Материалы по тегу: qualcomm
|
10.04.2024 [00:31], Николай Хижняк
Qualcomm представила энергоэффективный Wi-Fi чип для IoT и платформу RB3 Gen 2 для роботовQualcomm представила двухдиапазонный Wi-Fi чип QCC730, обеспечивающий улучшенную дальность работы и скорость передачи данных при сниженном потреблении энергии. Новинка предназначена для устройств интернета вещей (IoT). Qualcomm заявляет для него уменьшение энергопотребления на 88 % по сравнению с решением предыдущего поколения. Новый Wi-Fi-чип предлагает прямое подключение к облаку, интеграцию с Matter, открытый SDK а также возможность разгрузки подключения к облаку через программный стек. Он представлен как альтернатива Bluetooth для IoT-приложений и может функционировать в том числе в хост-режиме. Впрочем, возможности QCC730 весьма скромны, хотя и достаточны для IoT. Он предлагает поддержку Wi-Fi 4 (802.11a/b/g/n) в конфигурации 1×1 с шириной канала 20 МГц и канальной скоростью менее 30 Мбит/с (MCS3). «Сердцем» SoC является ядро Cortex-M4F. 
Источник изображений: Qualcomm Помимо QCC730 компания Qualcomm также представила ИИ-платформу для роботов RB3 Gen 2 корпоративного и промышленного назначения. В состав платформы входит процессор Qualcomm QCS6490 (8 ядер с частотой до 2,7 ГГц) с графическим ядром Adreno 643. Для неё заявляется поддержка нескольких датчиков камеры, а также наличие встроенного модуля Wi-Fi 6E. Кроме того, RB3 Gen 2 предлагает поддержку Bluetooth 5.2 и LE-аудио.  Платформа RB3 Gen 2 предназначена для широкого спектра продуктов, включая дроны, камеры и другие промышленные устройства. Комплекты для разработчиков включают блок питания, динамики, USB-кабель и плату. Qualcomm также предлагает Vision Kits с монтажными кронштейнами и камерами CSI. Для заинтересованных клиентов платформа Qualcomm RB3 Gen 2 станет доступна в июне этого года.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 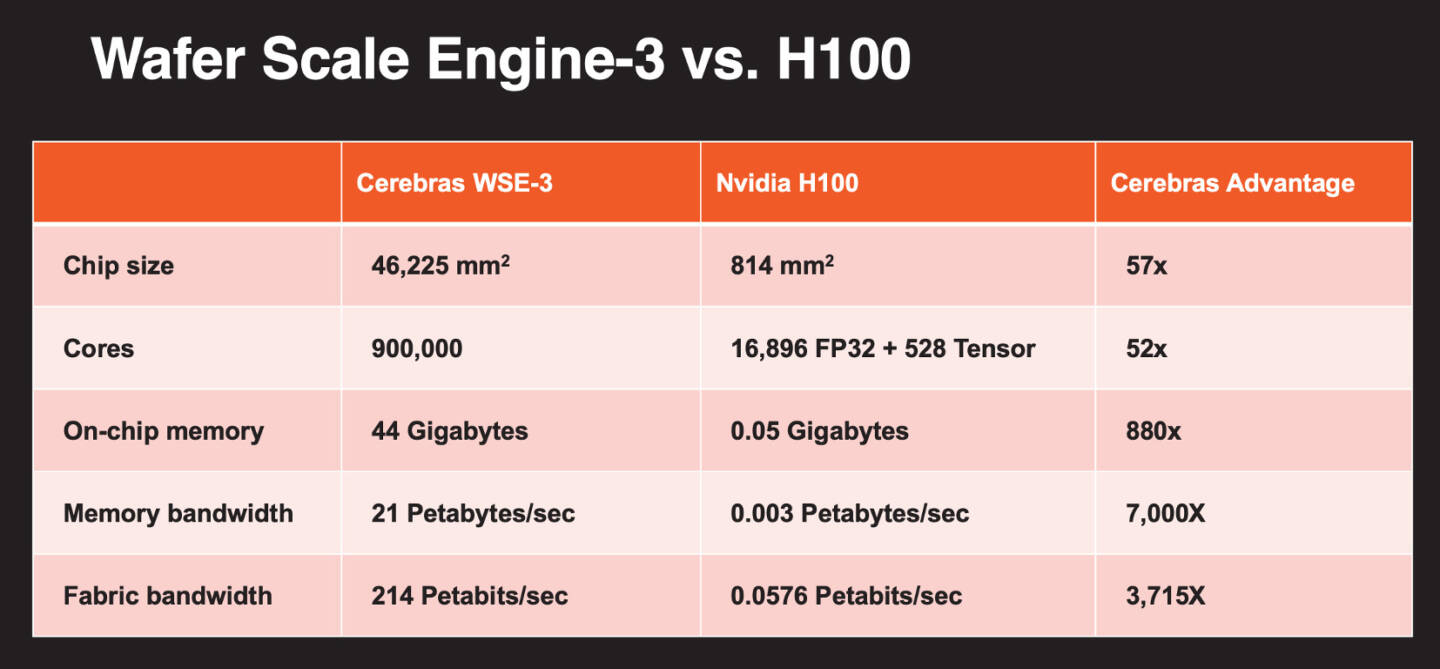 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 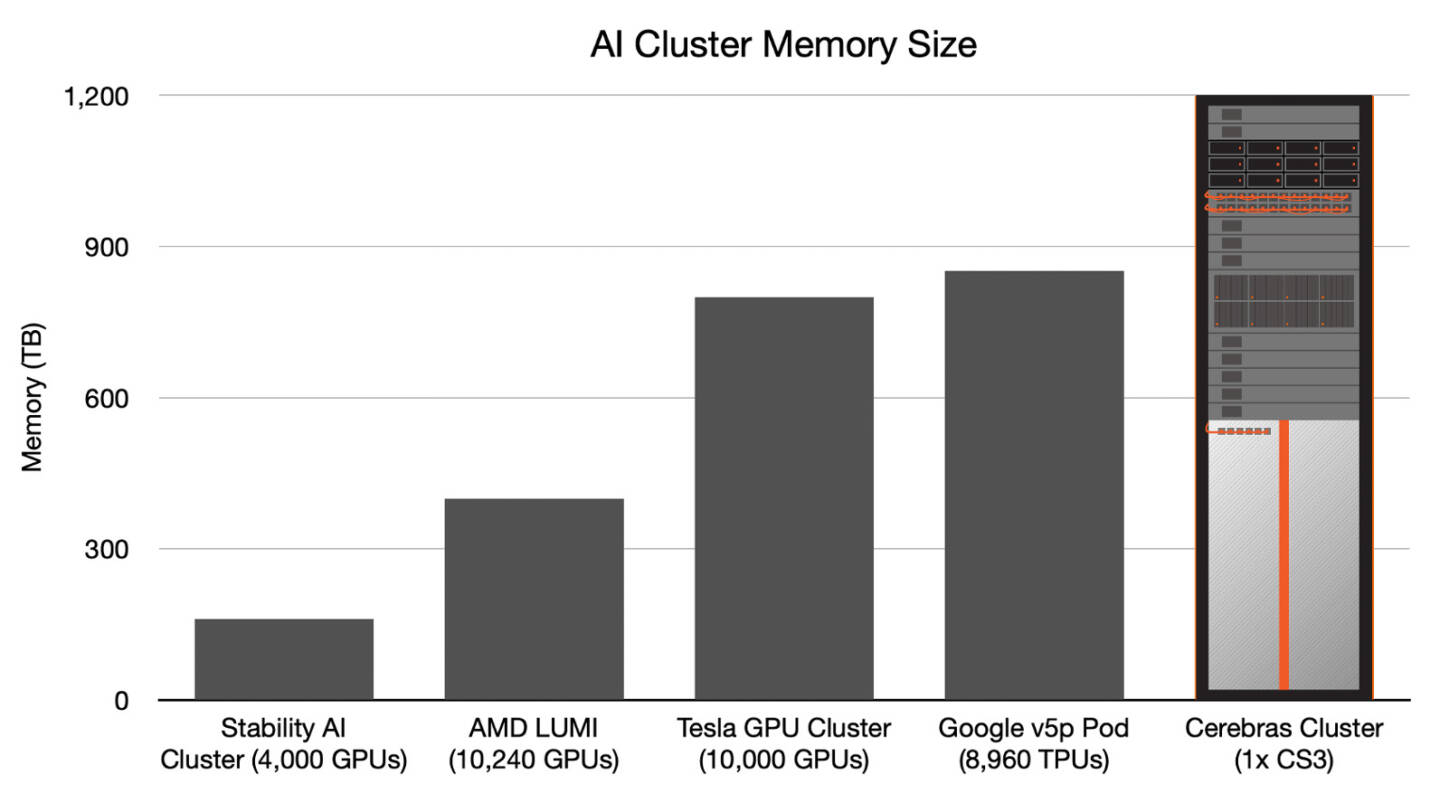 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 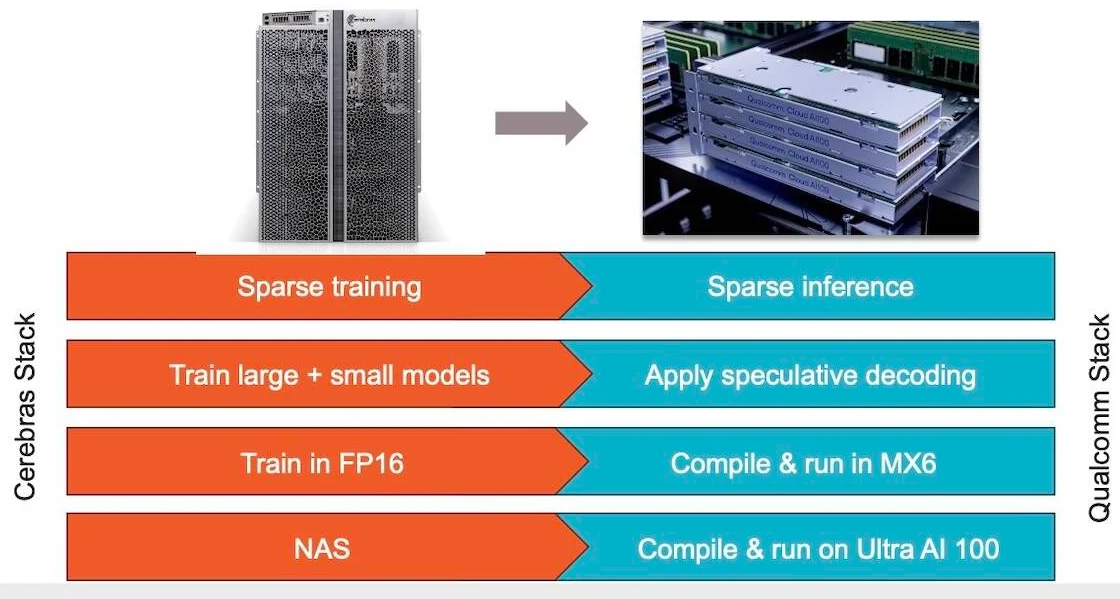 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
12.12.2023 [13:35], Сергей Карасёв
Zyxel выпустила точку доступа WBE660S стандарта Wi-Fi 7 для малого и среднего бизнесаКомпания Zyxel Networks сообщила о начале продаж точки доступа WBE660S WiFi 7 BE22000 Triple-Radio NebulaFlex Pro — своего первого решения данного типа с поддержкой стандарта Wi-Fi 7, ориентированного на поставщиков управляемых услуг (MSP), а также предприятия малого и среднего бизнеса. Устройство поддерживает работу в частотных диапазонах 2,4, 5 и 6 ГГц. Канальная скорость передачи данных достигает соответственно 1376, 8646 и 11530 Мбит/с. Радиочастотный фильтр с усовершенствованной конструкцией устраняет помехи между диапазонами 5 и 6 ГГц, а встроенный фильтр 4G/5G обеспечивает беспрепятственное сосуществование с сотовыми сетями, сообщает компания. 
Источник изображений: Zyxel Точка доступа выполнена с применением технологии смарт-антенны. Она отвечает за эффективное подавление внутриканальных помех, постоянно контролируя соединения и динамически регулируя диаграммы направленности. Благодаря этому достигается оптимальная производительность для каждого соединения. Говорится о поддержке WEP, WPA, WPA2 и WPA3, аутентификации IEEE 802.1x и RADIUS, MAC-фильтрации, L2-изоляции и пр.  Применён процессор Qualcomm с четырьмя ядрами. Точка доступа располагает сетевым портом 1/2.5/5/10GbE с поддержкой PoE и разъёмом USB Type-C с возможностью подачи питания (15 В / 3 А). В конструкции, как утверждается, используются тщательно отобранные высококачественные компоненты, обеспечивающие надёжность и увеличенный срок службы. Благодаря технологии NebulaFlex Pro устройством можно управлять через центр Nebula или при помощи аппаратного контроллера. Использовать новинку также можно в автономном режиме. Диапазон рабочих температур простирается от 0 до +45 °C. Габариты составляют 310 × 178 × 56 мм, вес — 1,4 кг. Модель Zyxel WBE660S предлагается по ориентировочной цене $800.
19.11.2023 [01:46], Сергей Карасёв
В облаке Cirrascale появились ИИ-ускорители Qualcomm Cloud AI 100Компания Cirrascale Cloud Services сообщила о том, что в её облаке AI Innovation Cloud стали доступны инстансы на основе специализированных ИИ-ускорителей Qualcomm Cloud AI 100. Сервис предназначен для инференса, обработки больших языковых моделей (LLM), генеративных ИИ-систем, приложений машинного зрения и т. п. Решение Qualcomm Cloud AI 100, выполненное в виде однослотовой 75-Вт карты PCIe с пассивынм охлаждением. Ускоритель поддерживает вычисления FP16/32 и INT8/16. Задействованы 16 ядер Qualcomm AI Cores и 16 Гбайт памяти LPDDR4x-2133 с пропускной способностью 136,5 Гбайт/с. Qualcomm Cloud AI 100 обеспечивает быстродействие до 350 TOPS на операциях INT8 и до 175 Тфлопс при вычислениях FP16. Cirrascale Cloud Services предлагает инстансы на базе одной, двух, четырёх и восьми карт Qualcomm Cloud AI 100. Количество vCPU варьируется от 12 до 64, объём оперативной памяти — от 48 до 384 Гбайт. Во всех случаях задействован SSD вместимостью 1 Тбайт (NVMe). 
Источник изображения: Qualcomm / Lenovo Разработчики могут использовать комплект Qualcomm Cloud AI SDK, который предлагает различные инструменты в области ИИ — от внедрения предварительно обученных моделей до развёртывания приложений глубокого обучения. Стоимость инстансов варьируется от $329 до $2499 в месяц (при оформлении годовой подписки — от $259 до $2019 в месяц).
13.10.2023 [22:38], Алексей Степин
Wi-Fi 7 корпоративного класса: CommScope представила точку доступа Ruckus R770Вслед за анонсами чипов с поддержкой 802.11be подтягиваются и производители сетевого оборудования. Так, компания CommScope анонсировала точку доступа Wi-Fi 7, относящуюся к корпоративному классу. Модель Ruckus R770 наделена широкими возможностями и включает в себя ряд фирменных технологий. Модель R770 разработана Ruckus Networks, ранее бывшей частью Arris International, но выкупленной CommScope в 2019 году за $7,4 млрд. Главной особенностью новой точки доступа, естественно, является поддержка Wi-Fi 7. Этот стандарт беспроводных сетей должен прийти на смену Wi-Fi 6 — в теории он сможет обеспечить минимум вчетверо более высокую пропускную способность беспроводных соединений. 
Источник изображений здесь и далее: CommScope/Ruckus Networks В основе R770 лежит платформа Qualcomm Networking Pro третьего поколения. В данном случае предусматривается работа в трёх радиодиапазонах (2,4 ГГц, 5 ГГц и 6 ГГц), поддержка модуляции 4K QAM, каналов шириной до 320 МГц и восьми потоках. Это позволяет говорить о совокупной пропускной способности каналов на уровне 12,2 Гбит/с. Проводная же часть представлена 10GbE-интерфейсом. В конструкции R770 использованы фирменные адаптивные антенны BeamFlex+.  Одной из интересных технологий является поддержка MLO (multilink operations), позволяющая задействовать одному устройству сразу несколько радиопотоков, что существенно повышает скорость обмена данными. Кроме того, R770 может работать с соединениями Bluetooth LE и Zigbee, что делает её подходящей в качестве точки доступа для IoT-сред. В дальнейшем компания планирует добавить поддержку протоколов Matter и Thread. Питается точка доступа или от внешнего DC-адаптера, потребляя до 32 Вт, или посресдством PoE (802.3bt).  Также в R770 реализованы фирменные технологии, в частности, интеллектуальная система диагностики Ruckus AI, способная ранжировать возникающие проблемы по степени их серьёзности и предлагать способы решения этих проблем. Другой интересной функцией является Dynamic PSK. Как правило, в пределах одной Wi-Fi-сети все устройства подключаются к точке доступа с помощью единого пароля, но R770 позволяет назначить уникальные пароли каждому клиентскому устройству. Это повышает администраторам сети более тонко управлять аспектами безопасности.  Спектр применения Ruckus R770 широк: в качестве возможных сценариев использования производитель предлагает применение новинки в гостиницах, жилых зданиях, образовательных учреждениях, в производственных помещениях и т.д. В настоящее время новинка уже доступна избранным клиентам CommScope, а массовые поставки R770 должны начаться в декабре.
17.06.2023 [15:11], Владимир Мироненко
Lenovo представила новые ИИ-серверы для периферии и ЦОДLenovo планирует инвестировать $1 млрд в течение трёх лет в разработку оборудования и программного обеспечения для ИИ-сектора. Речь идёт не только о решениях для ЦОД, но и для периферии. Сейчас Lenovo занимается сертификацией большей части своего существующего оборудования для обработки ИИ-нагрузок. По словам Роберта Дейгла (Robert Daigle), старшего менеджера подразделения Lenovo ISG Global AI, компания работала с 45 партнёрами над созданием 150 систем и ИИ-решений «под ключ». На днях компания анонсировала два новых ИИ-сервера для периферийных вычислений. ThinkEdge SE360 V2 предназначен ускорених таких нагрузок, как компьютерное зрение, голосовой ИИ и генеративный ИИ. ThinkEdge SE360 V2 построен на базе процессоров Intel Xeon D-2700 и ускорителей NVIDIA A2/L4 (с поддержкой NVIDIA AI Enterprise) или Qualcomm Cloud AI 100. Устройство имеет компактные размеры (2U, ½ ширины) и прочный корпус, что позволяет его использовать в условиях неблагоприятной окружающей среды. 
ThinkEdge SE360 V2 (Источник изображений: Lenovo) 1U-сервер Lenovo ThinkEdge SE350 V2 разработан для гибридного облака и использования в гиперконвергентной инфраструктуре. У этого сервера увеличенная ёмкость дисковой подсистемы в сочетании с процессором Intel Xeon D-2700 и 100G-подключением. Сервер главным образом предназначен для консолидации рабочих нагрузок, резервного копирования данных при совместной работе и доставке контента. 
ThinkEdge SE350 V2 Также Lenovo представила ИИ-сервер ThinkSystem SR675 V3 на базе AMD EPYC Genoa. В шасси высотой 3U можно разместить HGX-плату с четырьмя SXM-ускорителями H100 или четыре или восемь ускорителей двойной ширины NVIDIA или AMD. В зависимости от конфигурации доступны различные варианты дисковой подсистемы, но упор сделан на NVMe SSD. Также для платформы есть опция установки фирменной СЖО Neptune. 
ThinkSystem SR675 V3 ThinkSystem SR675 V3 оптимизирован для работы с цифровыми двойникам в сочетании с ИИ с целью улучшения бизнес-процессов и результатов проектирования. Lenovo также работала с NVIDIA над повышением производительности рабочих нагрузок Omniverse Enterprise. Ещё один новый проект Lenovo — Центр передового опыта Lenovo AI Discover, который проводит семинары для клиентов, желающих начать работу с такими технологиями, как генеративный ИИ и компьютерное зрение.
25.04.2023 [18:42], Сергей Карасёв
Qualcomm представила четыре новых SoC для IoT-устройствКомпания Qualcomm анонсировала сразу четыре SoC для различного IoT-оборудования — дронов, устройств для облачных игр, мобильных гаджетов и пр. Изделия, представленные в ходе отраслевой выставки Hannover Messe 2023, получили обозначения QCS8550, QCM8550, QCS4490 и QCM4490. Первые два из дебютировавших чипов — это мощные модели, единственное различие между которыми заключается в том, что вариант «М» имеет встроенный сотовый модем. Они изготавливаются по 4-нм технологии. Конфигурация включает одно ядро Kryo GoldPlus (3,2 ГГц), четыре ядра Gold (2,8 ГГц) и три ядра Silver (2,0 ГГц). Возможно использование оперативной памяти LPDDR5/5x-4200. 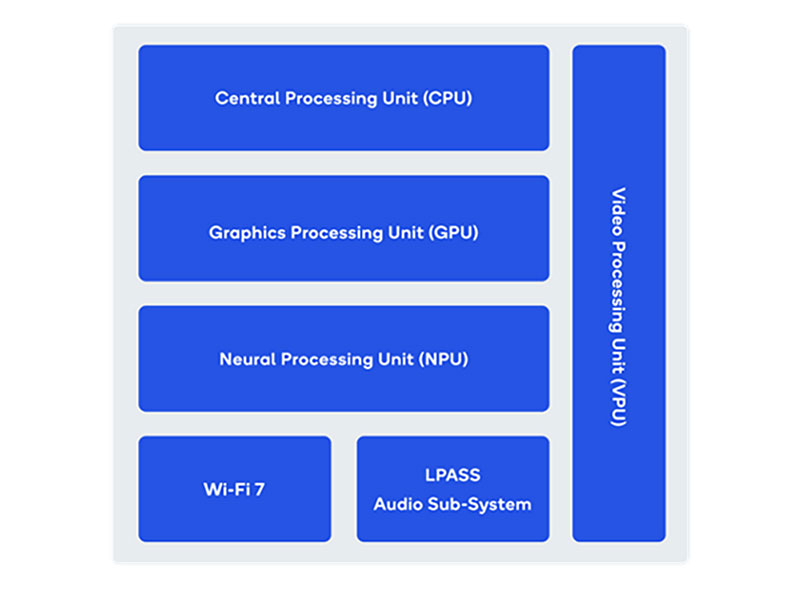
Источник изображения: Qualcomm В состав SoC входят блок Adreno 740 GPU, приёмник GPS/GLONASS/BeiDou/Galileo/QZSS/NavIC, адаптеры Wi-Fi 7 (802.11be) и Bluetooth 5.3, модуль сенсоров Qualcomm Sensing Hub 3.0, NPU-блок Qualcomm Hexagon Tensor Processor (HTP) и пр. Поддерживается фотосъёмка с разрешением до 200 МПикс. Чип QCM8550 наделён модемом 5G. Возможно декодирование видеоматериалов 4K240/8K60. Новинки подходят для таких сфер применения, как автономные мобильные роботы, промышленные дроны, ИИ-устройства и др. В свою очередь, QCS4490 и QCM4490 оптимизированы для мобильных Android-гаджетов. Они получили два ядра Gold A78 (2,4 ГГц) и шесть ядер Silver A55 (2,0 ГГц), ускоритель Adreno GPU 613, контроллер памяти LPDDR4X/LPDDR5, адаптеры Wi-Fi 6E и Bluetooth 5.2 и поддержку GPS/BeiDou/GLONASS/Galileo/NavIC. В состав QCM4490 включён модем 5G.
16.03.2023 [15:18], Сергей Карасёв
DFI и Qualcomm представили первый в мире одноплатный компьютер на чипе QRB5165Компании DFI и Qualcomm в ходе конференции Embedded World 2023 анонсировали первый в мире одноплатный компьютер, оборудованный процессором Qualcomm QRB5165. Новинка предназначена для систем промышленной автоматизации, робототехники, периферийных ИИ-вычислений и пр. Чип Qualcomm QRB5165 содержит восемь вычислительных ядер Kryo 585 с тактовой частотой до 2,84 ГГц, графический ускоритель Adreno 650, ISP-блок Qualcomm Spectra 480, а также цифровой сигнальный процессор Hexagon 698. Говорится о поддержке OpenGL ES 3.2, Vulkan 1.1, DX12 и OpenCL 2.0. 
Источник изображения: DFI Одноплатный компьютер выполнен в формате 3,5″ с габаритами 146 × 102 мм. Объём оперативной памяти LPDDR4 может составлять 6/8 Гбайт (в дальнейшем планируется реализация поддержки LPDDR5). Для хранения данных служит флеш-модуль UFS 3.0 вместимостью 128 Гбайт. Платформа Qualcomm QRB5165 обеспечивает поддержку Wi-Fi 6 (802.11ax) и Bluetooth 5.1. Плата наделена коннекторами M.2 B key 3052/2242 (PCIe x2, USB 3.1) и M.2 E key 2230 (PCIe x1), а также слотом Nano SIM. Таким образом, может быть добавлен модуль для работы в сотовых сетях. Доступны по два порта USB 3.1 Gen1 Type-A и USB 2.0, разъём USB 3.1 Type-C, последовательный порт RS232/422/485 (DB9), сетевой разъём RJ-45 (1GbE), интерфейс HDMI 1.4, коннектор Micro-USB, стандартное аудиогнездо на 3,5 мм. Питание подаётся через разъём DC (12 В). Упомянута CAN-шина. Диапазон рабочих температур — от 0 до +60 ºC. Говорится о совместимости с ОС Ubuntu 18.04 (ядро 4.19).
18.08.2022 [23:23], Игорь Осколков
Qualcomm надумала вернуться в серверный бизнес с новым Arm-процессоромBloomberg, ссылаясь на собственные источники, сообщает, что компания Qualcomm намерена вернуться в сегмент серверных CPU с новыми чипами, основанными на наработках купленного в прошлом году стартапа Nuvia. Nuvia была сформирована выходцами из Apple — компания обещала создать Arm-процессоры Phoenix, которые были бы быстрее и энергоэффективнее AMD EPYC и Intel Xeon. После поглощения речь о серверных решениях уже не велась. Теперь же Qualcomm, судя по всему, пытается диверсифицировать свой бизнес. Это не первая попытка компании освоить серверный рынок — в 2018 году она отказалась от развития чипов серии Centriq 2400, предпочтя сосредоточиться на решениях для мобильных устройств. Не исключено, что к изменению курса компанию подтолкнул успех Ampere Computing, Arm-процессоры которой появились не только у ряда облачных провайдеров второго эшелона, но и в Google Cloud Platform, Microsoft Azure, а также в серверах Gigabyte, HPE и т.д. 
Изображение: Nuvia/Qualcomm Из «большой тройки» облаков Ampere Altra были проигнорированы (во всяком случае официально) только AWS. Зато в AWS доступно уже третье поколение Arm-процессоров Graviton собственной разработки. Кроме того, у AWS есть собственные же DPU, SSD, ИИ-ускорители для обучения (Trainium) и инференса (Inferentia), т.е. практически полный аппаратный стек. Тем не менее, компания продолжает закупать продукты AMD, Intel и NVIDIA. А теперь, по данным Bloomberg, в AWS якобы обратили внимание и на новые серверные чипы Qualcomm. Сейчас альтернатив Arm-чипам Ampere в серверном сегменте не так много. Alibaba Cloud пошла по пути Amazon, занявшись разработкой собственных процессоров Yitian. Наследие Broadcom, пройдя через руки Cavium и Marvell, оказалось заброшенным. AMD в своё время также отказалась от развития Arm-чипов, и это решение Джим Келлер впоследствии назвал глупым. Китайские HiSilicon и Phytium пострадали от санкций. А Fujitsu A64FX и NVIDIA Grace ориентированы в первую очередь на HPC-нагрузки. Европейские же чипы SiPearl пока не готовы.
23.06.2022 [22:23], Владимир Мироненко
Qualcomm представила унифицированный ИИ-стек Qualcomm AI StackQualcomm Technologies анонсировала стек Qualcomm AI Stack, объединяющий «лучшие в своём классе программные предложения для ИИ» компании в единый пакет. Цель компании — унифицировать и упростить набор программных инструментов для OEM-производителей и разработчиков, чтобы они могли создавать, оптимизировать и развёртывать ИИ-решения на базе продуктов Qualcomm, которые охватывают всё больше сегментов, от встраиваемых решений до целых ЦОД. Qualcomm AI Stack поддерживает популярные ИИ-платформы и среды, в том числе TensorFlow, PyTorch, ONNX. Новый стек состоит из базовых библиотек и сервисов для разработчиков, системного ПО, инструментов и компиляторов. По словам компании, теперь любую ИИ-функциональность, разработанную для одного устройства, можно легко развёрнуть на других — с помощью нового стека можно единожды создать и оптимизировать ИИ-модель, а затем быстро перенести её на другую платформу и настроить, что помогает существенно экономить время и ресурсы. 
Источник изображения: Qualcomm Technologies В стек входят Neural Processing SDK, AI Model Efficiency Toolkit (AIMET) Pro, AIMET Model Zoo, Model Analyzers, Neural Architecture Search и т.д. Кроме того, Qualcomm недавно перенесла SDK Qualcomm Neural Processing SDK на Microsoft Windows, а решение Qualcomm AI Engine Direct теперь доступно для всех продуктов Qualcomm, включая ИИ-ускоритель Qualcomm Cloud AI 100. От последнего, к слову, Meta✴ в своё время отказалась как раз из-за проблем с ПО. 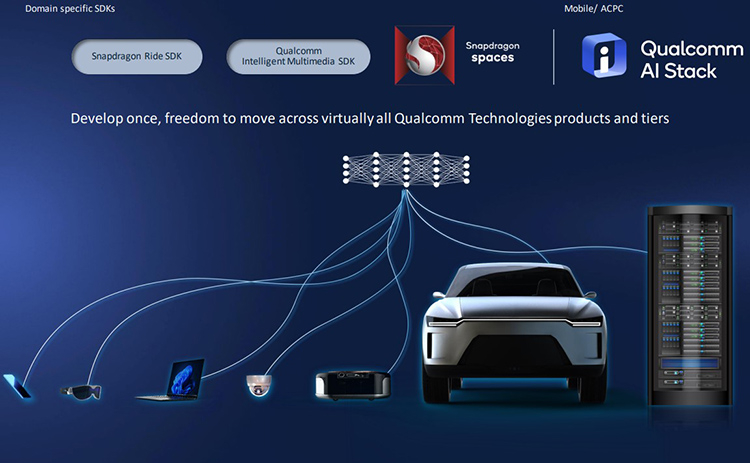
Источник изображения: Qualcomm Technologies Как отметила компания, Qualcomm Neural Processing SDK для Android и недавно анонсированная Windows-версия остаются ключевыми продуктами для OEM-производителей и разработчиков и будут получать регулярные обновления и поддержку. В Qualcomm AI Software Stack также входят три SDK для автономных транспортных средств (Snapdragon Ride SDK), Intelligent Multimedia и SDK для робототехники, Интернета вещей и виртуальной реальности (Snapdragon Spaces SDK). Общая основа этих SDK помогает разработчикам поддерживать весь портфель аппаратных решений Qualcomm в различных сегментах. |
|

