Материалы по тегу: инференс
|
11.04.2024 [17:59], Алексей Степин
Сделано в Европе: Kalray представила ускоритель Turbocard4 для машинного зрения и обработки ИИ-данныхКомпания Kalray объявила о коммерческой доступности новых ускорителей Turbocard4 (TC4). Новинка позиционируется в качестве решения для ускорения работы систем машинного зрения, либо как акселератор «умной» индексации данных. На борту ускорителя, выполненного в формате FHFL установлено сразу четыре чипа DPU Coolidge 2 с фирменной архитектурой Kalray MPPA. Эти процессоры были анонсированы ещё летом прошлого года в качестве энергоэффективных DPU с производительностью до 1,5 Тфлопс в режиме FP32 и 50 Топс в характерном для инференса режиме INT8. 
Источник изображений здесь и далее: Kalray Выбор рынков не случаен: машинное зрение сегодня является быстро растущей отраслью, в 2023 году оцененной в более чем $20 млрд, а к 2032 году эта цифра обещает вырасти до $175 млрд. Про индексацию данных для генеративного ИИ нечего и говорить — на дворе бум подобных технологий, а объёмы наборов данных постоянно растут. Такие датасеты требуют эффективной предобработки, иначе растущее время выборки нужных данных будет сдерживать производительность и обучения, и инференса.  Интересно, что производятся TC4 в Европе, на французской фабрике Asteelflash, уже получившей первый заказ на сумму более $1 млн. В силу перспективности избранных направлений не следует удивляться, что европейская инициатива Kalray и Asteelflash поддержана французским правительством в рамках программы CARAIBE. Уже в 2025 году планируется довести темпы производства ускорителей TC4 с сотен до нескольких тысяч в месяц. 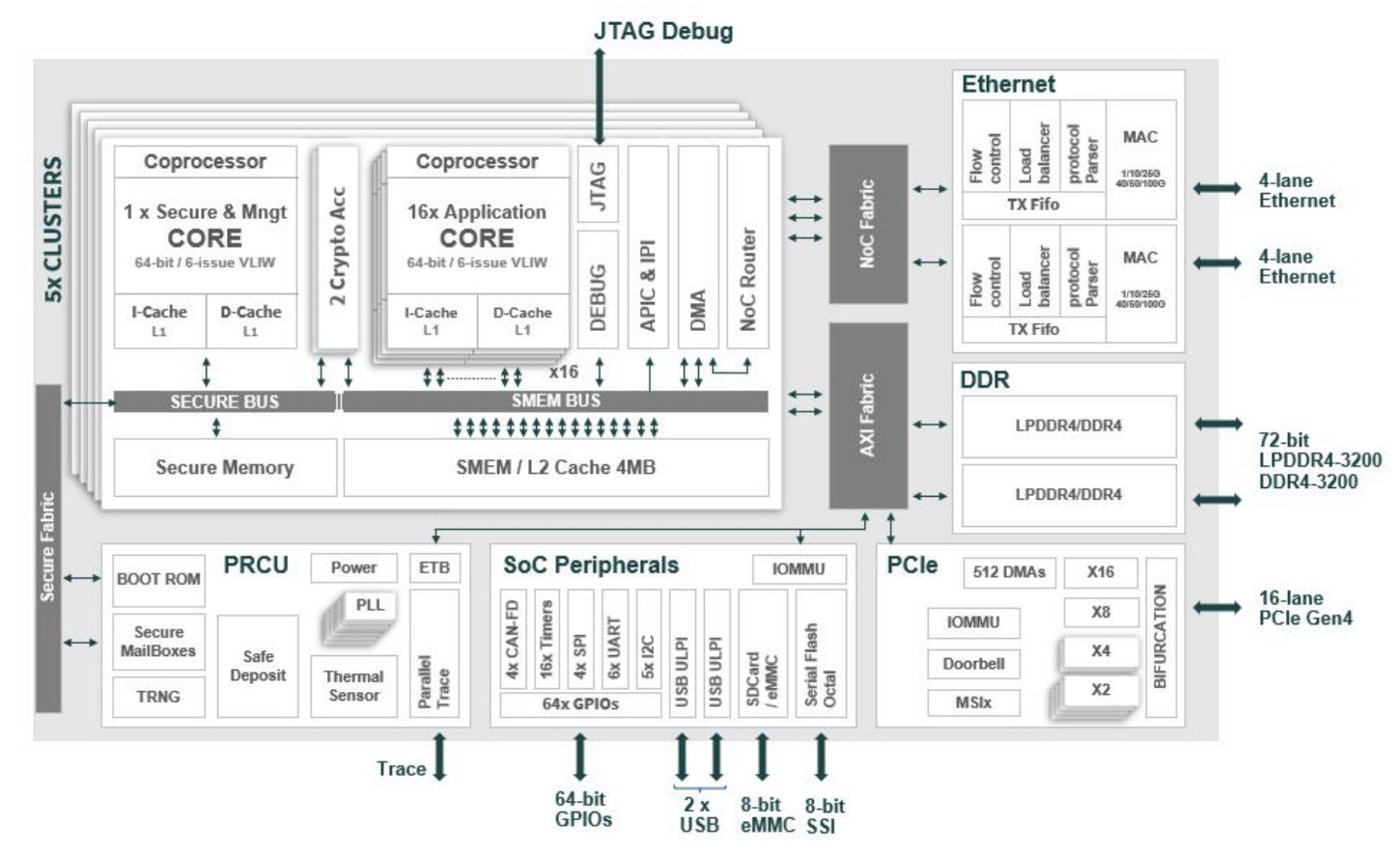 Coolidge 2, по словам создателей, представляет собой универсальное решение на базе архитектуры VLIW. Он имеет 80 ядер с частотой до 1,2 ГГц, причём каждое ядро располагает FPU (IEEE 754-2008). Имеются оптимизации для матричных операций и трансцендентных функций. Процессор разделён на 5 кластеров по 16 ядер, каждый кластер имеет дополнительное управляющее ядро, отвечающее также за функции безопасности. Дополняет Coolidge 2 кеш объёмом 8 Мбайт, двухканальный контроллер памяти DDR4-3200 и пара интерфейсов 100GbE с поддержкой RoCE. Чип поддерживает форматы INT8, FP16, FP32 и даже FP64. Поскольку на борту Turbocard4 работает сразу четыре Coolidge 2, речь идёт о 6 Тфлопс для FP32, 100 Тфлопс для FP16 и 200 Топс для INT8 при теплопакете в районе 120 Вт. Что касается программной поддержки, Kalray сопровождает свои решения SDK, базирующимся на открытых стандартах. Поддерживаются Linux и RTOS.
11.04.2024 [02:16], Владимир Мироненко
Второе поколение ИИ-ускорителей Meta✴ MTIA втрое быстрее первогоКомпания Meta✴ поделилась подробностями о следующем собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator. Новый чип отличается более высокой производительностью по сравнению со чипом MTIA v1, представленным в мае прошлого года, и будет играть решающую роль в обеспечении работы ИИ-моделей Meta✴. Следующее поколение крупномасштабной инфраструктуры Meta✴ рассчитано на поддержку новых продуктов и услуг в области генеративного ИИ, рекомендательных систем и передовых исследований в области ИИ. Создание нового чипа является частью инвестиций в инфраструктуру. В ближайшие годы, как ожидается, затраты в этом направлении будут расти, поскольку требования к вычислительным ресурсам для поддержки моделей будут расти вместе с усложнением последних. 
Источник изображений: Meta✴ Архитектура чипа ориентирована на обеспечение «правильного баланса вычислений, пропускной способности и объёма памяти» даже при относительно небольших размерах обрабатываемых последовательностей. MTIA v2 в сравнении с MTIA v1 в 3,5 раза быстрее в обычных вычислениях и в 7 раз — в разреженных. Новый чип изготавливается по 5-нм техпроцессу TSMC и имеет габариты 25,6 × 16,4 мм (упаковка 40 × 50 мм). Ускоритель работает на частоте 1,35 ГГц, а его TDP составляет 90 Вт, тогда как 7-нм MTIA v1 работал на частоте 800 МГц и имел TDP всего 25 Вт. Готовая стоечная система вмещает до 72 ускорителей и состоит из трёх шасси с 12 платами, на каждой из которых размещено по два ускорителя. Для дальнейшего масштабирования можно добавить RDMA-сеть.  Чип состоит из 64 вычислительных элементов (PE). У каждого PE есть небольшой блок локальной памяти объёмом 384 Кбайт с ПСП 1 Тбайт/с. На весь чип приходится 256 Мбайт SRAM (2,7 Тбайт/с), а внешняя память представлена 128 Гбайт LPDDR5 (204,8 Гбайт/с). Для подключения к хосту используется интерфейс PCIe 5.0 x8 (32 Гбайт/с). При работе с матрицами чип развивает 177 (FP16/BF16) и 354 (INT8) Тфлопс, в разреженных вычислениях — вдвое больше. SIMD-блоки выдают 2,76 Тфлопс для FP32 и 5,53 Тфлопс для INT8/FP16/BF16. В векторных расчётах значения те же, только для INT8 показатель составляет уже 11,06 Тфлопс. 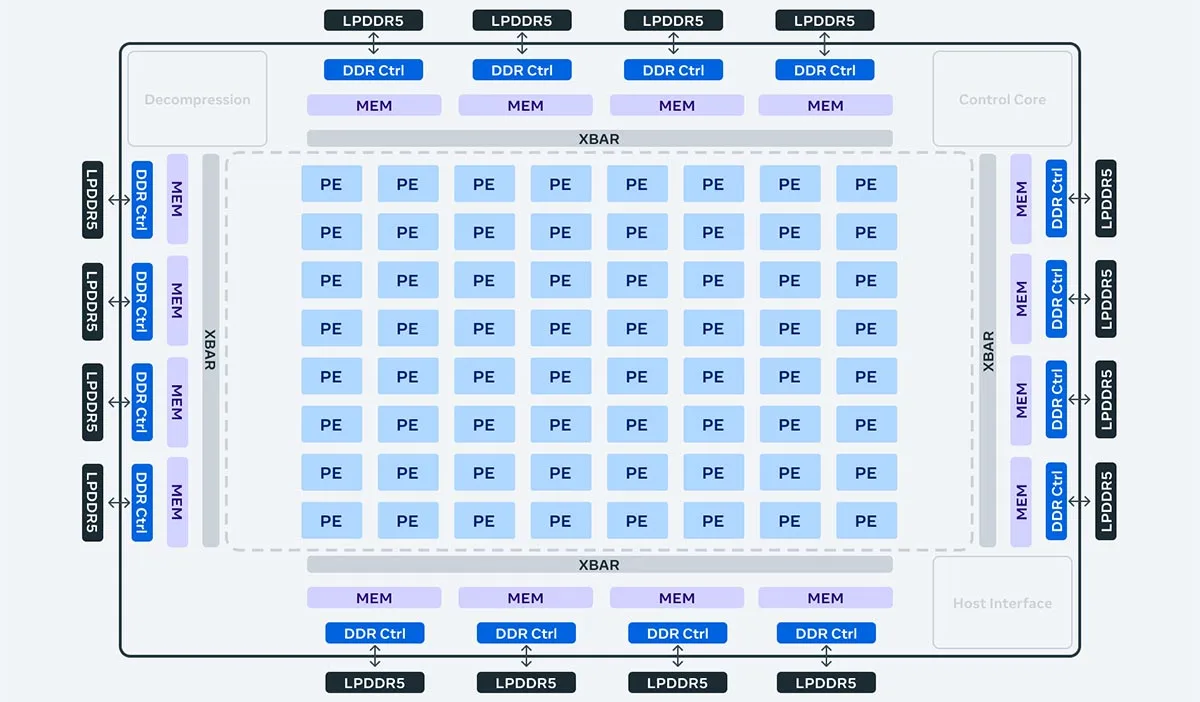 MTIA v2 совместим с кодами, разработанными для MTIA v1. Стек MTIA ориентирован на PyTorch 2.0 и включает компилятор Triton-MTIA. Предварительные испытания MTIA v2 на четырёх ключевых ИИ-моделях компании показали, что он втрое быстрее MTIA v1 чип первого поколения. А на уровне платформы достигнуто шестикратное увеличение пропускной способности модели и рост производительности на Вт в 1,5 раза. Чипы MTIA уже развёрнуты в ЦОД компании. Правда, для обучения Meta✴ их пока не использует.
09.04.2024 [12:45], Сергей Карасёв
Hyperion Research: спрос на облачные НРС-услуги будет быстро растиКомпания Hyperion Research, по сообщению ресурса HPC Wire, сделала прогноз по мировому рынку облачных HPC-решений. По мнению аналитиков, спрос на такие услуги в ближайшие годы будет быстро расти, что объясняется стремительным внедрением ИИ, генеративных сервисов и других современных решений. Говорится, что значение CAGR (среднегодовой темп роста в сложных процентах) на рынке облачных НРС-сервисов в перспективе пяти лет составит 18,1 %. При этом, как отмечается, данный показатель не в полной мере учитывает значительное влияние ИИ на увеличение спроса на технические вычисления в облаке. Аналитики отмечают, что обучение ИИ-моделей, имеющее большое значение, может быть отодвинуто на второй план из-за роста потребностей в инференсе. Дело в том, что обучение требует значительных вычислительных ресурсов, но на относительно небольшие периоды времени. Кроме того, обучение выполняет сравнительно небольшое количество пользователей. Вместе с тем инференс востребован среди широкого круга заказчиков для самых разных приложений. 
Источник изображения: pixabay.com В исследовании также говорится, что рост использования генеративного ИИ продолжится, тогда как его темпы внедрения стабилизируются. В сегменте больших языковых моделей (LLM) популярность начнут обретать фреймворки. В плане аппаратного обеспечения, как полагают аналитики Hyperion Research, резко возрастёт востребованность Arm-процессоров. В сегменте НРС выручка от Arm-систем в 2024 году поднимется в два раза по отношению к предыдущему году. Кроме того, ожидается рост популярности чипов с открытой архитектурой RISC-V. Прогнозируется также увеличение интереса к локальным квантовым компьютерам, которые будут дополнять квантовые вычисления через облако.
08.04.2024 [01:50], Владимир Мироненко
Groq больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисыСтартап Groq, создавший ускоритель LPU на базе собственного массивно-параллельного тензорного процессора TSP, больше не продаёт оборудование, предлагая вместо этого воспользоваться его облачными ИИ-сервисами или стать партнёром в создании ЦОД. Об этом генеральный директор Groq Джонатан Росс (Jonathan Ross) сообщил ресурсу EE Times. Он пояснил, что для стартапа заниматься продажами чипов слишком сложно, потому что «минимальная сумма покупки, чтобы это имело смысл, высока, затраты высоки, и никто не хочет рисковать, покупая большое количество оборудования — неважно, насколько оно потрясающее». По его словам, в облаке GroqCloud для инференса больших языковых моделей (LLM) в реальном времени уже зарегистрировано 70 тыс. разработчиков и запущено более 19 тыс. новых приложений. 
Источник изображений: Groq В случае поступления заказов на поставку больших объёмов чипов для очень крупных систем Groq вместо продажи предлагает партнёрство по развёртыванию ЦОД. Groq подписала соглашение с саудовской государственной нефтяной компанией Aramco, которое предполагает масштабное развёртывание LPU. Похожее соглашение в ОАЭ подписала Cerebras, ещё один молодой разработчик ИИ-ускорителей. «Правительство США и его союзники — единственные, кому мы готовы продавать оборудование, — говорит Росс. — Для всех остальных мы лишь (совместно) создаём коммерческие облака». По его словам, в этом году Groq планирует разместить 42 тыс. LPU в GroqCloud, при этом Aramco и другие партнёры «завершают» свои сделки по получению такого же количества чипов. Компания способна выпустить 220 тыс. LPU только в этом году, а общий объём производства на ближайшее время составляет 1,5 млн ускорителей. Около 1 млн из них всё ещё не зарезверированы, но это количество быстро сокращается. Росс пообещал, что к концу 2025 году компания развернёт столько LPU, что их вычислительная мощность будет эквивалентна ИИ-мощностям всех гиперскейлерам вместе взятых.  Росс с оптимизмом смотрит на перспективы Groq, поскольку чипы TSP не используют память HBM, на которую полагаются решения конкурентов, включая NVIDIA, и поставки которой расписаны до конца 2024 года. Что касается LPU следующего поколения, то компания планирует сразу перейти с 14-нм техпроцесса (Global Foundries) на 4-нм. По словам Росса, новый чип будет оптимизирован для генеративного ИИ, но у него в силу универсальности архитектуры не будет каких-то специальных функций для обработки LLM. Будет ли новый ускоритель всё так же изготавливаться на территории США, не уточняется. Groq, похоже, достаточно уверена в своих чипах, которые в бенчмарках действительно обгоняют конкурентов. После анонса архитектуры NVIDIA Blackwell, обеспечивающей кратное увеличение производительности в задачах генеративного ИИ, компания выпустил в ответ пресс-релиз из одного предложения: «Groq всё ещё быстрее». А чуть позже даже раскритиковала NVIDIA.
07.04.2024 [14:12], Сергей Карасёв
Разработчик ИИ-чипов SiMa.ai получил на развитие ещё $70 млнСтартап SiMa.ai, разрабатывающий аппаратные и программные решения для обработки ИИ-задач на периферии, объявил о проведении раунда финансирования на сумму в $70 млн. Таким образом, в общей сложности компания привлекла на развитие $270 млн. Ключевым продуктом SiMa.ai является изделие Machine Learning System-on-Chip (MLSoC). Оно специально спроектировано с прицелом на периферийные ИИ-приложения. Это могут быть роботы, дроны, системы машинного зрения, автомобильные платформы, медицинское оборудование и пр. В состав MLSoC входит ряд блоков. Это, в частности, ИИ-ускоритель с 25 Мбайт интегрированной памяти, обеспечивающий производительность до 50 TOPS (INT8) или 10 TOPS/Вт. Он дополнен процессором приложений на базе четырёх вычислительных ядер Arm Cortex-A65 с частотой 1,15 ГГц. Присутствует четырёхъядерный узел компьютерного зрения Synopsys ARC EV74. Изделие также несёт на борту блоки (де-)кодирования видео в формате H.264. Реализована поддержка четырёх портов 1GbE, интерфейсов PCIe 4.0 х8, SPIO, I2C и GPIO. 
Источник изображения: SiMa.ai Чип MLSoC доступен в составе платы для разработчиков. Компания также предоставляет специализированный набор инструментов под названием Pallet, упрощающий создание ПО для чипа. Этот комплект включает, в частности, компилятор, который преобразует модели ИИ в формат, оптимизированный для работы в системах на основе MLSoC. Сообщается, что раунд финансирования на $70 млн проведён под руководством Maverick Capital. В нём также приняли участие Point72, Jericho, Amplify Partners, Dell Technologies Capital, предприниматель Лип-Бу Тан (Lip-Bu Tan) и др. Полученные средства пойдут на разработку 6-нм чипа MLSoC второго поколения, который будет выпущен на TSMC в I квартале 2025 года. Известно, что это решение объединит CPU на базе Arm Cortex-A и модуль компьютерного зрения Synopsys EV74.
06.04.2024 [21:08], Сергей Карасёв
M.2-модуль Hailo-10 обеспечивает ИИ-производительность до 40 TOPSКомпания Hailo анонсировала специализированный модуль Hailo-10, предназначенный для обслуживания генеративного ИИ. Этот ускоритель с высокой энергетической эффективностью может быть установлен, например, в рабочую станцию или edge-систему. Изделие выполнено в форм-факторе M.2 Key M 2242/2280 с интерфейсом PCIe 3.0 х4. В оснащение входят чип Hailo-10H и 8 Гбайт памяти LPDDR4. Говорится о совместимости с компьютерами, оснащёнными CPU на архитектурах x86 и Aarch64 (Arm64). Заявлена поддержка Windows 11, а также ИИ-фреймворков TensorFlow, TensorFlow Lite, Keras, PyTorch и ONNX. 
Источник изображения: Hailo Как отмечает Hailo, новинка обеспечивает ИИ-производительность до 40 TOPS. Типовое энергопотребление составляет менее 3,5 Вт. Утверждается, что ИИ-модуль поддерживает нагрузки, связанные с инференсом, в режиме реального времени. Например, при работе с большой языковой моделью Llama2-7B достигается скорость до 10 токенов в секунду (TPS). При использовании Stable Diffusion 2.1 возможна генерация одного изображения на основе текста менее чем за 5 с. Применение Hailo-10 позволяет перенести определённые ИИ-нагрузки из облака или дата-центра на периферию. Это снижает задержки и даёт возможность решать задачи в офлайновом режиме. Изначально новинка будет позиционироваться для применения в сферах ПК и автомобильных информационно-развлекательных комплексов для обеспечения работы чат-ботов, средств автопилотирования, персональных помощников и систем с голосовым управлением. Поставки образцов Hailo-10 будут организованы во II квартале 2024 года. В ассортименте компании также присутствует ускоритель Hailo-8 в формате M.2: он обеспечивает производительность до 26 TOPS и при этом имеет энергоэффективность 3 TOPS/Вт.
28.03.2024 [14:31], Сергей Карасёв
Intel Gaudi2 остаётся единственным конкурентом NVIDIA H100 в бенчмарке MLPerf InferenceКорпорация Intel сообщила о том, что её ИИ-ускоритель Habana Gaudi2 остаётся единственной альтернативой NVIDIA H100, протестированной в бенчмарке MLPerf Inference 4.0. При этом, как утверждается, Gaudi2 обеспечивает высокое быстродействие в расчёте на доллар, хотя именно чипы NVIDIA являются безоговорочными лидерами. Отмечается, что для платформы Gaudi2 компания Intel продолжает расширять поддержку популярных больших языковых моделей (LLM) и мультимодальных моделей. В частности, для MLPerf Inference v4.0 корпорация представила результаты для Stable Diffusion XL и Llama v2-70B. Согласно результатам тестов, в случае Stable Diffusion XL ускоритель H100 превосходит по производительности Gaudi2 в 2,1 раза в оффлайн-режиме и в 2,16 раза в серверном режиме. При обработке Llama v2-70B выигрыш оказывается более значительным — в 2,76 раза и 3,35 раза соответственно. Однако на большинстве этих задач (кроме серверного режима Llama v2-70B) решение Gaudi2 выигрывает у H100 по показателю быстродействия в расчёте на доллар. 
Источник изображений: Intel В целом, ИИ-ускоритель Gaudi2 в Stable Diffusion XL показал результат в 6,26 и 6,25 выборок в секунду для оффлайн-режима и серверного режима соответственно. В случае Llama v2-70B достигнут показатель в 8035,0 и 6287,5 токенов в секунду соответственно. 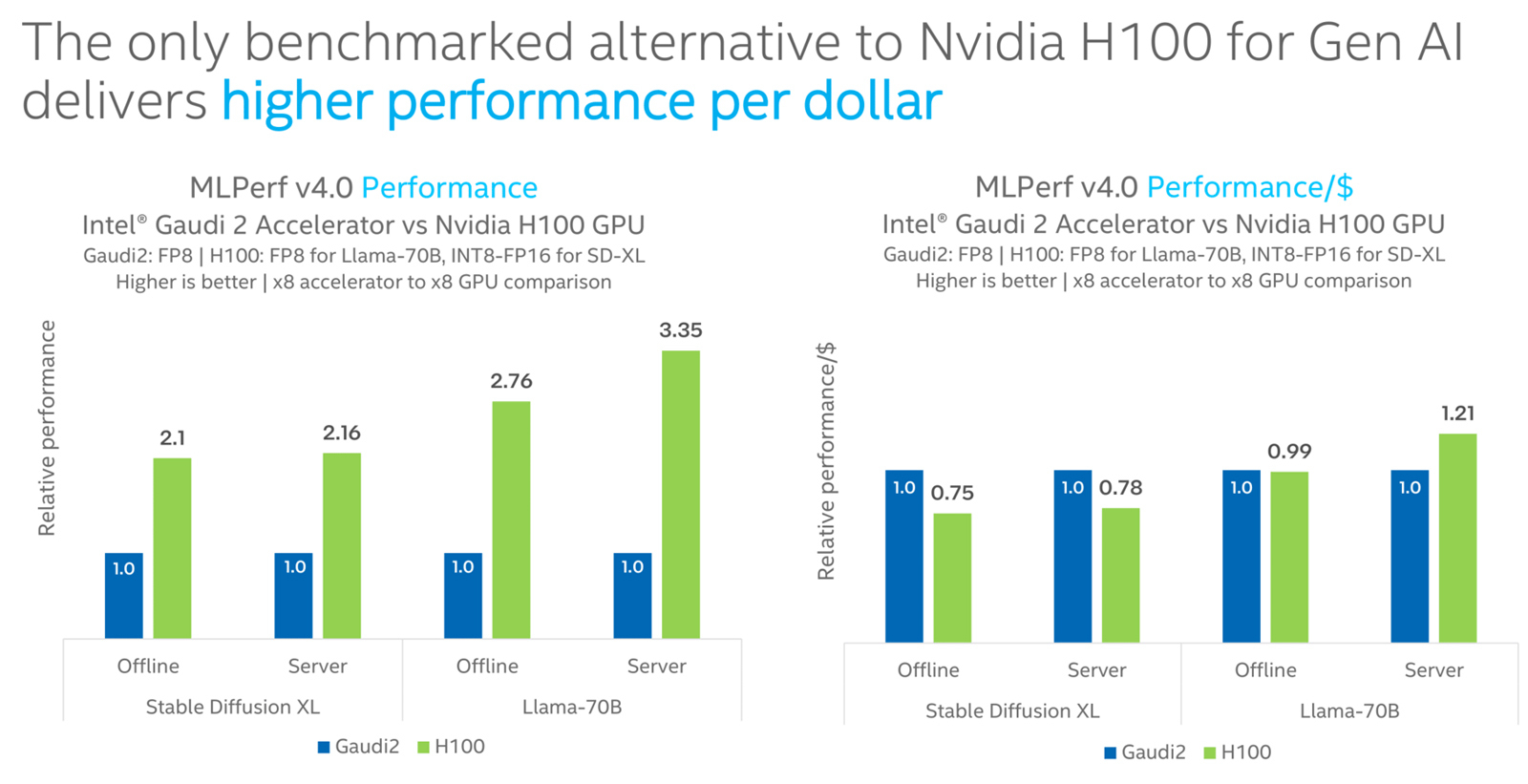 Говорится также, что серверные процессоры Intel Xeon Emerald Rapids благодаря улучшениям аппаратной и программной составляющих в бенчмарке MLPerf Inference v3.1 демонстрируют в среднем в 1,42 раза более высокие значения по сравнению с чипами Xeon Sapphire Rapids. Например, для GPT-J с программной оптимизацией и для DLRMv2 зафиксирован рост быстродействия примерно в 1,8 раза.
27.03.2024 [22:29], Алексей Степин
Новый бенчмарк — новый рекорд: NVIDIA подтвердила лидерские позиции в MLPerf InferenceКомпания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям. Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию». 
Источник изображений: NVIDIA Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel). 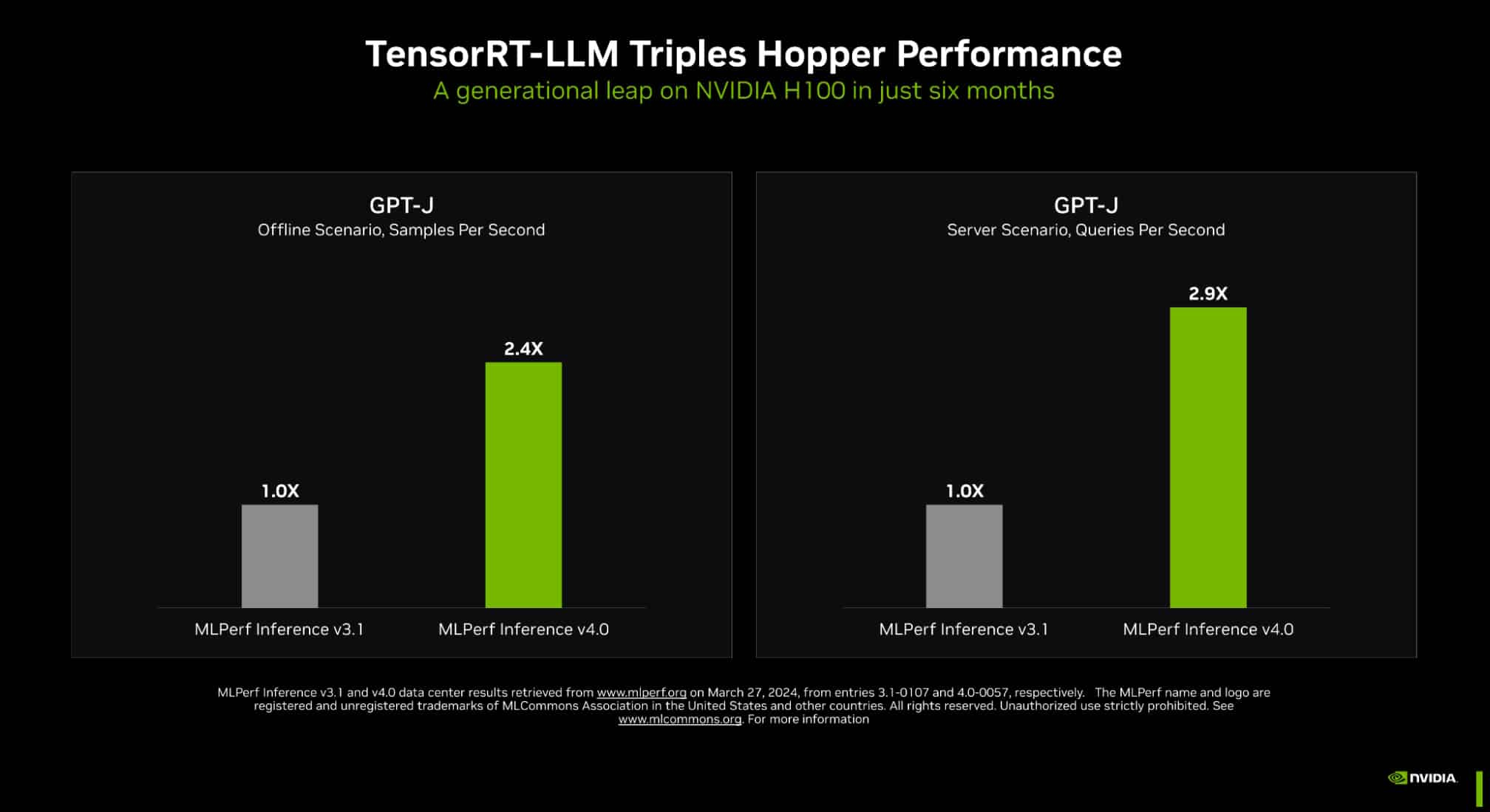 В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %. 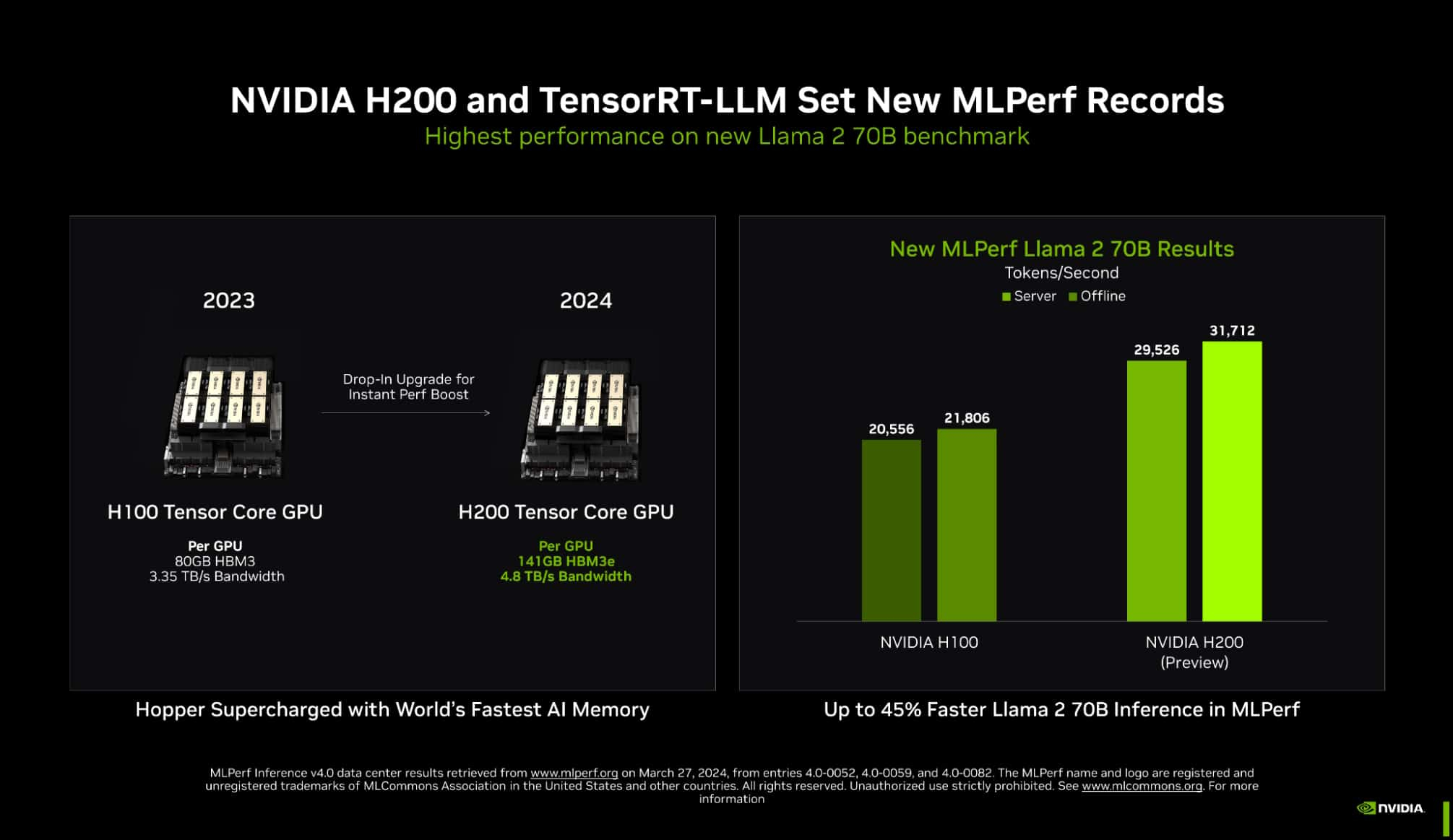 В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности. На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
25.03.2024 [21:23], Владимир Мироненко
Samsung поставит Naver ИИ-ускорители Mach-1 на $752 млнКомпания Samsung Electronics поставит в этом году ведущей южнокорейской интернет-компании Naver Corp. ИИ-ускорители Mach-1 следующего поколения собственной разработки. Сумма контракта составит до ₩1 трлн (около $752 млн), сообщил ресурс KED Global со ссылкой на отраслевые источники. Это позволит Naver значительно сократить зависимость от поставок ускорителей NVIDIA. В октябре прошлого года Naver вынужденно стала использовать процессоры Intel Xeon вместо ускорителей NVIDIA. Смена оборудования Naver происходит на фоне роста недовольства технологических компаний увеличением цен на ускорители NVIDIA и их глобальной нехваткой. По словам Samsung, Mach-1 был разработан для поддержки Transformer-моделей и позволяет выполнять инференс больших языковых моделей (LLM) даже с маломощной памятью вместо энергоёмкой HBM, что делает его в восемь раз энергоэффективнее традиционных ускорителей на базе GPU. При этом Mach 1 на порядок дешевле чипов NVIDIA. По словам источников, бизнес-подразделение Samsung System LSI и Naver находятся в заключительной стадии переговоров о поставке 150–200 тыс. ИИ-ускорителей Mach-1, цена которых может составить ₩5 млн ($3756) за штуку. Цены и точный объём поставок пока не согласованы. Сообщается, что Naver будет использовать Mach-1 для инференса вместо ускорителей NVIDIA в картографическом сервисе AI Naver Place. Naver готова покупать эти чипы и в дальнейшем, если первая партия покажет «хорошую производительность», отметили источники, по словам которых Samsung также ведёт переговоры о поставках Mach-1 с Microsoft и Meta✴. 
Источник изображения: Samsung Для Samsung сделка с Naver важна с точки зрения конкуренции с SK hynix, доминирующей в сегменте памяти HBM, спрос на которую в связи с популярностью генеративного ИИ резко вырос. Samsung сообщила о разработке первой в отрасли памяти HBM3E 12-Hi, массовое производство которой начнётся в I половине этого года. Кроме того, SK Group поддерживает разработку ИИ-ускорителей Sapeon, а Samsung сотрудничает с Rebellions. По оценкам Omdia, глобальный рынок ИИ-ускорителей вырастет с $6 млрд в 2023 году до $143 млрд к 2030 году.
23.03.2024 [22:33], Сергей Карасёв
Akamai внедрит в своей сети ПО Neural Magic для ускорения ИИ-нагрузокCDN-провайдер Akamai Technologies объявил о заключении соглашения о стратегическом партнёрстве с компанией Neural Magic, разработчиком специализированного ПО для ускорения рабочих нагрузок, связанных с ИИ. Сотрудничество призвано расширить возможности глубокого обучения на базе распределённой вычислительной инфраструктуры Akamai. Компания Akamai реализует комплексную стратегию по трансформации в распределённого облачного провайдера. В частности, в начале 2023 года Akamai запустила платформу Connected Cloud на базе Linode: это более распределённая альтернатива сервисам AWS или Azure. А в феврале 2024 года была представлена система Gecko (Generalized Edge Compute), которая позволяет использовать облачные вычисления на периферии. 
Источник изображения: pixabay.com В рамках сотрудничества с Neural Magic провайдер предоставит клиентам высокопроизводительную инференс-платформу. Утверждается, что софт Neural Magic даёт возможность запускать ИИ-модели на обычных серверах на базе CPU без дорогостоящих ускорителей на основе GPU. ПО позволяет ускорить выполнение ИИ-задач с помощью технологий автоматического разрежения моделей (model sparsification). Софт Neural Magic дополнит возможности Akamai по масштабированию, обеспечению безопасности и доставке приложений на периферии. Это позволит компаниям развёртывать ИИ-сервисы в инфраструктуре Akamai c более низкими задержками и повышенной производительностью без необходимости аренды GPU-ресурсов. Платформа Akamai и Neural Magic особенно хорошо подходит для ИИ-приложений, в которых большие объёмы входных данных генерируются близко к периферии. |
|

