Материалы по тегу: dgx
|
20.03.2024 [15:25], Руслан Авдеев
BNY Mellon стал первым транснациональным банком, внедрившим ИИ-суперкомпьютер NVIDIA на базе DGX SuperPOD H100Банк Bank of New York Mellon Corporation (BNY Mellon) стал первой структурой подобного профиля и масштаба, приступившей к внедрению собственного ИИ-суперкомпьютера на основе систем NVIDIA. Банку получил кластер DGX SuperPOD из нескольких десятков систем DGX H100, объединённых интерконнектом NVIDIA InfiniBand. Основанный в 2007 году в результате слияния The Bank of New York и Mellon Financial Corporation банк намерен использовать новый суперкомпьютер вкупе с NVIDIA AI Enterprise для создания и внедрения ИИ-приложений и управления ИИ-инфраструктурой своего бизнеса. Банк уже использует более 20 ИИ-решений, в том числе для прогнозирования в сфере депозитов, автоматизации платежей, предиктивной торговой аналитики и т.д. Всего же компания нашла более 600 вариантов использования ИИ в своей банковской системе. Как заявляют в руководстве BNY Mellon, внедрение ИИ-суперкомпьютера увеличит возможности по обработке данных и запуску ИИ-проектов, помогающих управлять активами клиентов и обеспечивать их защиту. 
Источник изображения: NVIDIA Компания пока не сообщила, где будет расположен суперкомпьютер и его полные характеристики. Ранее банку принадлежал дата-центр в Нью-Джерси, также он управлял IT-объектами в Пенсильвании и Теннесси.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 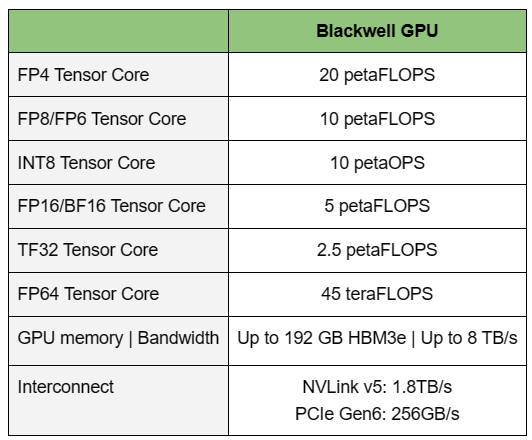 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 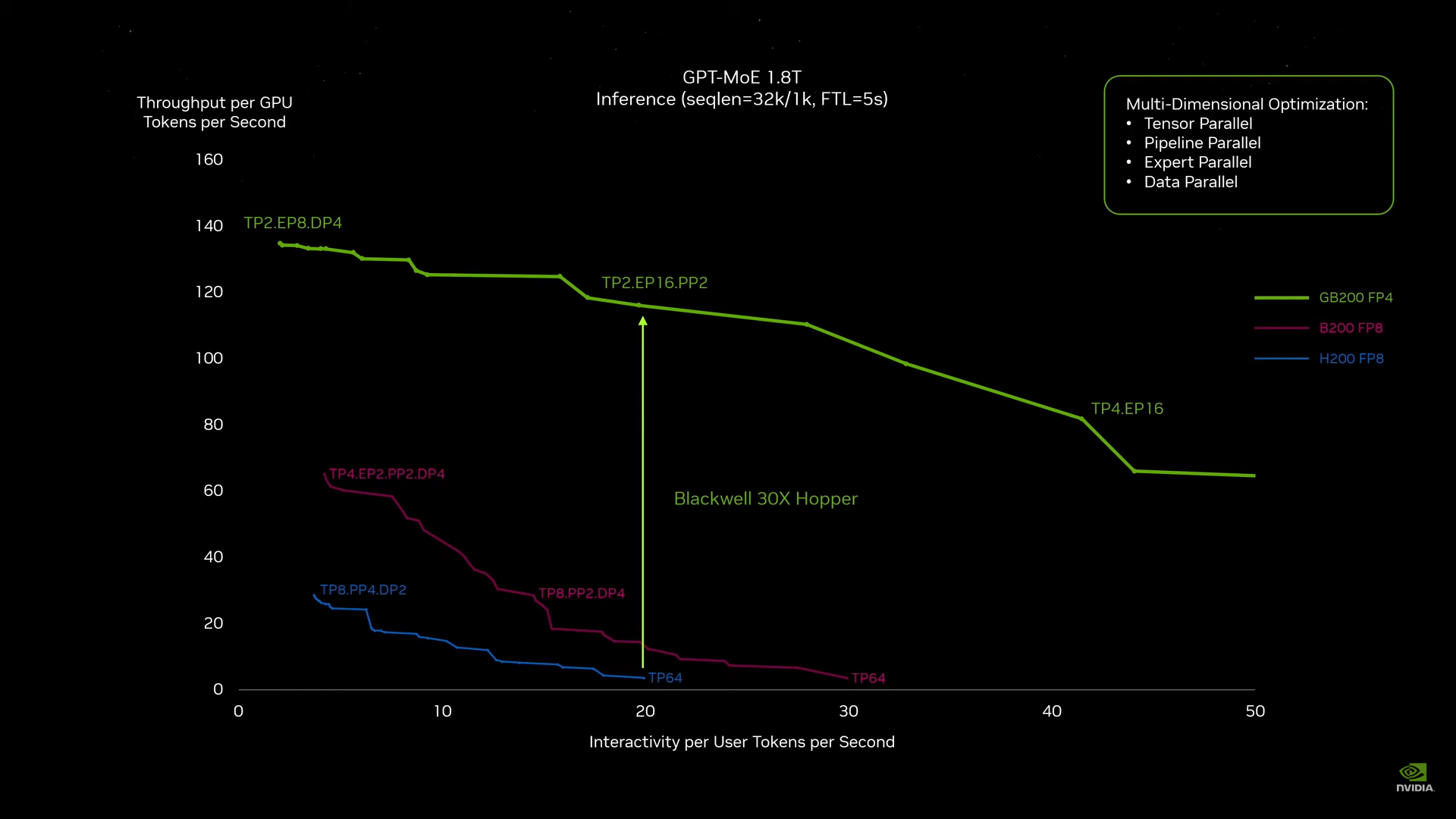 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 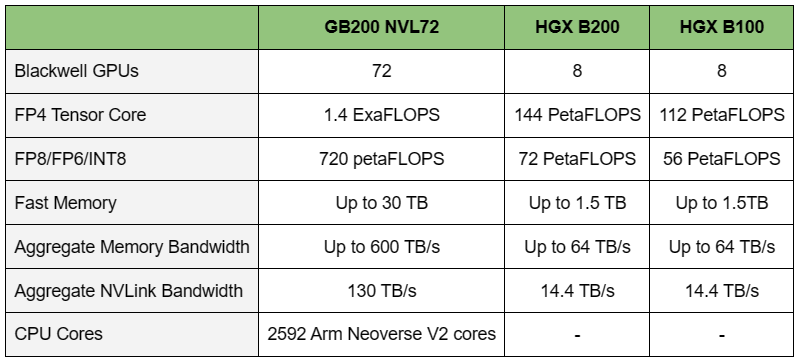 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
20.02.2024 [23:25], Сергей Карасёв
Поменьше и побольше: у NVIDIA оказалось сразу два ИИ-суперкомпьютера EOSНа днях NVIDIA снова официально представила суперкомпьютер EOS для решения ресурсоёмких задач в области ИИ. Издание The Register обратило внимание на нестыковки в публичных заявлениях компании относительно конфигурации и производительности машины. В итоге NVIDIA признала, что у неё есть две архитектурно похожих системы под одним и тем же именем. Впрочем, полной ясности это не внесло. НРС-комплекс EOS изначально был анонсирован почти два года назад — в марте 2022-го. Тогда речь шла о кластере, объединяющем 576 систем NVIDIA DGX H100, каждая из которых содержит восемь ускорителей H100 — в сумме 4608 шт. Суперкомпьютер, согласно заявлениям NVIDIA, обеспечивает ИИ-быстродействие на уровне 18,4 Эфлопс (FP8), тогда как производительность на операциях FP16 составляет 9 Эфлопс, а FP64 — 275 Пфлопс.  Вместе с тем в ноябре 2023 года NVIDIA объявила о том, что ИИ-суперкомпьютер EOS поставил ряд рекордов в бенчмарках MLPerf Training. Тогда говорилось, что комплекс содержит 10 752 ускорителя H100, а его FP8-производительность достигает 42,6 Эфлопс. Представители компании сообщили, что суперкомпьютер, использованный для MLPerf Training с 10 752 ускорителями H100, «представляет собой другую родственную систему, построенную на той же архитектуре DGX SuperPOD». Вместе с тем комплекс, занявший 9-е место в TOP500 от ноября 2023 года — это как раз версия EOS с 4608 ускорителями, представленная на днях в рамках официального анонса. Но... цифры всё не сходятся! В TOP500 FP64-производительность EOS составляет 121,4 Пфлопс при пиковом значении 188,7 Пфлопс. Сама NVIDIA, как уже было отмечено выше, называет цифру в 275 Пфлопс. Таким образом, суперкомпьютер, участвующий в рейтинге TOP500, мог содержать от 2816 до 3161 ускорителя H100 из 4608 заявленных. С чем связано такое несоответствие, не совсем ясно. Высказываются предположения, что у NVIDIA могли возникнуть сложности с обеспечением стабильности кластера на момент составления списка TOP500, поэтому система была включена в него в урезанной конфигурации.
07.02.2024 [22:31], Владимир Мироненко
Северный браузерный ИИ: Opera развернёт в исландском дата-центре atNorth кластер NVIDIA DGX SuperPOD для обучения чат-бота AriaНорвежская компания Opera Software, разработчик браузера Opera, объявила о предстоящем запуске в этом месяце ИИ-кластера на базе NVIDIA DGX SuperPOD в дата-центре atNorth в Кеблавике (Исландия). Принадлежащий atNorth ЦОД ICE02 ёмкостью более 80 МВт имеет площадь 13 750 м2 и вмещает около 3000 стоек. С помощью нового кластера Opera будет обучать встроенный в браузер чат-бот Aria на основе ИИ. Как сообщается в пресс-релизе ИИ-кластер спроектирован так, чтобы оказывать минимально возможное воздействие на окружающую среду. Он использует гидроэлектрическую и геотермальную энергию для получения энергии, и пользуется преимуществами прохладного климата Исландии для охлаждения оборудования. Кластер на базе NVIDIA DGX SuperPOD оснащён ускорителями NVIDIA H100 и программной платформой NVIDIA AI Enterprise. «Aria быстро развивается, и мы продолжаем расширять его возможности в качестве помощника в навигации для наших пользователей», — сообщил Кристиан Зубель (Krystian Zubel), вице-президент ИТ-группы компании Opera. 
Источник изображения: Opera Как отметил представитель NVIDIA Карло Руис (Carlo Ruiz), компаниям, модернизирующим свой бизнес с помощью ИИ, требуется мощная инфраструктура для разработки больших языковых моделей (LLM) и создания приложений генеративного ИИ. «NVIDIA DGX SuperPOD с ускорителями NVIDIA H100 предоставляет Opera расширенные возможности супервычислений на базе ИИ, помогая разработчикам создавать новые функции, которые сделают опыт генеративного ИИ доступным для пользователей», — заявил он.
25.01.2024 [16:57], Владимир Мироненко
Equinix Private AI поможет компаниям быстро развернуть частные ИИ-облака на базе NVIDIA DGXEquinix анонсировала полностью управляемый частный облачный сервис Private AI, который упрощает компаниям работу суперкомпьютерной ИИ-инфраструктурой NVIDIA DGX AI, ускоряя таким образом создание и запуск пользовательских моделей генеративного искусственного интеллекта (ИИ). Equinix обеспечивает поддержку и безопасность корпоративного уровня, включая помощь специалистов ЦОД IBX и экспертов NVIDIA по ИИ. Equinix Private AI охватывает системы NVIDIA DGX, сетевые решения NVIDIA и программную платформу NVIDIA AI Enterprise. Equinix развёртывает принадлежащую клиенту инфраструктуру в ЦОД IBX и управляет ей. Глава Equinix заявил, что для реализации потенциала генеративного ИИ, предприятиям необходима адаптируемая, масштабируемая гибридная инфраструктура на местных рынках. «Наш новый сервис предоставляет клиентам быстрый и экономичный способ внедрения передовой инфраструктуры ИИ, которая эксплуатируется и управляется экспертами по всему миру», — отметил он. 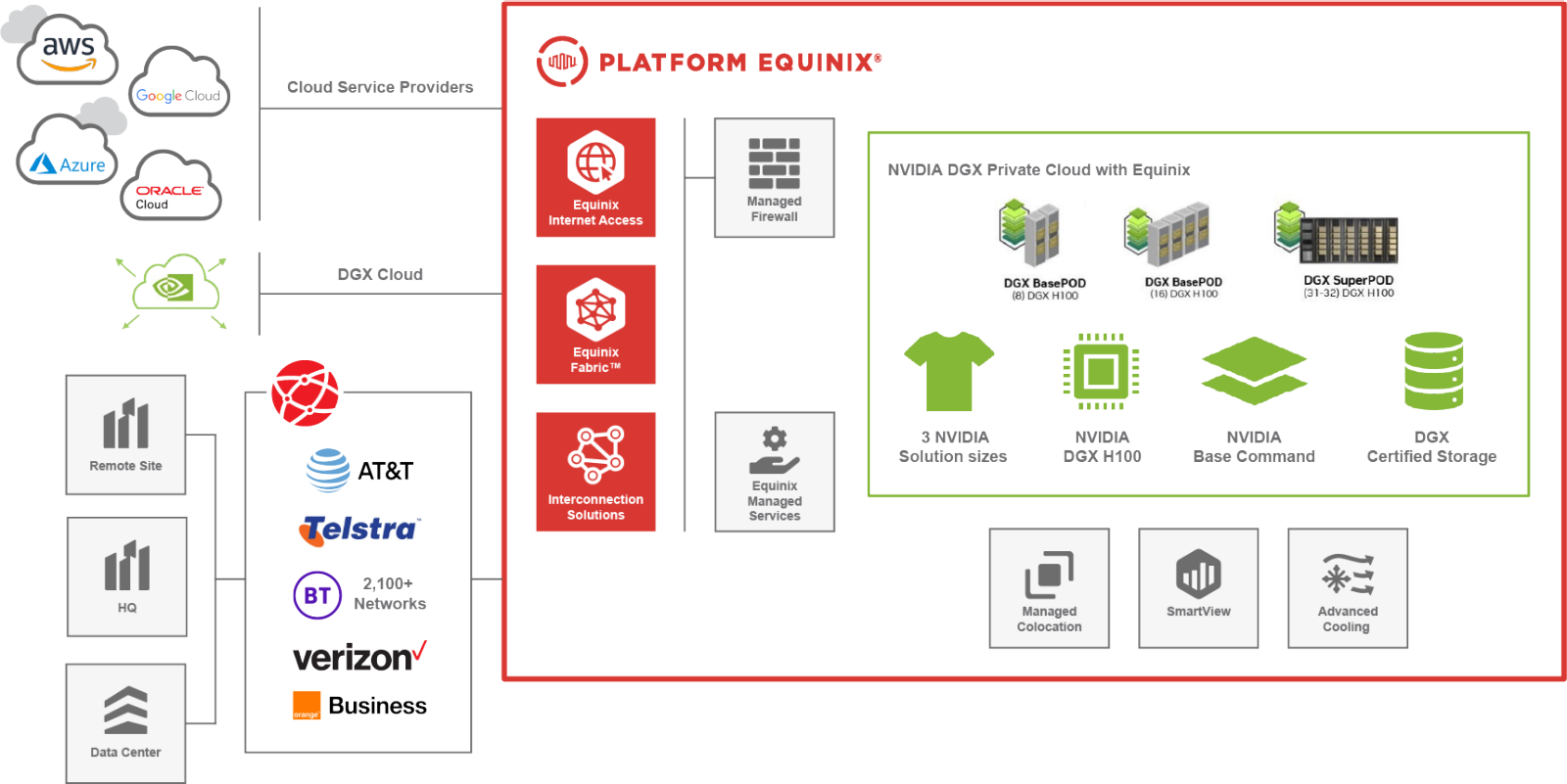
Источник изображений: Equinix Сервис уже доступен для всех желающих. Среди компаний, получивших ранний доступ к нему, есть ведущие бренды в области биофармацевтики, финансовых услуг, ПО, автомобилестроения и ретейла, которые создают центры передового опыта в области ИИ. Они формируют основу для широкого спектра быстро развивающихся вариантов использования LLM, таких как ускорение вывода на рынок новых препаратов, разработка ИИ-ассистентов для агентов по обслуживанию клиентов и виртуальных помощников по повышению производительности.  Полностью управляемый сервис NVIDIA AI от Equinix позволяет клиентам управлять своей инфраструктурой ИИ в непосредственной близости от источников данных. Сервис предлагает высокоскоростной доступ к частным сетям, облакам и поставщиками корпоративных услуг, что ускоряет обработку ИИ-нагрузок с одновременным соблюдением требований к безопасности данных и соответствием правовым нормам.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 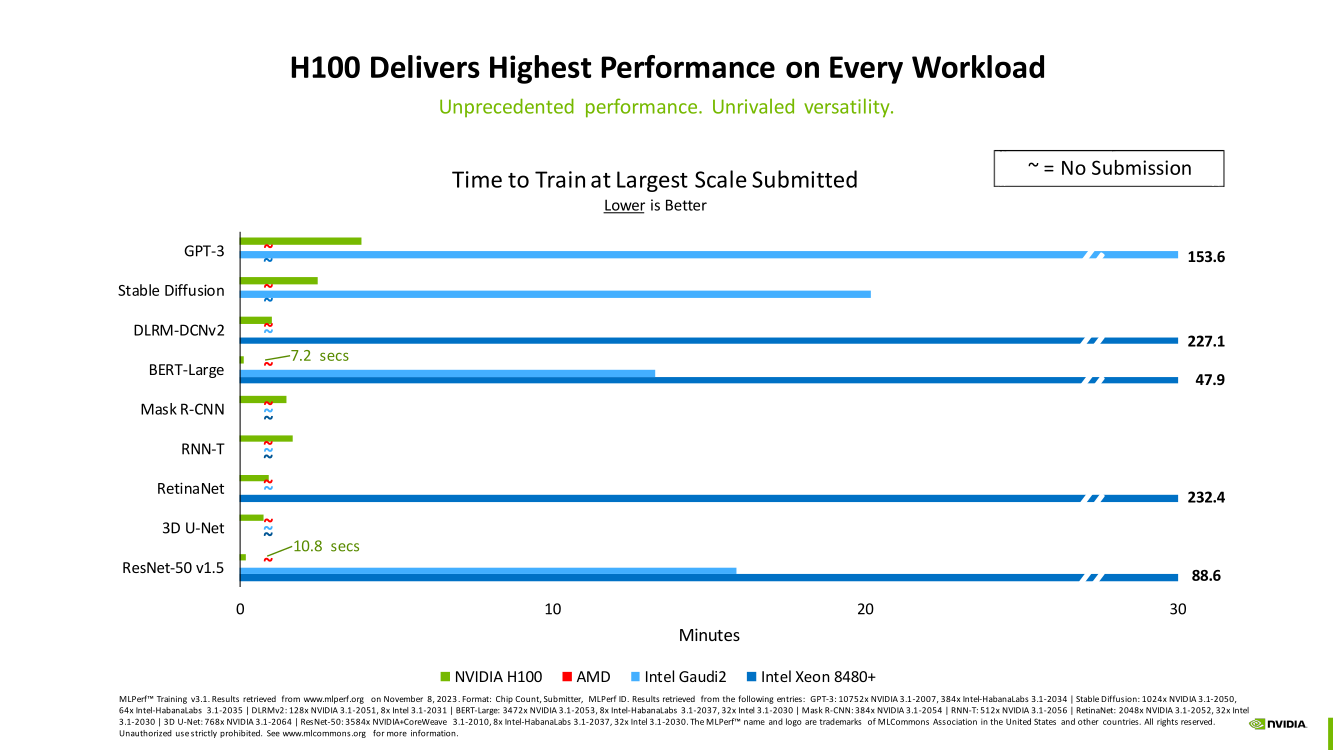 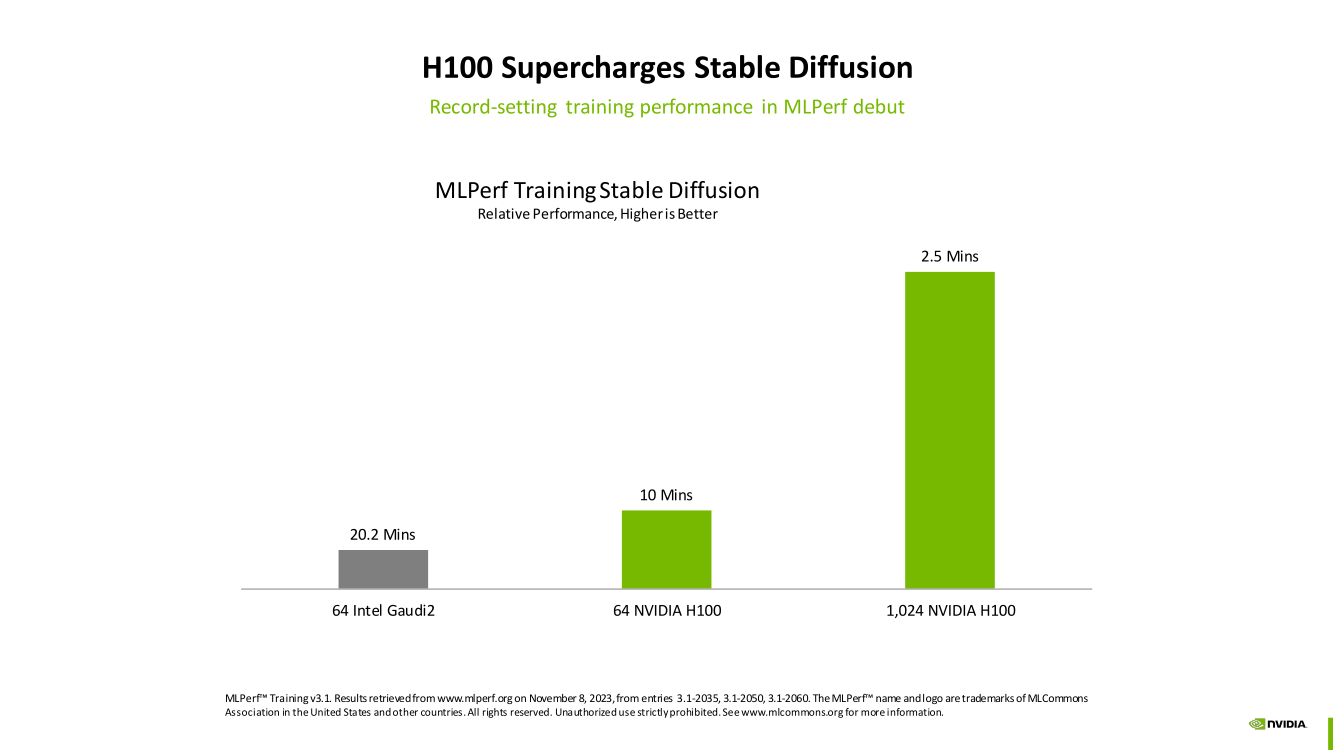 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 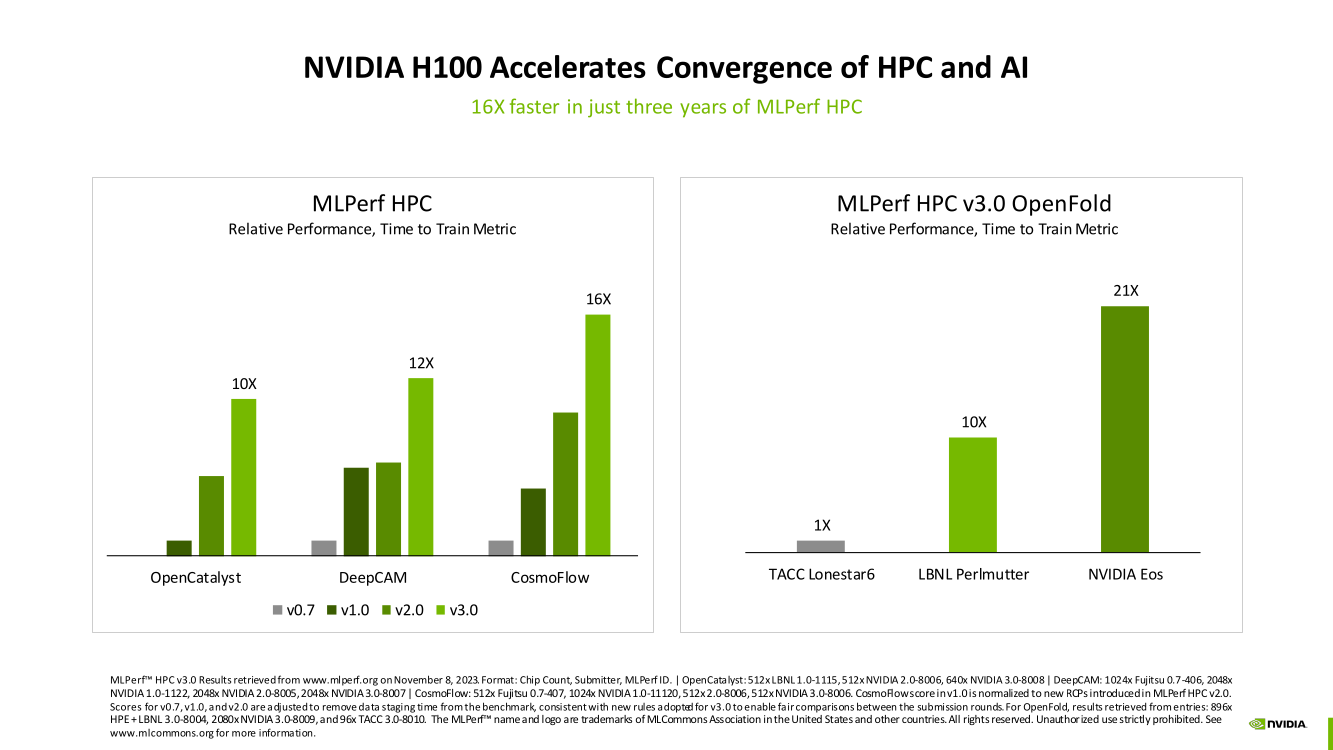
05.10.2023 [13:06], Сергей Карасёв
ИИ-провайдер 6Estates развернул свою первую систему NVIDIA DGX BasePOD на базе DGX H100Компания 6Estates, сингапурский провайдер ИИ-решений для корпоративных заказчиков, объявила о развёртывании первой системы NVIDIA DGX BasePOD на основе DGX H100. Кластер будет применяться для решения ресурсоёмких задач в области ИИ. Фирма 6Estates, созданная на базе Национального университета Сингапура и Университета Цинхуа, специализируется на предоставлении предприятиям решений, использующих LLM. Кроме того, 6Estates является участником программы NVIDIA Inception по поддержке стартапов в области ИИ. DGX BasePOD — это референсная архитектура, которая объединяет вычислительные мощности, сетевые инструменты, СХД, необходимое ПО и другие компоненты в интегрированную ИИ-инфраструктуру на основе NVIDIA DGX. 6Estates планирует использовать BasePOD на базе DGX H100 для своего нового предложения Model Solutions, которое даёт предприятиям возможность создавать персонализированные LLM и приложения для конкретных задач. Кроме того, 6Estates получит доступ к комплексному пакету фреймворков и ИИ-инструментов NVIDIA AI Enterprise. 
Источник изображения: 6Estates Используя DGX H100, 6Estates существенно сократит время обучения моделей и обеспечит более быстрое предоставление услуг Model Solutions корпоративным клиентам. Кластер также будет поддерживать существующие решения 6Estates в области ИИ, в частности, специализированную платформу, которая автоматизирует обработку и анализ неструктурированных документов без шаблонов, а также автоматизирует рабочие процессы для кредиторов и торговых компаний.
29.09.2023 [22:57], Руслан Авдеев
Французская iliad Group приобрела ИИ-кластер NVIDIA DGX SuperPOD из 1016 ускорителей H100 и задумала создать универсальный ИИФранцузская ГК iliad Group заявила о приобретении системы NVIDIA DGX SuperPOD для предоставления участникам европейского рынка IT «самого мощного» в регионе облачного ИИ-суперкомпьютера, включающего 1016 ускорителей H100 (127 систем DGX последнего поколения). За покупку отвечал облачный провайдер Scaleway, а сама машина разместилась в ЦОД Datacenter 5 в окрестностях Парижа. 
Фото: iliad Group Это только первый шаг компании на пути к достижению краткосрочной цели по предоставлению новых вычислительных мощностей клиентам. Для того, чтобы удовлетворить любые запросы клиентов, Scaleway обеспечила предоставление вычислительных мощностей небольшими блоками, по паре связанных серверов DGX H100 в каждом. В ближайшие месяцы Scaleway продолжит наращивать вычислительные способности платформы. Кроме того, iliad анонсировала создание в Париже ИИ-лаборатории, в которую уже инвестировано более €100 млн. Её главой стал миллиардер Ксавье Ниль (Xavier Niel), фактически контролирующий iliad Group. Лаборатория, как сообщается, привлекла известных исследователей из крупнейших международных компаний. Основной целью лаборатории станет помощь в создании универсального ИИ, а результаты исследований в этом направлении будут доступны публично.
27.07.2023 [15:42], Сергей Карасёв
NVIDIA объявила о доступности облака DGX Cloud для генеративного ИИКомпания NVIDIA объявила о доступности облачного сервиса DGX Cloud, предназначенного для обучения сложных моделей для генеративного ИИ и других приложений. Инфраструктура вычислительной платформы расположена в США и Великобритании. Сервис DGX Cloud был анонсирован в марте нынешнего года. Эта ИИ-платформа предоставляет предприятиям доступ к инфраструктуре и сопутствующему ПО для решения ресурсоёмких задач. Каждый экземпляр DGX Cloud оснащен восемью ускорителями NVIDIA. Инстансы могут объединяться в кластеры и управлять всем комплексом посредством NVIDIA Base Command Platform. Говорится, что на сегодняшний день тысячи ускорителей NVIDIA включены в состав Oracle Cloud Infrastructure (OCI). 
Источник изображения: NVIDIA Доступ к облачному ИИ-суперкомпьютеру клиенты могут получить через браузер. Стоимость инстансов DGX Cloud начинается с $36 999 в месяц. Заказчикам доступно ПО NVIDIA AI Enterprise — набор специализированных ИИ-инструментов, который упрощает разработку, внедрение и управление жизненным циклом ИИ-моделей.
12.07.2023 [15:35], Сергей Карасёв
Дата-центр Digital Realty в Японии получил сертификацию NVIDIA DGX H100-ReadyАмериканский оператор дата-центров Digital Realty сообщил о том, что его новый ЦОД KIX13 в Осаке (Япония) получил сертификацию NVIDIA DGX H100-Ready. Это означает, что на площадке могут использоваться системы DGX H100 для работы с ресурсоёмкими приложениями ИИ. 
Источник изображения: NVIDIA Сертификация выполнена в рамках программы NVIDIA DGX-Ready Data Center. Площадка KIX13 была открыта в феврале нынешнего года. Дата-центр имеет общую площадь приблизительно 23 тыс. м2, а полезная мощность составляет 21 МВт. Коэффициент энергоэффективности PUE равен 1,4. «Digital Realty понимает, какое влияние ИИ окажет на то, как предприятия будут проводить цифровую трансформацию в ближайшие годы. Однако бизнес-прорывы, ставшие возможными благодаря ИИ, могут быть реализованы только в том случае, если компании смогут интегрировать эту технологию в свою деятельность, и именно в этом мы им поможем», — сказал Крис Шарп (Chris Sharp), технический директор Digital Realty. |
|

