Материалы по тегу: ускоритель
|
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 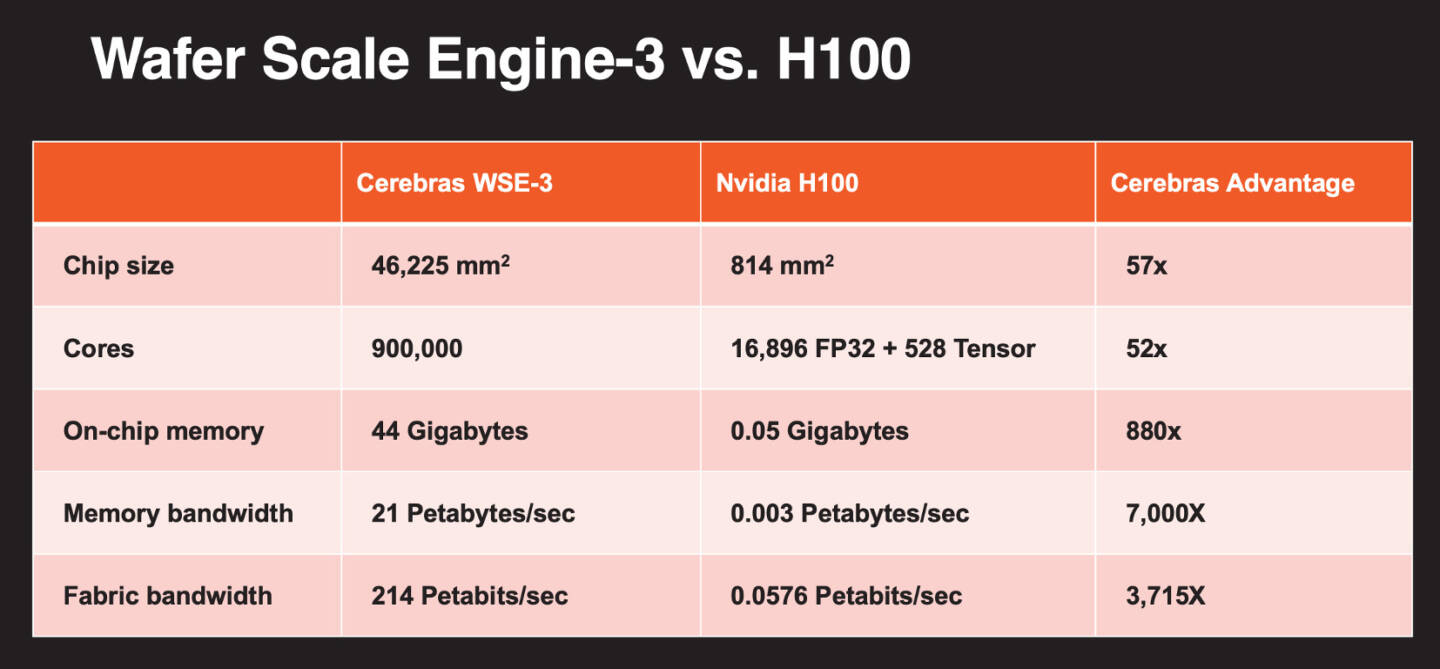 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 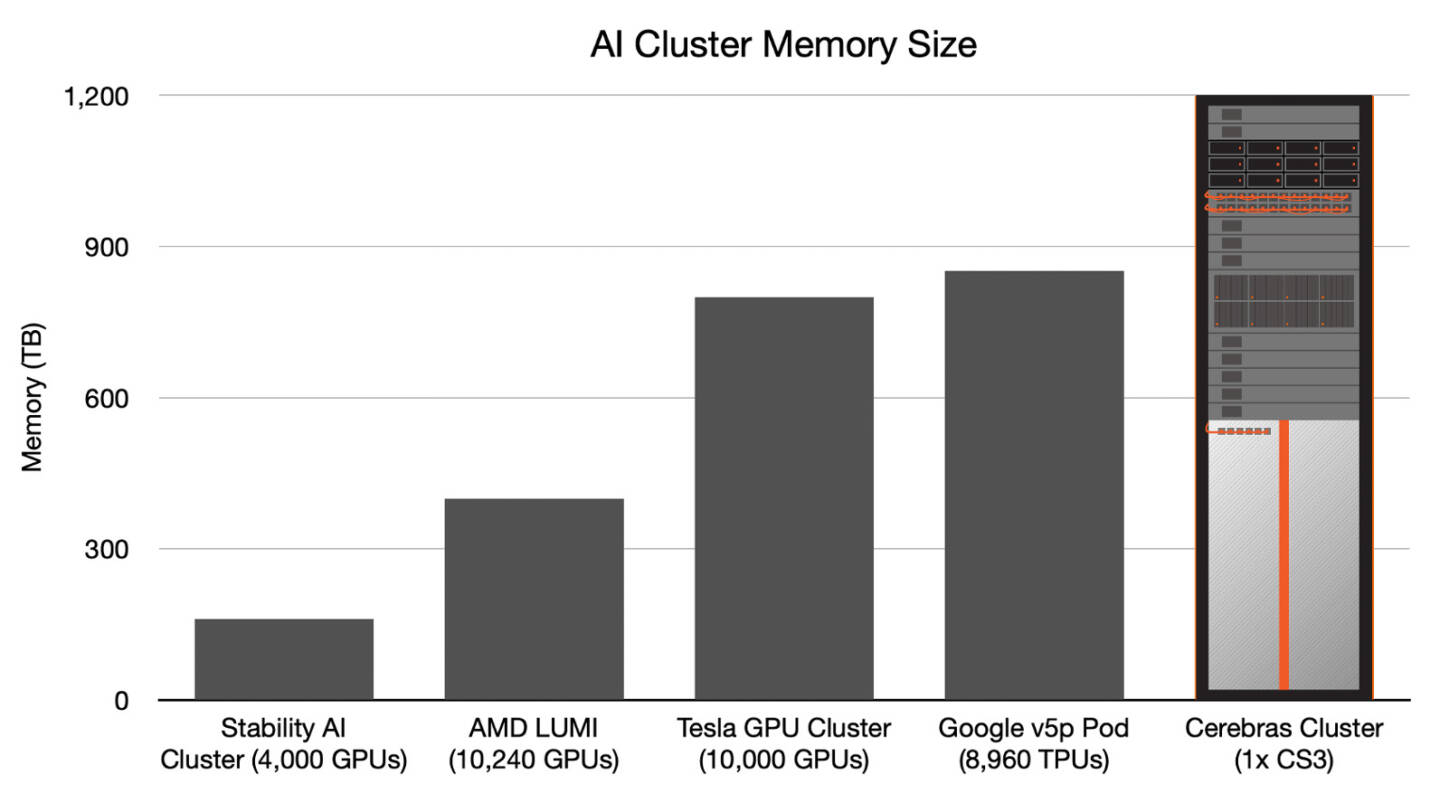 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 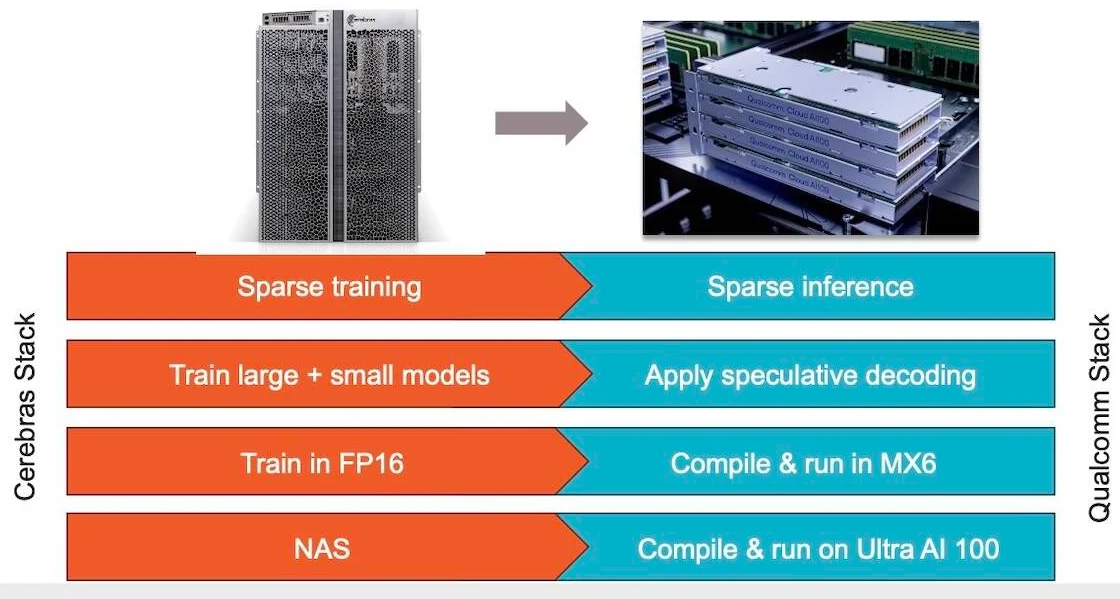 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
10.03.2024 [21:00], Сергей Карасёв
В Южной Корее создан сверхэффекттивный ИИ-чип, сочетающий классический и нейроморфный подходыИсследователи из Южной Кореи разработали, как утверждается, первый в мире полупроводниковый ИИ-чип, который обладает высоким быстродействием при минимальном энергопотреблении. Изделие, предназначенное для обработки больших языковых моделей (LLM), основано на принципах, имитирующих структуру и функции человеческого мозга. В работе приняли участие специалисты Корейского института передовых технологий (KAIST). Утверждается, что при обработке модели GPT-2 новинка по сравнению с ускорителем NVIDIA A100 затрачивает в 625 раз меньше энергии и занимает в 41 раз меньше физического пространства. Таким образом, южнокорейский ИИ-чип теоретически может применяться даже в смартфонах. Чип производится по 28-нм процессу Samsung Electronics. 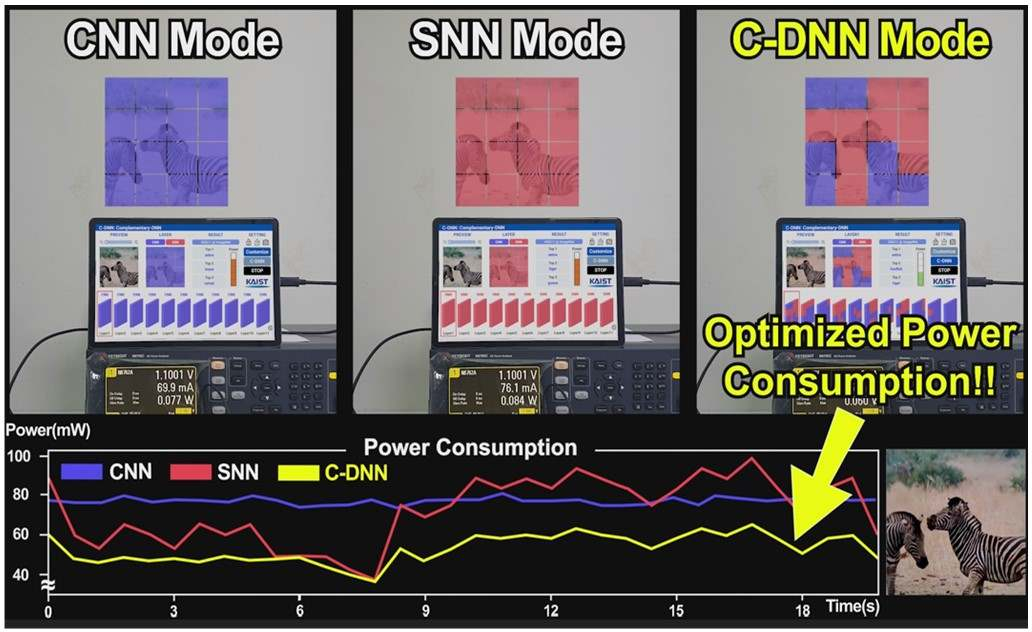
Источник изображений: KAIST Отмечается, что обычно для обработки модели GPT-2 требуются ускорители на базе GPU, потребляющие около 250 Вт энергии. Разработанное изделие требует для этого всего от 40 мВт, а его размеры составляют 4,5 × 4,5 мм. Причём на выполнение операций затрачивается только 0,4 с. Чип наделён 552 Кбайт памяти SRAM. Напряжение питания варьируется от 0,7 до 1,1 В. Тактовая частота варьируется в диапазоне 50–200 МГц. 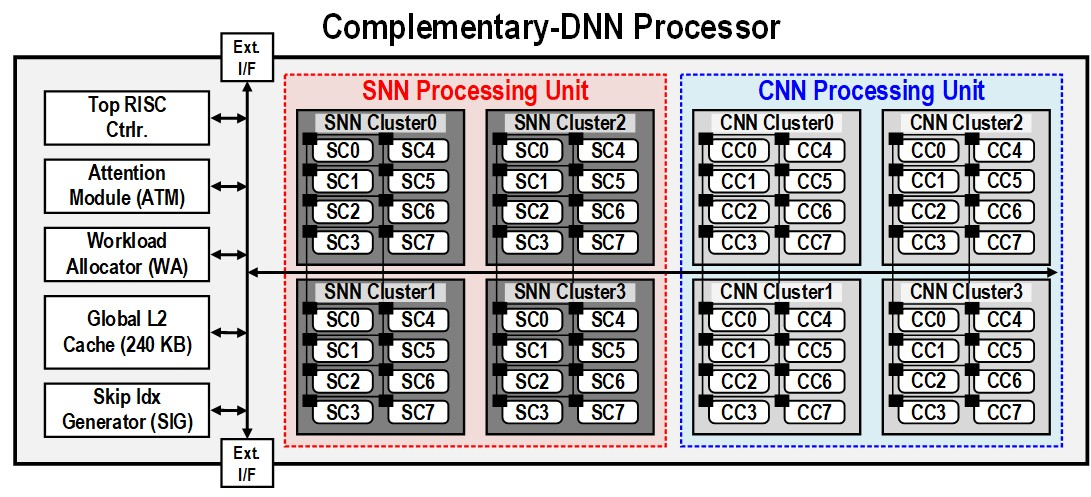 Технология, получившая название C-DNN (Complementary Deep Neural Network) позволяет использовать свёрточные нейронные сети (CNN) и импульсные нейронные сети (SNN), имитирующие процессы, которые задействованы в человеческом мозге при обработке информации. Иными словами, обучение происходит через несколько слоёв нейронных сетей, а потребление энергии варьируется в зависимости от когнитивной нагрузки. Технология минимизирует энергозатраты благодаря использованию DNN для больших входных значений и SNN для меньших. Правда, чип поддерживает максимум INT16. 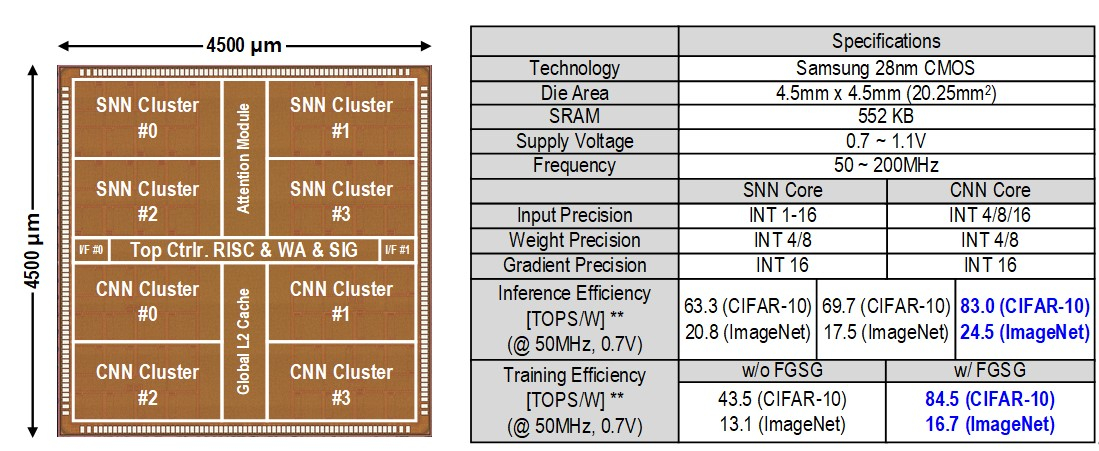 Утверждается, что C-DNN является первым ускорителем, который может поддерживать распределение рабочей нагрузки CNN/SNN, используя компромисс между производительностью и энергопотреблением. Изделие обеспечивает энергоэффективность на уровне 85,8 TOPS/Вт и 79,9 TOPS/Вт для инференса с наборами данных CIFAR-10 и CIFAR-100 соответственно (VGG-16). Энергоэффективность в случае ResNet-50 составляет 24,5 TOPS/Вт. При обучении чип C-DNN демонстрирует энергоэффективность в 84,5 TOPS/Вт и 16,7 TOPS/Вт для CIFAR-10 и ImageNet соответственно. Результаты получены при напряжении 0,7 В и частоте 50 МГц. 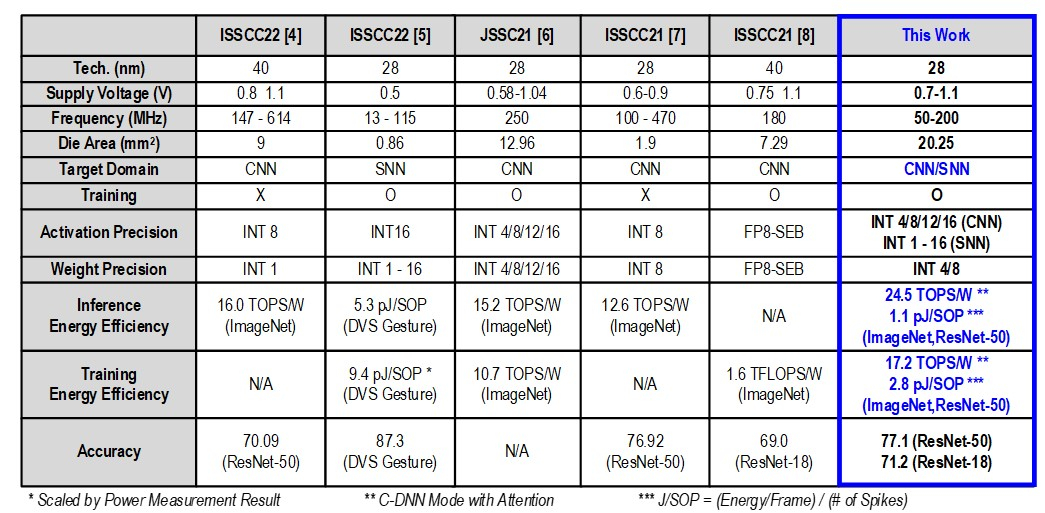 «Нейроморфные вычисления, имитирующие функции мозга, — это технология, которую такие крупные компании, как IBM и Intel, пока по-настоящему не реализовали. Мы гордимся тем, что первыми в мире начали использовать LLM со сверхэффективным нейроморфным ускорением», — говорит руководитель проекта профессора Ю Хой-Джун (Yu Hoi-jun).
07.03.2024 [14:12], Владимир Мироненко
Индивидуальный подход: разработчик специализированных ИИ-чипов Taalas привлёк $50 млн инвестицийСтартап Taalas Inc., занимающийся разработкой специализированных чипов ИИ, объявил о выходе из скрытого режима (stealth mode) и привлечении $50 млн инвестиций в ходе двух раундов финансирования, которые возглавили Quiet Capital и венчурный капиталист Пьер Ламонд (Pierre Lamond). Taalas была основана выходцами из Tenstorrent, ещё одного разработчика ИИ-ускорителей. Практически все чипы ИИ оптимизированы для ускорения перемножения матриц, что необходимо для работы нейронных сетей, отметил ресурс SiliconANGLE. Некоторые чипы имеют дополнительные оптимизации, ориентированные на конкретные случаи использования ИИ. Например, ИИ-ускоритель NVIDIA H200 оснащён увеличенным объёмом высокоскоростной памяти для ускорения инференса больших языковых моделей (LLM). Taalas занимается дальнейшим развитием этой концепции. Как сообщил ресурс The Information, компания разрабатывает ускорители, которые не просто оптимизированы для обработки ИИ-нагрузок, а построены с учётом требований конкретной нейронной сети. Компания считает, что такой подход сделает её чипы значительно быстрее, чем ИИ-ускорители общего назначения от ведущих производителей. 
Источник изображения: Taalas «Коммерческое использование ИИ требует 1000-кратного улучшения вычислительной мощности и эффективности — цель, которая недостижима с помощью нынешних поэтапных подходов, — заявил Любиша Бажич (Ljubisa Bajic), сооснователь и гендиректор Taalas. — Путь вперёд — реализовать внедрение моделей глубокого обучения в кремнии — это самый верный путь к устойчивому ИИ». Разработка собственного ускорителя может занять годы и потребовать сотни миллионов долларов инвестиций. Также создание чипов, оптимизированных для разных алгоритмов искусственного интеллекта, вероятно, будет сопряжено с серьезными техническими проблемами. С целью их решения компания разрабатывает автоматизированный рабочий процесс проектирования, который, по её словам, позволит ускорить вывод полупроводников на рынок. Один из разрабатываемых Taalas чипов будет содержать достаточно памяти для хранения «большой модели ИИ» без надобности во внешней оперативной памяти, что позволит ускорить обработку данных. Taalas планирует выпустить свой первый чип для больших языковых моделей в III квартале 2024 года и начать его поставку клиентам в I квартале 2025 года.
05.03.2024 [21:32], Руслан Авдеев
Ускорители AMD Instinct MI309 оказались недостаточно слабы, чтобы США позволили продавать их КитаюПо неподтверждённым пока данным, компания AMD провалила попытку снизить производительность своих ИИ-ускорителей таким образом, чтобы те соответствовали экспортным ограничениям США. Bloomberg сообщает, что по этой причине Вашингтон пока запретил поставлять их в Китай. Это довольно распространённая тактика среди производителей чипов — Китай является одним из крупнейших рынков полупроводников в мире и отказываться от него по политическим соображениям компании не хотели бы, поскольку должны учитывать интересы акционеров, рассчитывающих на максимальную прибыль. Возможно, рынок заметно вырастет в ближайшее время, поскольку Пекин огласил планы сделать ИИ сердцем экономического развития. Другими словами, выпуск продуктов для Китая — очень выгодный бизнес. В Bloomberg предполагают, что в AMD посчитали новые ускорители, известные как MI309, пригодными для продажи в Поднебесную, но Министерство торговли США, ответственное за выдачу экспортных лицензий, посчитало чипы чересчур производительными. Речь идёт об урезанной версии MI300, при этом ускорители MI210 в Китай поставляются. Упрощённые ускорители A800 и H800 уже выпускала NVIDIA, но после ужесточения запретов в октябре 2023 года она разработала новые варианты (H20, L20 и L2) с ещё более скромной производительностью. Пока же её продажи в КНР упали. 
Источник изображения: Maxence Pira/unsplash.com Тем временем китайские IT-гиганты накопили огромные запасы ускорителей впрок и компании вроде Baidu и Tencent сообщают, что складских остатков хватит на год-два бесперебойного обеспечения ИИ-проектов. Примечательно, что Baidu говорит о своих разработках в контексте их сравнения с мировыми, а не местными конкурентами. При этом Baidu закупила и местные ИИ-ускорители Huawei Ascend 910B. Хотя китайские лидеры полупроводниковой отрасли хотя и отстают от AMD, Intel и NVIDIA, сбрасывать со счетов их не стоит. При этом некоторые китайские производители чипов занимаются созданием совместимых с CUDA решений. Это косвенно свидетельствует о том, что просто качественного «железо» для успеха мало — необходима совершенная программная среда для его эксплуатации. Это пока является слабым местом китайских разработок, отмечает The Register.
04.03.2024 [20:32], Руслан Авдеев
NVIDIA признала в Huawei потенциального соперника на ниве ИИ-ускорителейКитайская Huawei вновь попала в центр внимания СМИ после того, как глава NVIDIA признал её достижения в сфере ИИ-решений. По данным SCMP, хотя в отношении Китая Соединённые Штаты ввели жёсткие санкции, Huawei смогла предложить в материковом Китае альтернативу высокопроизводительным ускорителям NVIDIA. Ускоритель Ascend 910B уже доступен в Поднебесной и, по данным отраслевых экспертов, его производительность сравнима с характеристиками NVIDIA A100. По мнению экспертного сообщества, новинка выпускается ведущим контрактным производителем полупроводников Китая — компанией SMIC, тоже находящейся под американскими санкциями. Выпуск осуществляется в соответствии с 7-нм техпроцессом. В самой Huawei слухи о своих ускорителях не комментируют, хотя и признают, что ИИ является ключевой частью стратегии компании. Хотя ещё в 2019 году против Huawei введены США жёсткие санкции, компания сумела «перегруппироваться», нашла новых поставщиков в Китае, а летом прошлого года представила свой первый за несколько лет 5G-смартфон — Mate 60 Pro на базе флагманского 7-нм чипсета Kirin 9000, без лишнего шума разработанном под санкциями. Уже тогда «возрождение» Huawei оказалось в центре внимания СМИ, политиков и бизнеса. ИИ-чип Huawei появился приблизительно в то же время, а китайский поисковый гигант Baidu заказал сразу 1600 таких ускорителей. К нему присоединились и другие компании из КНР, занимающиеся ИИ-проектами и обучением больших языковых моделей (LLM). 
Источник изображения: Huawei В прошлом месяце глава NVIDIA Дженсен Хуанг (Jensen Huang) признал значимость конкурента, назвав в одном из интервью Huawei «очень, очень хорошей компанией». По его словам, Huawei, испытывая проблемы с доступом к современным технологиям, тем не менее, может объединять в кластеры многочисленные ускорители собственной разработки, чтобы повысить производительность обработки ИИ-задач. Пока, по данным китайских источников, новые чипы можно заказать, но с поставками наблюдаются некоторые трудности. По имеющимся сведениям, сервер с восемью ускорителями Ascend 910B стоит около ¥1,5 млн или немногим более $208 тыс. — приблизительно за столько же на местном чёрном рынке можно приобрести контрабандный сервер с NVIDIA A100. Эксперты не спешат комментировать возможную конкуренцию Huawei и NVIDIA, ограничиваясь замечаниями о том, что американская сторона имеет большой опыт ещё со времён разработки игровых GPU и предлагает целую экосистему на базе CUDA. Вероятно, Huawei придётся вложить средства в развитие программной экосистемы или делегировать это другим компаниям, сосредоточившись на разработке «железа». Но конкуренция с NVIDIA в любом случае не будет лёгкой.
04.03.2024 [17:00], Руслан Авдеев
Евросоюз намерен добиться полупроводникового суверенитета, используя архитектуру RISC-VВ Евросоюзе активно инвестируют в инициативы, призванные обеспечить полупроводниковый суверенитет благодаря использованию открытой архитектуры RISC-V. EE Times сообщает, что инициативу курирует Барселонский суперкомпьютерный центр (Barcelona Supercomputing Center или BSC) — пионер в разработке европейских решений RISC-V. 
Источник изображений: European Processor Initiative (EPI) Страны ЕС беспокоит полупроводниковая зависимость от иностранных компаний, и это беспокойство усугубляется относительно недавним дефицитом чипов в мире. В то же время за использование в своих решениях архитектуры RISC-V никому не надо платить и ни у кого не нужно получать разрешений на её применение, поэтому технология так привлекательна для разработчиков. BSC представляет собой один из ведущих исследовательских центров Европы. Он играет ключевую роль в разработке чипов на архитектуре RISC-V и возглавляет несколько проектов, связанных с этой технологией, в частности, European Processor Initiative (EPI). В рамках инициативы EPI стоимостью €70 млн разрабатывается новое поколение высокопроизводительных процессоров. Связанная с BSC компания OpenChip должна найти коммерческое применение разработанным технологиям.  BSC начал создавать собственные чипы семейства Lagarto довольно давно — первые 65-нм варианты представили ещё в мае 2019 года. Сегодня речь идёт уже о четвёртом поколении, которое будет выпускаться в соответствии с 7-нм техпроцессом. Центр работает и с другими европейскими компаниями и исследовательскими организациями над созданием комплексной экосистемы RISC-V, включающей ПО, ОС и компиляторы. Подобные инициативы должны снизить зависимость Евросоюза от американских и азиатских производителей — отсутствие в ЕС зрелой индустрии высокопроизводительных чипов расценивается как значимая уязвимость. Европа считает, что RISC-V — идеальная платформа для достижения суверенитета, при этом бесплатная. Впрочем, эксперты признают, что о полной независимости не может быть речи из-за сложности экосистемы полупроводниковой индустрии. Но у Европы есть большая база знаний и потенциал разработки новых решений, предпринимаются и шаги к организации производства.  В BSC уже экспериментировали с Arm-процессорами, но после Brexit и приобретения компании Arm группой Softbank, выяснилось, что собственной региональной технологии у ЕС нет, тогда и обратили внимание на общедоступную RISC-V. В 2019 году Еврокомиссию убедили в необходимости начать выпуск чипов на этой архитектуре для суперкомпьютеров. В числе других европейских компаний, предлагающих RISC-V продукты, есть Gaiser, Esperanto Technologies, Semidynamics и Codasip, но они уделяют больше внимания процессорам и ускорителям, а не конечным готовые решения. По оценкам экспертов, в Евросоюзе компаний, работающих с RISC-V, пока недостаточно. Тем не менее, организаторы новых инициатив предостерегают от нереалистичных ожиданий и призывают к стратегическому сотрудничеству — для производства требуются не только разработки, но и сырьё, высокоточное оборудование, и др. Европа может рассчитывать на выпуск решений в пределах 7-нм, более современные техпроцессы пока слишком дороги. Впрочем, ЕС уже добился значительного прогресса в достижении полупроводникового суверенитета с помощью RISC-V.
03.03.2024 [21:59], Сергей Карасёв
Киловаттный ускоритель NVIDIA B200 Blackwell появится в 2025 годуКомпания Dell во время конференции, посвящённой квартальному отчёту, подтвердила подготовку ускорителя нового поколения NVIDIA B200 семейства Blackwell для ресурсоёмких ИИ-задач и НРС-приложений, на что обратил внимание ресурс Videocardz. Ожидается, что это изделие появится в следующем году. Официальный анонс решений Blackwell состоится в этому году. Причём в NVIDIA прогнозируют, что ускорители окажутся в дефиците сразу после выхода. Объясняется это стремительным ростом рынка ИИ, в том числе быстрым развитием генеративных сервисов. Известно, что в семейство Blackwell войдут флагманское изделие B100 для ИИ и HPC-задач, модель B40 для корпоративных заказчиков, гибридное решение GB200, сочетающее чип B100 и Arm-процессор Grace, а также GB200 NVL для обработки больших языковых моделей (LLM). Теперь говорится, что также готовится ускоритель B200: отмечается, что это может быть название конечного продукта. 
Источник изображения: NVIDIA По данным Dell, показатель TDP в случае B200 может достигать 1000 Вт. Для сравнения: ускоритель NVIDIA H100 в форм-факторе SXM обладает TDP в 700 Вт. На подготовку B200 намекнул операционный директор Dell Джефф Кларк (Jeff Clarke). По его словам, инженерная команда компании будет готова к появлению продукта. Таким образом, можно предположить, что Dell уже проектирует серверы нового поколения, рассчитанные на установку ускорителей B200. Отмечается также, что акции Dell по состоянию на 1 марта 2024 года выросли в цене на 32 %, тогда как капитализация NVIDIA превысила $2 трлн. При этом Dell является одним из ключевых партнёров NVIDIA в сегменте дата-центров.
28.02.2024 [15:54], Руслан Авдеев
Доступность ускорителей NVIDIA H100 повысилась, что привело к появлению вторичного рынкаСроки поставок ускорителей NVIDIA H100 значительно сократилось, с 8–11 мес. до всего 3-4. По данным Tom’s Hardware, в результате многие компании, ранее сделавшие огромные запасы, пытаются продать излишки. Кроме того, стало намного легче арендовать ускорители в облаках Amazon, Google и Microsoft. Впрочем, разработчики ИИ-моделей до сих пор испытывают проблемы с доступом к ресурсам ускорителей, поскольку спрос превышает предложение. Как сообщают СМИ, некоторые компании пытаются перепродать доставшиеся им H100, а другие стали заказывать меньше в связи с высокой стоимостью обслуживания складских запасов и окончанием паники на рынке. В прошлом году приобрести подобные ускорители было чрезвычайно сложно. Отчасти улучшение ситуации на рынке связано с тем, что провайдеры облачных сервисов вроде Amazon (AWS) и других крупных игроков упростили аренду H100. 
Источник изображения: NVIDIA Несмотря на то, что доступ к H100 упростился, желающим обучать LLM добраться до ресурсов по-прежнему непросто, во многом потому, что им требуются ускорители в невероятных количествах, в некоторых случаях речь идёт о сотнях тысяч экземпляров, поэтому цены на них до сих пор не упали, а NVIDIA продолжает получать сверхприбыли. При этом рост доступности привёл к тому, что компании всё чаще пытаются сэкономить, ведут себя более избирательно при выборе предложений продажи или аренды, стараются приобрести более мелкие кластеры и внимательнее оценивают их экономическую целесообразность для бизнеса. Кроме того, альтернативные решения становятся все более распространёнными и всё лучше поддерживаются ПО. Это ведёт к формированию сбалансированной ситуации на рынке. Так или иначе, спрос на ИИ-чипы по-прежнему высок, а с учётом того, что LLM становятся всё масштабнее, требуется больше вычислительных мощностей. Поэтому крупные игроки, которые зависят от поставок решений NVIDIA, занялись созданием собственных ускорителей. Среди них Microsoft, Meta✴ и OpenAI.
28.02.2024 [15:31], Сергей Карасёв
На MWC 2024 замечен первый образец ускорителя AMD Instinct MI300X с 12-слойной памятью HBM3EКомпания AMD готовит новые модификации ускорителей семейства Instinct MI300, которые ориентированы на обработку ресурсоёмких ИИ-приложений. Изделия будут оснащены высокопроизводительной памятью HBM3E. Работу над ними подтвердил технический директор AMD Марк Пейпермастер (Mark Papermaster), а уже на этой неделе на стенде компании на выставке MWC 2024 был замечен образец обновлённого ускорителя. На сегодняшний день в семейство Instinct MI300 входят модификации MI300A и MI300X. Первая располагает 228 вычислительными блоками CDNA3 и 24 ядрами Zen4 на архитектуре x86. В оснащение входят 128 Гбайт памяти HBM3. На более интенсивные вычисления ориентирован ускоритель MI300X, оборудованный 304 блоками CDNA3 и 192 Гбайт HBM3. Но у этого решения нет ядер Zen4.  Недавно компания Micron сообщила о начале массового производства 8-слойной памяти HBM3E ёмкостью 24 Гбайт с пропускной способностью более 1200 Гбайт/с. Эти чипы будут применяться в ИИ-ускорителях NVIDIA H200, которые выйдут на коммерческий рынок во II квартале нынешнего года. А Samsung готовится к поставкам 12-слойных чипов HBM3E на 36 Гбайт со скоростью передачи данных до 1280 Гбайт/с.  AMD подтвердила намерение применять память HBM3E в обновлённых ускорителях Instinct MI300, но в подробности вдаваться не стала. В случае использования 12-слойных чипов HBM3E ёмкостью 36 Гбайт связка из восьми модулей обеспечит до 288 Гбайт памяти с высокой пропускной способностью. Наклейка на демо-образце недвусмысленно указывает на использование именно 12-слойной памяти. Впрочем, это может быть действительно всего лишь стикер, поскольку представитель AMD уклонился от прямого ответа на вопрос о спецификациях представленного изделия.  Ожидается также, что в 2025 году AMD выпустит ИИ-ускорители следующего поколения серии Instinct MI400. Между тем NVIDIA готовит ускорители семейства Blackwell для ИИ-задач: эти изделия, по заявлениям самой компании, сразу после выхода на рынок окажутся в дефиците.
26.02.2024 [23:34], Владимир Мироненко
Groq LPU способен успешно конкурировать с ускорителями NVIDIA, AMD и IntelСтартап Groq сообщил о значительных достижениях в области инференса с использованием ускорителя LPU, разработанного для запуска больших языковых моделей (LLM), таких как GPT, Llama и Mistral. Groq LPU имеет один массивно-параллельный тензорный процессор TSP, который обеспечивает производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. LPU Groq оснащён локальной SRAM объемом 230 Мбайт с пропускной способностью 80 Тбайт/с. Как сообщает компания, при запуске модели Mixtral 8x7B ускоритель LPU обеспечил скорость инференса 480 токенов в секунду, что является одним из ведущих показателей инференса в отрасли. В таких моделях, как Llama 2 70B с длиной контекста 4096 токенов, Groq может обеспечить скорость инференса 300 токенов/с, тогда как в меньшей модели Llama 2 7B с 2048 токенами контекста скорость инференса составляет 750 токенов/с. 
Изображение: Groq Согласно рейтингу бенчмарка LLMPerf, LPU Groq превосходит результаты систем облачных провайдеров на базе традиционных ИИ-ускорителей в деле запуска LLM Llama в конфигурациях от 7 до 70 млрд параметров. Groq лидирует по скорости инференса и занимает второе место по показателю задержки. 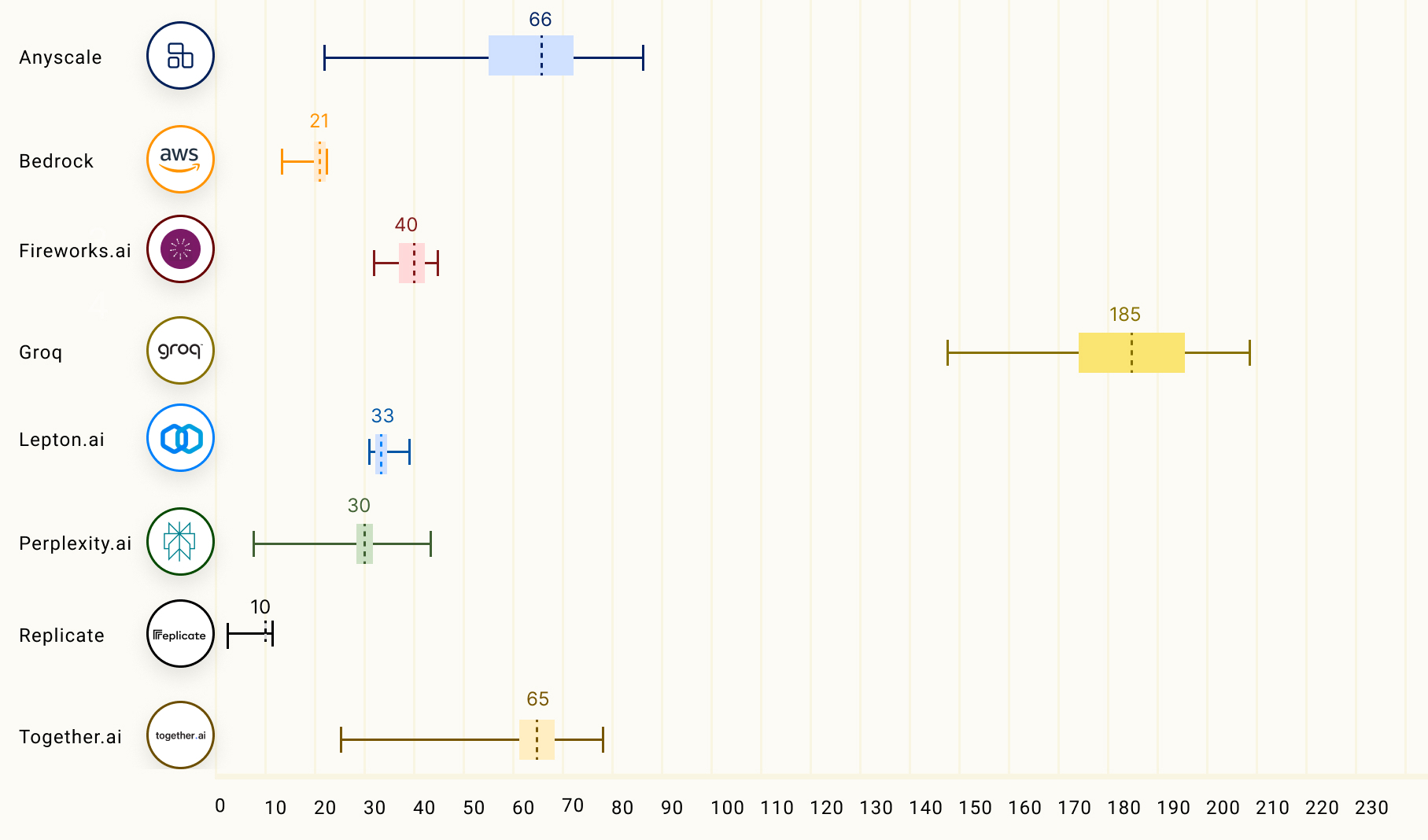
Источник: The Ray Team Для сравнения, бесплатный чат-бот ChatGPT на базе GPT-3.5 обеспечивает обработку около 40 токенов/с. Текущие LLM с открытым исходным кодом, такие как Mixtral 8x7B, могут превосходить GPT 3.5 в большинстве тестов, и теперь могут работать со скоростью почти 500 токенов/с. 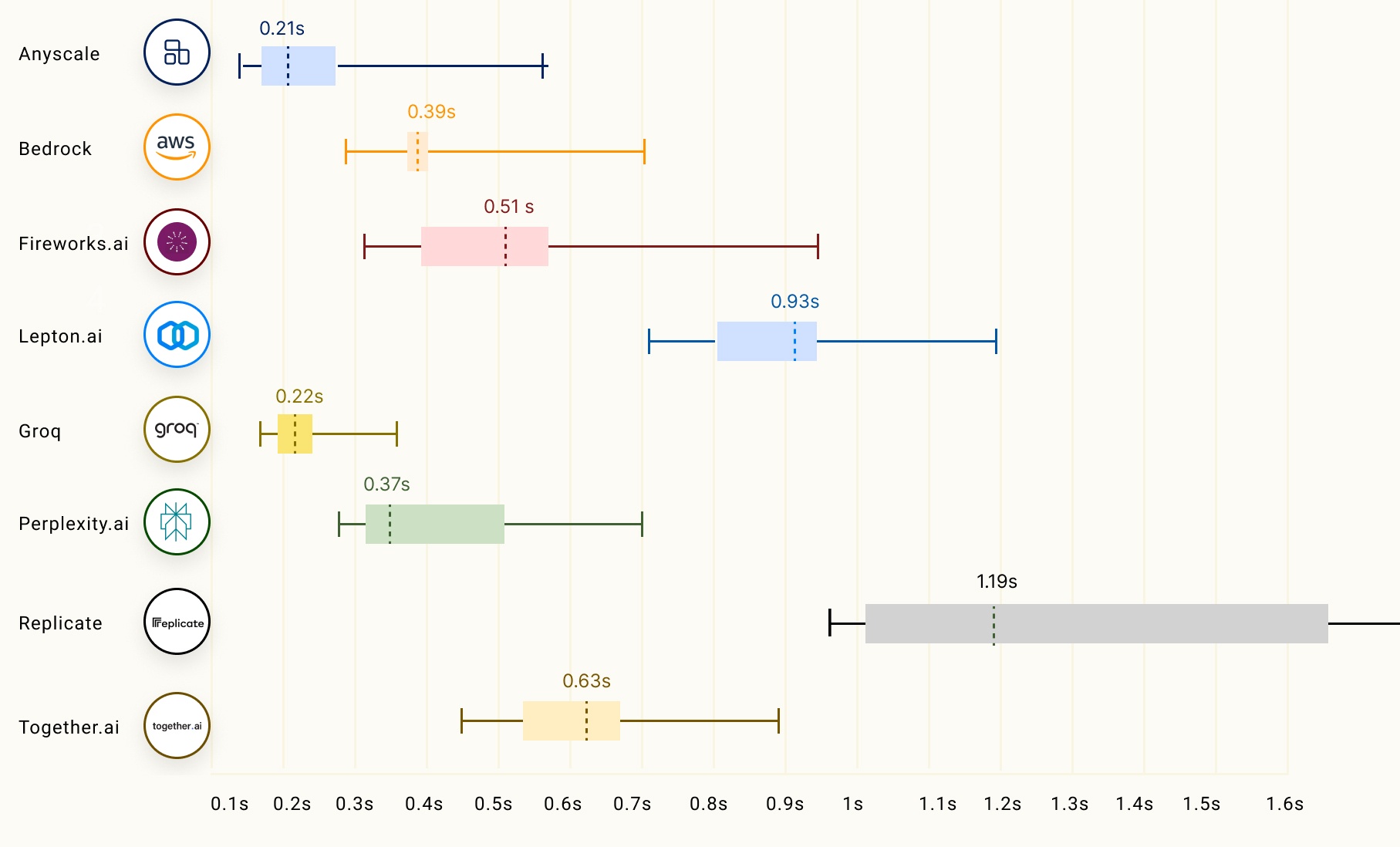
Источник: The Ray Team Опубликованные данные наглядно подтверждают, что предлагаемый Groq ускоритель LPU Groq значительно превосходит системы для инференса, предлагаемые NVIDIA, AMD и Intel, говорит компания. Groq не раскрывает имена своих заказчиков, но в настоящее время её ИИ-решения используются, например, Аргоннской национальной лабораторией Министерства энергетики США. |
|

