Материалы по тегу: asic
|
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 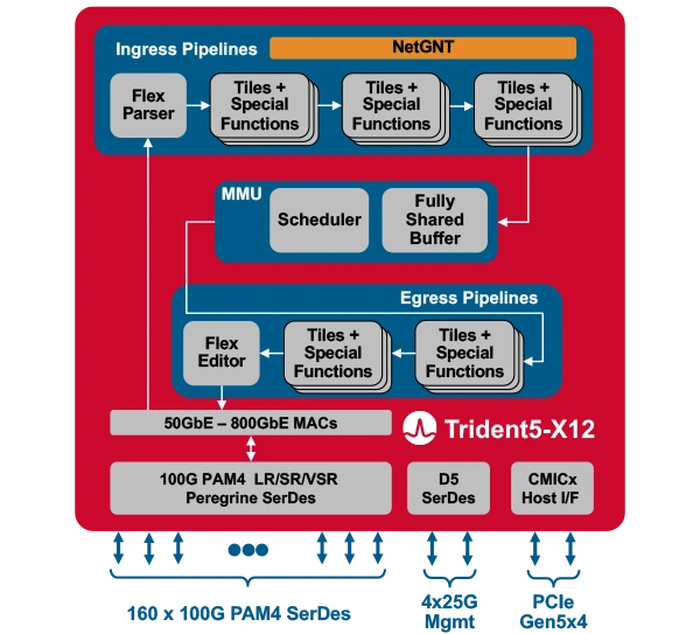 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
24.10.2023 [14:49], Алексей Степин
Broadcom представила первый в индустрии одночиповый маршрутизатор класса 25,6 Тбит/сBroadcom объявила о расширении серии одночиповых маршрутизаторов StrataDNX. Новинка, сетевой процессор Qumran3D, стал первым в мире высокоинтегрированным маршрутизатором с пропускной способностью 25,6 Тбит/с. Чип BCM88870 производится с использованием 5-нм техпроцесса. Решения на его основе, по словам Broadcom, позволят сэкономить 66 % энергии и 80 % стоечного пространства в сравнении с аналогичными по классу решениями предыдущих поколений. Новый чип также должен помочь в освоении высокоскоростного Ethernet — он может быть сконфигурирован для работы с портами от 100GbE до 800GbE. Поддерживается стандарт 800ZR+. Qumran3D располагает 256 линками, реализованными с помощью PAM4-блоков SerDes класса 100G. 
Источник изображений здесь и далее: Broadcom В устройстве реализовано шифрование MACSec и IPSec, работающее на полной скорости на всех сетевых портах. Наличие интегрированной памяти HBM обеспечивает расширенную буферизацию, гарантирующую отсутствие потери пакетов даже в самых нагруженных сетях. Причём объёма достаточно и для хранения расширенных политик и обширных таблиц маршрутизации, что освобождает решения на базе Qumran3D от необходимости использования дополнительных чипов, а значит, и удешевляет их дизайн.  Как и ряд других решений Broadcom, Qumran3D использует реконфигурируемые сетевые движки Elastic Pipe, позволяющие гибко настраивать сценарии маршрутизации с учётом требований заказчика, а также по необходимости вводить поддержку новых протоколов. Наличие движка иерархической приоритизации гарантирует стабильную пропускную полосу для заданных типов трафика, что делает Qumran3D подходящим в качестве провайдерского решения. Новый чип Broadcom имеет широкую область применения, но в первую очередь, он нацелен на рынок провайдеров сетевых услуг, ЦОД и облачных систем. Qumran3D уже поставляется избранным заказчикам, но дата начала массовых поставок пока не названа.
29.07.2023 [09:52], Сергей Карасёв
Broadcom представила платформу Trident 4-X7 для 400GbE-коммутаторовКомпания Broadcom анонсировала платформу StrataXGS Trident 4 BCM56690 (Trident 4-X7), предназначенную для создания коммутаторов нового поколения с поддержкой 400GbE. Полностью программируемый чип обеспечивает пропускную способность до 4 Тбит/с. Изделие Trident 4-X7 обеспечивает поддержку подключения 400GbE в инфраструктурах Spine/Fabric следующего поколения, которые проникают из облаков в корпоративные дата-центры. Утверждается, что энергопотребление в расчёте на порт 100GbE снижается вдвое по сравнению с существующими решениями. 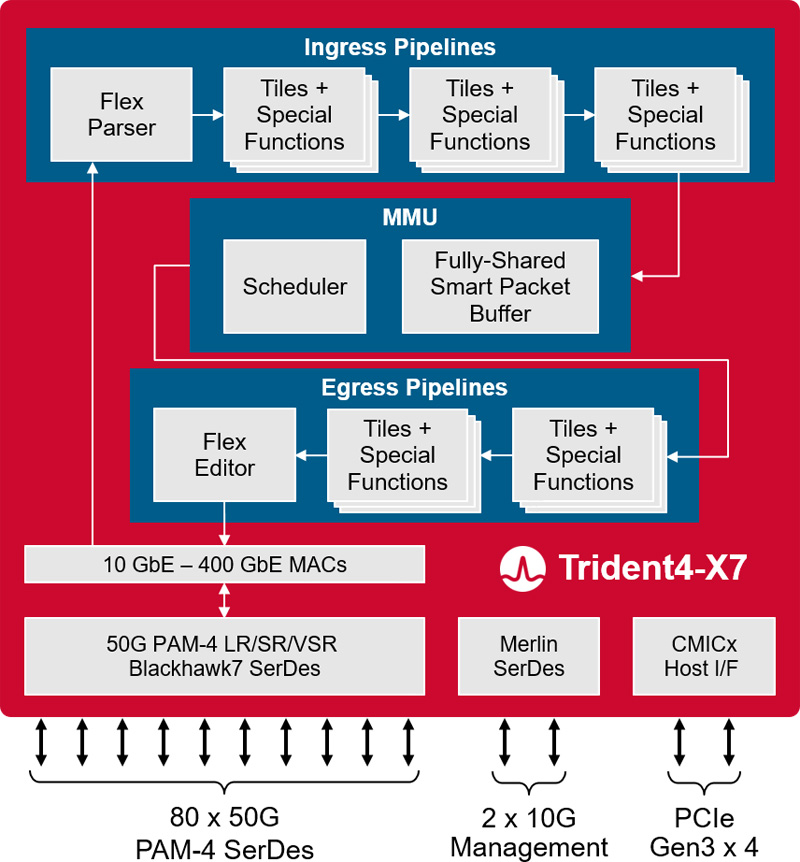
Источник изображения: Broadcom Платформа Trident 4-X7 предоставляет аппаратные функции для аналитики, диагностики и телеметрии, которые помогут облачным провайдерам автоматизировать многие операции в ЦОД. Это позволяет повысить надёжность при одновременном снижении эксплуатационных расходов. Возможность программирования даёт возможность настраивать чип под нужны конкретного оператора дата-центра. Решение поддерживает сетевую архитектуру 50G ToR (Top of Rack) в конфигурации 48 × 50G + 8 × 200G или 48 × 50G + 4 × 400G. При производстве чипа применяется технология 7-нм класса. Среди прочих преимуществ разработчик выделяет:
25.06.2023 [16:53], Алексей Степин
Cisco представила ASIC Silicon One G200: 51,2 Тбит/с для ИИКомпания Cisco успешно выпустила новые ASIC для сетевых коммутаторов с производительностью 51,2 Тбит/с. Как заявляют разработчики, коммутаторы на базе чипа серии G200 способны объединить в единый комплекс 32 тыс. ускорителей. Новое решение входит в портфолио Cisco Silicon One и изначально нацелено на рынок гиперскейлеров и создателей ИИ-кластеров. В новом чипе в два раза увеличено количество блоков SerDes с производительностью 112 Гбит/с (с 256 до 512), что и позволило довести общую коммутационную производительность до 51,2 Тбит/с. Доступны конфигурации 64×800GbE, 128×400GbE или 256×200GbE, всё зависит от желаемой плотности размещения и скорости портов. Это, в частности, позволяет избавиться от избыточных уровней в топологии сети. 
Источник изображений: Cisco Cisco отмечает, что новинка вдвое энергоэффективнее и имеет вдвое меньшую задержку в сравнении с G100. Кроме того, чипы предлагают расширенную телеметрию, поддержку языка P4 для обработки трафика на лету, а также возможность использования современных интерфейсов, в том числе интегрированную оптику или медные кабели длиной до 4 м, чего более чем достаточно для организации связи на уровне стойки. 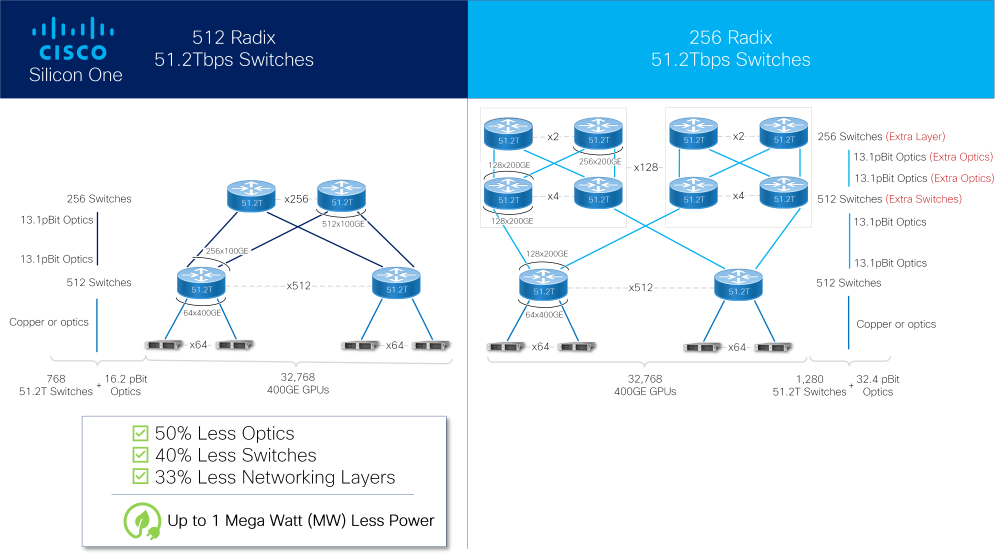 Как и Broadcom Tomahawk-5 или Jericho3-AI, Marvell Teralynx 10 и NVIDIA Spectrum-X, новый чип Cisco содержит возможности, востребованные в среде ИИ-систем, такие как продвинутые средства преодоления заторов в сети (congestion), технологии packet spraying и резервирование линков с возможностью мгновенного восстановления разорванного соединения. Новые чипы серии G200 уже поставляются, но компания пока не назвала даты появления на рынке коммутаторов Cisco на базе нового «кремния».
29.05.2023 [07:35], Сергей Карасёв
Ethernet для ИИ: NVIDIA представила 400G/800G-платформу Spectrum-XКомпания NVIDIA в ходе выставки Computex 2023 анонсировала передовую Ethernet-платформу Spectrum-X для облачных провайдеров: система поможет в масштабировании сервисов генеративного ИИ. Решение уже доступно гиперскейлерам и операторам крупных дата-центров. Платформа предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с) и 400GbE DPU NVIDIA BlueField-3. Отмечается, что BlueField-3 сочетает в себе большие вычислительные ресурсы, высокоскоростное сетевое соединение и обширные возможности программирования, что даёт возможность создавать программно-определяемые решения с аппаратным ускорением для самых требовательных задач. В результате, платформа Spectrum-X позволяет добиться 1,7-кратного увеличения производительности ИИ-нагрузок и повышения энергоэффективности по сравнению с другими решениями. 
Источник изображений: NVIDIA Для Spectrum-X заявлена возможность использования до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) на базе одного коммутатора или до 16 000 портов в случае архитектуры Spine-Leaf. В набор сопутствующего ПО входят SDK-комплекты для SDKCumulus Linux, SONiC и NetQ, а также фреймворк NVIDIA DOCA. С применением решений NVIDIA Mellanox LinkX возможно формирование сквозной 400GbE-фабрики, оптимизированной для облачных ИИ-сервисов.  Платформа Spectrum-X, в частности, будет применена в составе суперкомпьютера Israel-1, который NVIDIA строит в своём израильском дата-центре. Комплекс объединит серверы Dell PowerEdge XE9680 на основе NVIDIA HGX H100 (восемь GPU), изделия BlueField-3 DPU и коммутаторы Spectrum-4.
19.05.2023 [10:20], Сергей Карасёв
Meta✴ представила ИИ-процессор MTIA для дата-центров — 128 ядер RISC-V и потребление всего 25 ВтMeta✴ анонсировала свой первый кастомизированный процессор, разработанный специально для ИИ-нагрузок. Изделие получило название MTIA v1, или Meta✴ Training and Inference Accelerator: оно оптимизировано для обработки рекомендательных моделей глубокого обучения. Проект MTIA является частью инициативы Meta✴ по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Утверждается, что чип MTIA v1 был создан ещё в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме. 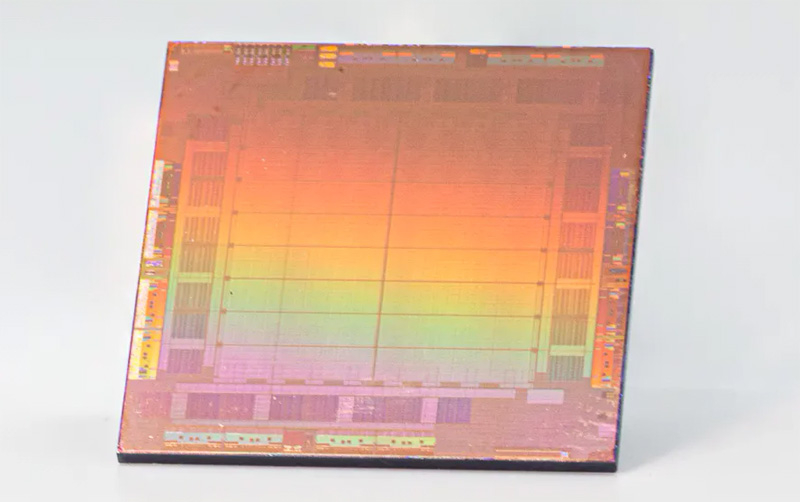
Источник изображений: Meta✴ Известно, что при производстве MTIA v1 используется 7-нм технология. Конструкция включает 128 Мбайт памяти SRAM. Чип может использовать до 64/128 Гбайт памяти LPDDR5. Задействован фреймворк машинного обучения Meta✴ PyTorch с открытым исходным кодом, который может применяться для решения различных задач в области компьютерного зрения, обработки естественного языка и пр. 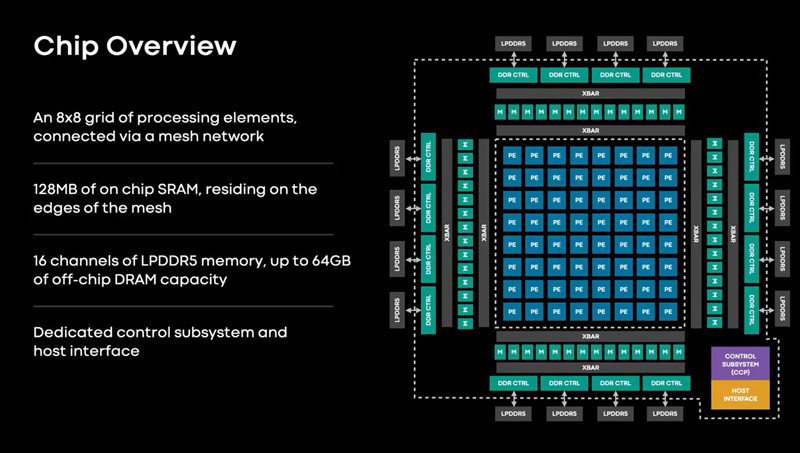 Процессор MTIA v1 имеет размеры 19,34 × 19,1 мм. Он содержит 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Тактовая частота достигает 800 МГц, заявленный показатель TDP — 25 Вт. Meta✴ признаёт, что у MTIA v1 присутствуют «узкие места» при работе с ИИ-моделями большой сложности: требуется оптимизация подсистем памяти и сетевых соединений. Однако в случае приложений низкой и средней сложности платформа, как утверждается, обеспечивает более высокую эффективность по сравнению с GPU. 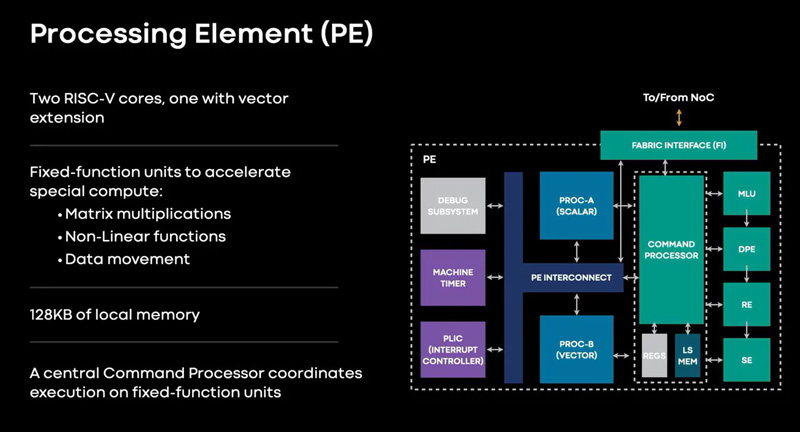 В дальнейшем в семействе MTIA появятся более производительные изделия, но подробности о них не раскрываются. Ранее говорилось, что Meta✴ создаёт некий секретный чип, который подойдёт и для обучения ИИ-моделей, и для инференса: это решение может увидеть свет в 2025 году.
19.05.2023 [10:00], Сергей Карасёв
Meta✴ анонсировала чип MSVP для ускорения обработки видеоКомпания Meta✴ представила специализированный чип MSVP, или Meta✴ Scalable Video Processor, спроектированный для ускорения выполнения операций, связанных с обработкой видеоматериалов. Это могут быть задачи по транскодированию роликов или потоковая передача контента. По данным Meta✴, пользователи соцсети Facebook✴ тратят 50 % своего времени на просмотр в общей сложности примерно 4 млрд видеороликов ежедневно. Эти материалы сжимаются после загрузки, а затем преобразовываются в другие форматы и передаются пользователям. Сложность заключается в том, чтобы быстро уменьшить размер файла, сохранить его на серверах Facebook✴ и передать в потоковом режиме с максимально возможным качеством для того или иного устройства, например, смартфона, планшета или ПК. 
Источник изображения: Meta✴ Эти задачи берёт на себя процессор MSVP. Он представляет собой интегральную схему специального назначения (ASIC). Чип предназначен для высококачественного транскодирования материалов для сервисов «видео по запросу», а также для оптимизации потоковых трансляций. В перспективе подобные процессоры, как ожидается, помогут организовать работу с видеороликами, созданными посредством генеративного ИИ. Кроме того, такие чипы будут использоваться в составе платформ AR/VR. Решение MSVP обеспечивает производительность транскодирования на уровне 4K@15в максимальном качестве в режиме «один поток на входе и пять на выходе». В стандартном качестве возможна работа в формате 4K@60.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 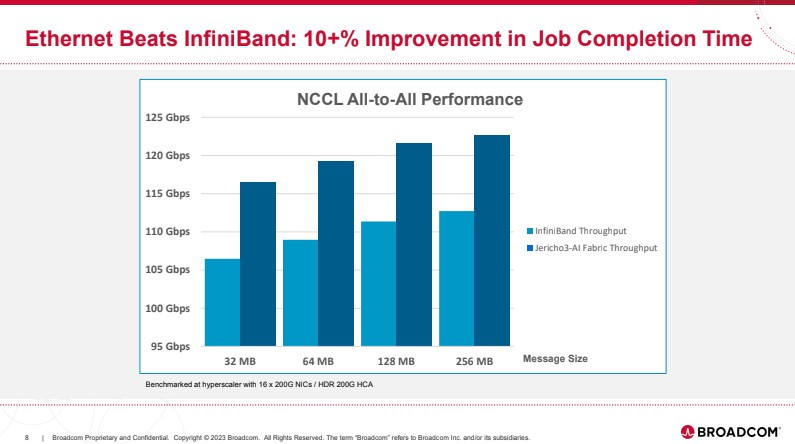 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
07.04.2023 [20:38], Сергей Карасёв
AMD представила ускоритель Alveo MA35D для «умного» кодирования AV1-видеоAMD анонсировала специализированный ускоритель Alveo MA35D для работы с видеоматериалами. Новинка приходит на смену FPGA Alveo U30 компании Xilinx, которую AMD поглотила в начале 2022 года. По сравнению с предшественником модель Alveo MA35D привносит поддержку AV1 и 8K, а также обещает четырёхкратное увеличение количества одновременно обрабатываемых видеопотоков. Решение может одновременно обрабатывать до 32-х потоков 1080p60, до восьми потоков 4Kp60 или до четырёх потоков 8Kp30. В основу ускорителя положены два VPU-блока на базе 5-нм ASIC, разработка которых началась ещё в недрах Xilinix, но которые не имеют отношения к FPGA. Каждый модуль VPU включает два «полноценных» кодировщика с поддержкой AV1/VP9/H.264/H.265 и два — только с AV1. Каждый из VPU использует 8 Гбайт собственной памяти LPDDR5, а для связи с CPU служит интерфейс PCIe 5.0 x8 (по x4 для каждого модуля). В состав VPU также входят четыре ядра общего назначения с архитектурой RISC-V. Для новинки доступен SDK-комплект с поддержкой широко используемых видеофреймворков FFmpeg и Gstreamer. 
Источник изображений: AMD (via AnandTech) Интересной особенностью является наличие выделенного ИИ-ускорителя (22 Топс) для предварительной обработки видеопотока и улучшения качества и скорости кодирования. Ускоритель покадрово определяет, какие части изображения (лица, текст и т.д.) должны быть закодированы с повышенными качестовом, а какие — нет. Также он определяет повреждённые кадры и по возможности восстанавливает или удаляет их до передачи кодировщику. При этом задержка при 4К-стриминге составляет приблизительно 8 мс. 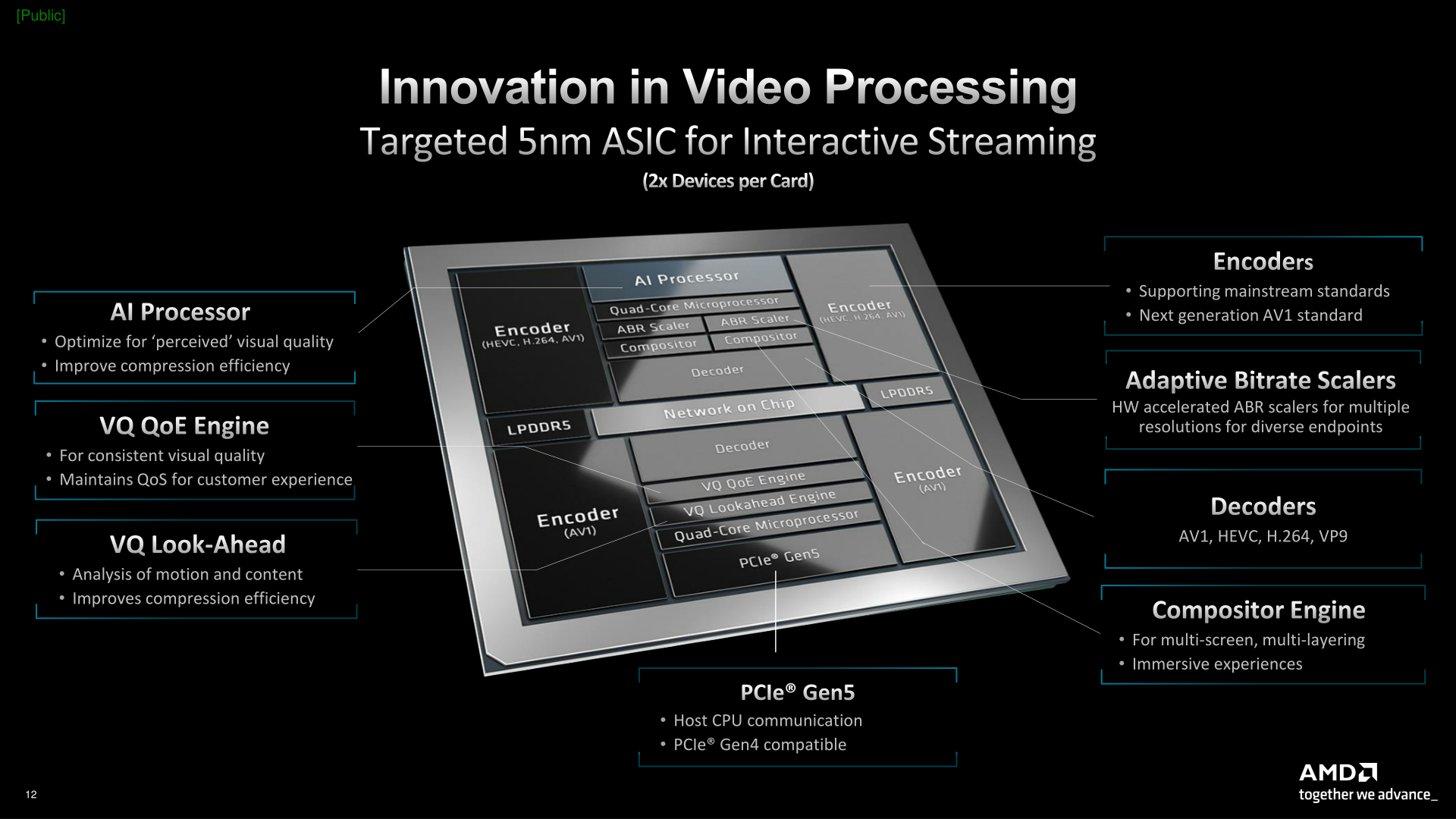 Заявленное энергопотребление составляет 1 Вт в расчёте на один канал 1080p60. Показатель TDP составляет 50 Вт, но, по заявлениям AMD, в обычных условиях он не превышает 35 Вт. Ускоритель выполнен в виде низкопрофильной однослотовой PCIe-карты. Задействована пассивная система охлаждения. В один 1U-сервер могут быть установлены до восьми таких ускорителей, что позволит одновременно обрабатывать до 256 видеопотоков. Пробные поставки карты уже начались, а массовые отгрузки намечены на III квартал 2023 года. Рекомендованная цена составляет $1595.  AMD подчёркивает, что новый (де-)кодер разработан с нуля, а не позаимствован из её же GPU. В этом отличие подхода от Intel и NVIDIA, которые предлагают использовать более универсальные GPU Flex и L4 соответственно. Alveo MA35D рассчитан на стриминговые площадки, видеохостинги и т.д. При этом Google, например, уже разработала собственные ASIC Argos, а Meta✴ заручилась поддержкой Broadcom для той же цели.
15.03.2023 [15:14], Сергей Карасёв
Phison представила обновлённую платформу Imagin+ для создания NAND-продуктовКомпания Phison Electronics в ходе мероприятия Embedded World Exhibition & Conference 2023 анонсировала обновлённую платформу Imagin+, призванную помочь в проектировании кастомизированных решений на основе флеш-памяти NAND. Imagin+ предполагает совместное использование ресурсов в области исследований и разработки, а также дизайн-сервисов в сегменте ASIC (интегральные схемы специального назначения) для создания NAND-контроллеров, устройств хранения данных, редрайверов/ретаймеров и микросхем управления питанием (PMIC). Отмечается, что работа платформы подкреплена более чем 20-летним опытом Phison в сфере НИОКР, а также более чем 2000 патентов. 
Источник изображения: Phison Electronics Компания заявляет, что Imagin+ не только позволяет партнёрам и клиентам создавать микросхемы ASIC и NAND-решения, но и даёт возможность участвовать в росте экосистемы новых технологий. Речь идёт об использовании CXL, PMIC нового поколения и пр. В целом, платформа отражает растущие потребности в хранении, передаче и высокоскоростной обработке данных, обусловленные появлением передовых приложений основе ИИ — вроде чат-бота ChatGPT. Обновлённая платформа Imagin+ предоставляет такие ресурсы, как устройства PCIe 4.0 SSD, адаптированные для космических миссий и спутникового оборудования; высокопроизводительные SSD-контроллеры PCIe, а также чипы Redriver/Retimer 5.0; карты памяти SD повышенной надёжности для медицинского оборудования; платформа X1 для PCIe 4.0 SSD корпоративного класса; CXL-решения для ЦОД нового поколения. |
|

