Материалы по тегу: apu
|
24.05.2023 [18:36], Сергей Карасёв
AMD показала узлы грядущего 2-Эфлопс суперкомпьютера El Capitan на базе новейших APU Instinct MI300AКомпания AMD в ходе суперкомпьютерной конференции ISC 2023, по сообщению ресурса Tom's Hardware, продемонстрировала компоненты суперкомпьютера El Capitan, который после ввода в эксплуатацию сможет претендовать на звание самого высокопроизводительного комплекса в мире. Новая НРС-машина расположится в Ливерморской национальной лаборатории им. Э. Лоуренса (LLNL) Министерства энергетики США. В основу лягут гибридные чипы Instinct MI300, а производительность превысит 2 Эфлопс (FP64). Для сравнения: самый мощный на сегодняшний день суперкомпьютер Frontier, установленный в Национальной лаборатории Окриджа, обладает быстродействием около 1,194 Эфлопс. На ISC 2023 Бронис Р. де Супински (Bronis R. de Supinski), технический директор LLNL, показал блейд-серверы, которые войдут в состав El Capitan. Устройство, изготовленное компанией HPE, объединяет четыре модуля Instinct MI300 с жидкостным охлаждением. Решение выполнено в форм-факторе 1U. 
Источник изображений: LLNL / Tom's Hardware Супински также показал фотографию лаборатории AMD в Остине, где испытываются рабочие образцы Instinct MI300. Таким образом, как отмечается, новые чипы практически готовы для использования в коммерческих системах. В частности, ввод суперкомпьютера El Capitan в эксплуатацию запланирован на вторую половину 2023 года. Тестовые кластеры El Capitan на базе AMD EPYC Milan и Instinct MI250X ещё в прошлом году попали в TOP500.  Любопытно, что Супинкси в ходе выступления назвал Instinct MI300 несколько другим именем — Instinct MI300A. Однако не ясно, является ли это специальной модификацией для El Capitan или более формальным индексом продукта. Супински отметил, что решение может работать в нескольких разных режимах, но основная конфигурация предусматривает единый домен памяти и домен NUMA, что обеспечивает общий доступ к памяти для всех ядер CPU и GPU.  Для El Capitan предусмотрено использование фирменного хранилища Rabbit. Оно включает 4U-узлы на основе 18 быстрых SSD, которые подключены к плате Rabbit-S, обеспечивающей коммутацию с вычислительной частью. За работу СХД отвечает контроллер Rabbit-P с чипом EPYC.  Администрации по национальной ядерной безопасности США (NNSA), которая будет использовать El Capitan, пришлось модифицировать энергетическую инфраструктуру для одновременной работы нового суперкомпьютера и действующего комплекса Sierra. Общая мощность увеличена с 45 МВт до 85 МВт, а ещё 15 МВт зарезервировано для системы охлаждения. Таким образом, суммарно доступны 100 МВт, хотя El Capitan будет потреблять менее 40 МВт.
24.05.2023 [14:14], Сергей Карасёв
AMD рассказала об архитектуре гигантского APU Instinct MI300: 24 ядра EPYC Genoa, ускоритель CDNA 3 и 128 Гбайт HBM3Компания AMD на суперкомпьютерной конференции ISC 2023, по сообщению ресурса Tom's Hardware, раскрыла дополнительную информацию о гибридном изделии Instinct MI300. Новый APU найдёт применение в HPC-системах, а также в высокопроизводительных серверах для дата-центров. Как говорилось ранее, MI300 — это самый крупный и сложный чип, когда-либо созданный специалистами AMD. Он содержит в общей сложности около 146 млрд транзисторов. Конструкция включает ядра CPU (Zen 4) и GPU (CDNA 3), вспомогательную логику, I/O-контроллер, а также память HBM3. В общей сложности задействованы 13 чиплетов, четыре из которых изготавливаются по 6-нм технологии, а ещё девять — по 5-нм. По сравнению с Instinct MI250 новинка получила ряд архитектурных изменений. В частности, узел с Instinct MI250 (как у Frontier) имеет отдельные блоки CPU и GPU, дополненные единственным процессором EPYC для координации рабочих нагрузок. В свою очередь, узел Instinct MI300 содержит интегрированный 24-ядерный чип EPYC Genoa, а поэтому необходимость во внешнем CPU отпадает. 
Источник изображений: AMD 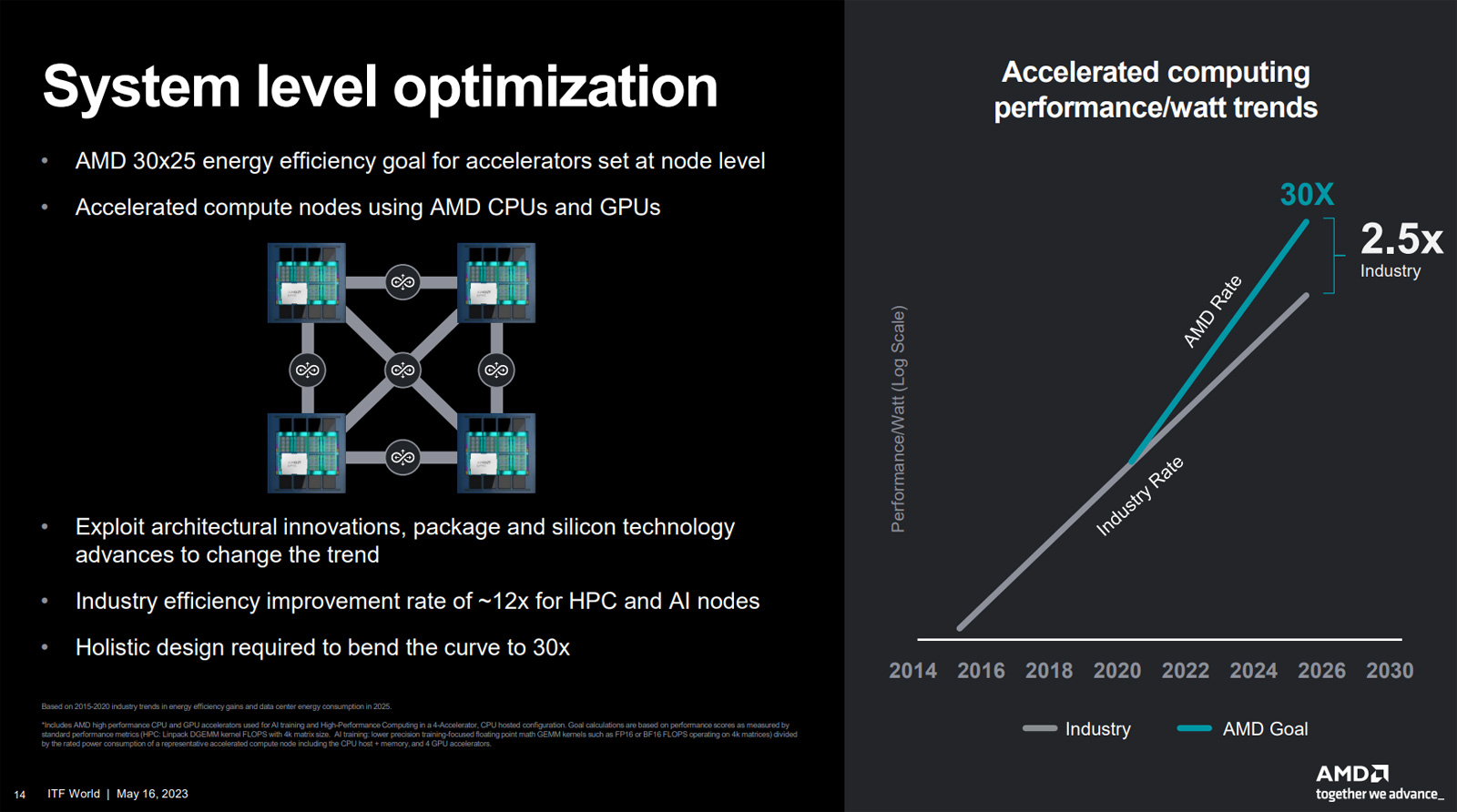 Вместе с тем сохранена топология, позволяющая каждому из блоков обмениваться данными со всеми другими. Причём в случае Instinct MI300 снижается задержка и повышается общая производительность. Компоненты чипа объединены посредством Infinity Fabric четвёртого поколения. В оснащение ходят 128 Гбайт общей для CPU и GPU памяти HBM3. Похожий подход реализован в чипах NVIDIA Grace Hopper, а вот Intel от гибридности в ускорителях Falcon Shores пока отказалась.
05.01.2023 [22:25], Алексей Степин
AMD продемонстрировала на CES 2023 гигантский APU Instinct MI300: 13 чиплетов в LGA-упаковкеНа CES 2023 компания AMD впервые показала публике новый APU Instinct MI300. На сегодняшний момент MI300 — крупнейший и самый сложный чип, когда-либо созданный в стенах Advanced Micro Devices. Он насчитывает 146 млрд транзисторов, составляющих ядра CPU и GPU, вспомогательную логику, I/O-контроллер, а также память HBM3. По сложности новинка, таким образом, превосходит и Intel Xeon Max (100 млрд транзисторов), и гибрид NVIDIA Grace Hopper (80 млрд транзисторов). Все компоненты чипа объединены посредством 4-го поколения Infinity Fabric, физически же чиплеты разнесены не только по горизонтали, но и по вертикали, причём сами чиплеты производятся с использованием разных техпроцессов. В составе MI300 имеется 4 чиплета, выполненных по технологии 6 нм, на которых, в свою очередь, располагаются ещё 9 чиплетов, но уже использующих вышеупомянутый 5-нм техпроцесс. 
Источник: AMD/YouTube 6-нм чиплетамы образуют активную подложку, которая включает I/O-контроллер (в том числе для работы с памятью) и вспомогательную логику, а более совершенный 5-нм техпроцесс использован для вычислительных ядер. CPU-ядер с архитектурой Zen 4 в составе нового процессора 24. К сожалению, именно о CDNA-ядрах говорится мало и не озвучивается даже их число. С учётом того, что в Zen 4 используются 8-ядерные чиплеты, 3 из 9 «верхних» блоков MI300 именно процессорные.  Также на снимке можно разглядеть 8 сборок HBM3, суммарный объём которых составляет 128 Гбайт. Теоретически это может означать эффективную ширину шины вплоть до 8192 бит и пропускную способность в районе 5 Тбайт/с или даже больше. Такое сочетание позволит MI300 в 8 раз опередить MI250X в ИИ-задачах (правда, речь о разреженных FP8-вычислениях), и это при пятикратном превосходстве в энергоэффективности. Последнюю цифру озвучивала и Intel, говоря о своих APU Falcon Shores, выход которых намечен на 2024 год.  Конкретные значения энергопотребления и тепловыделения пока остаются тайной, но MI300, согласно Tom's Hardware, получил LGA-упаковку (SH5), напоминающую таковую у новеньких EPYC Genoa. Также на презентации было указано, что работоспособный кремний MI300 уже получен и находится в настоящее время в лабораториях AMD. Иными словами, у «красных» всё идёт по плану — официальный анонс состоится во второй половине нынешнего, 2023 года. Впрочем, MI300 будет дорогим и редким чипом.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 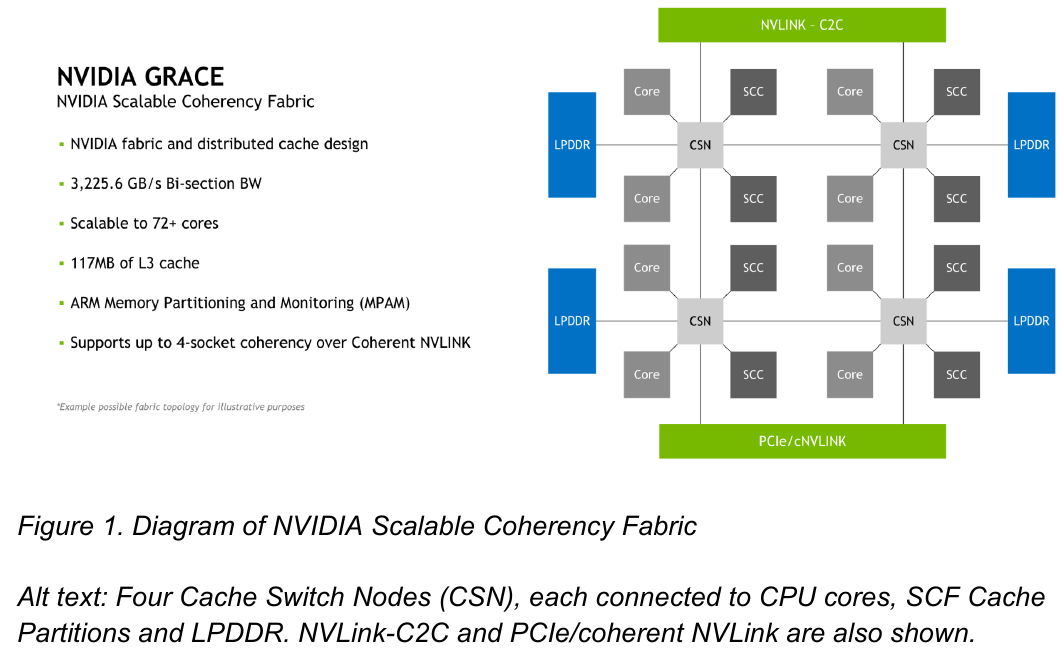
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 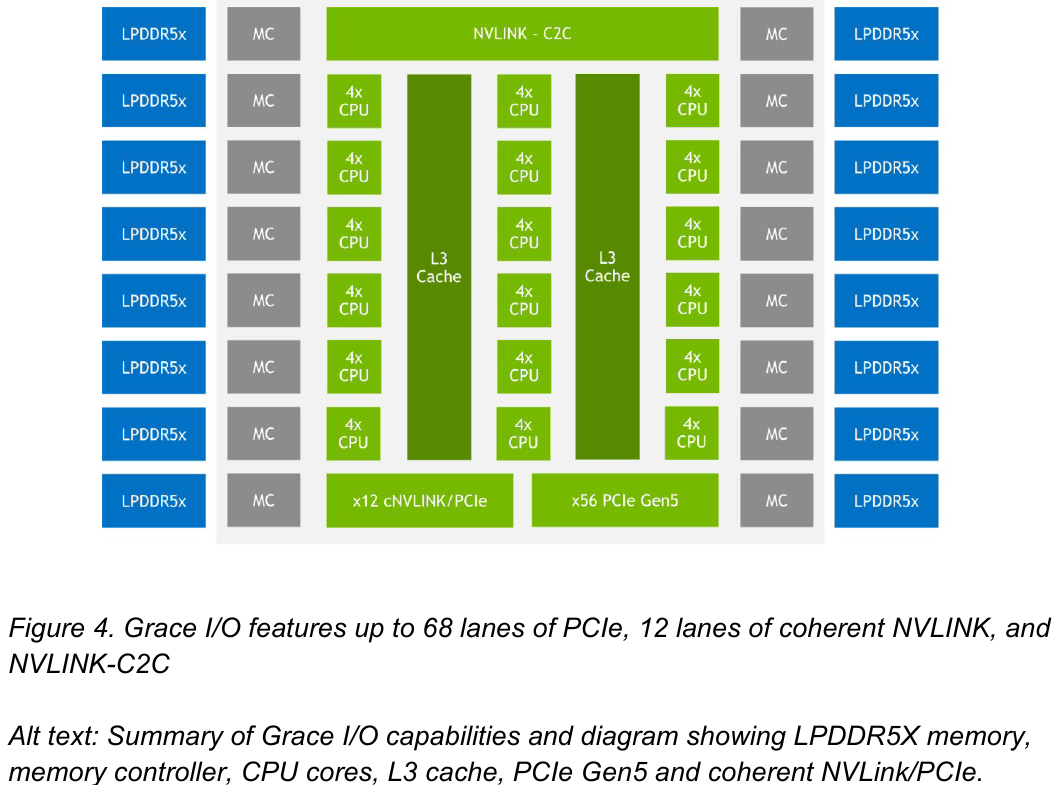
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 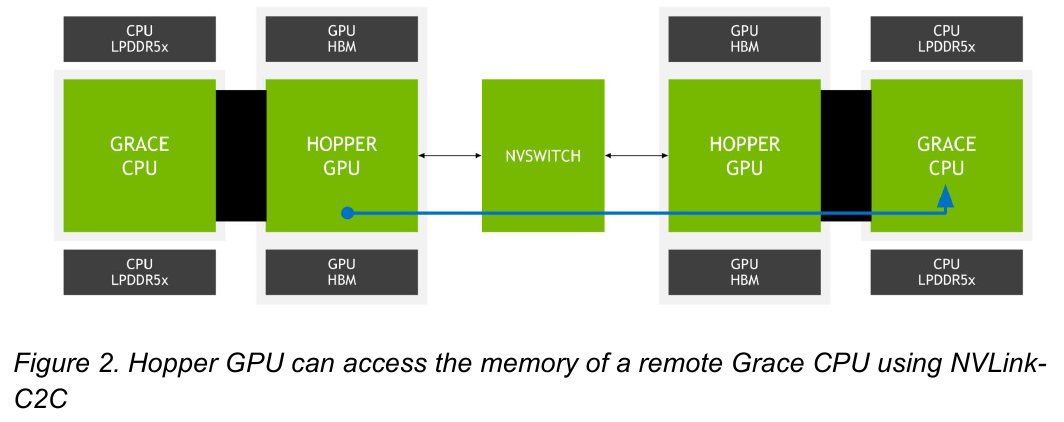
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 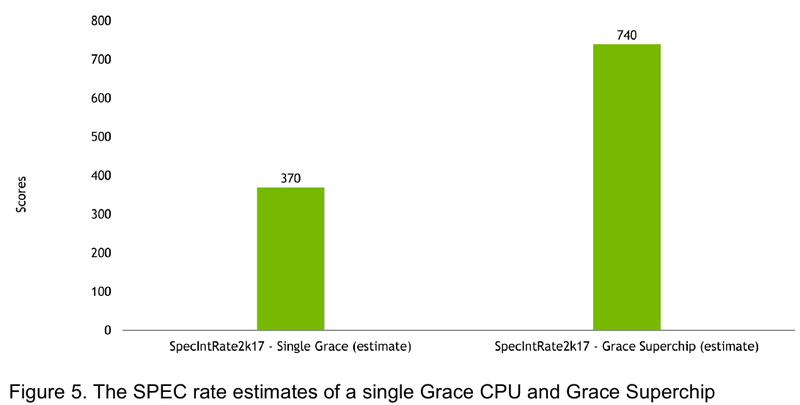
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
23.06.2022 [20:31], Алексей Степин
2-Эфлопс cуперкомпьютер El Capitan получит новейшие APU AMD MI300До ввода в строй нового кластера Лос-Аламосской национальной лаборатории (LLNL) под названием El Capitan ещё остается немало времени. Тестовые мини-кластеры El Capitan уже показывают неплохие результаты; в их основе лежит привычное сочетание процессоров AMD EPYC Milan и ускорителей Instinct MI250X, однако финальная версия суперкомпьютера, как оказалось, будет использовать более прогрессивную новинку — новейшие APU MI300. Об этом на очередном мероприятии HPC User Forum поведал миру глава центра высокопроизводительных вычислений LLNL. Поскольку полномасштабный запуск El Capitan назначен на конец 2023 года, времени на переход от EPYC 7003 с дискретными модулями ускорителей Instinct к высокоинтегрированному MI300 должно хватить. При этом ожидается, что машина будет активно эксплуатироваться минимум до 2030 года. 
Источник: LLNL MI300 — амбициозный проект AMD, который должен показать, что компания полностью освоила все преимущества чиплетной технологии: на одной подложке будут установлены чиплеты процессорных ядер Zen 4 (Genoa), блоки ускорителей с архитектурой CDNA3, модули кеша и сборки сверхбыстрой памяти типа HBM3. Таким образом, MI300 с полным основанием претендует на звание первого в мире действительно универсального процессора для HPC-систем, способного работать с любыми видами нагрузок. 
Источник: LLNL (via TheNextPlatform) Общий уровень энергопотребления El Capitan планируется удержать в рамках 40 МВт (а не 35 МВт) при FP64-производительности свыше 2 Эфлопс — удельный показатель составит порядка 50 Гфлопс/Вт. В последнем рейтинге Green500 кластер Frontier TDS показал почти 63 Гфлопс/Вт, тогда как для суперкомпьютера Frontier целиком удалось добиться 52,23 Гфлопс/Вт. В El Capitan лаборатория перейдет от использования проприетарного системного и управляющего ПО к собственному стеку NNSA Tri-Lab Operating System Stack (TOSS). 
Такие узлы HPE Cray EX235a используются в тестовых кластерах El Capitan. Переход на MI300 упростит конструкцию. Источник: HPC Wire Также было упомянуто, что у КНР есть уже два экзафлопсных суперкомпьютера, а «глобальные соперники» США за последние годы модернизировали свой ядерный арсенал. Подобная задача теперь стоит и перед самими Соединёнными Штатами. Национальное управление ядерной безопасности (National Nuclear Security Administration, NNSA) возложит эту миссию на El Capitan, начиная со II квартала 2024 года. Напомним, на очереди среди всех экзафлопсных систем США этот суперкомпьютер третий, вторым же является 2-Эфлопс Aurora, система HPE с изрядно задержавшимися процессорами Intel Sapphire Rapids и ускорителями Ponte Vecchio, которая устанавливается в Аргоннской национальной лаборатории. Но MI300 — не единственный HPC-гибрид. В скором времени появятся несколько машин с чипами NVIDIA Grace Hopper.
10.06.2022 [20:02], Алексей Степин
Первые серверные APU AMD MI300 объединят архитектуры CDNA 3 и Zen 4Идея интеграции классического процессора с графическим не нова — очень многие клиентские CPU/APU сегодня построены именно по такой схеме. В мире серверов и HPC эта концепция внедряется не так быстро, но на мероприятии Financial Analyst Day 2022 компания AMD рассказала о планах по созданию своего первого 5-нм гибридного APU MI300. Этот чип, запланированный на 2023 год, должен объединить в себе архитектуры Zen 4 и CDNA 3. 
MI300 Источник: AMD Как известно, текущее поколение ускорителей Instinct MI200 использует вторую версию архитектуры CDNA, и теперь мы знаем о планах «красных» по внедрению следующей версии. В отличие от других планов AMD, касающихся графических процессоров и завязанных на двухгодичный цикл обновления, серверные варианты ускорителей будут обновляться раз в год. Компания также раскрыла часть деталей, относящихся к CDNA 3. 
Источник: AMD Во-первых, весь «кремний» CDNA 3 будет производиться с использованием 5-нм техпроцесса (TSMC N5/N5P), и, как и CDNA 2, он будет базироваться на чиплетной компоновке с отдельными кристаллами для памяти, кешей и вычислительных ядер. При этом AMD называет свою технологию 3D chiplet, то есть, речь идёт о плотной вертикально-горизонтальной компоновке. Так, чиплеты кеша будут располагаться под процессорными, а на самый верх «стопки» компания вынесет чиплеты логики, как наиболее прожорливые и горячие. 
Источник: AMD Самым важным новшеством в CDNA — четвёртое поколение Infinity Architecture, позволяющее, в числе прочего, сделать подсистему памяти полностью унифицированной и когерентной — в MI200 реализована только когерентность, но не единое адресное пространство. Иными словами, если старшие варианты MI200 всё ещё выглядят как пара ускорителей, то решения на базе CDNA 3 с точки зрения системы будут выглядеть и функционировать как единый чип, несмотря на чиплетную компоновку. 
Источник: AMD Что касается памяти, то это, конечно же, общая для всех HBM. Тип не уточняется, но можно с достаточной степенью уверенности предположить, что это будет HBM3. Об архитектурных улучшениях в сценариях машинного обучения известно пока немного, известно, что в CDNA 3 появится поддержка новых смешанных типов вычислений, зато AMD уверенно обещает более чем в 5 раз поднять производительность на Вт в такого рода задачах. Надо полагать, что достигнуто это будет существенным увеличением качества и количества движков для матричных вычислений. 
Источник: AMD Но самое интересное в свежих планах AMD — проект MI300. Об интеграции классических CPU с ускорителями говорилось давно, однако недостаточно тонкие и энергоэффективные техпроцессы не позволяли создать чип, укладывающийся в разумные рамки энергопотребления и тепловыделения. С 5-нм оптимизированным техпроцессом это, похоже, становится возможным. 
Источник: AMD MI300 должен объединить в себе архитектуры CDNA 3 и Zen 4, причём, благодаря Infinity Architecture они смогут равноправно пользоваться всеми ресурсами памяти (и, возможно, кешей), имеющимися на чипе, что исключает копирование одного и того же набора данных между пулами памяти, лишь снижающего общую эффективность. Не исключено также, что отпадёт нужда во внешней DRAM благодаря наличию на борту этого монстра собственного объёмного пула HBM. Впрочем, новый вариант Infinity получил поддержку CXL 2.0, что упростит работу с внешними пулами DRAM. 
Источник: AMD Пока неизвестно, сколько процессорных ядер и сколько ядер CDNA 3 получит MI300, но AMD заявляет, что новинка более чем в 8 раз превзойдёт MI250X в задачах обучения ИИ-моделей. В целом, планы AMD хорошо укладываются в современную тенденцию гибкой компоновки ресурсов в рамках чипа: этим же путём идут NVIDIA со своим проектом Grace Hopper (процессорные ядра Grace + H100) и Intel, разрабатывающая XPU Falcon Shores (x86 + Xe). Сама AMD также планирует интегрировать CPU и FPGA.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 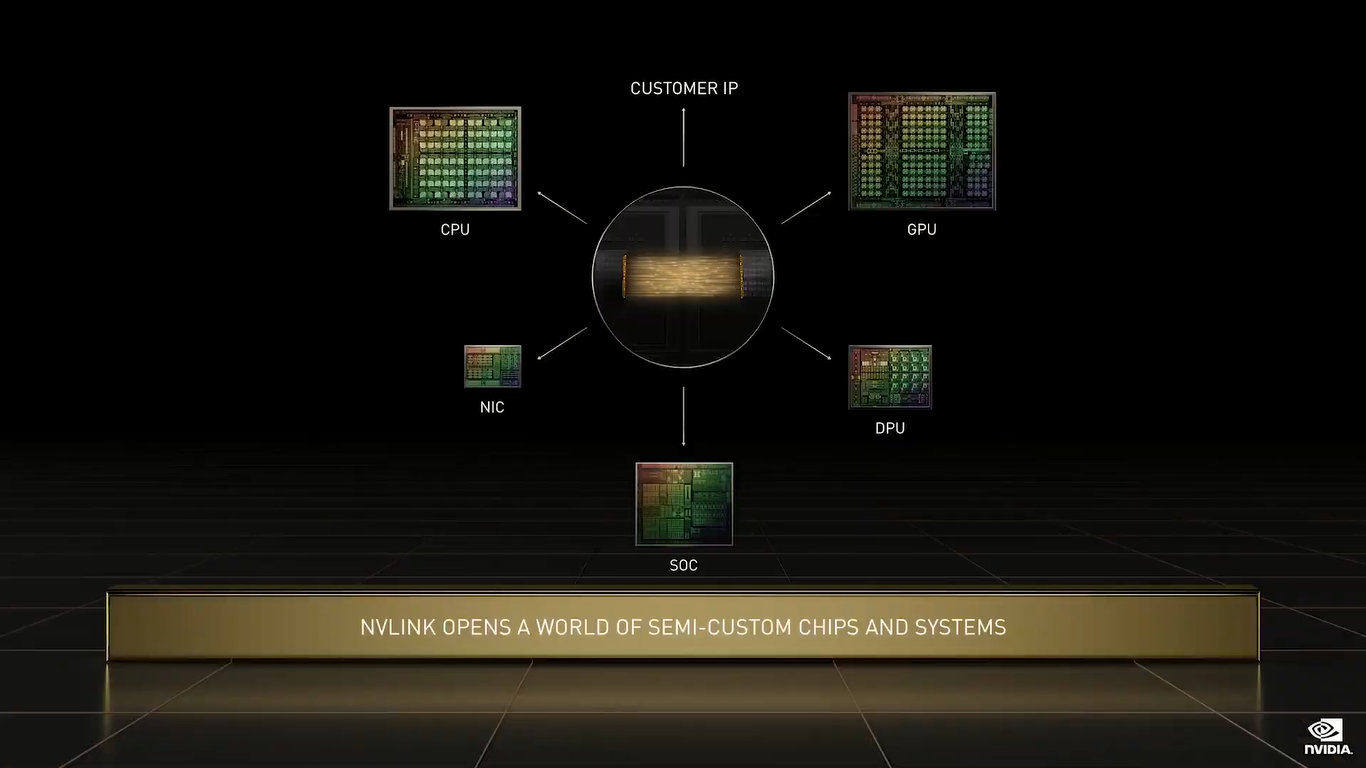 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 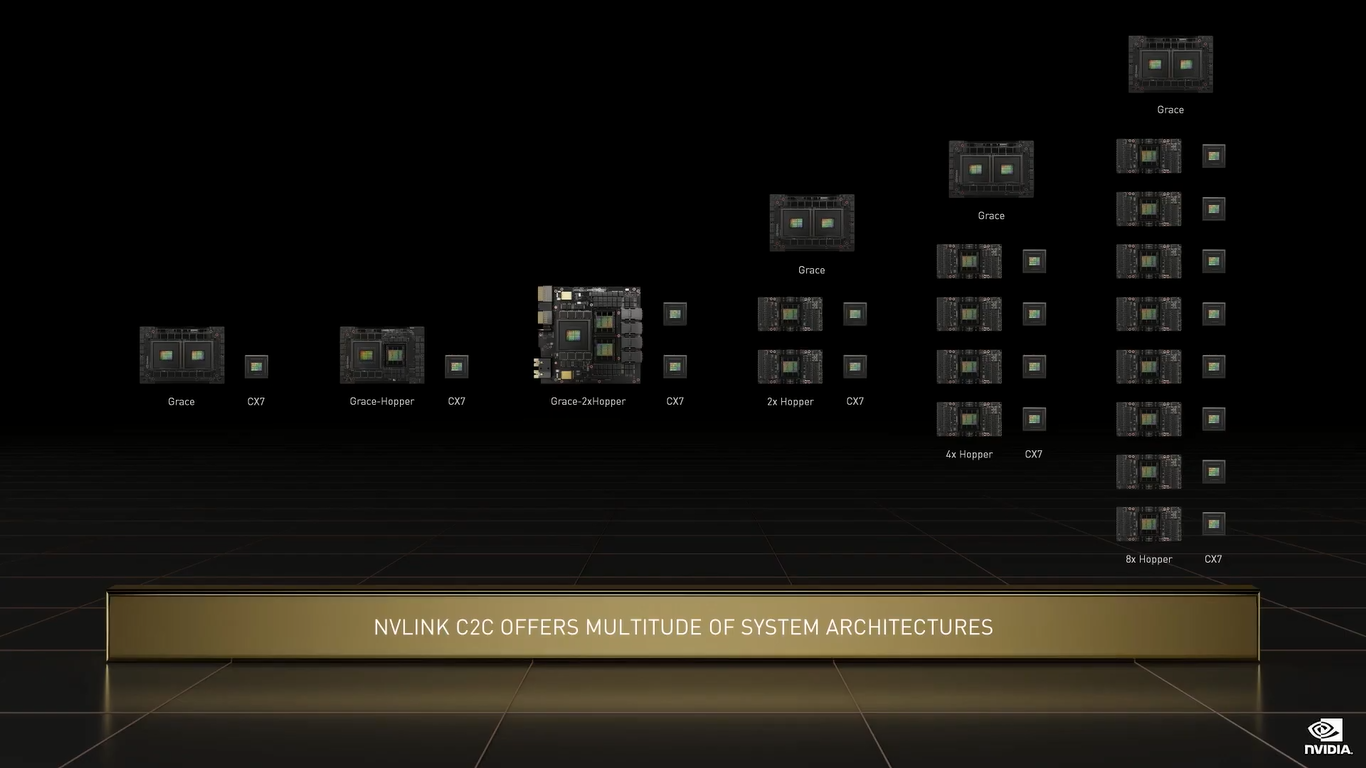 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe. |
|

