Материалы по тегу: aws
|
26.04.2024 [11:36], Сергей Карасёв
AWS построит в Индиане кампус ЦОД стоимостью $11 млрдКомпания Amazon и губернатор Индианы Эрик Холкомб (Eric J. Holcomb), по сообщению Datacenter Dynamics, анонсировали проект создания на территории этого штата крупного комплекса дата-центров. Инвестиции в проект оцениваются в $11 млрд, что станет крупнейшими капитальными вложениями в истории Индианы. Технические подробности об инициативе не раскрываются. Но известно, что объекты ЦОД расположатся в округе Сент-Джозеф на севере центральной Индианы. Говорится, что в 2023 году облачная платформа Amazon Web Services (AWS) купила в названном регионе более 364 га сельскохозяйственных земель через фирму Razor5. Именно на этой территории и планируется возведение сооружений. Как отмечается, кампус построят неподалёку от города Нью-Карлайла (расположен примерно в 130 км к востоку от Чикаго). По словам Холкомба, инвестиции в проект окажут положительное влияние на развитие региона «на многие годы вперёд». В частности, будут созданы дополнительные рабочие места. Кроме того, появление кампуса ЦОД будет способствовать расширению технологического сектора штата. 
Источник изображения: AWS Amazon в рамках проекта получила ряд налоговых льгот. Корпорация экономического развития Индианы (IEDC) предоставит AWS освобождение от налога с продаж для соответствующих капитальных вложений на срок 50 лет. Кроме того, IEDC обеспечит до $18,3 млн в виде налоговых льгот на персонал, до $5 млн в виде грантов на обучение, до $20 млн льгот на реконструкцию и пр. Отметим, что по итогам 2023 года AWS управляла 3,549 млн м2 площадей дата-центров и офисов. Облачная платформа продолжает активно развивать направление ЦОД. В ближайшие 15 лет Amazon планирует потратить почти $150 млрд на дата-центры, что позволит ей справиться с ожидаемым взрывным ростом спроса на ИИ и другие цифровые сервисы.
20.04.2024 [13:01], Сергей Карасёв
AWS закрыла службу Snowmobile по транспортировке данных на фурахОблачная платформа Amazon Web Services (AWS), по сообщению ресурса Datacenter Dynamics, закрыла сервис Snowmobile, в рамках которого предлагались услуги по физической транспортировке огромных массивов данных на грузовиках. Теперь в семействе AWS Snow доступны только предложения Snowball и Snowcone. Служба Snowmobile была запущена в 2016 году. Идея заключалась в том, что клиенты могли перемещать свои данные в облако AWS на фурах, вместо использования традиционных сетевых каналов. В случае массивов, исчисляющихся петабайтами, это обеспечивало значительный выигрыш во времени. Для Snowmobile использовались грузовики со 45-футовыми контейнерами с системами хранения общей вместимостью 100 Пбайт. Для загрузки данных из ЦОД клиента применялись линии с общей пропускной способностью на уровне 1 Тбит/с. При такой скорости заполнить весь доступный объём накопителей Snowmobile можно было примерно за 10 дней. После этого информация транспортировалась в ближайший регион AWS, где выгружалась на серверы облачного провайдера. 
Изображение: AWS Перемещение каждой фуры отслеживалось посредством GPS с возможностью передачи телеметрии через сотовые и спутниковые каналы. Стоимость услуг оценивалась в $0,005 за 1 Гбайт в месяц. Таким образом, для заказчиков, которым нужно было переместить в облако 100 Пбайт информации, услуга обходилась в $500 тыс. Как сообщили в AWS, решение о закрытии Snowmobile связано с тем, что с момента её запуска появились другие сервисы и функции, которые сделали перемещение данных в облако удобнее, быстрее и дешевле для клиентов. Это, в частности, устройство Snowball Edge размером с чемодан, которое может быть оснащено быстрыми SSD-накопителями, а также более компактное решение Snowcone.
17.04.2024 [13:00], Сергей Карасёв
Роскомнадзор заблокировал доступ к AWS и ряду хостинг-провайдеровРоскомнадзор начал блокировать доступ к облачной платформе Amazon Web Services (AWS), а также службам ряда хостинговых компаний, включая GoDaddy. Причина — нарушение так называемого закона «о приземлении», который был принят 1 июля 2021 года. Указанный закон (№236-ФЗ) предусматривает, что иностранные IT-компании с ежедневной аудиторией в России 500 тыс. человек и более обязаны открыть представительство на территории РФ, зарегистрировать личный кабинет на сайте Роскомнадзора и разместить на своей площадке электронную форму для обратной связи с российскими гражданами или организациями. За неисполнение перечисленных требований предусмотрены различные меры воздействия — вплоть до полной блокировки ресурсов. В конце 2023 года Роскомнадзор оштрафовал ряд иностранных хостинг-провайдеров за неисполнение закона «о приземлении»: в их число вошли AWS, GoDaddy, Kamatera, Network Solutions, WPEngine и др. Однако с тех пор эти компании нарушения не устранили, и теперь их сервисы в России заблокированы. 
Источник изображения: pixabay.com В частности, 25 марта регулятор ограничил работу хостинг-провайдера Kamatera, 27 марта — WPEngine, 29 марта — HostGator.com. Далее последовала блокировка Network Solutions — 1 апреля, DreamHost — 3 апреля, Bluehost — 5 апреля, Ionos — 8 апреля, DigitalOcean — 10 апреля. Наконец, 12 апреля были заблокированы ресурсы GoDaddy, а 15 апреля — сервисы AWS. В отношении указанных провайдеров действуют «полное ограничение доступа к информационному ресурсу иностранного лица» и «запрет на поисковую выдачу». Перечисленные компании зарегистрированы в США. Вместе с тем Роскомнадзор пока не ограничил доступ к сервисам Hetzner Online GmbH и FastComet, которые также входят в перечень иностранных провайдеров хостинга, подлежащих «приземлению» в России.
12.04.2024 [13:00], Сергей Карасёв
Суд обязал AWS выплатить $525 млн за нарушение патентов в сфере облачного хранилищаСуд присяжных в США, по сообщению Datacenter Dynamics, признал облачную платформу Amazon Web Services (AWS) виновной в нарушении патентов чикагской компании Kove. За незаконное использование чужих технологий на AWS наложен штраф в размере $525 млн. Претензии Kove связаны с тем, что ответчик нарушил права на разработки, связанные с системами и методами управления хранилищем данных, а также с поиском и извлечением информации. По заявлениям Kove, AWS без разрешения применяет соответствующие технологии в сервисах S3 и DynamoDB. В 2023 году Kove направила аналогичный иск против Google — это дело в настоящее время находится на стадии рассмотрения. 
Источник изображения: pixabay.com Kove подала иск против AWS в декабре 2018 года. В материалах дела упомянуты три американских патента Kove — №7,814,170, №7,103,640 и №7,233,978. Изобретателями значатся доктор Джон Овертон (John Overton) и доктор Стивен Бейли (Stephen Bailey), причём Овертон является генеральным директором Kove. В своей жалобе истцы заявляют, что технологии Kove имеют большое значение для AWS, поскольку объём данных, хранящихся в облаке Amazon, растёт в геометрической прогрессии, а её облачные сервисы столкнулись с ограничениями в плане обработки и извлечения огромных массивов информации. В 2020 году AWS выступила с опровержениями, отрицая нарушение рассматриваемых патентов и утверждая, что они якобы недействительны и, следовательно, не имеют исковой силы. Однако аргументы AWS не были учтены в суде, а на саму облачную платформу наложен штраф. Вместе с тем присяжные отклонили обвинения в том, что AWS нарушила патенты умышленно. Облачная платформа заявила, что не согласна с вердиктом, и сообщила о намерении подать апелляцию.
10.04.2024 [20:49], Руслан Авдеев
ИИ подождёт: AWS ввела лимиты на облачные ресурсы в Ирландии из-за дефицита энергииЭнергетический кризис в Ирландии, во многом связанный с концентрацией большого числа ЦОД в окрестностях Дублина, может привести к тому, что Amazon Web Services (AWS) начнёт рационировать предоставляемые клиентам облачные ресурсы, передаёт The Register. Некоторые пользователи жалуются на то, что им уже начали ограничивать облачные ресурсы в регионе eu-west-1. В частности, речь идёт об GPU-инстансах, необходимых для ИИ-вычислений. В случае возникновения проблем в AWS Europe предлагают перенести нагрузки в другие европейские регионы, например, в Швецию. AWS подчёркивает, что Ирландия остаётся ядром мировой инфраструктуры компании, поэтому она в любом случае продолжит обслуживание клиентов в этом регионе. Представители национальной энергетической компании EirGrid прямо заявили, что могут время от времени требовать у крупных потребителей ограничить энергопотребление, чтобы избежать проблем во всей сети. Впрочем, обращались ли с такими просьбами к гиперскейлерам, в компании не уточняли. Уклончивость вполне объяснима, поскольку ЦОД вносят огромный вклад в экономику Ирландии. Сейчас в стране насчитывается более 80 дата-центров, включая объекты крупнейших операторов вроде AWS, Microsoft и Google, заодно создающих и многочисленные рабочие места, платящих налоги и обеспечивающих стране доходы. Ещё полтора десятка объектов находятся на стадии строительства, а около 40 ждут разрешения властей. При этом политика властей уже привела к закрытию некоторых ЦОД. 
Источник изображения: Heri Susilo/unsplash.com Местные СМИ отмечают, что роль ЦОД в ирландской экономике весьма спорная. В 2021–2022 гг. энергопотребление ЦОД выросло почти на треть, достигнув 18 % от всех расходов электричества в стране. Более того, Международное энергетическое агентство (International Energy Agency, IEA) утверждает, что без регулирования доля ЦОД может вырасти до 32 % к 2026 году. По оценкам EirGrid этот показатель будет держаться на уровне «всего» 25,7 %, что тоже очень немало. Проблема связана не только с AWS и Ирландией. Энергетические ограничения могут коснуться в будущем Европы и других регионов. По данным IDC, уже ходят слухи об энергетических квотах для клиентов Microsoft Azure, способных повлиять на их бизнесы. Операторы ряда ЦОД уже столкнулись с нехваткой энергии, и расширить её поставки в соответствии со спросом будет довольно трудно. По мнению экспертов, это — одна из причин того, что большинство европейских организаций не спешат закрывать собственные ЦОД и переходить в публичные облака, поскольку те не смогут удовлетворить спрос на мощности десятилетиями. 
Источник изображения: Ilse Orsel/unsplash.com В прошлом году сообщалось, что европейским операторам ЦОД всё труднее обеспечить надёжное и экономически целесообразное энергоснабжение, а в прошлом месяце глава британской энергокомпании National Grid предупредил, что в следующие 10 лет потребление электричества ЦОД в стране может вырасти на 500 %. Один из экспертов, пожелавший остаться анонимным, подчеркнул, что Ирландия, Нидерланды и Сингапур уже опустошили свои энергетические резервы. А в Северной Вирджинии (США) новым дата-центрам, например, попросту не хватает ЛЭП. Операторы идут на отчаянные меры для обеспечения своего бизнеса энергией. Например, AWS недавно купила кампус в Пенсильвании, расположенный вблизи АЭС. Атомными проектами вообще активно интересуются многие операторы дата-центров, включая Microsoft. Пока что в Ирландии и Amazon, и Microsoft вынуждены довольствоваться временными решениями.
08.04.2024 [11:07], Руслан Авдеев
100-МВт солнечная электростанция AmpIn в Раджастхане компенсирует энергозатраты индийских дата-центров AWSИндийская AmpIn Energy Transition (ранее Amp Energy India) ввела в эксплуатацию солнечную электростанцию, компенсирующую потребление электроэнергии дата-центрами Amazon Web Services (AWS). Datacenter Dynamics сообщает, что речь идёт о проекте возобновляемой энергетики общей мощностью 100 МВт (в пике до 135 МВт). Электростанция площадью 235 га расположена в «солнечном парке» Bhadla в пустыне Тар (штат Раджастхан). Как заявляет оператор электростанции, сотрудничество с Amazon над столь значимым проектом подчёркивает приверженность AmpIn к переходу страны на возобновляемую энергетику, а также свидетельствует о поддержке правительственной миссии Цифровая Индия (Digital India). В AmpIn заявляют, что в Раджастхане ей сегодня реализуются проекты по выработке возобновляемой энергии на 1 ГВт. Ранее она заключила энергетическую сделку с Nxtra. 
Источник изображения: AmpIn Energy Площадка Bhadla — один из трёх проектов общей мощностью 420 МВт, в которые инвестирует Amazon в Раджастхане. Кроме того, гиперскейлер участвует ещё в трёх стройках на территории Индии на 500 МВт, а также занят возведением ветряной электростанции на 198 МВт. Компания уже располагает многочисленными солнечными элементами непосредственно на территории своих объектов в Индии — дата-центров, складов и др. Ещё в 2022 году Amazon анонсировала 37 проектов по выработке возобновляемой энергии по всему миру, а в 2023 году и вовсе стала крупнейшим корпоративным покупателем возобновляемой энергии в мире.
08.04.2024 [11:00], Сергей Карасёв
AWS запустила облачный сервис Deadline Cloud для высокопроизводительного рендерингаОблачная платформа Amazon Web Services (AWS) анонсировала полностью управляемый сервис Deadline Cloud, позволяющий клиентам быстро настраивать, разворачивать и масштабировать проекты в области высокопроизводительного рендеринга материалов 2D и 3D. В AWS отмечают, что создание сложной компьютерной графики и визуальных эффектов требует наличия мощных и дорогих вычислительных систем. Для решения этих задач кинематографисты и создатели контента формируют так называемые рендер-фермы, которые объединяют ресурсы сотен и тысяч узлов. Но на формирование таких платформ могут уходить недели и даже месяцы, поскольку процесс требует тщательного планирования и настройки сложной инфраструктуры. Сервис Deadline Cloud позволяет сократить время создания ферм до считаных минут. 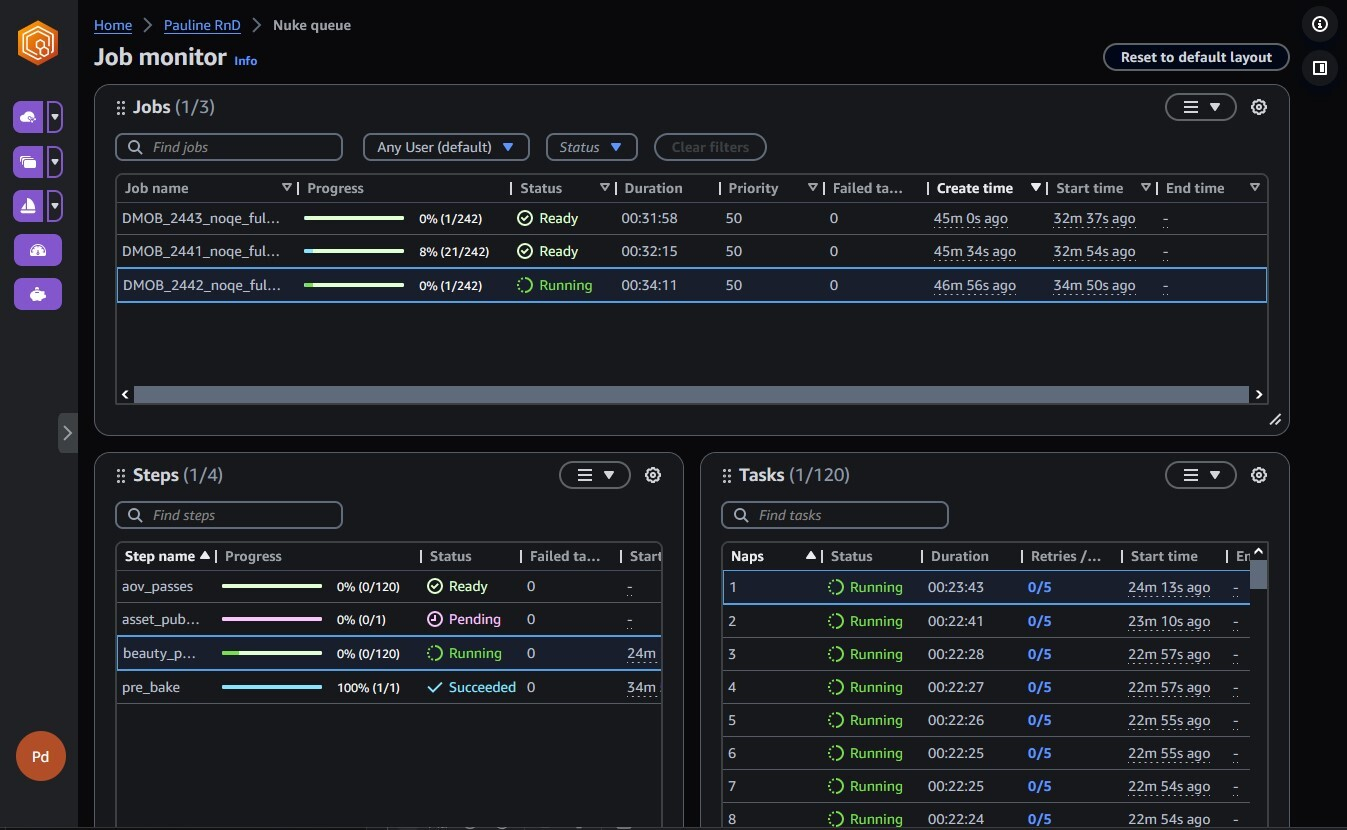
Источник изображений: Amazon Новая система предоставляет удобный и понятный интерфейс для быстрого создания ферм необходимой мощности. При этом отпадает необходимость в сложной настройке backend-инфраструктуры. Благодаря гибкому масштабированию можно использовать необходимое количество вычислительных инстансов — вплоть до тысяч. Это позволяет решать наиболее ресурсоёмкие задачи с минимальными временными затратами, говорит AWS. Предусмотрена возможность интеграции с Autodesk Arnold, Autodesk Maya, Foundry Nuke и SideFX Houdini. 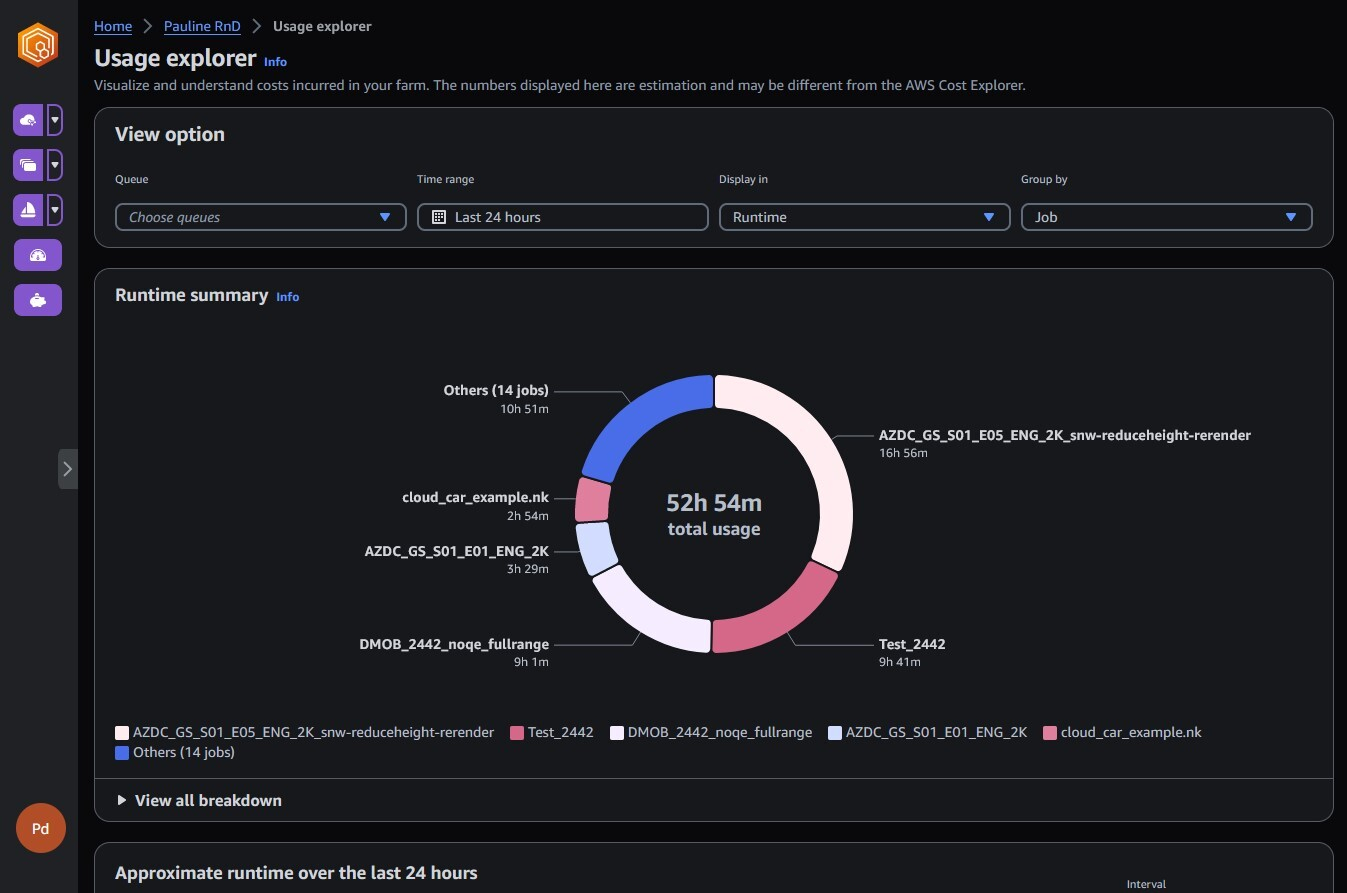 Мастер запуска поможет клиентам сформировать ферму: получив информацию о параметрах проекта, система выделит необходимые для него EC2-инстансы. Deadline Cloud предоставляет единый интерфейс для управления всеми проектами рендеринга. Это позволяет централизованно определять приоритеты для различных задач, просматривать журналы событий и текущее состояние процессов. Платформа Deadline Cloud построена таким образом, что клиенты платят только за те вычислительные ресурсы, которые им нужны, и тогда, когда они им нужны, что минимизирует расходы. Реализованы возможности управления бюджетом, которые помогут лучше изучить затраты на рендеринг для каждого проекта. Клиенты могут просмотреть, сколько ресурсов AWS используется, а также рассчитать примерную стоимость использования этих инстансов.
04.04.2024 [17:37], Руслан Авдеев
AWS намерена уволить сотни сотрудников различных подразделенийКомпания Amazon Web Services (AWS) намерена избавиться от сотен своих сотрудников, включая тех, кто работает в отделе продаж, занимается обучением или трудится в сфере обеспечения розничной торговли. По данным Silicon Angle, IT-гигант уже подтвердил сам факт сокращения штата, не сообщая о точном числе увольняемых. В прошлом году родительская Amazon.com уже провела два раунда масштабных увольнений, последний из которых, состоявшийся в марте 2024 года, также затронул и AWS и привёл к увольнению 9 тыс. человек. Теперь речь идёт о сокращениях в отделах продаж, маркетинга и глобального обслуживания Amazon, часть увольняемых сотрудников занимается продажами в интересах AWS. Другие занимаются обучением и сертификацией клиентов. Речь идёт лишь о части плана по крупной реорганизации подразделения. В частности, клиенты будут или заниматься самообучением, или получать соответствующие услуги у партнёров компании. Кроме того, на решение о сокращении повлиял факт дублирования некоторых ролей в структурах IT-гиганта. По словам старшего вице-президента Мэтта Гармана (Matt Garman), такие решения даются нелегко, но компания ведёт деятельность в быстро меняющейся отрасли и ей приходится всегда оставаться «проворной». 
Источник изображения: Magnet.me/unsplash.com Сокращения предположительно коснутся и т.н. группы Physical Stores Technology — подразделения, разрабатывающего технологии для розничных магазинов Amazon. Ожидается, что некоторые члены группы покинут свои места. Новость появилась вскоре после того, как Amazon объявила о свёртывании проекта Just Walk Out по бесконтактной оплате в своих магазинах Fresh. Система, дебютировавшая в 2016 году, должна была различать, какие продукты покупатели берут со стеллажей и автоматически добавлять их в счёт, автоматически оплачиваемый на выходе без малейшего вмешательства персонала. По слухам, на смену компания планирует внедрить умные тележки Dash Carts, представленные в 2020 году. Они тоже позволят избежать очередей, а встроенные сенсоры будут определять, какой добавляют товар покупатели и даже взвешивать его, если это необходимо. В компании заявляют, что благодаря использованным системам идентификации и расчётов в крупноформатных магазинах Amazon Fresh компания многому научилась и получила хорошую обратную связь. IT-гигант расширяет систему идентификации и расчётов для своих небольших магазинов 1P, а также сторонних торговых точек партнёров. Попавшие под сокращение в США сотрудники получат 60-дневное выходное пособие, а также помощь в трудоустройстве и другую поддержку. Параллельно ищутся «внутренние возможности» для тех, кого затронула реорганизация — облачный гигант, чья выручка выросла в прошлом квартале год к году на 13 %, имеет тысячи свободных вакансий.
03.04.2024 [16:37], Руслан Авдеев
В 2023 году AWS управляла более чем 3,5 млн кв. м ЦОД и офисовКомпания Amazon Web Services (AWS) в 2023 году управляла 3,549 млн м2 площадей дата-центров и офисов. По данным Datacenter Dynamics, такие цифры приводятся в форме годового отчёта K-10, предоставленной компанией государственным регуляторам США. Всего в прошлом году AWS владела 1,651 млн м2 площадей, а ещё порядка 1,899 м2 арендовала. Это на 14 % больше, чем в 2022 году, в котором, в свою очередь, отмечался рост на 28 % в сравнении с 2021 годом. Что касается 2021 года, то тот выдался просто рекордным. Тогдс компания распоряжалась 2,425 млн м2 площадей, на 44 % больше, чем в 2020 году (около 1,682 м2). 
Источник изображения: charlesdeluvio/unsplash.com В отчётности не раскрывается, какая часть площадей приходится на помещения, предназначенные непосредственно для IT-оборудования и инфраструктуры, а сколько — на дополнительные строения иного назначения. Тем не менее речь в любом случае не идёт, например, о штаб-квартирах компании. Кроме того, в расчёт не принимаются изменения в плотности ЦОД. Теоретически AWS способна значительно увеличить вычислительные мощности, не расширяя площадей, хотя это и требует внедрения новых технологий. Сегодня компания управляет 105 зонами доступности в 33 регионах, ещё больше появится в обозримом будущем. Местоположение ЦОД не раскрывается, как и имена партнёрлв-«оптовиков», с которыми сотрудничает компания. Datacenter Dynamics напоминает, что лишь в 2018 году сервис WikiLeaks раскрыл местоположение ЦОД Amazon по состоянию на 2015 год. Компания намерена потратить как минимум $148 млрд в следующие десять лет на инфраструктуру дата-центров, как расширяя существующие площадки, так и строя новые кампусы по всему миру.
29.03.2024 [01:29], Владимир Мироненко
Amazon потратит почти $150 млрд на расширение ЦОД, чтобы стать лидером в области ИИВ ближайшие 15 лет Amazon планирует потратить $148 млрд на дата-центры, что позволит ей справиться с ожидаемым взрывным ростом спроса на приложения ИИ и другие цифровые сервисы, пишет Bloomberg. В прошлом году темпы роста выручки AWS упали до рекордно низкого уровня, поскольку клиенты стремились сократить расходы и откладывали реализацию проектов модернизации. Сейчас их расходы снова начинают расти, и Amazon готовит на будущее землю под расширение ЦОД и договаривается о поставках электроэнергии. Планируемые затраты Amazon на ЦОД превышают обязательства Microsoft и Google (холдинг Alphabet), хотя ни одна из компаний не раскрывает расходы, связанные с ЦОД, так последовательно, как Amazon, отметил Bloomberg. «Мы значительно расширяем мощности, — сообщил Кевин Миллер (Kevin Miller), вице-президент AWS, курирующий дата-центры компании. — Я думаю, это просто даёт нам возможность стать ближе к клиентам». Компания планирует расширить существующие ЦОД в Северной Вирджинии и Орегоне, а также развиваться в новых регионах, в том числе в Миссисипи, Саудовской Аравии и Малайзии. Эти усилия в основном направлены на удовлетворение растущего спроса на корпоративные сервисы, такие как хранение файлов и базы данных. Вместе с тем эти мощности наряду с передовыми ускорителями призваны обеспечить огромную вычислительную мощность, необходимую для ожидаемого бума генеративного ИИ. 
Источник изображения: aboutamazon.com Развивая свои собственные ИИ-инструменты, чтобы конкурировать с ChatGPT компании OpenAI, и сотрудничая с другими компаниями для обеспечения поддержки ИИ-сервисов на своих серверах, Amazon рассчитывает заработать десятки миллиардов долларов. В последние годы Amazon была крупнейшим в мире корпоративным покупателем возобновляемой энергии, что является частью её обязательства обеспечить к 2025 году всю деятельность возобновляемой электроэнергией. Но эту цель реализовать не так уж и просто из-за несоответствия между спросом и предложением, которое вносит неразбериху в раздробленную энергосистему США. Миллер заявил, что компания продолжает оценивать проекты в сфере экологически чистой энергетики, включая использование аккумуляторных батарей и ядерную энергетику, которые позволят заменить электростанции, работающие на ископаемом топливе. Он пообещал найти способ «удовлетворить потребность в энергии благодаря возобновляемой, безуглеродной энергетике». |
|

