Материалы по тегу: ускоритель
|
08.04.2024 [01:50], Владимир Мироненко
Groq больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисыСтартап Groq, создавший ускоритель LPU на базе собственного массивно-параллельного тензорного процессора TSP, больше не продаёт оборудование, предлагая вместо этого воспользоваться его облачными ИИ-сервисами или стать партнёром в создании ЦОД. Об этом генеральный директор Groq Джонатан Росс (Jonathan Ross) сообщил ресурсу EE Times. Он пояснил, что для стартапа заниматься продажами чипов слишком сложно, потому что «минимальная сумма покупки, чтобы это имело смысл, высока, затраты высоки, и никто не хочет рисковать, покупая большое количество оборудования — неважно, насколько оно потрясающее». По его словам, в облаке GroqCloud для инференса больших языковых моделей (LLM) в реальном времени уже зарегистрировано 70 тыс. разработчиков и запущено более 19 тыс. новых приложений. 
Источник изображений: Groq В случае поступления заказов на поставку больших объёмов чипов для очень крупных систем Groq вместо продажи предлагает партнёрство по развёртыванию ЦОД. Groq подписала соглашение с саудовской государственной нефтяной компанией Aramco, которое предполагает масштабное развёртывание LPU. Похожее соглашение в ОАЭ подписала Cerebras, ещё один молодой разработчик ИИ-ускорителей. «Правительство США и его союзники — единственные, кому мы готовы продавать оборудование, — говорит Росс. — Для всех остальных мы лишь (совместно) создаём коммерческие облака». По его словам, в этом году Groq планирует разместить 42 тыс. LPU в GroqCloud, при этом Aramco и другие партнёры «завершают» свои сделки по получению такого же количества чипов. Компания способна выпустить 220 тыс. LPU только в этом году, а общий объём производства на ближайшее время составляет 1,5 млн ускорителей. Около 1 млн из них всё ещё не зарезверированы, но это количество быстро сокращается. Росс пообещал, что к концу 2025 году компания развернёт столько LPU, что их вычислительная мощность будет эквивалентна ИИ-мощностям всех гиперскейлерам вместе взятых.  Росс с оптимизмом смотрит на перспективы Groq, поскольку чипы TSP не используют память HBM, на которую полагаются решения конкурентов, включая NVIDIA, и поставки которой расписаны до конца 2024 года. Что касается LPU следующего поколения, то компания планирует сразу перейти с 14-нм техпроцесса (Global Foundries) на 4-нм. По словам Росса, новый чип будет оптимизирован для генеративного ИИ, но у него в силу универсальности архитектуры не будет каких-то специальных функций для обработки LLM. Будет ли новый ускоритель всё так же изготавливаться на территории США, не уточняется. Groq, похоже, достаточно уверена в своих чипах, которые в бенчмарках действительно обгоняют конкурентов. После анонса архитектуры NVIDIA Blackwell, обеспечивающей кратное увеличение производительности в задачах генеративного ИИ, компания выпустил в ответ пресс-релиз из одного предложения: «Groq всё ещё быстрее». А чуть позже даже раскритиковала NVIDIA.
07.04.2024 [14:12], Сергей Карасёв
Разработчик ИИ-чипов SiMa.ai получил на развитие ещё $70 млнСтартап SiMa.ai, разрабатывающий аппаратные и программные решения для обработки ИИ-задач на периферии, объявил о проведении раунда финансирования на сумму в $70 млн. Таким образом, в общей сложности компания привлекла на развитие $270 млн. Ключевым продуктом SiMa.ai является изделие Machine Learning System-on-Chip (MLSoC). Оно специально спроектировано с прицелом на периферийные ИИ-приложения. Это могут быть роботы, дроны, системы машинного зрения, автомобильные платформы, медицинское оборудование и пр. В состав MLSoC входит ряд блоков. Это, в частности, ИИ-ускоритель с 25 Мбайт интегрированной памяти, обеспечивающий производительность до 50 TOPS (INT8) или 10 TOPS/Вт. Он дополнен процессором приложений на базе четырёх вычислительных ядер Arm Cortex-A65 с частотой 1,15 ГГц. Присутствует четырёхъядерный узел компьютерного зрения Synopsys ARC EV74. Изделие также несёт на борту блоки (де-)кодирования видео в формате H.264. Реализована поддержка четырёх портов 1GbE, интерфейсов PCIe 4.0 х8, SPIO, I2C и GPIO. 
Источник изображения: SiMa.ai Чип MLSoC доступен в составе платы для разработчиков. Компания также предоставляет специализированный набор инструментов под названием Pallet, упрощающий создание ПО для чипа. Этот комплект включает, в частности, компилятор, который преобразует модели ИИ в формат, оптимизированный для работы в системах на основе MLSoC. Сообщается, что раунд финансирования на $70 млн проведён под руководством Maverick Capital. В нём также приняли участие Point72, Jericho, Amplify Partners, Dell Technologies Capital, предприниматель Лип-Бу Тан (Lip-Bu Tan) и др. Полученные средства пойдут на разработку 6-нм чипа MLSoC второго поколения, который будет выпущен на TSMC в I квартале 2025 года. Известно, что это решение объединит CPU на базе Arm Cortex-A и модуль компьютерного зрения Synopsys EV74.
06.04.2024 [21:08], Сергей Карасёв
M.2-модуль Hailo-10 обеспечивает ИИ-производительность до 40 TOPSКомпания Hailo анонсировала специализированный модуль Hailo-10, предназначенный для обслуживания генеративного ИИ. Этот ускоритель с высокой энергетической эффективностью может быть установлен, например, в рабочую станцию или edge-систему. Изделие выполнено в форм-факторе M.2 Key M 2242/2280 с интерфейсом PCIe 3.0 х4. В оснащение входят чип Hailo-10H и 8 Гбайт памяти LPDDR4. Говорится о совместимости с компьютерами, оснащёнными CPU на архитектурах x86 и Aarch64 (Arm64). Заявлена поддержка Windows 11, а также ИИ-фреймворков TensorFlow, TensorFlow Lite, Keras, PyTorch и ONNX. 
Источник изображения: Hailo Как отмечает Hailo, новинка обеспечивает ИИ-производительность до 40 TOPS. Типовое энергопотребление составляет менее 3,5 Вт. Утверждается, что ИИ-модуль поддерживает нагрузки, связанные с инференсом, в режиме реального времени. Например, при работе с большой языковой моделью Llama2-7B достигается скорость до 10 токенов в секунду (TPS). При использовании Stable Diffusion 2.1 возможна генерация одного изображения на основе текста менее чем за 5 с. Применение Hailo-10 позволяет перенести определённые ИИ-нагрузки из облака или дата-центра на периферию. Это снижает задержки и даёт возможность решать задачи в офлайновом режиме. Изначально новинка будет позиционироваться для применения в сферах ПК и автомобильных информационно-развлекательных комплексов для обеспечения работы чат-ботов, средств автопилотирования, персональных помощников и систем с голосовым управлением. Поставки образцов Hailo-10 будут организованы во II квартале 2024 года. В ассортименте компании также присутствует ускоритель Hailo-8 в формате M.2: он обеспечивает производительность до 26 TOPS и при этом имеет энергоэффективность 3 TOPS/Вт.
03.04.2024 [12:57], Руслан Авдеев
Выходцы из Google основали стартап MatX для разработки чипов для тренировки ИИ-моделейБывшие сотрудники Google объединились для создания стартапа, который займётся разработкой современных ИИ-чипов. По данным Bloomberg, новые продукты будут предназначены для тренировки больших языковых моделей (LLM), и компания уже привлекла $25 млн на реализацию собственных инициатив. В интервью Bloomberg основатели компании Майк Гюнтер (Mike Gunter) и Райнер Поуп (Reiner Pope) заявили, что Google удалось ускорить работу своих LLM, но её цели оказались слишком «размытыми», из-за чего коллеги решили заняться собственными разработками — чипами для обучения языковых моделей. 
Источник изображения: MatX В Google Поуп занимался ПО, а Гюнтер — разработкой аппаратной составляющей, включая чипы для работы с создаваемым в компании ПО. В интервью предприниматели сообщили, что в Google разрабатывали тензорные ИИ-ускорители TPU задолго до появления современных ИИ-моделей, но оптимизировать их под актуальные задачи было довольно трудно, в том числе потому, что многие в Google требовали оптимизации ускорителей под собственные потребности. Теперь пара бизнесменов-энтузиастов рассчитывает, что MatX удастся создать процессоры как минимум в 10 раз лучше в обучении и эксплуатации LLM, чем ускорители NVIDIA. Добиться этого планируется удалением из чипов т.н. «дополнительной недвижимости» — функциональности, позволяющей выполнять ненужные для ИИ-систем вычислительные задачи. Утверждается, что NVIDIA просто повезло — GPU оказались намного лучше для решения ИИ-задач, чем обычные процессоры, поэтому сейчас компания зарабатывает на случайно пришедшейся к месту технологии, предназначавшейся совсем для другого. В MatX же займутся разработкой специализированных чипов с одним большим вычислительным ядром. Сообщается, что стартап уже нанял десятки сотрудников и рассчитывает подготовить окончательную версию своего продукта к 2025 году. По словам Поупа, чипы NVIDIA — по-настоящему сильные продукты и подходят большинству компаний. Но разработчики считают, что могут сделать чипы намного лучше. В MatX прогнозируют, что при сохранении вектора развития программного обеспечения, связанного с ИИ, понадобятся огромные вычислительные мощности. Если для тренировки современных моделей сегодня требуется в среднем $1 млрд, то для LLM будущего эта сумма вырастет до $10 млрд. Представители стартапа утверждают, что смогут добиться большего успеха, чем компании вроде OpenAI или Anthropic PBC. Те тратят все деньги на вычисления, фактически не заботясь о прибыли, так что в итоге, если ничего не изменится, деньги у них просто закончатся. Проблема в том, что на разработку нового чипа уходит от трёх до пяти лет, а гиганты вроде NVIDIA не будут стоять на месте, создавая собственные продукты. Стартапам придётся чрезвычайно точно оценивать современные тренды и предсказывать в каком направлении будет развиваться отрасль — причём права на ошибку, в отличие от крупных игроков, у них нет. Разработчиков ПО предстоит убедить в том, что переделка программ под новые полупроводники будет чрезвычайно выгодной — новый чип должен быть как минимум в 10 раз потенциально лучше прежних, чтобы им заинтересовались возможные клиенты.
30.03.2024 [15:06], Сергей Карасёв
AMD готовит ускоритель Instinct MI388XКомпания AMD, по сообщению ресурса VideoCardz, направила в Комиссию по ценным бумагам и биржам США (SEC) документацию, в которой говорится о подготовке нового продукта семейства Instinct — изделия с обозначением MI388X. Судя по имеющейся информации, это производительное решение, не предназначенное для поставок на китайский рынок. Технические характеристики новинки не раскрываются. Известно лишь, что в основу Instinct MI388X положена архитектура CDNA3. Предусмотрено использование 5-нм и 6-нм техпроцессов TSMC. 
Источник изображения: AMD Судя по наличию индекса «Х» в обозначении, новое изделие представляет собой самостоятельный ИИ-ускоритель (как и Instinct MI300X), а не гибридное решение, как в случае MI300A, которое наделено x86-ядрами Zen4. Высказываются предположения, что новинка могла проектироваться под нужды какого-либо конкретного заказчика или для определённого рыночного сегмента. Более того, есть вероятность, что изначально ускоритель Instinct MI388X создавался именно для КНР, но AMD не получила экспортное разрешение на его поставки на китайский рынок. Нужно отметить, что ранее AMD была вынуждена отказаться от поставок в Китай ускорителей Instinct MI309: они оказались слишком мощными, а поэтому попали под американские санкции. Решения MI300X и MI300A также запрещены для отгрузок китайским заказчикам. Между тем в феврале был продемонстрирован вариант Instinct MI300X, оснащённый 12-слойной памятью HBM3E. Суммарный объём такой памяти у модифицированного ускорителя может достигать 288 Гбайт против 192 Гбайт у стандартной версии MI300X.
25.03.2024 [21:23], Владимир Мироненко
Samsung поставит Naver ИИ-ускорители Mach-1 на $752 млнКомпания Samsung Electronics поставит в этом году ведущей южнокорейской интернет-компании Naver Corp. ИИ-ускорители Mach-1 следующего поколения собственной разработки. Сумма контракта составит до ₩1 трлн (около $752 млн), сообщил ресурс KED Global со ссылкой на отраслевые источники. Это позволит Naver значительно сократить зависимость от поставок ускорителей NVIDIA. В октябре прошлого года Naver вынужденно стала использовать процессоры Intel Xeon вместо ускорителей NVIDIA. Смена оборудования Naver происходит на фоне роста недовольства технологических компаний увеличением цен на ускорители NVIDIA и их глобальной нехваткой. По словам Samsung, Mach-1 был разработан для поддержки Transformer-моделей и позволяет выполнять инференс больших языковых моделей (LLM) даже с маломощной памятью вместо энергоёмкой HBM, что делает его в восемь раз энергоэффективнее традиционных ускорителей на базе GPU. При этом Mach 1 на порядок дешевле чипов NVIDIA. По словам источников, бизнес-подразделение Samsung System LSI и Naver находятся в заключительной стадии переговоров о поставке 150–200 тыс. ИИ-ускорителей Mach-1, цена которых может составить ₩5 млн ($3756) за штуку. Цены и точный объём поставок пока не согласованы. Сообщается, что Naver будет использовать Mach-1 для инференса вместо ускорителей NVIDIA в картографическом сервисе AI Naver Place. Naver готова покупать эти чипы и в дальнейшем, если первая партия покажет «хорошую производительность», отметили источники, по словам которых Samsung также ведёт переговоры о поставках Mach-1 с Microsoft и Meta✴. 
Источник изображения: Samsung Для Samsung сделка с Naver важна с точки зрения конкуренции с SK hynix, доминирующей в сегменте памяти HBM, спрос на которую в связи с популярностью генеративного ИИ резко вырос. Samsung сообщила о разработке первой в отрасли памяти HBM3E 12-Hi, массовое производство которой начнётся в I половине этого года. Кроме того, SK Group поддерживает разработку ИИ-ускорителей Sapeon, а Samsung сотрудничает с Rebellions. По оценкам Omdia, глобальный рынок ИИ-ускорителей вырастет с $6 млрд в 2023 году до $143 млрд к 2030 году.
21.03.2024 [22:16], Сергей Карасёв
HP оснастит рабочие станции ускорителями NVIDIA A800, предназначавшимися для КитаяКомпания HP, по сообщению ресурса Tom's Hardware, готовит к выпуску новые рабочие станции серии Z, рассчитанные на приложения ИИ. В оснащение этих компьютеров войдут ускорители NVIDIA A800, которые изначально создавались для Китая в качестве «урезанной» версии А100 (40 Гбайт). Предполагалось, что операторы дата-центров в КНР смогут закупать решения A800, которые проектировались специально с учётом санкционных ограничений со стороны США. Стоимость этих ускорителей, по имеющимся данным, на начальном этапе составляла $14,5 тыс. Однако в связи с введением новых экспортных ограничений США на поставку в Китай современных технологий отгрузки A800 в Поднебесную стали невозможны. Вместо них NVIDIA подготовила ускорители H20, L20 и L2. А выпущенные A800 пришлось перераспределять в другие регионы. Однако из-за того, что у A800 пропускная способность интерконнекта NVLink в угоду санкциям снижена до 400 Гбайт/с против 600 Гбайт/с у А100, «урезанные» ускорители оказались не слишком популярны среди заказчиков. В такой ситуации установка A800 в рабочие станции НР поможет NVIDIA реализовать имеющиеся запасы продукции. 
Источник изображения: NVIDIA Характеристики систем НР серии Z пока не раскрываются. Высказываются предположения, что в их основу лягут либо процессоры Intel Xeon Emerald Rapids (или, возможно, Xeon Sapphire Rapids), либо чипы AMD Ryzen Threadripper Pro 7000 WX. Сама NVIDIA ещё в ноябре 2023 года фактически анонсировала A800 для западных рынков, заявив, что это «идеальная платформа для рабочих станций для ИИ, анализа данных и высокопроизводительных вычислений». В числе партнёров NVIDIA, которые занимаются продвижением A800, значатся PNY, Colfax International, ASK и Elsa.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 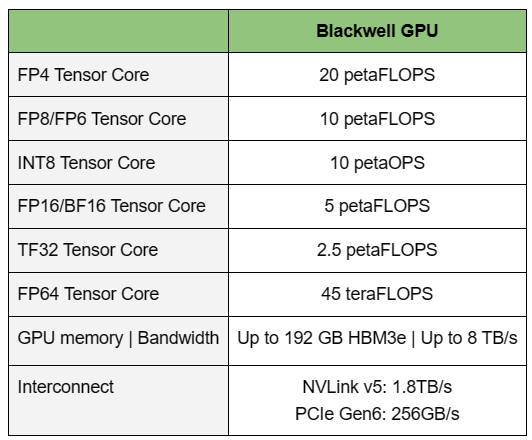 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 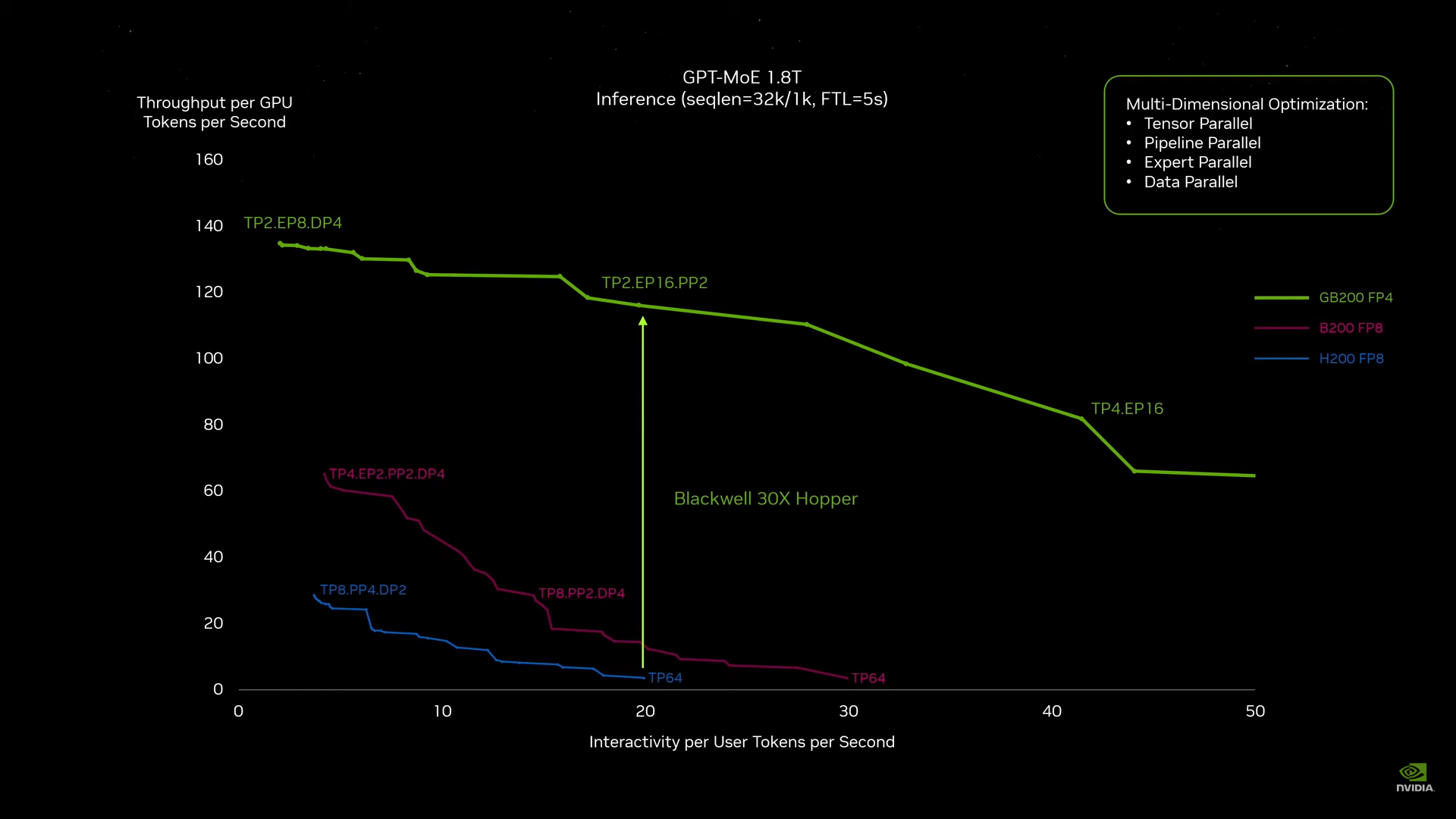 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 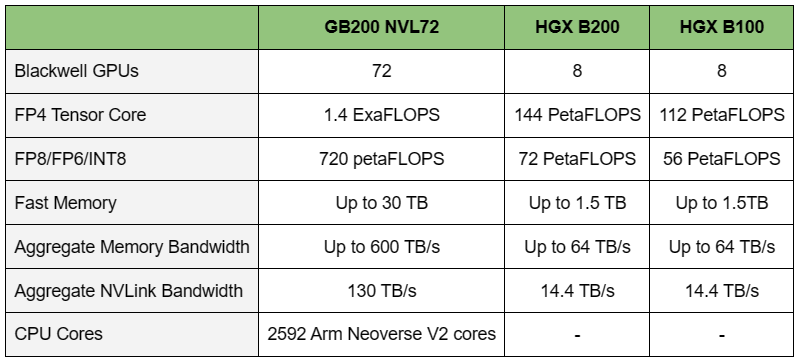 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
15.03.2024 [22:43], Алексей Степин
Tenstorrent под руководством Джима Келлера представила свои первые ИИ-ускорители Grayskull на базе RISC-VКанадский разработчик микрочипов Tenstorrent, возглавляемый легендарным Джимом Келлером (Jim Keller), наконец, представил свои первые решения на базе архитектуры RISC-V — ИИ-процессоры Grayskull и ускорители на их основе, Grayskull e75 и e150. Оба варианта доступны для приобретения уже сейчас по цене $599 за младшую версию и $799 за старшую. Данные решения предназначены для инференс-систем, разработки и отладки ПО. В комплект разработчика входят инструменты TT-Buda и TT-Metalium. В первом случае речь идёт о высокоуровневом стеке, предназначенном для компиляции и запуска ИИ-моделей на аппаратном обеспечении Tenstorrent, а во втором — о низкоуровневой программной платформе, обеспечивающей прямой доступ к аппаратным ресурсам. Поддерживается PyTorch, ONNX и другие фреймворки. Создатели делают особенный упор на простоте программирования в сравнении с классическими GPU. Поддерживается широкий спектр ИИ-моделей, но Tenstorrent особенно выделяет BERT, ResNet, Whisper, YOLOv5 и U-Net. 
Источник изображений здесь и далее: Tenstorrent Архитектура Grayskull базируется на RISC-V, в настоящий момент максимальное количество фирменных ядер Tensix достигает 120, работают они на частотах вплоть до 1,2 ГГц. Каждое такое ядро содержит пять полноценных ядер RISC-V, блок тензорных операций, блок SIMD для векторных операций, а также ускорители сетевых операций и сжатия/декомпрессии данных. Дополнительно каждое ядро может иметь до 1,5 Мбайт сверхбыстрой памяти SRAM. Между собой ядра общаются напрямую.  В случае Grayskull e150 процессор работает в полной конфигурации со 120 ядрами и 120 Мбайт SRAM, объём внешней памяти LPDDR4 составляет 8 Гбайт (ПСП 118,4 Гбайт/с). Ускоритель выполнен в формате полноразмерной платы расширения с теплопакетом 200 Вт и интерфейсом PCIe 4.0 x16. У младшей модели, Grayskull e75, активных ядер только 96, их частота снижена до 1 ГГц, а пропускная способность внешней памяти при том же объёме снижена до 102,4 Гбайт/с. При этом теплопакет составляет всего 75 Вт, что позволило выполнить ускоритель в виде низкопрофильной платы расширения и обойтись без дополнительного питания.  Чипы Wormhole тоже используют Tensix. В составе Wormhole n300 таких ядер 128, частота равна 1 ГГц при теплопакете 300 Вт. Объём SRAM составляет 1,5 Мбайт на ядро, а внешняя подсистема памяти включает 12 Гбайт GDDR6 и с ПСП 288 Гбайт/с. Wormhole n150 имеют такую же конфигурацию памяти, но оснащены только 72 ядрами Tensix и 108 Мбайт SRAM. TDP составляет 160 Вт. От Grayskull эти решения отличаются возможностью масштабирования путём прямого объединения плат. Также есть по паре сетевых интерфейсов 200GbE. Возможна работа с форматами FP8/16/32, TF32, BFP2/4/8, INT8/16/32 и UINT8. Чипы Tenstorrent Grayskull и Wormhole лежат в основе уникальных масштабируемых платформ собственной разработки — AICloud и Galaxy. В первом случае используются процессоры Grayskull, поскольку Wormhole на рынке должен появиться позже. Платформа предназначена в качестве аппаратной для ИИ и HPC-нагрузок в облаке Tenstorrent. 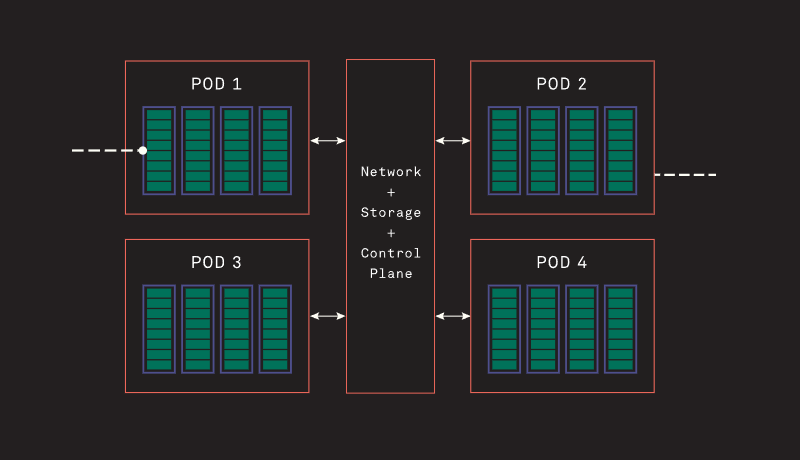 Каждый 4U-узел AICloud высотой содержит восемь карт (16 чипов) и способен предоставить в распоряжение пользователей от 30 до 60 vCPU и от 256 до 1024 Гбайт памяти, вкупе с дисковым пространством объёмом 100–400 Гбайт. Восемь таких узлов составляют стойку, а четыре стойки — кластер Server Pod. Четыре таких кластера объединены общей системой интерконнекта, управления и СХД (до 200 Тбайт), дальнейшее масштабирование уже выходит на уровень ЦОД. 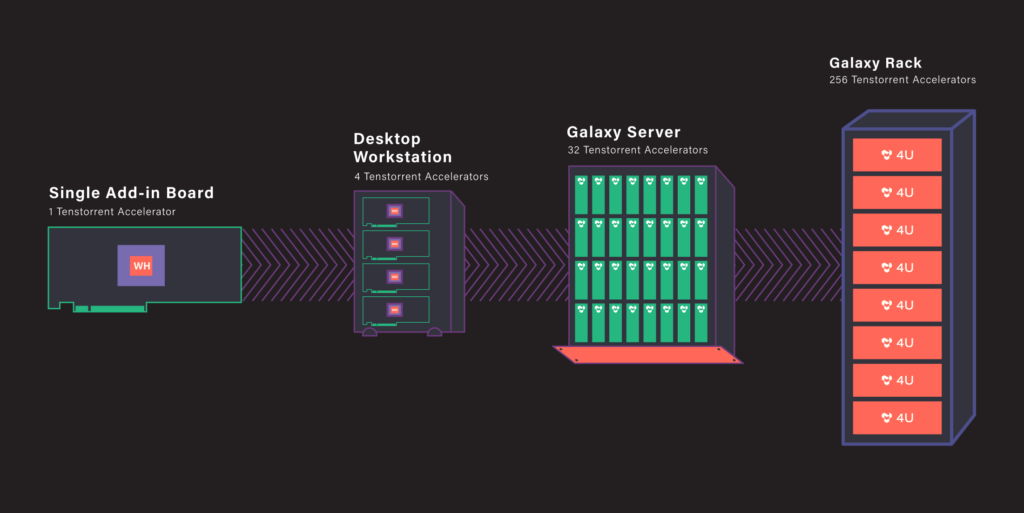 В Tenstorrent Galaxy упор сделан на возможность создания высокопроизводительных ИИ-систем с быстрым интерконнектом на базе Ethernet. Строительным блоком здесь являются 80-ядерные модули Wormhole. 4U-сервер вмещает 32 таких модуля, что в совокупности даёт 2560 ядер Tensix и 384 Гбайт глобально адресуемой GDDR6. Наличие 16 каналов 200GbE в каждом модуле обеспечивает производительность интерконнекта на уровне 3,2 Тбитс. На уровне стойки высотой 48U это дает 256 чипов Wormhole, общий объём SRAM в этом случае достигает 30,7 Гбайт, а GDDR6 — 3 Тбайт. Производительность стойки оценивается разработчиками в 20 Попс (Петаопс), а совокупная скорость интерконнекта — в 76,8 Тбит/с. Расплатой за универсальность и производительность станет энергопотребление, достигающее 60 КВт.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 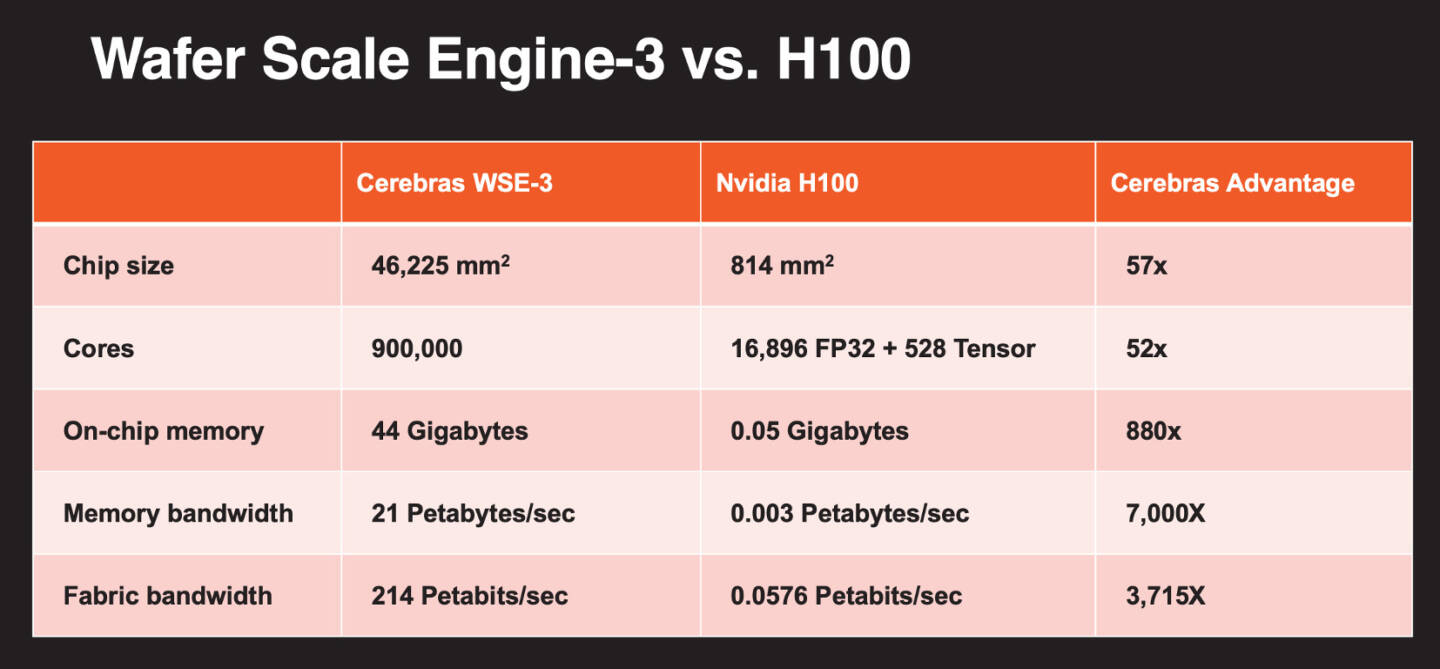 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 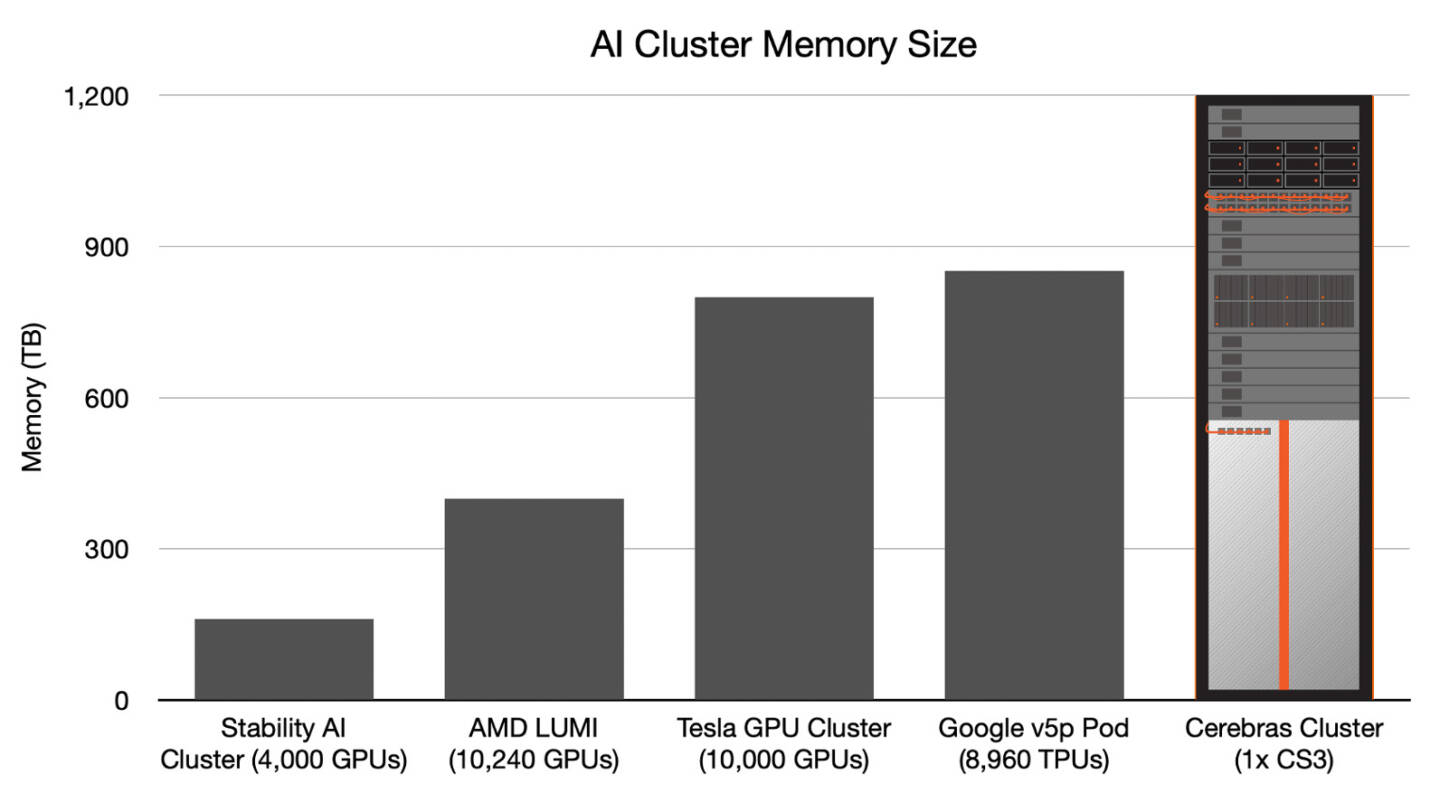 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 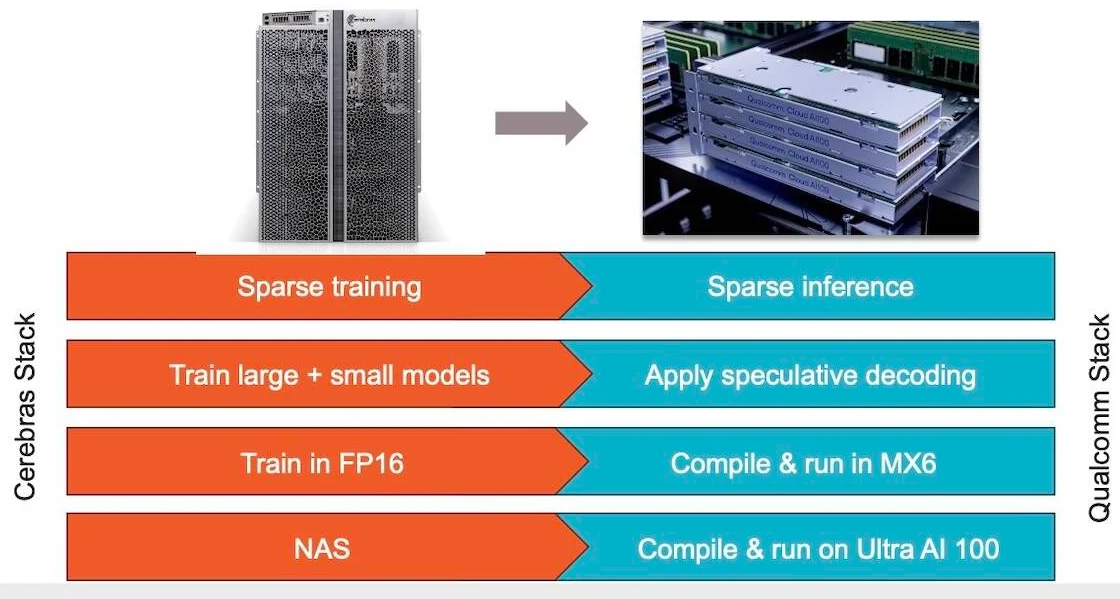 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений. |
|

