Материалы по тегу: arm
|
18.04.2024 [13:23], Сергей Карасёв
Eviden и CEA анонсировали второй суперкомпьютер EXA1 — HE на базе Arm-суперчипов NVIDIA Grace HopperКомпания Eviden (дочерняя структура Atos) и Комиссариат по атомной и альтернативным видам энергии Франции (СЕА) объявили о реализации второй фазы суперкомпьютерной программы EXA1. Она предусматривает ввод в эксплуатацию НРС-комплекса EXA1 HE (High Efficiency) на платформе Eviden BullSequana XH3000. Первая очередь системы — EXA1 HF (High-Frequency) — была запущена в 2021 году. Основой послужила платформа BullSequana XH2000. Изначально машина включала 12 960 процессоров AMD EPYC 7763 (64C/128T, 2,45 ГГц), а её производительность на момент анонса составляла 23,2 Пфлопс. Комплекс EXA1 HE использует 477 вычислительных узлов на базе суперчипов NVIDIA Grace Hopper. Применяется жидкостное охлаждение тёплой водой. Заявленная производительность в тесте Linpack составляет приблизительно 60 Пфлопс, а пиковое быстродействие достигает 104 Пфлопс. Задействован фирменный интерконнект BXI (BullSequana eXascale Interconnect). Сеть основана на топологии DragonFly и состоит из 156 коммутаторов. Отмечается, что суперкомпьютер EXA1 соответствует требованиям оборонных программ, реализуемых военным отделом CEA. 
Источник изображения: Eviden Отметим, что в марте нынешнего года компания Eviden заключила соглашение о модернизации французского НРС-комплекса Jean Zay. Суперкомпьютер получит 1456 ускорителей NVIDIA H100 в дополнение к 416 картам NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. В результате, пиковая производительность Jean Zay поднимется с нынешних 36,85 до 125,9 Пфлопс.
16.04.2024 [16:20], Сергей Карасёв
Завершено строительство Arm-суперкомпьютера Venado на базе суперчипов NVIDIA Grace HopperЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США объявила о завершении сборки НРС-комплекса Venado, предназначенного для решения сложных ресурсоёмких задач в области ИИ. В создании системы приняли участие компании HPE и NVIDIA. Проект Venado был анонсирован в мае 2022 года. Система смонтирована в Центре моделирования и симуляции Николаса К. Метрополиса (Nicholas C. Metropolis) в составе LANL. В церемонии открытия комплекса приняли участие представители Министерства энергетики США, Администрации по национальной ядерной безопасности США и других организаций. Venado — первый в США суперкомпьютер, построенный на суперчипах NVIDIA Grace и Grace Hopper с ядрами Arm. Суперкомпьютер построен на платформе HPE Cray EX. В общей сложности задействованы 2560 гибридных суперчипов Grace Hopper с прямым жидкостным охлаждением: эти изделия объединяют ядра Arm v9 и ускорители на архитектуре Hopper. Кроме того, в состав НРС-системы входят 920 суперчипов Grace. Узлы объединены интерконнектом HPE Slingshot 11. 
Источник изображений: LANL На суперкомпьютере используется специализированное ПО HPE Cray, которое, как утверждается, позволяет оптимизировать рабочие нагрузки по моделированию и симуляции. Систему планируется использовать в таких областях, как материаловедение, возобновляемые источники энергии, астрофизика и пр. ИИ-производительность системы (FP8) составит около 10 Эфлопс. Машина также получит Lustre-хранилище.  «Являясь первым в США суперкомпьютером на базе NVIDIA Grace Hopper, система Venado обеспечивает революционную производительность и энергоэффективность для ускорения научных открытий», — говорит Ян Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA. При этом Venado относится к классу экспериментальных суперкомпьютеров и будет использоваться для переноса и оптимизации имеющихся кодов, а также для создания нового ПО и проверки различных концепций.
10.04.2024 [01:30], Алексей Степин
Google анонсировала Axion, свой первый серверный Arm-процессорКомпания Google объявила о выпуске собственного процессора для своих ЦОД. В основу новинки, получившей имя Axion, легла архитектура Arm, что ставит её в один ряд с Amazon Graviton, Alibaba Yitian и Microsoft Cobalt. Это не первый процессор, разработанный Google: c 2015 года компания успела создать пять поколений ИИ-ускорителей Tensor Processing Units (TPU), а в 2018 она представила процессор Video Coding Unit (VCU) Argos для транскодирования видео. Но Axion стал первым чипом Google, который подпадает под определение «процессор общего назначения». При его создании компания сделала упор не только на энергоэффективность, но и на высокий уровень производительности, достаточный для использования в современных серверах. 
Источник изображений: Google В основу Axion легли Armv9-ядра Neoverse V2 (Demeter). Этот же дизайн используется в AWS Graviton4 и NVIDIA Grace. К сожалению, архитектурных подробностей Google пока не раскрывает, известно лишь, что ядра Neoverse V2 работают совместно с фирменными контроллерами Titanium. Последние отвечают за работу с сетью, защиту и разгрузку IO-операций при работе с блочным хранилищем Hyperdisk, то есть чем-то напоминают AWS Nitro. При этом Google вложилась в SystemReady Virtual Environment (VE), чтобы упростить перенос нагрузок на новые чипы как для себя, так и для пользователей облака. 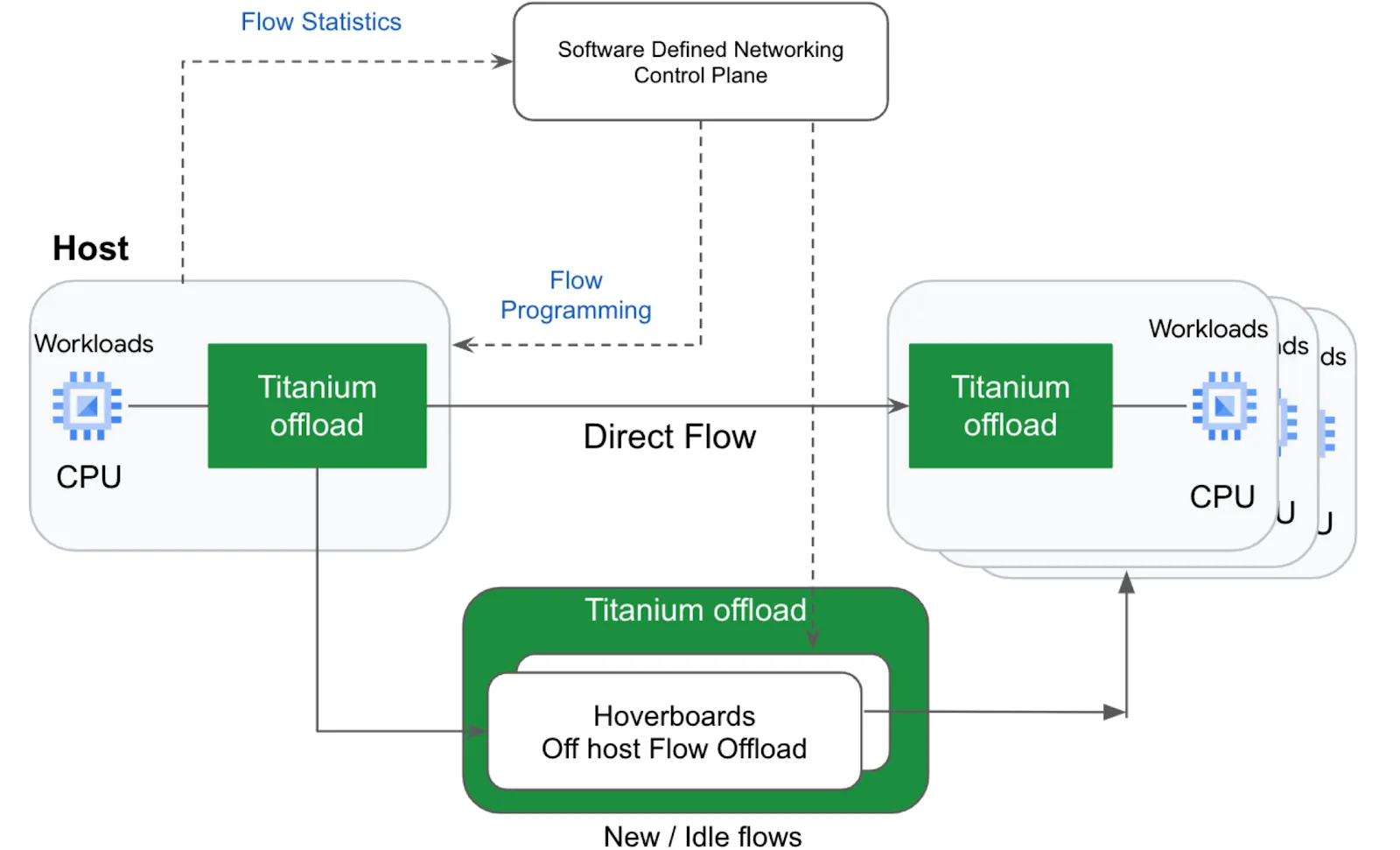 Если верить разработчикам, на момент анонса Google инстансы на базе Axion минимум на 30 % производительнее инстансов на базе самых быстрых Arm-процессоров других вендоров, а по сравнению с сопоставимыми по классу x86-процессорами преимущество может достигать и 50 % при 60 % выигрыше в энергоэффективности. Судя по всему, Axion ранее был известен под кодовым именем Cypress. А ещё один Arm-процессор Google Maple, который, по слухам, являлся наследником почивших Marvell ThunderX, в серию, видимо, не пошёл. Сама компания уже начала переводить на Axion сервисы BigTable, Spanner, BigQuery, Blobstore, Pub/Sub, Google Earth Engine и YouTube Ads. Ряд клиентов и партнёров Google уже оценили Axion по достоинству. Виртуальные машины с новыми процессорами будут доступны в ближайшие месяцы. Они же будут доступны и в Kubernetes Engine, Dataproc, Dataflow, Cloud Batch и т.д.
10.03.2024 [22:13], Сергей Карасёв
Arm-процессор SiPearl Rhea2 для европейских суперкомпьютеров выйдет в 2025 годуКонсорциум European Processor Initiative (EPI) раскрыл планы по выпуску HPC-процессоров нового поколения с архитектурой Arm. Речь идёт о чипах Rhea2, которые, как ожидается, войдут в состав следующего европейского суперкомпьютера экзафлопсного уровня. Разработчиком изделий Rhea является французская компания SiPearl. Процессор первого поколения на базе Arm Neoverse V1 обладает высокой энергетической эффективностью. Он производится на предприятии TSMC с использованием 6-нм технологии N6. Чип станет основой одного из блоков экзафлопсного суперкомпьютера Jupiter, который в нынешнем году будет запущен в Юлихском исследовательском центре (FZJ) в Германии. О процессоре Rhea2 информации пока не слишком много. Известно, что он получит двухчиплетную компоновку. Ожидается, что будет реализована поддержка памяти HBM и DDR5. Разработчик переведёт Rhea2 на более «тонкий» по сравнению с чипом первого поколения техпроцесс. 
Источник изображения: EPI Сообщается, что Rhea2 дебютирует в 2025 году. Процессор будет задействован в новом европейском НРС-комплексе — вероятно, в системе «Жюль Верн» (Jules Vernes), которая расположится во Франции. Ввод этого суперкомпьютера в эксплуатацию запланирован на 2026 год. Создание машины финансируется Евросоюзом, Францией и Нидерландами, а её управление возьмёт на себя Французское национальное агентство по высокопроизводительным вычислениям (GENCI), которое на 49 % принадлежит французскому правительству. Генеральный директор SiPearl Филипп Ноттон (Philippe Notton) отметил, что разработка чипа Rhea2 проходит быстрее, поскольку компания многому научилась при создании изделия первого поколения и учла допущенные ошибки. Он добавил, что SiPearl сотрудничает со многими партнёрами, включая NVIDIA, AMD и Intel, но вдаваться в подробности о характеристиках Rhea2 не стал. Эксперты полагают, что Rhea2 будет использовать ядра Neoverse 3 (Poseidon).
26.02.2024 [13:44], Сергей Карасёв
Одноплатный компьютер Milk-V Duo S с ядрами RISC-V и Arm стоит от $11Компания Shenzhen MilkV Technology (Milk-V), по сообщению ресурса Liliputing, начала приём заказов на одноплатный компьютер Duo S — одно из первых изделий на аппаратной платформе Sophgo SG2000. Новинка предназначена для создания интеллектуальных устройств Интернета вещей (AIoT). Чип SG2000 объединяет два 64-битных ядра RISC-V C906 (Alibaba T-head) с частотами 1000 и 700 МГц, а также одно ядро Arm Cortex-A53 с частотой 1000 МГц. Кроме того, присутствует NPU-блок с производительностью 0,5 TOPS на операциях INT8. Отмечается, что ядра RISC-V и Arm пока невозможно использовать одновременно: один из двух режимов работы выбирается при старте системы. 
Источник изображения: Milk-V Изделие имеет размеры 43 × 43 мм. В оснащение входят 512 Мбайт оперативной памяти DDR3, слот для карты microSD и сетевой контроллер 10/100MbE с разъёмом RJ-45. Кроме того, есть по одному порту USB Type-C (данные и питание) и USB 2.0 Type-A, две 26-контактные колодки GPIO. Поддерживаются интерфейсы MIPI-CSI (две линии) и MIPI-DSI (четыре линии). Одноплатный компьютер Milk-V Duo S предлагается в четырёх модификациях. Базовая версия стоит $11, тогда как модель с поддержкой Wi-Fi 6 и Bluetooth 5 оценена в $14. Эти варианты также могут быть дополнены флеш-модулем eMMC вместимостью 8 Гбайт — такие версии стоят $16 и $20 соответственно. Причём старшая модель комплектуется платой расширения PoE HAT. Возможно использование платформ Linux и RTOS.
23.02.2024 [01:27], Алексей Степин
Arm представила процессорные ядра Neoverse N2 и V3: упор на ИИКомпания Arm продолжает развивать инициативу Neoverse Compute Subsystem (CSS), анонсировав два новых ядра, Neoverse N3 (Hermes) и V3 (Poseidon), рассчитанных на техпроцессы 2–5 нм. Они являются преемниками N2 (Perseus) и V2 (Demeter), а упор в их архитектуре сделан главным образом на повышении производительности в задачах ИИ. Платформа CSS представляет собой комплект IP-блоков Arm, включающий в себя помимо собственно процессорных ядер подсистемы интерконнекта, контроллеры памяти, блоки ввода-вывода и управления питанием и тому подобную «обвязку», облегчающую создание и вывод на рынок новых SoC. 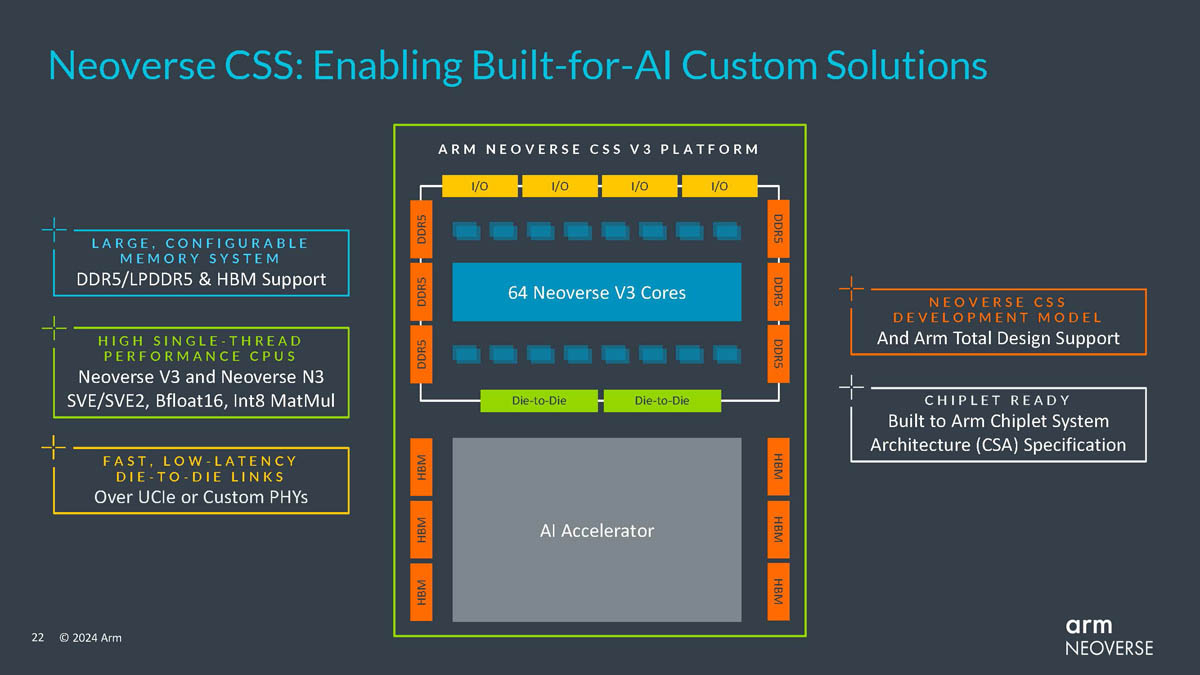
Источник изображений здесь и далее: Arm via ServeTheHome Будущие процессоры на базе Neoverse V3 получат до 64 ядер Armv9-A (v9.2) на кристалл и до 128 на сокет — в виде сборки из двух 64-ядерных кристаллов. Каждый из таких кристаллов получит шесть каналов (LP)DDR5, но также заявлена поддержка HBM3. Поддерживаются двухсокетные конфигурации. Более того, у V3 есть два блока для объедениия с чиплетами, а основным интерфейсом является UCIe 1.1, причём Arm прямо говорит о возможности подключения ИИ-ускорителя, как это сделано в NVIDIA Grace Hopper. Помимо интерконнекта для чиплетных сборок V3 будет располагать собственными контроллерами I/O с поддержкой PCIe 5.0 и CXL 3.0 — до 64 линий. 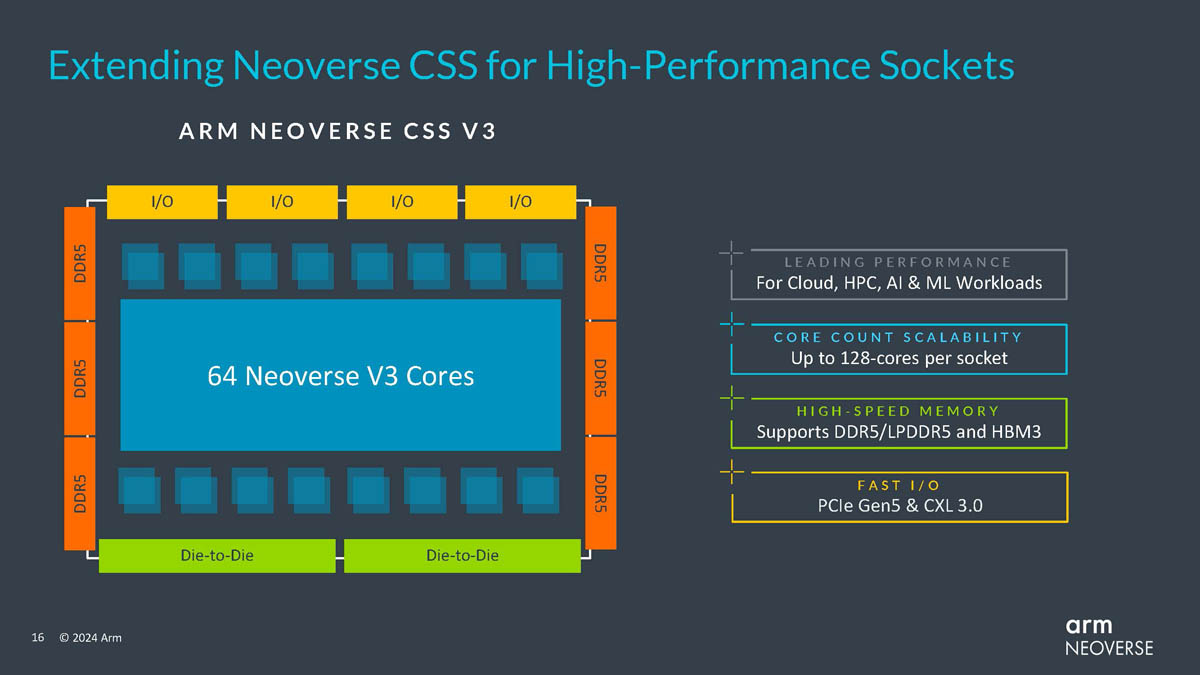 В подавляющем большинстве сценариев прирост относительно V2, обещанный Arm, не слишком велик и составляет от 9 % до 16 %, но вот производительность в ИИ-задачах подтянута аж на 84 %, что однозначно указывает на позиционирование новых ядер — это, в первую очередь, рынок гиперскейлеров, которые сегодня почти поголовно заинтересованы в применении ИИ-технологий. Сами ядра имеют по 64 Кбайт L1-кеша для инструкций и данных и до 3 Мбайт L2-кеша. Интереснее всего поддержка SVE2, но ширину и количество этих SIMD-блоков компания не раскрывает.  В N3 ядер меньше, от 8 до 32, а главным улучшением снова стала повышение энергоэффективности. Относительно N2 процессор N3 будет на 20 % быстрее в пересчёте на Вт. Максимальный теплопакет для 32-ядерного варианта составит всего 40 Вт. Этот дизайн должен найти своё применение в DPU и телекоммуникационных решениях. Сами ядра здесь точно такие же, что в V3, но L1-кеши можно урезать до 32 Кбайт, а L2-кеш не может быть больше 2 Мбайт. N3 также поддерживает объединение двух блоков ядер в одном чипе, двухсокетные конфигурации и UCIe-подключение стороннего чиплета, но для этого тут есть только один блок. Количество линий PCIe 5.0/CXL 3.0 вдвое меньше, до 32 шт. Каналов памяти (LP)DDR5 всего четыре.  Прирост по сценариям применения относительно N2 здесь выглядит иначе: серьёзное внимание уделено задачам сжатия и декомпрессии данных и работе с СУБД. Однако упор на ИИ-нагрузки тут даже более серьёзный, нежели у старшего собрата — прирост производительности может достигать 196 % относительно N2. Правда, в случае и N3, и V3 речь идёт о вполне конкретной библиотеке XGBoost. 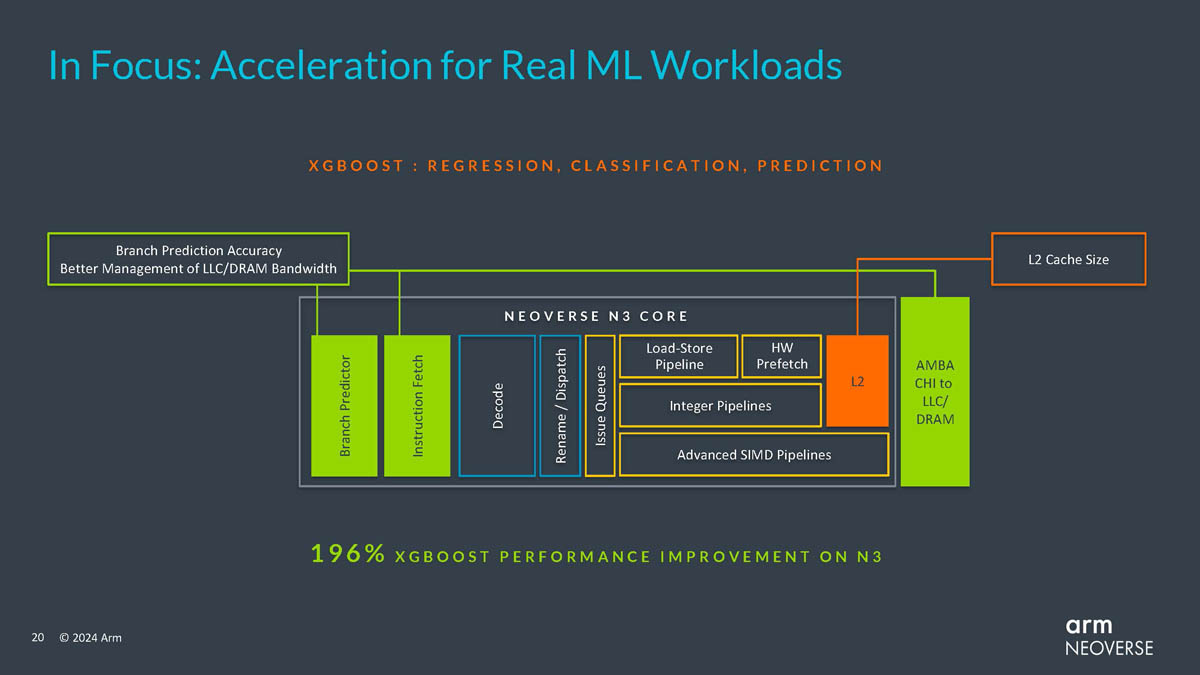 В арсенале Arm также есть ядро E3, о котором, впрочем, компания пока ничего не рассказала. Упомянуто лишь, что эта платформа ориентирована на сценарии с «прокачкой» больших объёмов данных. Заодно компания поделилась именами будущих решений четвёртого поколения. Платформа V-серии получит имя Vega с процессорными ядрами Adonis, N-серия станет называться Ranger с ядрами Dionysus, а E-серия пока никак не названа, но для ядер выбрано имя Lycius. 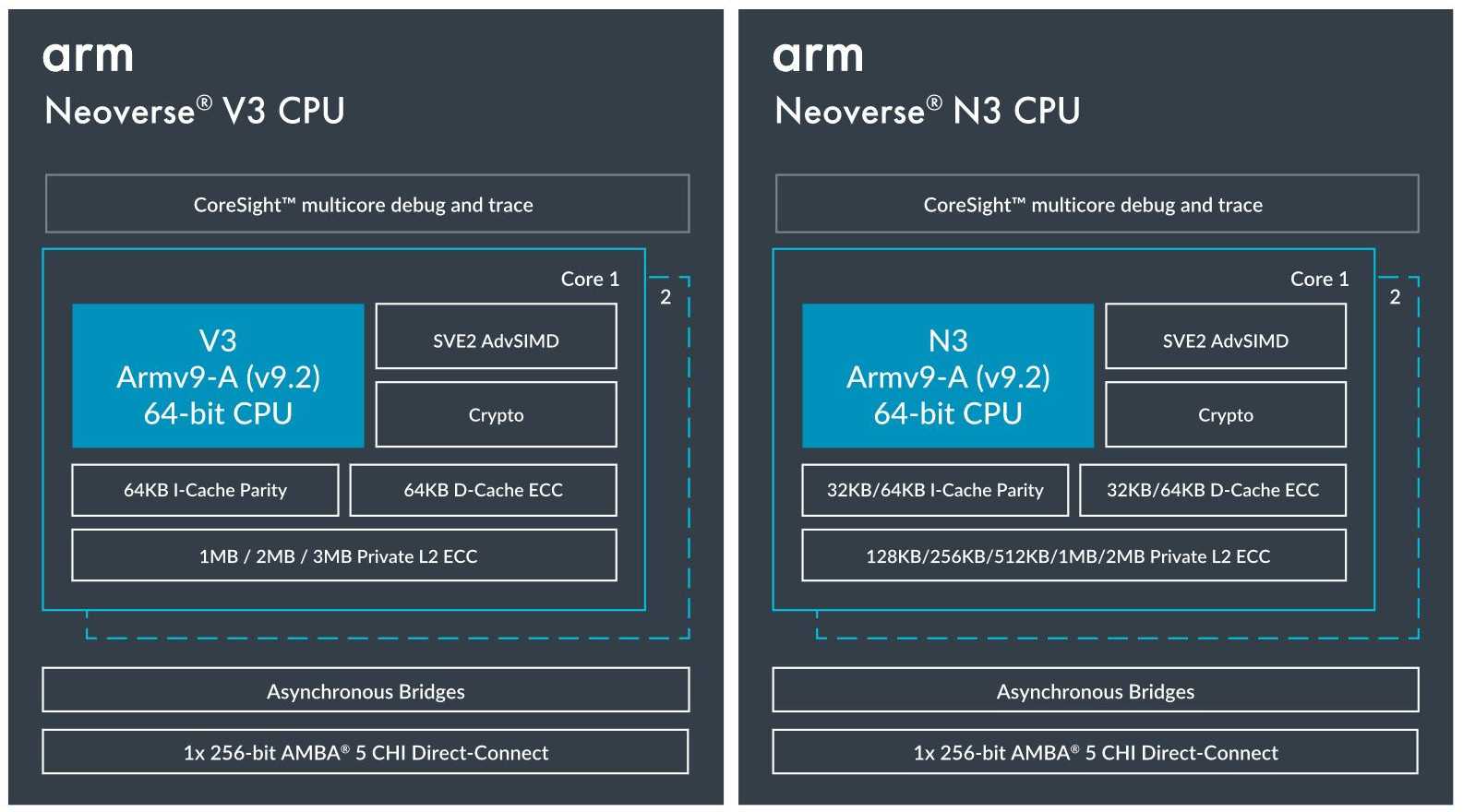 Arm не без оснований считает новые платформы и ядра лучшим поколением Neoverse на данный момент. Компания уверена в том, что за её экосистема станет основой вычислительных решений нового поколения, в том числе для ИИ. Конкурировать новым решениям предстоит, в том числе, с лучшими процессорами Intel и AMD. Сама Intel собирается поддерживать разработку технологий на базе Arm, предоставляя как интеллектуальную собственность, так и производственные мощности. 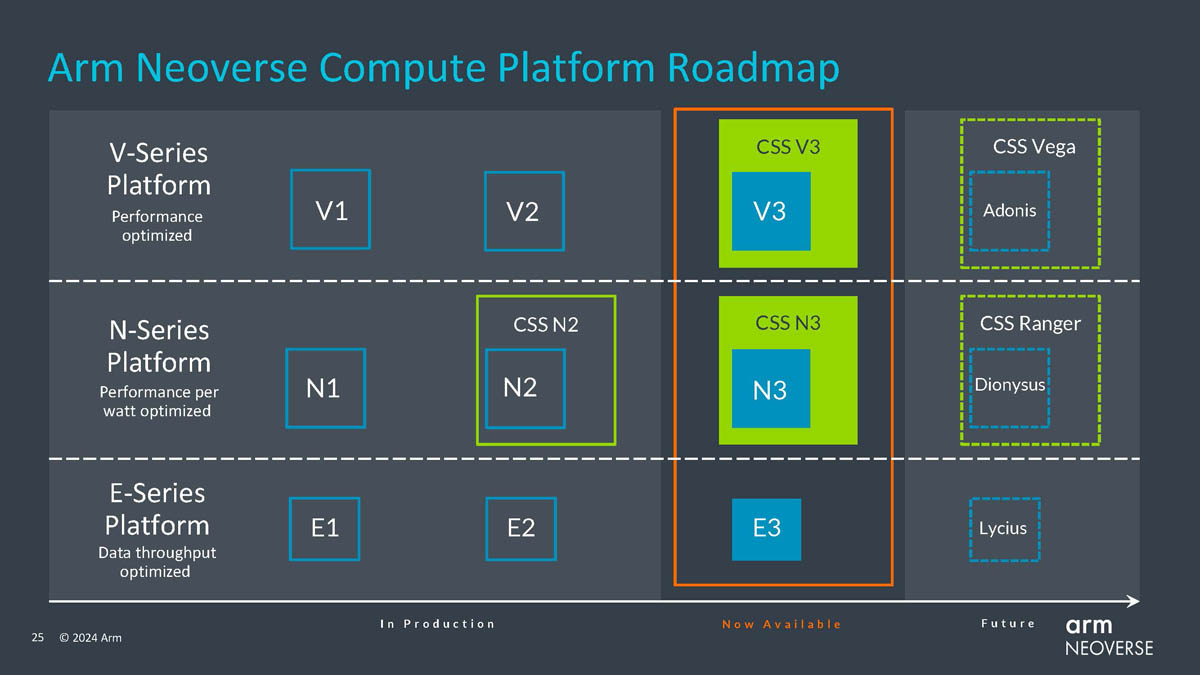 Последние два года стали для Arm весьма успешным в деле освоения рынка ЦОД. NVIDIA представила Grace и Grace Hopper, AWS создала уже четвёртое поколение собственных процессоров Graviton, Microsoft показала свой первый CPU Cobalt 100, да и Google трудится над процессорами Maple и Cypress. А основатель Oracle, которая активно перебирается на чипы Ampere, и вовсе считает, что архитектура Intel x86 теряет актуальность для серверов. Про доминирование Arm в сегменте DPU и говорить нечего.
12.02.2024 [13:43], Алексей Степин
Faraday Technology создаст 64-ядерные Arm-процессоры на основе техпроцесса Intel 18AНа прошлой неделе контрактный разработчик микроэлектронных устройств, компания Faraday Technology раскрыла свои планы, в которые входит создание 64-ядерного процессора с архитектурой Arm Neoverse. Главной сферой применения новой SoC компания видит крупные ЦОД гиперскейлеров, периферийные серверные системы и инфраструктуру 5G. В состав чипа войдут элементы, разработанные в рамках инициативы Arm Total Design, правда, пока неизвестно, какие именно. Также компания не сообщила, какой именно дизайн ядер Neoverse она планирует использовать, но с учётом планов на 2025 год — скорее всего, речь идёт о Neoverse V2. Следовательно, SoC получит поддержку DDR5, PCI Express 5.0 и CXL 2.0. 
Источник здесь и далее: Intel Но наиболее интересным в этом проекте представляется достижение договорённостей с Intel — будущий процессор Faraday будет выпускаться на контрактных мощностях Intel Foundry Services, причём с использованием весьма передового техпроцесса 18A (класс 1,8 нм). Новинка должна увидеть свет в I половине следующего года. Как утверждает сама Intel, техпроцесс 18A, внедрение которого начнётся уже в первом квартале, позволит получить коммерческие продукты на его основе уже во II половине текущего года, в то время как конкурирующий TSMC N2 (класс 2 нм) будет развёрнут не ранее II полугодия 2025 года. Также известно, что Faraday не планирует продавать сами процессоры, но предложит дизайн нового SoC клиентам для дальнейшей адаптации под конкретные нужды. Имена заказчиков Faraday не раскрывает, но, судя по всему, разработчики уверены в востребованности своего будущего детища. Faraday в основном известна тем, что помогает компания переводить FPGA-прототипы в готовые ASIC.  О плодотворности союза Faraday и IFS заявили руководители обеих структур. Для Faraday такое сотрудничество означает получение допуска к самым продвинутым технологическим процессам и ускорение вывода на рынок передовых решений, а Intel Foundry Services получит крупного заказчика с передовым продуктом на базе быстро набирающей популярность серверной архитектуры. Стоит отметить, что IFS и Arm заключили соглашение с целью создания однокристальных платформ на базе передовых техпроцессов Intel ещё в апреле прошлого года. Похоже, инициатива Faraday поможет, наконец, получить первые серьёзные плоды в этой области.
09.02.2024 [23:02], Алексей Степин
Sophgo представила гибридные SoC, сочетающие ядра Arm и RISC-VКомпания Sophgo, китайский разработчик тензорных нейрочипов и процессоров с архитектурой RISC-V, анонсировала универсальные SoC SG2000 и SG2002. Они способны работать с несколькими операционными системами одновременно, в частности, Linux, Android и FreeRTOS. Для этого разработчики снабдили новинку процессорными ядрами разных типов — RISC-V, Arm Cortex-A, Intel 8051, а также отдельным ИИ-сопроцессором. Решения предназначены для «умного интернета вещей» (Artificial Intelligence of Things, AIoT), включая «умные» IP-камеры и контроллеры систем умного дома. При этом микросхемы очень компактны, корпуса LFBGA имеют габариты всего 10 × 10 × 1,3 мм с 205 контактами. Они способны работать в диапазоне температур 0-70 °C. Архитектура новых процессоров Sophgo действительно необычна: в состав входят два 64-битных ядра RISC-V C906 с частотами 1000 и 700 МГц, одно ядро Arm Cortex-A53 с частотой 1000 МГц, а также ядро контроллера 8051 с варьирующейся от 25 до 300 МГц частотой; последнее используется для задач реального времени и имеет собственный небольшой объём SRAM. 
Источник здесь и далее: Sophgo via CNX Software Графического ускорителя в составе новых SoC нет, однако средства обработки видеопотока имеются: блок VPU поддерживает кодирование и декодирование в форматах H.264/H.265 с разрешением 5К@30. Интегрированный NPU для работы с INT8 имеет мощность 0,5 Топс у SG2000 и 1 Топс у SG2002. Объём интегрированной оперативной памяти составляет 512 или 256 Мбайт. 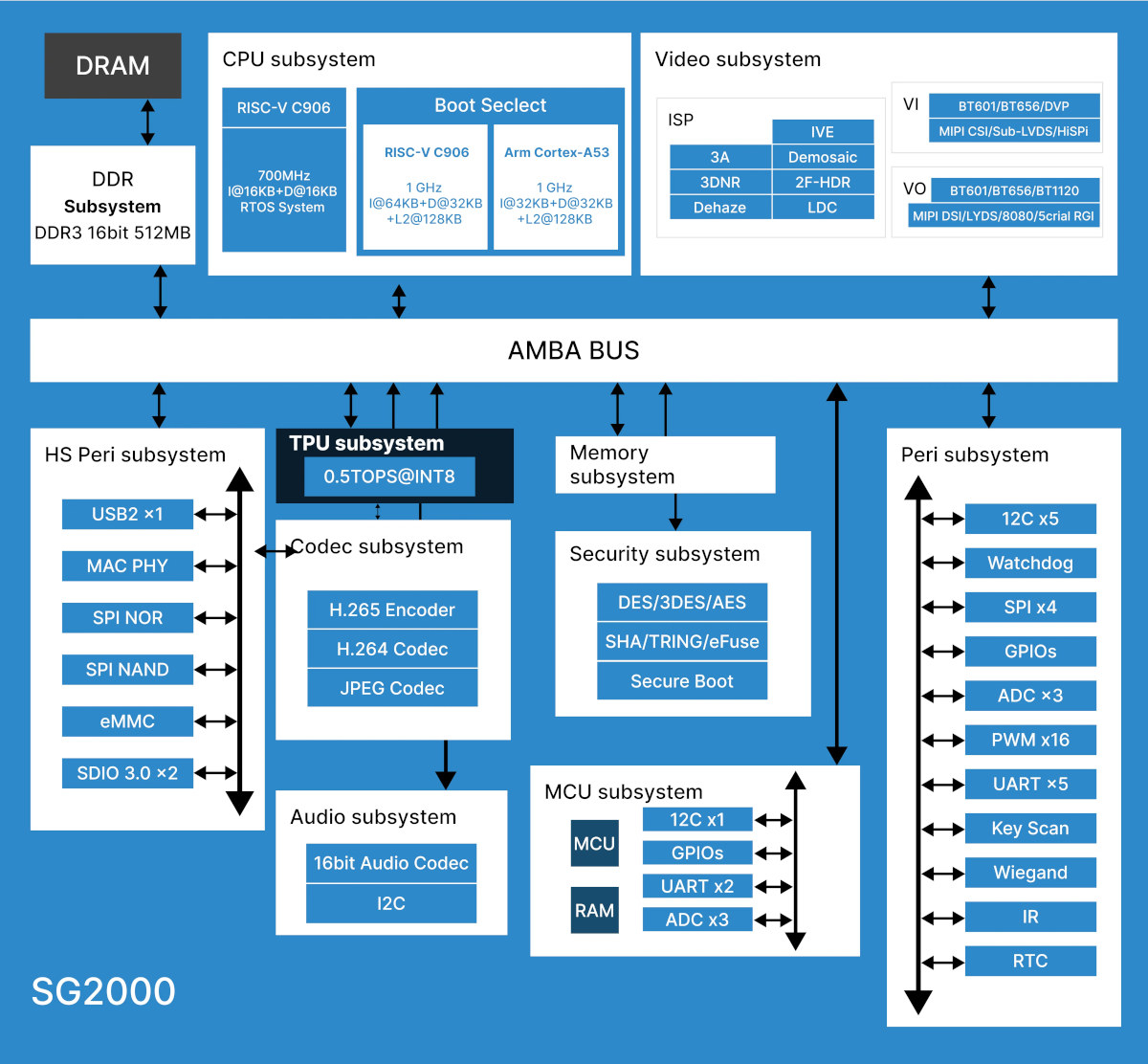 Подключение дисплеев реализовано через интерфейс MIPI DSI, поддерживаются разрешения вплоть до 2880 × 1620@30, имеется четыре линии MIPI CSI для подключения модулей видеокамер. Также предусмотрен 16-битный аудиокодек с двумя шинами I2S и микрофонным входом DMIC. Есть контроллеры 100 Мбит/с Ethernet и USB 2.0. 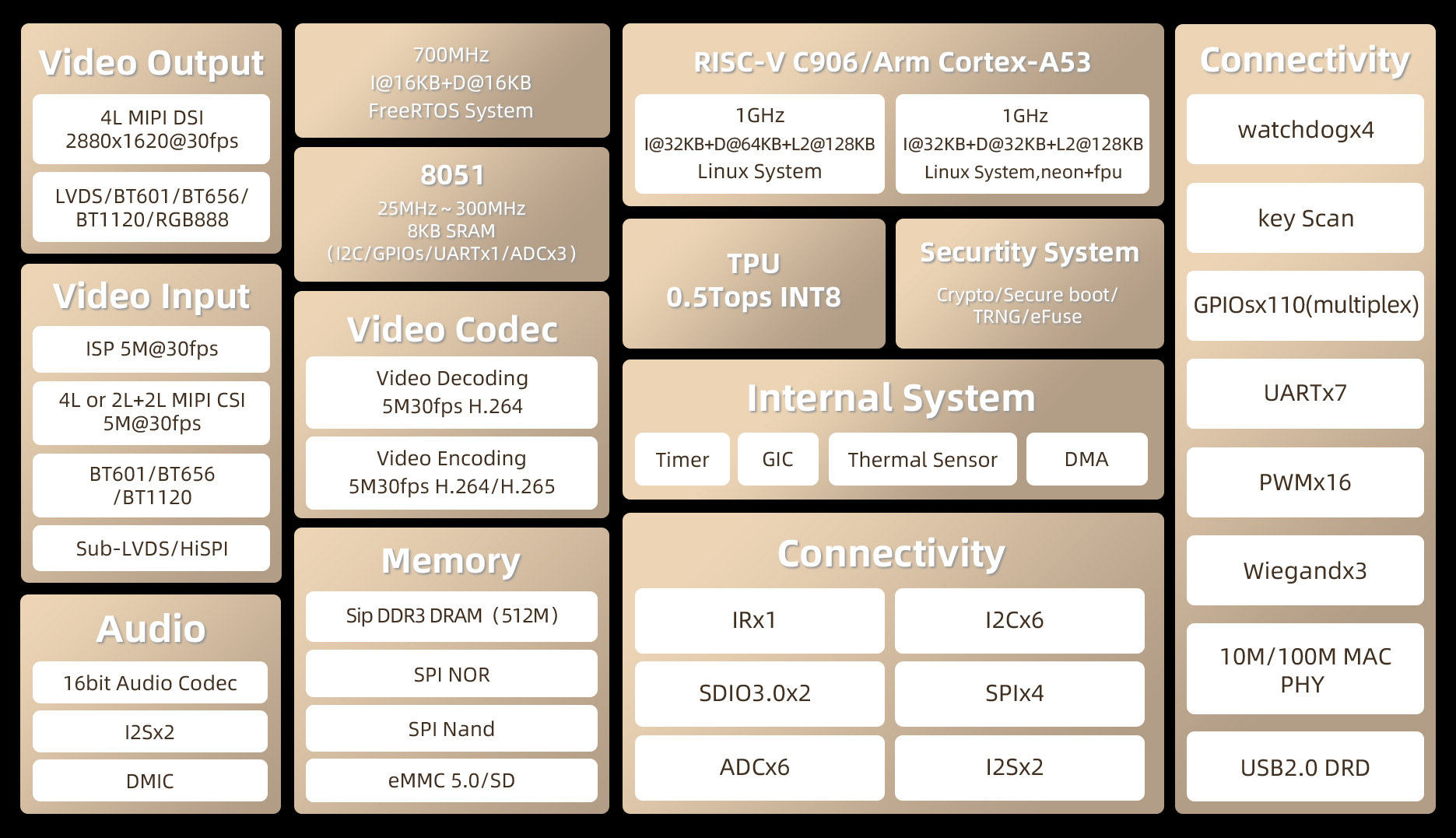 Широко представлены интерфейсы для подключения различной низкоскоростной периферии: 5 × UART, 4 × SPI, 16 × PWM, 1 × IR, 6 × I2C, 6 × ADC и до 128 линий GPIO. Не забыты средства безопасности: чипы имеют собственные криптоблоки с аппаратными генераторами случайных чисел, поддерживают безопасную загрузку и располагают комплектом «пережигаемых предохранителей» (e-fuse). 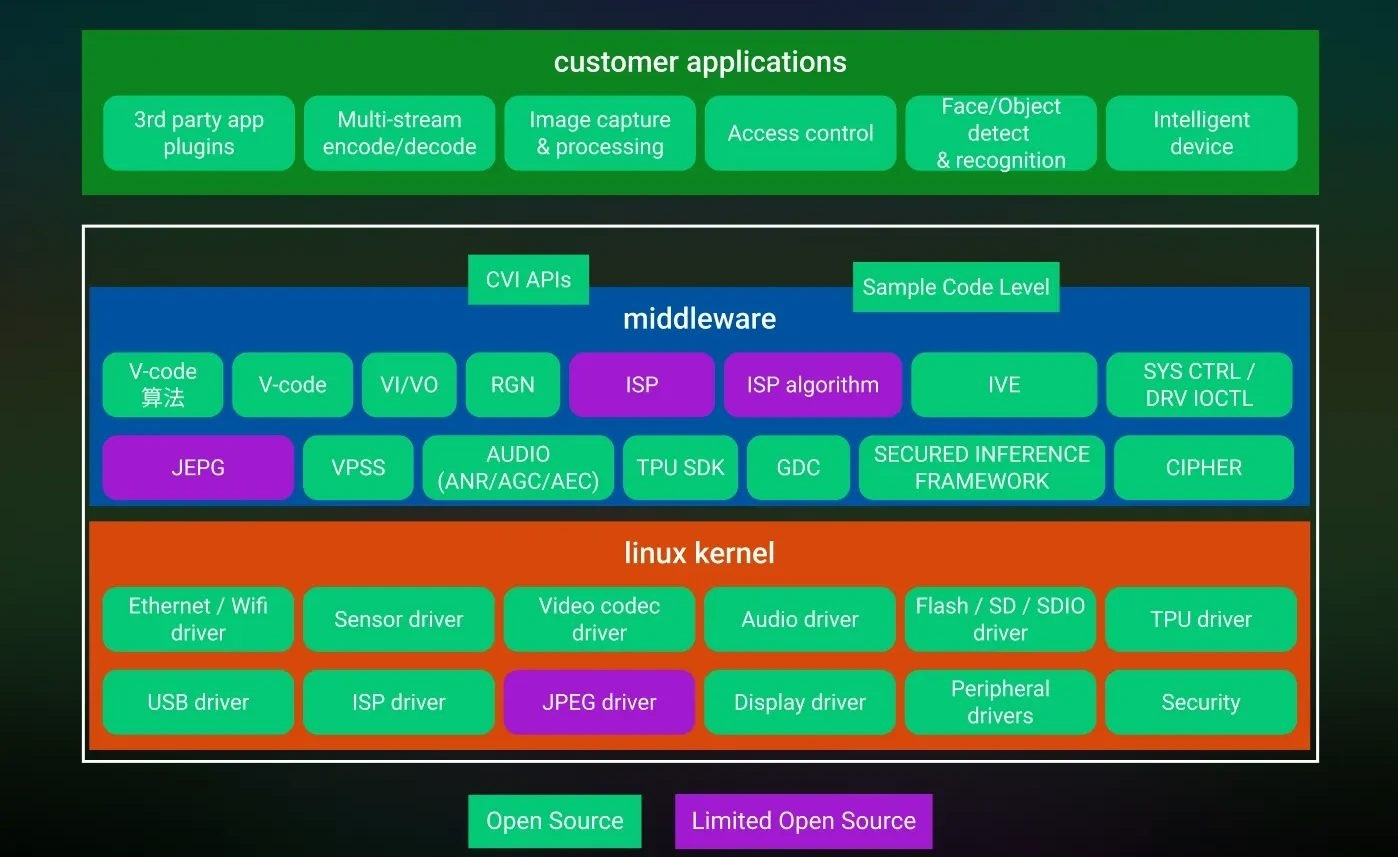 Разработчик заявляет о поддержке SDK на базе Linux 5.10, однако на момент анонса программные компоненты ещё не были полностью доступны. Если верить опубликованным слайдам, SDK планируется весьма развитое, включая поддержку Arduino-сред для одного из ядер RISC-V (с частотой 700 МГц). На базе новых чипов анонсировано сразу три одноплатных решения: Shenzhen MilkV Technology Duo S (SG2000) и Duo 256M (SG2002), а также Sipeed LicheeRV Nano (SG2002). Последний вариант уже доступен на Aliexpress, к нему также имеется первичная документация и репозиторий на GitHub.
09.01.2024 [13:14], Сергей Карасёв
ASRock Rack представила серверы с Arm-процессорами Ampere AltraКомпания ASRock Rack анонсировала серверы 1U10E-ALTRA/1L2T и 4U2G-ALTRA/2T, выполненные в форм-факторе 1U и 4U соответственно. Новинки рассчитаны на работу с одним Arm-процессором Ampere Altra Max / Ampere Altra в исполнении LGA 4926. Серверы располагают восемью слотами для модулей DDR4-3200 суммарным объёмом до 2 Тбайт. В оснащение входят контроллеры ASPEED AST2500, а также Intel X550 (два порта RJ-45 10GbE) и Intel i210 (один порт RJ-45 1GbE). 
Источник изображений: ASRock Rack Модель 1U10E-ALTRA/1L2T оборудована десятью фронтальными отсеками для SFF-накопителей NVMe (PCIe 4.0 x4), одним слотом PCIe 4.0 x16 для карты расширения FHFL и двумя коннекторами M.2 2280/2230 (PCIe 4.0 x4). Питание обеспечивают два блока мощностью 650 Вт с сертификатом 80 Plus Platinum. В свою очередь, сервер 4U2G-ALTRA/2T наделён четырьмя внутренними посадочными местами для накопителей NVMe (PCIe 4.0 x4), четырьмя слотами PCIe 4.0 x16, разъёмом PCIe 4.0 x8 для карты FHFL и двумя коннекторами M.2 (PCIe 4.0 x4). Установлен блок питания на 1100 Вт с сертификатом 80 Plus Gold.  В новинках применяется воздушное охлаждение. Диапазон рабочих температур — от +10 до +35 °C. Помимо сетевых портов, есть четыре разъёма USB 3.2 Gen1 Type-A и интерфейс D-Sub. Говорится о совместимости с RHEL 8.5, RHEL 9.2, CentOS-Stream 8 и CentOS-Stream 9.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев. Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200. |
|


