Материалы по тегу: ускоритель
|
23.04.2024 [11:45], Сергей Карасёв
Samsung откроет в Кремниевой долине лабораторию по созданию ИИ-чипов на базе RISC-V, чтобы побороться с NVIDIAКомпания Samsung Electronics, по сообщению ресурса Business Korea, откроет новую научно-исследовательскую и опытно-конструкторскую (R&D) лабораторию в Кремниевой долине. Её специалисты займутся прежде всего созданием ИИ-чипов на открытой архитектуре RISC-V. По имеющейся информации, Технологический институт Samsung SAIT (Samsung Advanced Institute of Technology) учредил исследовательский центр Advanced Processor Lab (APL). Южнокорейская компания намерена расширить свои возможности в области разработки ИИ-решений, чтобы в перспективе бросить вызов американским корпорациям, в числе которых называется NVIDIA. Около месяца назад Samsung сформировала лабораторию Semiconductor AGI Computing Lab, сотрудники которой разрабатывают чипы следующего поколения для ИИ-приложений. Офисы данного подразделения располагаются в Южной Корее и США. Основным направлением исследований являются системы «общего искусственного интеллекта» (Artificial General Intelligence, AGI). В заявлении в LinkedIn глава Samsung Semiconductor Ке Хён Гён (Kye Hyun Kyung) отметил, что на первом этапе лаборатория сосредоточит усилия на разработке чипов для больших языковых моделей (LLM), тогда как реализация проектов в области AGI начнётся позднее. 
Источник изображения: pixabay.com Между тем власти США в рамках «Закона о чипах» выделили Samsung $6,4 млрд безвозвратных субсидий на строительство предприятий в Техасе. По условиям соглашения, в городе Тейлоре будут построены два завода по выпуску полупроводниковых изделий с нормами 4 и 2 нм. «Мы считаем, что полупроводниковые технологии нового поколения, созданные с использованием ИИ и компьютерной техники, сыграют ключевую роль в повышении качества жизни. Именно поэтому SAIT тесно сотрудничает с учёными и экспертами в поисках новых долгосрочных драйверов роста для Samsung», — говорит Гёйонг Джин (Gyoyoung Jin), президент SAIT.
22.04.2024 [21:30], Сергей Карасёв
Microsoft к концу 2024 года планирует использовать до 1,8 млн ИИ-ускорителей на базе GPUКорпорация Microsoft, по сообщению ресурса Business Insider, в течение 2024 года намерена утроить количество ускорителей на базе GPU в составе своей вычислительной ИИ-инфраструктуры. В результате, как ожидается, к декабрю общее количество таких изделий, находящихся в распоряжении редмондского гиганта, может достичь 1,8 млн. Два года назад у Microsoft было несколько сотен тысяч ускорителей, в том числе FPGA и ASIC. Microsoft в партнёрстве с OpenAI реализует комплексную программу по развитию ИИ-систем. В частности, планируется строительство масштабного кампуса ЦОД под названием Stargate стоимостью $100 млрд. Средства, как уточняет Business Insider, пойдут в том числе на закупку GPU-ускорителей. Аналитики DA Davidson подсчитали, что в прошлом году Microsoft потратила приблизительно $4,5 млрд на приобретение ИИ-ускорителей NVIDIA. Один из руководителей Microsoft подтвердил, что эта цифра близка к фактическим расходам корпорации в рассматриваемом сегменте. 
Источник изображения: Microsoft Microsoft также проектирует собственные ИИ-чипы, которые помогут снизить зависимость от сторонних поставщиков. Так, она уже представила свой первый ИИ-ускоритель Maia 100, который спроектирован под задачи облачного обучения и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Однако некоторые специалисты относятся скептически к этим усилиям Microsoft, поскольку корпорация на годы отстаёт от NVIDIA в плане создания мощных ИИ-решений. Business Insider со ссылкой на документацию Microsoft сообщает, что во II половине 2023-го корпорация развернула «рекордные мощности GPU». Однако конкретные цифры и тип ускорителей не раскрываются. Другие крупные IT-компании и облачные провайдеры также продолжают наращивать ИИ-ресурсы. Например, Meta✴, как ожидается, к концу 2024 года будет иметь в своём распоряжении около 350 тыс. NVIDIA H100 и неназванное количество ускорителей собственной разработки MTIA v1 и MTIA v2. Некоторые игроки рынка присматриваются к конкурирующим решениям. Так, Dell намерена использовать ИИ-ускорители Intel Gaudi3, а стартап TensorWave разворачивает ИИ-облако из 20 тыс. ускорителей AMD Instinct MI300X.
18.04.2024 [12:20], Сергей Карасёв
Rivos, разработчик ИИ-ускорителей на базе RISC-V, получил на развитие более $250 млнКалифорнийский стартап Rivos, основанный в 2021 году, сообщил о проведении раунда финансирования Series-A3, в ходе которого на развитие привлечено более $250 млн. Ключевым инвестором стала фирма Matrix Capital Management. Кроме того, средства предоставили Intel Capital, Dell Technologies Capital, MediaTek и др. Rivos занимается разработкой чипов на открытой архитектуре RISC-V для приложений ИИ и больших языковых моделей (LLM). Изделия планируется изготавливать на предприятии TSMC с применением 3-нм технологии. Предполагается, что такие решения станут менее дорогой альтернативой ускорителям NVIDIA. Привлеченные средства стартап направит на ускорение разработки чипов и коммерциализацию решений. При этом ориентировочные сроки начала массового производства таких изделий пока не раскрываются. 
Источник изображения: pixabay.com На сегодняшний день Rivos раскрывает лишь общую информацию о характеристиках своих чипов. В их состав войдёт узел Data Parallel Accelerator и вычислительные ядра с архитектурой RISC-V. Узлы чипа получат доступ к памяти DDR DRAM и HBM. Rivos также предоставит набор специальных программных инструментов для своих чипов. С их помощью разработчики смогут развёртывать и обучать модели ИИ. По имеющейся информации, Rivos нацеливается на приложения ИИ, которые смогут работать с PyTorch и JAX.
15.04.2024 [15:15], Сергей Карасёв
Intel готовит «урезанные» версии ИИ-ускорителя Gaudi3 для КитаяКорпорация Intel, как отмечает ресурс The Register, готовит специализированные модификации ИИ-ускорителя Gaudi3 для китайского рынка. Эти варианты из-за санкционных ограничений со стороны США будут отличаться от стандартных версий пониженным TDP и «урезанной» производительностью. Intel официально представила Gaudi3 менее недели назад. Изделие имеет чиплетную компоновку: оно состоит из двух одинаковых кристаллов с быстрым интерконнектом. В оснащение входят 128 Гбайт памяти HBM2e. Заявленная производительность FP8 и BF16 достигает 1835 Тфлопс (MME — блоки матричной математики). В семейство Gaudi3 входят ОАМ-версии HL-325L и HL-335 с показателем TDP в 900 Вт, а также PCIe-вариант HL-338 с TDP на уровне 600 Вт. 
Источник изображения: Intel Для Китая Intel предложит ОАМ-ускоритель HL-328 и PCIe-модификацию HL-388 — их поставки начнутся в июне и сентябре нынешнего года соответственно. Как и обычные изделия, ускорители для китайских заказчиков содержат два кристалла, а конфигурация памяти не изменилась — 128 Гбайт HBM2e с пропускной способностью 3,7 Тбайт/с. Вместе с тем величина TDP в обоих случаях снижена до 450 Вт. 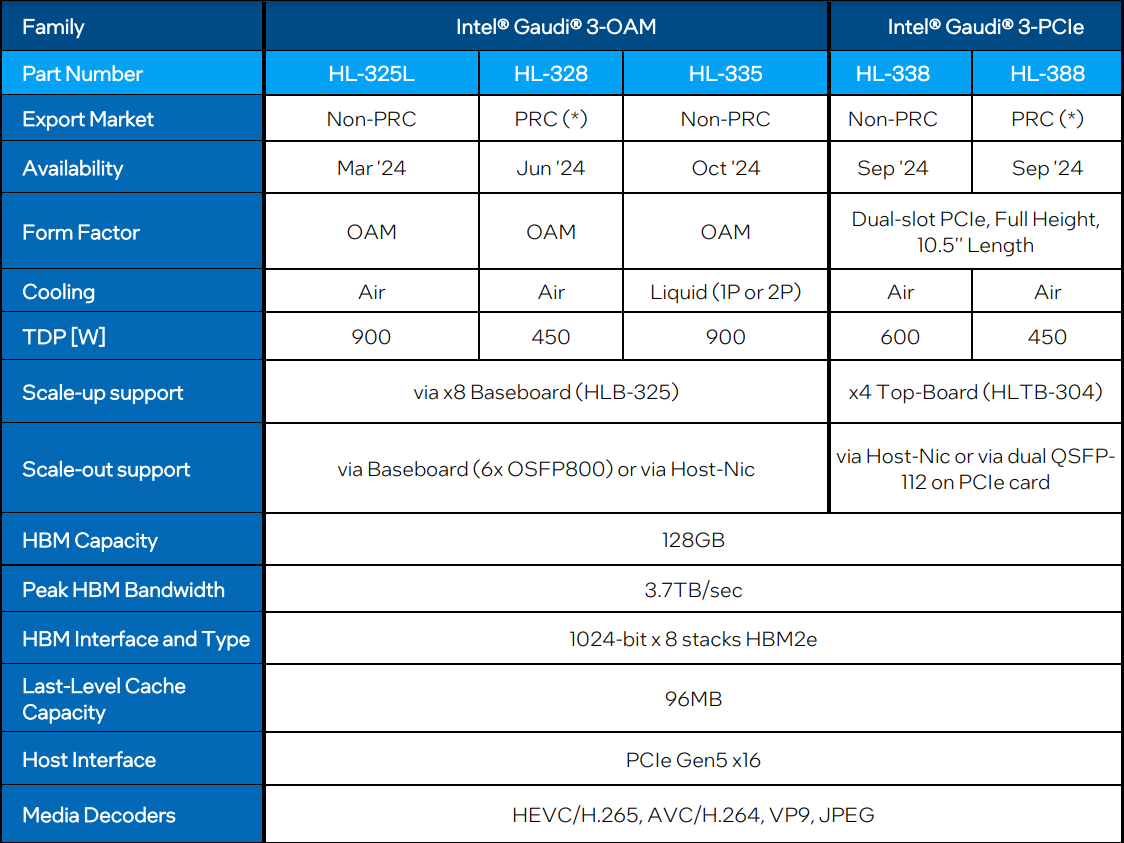
Источник: Intel В соответствии с экспортными ограничениями со стороны США, в Китай запрещаются поставки чипов с производительностью BF16 более 150 Тфлопс. Как именно Intel ограничивает быстродействие в китайских версиях Gaudi3, не ясно. Это может достигаться за счёт снижения тактовой частоты или какого-то другого метода. При этом возможность объединения таких ускорителей в группы остаётся. Отмечается также, что в Китай, по всей видимости, не будут поставляться варианты Gaudi3 с жидкостным охлаждением. NVIDIA уже дважды меняла характеристики ускорителей, чтобы обойти санкции США в отношении Китая, причём компания успела выпустить существенный объём продукции, которую в итоге пришлось направить на другие рынки. Многие китайские компании успели накопить запасы ускорителей, которых хватит на ближайшие пару лет. AMD, как выяснилось, тоже подготовила «урезанную» версию ускорителя Instinct MI309, но Министерство торговли США всё равно не разрешило поставлять её Китаю.
15.04.2024 [14:23], Сергей Карасёв
Стартап в области децентрализованных облачных ИИ-вычислений GPUnet получил на развитие $5,25 млнМолодая компания GPUnet, занимающаяся технологиями облачных вычислений, сообщила о проведении раунда финансирования Series A, в ходе которого привлечено $5,25 млн. В число инвесторов вошли Momentum6, Spicy Capital, Exnetwork, Blackdragon, Zephyrus Capital, Aza Ventures, F7 Foundation, Halvings Capital и Bigger than Race. Стартап GPUnet создаёт платформу децентрализованных облачных вычислений на базе GPU. Отмечается, что в свете стремительного развития технологий ИИ ускорители на базе GPU превратились в дефицитный ресурс. Вместе с тем в мировом масштабе четыре крупнейших поставщика облачных услуг — Amazon, Google, Microsoft и Oracle — контролируют 80 % соответствующих мощностей. В результате компании и исследовательские организации вынуждены либо подписываться на сервисы по значительной цене, либо закупать собственное оборудование. Но во втором случае требуются навыки управления ЦОД, а поставки ускорителей занимают много времени. GPUnet рассчитывает решить перечисленные проблемы путём объединения в единую сеть ресурсов независимых операторов дата-центров, которые специализируются на «вычислениях для проектов Web3», в частности, для майнинга. Отмечается, что такие операторы зачастую располагают ценными вычислительными ресурсами в небольших кластерах. GPUnet планирует использовать архитектуру распределённых вычислений, чтобы объединить кластеры в единую экосистему, создав удобную облачную среду для разработчиков и исследователей. 
Источник изображения: GPUnet На веб-сайте GPUnet говорится, что посредством новой платформы клиенты получают доступ к ускорителям NVIDIA. В частности, стоимость аренды H100 составляет $5/час, A100 — $1,5/час, А10 — $1/час. К 2030 году GPUnet рассчитывает объединить в своей экосистеме до 1 млн GPU.
11.04.2024 [17:59], Алексей Степин
Сделано в Европе: Kalray представила ускоритель Turbocard4 для машинного зрения и обработки ИИ-данныхКомпания Kalray объявила о коммерческой доступности новых ускорителей Turbocard4 (TC4). Новинка позиционируется в качестве решения для ускорения работы систем машинного зрения, либо как акселератор «умной» индексации данных. На борту ускорителя, выполненного в формате FHFL установлено сразу четыре чипа DPU Coolidge 2 с фирменной архитектурой Kalray MPPA. Эти процессоры были анонсированы ещё летом прошлого года в качестве энергоэффективных DPU с производительностью до 1,5 Тфлопс в режиме FP32 и 50 Топс в характерном для инференса режиме INT8. 
Источник изображений здесь и далее: Kalray Выбор рынков не случаен: машинное зрение сегодня является быстро растущей отраслью, в 2023 году оцененной в более чем $20 млрд, а к 2032 году эта цифра обещает вырасти до $175 млрд. Про индексацию данных для генеративного ИИ нечего и говорить — на дворе бум подобных технологий, а объёмы наборов данных постоянно растут. Такие датасеты требуют эффективной предобработки, иначе растущее время выборки нужных данных будет сдерживать производительность и обучения, и инференса.  Интересно, что производятся TC4 в Европе, на французской фабрике Asteelflash, уже получившей первый заказ на сумму более $1 млн. В силу перспективности избранных направлений не следует удивляться, что европейская инициатива Kalray и Asteelflash поддержана французским правительством в рамках программы CARAIBE. Уже в 2025 году планируется довести темпы производства ускорителей TC4 с сотен до нескольких тысяч в месяц. 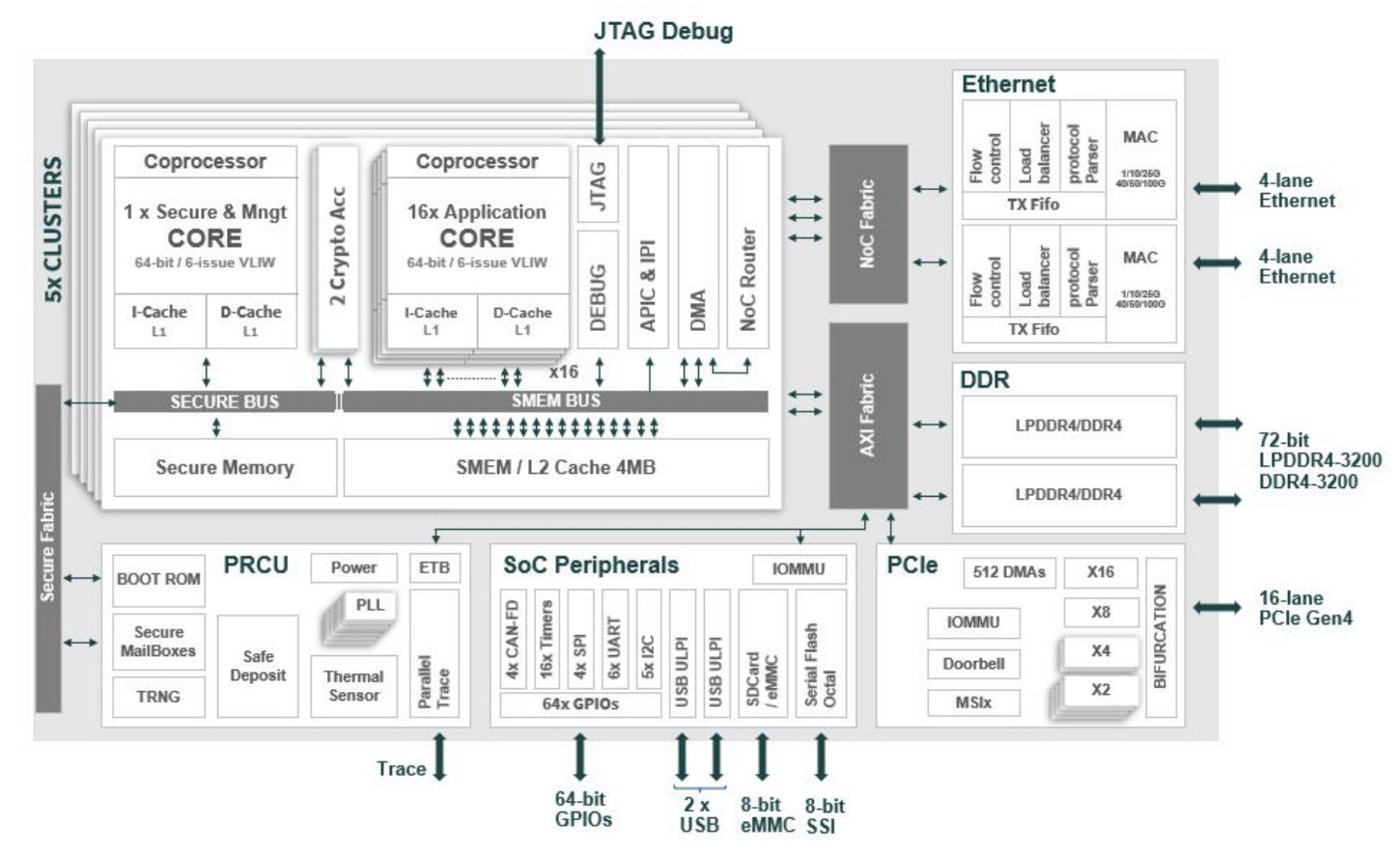 Coolidge 2, по словам создателей, представляет собой универсальное решение на базе архитектуры VLIW. Он имеет 80 ядер с частотой до 1,2 ГГц, причём каждое ядро располагает FPU (IEEE 754-2008). Имеются оптимизации для матричных операций и трансцендентных функций. Процессор разделён на 5 кластеров по 16 ядер, каждый кластер имеет дополнительное управляющее ядро, отвечающее также за функции безопасности. Дополняет Coolidge 2 кеш объёмом 8 Мбайт, двухканальный контроллер памяти DDR4-3200 и пара интерфейсов 100GbE с поддержкой RoCE. Чип поддерживает форматы INT8, FP16, FP32 и даже FP64. Поскольку на борту Turbocard4 работает сразу четыре Coolidge 2, речь идёт о 6 Тфлопс для FP32, 100 Тфлопс для FP16 и 200 Топс для INT8 при теплопакете в районе 120 Вт. Что касается программной поддержки, Kalray сопровождает свои решения SDK, базирующимся на открытых стандартах. Поддерживаются Linux и RTOS.
11.04.2024 [02:16], Владимир Мироненко
Второе поколение ИИ-ускорителей Meta✴ MTIA втрое быстрее первогоКомпания Meta✴ поделилась подробностями о следующем собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator. Новый чип отличается более высокой производительностью по сравнению со чипом MTIA v1, представленным в мае прошлого года, и будет играть решающую роль в обеспечении работы ИИ-моделей Meta✴. Следующее поколение крупномасштабной инфраструктуры Meta✴ рассчитано на поддержку новых продуктов и услуг в области генеративного ИИ, рекомендательных систем и передовых исследований в области ИИ. Создание нового чипа является частью инвестиций в инфраструктуру. В ближайшие годы, как ожидается, затраты в этом направлении будут расти, поскольку требования к вычислительным ресурсам для поддержки моделей будут расти вместе с усложнением последних. 
Источник изображений: Meta✴ Архитектура чипа ориентирована на обеспечение «правильного баланса вычислений, пропускной способности и объёма памяти» даже при относительно небольших размерах обрабатываемых последовательностей. MTIA v2 в сравнении с MTIA v1 в 3,5 раза быстрее в обычных вычислениях и в 7 раз — в разреженных. Новый чип изготавливается по 5-нм техпроцессу TSMC и имеет габариты 25,6 × 16,4 мм (упаковка 40 × 50 мм). Ускоритель работает на частоте 1,35 ГГц, а его TDP составляет 90 Вт, тогда как 7-нм MTIA v1 работал на частоте 800 МГц и имел TDP всего 25 Вт. Готовая стоечная система вмещает до 72 ускорителей и состоит из трёх шасси с 12 платами, на каждой из которых размещено по два ускорителя. Для дальнейшего масштабирования можно добавить RDMA-сеть.  Чип состоит из 64 вычислительных элементов (PE). У каждого PE есть небольшой блок локальной памяти объёмом 384 Кбайт с ПСП 1 Тбайт/с. На весь чип приходится 256 Мбайт SRAM (2,7 Тбайт/с), а внешняя память представлена 128 Гбайт LPDDR5 (204,8 Гбайт/с). Для подключения к хосту используется интерфейс PCIe 5.0 x8 (32 Гбайт/с). При работе с матрицами чип развивает 177 (FP16/BF16) и 354 (INT8) Тфлопс, в разреженных вычислениях — вдвое больше. SIMD-блоки выдают 2,76 Тфлопс для FP32 и 5,53 Тфлопс для INT8/FP16/BF16. В векторных расчётах значения те же, только для INT8 показатель составляет уже 11,06 Тфлопс. 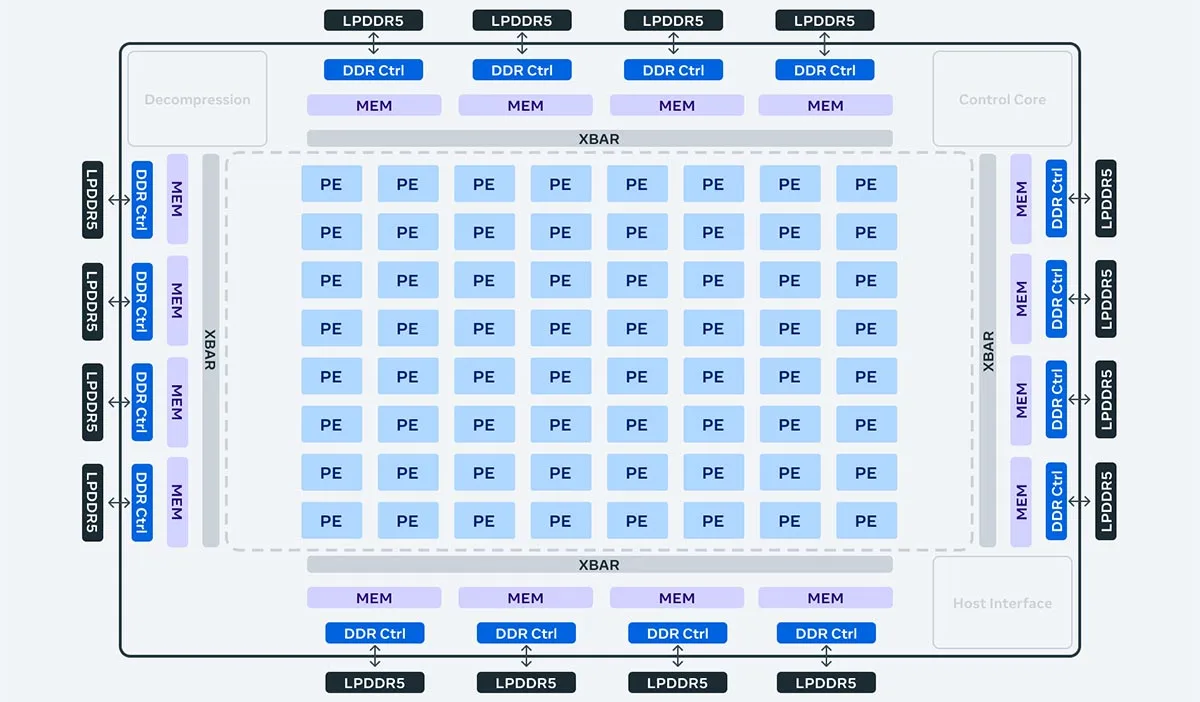 MTIA v2 совместим с кодами, разработанными для MTIA v1. Стек MTIA ориентирован на PyTorch 2.0 и включает компилятор Triton-MTIA. Предварительные испытания MTIA v2 на четырёх ключевых ИИ-моделях компании показали, что он втрое быстрее MTIA v1 чип первого поколения. А на уровне платформы достигнуто шестикратное увеличение пропускной способности модели и рост производительности на Вт в 1,5 раза. Чипы MTIA уже развёрнуты в ЦОД компании. Правда, для обучения Meta✴ их пока не использует.
10.04.2024 [22:45], Алексей Степин
Intel Gaudi3 готов бросить вызов ИИ-ускорителям NVIDIAС момента анонса ускорителей Intel Habana Gaudi2 минуло два года и всё это время они достойно сражались с решениями NVIDIA, хоть и уступая в чистой производительности, но нередко выигрывая по показателю быстродействия в пересчёте на доллар. Теперь пришло время нового поколения — корпорация Intel анонсировала выпуск чипов Gaudi3 и ускорителей на их основе. Новый ИИ-процессор Gaudi3 взял на вооружение 5-нм техпроцесс TSMC, а также получил чиплетную компоновку, которая, впрочем, на логическом уровне никак себя не проявляет — Gaudi3 с точки зрения хоста остаётся монолитным ускорителем. Был увеличен с 96 до 128 Гбайт объём набортной памяти, но это по-прежнему HBM2e в отличие от решений основного соперника, давно перешедшего на HBM3. 
Источник изображений здесь и далее: Intel Intel выступила с достаточно серьёзным заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при существенно меньшей стоимости. Звучит многообещающе, особенно на фоне сочетания высоких цен с дефицитом со стороны «зелёных».  Физически, как уже упоминалось, Gaudi3 состоит из двух одинаковых кристаллов, «сшитых» между собой быстрым низколатентным интерконнектом. Архитектурно чип подобен предшественнику и по-прежнему включает блоки матричной математики (MME) и кластеры программируемых тензорных процессоров (TPC), имеющих доступ к разделу быстрой памяти SRAM.  Однако в сравнении с Gaudi2 количество блоков серьёзно выросло: вместо 2 MME в составе Gaudi3 теперь 8 таких блоков, а число тензорных процессоров увеличилось с 24 до 64. Вдвое, то есть с 48 до 96 Мбайт, вырос объём SRAM, а её пропускная способность возросла с 6,4 Тбайт/с до 12,8 Тбайт/с. Логически Gaudi3 делится на ядра DCORE (Deep Learning Core), в состав каждого входит два движка MME, 16 тензорных ядер и 24 Мбайт кеша L2. 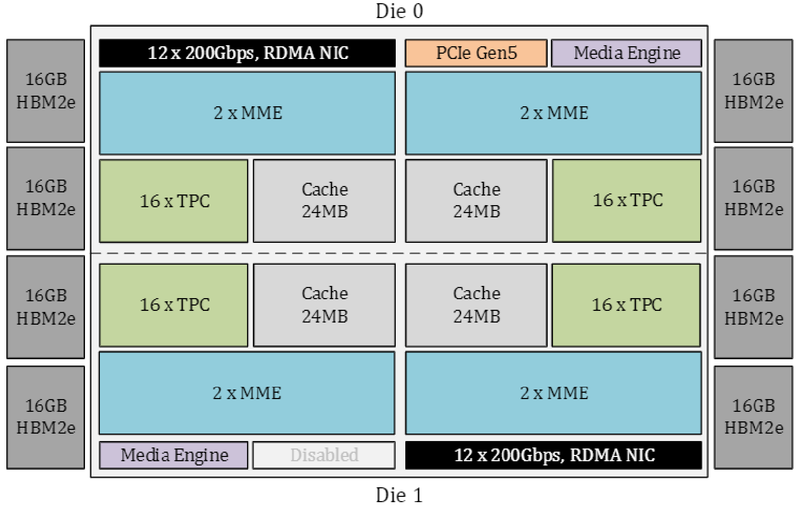
Блок-схема Gaudi3 Усилен также блок медиадвижков, их в новом чипе 14 против 8 у Gaudi2. Всё это не могло не сказаться на тепловыделении: несмотря на применение 5-нм техпроцесса теплопакет у флагманского варианта составляет целых 900 Вт, хотя в новом модельном ряду есть и не столь горячие версии с TDP 600 и 450 Вт. Последний вариант предназначен для экспорта в КНР. 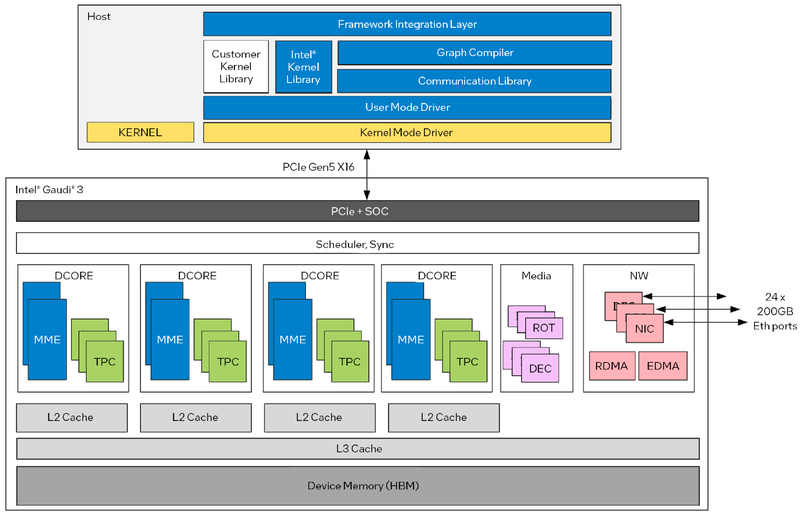
Архитектура Gaudi3 и его программная прослойка Поскольку объём HBM2e был увеличен с 96 до 128 Гбайт, в сборке используется не шесть, а восемь 16-Гбайт кристаллов, что позволило увеличить ПСП с 2,46 до 3,7 Тбайт/с. Работает память на частоте 3,6 ГГц. В составе Gaudi3 также имеется специализированный программируемый блок управления. Он отвечает за формирование очередей, управление прерываниями, синхронизацию, работу планировщика и имеет выход непосредственно на шину PCIe. 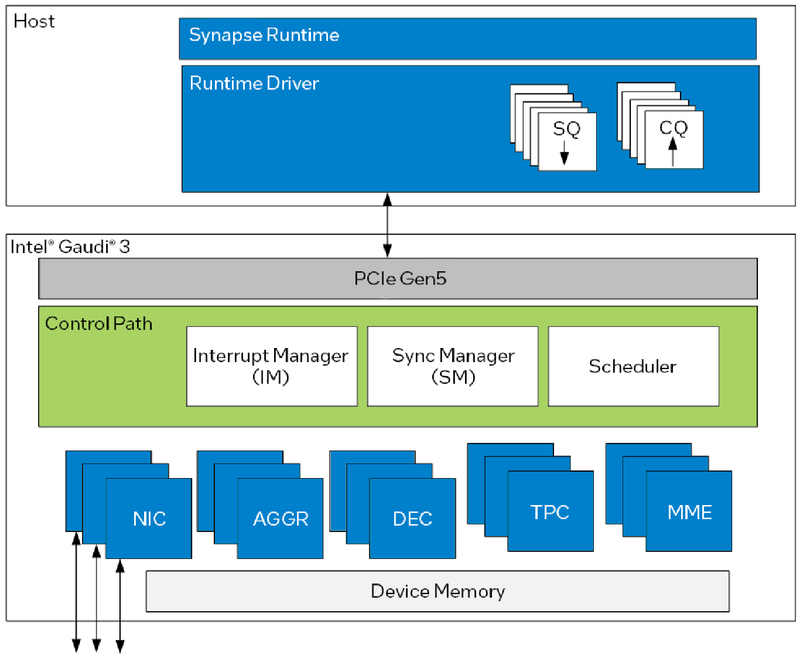
Управляющая подсистема (Control Path) Gaudi3 Сетевая часть всё ещё состоит из 24 контроллеров Ethernet (c RoCE), но появилась поддержка скорости 200 Гбит/с, а значит, вдвое возросла и совокупная производительность сети. Intel подчёркивает, что для масштабирования кластеров на базе Gaudi3 нужна обычная Ethernet-фабрика (а ещё лучше Ultra Ethernet) и нет никакой привязки к конкретному вендору, что является упрёком NVIDIA с её InfiniBand. Наконец, в качестве хост-интерфейса на смену PCI Express 4.0 пришёл PCI Express 5.0 (x16), что также означает подросшую с 64 до 128 Гбайт/с пропускную способность. 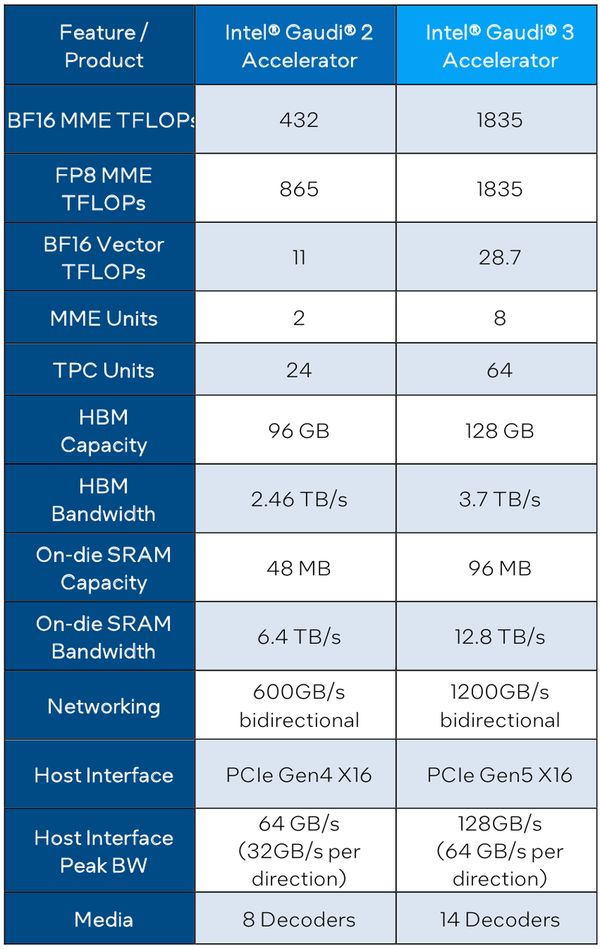
Сравнительные характеристики Gaudi2 и Gaudi3 Все эти улучшения позволяют Intel говорить о теоретической производительности в 2–4 раза более высокой, нежели было достигнуто в поколении Gaudi2. Наибольший прирост заявлен для операций с форматом BF16 на MME, что вполне закономерно, учитывая большее количество самих MME. 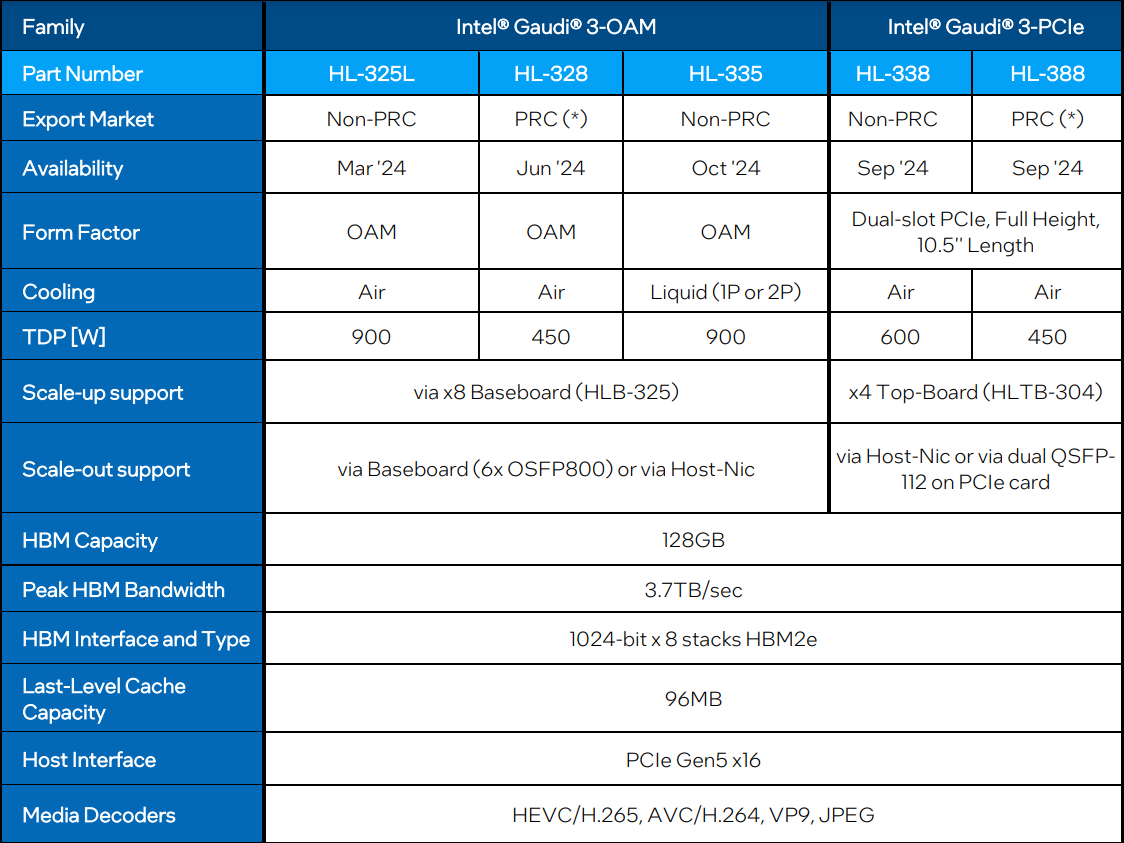 На практике результаты, демонстрируемые Gaudi3, выглядят также достаточно многообещающе: в тестах на обучение популярных нейросетей преимущество над Gaudi2 ни разу не составило менее 1,5x, а в отдельных случаях даже превысило 2,5x. 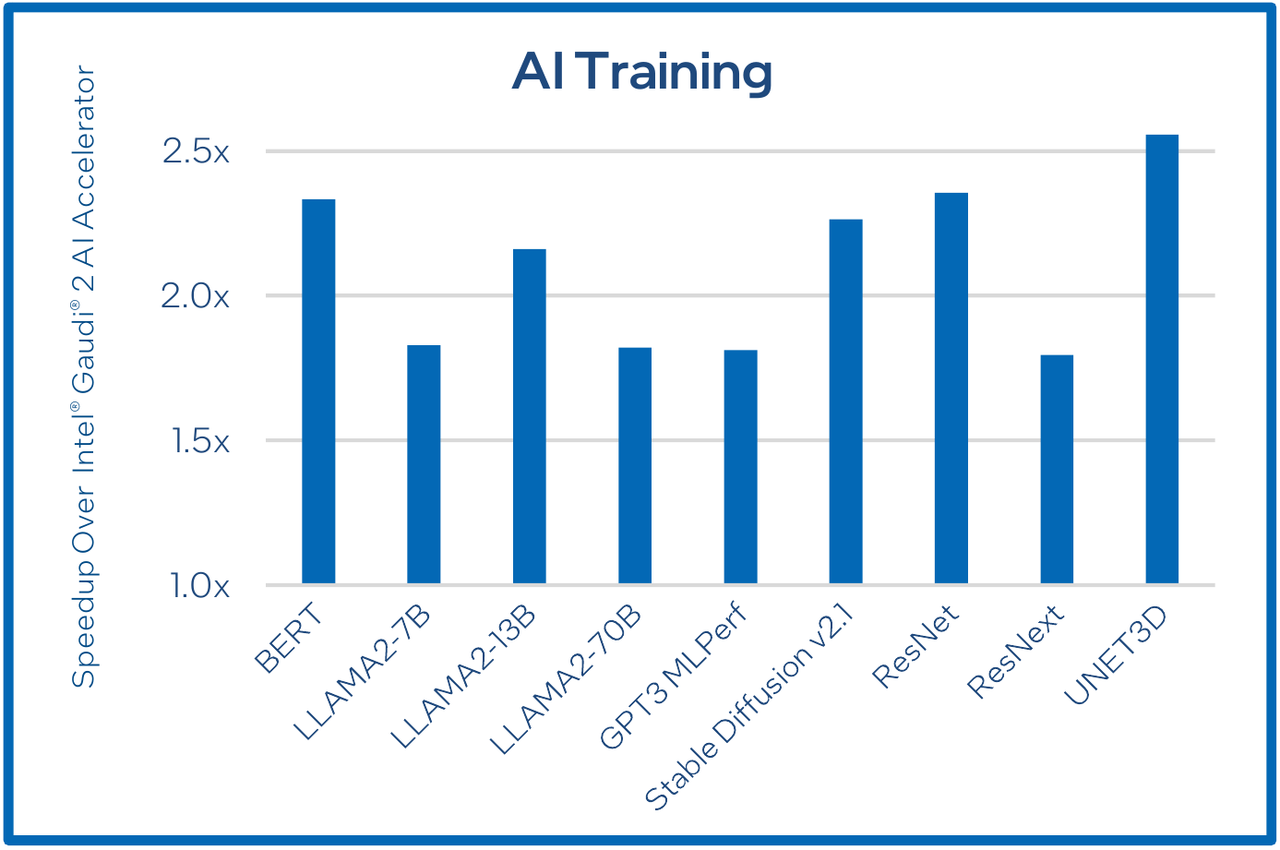 В инференс-тестах отрыв оказался чуть меньше, но и здесь минимальна разница составляет полтора раза. Что немаловажно для инференс-сценариев, серьёзно улучшились показатели латентности. Отчасти это заслуга не только серьёзно подросших «мускул» нового процессора, но и наличие большего объёма HBM, что позволяет разместить в памяти больше параметров и расширить контекстное окно. 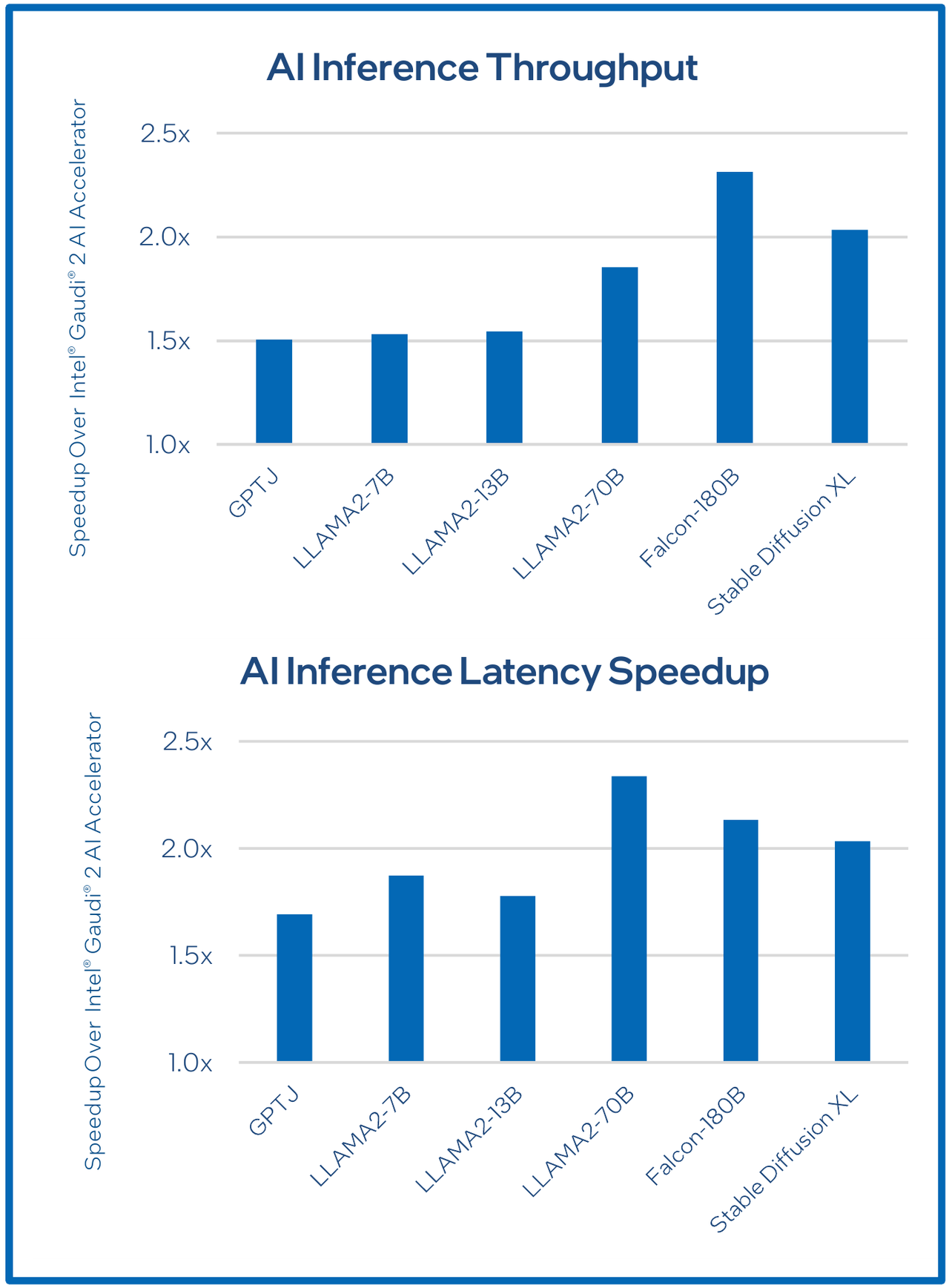 Опубликовала Intel и результаты сравнительного тестирования Gaudi3 против NVIDIA H100 в MLPerf, где новинка действительно выступила весьма достойно, в худшем случае демонстрируя 90% от производительности H100, а в отдельных тестах опережая конкурента более чем в 2,5 раза. Примерно так же распределились результаты и в тестах на энергоэффективность. 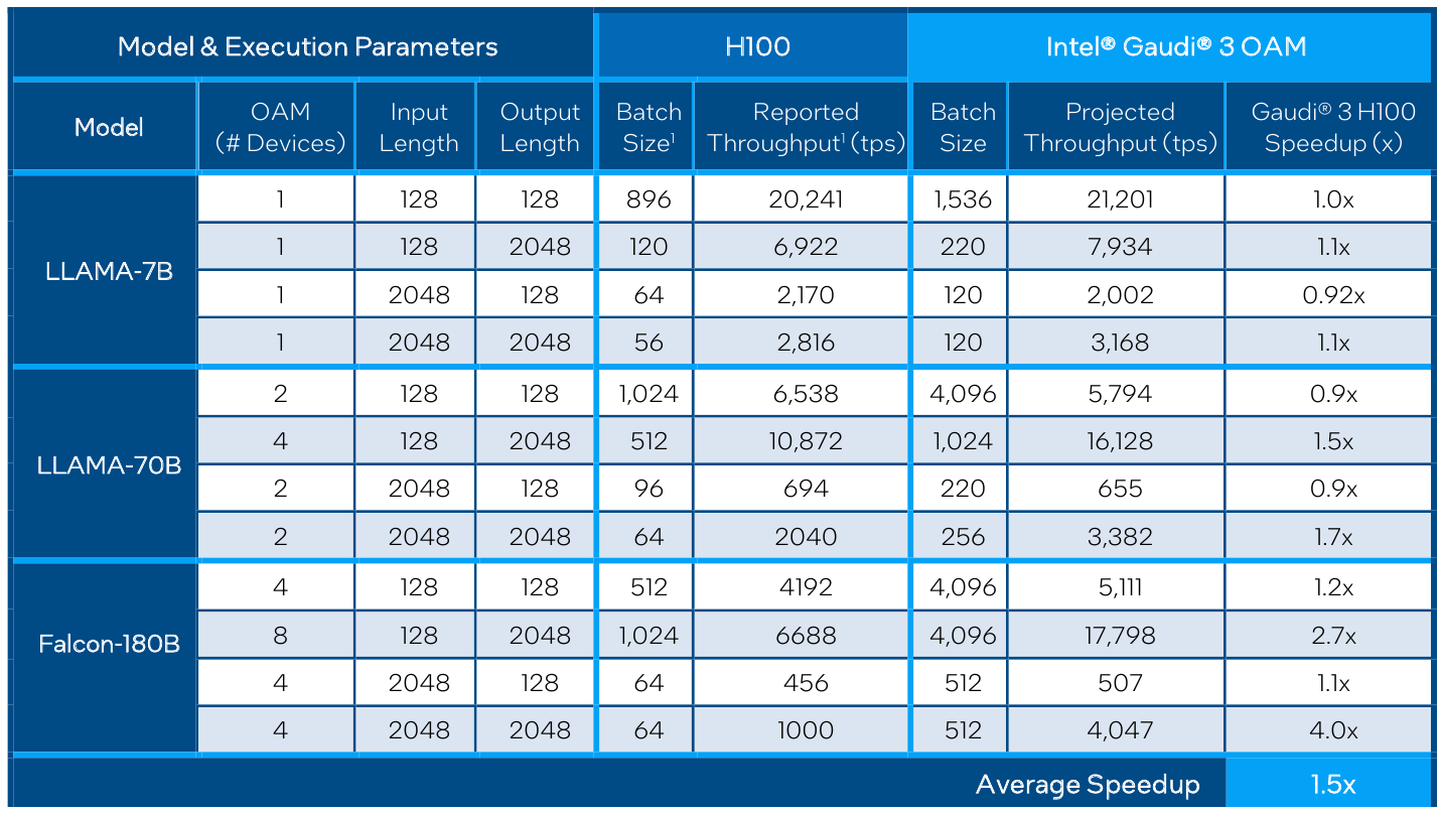 Что же касается инженерно-технической реализации, то на этот раз Intel представила сразу несколько вариантов ускорителей на базе Gaudi3, отличающихся как теплопакетом, так и конструктивом. Самым быстрым вариантом в семействе является модуль HL-325L OCP. Он выполнен в формате мезонинной платы OCP OAM 2.0 и поддерживает теплопакет 900 Вт для воздушного охлаждения и 1200 Вт — для жидкостного. 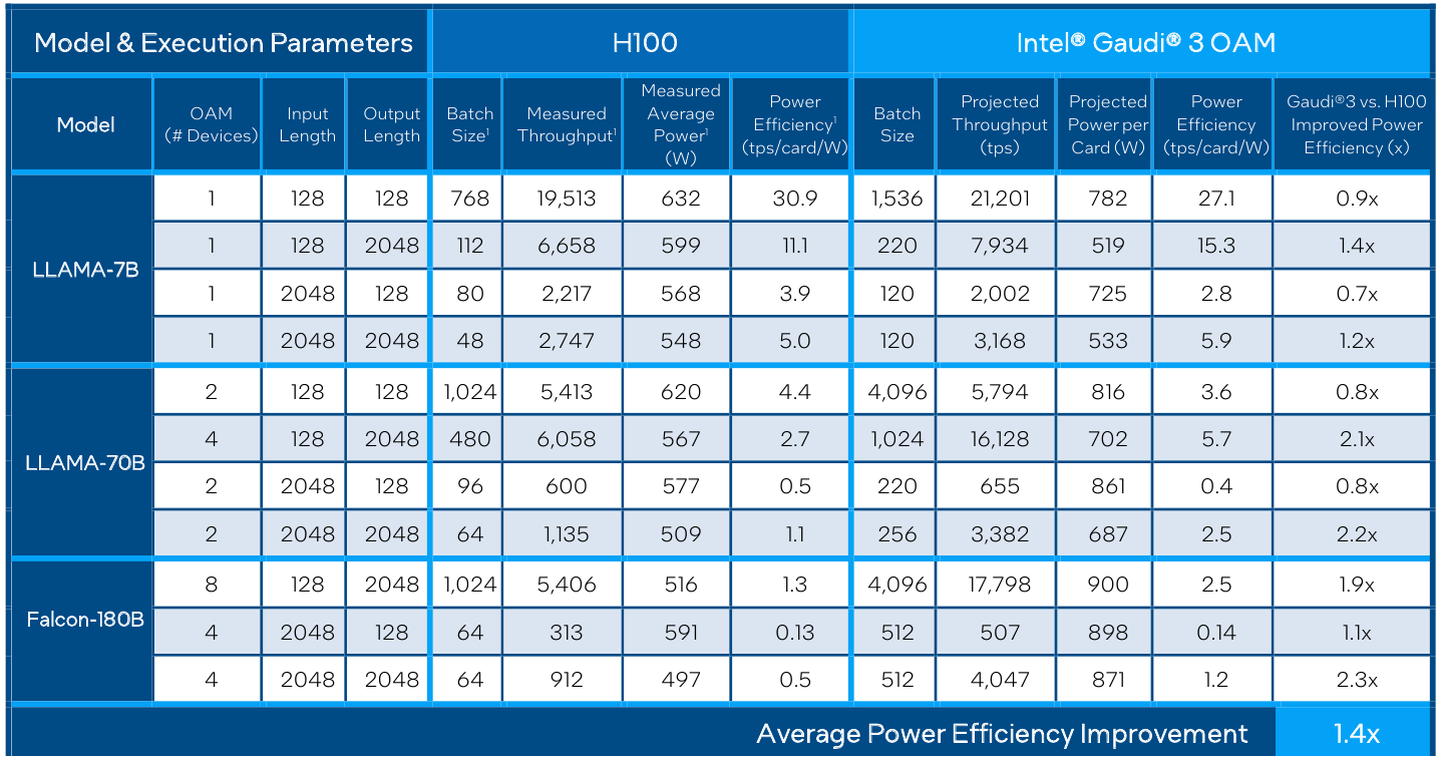 Для этой модели была специально разработана новая UBB-плата HLB-325L, приходящая на смену HLBA-225. Она поддерживает установку восьми ускорителей HL-325L, причём 21 сетевое подключение на каждом из них позволяет реализовать интерконнект по схеме «все со всеми», а оставшиеся подключения сведены через PAM4-ретаймеры в шесть 800GbE-портов OSFP для дальнейшего масштабирования кластера. Имеется и вывод PCI Express 5.0 с помощью PCIe-ретаймеров, также установленных на плате. HLB-325L рассчитана на питание 54 В, которое в последнее время становится всё популярнее в новых ЦОД и HPC-системах. 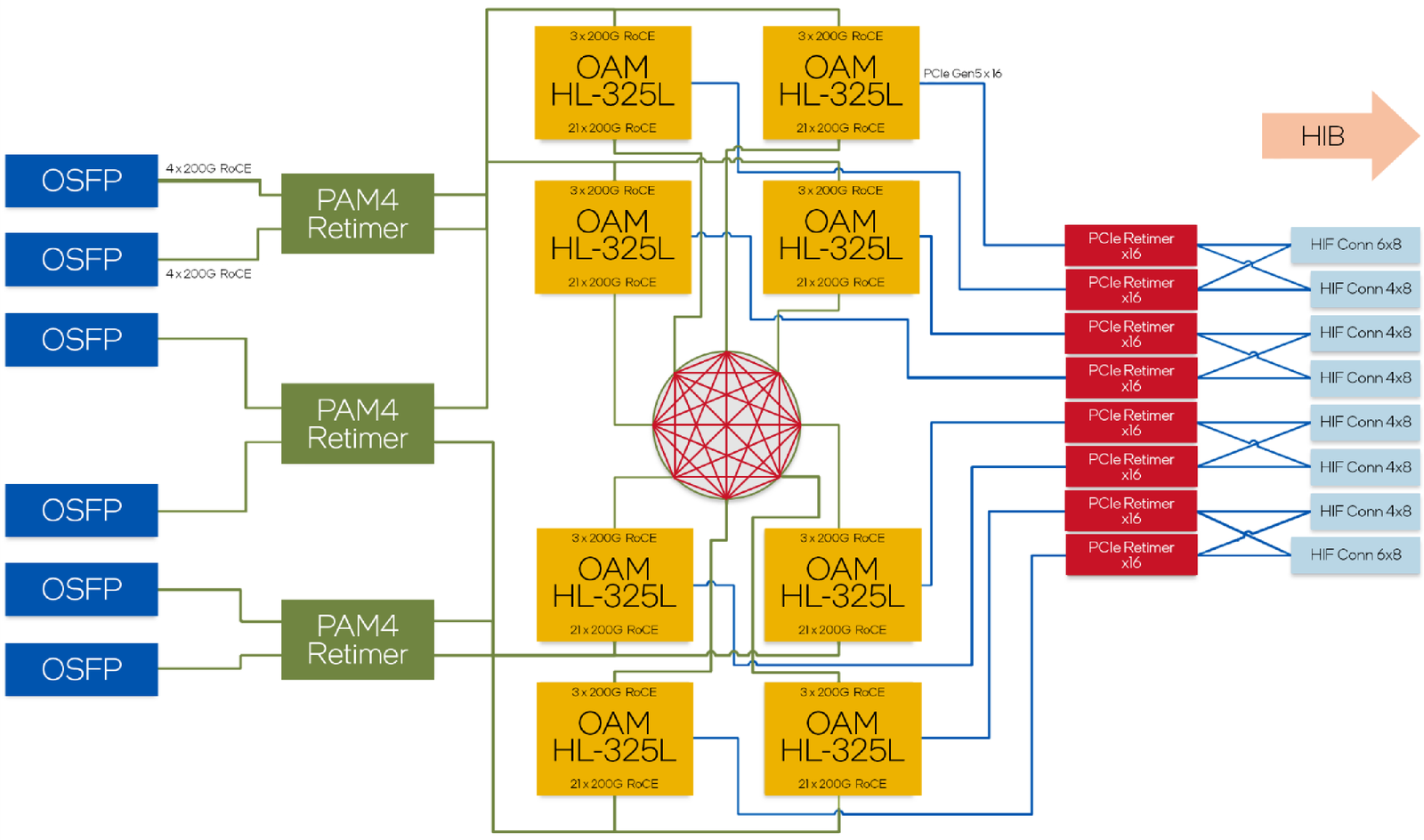
Топология базовой платы HLB-325L с восемью Gaudi3 Другой вариант Gaudi3 — ускоритель HL-338. Он представляет собой стандартную плату расширения PCIe с двумя внешними портами QSFP112 400GbE. Поддерживаются теплопакеты вплоть до 600 Вт при стандартном воздушном охлаждении. Дополнительный мостик HLTB-304, устанавливаемая поверх четырёх ускорителей HL-338, обеспечивает интерконнект за счёт 18 набортных линков 200GbE. Такая реализация кластера на базе Gaudi3 по понятным причинам будет несколько менее производительной, нежели вариант с OAM-модулями, но позволит обойтись стандартными аппаратными средствами и корпусами серверов. 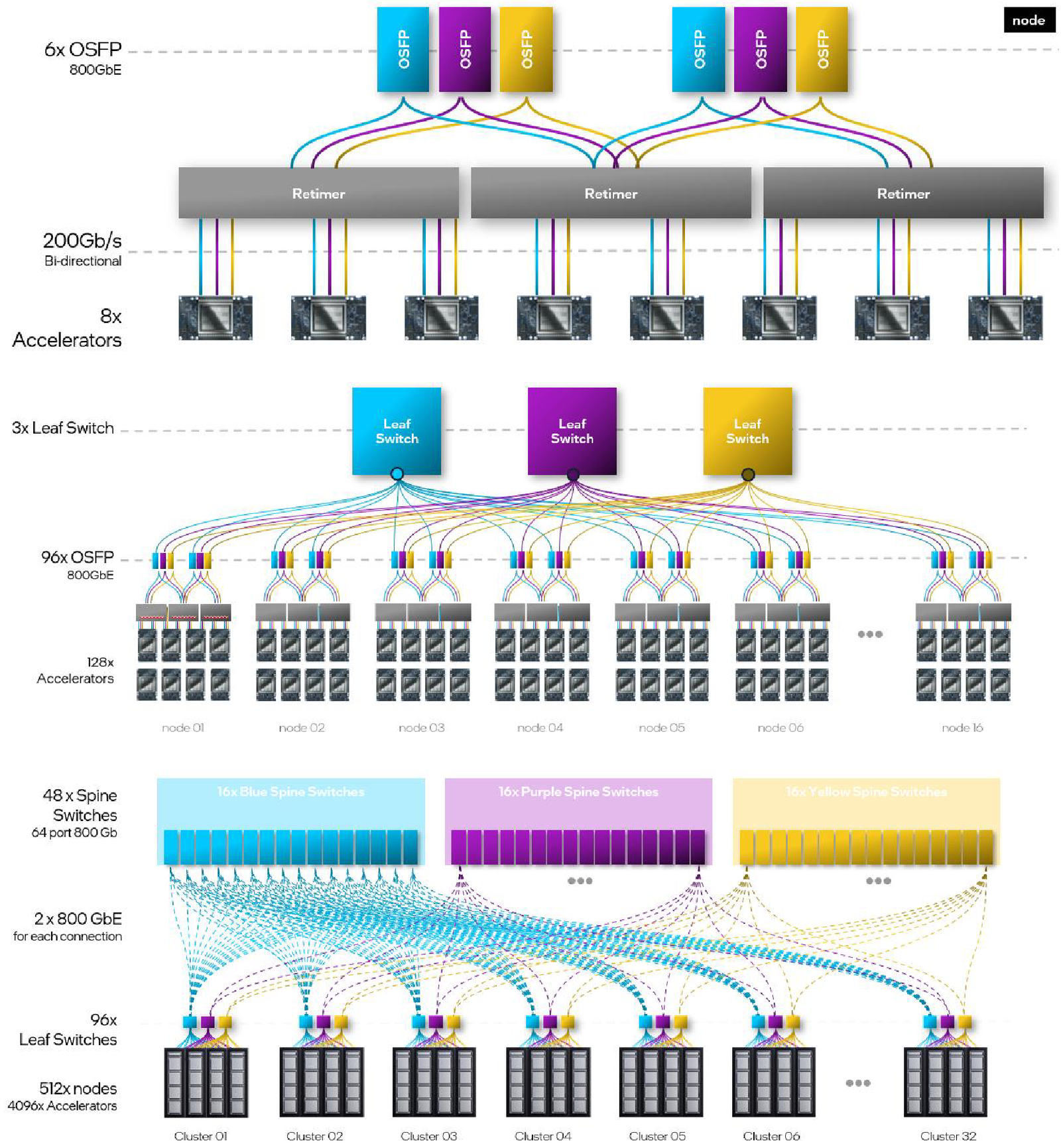
Масштабирование и кластеризация Gaudi3 Первые пробные партии ускорителей на базе Gaudi3 поступят избранным партнёрам Intel уже в этом полугодии. Вариант OAM с воздушным охлаждением уже тестируется в квалификационных лабораториях компании, а образцы с жидкостным охлаждением появятся позднее в этом квартале. В новинке заинтересованы Dell, HPE, Lenovo и Supermicro. Массовые поставки стартуют в III квартале 2024 года. Последними на рынке появятся PCIe-версии, их поставки намечены на IV квартал. 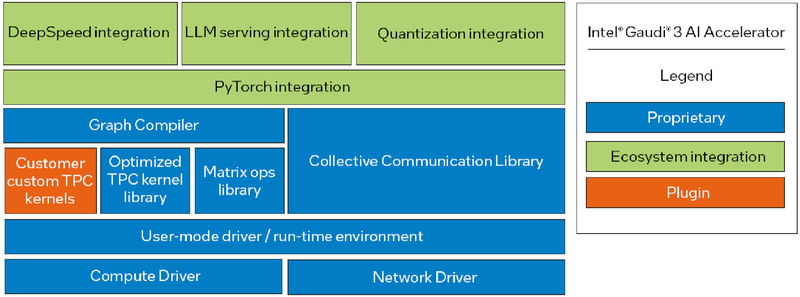
Программная экосистема Intel Gaudi Intel Gaudi3 выглядит весьма неплохо. В нём устранены узкие места, свойственные Gaudi2, что позволяет тягаться на равных с NVIDIA H100 и H200, и даже заметно превосходить их в некоторых сценариях. Однако NVIDIA уже анонсировала архитектуру Blackwell. Впрочем, основная борьба развернётся не на аппаратном, а на программном уровне — Intel вслед за AMD упростила работу с PyTorch, что позволит перенести множество нагрузок на Gaudi. А там, глядишь, и UXL станет хоть какой-то альтернативой CUDA.
08.04.2024 [01:50], Владимир Мироненко
Groq больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисыСтартап Groq, создавший ускоритель LPU на базе собственного массивно-параллельного тензорного процессора TSP, больше не продаёт оборудование, предлагая вместо этого воспользоваться его облачными ИИ-сервисами или стать партнёром в создании ЦОД. Об этом генеральный директор Groq Джонатан Росс (Jonathan Ross) сообщил ресурсу EE Times. Он пояснил, что для стартапа заниматься продажами чипов слишком сложно, потому что «минимальная сумма покупки, чтобы это имело смысл, высока, затраты высоки, и никто не хочет рисковать, покупая большое количество оборудования — неважно, насколько оно потрясающее». По его словам, в облаке GroqCloud для инференса больших языковых моделей (LLM) в реальном времени уже зарегистрировано 70 тыс. разработчиков и запущено более 19 тыс. новых приложений. 
Источник изображений: Groq В случае поступления заказов на поставку больших объёмов чипов для очень крупных систем Groq вместо продажи предлагает партнёрство по развёртыванию ЦОД. Groq подписала соглашение с саудовской государственной нефтяной компанией Aramco, которое предполагает масштабное развёртывание LPU. Похожее соглашение в ОАЭ подписала Cerebras, ещё один молодой разработчик ИИ-ускорителей. «Правительство США и его союзники — единственные, кому мы готовы продавать оборудование, — говорит Росс. — Для всех остальных мы лишь (совместно) создаём коммерческие облака». По его словам, в этом году Groq планирует разместить 42 тыс. LPU в GroqCloud, при этом Aramco и другие партнёры «завершают» свои сделки по получению такого же количества чипов. Компания способна выпустить 220 тыс. LPU только в этом году, а общий объём производства на ближайшее время составляет 1,5 млн ускорителей. Около 1 млн из них всё ещё не зарезверированы, но это количество быстро сокращается. Росс пообещал, что к концу 2025 году компания развернёт столько LPU, что их вычислительная мощность будет эквивалентна ИИ-мощностям всех гиперскейлерам вместе взятых.  Росс с оптимизмом смотрит на перспективы Groq, поскольку чипы TSP не используют память HBM, на которую полагаются решения конкурентов, включая NVIDIA, и поставки которой расписаны до конца 2024 года. Что касается LPU следующего поколения, то компания планирует сразу перейти с 14-нм техпроцесса (Global Foundries) на 4-нм. По словам Росса, новый чип будет оптимизирован для генеративного ИИ, но у него в силу универсальности архитектуры не будет каких-то специальных функций для обработки LLM. Будет ли новый ускоритель всё так же изготавливаться на территории США, не уточняется. Groq, похоже, достаточно уверена в своих чипах, которые в бенчмарках действительно обгоняют конкурентов. После анонса архитектуры NVIDIA Blackwell, обеспечивающей кратное увеличение производительности в задачах генеративного ИИ, компания выпустил в ответ пресс-релиз из одного предложения: «Groq всё ещё быстрее». А чуть позже даже раскритиковала NVIDIA.
07.04.2024 [14:12], Сергей Карасёв
Разработчик ИИ-чипов SiMa.ai получил на развитие ещё $70 млнСтартап SiMa.ai, разрабатывающий аппаратные и программные решения для обработки ИИ-задач на периферии, объявил о проведении раунда финансирования на сумму в $70 млн. Таким образом, в общей сложности компания привлекла на развитие $270 млн. Ключевым продуктом SiMa.ai является изделие Machine Learning System-on-Chip (MLSoC). Оно специально спроектировано с прицелом на периферийные ИИ-приложения. Это могут быть роботы, дроны, системы машинного зрения, автомобильные платформы, медицинское оборудование и пр. В состав MLSoC входит ряд блоков. Это, в частности, ИИ-ускоритель с 25 Мбайт интегрированной памяти, обеспечивающий производительность до 50 TOPS (INT8) или 10 TOPS/Вт. Он дополнен процессором приложений на базе четырёх вычислительных ядер Arm Cortex-A65 с частотой 1,15 ГГц. Присутствует четырёхъядерный узел компьютерного зрения Synopsys ARC EV74. Изделие также несёт на борту блоки (де-)кодирования видео в формате H.264. Реализована поддержка четырёх портов 1GbE, интерфейсов PCIe 4.0 х8, SPIO, I2C и GPIO. 
Источник изображения: SiMa.ai Чип MLSoC доступен в составе платы для разработчиков. Компания также предоставляет специализированный набор инструментов под названием Pallet, упрощающий создание ПО для чипа. Этот комплект включает, в частности, компилятор, который преобразует модели ИИ в формат, оптимизированный для работы в системах на основе MLSoC. Сообщается, что раунд финансирования на $70 млн проведён под руководством Maverick Capital. В нём также приняли участие Point72, Jericho, Amplify Partners, Dell Technologies Capital, предприниматель Лип-Бу Тан (Lip-Bu Tan) и др. Полученные средства пойдут на разработку 6-нм чипа MLSoC второго поколения, который будет выпущен на TSMC в I квартале 2025 года. Известно, что это решение объединит CPU на базе Arm Cortex-A и модуль компьютерного зрения Synopsys EV74. |
|

