Материалы по тегу: hardware
|
23.04.2026 [09:40], Руслан Авдеев
Как на Татуине: индийская Uravu будет добывать питьевую воду из воздуха с помощью «мусорного» тепла ЦОДИндийский стартап Uravu предложил систему, в которой соль является ключевым ингредиентом, способствующим эффективному охлаждению серверных стоек. Более того, метод позволяет получать воду непосредственно из тёплого воздуха, проходящего через системы охлаждения ЦОД, сообщает Datacenter Dynamics. Основанный в 2012 году стартап Uravu предложил добавить в контур охлаждения влагопоглотитель на основе солёной воды — благодаря этому можно будет извлекать воду из «отработанного» тёплого воздуха. Потом её можно повторно использовать для охлаждения оборудования, а излишки воды можно даже продавать. Разработчики явно вдохновлялись решениями с пустынной планеты Татуин, показанной во франшизе «Звёздные войны» — там вода тоже добывалась непосредственно из воздуха. Поэтому и свою установку они назвали Tatooine. Tatooine использует низкотемпературное (+35–65 °C) избыточное тепло, отдаваемое системами охлаждения. Модуль-абсорбент (поглотитель) забирает тёплый воздух, из части которого извлекается вода. Другая часть вступает в контакт с поглотителем на основе солёной воды, участвуя в процессах тепло- и массообмена. После солевой раствор передаётся в десорбер, где выделяет влагу в виде пара при помощи вакуумного насоса. Сконденсированная вода имеет на выход температуру +27–32 °C, что соответствует верхней границе рекомендаций ASHRAE. Гиперскейлеры допускают работу серверов и при таких температурах. 
Источник изображения: Uravu Абсорбент Uravu начинает отбирать избыточное тепло при разнице с температурой окружающей среды в +4 °C. По оценке самой компании, Tatooine во многих сценариях позволят вообще не использовать традиционные чиллеры или драйкулеры, а на 1 МВт мощности ЦОД система способна отдавать до 30 м3/сут. чистой дистиллированной воды. Показатель может колебаться в зависимости от условий окружающей среды и уровня влажности, но как минимум 5 м3/сут. готовой для питья или других нужд воды она будет давать. Использование отработанного тепла позволяет улучшить показатели энергетической эффективности (PUE) и эффективности использования воды (WUE) дата-центров. Последний и вовсе достигает отрицательных значений — вода не просто восстанавливается, а извлекается в избытке, поэтому её можно продавать близлежащим потребителям. Уже сегодня Uravu имеет партнёрские соглашения с предприятиями других секторов, поставляя им «воду из воздуха». В частности, одна из её систем используется для производства бутилированной воды в Бангалоре, хотя и в скромных объёмах (всё те же 5 м3 /сут.). Компания начала взаимодействовать с участниками OCP и разработала 125-кВт демо-систему, подходящую для небольших и пилотных проектов. Следующая цель — блок на 1 МВт, с прицелом на создание модульного решения и стандартизацию производства. Разработка начнётся в 2026 году, условия проекта согласованы с неким «крупным провайдером». Также ведутся переговоры с пятью другими компаниями, занимающимися цифровой инфраструктурой. От венчурных фондов Uravu привлекла $4,7 млн и намерена инициировать раунд финансирования серии A до конца текущего года. 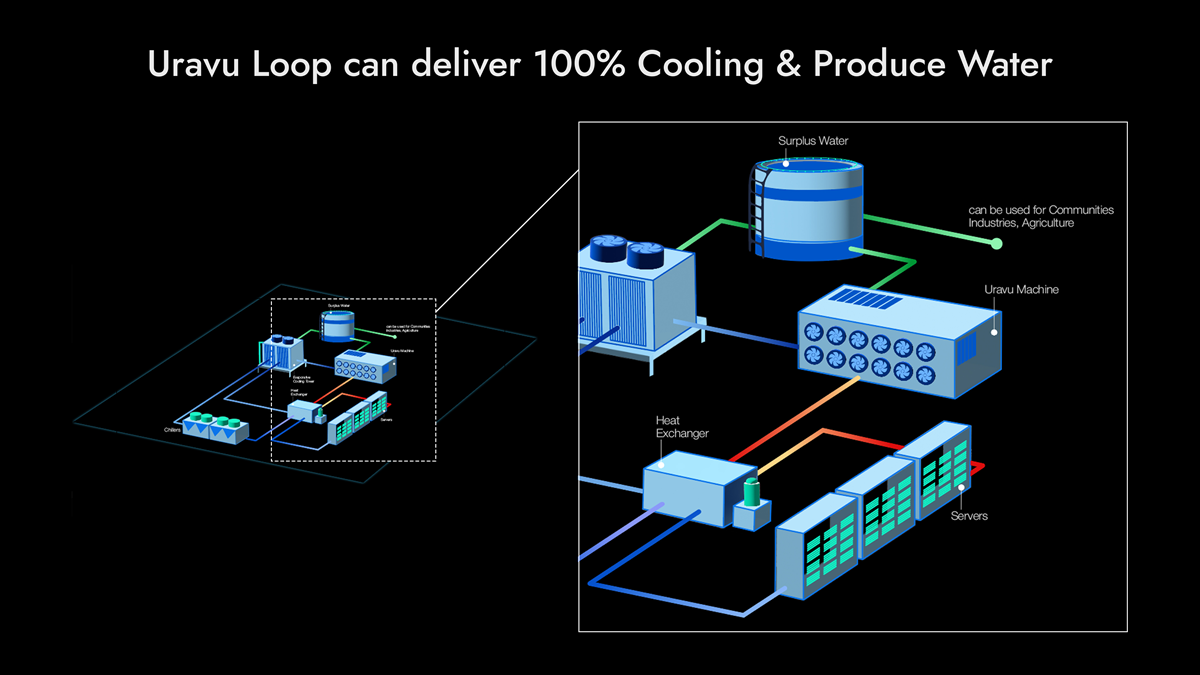
Источник изображения: Uravu Это не первые решения, использующие тепло ЦОД и сопутствующую воду. Так, в 2025 году появилась новость, что AirJoule разработала технологию «превращения» тепла дата-центров в дистиллированную воду, а в Нью-Йоркском университете (NYU) разработали необычную систему охлаждения на основе минералов. Благодаря им выделяемое на заводах тепло можно использовать для охлаждения дата-центров. Дефицит воды является большой проблемой для многих стран. В Индии проживают 18 % населения Земли, но на неё приходится лишь 4 % мировых водных ресурсов. По оценкам Всемирного банка, 600 млн жителей страны живут в районах, где воды не хватает, а, тем временем, потребление воды в стране к 2030 году может удвоиться, что только усугубит проблему. При этом ЦОД участвуют в конкуренции за воду наравне с людьми.
23.04.2026 [09:09], Руслан Авдеев
Войн нет, энергии хватает, народ дружелюбный: Scala Data Centers призвала присмотреться к ИИ ЦОД в БразилииБразилия стремится привлечь инвестиции ИИ-бизнесов, полагаясь на геополитические преимущества региона. В частности, местный строитель ЦОД Scala Data Centers предлагает свои объекты иностранным бизнесам, в первую очередь из США и Китая, сообщает Datacenter Knowledge. В конце 2026 года должно начаться строительство т.н. Scala AI City, проект уже одобрен властями. Поддерживаемая DigitalBridge Group компания начала переговоры с техногигантами из США и КНР, желая привлечь в «ИИ-суперкампус» размером с город крупного клиента. Как утверждает Scala, нестабильность на Ближнем Востоке подчёркивает привлекательность бразильского рынка, изолированного от зон крупных конфликтов. По данным Scala, первый этап строительства обойдётся приблизительно в $500 млн, которые пойдёт непосредственно на инфраструктуру. В несколько раз больше потратит сам арендатор — облачный провайдер на ИИ-оборудование. Предполагается, что американские и китайские провайдеры могли бы использовать в Scala AI City отдельные ЦОД, не рискуя безопасностью своих данных. Компания уже получила разрешение на получение до 5 ГВт электроэнергии в окрестностях Порту-Алегри (Porto Alegre) в штате Риу-Гранди-ду-Сул — приблизительно столько потребляет Сан-Паулу или Лондон. 
Источник изображения: Scala Data Centers Наличие в Южной Америке многочисленных возобновляемых источников энергии и оптоволоконных магистралей, а также энергосеть с многочисленными перекрёстными подключениями делают Бразилию оптимальным региональным игроком в контексте бума ИИ ЦОД. Удары беспилотников по дата-центрам в ОАЭ и Бахрейне в целом заставляют компании переосмысливать принципы размещения в мире критической инфраструктуры. Власти штатов и муниципалитетов Бразилии всеми силами стремятся привлечь инвестиции в ЦОД, это должно стимулировать местную экономику и способствовать созданию технологических центров. Для сравнения, во многих штатах США бизнес и политики сталкиваются с недовольством общественности — иногда доходит до стрельбы и изгнания чиновников. Scala Data Centers была сформирована DigitalBridge в 2020 году после покупки ЦОД-активов у бразильской UOL Diveo. Японская SoftBank Group купила DigitalBridge приблизительно за $4 млрд в 2025 году. В текущем году компания планирует расширить и другие проекты ЦОД в Бразилии. Так, кампус в Сан-Паулу, куда уже инвестировано порядка R$12 млрд ($2,4 млрд), будет расширен до 600 МВт.
23.04.2026 [01:20], Владимир Мироненко
Для обучения и инференса — Google анонсировала ИИ-ускорители TPU 8t и TPU 8iGoogle представила два TPU восьмого поколения: TPU 8t для обучения ИИ и TPU 8i для ИИ-инференса. Компания и раньше экспериментировала с различными вариантами TPU, в частности, со своими чипами пятого поколения V5p и V5e, но последние поколения, такие как Trillium и Ironwood, в основном следовали единому подходу. По словам Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога Google по ИИ и инфраструктуре, TPU 8t и TPU 8i — результат десятилетней разработки (первые TPU были анонсированы в мае 2016 г.), специально созданные для обеспечения работы суперкомпьютеров следующего поколения с высокой эффективностью и масштабируемостью. Вахдат описывает TPU 8t как «мощную платформу для обучения», созданную для «сокращения цикла разработки моделей с месяцев до недель». Она предлагает в 2,8 раза лучшее соотношение цены и производительности, чем предыдущее поколение. 
Источник изображений: Google В TPU 8t используются векторные, матричные и SparseCore-ядра, дополненные 128 Мбайт SRAM и 216 Гбайт HBM (6,5 Тбайт/с). FP4-производительность составляет до 12,6 Пфлопс. Для вертикального масштабирования используется межчиповый интерконнект (ICI) со скоростью 19,2 Тбит/с (в каждую сторону), для горизонтального — 400 Гбит/с. Кластер с TPU 8t может масштабироваться до 9,6 тыс. чипов, предлагая 2 Пбайт памяти HBM, 121 Эфлопс и вдвое большую межчиповую пропускную способность по сравнению с Ironwood, позволяя самым сложным моделям использовать единый, огромный пул памяти. 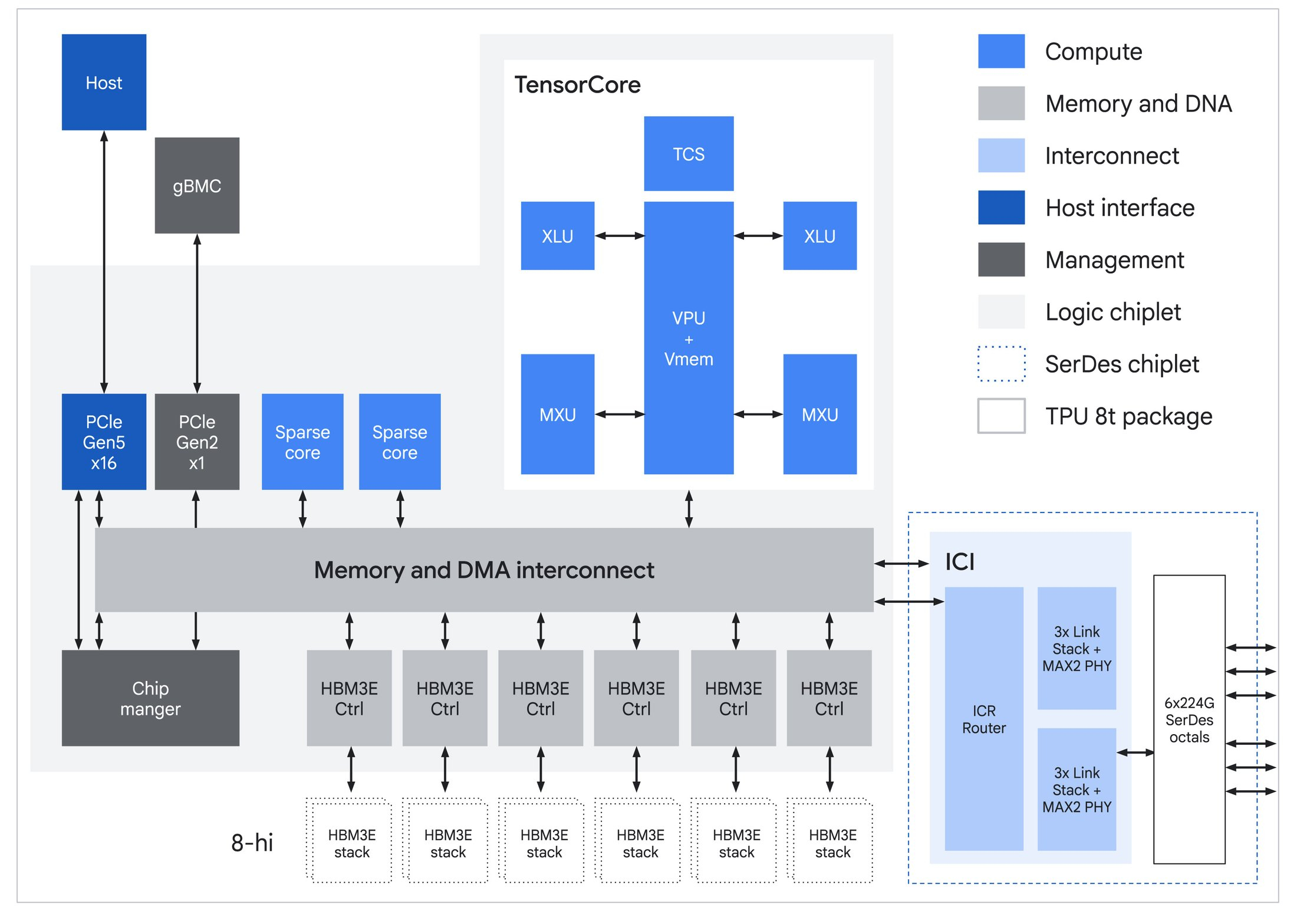 8t-кластеры объдиняет сеть Virgo Network, которая использует плоскую двухуровневую неблокирующую топологию, обеспечивает четырёхкратное увеличение пропускной способности в ЦОД и построена на коммутаторах с высокой степенью защиты, что сокращает количество сетевых уровней. В рамках одного ЦОД Virgo Network позволяет объединить до 134 тыс. чипов, что даёт до 47 Пбит/с неблокирующих соединений и более 1,6 Ифлопс с почти линейным масштабированием. А в рамках нескольких ЦОД в единый кластер можно объединить более 1 млн TPU. 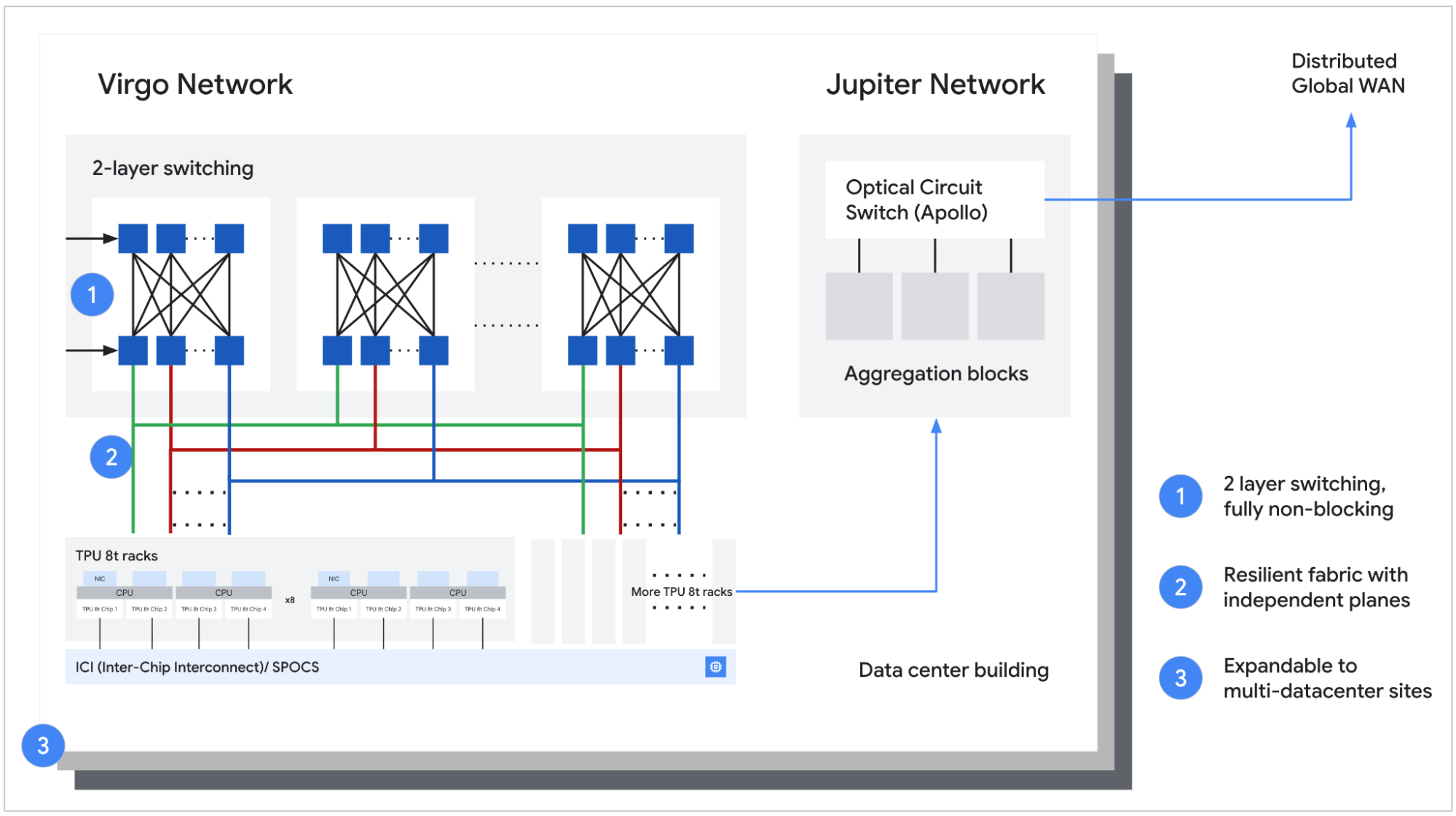 В TPU 8t используются технологии TPUDirect RDMA и TPUDirect Storage. TPU Direct RDMA обеспечивает прямую передачу данных между HBM и NIC, минуя CPU и DRAM хоста, а TPUDirect Storage напрямую связывает память TPU и СХД, таким как 10T Lustre, которая обеспечивает до 10 Тбайт/с, что даёт на порядок более быстрый доступ к хранилищу в сравнении с Ironwood и позволяет доставлять петабайты данных к ускорителям. 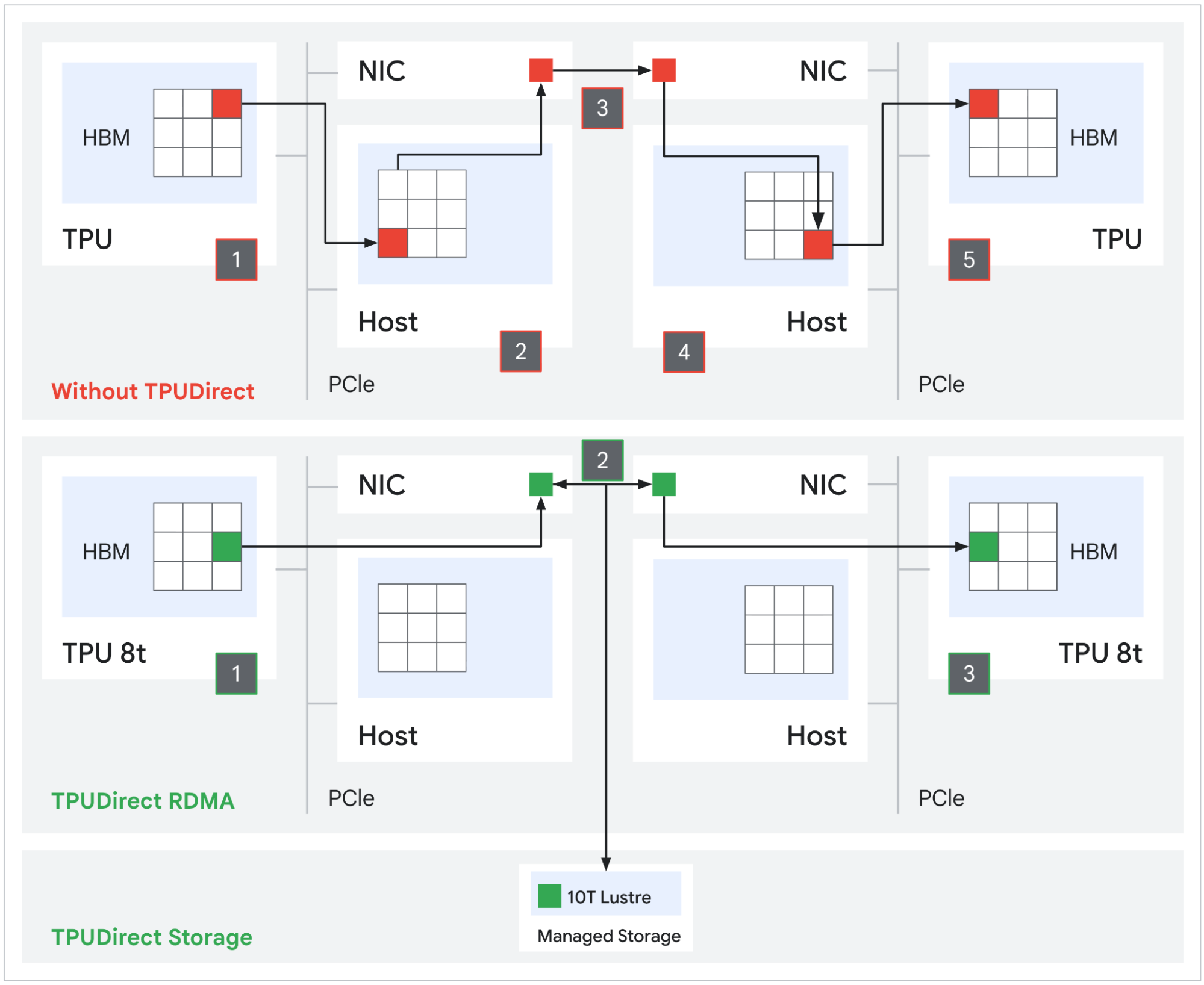 Кроме того, TPU 8t получили расширенные возможности RAS. К ним относятся телеметрия в реальном времени для десятков тысяч чипов, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека. Всё это позволяет довести уровень утилизации чипа до 97 %.  В свою очередь, TPU 8i создан для обработки «сложной, совместной, итеративной работы множества специализированных агентов», которые появляются с развитием агентного ИИ. TPU 8i использует 288 Гбайт памяти HBM (8,6 Тбайт/с) в паре с 384 Мбайт SRAM — втрое больше, чем в предыдущем поколении. По словам Google, такой объём SRAM помогает TPU 8i удерживать большую часть KV-кеша на кристалле, что значительно сокращает время простоя ядер во время декодирования длинных контекстов. Компания отказалась от SparseCores в пользу нового встроенного механизма ускорения коллективных операций (CAE), снижая задержки на уровне кристалла и разгружая коллективные коммуникации, которые в противном случае привели бы к простою тензорных ядер чипа, отметил The Register. 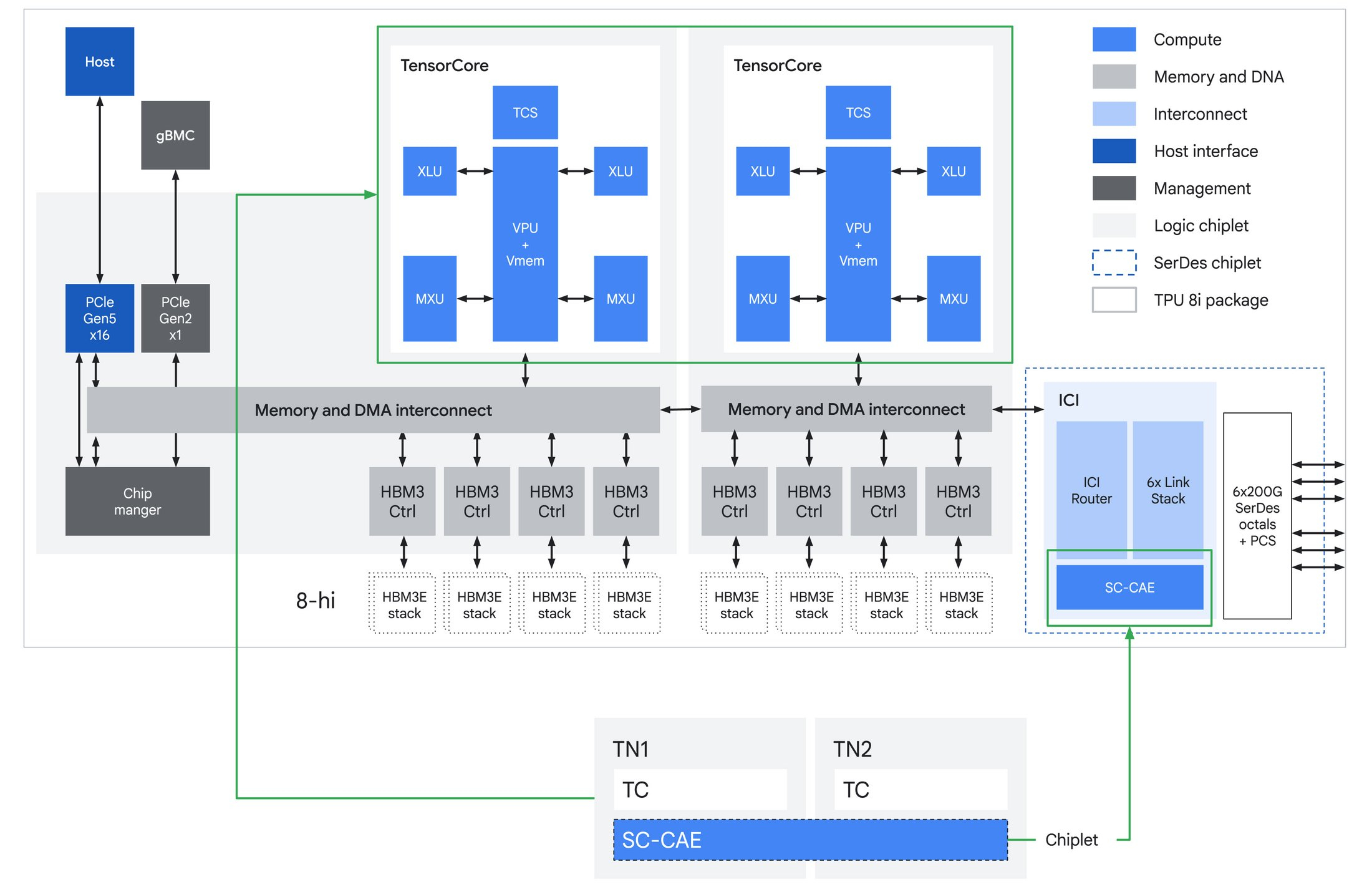 TPU 8i масштабируется до 1152 чипов в одном кластере (впрочем, в каждый момент активно не более 1024): 11,6 Эфлопс и 331,8 Тбайт HBM. ICI у 8i такой же, что у 8t, однако для объединения чипов используется топология Boardfly вместо 3D-тора, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами. Эти инновации обеспечивают на 80 % лучшую производительность на доллар по сравнению с предыдущим поколением, позволяя предприятиям обслуживать почти вдвое больше клиентов при тех же затратах, сообщила компания. 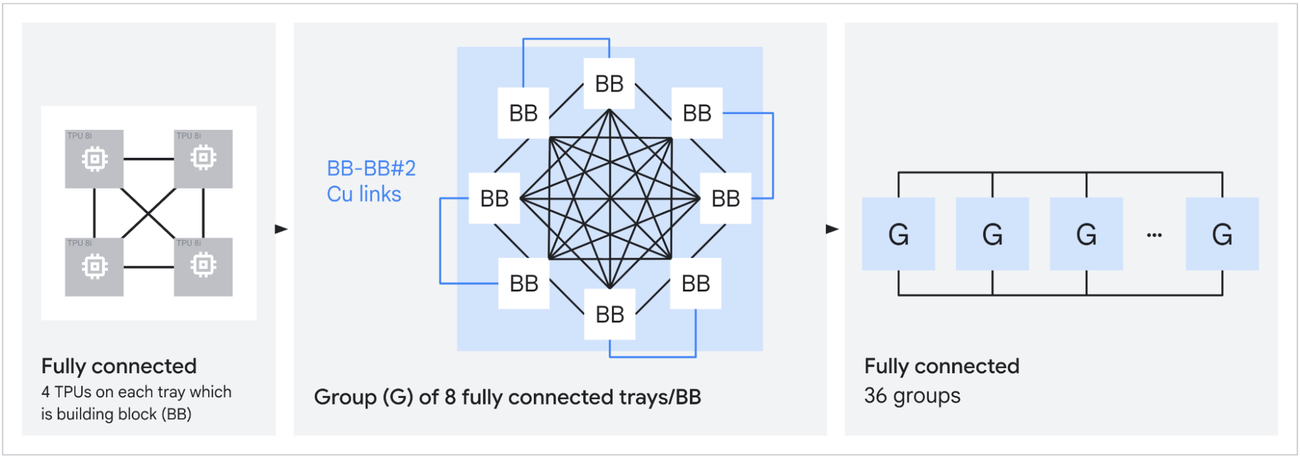 Как TPU 8t, так и 8i работают на базе собственного Arm-процессора Axion и поддерживают СЖО. Компания также заявила, что оптимизировала эффективность всей системы для обеспечения интегрированного управления питанием, которое может регулировать потребление энергии в зависимости от спроса в реальном времени, что приводит к повышению производительности на ватт до двух раз по сравнению с Ironwood. 
Фото: Sundar Pichai TPU 8 станут общедоступными на Google Cloud Platform позже в этом году в виде отдельных инстансов или как часть полнофункциональной платформы AI Hypercomputer, которая объединяет все сетевые ресурсы, хранилище, вычислительные мощности и ПО, необходимые для развёртывания или обучения LLM в масштабе. 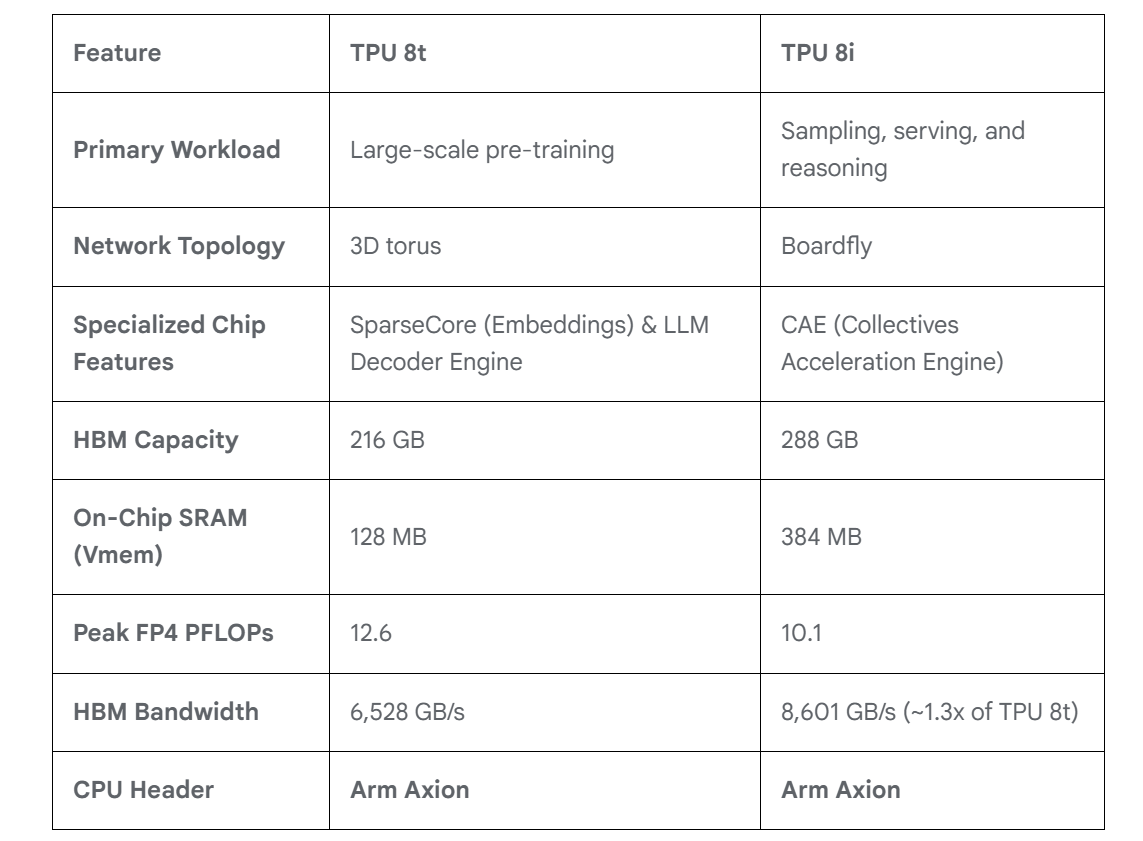
22.04.2026 [18:44], Руслан Авдеев
Meta✴ подала заявку на расширение кампуса в Эль-Пасо и анонсировала 28-й по счёту дата-центр в США — в ТалсеКомпания Meta✴ подала заявку на строительство 12 новых зданий дата-центров на территории кампуса в Эль-Пасо (El Paso, Техас). В поданном властям штата заявлении дочерняя структура Wurldwide LLC сообщила, что намерена построить новые объекты в рамках проекта Seafox, сообщает Datacenter Dynamics. Кампус стал третьей площадкой Meta✴ в Техасе. У компании уже есть ЦОД в Форт-Уэрте и Темпле. Кроме того, компания управляет недалеко расположенными площадками в Лос-Лунасе (Нью-Мексико) и Месе (Аризона). Помимо зданий ЦОД Meta✴ рассчитывает возвести пять новых собственных подстанций и освоить более 242 га. Общая площадь зданий составит 2,4 млн м2. Проектированием занимается компания Stantec. Работы стартовали в ноябре 2025 года и будут завершены к февралю 2029-го. Прямо Meta✴ в документах не упоминается, но о её связи с Wurldwide известно с конца 2023 года, когда появились данные о планах построить кампус на 404 га в Эль-Пасо. Предполагалось, что строить объект будут в пять этапов, в первый рассчитывали вложить $800 млн. Формально кампус в Эль-Пасо с проектной мощностью 1 ГВт был анонсирован в октябре 2025 года Meta✴. Тогда же вероятный объём первоначальных вложений увеличился до $1,5 млрд. Ранее предполагалось, что на первом этапе построят здания ЦОД площадью более 74 тыс. м2, всего — более 371 тыс. м2. Но теперь планы стали более амбициозными, и Meta✴ пообещала увеличить инвестиции в кампус ЦОД в Техасе до $10 млрд. 
Источник изображения: Meta✴ Кампус будет частично запитан от 813 модульных газовых генераторов, ввести в эксплуатацию которые планируют в 2027 году. Их совокупная мощность составит 366 МВт, стоимость — $473 млн. Meta✴ рассчитывает, что кампус будет поддерживать и традиционные серверы, и ИИ-оборудование будущего. Кампус будет полагаться преимущественно на замкнутую систему жидкостного охлаждения и не будет потреблять питьевую воду «большую часть года». Ранее на этом месте в Эль-Пасо планировалось построить неназванное производство. Кроме того, на днях появилась информация о строительстве нового кампуса в Талсе (Оклахома). Это 28-й ЦОД компании в США и 32-й — в мире. Новый кампус ЦОД обеспечит около 100 постоянных рабочих мест. Meta✴ обещает поддержать местных жителей, инвестировав $25 млн в улучшение местной инфраструктуры. Компания будет сотрудничать с местной системой подготовки кадров, поможет местным малообеспеченным с оплатой счетов за электроэнергию и воду и др. Общие инвестиции в регион до завершения строительства превысят $1 млрд.
22.04.2026 [15:37], Руслан Авдеев
Anthropic ищет аналитика для оценки геополитических рисков и угроз персоналу, офисам и дата-центрамКомпания Anthropic ищет «аналитика в области геополитической разведке» (Geopolitical Intelligence Analyst), готового оценивать риски для её сотрудников и бизнес-процессов со стороны государств, сообщает Datacenter Dynamics. Специалист войдёт в состав глобальной команды компании, занимающейся вопросами безопасности, разведки и защиты. Предполагается, что аналитик станет «проводить сбор и анализ развединформации из всех источников» — для выявления, оценки и выстраивания приоритетов в сфере геополитических рисков и угроз со стороны государственных структур «для компании Anthropic, её персонала и деятельности». В том числе речь идёт о поиске возникающих очагов напряжённости геополитического уровня, политических изменений и макро-трендов, способных повлиять на работу Anthropic или стратегическое позиционирование компании. Согласно тексту вакансии, предполагается подготовка аналитики для руководства Anthropic, от срочных сводок до стратегических оценок регионов и стран. Предусмотрен учёт международной обстановки при принятии компанией решений, мониторинг потенциальных кризисов, политических изменений и глобальных тенденций. Необходима оценка рисков для поездок сотрудников, международной экспансии, размещения объектов и др. Также потребуется взаимодействие с внешними экспертами, государственными структурами и отраслевыми партнёрами — для обмена информацией об угрозах компаниям, действующих на рынке передовых ИИ-решений. Ожидается, что соискатель будет иметь степень бакалавра в области международных отношений, политологии или смежных дисциплин, иметь 5–8 лет опыта анализа геополитических рисков, независимо действовать с минимальным контролем со стороны руководства, а также работать по гибкому графику, постоянно находясь на связи в случае международных кризисов и важных геополитических событий в целом. 
Источник изображения: mostafa meraji/unspalsh.com Сейчас компания работает из США, её штаб-квартира находится в Сан-Франциско, а дата-центры строятся по всей стране. Имеются офисы в Германии, Франции, Ирландии, Индии и Швейцарии. Дополнительно компания рассчитывает открыть региональные штаб-квартиры в Великобритании и Австралии. Также в Европе и Австралии планируется аренда ЦОД. Геополитические риски глобальной инфраструктуре ЦОД нельзя игнорировать, поскольку только в последние недели Иран поразил несколько дата-центров американских компаний в ОАЭ и Бахрейне, а также пригрозил атаковать строящийся в рамках проекта OpenAI Stargate гигантский ЦОД G42 в ОАЭ. OpenAI сталкивалась с угрозами и в США, хотя речь шла об отдельных лицах, а не собственно государстве. Так, нападению дважды подвергся дом главы компании Сэма Альтмана (Sam Altman). Сама Anthropic тоже стала жертвой угроз, но в её случае к этому приложили руку непосредственно американские власти. Пентагон назвал Anthropic угрозой для цепочки поставок после того, как компания отказалась предоставлять услуги на условиях военного ведомства, требовавшего организовать массовое наблюдение и поддержку использования полностью автономного оружия. Ситуацией попытались воспользоваться британцы, которые готовят Anthropic предложение по расширению присутствия в Соединённом Королевстве. В частности, якобы будет предложено расширение офиса Anthropic в Лондоне и «двойной листинг».
22.04.2026 [14:14], Сергей Карасёв
Meta✴ зарезервировала 100 ГВт·ч ёмкости для хранения энергии на базе инновационных накопителей Noon EnergyКомпания Meta✴, по сообщению Datacenter Dynamics, заключила соглашение о сотрудничестве с американской фирмой Noon Energy, специализирующейся на разработке систем долговременного хранения энергии нового поколения. По условиям договора, Meta✴ зарезервировала до 100 ГВт·ч ёмкости для своих дата-центров. Технология Noon Energy предполагает использование системы твердооксидных топливных элементов (SOFC) с обратимым действием. Энергия, поступающая от возобновляемых источников, например, солнечной или ветровой станции, запасается в химическом накопителе. Затем при пиковых нагрузках или при падении генерации из-за погодных условий происходит обратное преобразование запасенной химической энергии в электрическую, которая подается в сеть. Решение Noon Energy обеспечивает ряд существенных преимуществ перед альтернативными методами. В частности, вместо дорогостоящих материалов, таких как литий, применяется углеродсодержащее вещество. Заявленная стоимость хранения составляет менее $20/кВт·ч. Накопители нового типа при сопоставимой ёмкости в три раза компактнее и легче, чем литий-ионные батареи, и занимают в 20–200 раз меньше площади, чем другие стационарные системы. При этом платформа Noon Energy обеспечивает 100 и более часов непрерывной генерации электричества. Более того, у некоторых прототипов этот показатель достигает 200 часов. 
Источник изображения: Noon Energy В рамках соглашения Noon Energy на первом этапе предоставит компании Meta✴ систему хранения энергии ёмкостью 2,5 ГВт·ч: реализация этого проекта запланирована на 2028 год. В дальнейшем ресурсы будут постепенно наращиваться. Новая система дополнит другие энергетические ресурсы Meta✴, в число которых входят газовые генераторы, геотермальные источники, атомные станции, солнечные фермы и пр.
22.04.2026 [12:55], Сергей Карасёв
MSI IPC выпустила индустриальный компьютер MS-C936 на базе Intel Raptor Lake-P Refresh для AIoT-приложенийКомпания MSI IPC объявила о выходе индустриального компьютера небольшого форм-фактора MS-C936. Устройство предназначено для AIoT-приложений, промышленной автоматизации, построения различных терминалов и пр. В основу новинки положена аппаратная платформа Intel Raptor Lake-P Refresh. Применён процессор Core i5-120U с 10 вычислительными ядрами (2Р+8Е/12T); максимальная тактовая частота составляет 5 ГГц в турбо-режиме. В состав чипа входит ускоритель Intel Graphics с частотой до 1,3 ГГц. Задействовано пассивное охлаждение. Компьютер может нести на борту до 96 Гбайт DDR5-5200 в виде двух модулей SO-DIMM. Допускается установка SFF-накопителя с интерфейсом SATA, а также SSD типоразмера M.2 2242/2280 с интерфейсом PCIe 4.0 x4 или SATA-3. Кроме того, предусмотрены коннектор M.2 B key 2242/3042 (PCIe x1, USB 3.2, USB 2.0, Nano-SIM) для сотового модема и слот M.2 E key 2230 (PCIe x1, USB 2.0, CNVi) для адаптера Wi-Fi. В оснащение входят звуковой кодек Realtek ALC897 HD Audio и двухпортовый сетевой контроллер 2.5GbE (Intel I226-LM). Кроме того, упомянут TPM-контроллер Infineon SLB9670VQ 2.0. 
Источник изображения: MSI IPC Допускается вывод изображения одновременно на четыре независимых монитора через два выхода HDMI 2.0 (4096 × 2304 точки; 60 Гц) и два порта DP (7680 × 4320 пикселей; 60 Гц; USB Type-C). Предусмотрены два гнезда RJ45 для сетевых кабелей, два последовательных порта, аудиогнездо на 3,5 мм, шесть портов USB 2.0 Type-A, а также по два интерфейса USB 3.1 Type-A и USB 3.1 Type-С. Питание подаётся через DC-разъём. Устройство имеет размеры 196 × 285 × 29 мм и весит 2,22 кг. Говорится о защите от влаги и пыли по стандарту IP40. Диапазон рабочих температур простирается от -10 до +50 °C. Возможен монтаж посредством крепления VESA. Заявлена совместимость с Windows 10/11 IoT Enterprise и Linux.
21.04.2026 [22:14], Руслан Авдеев
Fermi 2.0: из проекта мега-ЦОД им. Трампа ушёл не только гендир, но и главбухМногочисленные проблемы Fermi America, занимающейся эпохальным проектом мега-ЦОД им. Дональда Трампа (The President Donald J. Trump Advanced Energy and Intelligence Campus), сообщает The Register. В последние дни компания, отвечающая за строительство 17-ГВт кампуса Project Matador (HyperGrid) площадью 2,9 тыс. га в Западном Техасе, пережила серию потрясений. Сооснователь компании Тоби Нойгебауэр (Toby Neugebauer) отказался от поста генерального директора, следом подал в отставку и финансовый директор Майлз Эверсон (Miles Everson). Впрочем, оба остались членами совета директоров. Fermi не так давно столкнулась с проблемами при закупках энергетического оборудования, а также с поиском якорного арендатора мощностей своего будущего кампуса. Ранее сообщалось, что некий арендатор найден в ноябре 2025 года, но позже он отказался от сделки. Неофициально глава Fermi говорил об AWS, но фактически ни одна из сторон не признала факт переговоров. Среди других потенциальных клиентов также называлась Palantir. В результате инвесторы подали к компании коллективный иск. По данным экспертов Stifel, в минувшие выходные компания провела конференцию с целью успокоить инвесторов. По словам компании, в уходе Нойгебауэра есть и положительные стороны. Беспокойство, вызванное соответствующей новостью, понятно, но в смене CEO нет ничего экстраординарного. Кроме того, после объявления об уходе в пятницу отмечена активизация переговоров с клиентами — высока вероятность того, что проблема была именно в самом Нойгебауэре, поэтому в дальнейшем переговоры, вероятно, упростятся. 
Источник изображения: Fermi America Нойгебауэр уже столкнулся с многочисленными судебными исками, в одном из которых его обвиняют в мошенничестве. Сам бизнесмен тоже подал в суд на некоторых бывших инвесторов, в том числе известных политиков и бизнесменов, связанных PayPal, Palantir и Founders Fund. Более того, Нойгебауэ недавно вступил в перепалку с министром торговли США Говардом Лютником (Howard Lutnick), который, по его мнению, частично блокирует реализацию Project Matador. Так или иначе в понедельник были анонсированы изменения, получившие название Fermi 2.0. Ведущий независимый член совета директоров Fermi Мариус Хаас (Marius Haas) назначен председателем совета. Ранее он занимал руководящие должности в Compaq, HPE, KKR и Dell. Он же будет курировать поиск нового генерального директора. В качестве временной меры сформирован т.н. «Офис генерального директора» (Office of the CEO) — структура с двойным руководством, которую будут возглавлять недавно назначенный сопрезидент и бывший операционный директор Хакобо Ортис Бланес (Jacobo Ortiz Blanes), а также бывший советник совета директоров Анна Бофа (Anna Bofa), имеющая опыт работы в Google, Dropbox, Pinterest и Meta✴. Параллельно ведутся переговоры с кандидатом на должность временного финансового директора. Также компания прибегла к услугам кадрового агентства Heidrick & Struggles. Кроме того, появятся два новых места в совете директоров. Дополнительно компания формирует новую штаб-квартиру в Далласе (Техас) и обустраивает офис в Амарилло (Техас) — в непосредственной близости от места реализации Project Matador. В понедельник акции Fermi закрылись с падением на 15 %, их цена оказалась на 80 % ниже максимума октября 2025 года, когда они стоили $29,08.
21.04.2026 [20:48], Владимир Мироненко
В ВТБ призвали к партнёрству с Китаем для развития суверенного ИИРазвивать суверенные технологий ИИ в России, включая использование больших языковых моделей (LLM) и вычислительных мощностей, необходимо в партнёрстве с дружественными странами, прежде всего, с Китаем, заявил заместитель руководителя технологического блока ВТБ. Он подчеркнул, что при этом важно учитывать необходимость защиты данных россиян, которые используются при обучении ИИ. Топ-менеджер отметил, что открытые LLM, разработанные китайскими компаниями, работают «чуть лучше», чем российские модели, но их использование несёт определенные риски для технологического суверенитета, так как они созданы за пределами России. Использование российских моделей, в частности, от «Яндекса» и Сбера, снимает часть этих рисков. Вместе с тем топ-менеджер ВТБ считает, необходимо использовать лучшие технологии, чтобы не оказаться в числе отстающих: «Для того, чтобы наши модели были не хуже, мы стараемся обучать их на обезличенных данных. И считаем, что партнёрство с Китаем — это правильный возможный вариант, они действительно сейчас по многим направлениям лидируют». Это также относится к развитию суперкомпьютеров, необходимых для ИИ: «Если взять вычислительные мощности, которые есть за рубежом и которые есть у нас, понятно, что те суперкомпьютеры, которые сейчас работают, в первую очередь в США, многократно превышают те мощности, которые есть в России. И это тоже проблема». 
Источник изображения: Hanson Lu/unsplash.com Он добавил, что в рамках кооперации уже запущены большие совместные лаборатории с китайскими коллегами. Также начинают осуществлять сборку серверов в России с китайскими GPU: «Это — будущее, так как без кооперации не обойтись. Мы большая и сильная страна, но есть другие большие и сильные страны, вместе с которыми мы достигнем больших результатов». Также было отмечено, что применение ИИ-технологий в финансовом секторе усложняется в связи с необходимостью выполнения требований по соблюдению банковской тайны и защите персональных данных. Поэтому, для того чтобы использовать самые эффективные и популярные большие языковые модели, но при этом не допустить утечку данных, в ВТБ используют их on-premise, ограничивая их применение защищённым банковским контуром. «На сегодняшний день к такому режиму работы готовы наши российские большие языковые модели, в том числе YandexGPT и GigaChat», — сообщил топ-менеджер.
21.04.2026 [19:38], Руслан Авдеев
Google и CoreWeave взялись за «мусорные» облигации на миллиарды долларовПоддерживаемая Google рекордная сделка по привлечению инвестиций и дополнительная продажа облигаций компанией CoreWeave обеспечили новое вливание в индустрию ИИ, на этот раз в объёме $6,7 млрд, сообщает Bloomberg. При это речь идёт о высокодоходных, но высокорисковых «мусорных» облигациях. Связанная с Google сделка под руководством Morgan Stanley оценивается в $5,7 млрд, хотя общая сумма заявок от всех желающих составила $19 млрд. Средства пойдут на строительство двух дата-центров в кампусе Meridian Arc HoldCo в округе Салливан (Sullivan, Индиана). Мощности ЦОД будут сданы в аренду неооблаку Fluidstack, а сама сделка поддерживается Google. Тем временем провайдер облачной инфраструктуры CoreWeave продал новый пакет облигаций на сумму $1 млрд под 9,75 % с погашением в 2031 году, всего через неделю после предыдущего размещения ценных бумаг на $1,75 млрд. По данным Datacenter Dynamics, в марте 2026 года CoreWeave получила взаймы $8,5 млрд для поддержки закупок ИИ-ускорителей для Meta✴. Неооблачный провайдер наращивает свою долговую нагрузку для расширения инфраструктуры, к концу 2025 года совокупный долг компании составил $21,6 млрд. Ранее в текущем году она получила $2 млрд инвестиций от NVIDIA. 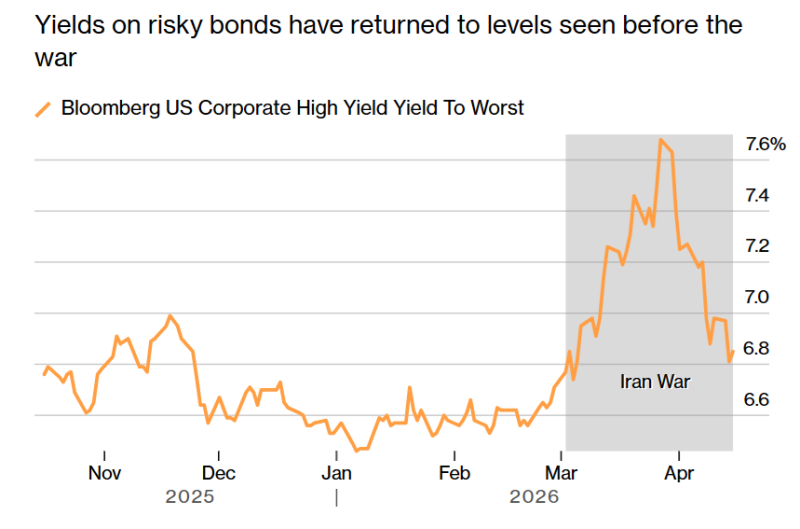
Источник изображения: Bloomberg Быстрое распространение ИИ вызвало беспрецедентный дефицит свободных мощностей ЦОД, ИИ-ускорителей и электроэнергии для обеспечения их работы. Для финансирования компании буквально воюют за все доступные на рынке средства от «мусорных» облигаций до проектного финансирования. За последние недели резиденты Уолл-Стрит обеспечили финансирование на десятки миллиардов долларов, даже несмотря на то, что конфликт на Ближнем Востоке заставил некоторых потенциальных участников снизить активность. Но по мере того как у многих растёт оптимизм относительно перспектив долгосрочного мира, стоимость заёмных средств для компаний всех типов постепенно снижается. Meridian Arc HoldCo представляет собой совместное предприятие Next Frontier и Fluidstack, именно оно выпустило пятилетние облигации для финансирования ЦОД в Индиане; компания поддерживается Google. Заём на $5,7 млрд с доходностью 6,25 % — это крупнейший выпуск высокодоходных облигаций в США, связанных с ИИ. Кроме того, это крупнейшая сделка такого рода, организованная единственной финансовой структурой с Уолл-Стрит. Размещение завершилось всего через день после старта официальной маркетинговой компании. Размещение побило собственный рекорд Morgan Stanley. Ранее рекордным считалось размещение облигаций в интересах криптомайнера TeraWulf в 2025 году на $3,2 млрд, также поддержанное Google и сделанное в интересах Fluidstack. Fluidstack занимается строительством высокопроизводительной вычислительной инфраструктуры, в этой сфере наблюдается бум на фоне взрывного развития ИИ-проектов. Недавно компания анонсировала сделку с Anthropic на $50 млрд, предусматривающую строительство кастомных ЦОД для разработчика ИИ-моделей. В феврале 2026 года Google привлекла со помощью облигаций $32 млрд для поддержки растущих капитальных расходов. Техногигант рассчитывает, что последние составят в 2026 году $185 млрд, большая доля которых пойдёт на ЦОД и ИИ-инфраструктуру. Кроме того, Google снова поддержала Fluidstack, купив облигации на $1,3 млрд. |
|

