Материалы по тегу: gh200
|
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000.
27.02.2024 [16:08], Сергей Карасёв
Supermicro анонсировала ИИ- и телеком-серверы на базе AMD EPYC Siena, Intel Xeon Emerald Rapids и NVIDIA Grace Hopper
5g
amd
emerald rapids
epyc
gh200
grace
hardware
intel
mwc 2024
nvidia
siena
supermicro
ии
периферийные вычисления
сервер
Компания Supermicro представила на выставке мобильной индустрии MWC 2024 в Барселоне (Испания) новые серверы для телекоммуникационной отрасли, 5G-инфраструктур, задач ИИ и периферийных вычислений. Дебютировали модели с процессорами AMD EPYC 8004 Siena, Intel Xeon Emerald Rapids и с суперчипами NVIDIA GH200 Grace Hopper.  В частности, анонсирована стоечная система ARS-111GL-NHR высокой плотности в форм-факторе 1U на базе GH200. Устройство наделено двумя слотами PCIe 5.0 x16, восемью фронтальными отсеками для накопителей E1.S NVMe и двумя коннекторами для модулей M.2 NVMe. Сервер предназначен для работы с генеративным ИИ и большими языковыми моделями (LLM). На периферийные 5G-платформы ориентировано решение SYS-211E ультрамалой глубины — 298,8 мм. Модель рассчитана на один процессор Xeon Emerald Rapids в исполнении LGA-4677. Есть восемь слотов для модулей DDR5-5600 общей ёмкостью до 2 Тбайт и до шести слотов PCIe 5.0 в различных конфигурациях для карт расширения. Модификация SYS-211E-FRDN13P для сетей Open RAN предлагает 12 портов 25GbE и поддерживает технологию Intel vRAN Boost.  Ещё одна новинка — сервер AS-1115S-FWTRT формата 1U с возможностью установки одного процессора EPYC 8004 Siena (до 64 ядер). Реализована поддержка до 576 Гбайт памяти DDR5-4800 (шесть слотов), двух портов 10GbE, двух слотов PCIe 5.0 x16 FHFL и одного слота PCIe 5.0 x16. Решение предназначено для edge-приложений.
Представлены также многоузловая платформа SYS-211SE-31D/A и система высокой плотности SYS-221HE: обе модели выполнены в формате 2U на процессорах Xeon Emerald Rapids. Второй из этих серверов допускает монтаж до трёх двухслотовых ускорителей NVIDIA H100, A10, L40S, A40 или A2. Наконец, анонсирован сервер AS-1115SV типоразмера 1U с поддержкой процессоров EPYC 8004 Siena, 576 Гбайт памяти DDR5, трёх слотов PCIe 5.0 x16 и 10 накопителей SFF.
27.02.2024 [13:24], Сергей Карасёв
ASRock Rack представила MECAI-GH200 — самый компактный в мире сервер с суперчипом NVIDIA GH200Компания ASRock Rack продемонстрировала сервер MECAI-GH200: это, как утверждается, самая компактная в мире система, оснащённая гибридным суперчипом NVIDIA GH200 Grace Hopper с 72-ядерным Arm-процессором NVIDIA Grace и ускорителем NVIDIA H100 с 96 Гбайт памяти HBM3. Новинка выполнена в 2U-корпусе небольшой глубины. Доступны два посадочных места для накопителей формата E1.S (PCIe 5.0 х4), два коннектора для модулей М.2 (PCIe 5.0 х4) и два слота для карт расширения FHFL с интерфейсом PCIe 5.0 х16. Питание обеспечивают два блока мощностью 1600 Вт. Глубина MECAI-GH200 составляет 450 мм. Сервер предназначен для решения ИИ-задач на периферии. Прочие характеристики сервера пока не раскрываются.  «В ASRock Rack мы стремимся обеспечить возможность повсеместного использования ИИ. Для достижения этой цели мы создаём надёжные серверные решения в различных форм-факторах и для различных сценариев», — говорит вице-президент компании Хантер Чен (Hunter Chen).  ASRock Rack также представила на выставке MWC 2024 новые barebone-системы и материнские платы для процессоров Intel, AMD и Ampere. Например, впервые демонстрируется плата SIENAD8UD-2L2Q с поддержкой чипов AMD EPYC 8004 Siena и двумя сетевыми портами 25GbE SFP28.
23.02.2024 [19:07], Сергей Карасёв
Австралийский суперкомпьютерный центр внедрит суперчипы NVIDIA Grace Hopper для квантовых исследованийАвстралийский суперкомпьютерный центр Pawsey начнёт использовать решение NVIDIA CUDA Quantum — открытую платформу для интеграции и программирования CPU, GPU и квантовых компьютеров (QPU). Ожидается, что это поможет ускорить развитие перспективного направления квантовых вычислений. Pawsey развернёт в своём Национальном центре инноваций в области суперкомпьютеров и квантовых вычислений восемь узлов с суперчипами NVIDIA GH200. Эти изделия содержат 72-ядерный Arm-процессор Grace и ускоритель H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с. Сообщается, что узлы проектируемой системы будут использовать модульную архитектуру NVIDIA MGX, которая предназначена для построения HPC-систем и комплексов ИИ. Предполагается, что высокопроизводительная гибридная платформа с CPU, GPU и QPU позволит выполнять высокоточные и гибко масштабируемые квантовые симуляции. В рамках проекта будет применяться специализированное ПО NVIDIA cuQuantum для разработки квантовых решений. 
Источник изображения: NVIDIA Национальное научное агентство Австралии (CSIRO) оценивает размер внутреннего рынка квантовых вычислений в $2,5 млрд в год с потенциалом создания до 10 тыс. новых рабочих мест к 2040-му. Для достижения таких показателей необходимо внедрение квантовых вычислений в различных областях, включая астрономию, науки о жизни, медицину, финансы и пр.
10.02.2024 [20:32], Алексей Степин
Опубликованы результаты тестирования рабочей станции на базе NVIDIA GH200Поскольку NVIDIA со своим проектом Grace явно метит в мир высокопроизводительных многоядерных процессоров, результаты тестирования новых чипов представляют существенный интерес для всех, кто интересуется решениями подобного класса. Ресурс Phoronix опубликовал результаты проведённого тестирования NVIDIA GH200, причём в составе рабочей станции. Это, напомним, гибридное решение, включающее в себя 72-ядерный Arm-процессор и ускоритель H100. Сборка также включает в себя 480 Гбайт памяти LPDDR5 для процессорной части, а ускоритель располагает собственной высокоскоростной памятью HBM3e объёмом 96 Гбайт или 144 Гбайт. Связаны CPU и GPU высокоскоростной шиной NVLink-C2C с пропускной способностью 900 Гбайт/с. С периферийными устройствами GH200 может общаться посредством четырёх комплексов PCIe 5.0 по 16 линий каждый, а со стороны ускорителя имеется 18 линий NVLink 4 (900 Гбайт/с совокупно). 
Фото: GPTshop.ai Систему на тестирование предоставил магазин GPTshop.ai, позиционирующий решения на базе GH200 в качестве «настольных суперкомпьютеров». Рабочая станция в башенном корпусе включает в себя модуль GH200 на плате QCT и два блока питания мощностью 2000 Ватт, твердотельные накопители и сетевые карты NVIDIA ConnectX/Bluefield — по желанию заказчика. Стоимость стартует с отметки €47,4 тыс. 
Фото: GPTshop.ai В качестве ОС может использоваться любой дистрибутив Linux с поддержкой AArch64. В Phoronix использовали Ubuntu 23.10 с ядром версии 6.5 и стоковым компилятором GCC 13. В сравнении приняли участия системы на базе Intel Xeon Emerald Rapids, AMD EPYC и Ampere Altra Max. 
Источник: Phoronix В зависимости от сценария система на базе GH200 выступила с переменным успехом, но в среднем производительность процессорной части оказалась примерно на уровне 64-ядерных x86-процессоров — Xeon Platinum 8592+ или EPYC 9554. А 128-ядерный Altra Max M128-30 решение от NVIDIA уверенно обгоняет за счёт и более совершенной архитектуры, и более производительной подсистемы памяти. 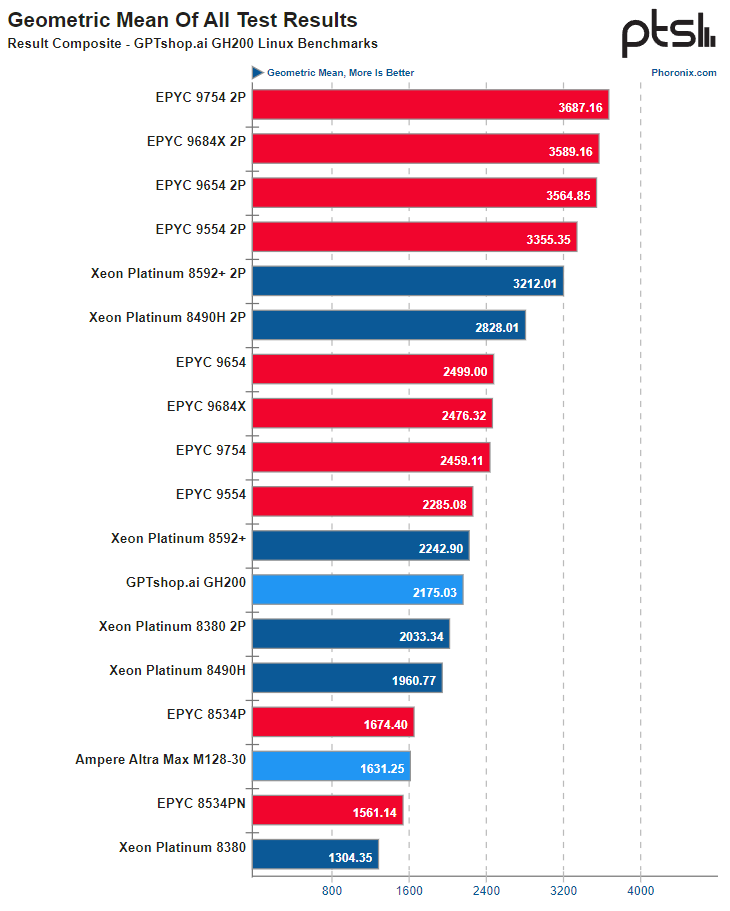
Источник: Phoronix К сожалению, вопрос энергоэффективности пока остался непроясненным, поскольку система не предоставляет интерфейсов RAPL/PowerCap/HWMON в Linux и точных метрик потребления получить невозможно, доступно лишь примерное значение потребления системы в целом через IPMI. Потенциал у GH200, определённо, есть, хотя временами и сказывается недостаточная оптимизация программного обеспечения под архитектуру AArch64. Конкуренции двухпроцессорным решениям Intel или AMD GH200 не составляет, однако в распоряжении NVIDIA имеется и 144-ядерный вариант Grace Superchip. Тестирование такой системы уже значится в планах Phoronix.
01.12.2023 [11:50], Сергей Карасёв
В основу ИИ-суперкомпьютера NCSA DeltaAI лягут суперчипы NVIDIA GH200 Grace HopperНациональный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США) сообщил о том, что в 2024 году в эксплуатацию будет введён вычислительный комплекс DeltaAI. Его основой послужат суперчипы NVIDIA GH200 Grace Hopper. Система DeltaAI создаётся с прицелом на ресурсоёмкие приложения ИИ. В рамках проекта NCSA в июле нынешнего года получил $10 млн от Национального научного фонда США (NSF). Инициатива DeltaAI направлена на расширение использования возможностей ИИ при реализации различных исследовательских задач. Комплекс DeltaAI станет дополнением к суперкомпьютеру Delta, который заработал в NCSA в 2022 году. Данная система занимает 199-е место в ноябрьском рейтинге TOP500 с быстродействием около 3,81 Пфлопс. Теоретическая пиковая производительность достигает 8,05 Пфлопс. В основу положены процессоры AMD EPYC 7763 Milan и интерконнект Slingshot-10. 
Источник изображения: NCSA Отмечается, что DeltaAI утроит вычислительные мощности NCSA, ориентированные на задачи ИИ, и значительно расширит ресурсы, доступные в НРС-экосистеме, финансируемой NSF. Благодаря использованию передовых интерфейсов система DeltaAI будет более доступна для различных исследовательских ИИ-проектов. Производительность DeltaAI пока не раскрывается. Нужно отметить, что суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру. Это, в частности, первый европейский суперкомпьютер экзафлопсного класса Jupiter, британский комплекс Isambard-AI в Бристольском университете и пр.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
21.11.2023 [09:51], Сергей Карасёв
Европейский экзафлопсный суперкомпьютер Jupiter получит универсальный блок cCuster на европейских Arm-процессорах SiPearl RheaВ 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Профессор Томас Липперт (Thomas Lippert; на фото ниже) из FZJ рассказал об особенностях конфигурации этой системы. Ранее сообщалось, что в состав Jupiter будет включён высокомасштабируемый блок ускорителей (Booster). Речь идёт об использовании платформы Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули NVIDIA Quad GH200. Общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Блок Booster предназначен для решения особо ресурсоёмких задач. Как сообщил господин Липперт, второй составляющей НРС-комплекса станет универсальный блок cCuster, который сможет поддерживать приложения всех типов: это, в частности, операции с высокой интенсивностью использования данных. Оба блока можно будет использовать по отдельности или вместе, что позволит добиться максимальной эффективности при реализации различных проектов. В основе cCuster — энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Эти изделия обеспечивают высокое соотношение производительности к пропускной способности — 0,5 байт/флоп. Поэтому процессоры хорошо подходят для сложных приложений с интенсивным использованием данных. 
Источник изображения: FZJ Все вычислительные узлы Jupiter подключены к высокопроизводительной сети NVIDIA Mellanox InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность «незначительно превысит 1 Эфлопс». Общая стоимость проекта составит €273 млн, включая доставку, установку и обслуживание Jupiter.
18.11.2023 [23:57], Сергей Карасёв
ИИ-суперкомпьютер «под ключ»: HPE и NVIDIA представили HPC-платформу на базе гибридных суперчипов Grace HopperКомпании HPE и NVIDIA анонсировали модульную суперкомпьютерную систему для генеративного ИИ и обучения моделей на основе частных массивов данных. Комплекс ориентирован на крупные предприятия, исследовательские организации и государственные структуры. В основу решения положена аппаратная платформа Cray EX2500. В состав входят суперчипы NVIDIA GH200 Grace Hopper, содержащие 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Каждый узел системы использует четыре таких суперчипа. Узлы соединены друг с другом при помощи интерконнекта Slingshot. Говорится, что реализованная архитектура позволяет осуществлять масштабирование до тысяч ускорителей. При этом все мощности могут выделяться для решения одной задачи ИИ, что обеспечивает максимальную эффективность использования ресурсов. По сути, новое решение представляет собой мини-версию ИИ-суперкомпьютера Isambard-AI, который разместится в Бристольском университете (Великобритания). HPE и NVIDIA будут предлагать систему в качестве решения «под ключ» с услугами по установке и настройке. 
Источник изображения: HPE Кроме того, предусмотрен стек ПО для решения различных ИИ-задач: это среда HPE Machine Learning Development Environment, набор инструментов HPE Cray Programming Environment, а также пакет NVIDIA AI Enterprise. В целом, как отмечается, новая система предлагает заказчикам производительность и масштабируемость, которые позволяют решать наиболее сложные ИИ-задачи, включая обучение больших языковых моделей (LLM) и создание рекомендательных систем.
14.11.2023 [19:26], Сергей Карасёв
TACC получит ИИ-суперкомпьютер Vista с суперчипами NVIDIA GH200 Grace HopperТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) на конференции по высокопроизводительным вычислениям SC23 анонсировал суперкомпьютер Vista, ориентированный на задачи ИИ и машинного обучения. Запуск этого комплекса в эксплуатацию запланирован на начало 2024 года. Отмечается, что Vista станет связующим звеном между нынешним суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Ввод Horizon в строй намечен на 2025 год: ожидается, что этот комплекс будет на порядок быстрее Frontera. Что касается Vista, то эта система знаменует собой переход от традиционной архитектуры х86, которая применяется во Frontera и системах Stampede, в пользу Arm. В частности, будут задействованы суперчипы NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. В составе Vista чипами GH200 будут оборудованы немногим более половины всех вычислительных узлов. Оставшиеся узлы получат процессор NVIDIA Grace CPU Superchip, содержащий два кристалла Grace в одном модуле (144 ядра). 
Источник изображения: TACC Для Vista предусмотрено использование 400G-интерконнекта NVIDIA Quantum-2 InfiniBand. Компания VAST Data предоставит для суперкомпьютера высокопроизводительное флеш-хранилище, подключенное к Stampede3. Вычислительные узлы будут производиться компанией Gigabyte, а интеграцию обеспечит Dell. |
|


