено на 2026 год. Оригинальные чипы Cobalt 100 дебютировали в ноябре 2023 года. Они объединяют 128 ядер Armv9 Neoverse N2 (Perseus). Они развёрнуты уже в 32 регионах Azure. И Microsoft, и её клиенты успешно переносят на новые чипы часть своих нагрузок. В частности, после миграции производительность Microsoft Teams выросла на 45 %, теперь сервису требуется на 35 % меньше вычислительных ядер при обработке видео- и аудиостриминга. Среди крупных пользователей Cobalt 100 компания также называет Databricks и Snowflake. 
Источник изображений: Microsoft При разработке Cobalt 200, как заявляет Microsoft, были оценены более 350 тыс. вариантов конфигурации. С помощью моделирования и ИИ были оценены различные комбинации компонентов — от ядер, кешей и памяти до питания, архитектуры отдельных узлов и целых стоек. Созданное в результате изделие по производительности более чем на 50 % превосходит решения первого поколения в реальных нагрузках Azure, данные о которых были собраны с помощью телеметрии, при сохранении энергоэффективности, говорит компания. 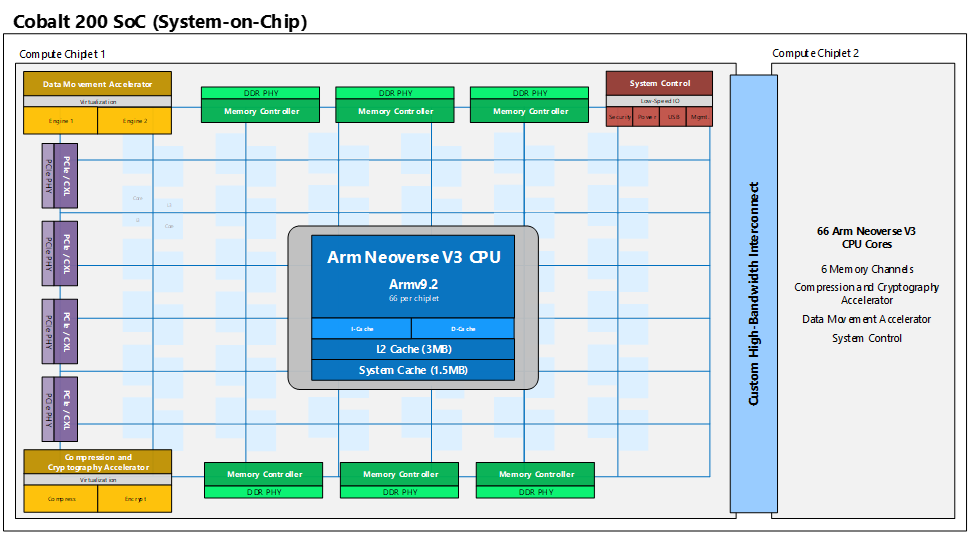 Cobalt 200 представляет собой SoC, состоящую из двух чиплетов. Каждый из них насчитывает 66 ядер с архитектурой Armv9.2 (Neoverse V3) и шесть каналов DDR. Таким образом, в общей сложности используются 132 ядра и 12 каналов памяти. Чипы получили 3 Мбайт L2-кеша в расчёте на ядро и 192 Мбайт общего L3-кеша. Количество и тип линий PCIe/CXL не уточняется.  Одной из уникальных особенностей процессоров является индивидуальное динамическое регулирование напряжения и частоты (DVFS) для каждого ядра. Это означает, что каждое из 132 ядер может работать с разным уровнем производительности, обеспечивая оптимальное энергопотребление независимо от нагрузки. Изделия производятся по 3-нм техпроцессу TSMC.  При разработке Cobalt 200 особое внимание уделено безопасности. Применён специальный контроллер памяти с активированным по умолчанию шифрованием, которое практически не влияет на производительность. Кроме того, реализована архитектура Arm CCA (Confidential Compute Architecture) с поддержкой аппаратной изоляции памяти виртуальной машины от гипервизора и операционной системы хоста. Кроме того, компания внедрила в чипы блоки аппаратного ускорения компрессии и шифрования данных собственной разработки. Узлы с новыми чипами получили DPU Azure Boost и аппаратный HSM-модуль.
16.11.2025 [23:30], Игорь Осколков
Intel отказалась от массовых Xeon Diamond Rapids с восемью каналами памяти — останутся только 16-канальные процессорыIntel, по сообщению ServeTheHome, решила отказаться в следующем поколении серверных процессоров Xeon Diamond Rapids на платформе Oak Stream от чипов с поддержкой восьми каналов памяти, оставив только модели с 16 каналами DRAM и поддержкой MRDIMM. Иными словами, в новом поколении компания, по-видимому, будет ориентироваться на топовый сегмент, оставив недорогие массовые платформы за бортом. Компания дала официальный комментарий ServeTheHome: «Мы исключили 8-канальные Diamond Rapids из наших планов. Мы упрощаем платформу Diamond Rapids, уделяя особое внимание 16-канальным процессорам и расширяя её преимущества для всех остальных, чтобы удовлетворить потребности различных клиентов». Грядущие AMD EPYC Venice также получат 16-канальный контроллер памяти. 
Источник изображения: Intel Пока что и у AMD, и у Intel максимальное количество поддерживаемых каналов памяти составляет 12. Однако в случае Intel реально доступными являются только Xeon Granite Rapids-AP (6900P), тогда как Sierra Forest-AP (6900E) так и остались нишевым продуктом. Грядущие Xeon 6+ Clearwater Forest также останутся при 12 каналах. При этом у EPYC поколения Turin (9005) во всех вариантах доступны 12 каналов.  Наиболее массовые Granite Rapids-SP (6500P/6700P) и Sierra Forest-SP (6700E) на платформе Birch Stream ограничены восемью каналами памяти, но… это может быть не так уж и плохо. Платформы для них дешевле, чем для AP-версий, а относительно небольшое количество каналов памяти даёт определённую гибкость в выборе компонентов. Речь в том числе про физические характеристики серверных платформ — платы с 32 или 48 слотами DIMM вынужденно переходят к «двухярусной» компоновке, когда один процессор сдвинут вглубь шасси из-за невозможности комфортно разместить все слоты и оба сокета в один ряд в рамках стандартного 19” корпуса. 
В многоузловых системах компоновка ещё более экзотическая При этом типовые восьмиканальные решения позволяют легко набрать нужный объём RAM в 2DPC-режиме более дешёвыми модулями памяти (пусть и с потерей производительности), чем в случае 12-канальных платформ с 1DPC. Поэтому 2S-системы с восьмиканальными CPU всё ещё остаются крайне популярными. Однако Intel в Diamond Rapids решила отказаться от массовых платформ.
13.11.2025 [16:32], Сергей Карасёв
1024 ядра, 6 ГГц и 48 Тбайт DDR5-17600: Tachyum обновила характеристики несуществующего процессора ProdigyСловацкая компания Tachyum в очередной раз поделилась информацией о процессорах Prodigy с уникальной архитектурой, которые объединят возможности CPU, GPU и TPU. Эти изделия, как утверждается, позволят работать с ИИ-моделями, которые по количеству параметров будут на много порядков превосходить современные решения, но за несколько лет компания так и не представила ни одного работающего чипа. Tachyum работает над Prodigy с 2019 года. При этом фактический выпуск процессоров многократно переносился: последовательно назывались 2021, 2022, 2023, 2024 и 2025 годы, но пока эти чипы существуют только на бумаге. Между тем компания заявляет о внесении улучшений в архитектуру Prodigy в соответствии с постоянно меняющимися требованиями в отношении аппаратных платформ для ИИ и НРС. 
Источник изображений: Tachyum Изначально предполагалось, что в состав Prodigy войдут до 192 ядер с тактовой частотой до 5 ГГц и выше. Говорилось о поддержке 16 каналов памяти DDR5-7200 с возможностью использования до 32 Тбайт ОЗУ в расчёте на процессорный разъём, а также 96 линий PCIe 5.0. Выпускать изделия компания намеревалась по 5-нм технологии. 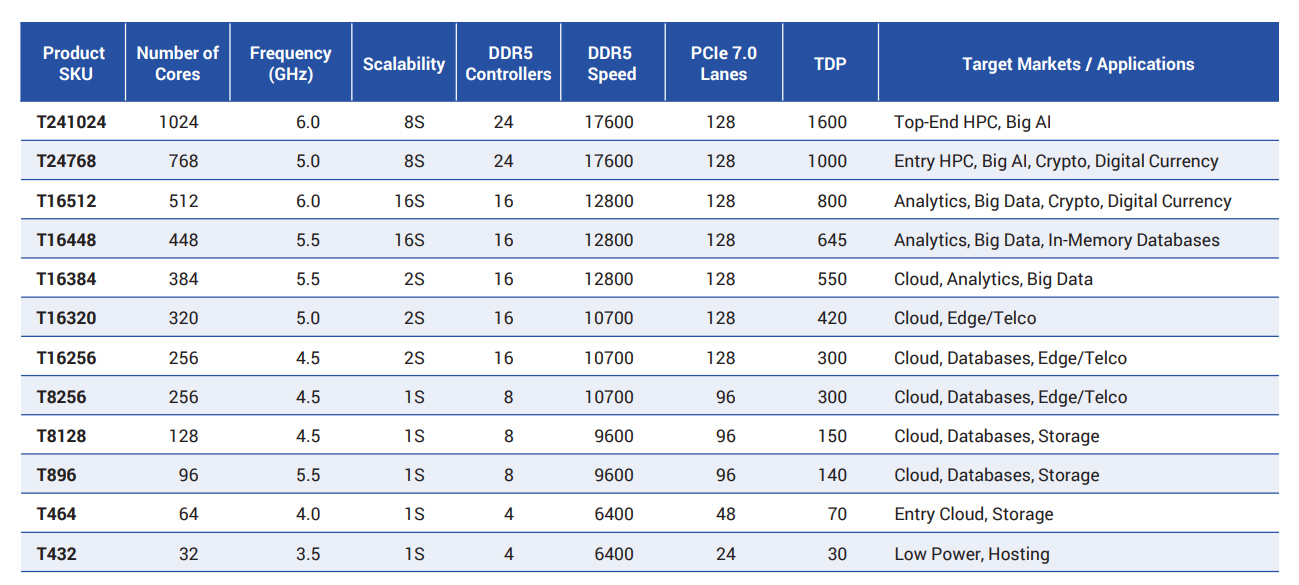 Теперь Tachyum заявляет, что Prodigy будут производиться по 2-нм технологии. Каждый чиплет в составе процессоров объединит до 256 высокопроизводительных кастомизированных 64-бит ядер с частотой до 6 ГГц, что в сумме даст до 1024 ядер в конфигурации с четырьмя чиплетами. Упомянуты 24 контроллера памяти с поддержкой DDR5-17600 и 128 линий PCIe 7.0. Максимальный объём памяти достигает 48 Тбайт в расчёте на сокет. Показатель TDP — до 1600 Вт. Возможно формирование 8S-систем. Такими характеристиками будут обладать флагманские изделия серии Prodigy Ultimate. 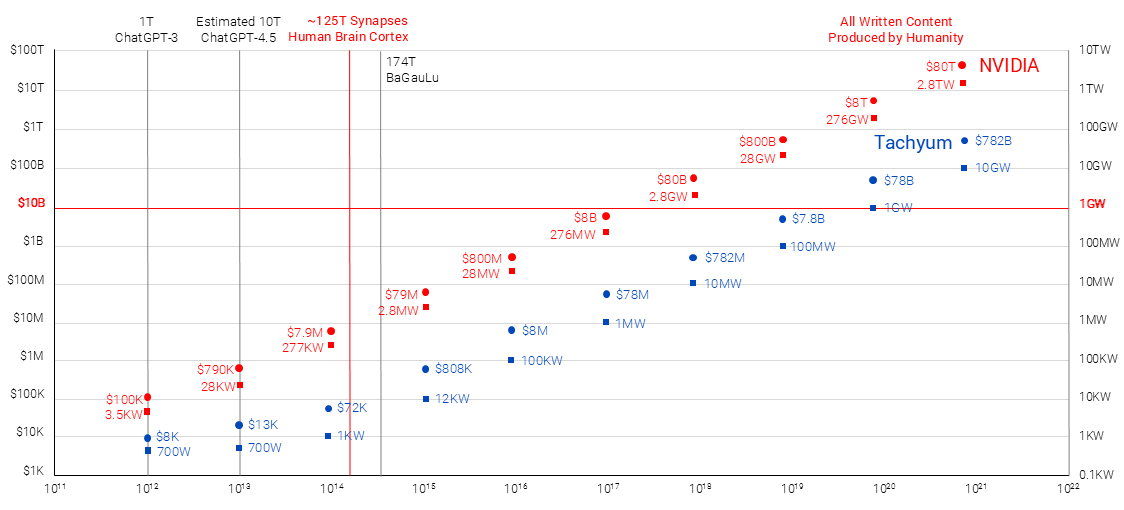 Кроме того, готовятся чипы Prodigy Premium, имеющие до 512 ядер и до 16 каналов памяти DDR5-12800, а также «обычные» чипы Prodigy, содержащие до 128 ядер и до 8 каналов DDR5-9600. Первые могут применяться в 16S-системах, вторые — в односокетных. Кроме того, заявлена возможность запуска немодифицированных x86-приложений, а также Arm и RISC-V ПО. В целом, утверждает Tachyum, решения Prodigy Ultimate обеспечат до 21,3 раза более высокую ИИ-производительность на уровне стойки по сравнению с NVIDIA Rubin Ultra NVL576. В свою очередь, Prodigy Premium якобы превзойдут по ИИ-быстродействию систему NVIDIA Vera Rubin NVL144 в 25,8 раза. Разработчик также заявляет, что Prodigy станет первым чипом с производительностью более 1000 Пфлопс на задачах инференса против 50 Пфлопс у NVIDIA Rubin на аналогичных операциях. Впрочем, в спецификациях Prodigy пока говорится от 400 Тфлопс в FP64-вычислениях и о 400 Пфлопс в ИИ-вычислениях неназванной точности.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 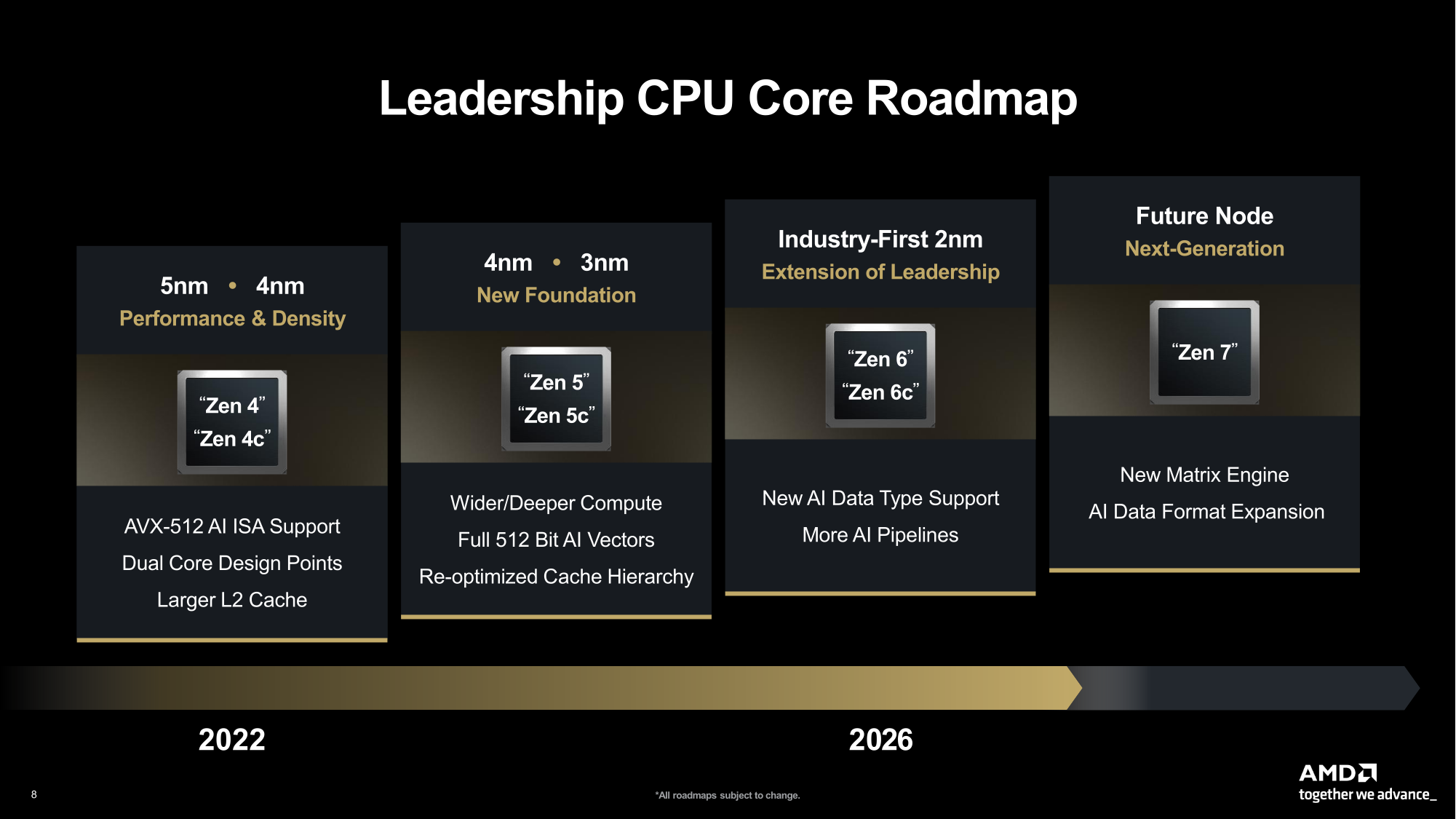 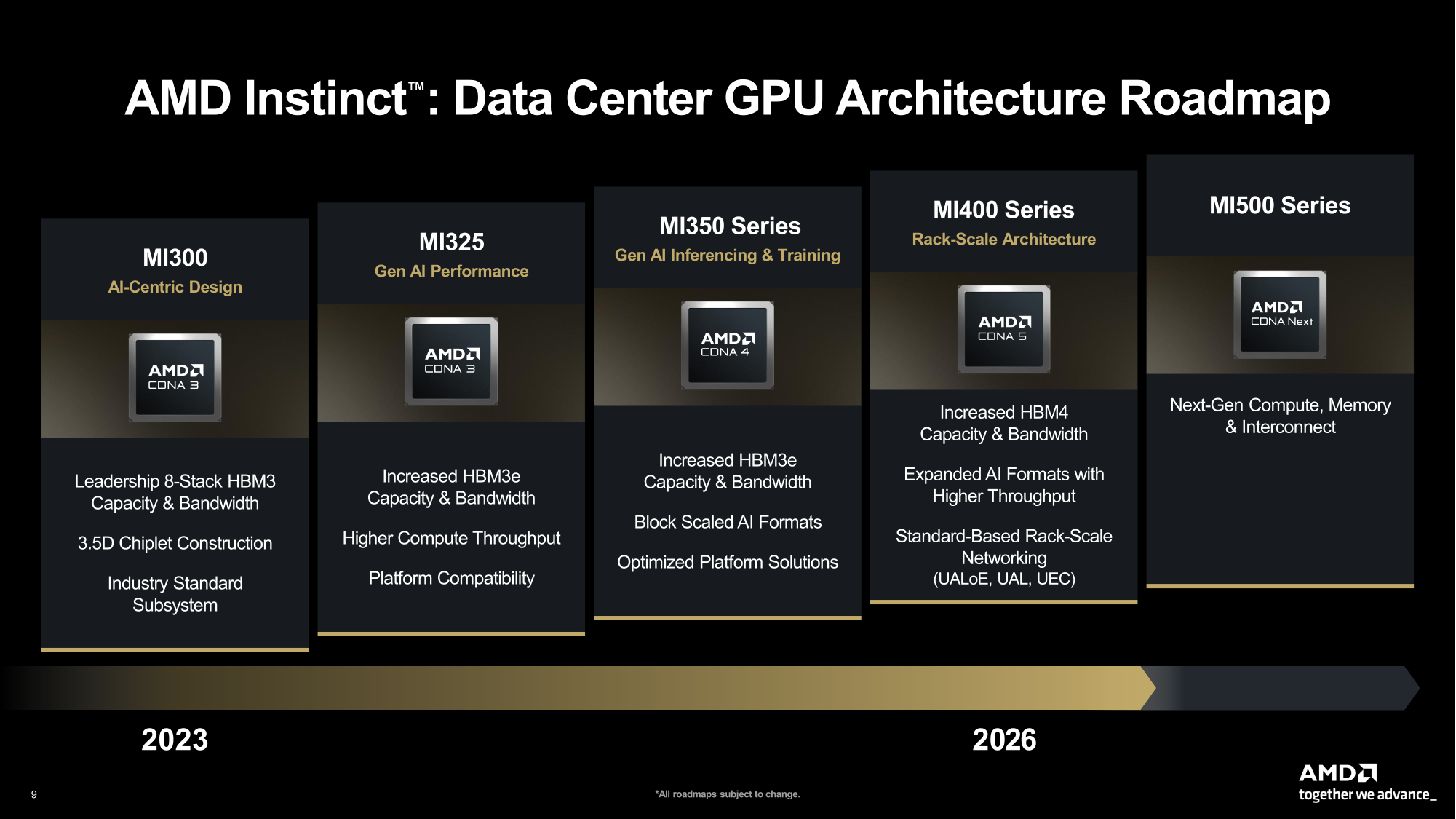 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  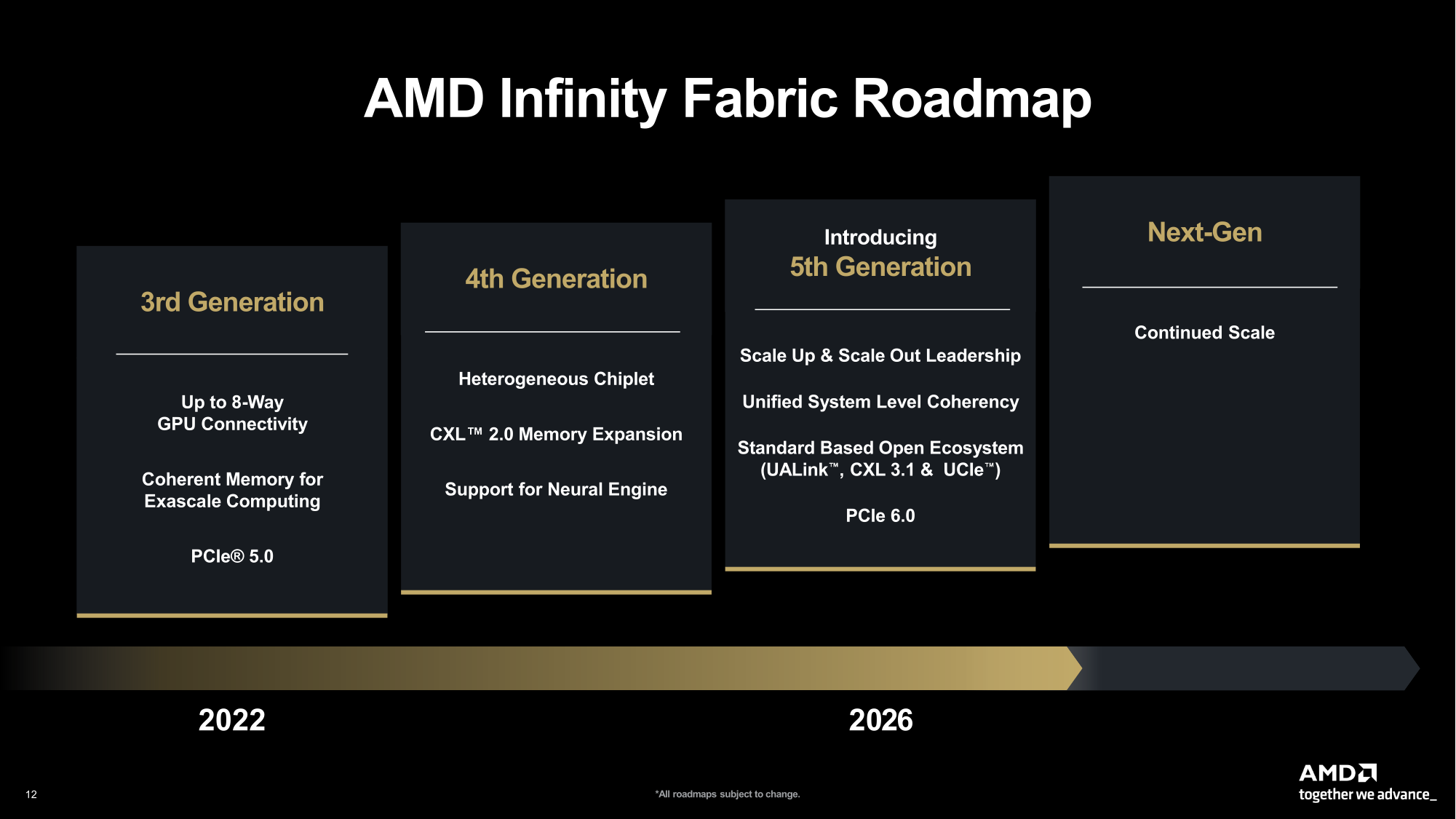 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  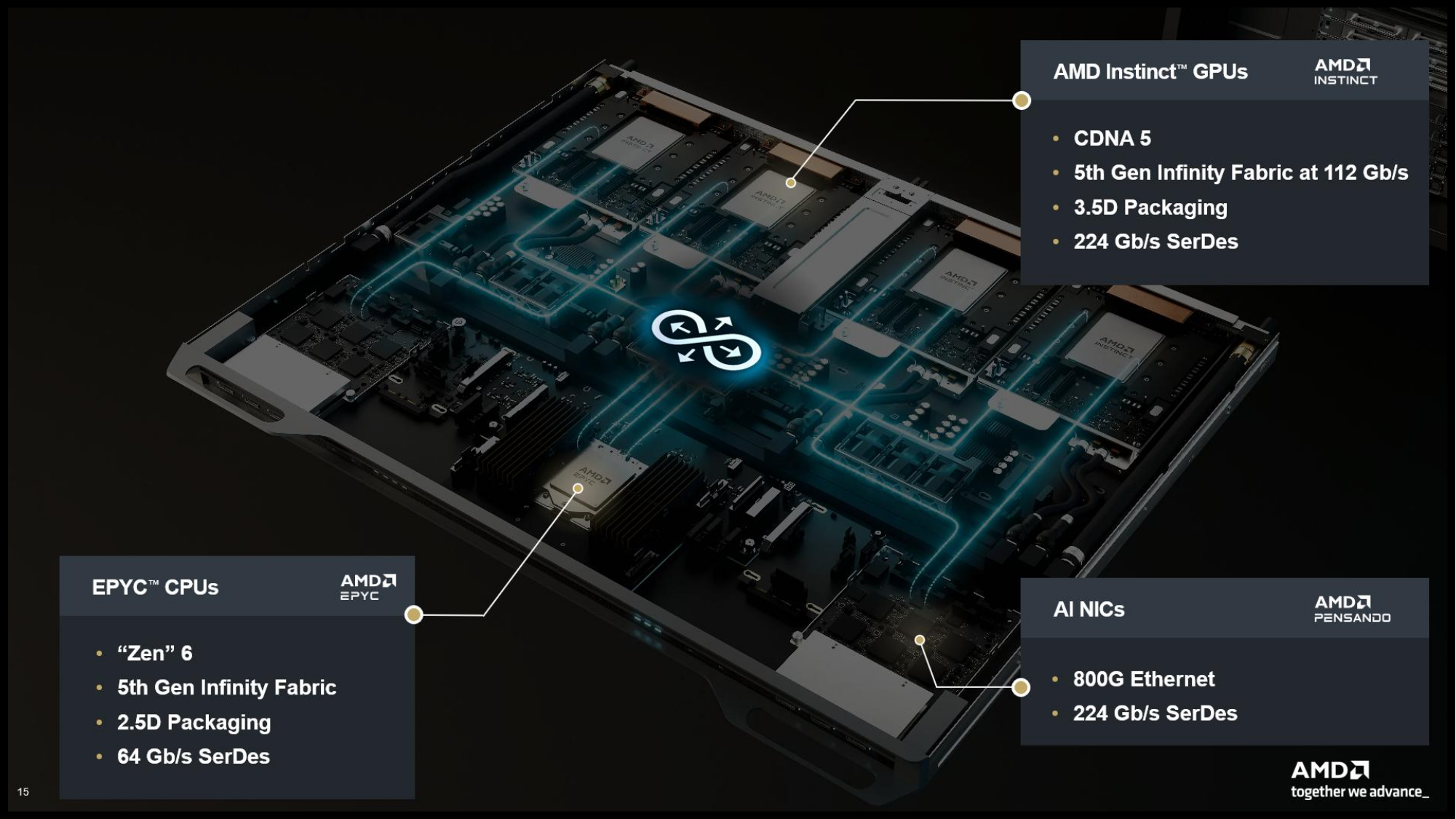 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  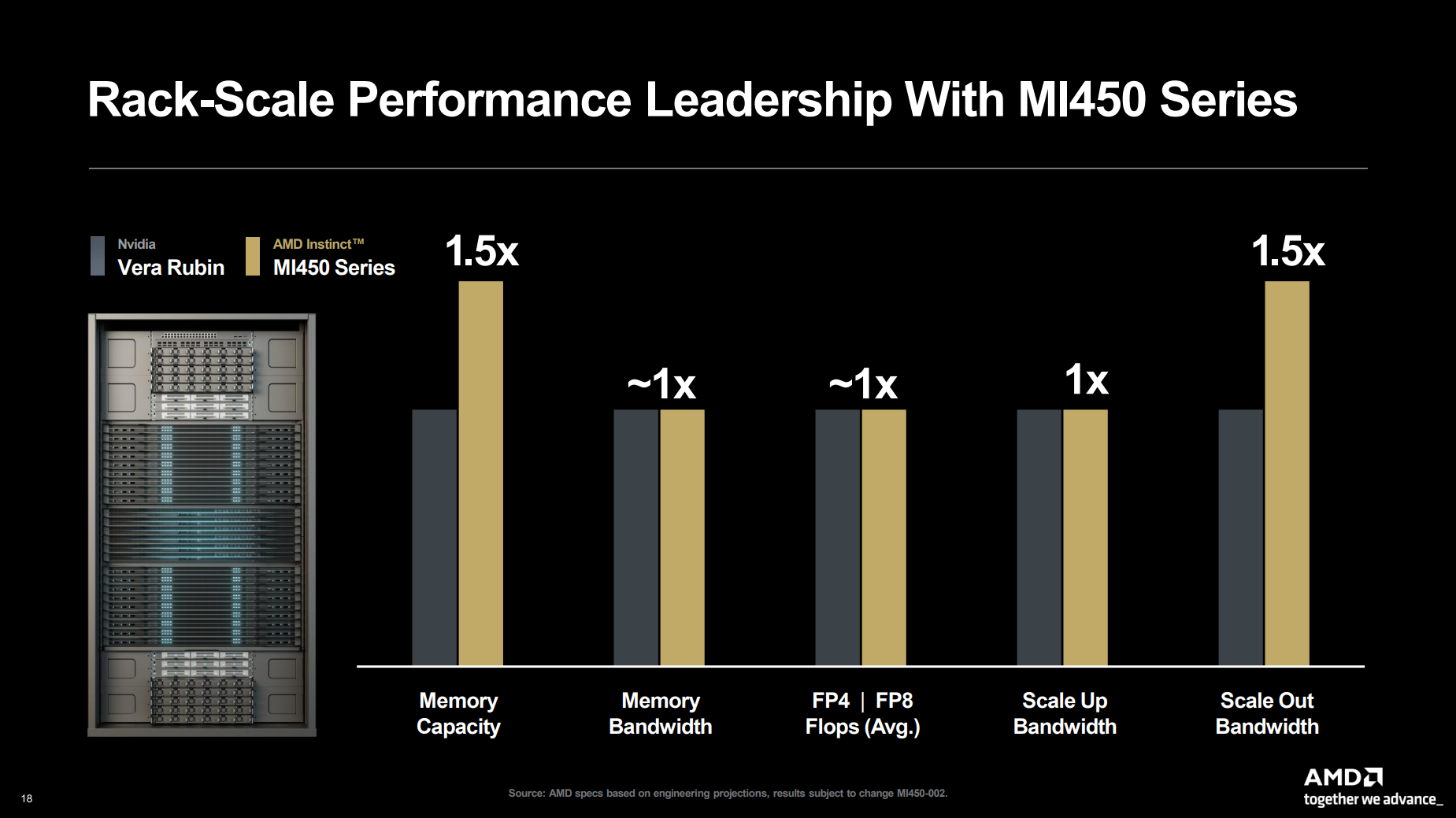 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth.   AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 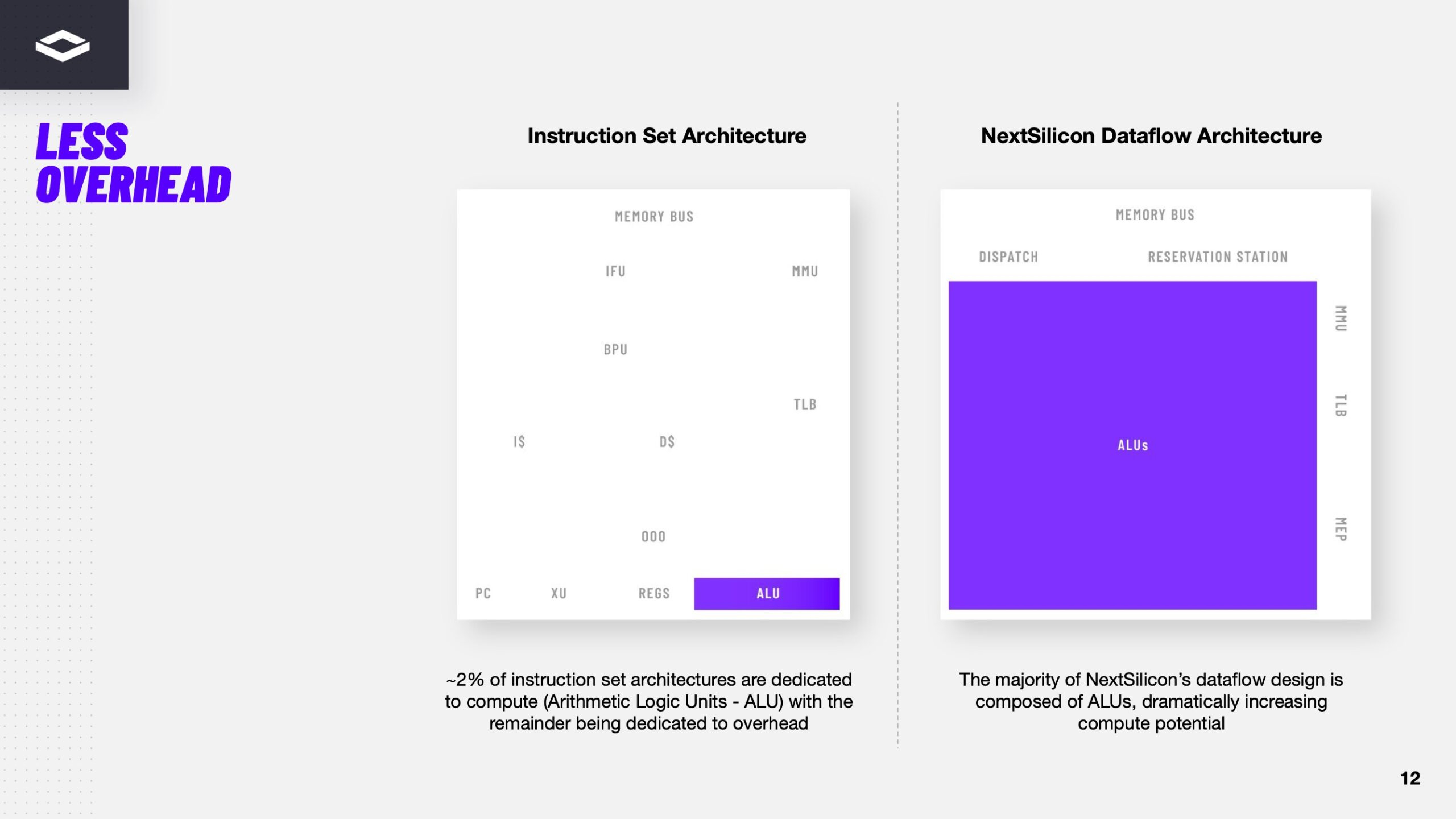
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 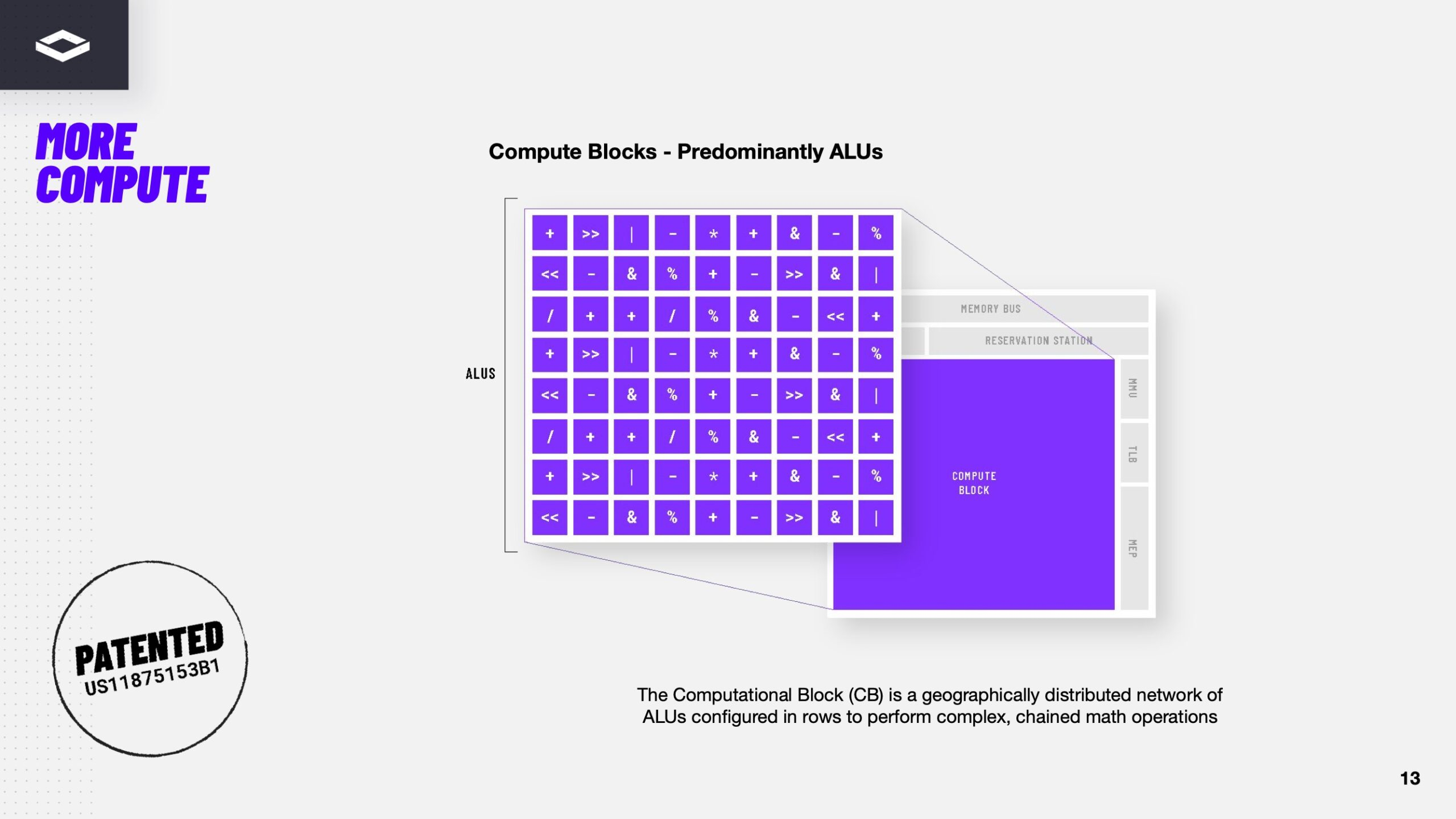 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 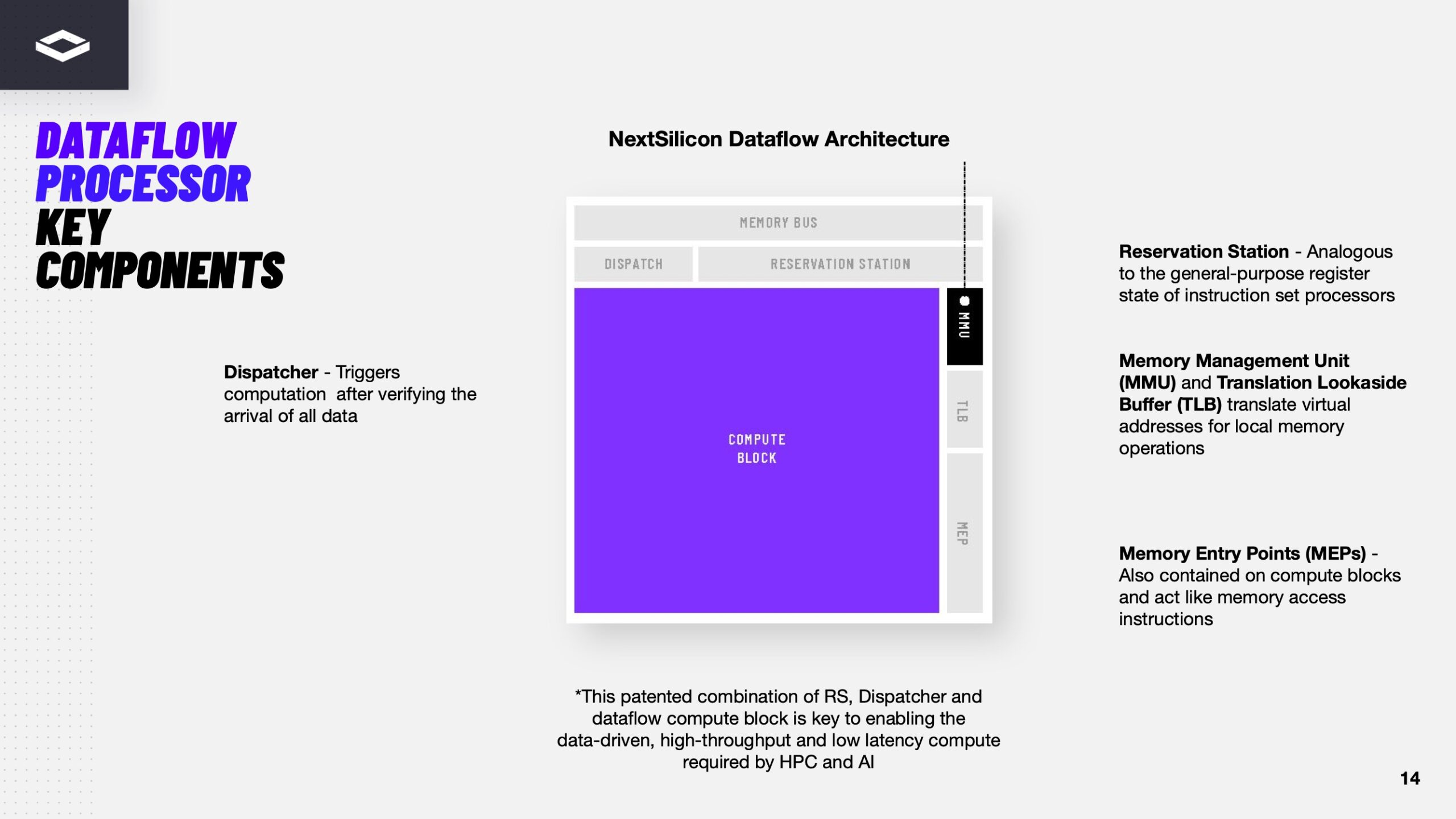 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 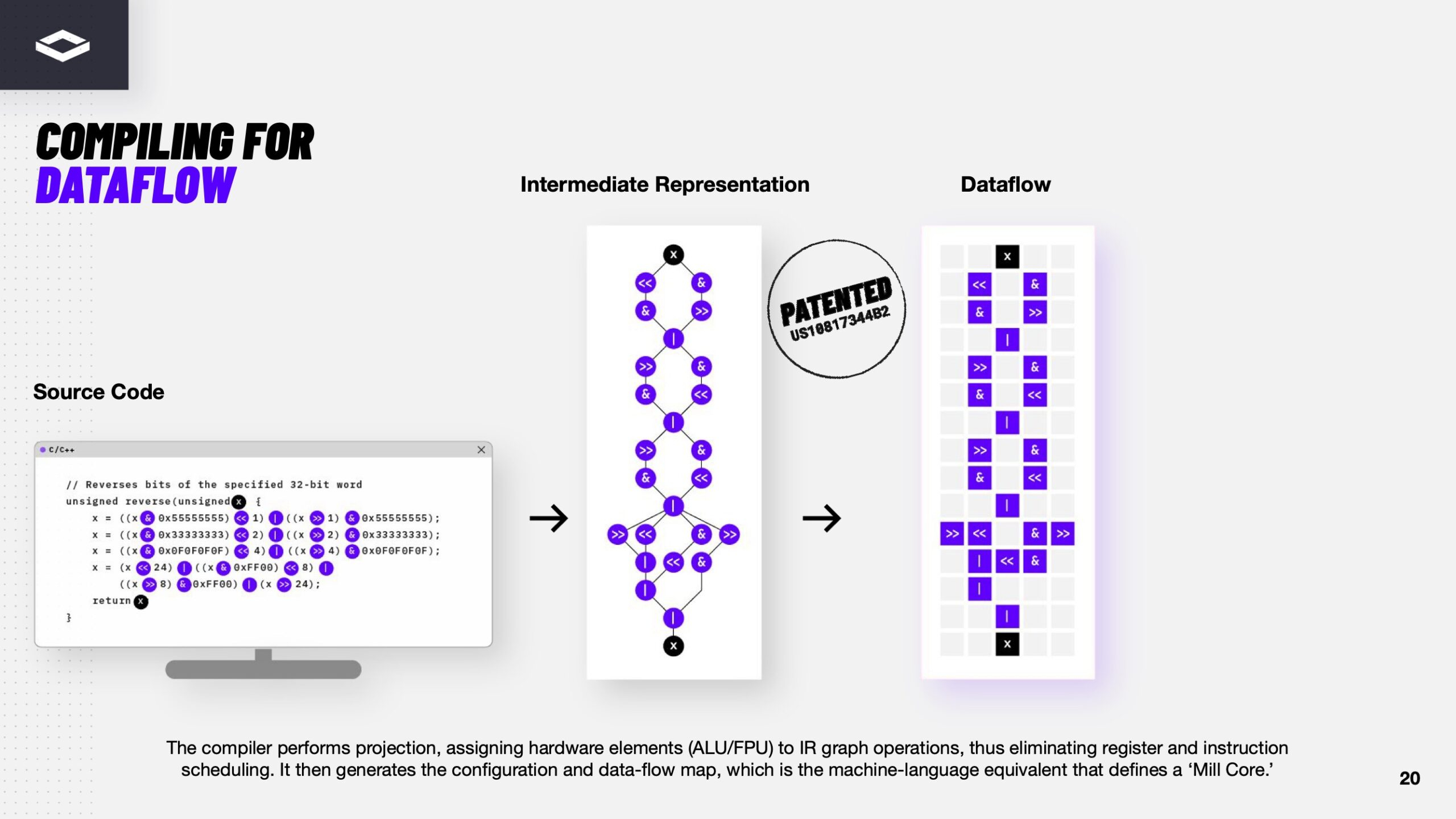 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 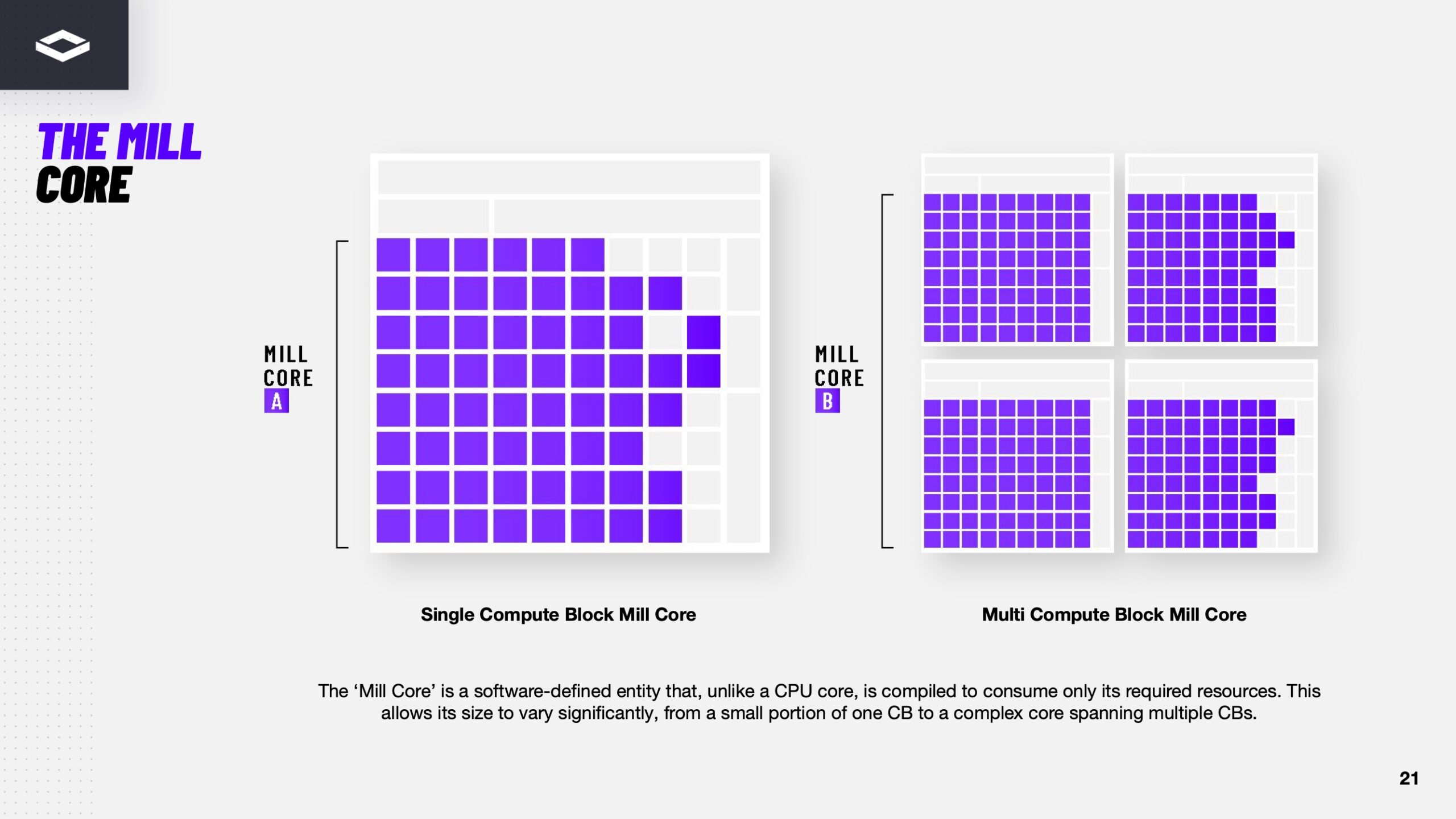 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 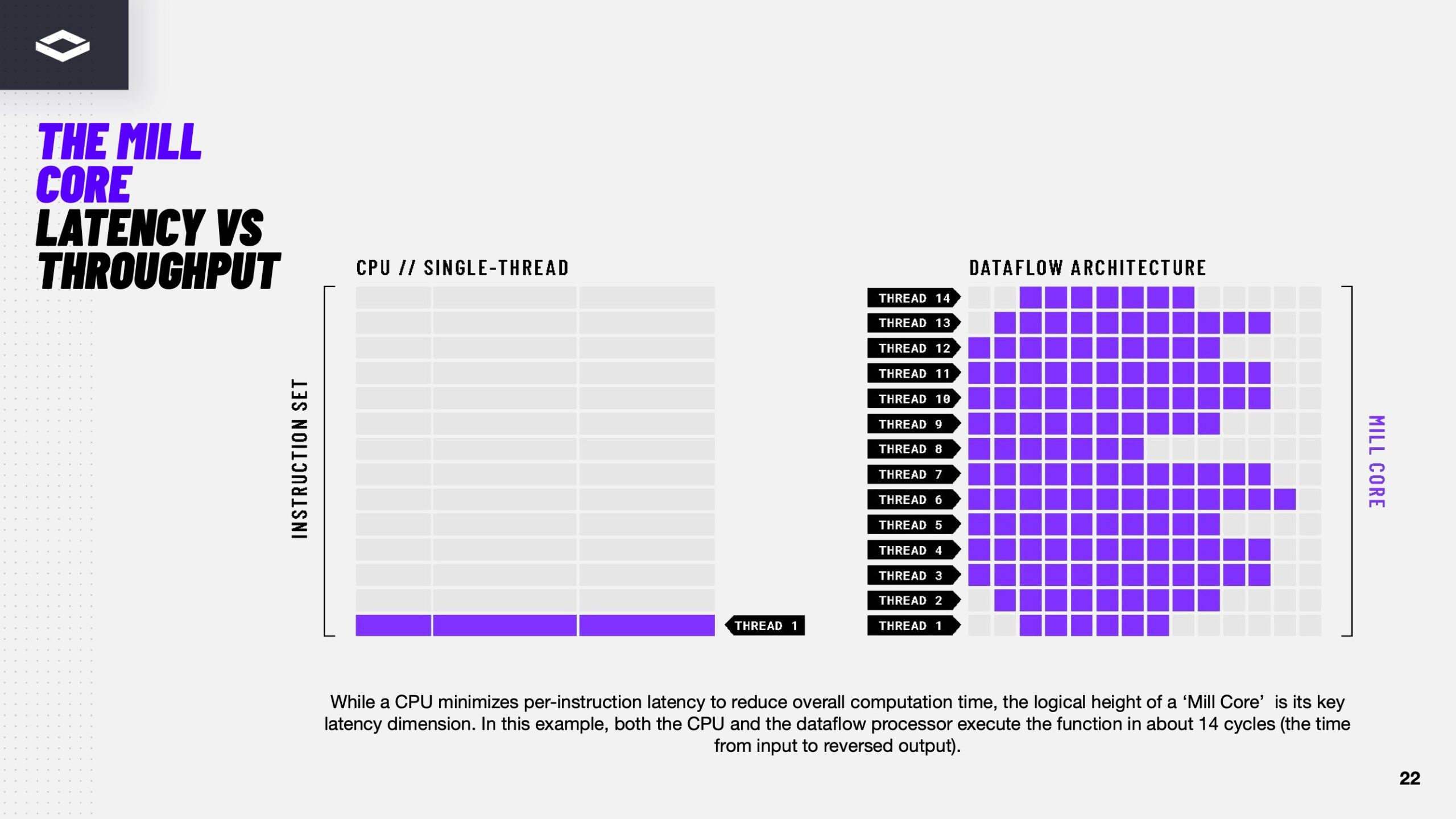 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 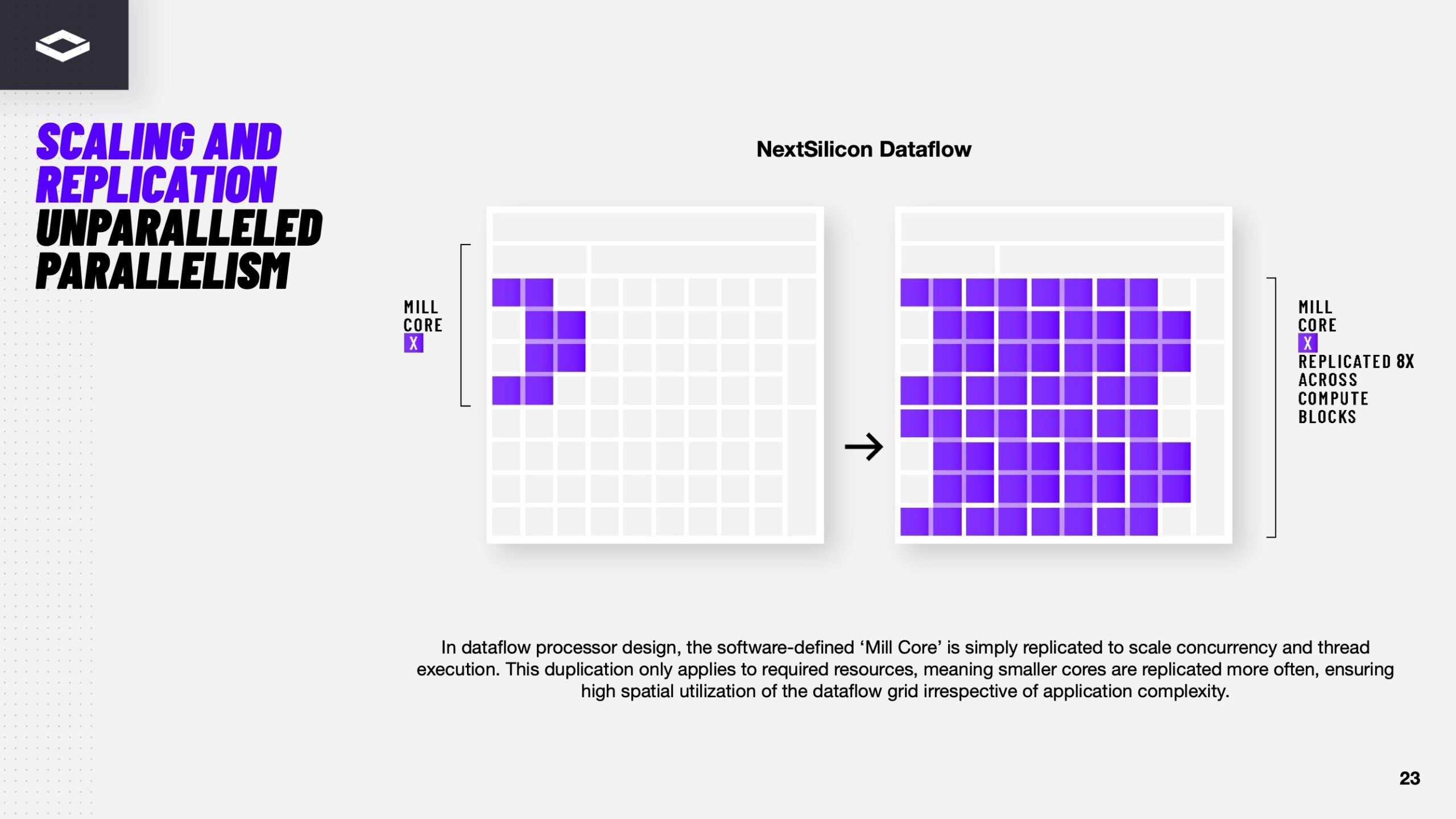 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 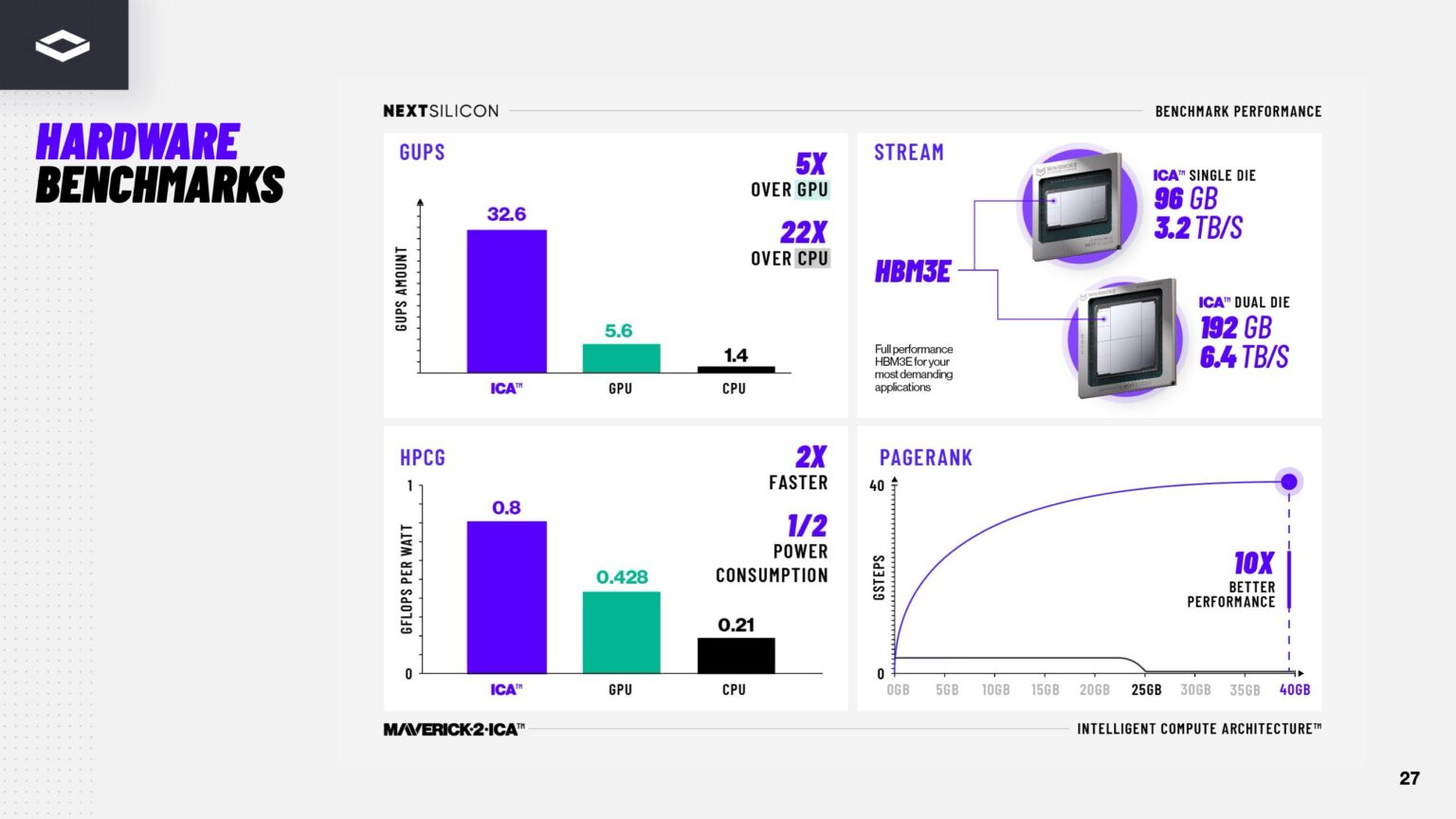 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 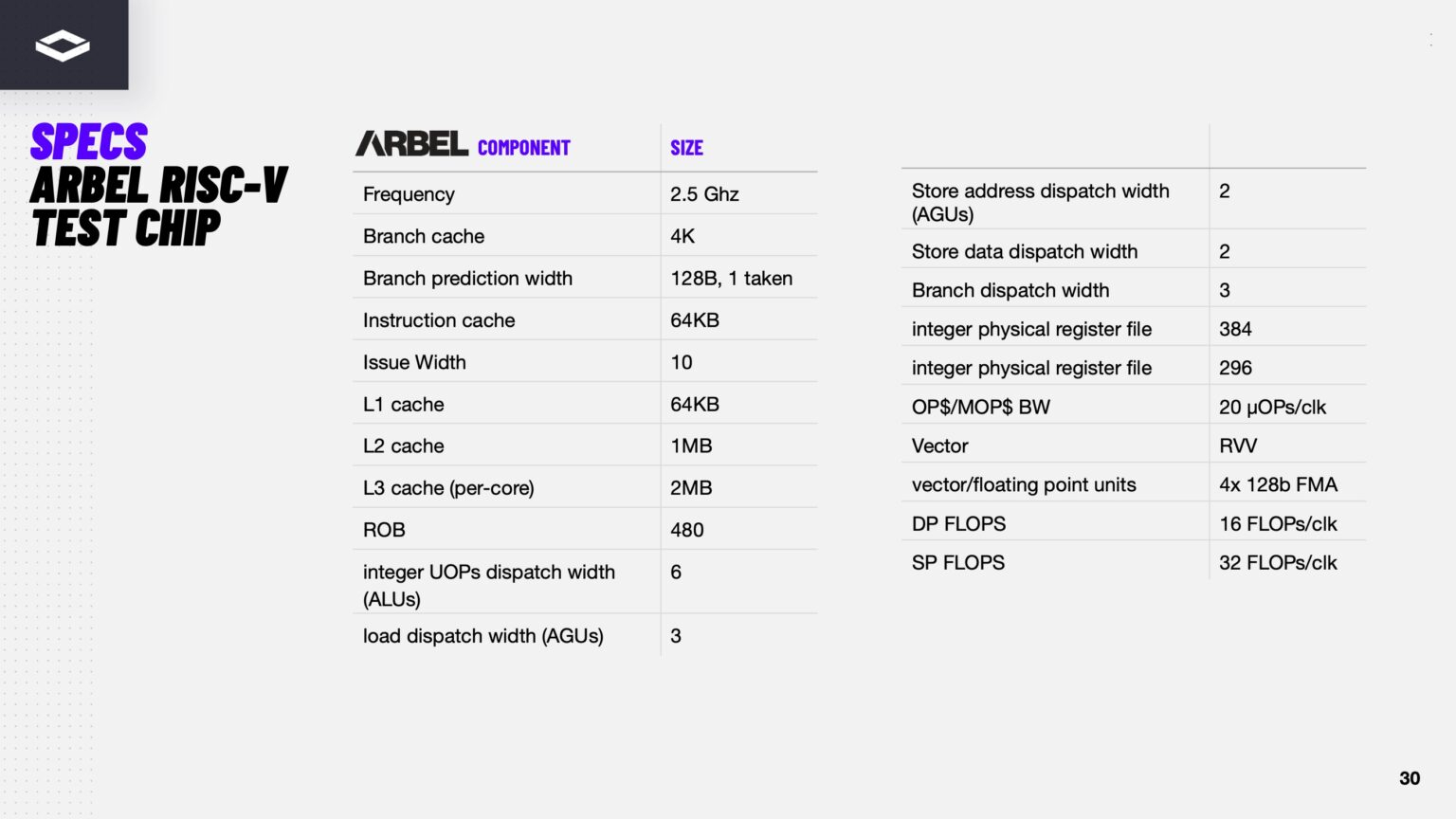 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 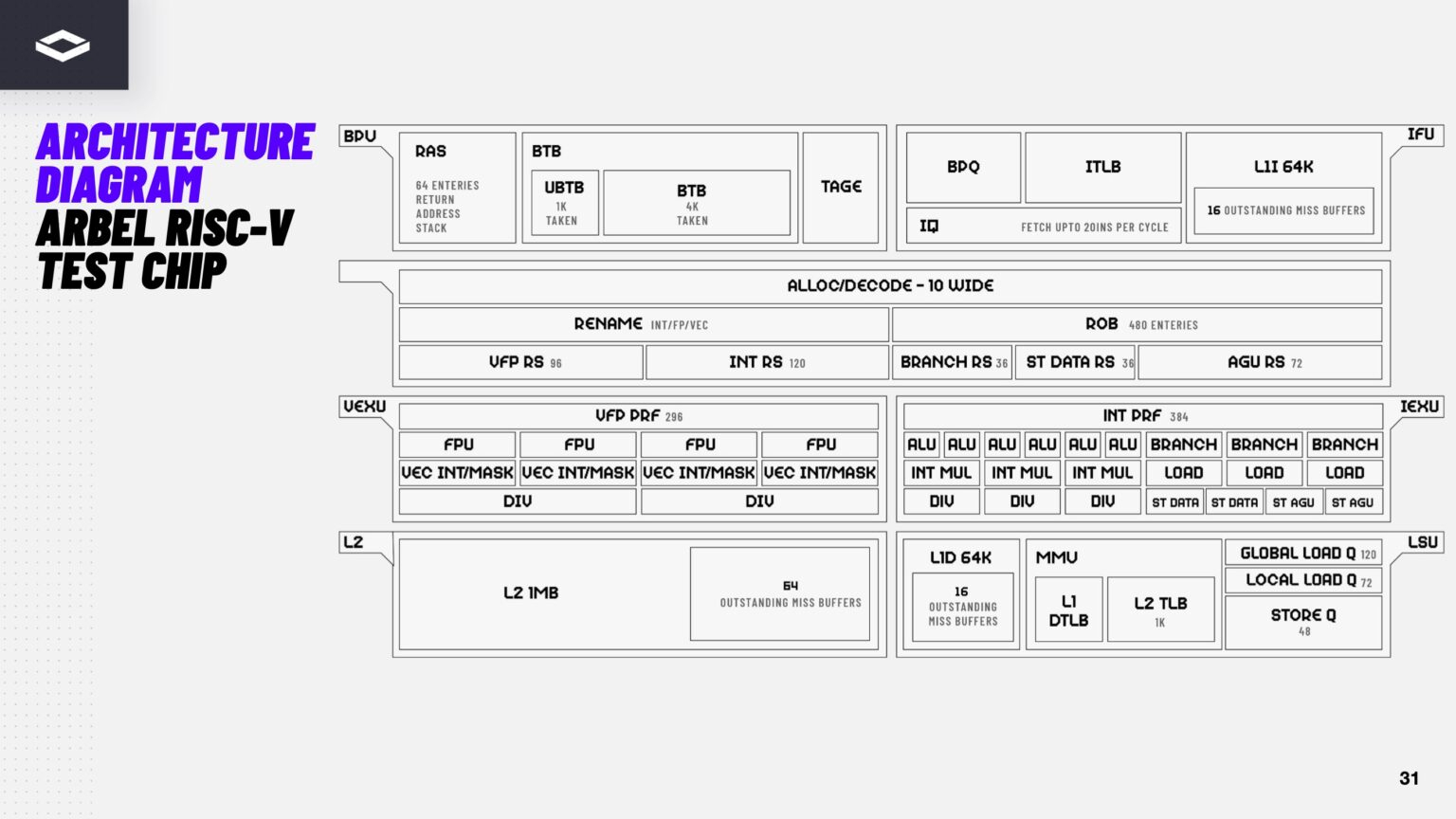 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
18.10.2025 [15:39], Сергей Карасёв
В Linux появилось упоминание загадочного x86-процессора от неизвестного ранее производителяВ списках рассылок Linux Kernel и GNU Binutils, по сообщению ресурса Phoronix, появилась информация о кодах операций (opcode), которые используются в процессорах с архитектурой х86, не имеющих отношения к изделиям AMD и Intel. О каком именно производителе чипов идёт речь, пока не ясно. О загадочных инструкциях сообщил Кристиан Ладлофф (Christian Ludloff), опытный эксперт по архитектуре x86. Он в течение многих лет работал в компаниях Google, AMD и Texas Instruments. Кроме того, Ладлофф является создателем сайта sandpile.org, на котором собрана различная техническая информация о чипах x86. Известно, что новые инструкции используются в продуктах некоего производителя изделий. То есть речь не идёт об исследовательской организации или каком-либо экспериментальном проекте. 
Источник изображения: Phoronix Высказываются предположения, что за новым x86-процессором может стоять китайская компания Zhaoxin. Минувшим летом она представила чип KH-50000 для серверов и ИИ-систем. Изделие выполнено на x86-совместимой архитектуре Zhaoxin Century Avenue, лицензия на которую ей досталась по наследству от Cyrix и VIA. В целом, китайские компании на фоне американских санкций активно развивают направление собственных серверных чипов. Так, компания Loongson недавно представила 64-ядерные процессоры 3C6000 на архитектуре LoongArch. Однако для Zhaoxin нет смысла секретничать, поскольку компания давно открыто и активно занимается разработкой, развивая открытые проекты, в том числе ядро Linux, библиотеки, компиляторы и т.д. В Китае также есть Hygon, которая, как ранее сообщалось, готовит 128-ядерного конкурента AMD EPYC с SMT4 и AVX-512. Ранее AMD и Hygon выпустили процессор Dhyana, который представлял собой чуть доработанный под местные требования первые EPYC Naples. Чем-то похожим занимается Montage Technology, выпускающая под брендом Jintide перелицованные Intel Xeon. Также известна тайваньская DM&P Electronics, которая выпускает 32-бит x86-процессоры Vortex86, которые корнями уходят к Rise Technology и SiS. Лицензии на современный набор инструкций у неё нет. Среди других предположений, высказанных в Сети, есть упоминание сделки Intel с NVIDIA по разработке кастомных CPU. Наконец, упоминаются эмуляторы, программные или с аппаратной поддержкой, т.е. не x86-процессоры. Это может быть интересно, например, Qualcomm. Кроме того, в российских процессорах «Эльбрус» есть двоичная трансляция x86-кода.
09.10.2025 [22:09], Владимир Мироненко
Intel анонсировала процессоры Xeon 6+ — Clearwater Forest с 288 E-ядрами DarkmontIntel раскрыла на мероприятии Intel Tech Tour Arizona новые подробности о следующем поколении серверных процессоров, выполненных по техпроцессу Intel 18A, которые получат название Xeon 6+ (Clearwater Forest) и будут иметь до 288 энергоэффективных ядер Darkmont E-Core, сообщил ресурс Phoronix. В максимальной конфигурации Xeon 6+ включает 12 чиплетов E-Core (Intel 18A с RibbonFET и PowerVia), 3 базовых тайла (Intel 3) и 2 чиплета I/O (Intel 7). 12 EMIB-тайлов объединяют все чиплеты в единую 2.5D-упаковку. Как сообщается, Xeon 6+ имеет в 1,9 раза более высокую пропускную способность памяти по сравнению с предыдущим поколением. Это связано с поддержкой 12 каналов памяти DDR5-8000 по сравнению с восемью каналами DDR5-6400 в процессорах Xeon 6700E (Sierra Forest-SP). Впрочем, у Xeon 6900E (Sierra Forest-AP) тоже поддерживает 12 каналов памяти, хотя и DDR5-6400 (а в 2DPC — 5200). Модули памяти MRDIMM новинки не поддерживают. 
Источник изображений: Intel/Wccftech.com Производительность Clearwater Forest также обеспечивается L3-кешем объёмом до 576 Мбайт (в 6700E было до 108 Мбайт, а 6900P — до 504 Мбайт), техпроцессом 18A и новой функцией Intel AET. Intel AET (Application Energy Telemetry) — технология телеметрии энергопотребления приложений, помогающая разработчикам/администраторам профилировать и масштабировать рабочие нагрузки на этих процессорах с большим количеством ядер.  Intel Xeon 6+ также позиционируется как процессор с улучшенной эффективностью до 23 % по всем видам нагрузок. На ещё одном слайде указано, что у Intel Xeon 6+ «в 1,9 раза более высокая производительность», чем у Xeon 6780E. Ресурс Phoronix вполне справедливо считает такое сравнение некорректным, учитывая удвоенное количество ядер, большее количество каналов памяти и более высокую скорость памяти, больший размер L3-кеша и т. д. Впрочем, есть надежда, что Intel вскоре опубликует более конкретные сравнительные показатели, а также таблицу с моделями Xeon 6+, чтобы получить точное представление о сравнении с серией Xeon 6700E.  Intel также подтвердила, что Xeon 6+ будет обладать максимальным TDP в диапазоне от 300 до 500 Вт и совместимостью с одно- и двухсокетными платформами. Также доступно до шести каналов UPI 2.0, до 96 линий PCIe 5.0 и до 64 линий CXL 2.0. Ускорители Intel QAT, DLB, DSA и IAA по-прежнему поддерживаются Xeon 6+, но Intel практически ничего не рассказала об этих блоках. |
|

