Материалы по тегу: hpc
|
27.03.2024 [22:34], Сергей Карасёв
Lenovo создаст для Великобритании ИИ-суперкомпьютер производительностью 44,7 ПфлопсСовет по науке и технологиям Великобритании (STFC), по сообщению The Register, заключил с Lenovo соглашение о создании нового НРС-комплекса, ориентированного на решение задач в области ИИ. Речь идёт о суперкомпьютере с жидкостным охлаждением, производительность которого составит приблизительно 44,7 Пфлопс (точность вычислений не уточняется). Система будет смонтирована в принадлежащем STFC Вычислительном центре имени Хартри в Дарсбери (графство Чешир). Ожидается, что по быстродействию новый комплекс примерно в 10 раз превзойдёт нынешнюю НРС-систему центра под названием Scafell Pike. 
Источник изображения: Lenovo В основу суперкомпьютера лягут серверы Lenovo ThinkSystem с технологией прямого водяного охлаждения (DWC) Neptune. Применение СЖО, как ожидается, поможет снизить потребление энергии примерно на 40 % по сравнению с воздушным охлаждением и дополнительно повысить производительность на 10 %. Технические характеристики будущего суперкомпьютера не раскрываются, но известно, что он будет использовать узлы с ускорителями на базе GPU. Технология Neptune, в частности, применяется в серверах ThinkSystem SD650-N V3, которые комплектуются процессорами Intel Xeon Emerald Rapids и ускорителями NVIDIA HGX H100 (SXM). Ожидается, что новый суперкомпьютер, который пока не получил имя, будет применяться для решения сложных задач, связанных с ИИ. Это моделирование погоды и глобальных изменений климата, инициативы в области чистой энергетики, разработка передовых лекарственных препаратов, новые материалы, автомобильные технологии и пр. Система Lenovo станет частью программы Национального центра цифровых инноваций Хартри (HNCDI) стоимостью около $265 млн, которая предполагает поддержку предприятий и организаций государственного сектора, внедряющих средства ИИ.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 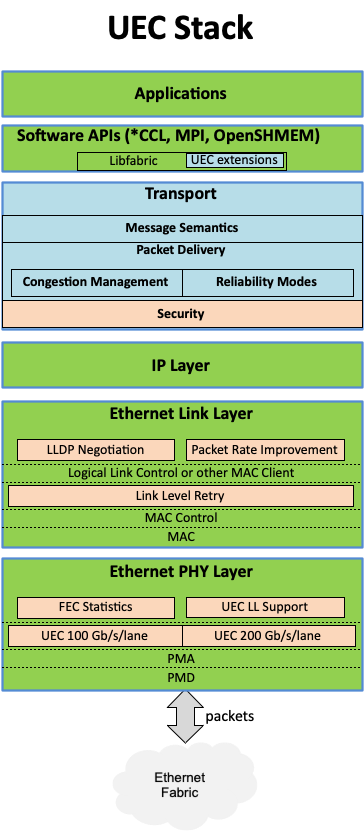
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 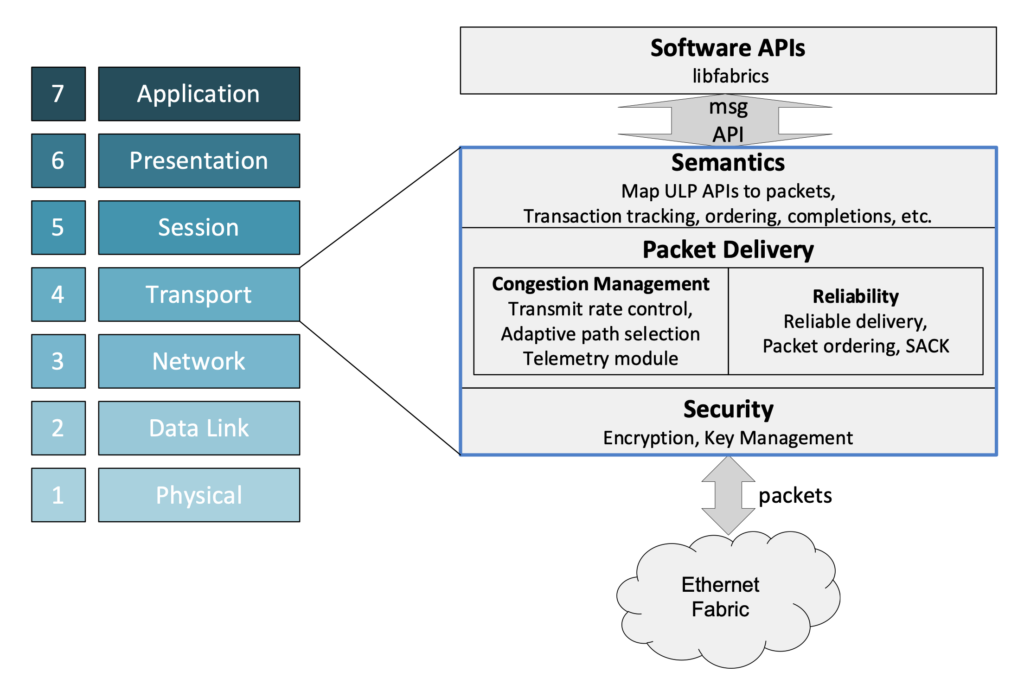
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы.
21.03.2024 [22:21], Сергей Карасёв
Eviden создаст для Дании ИИ-суперкомпьютер Gefion на базе NVIDIA DGX SuperPOD H100Компания Eviden, дочерняя структура Atos, объявила о заключении соглашения с Датским центром инноваций в области искусственного интеллекта (Danish Centre for AI Innovation) на создание передового суперкомпьютера для решения ИИ-задач. Вычислительный комплекс под названием Gefion, как ожидается, заработает до конца текущего года. Как сообщается, в основу Gefion ляжет платформа NVIDIA DGX SuperPOD. Конфигурация включает 191 систему NVIDIA DGX H100, а общее количество ускорителей NVIDIA H100 составит 1528 штук. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand. В состав суперкомпьютера также войдут 382 процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids. Эти чипы насчитывают 56 ядер (112 потоков), работающих на частоте 2,0/3,8 ГГц. Для подсистемы хранения выбрано решение DataDirect Networks (DDN). Ожидаемая ИИ-производительность Gefion на операциях FP8 составит около 6 Эфлопс. В рамках проекта Eviden отвечает за доставку компонентов комплекса, монтаж и пуско-наладочные работы. Система разместится в дата-центре Digital Realty. Её питание будет на 100 % обеспечиваться за счёт энергии из возобновляемых источников. 
Источник изображения: NVIDIA Датский центр инноваций в области ИИ принадлежит фонду Novo Nordisk Foundation и Экспортно-инвестиционному фонду Дании. При этом Novo Nordisk Foundation, основанный в Дании ещё в 1924 году, представляет собой корпоративный фонд с филантропическими целями. Его видение заключается в улучшении здоровья людей, повышении устойчивости общества и планеты. Отмечается, что Novo Nordisk Foundation обеспечит финансирование центра в размере примерно 600 млн датских крон (около $87,5 млн), а Экспортно-инвестиционный фонд — 100 млн датских крон ($14,6 млн).
20.03.2024 [15:25], Руслан Авдеев
BNY Mellon стал первым транснациональным банком, внедрившим ИИ-суперкомпьютер NVIDIA на базе DGX SuperPOD H100Банк Bank of New York Mellon Corporation (BNY Mellon) стал первой структурой подобного профиля и масштаба, приступившей к внедрению собственного ИИ-суперкомпьютера на основе систем NVIDIA. Банку получил кластер DGX SuperPOD из нескольких десятков систем DGX H100, объединённых интерконнектом NVIDIA InfiniBand. Основанный в 2007 году в результате слияния The Bank of New York и Mellon Financial Corporation банк намерен использовать новый суперкомпьютер вкупе с NVIDIA AI Enterprise для создания и внедрения ИИ-приложений и управления ИИ-инфраструктурой своего бизнеса. Банк уже использует более 20 ИИ-решений, в том числе для прогнозирования в сфере депозитов, автоматизации платежей, предиктивной торговой аналитики и т.д. Всего же компания нашла более 600 вариантов использования ИИ в своей банковской системе. Как заявляют в руководстве BNY Mellon, внедрение ИИ-суперкомпьютера увеличит возможности по обработке данных и запуску ИИ-проектов, помогающих управлять активами клиентов и обеспечивать их защиту. 
Источник изображения: NVIDIA Компания пока не сообщила, где будет расположен суперкомпьютер и его полные характеристики. Ранее банку принадлежал дата-центр в Нью-Джерси, также он управлял IT-объектами в Пенсильвании и Теннесси.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее.
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
19.03.2024 [15:06], Сергей Карасёв
Юлихский суперкомпьютерный центр получил 5-кубитную квантовую систему IQMВ июле нынешнего года Юлихский суперкомпьютерный центр в Германии (JSC) намерен ввести в эксплуатацию новый квантовый компьютер — 5-кубитную систему Spark немецко-финского производителя IQM Quantum Computers. Новая система станет частью Унифицированной инфраструктуры квантовых вычислений Юлиха (Jülich UNified Infrastructure for Quantum Computing, JUNIQ). Spark будет работать в тандеме с классическими суперкомпьютерами, что позволит исследователям изучать различные варианты использования гибридных вычислений. Базовая версия IQM Spark стоит менее €1 млн. Система разработана специально для проведения экспериментов, а также для применения в образовательных целях. В этом компьютере кубиты (квантовые биты) генерируются с помощью сверхпроводящих электронных резонансных цепей. Для этого их необходимо охлаждать до температур, близких к абсолютному нулю (-273,15 °C). Платформа IQM Spark отличается гибкими возможностями в плане расширения и подключения, что делает её идеально подходящей для использования в составе инфраструктуры JUNIQ. 
Источник изображения: IQM Отмечается, что квантовые компьютеры способны решать определённые задачи гораздо быстрее, чем это возможно с помощью классических НРС-комплексов. Это может быть, например, моделирование сложных химических реакций и молекул, оптимизация процессов в финансовом секторе и пр. Однако квантовые компьютеры всё ещё находятся на ранней стадии развития. Проект JUNIQ поможет найти новые практические применения концепции гибридных квантово-классических вычислений. IQM развернула локальные квантовые системы в некоторых других университетах и исследовательских институтах, включая Суперкомпьютерный центр Лейбница в Германии (LRZ) и Центр технических исследований VTT в Финляндии.
19.03.2024 [01:02], Сергей Карасёв
Ускорители NVIDIA H100 лягут в основу японского суперкомпьютера ABCI-Q для квантовых вычисленийКомпания NVIDIA сообщила о том, что её технологии лягут в основу нового японского суперкомпьютера ABCI-Q, предназначенного для проведения исследований в области квантовых вычислений. Платформа, в частности, будет использоваться для тестирования гибридных систем, объединяющих классические и квантовые технологии. Развёртыванием комплекса займётся корпорация Fujitsu. Машина расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). Ввод ABCI-Q в эксплуатацию намечен на начало 2025 года. В состав суперкомпьютера войдут более 500 узлов, насчитывающих в общей сложности свыше 2000 ускорителей NVIDIA H100. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также NVIDIA CUDA Quantum — открытой платформы для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Комплекс ABCI-Q проектируется с прицелом на возможность добавления будущих аппаратных компонентов для квантовых вычислений. 
Источник изображения: NVIDIA Ожидается, что ABCI-Q позволит проводить высокоточное квантовое моделирование в рамках исследовательских проектов в различных отраслях. Учёные смогут тестировать приложения нового типа с целью ускорения их практического внедрения. Кроме того, специалисты смогут прорабатывать передовые алгоритмы для решения специфичных задач. NVIDIA и AIST также планируют сотрудничать при разработке промышленных приложений на базе ABCI-Q. В целом, ABCI-Q является частью стратегии Японии в области квантовых технологий, задачей которой является создание новых возможностей для бизнеса и общества, а также получение выгоды от квантовых технологий, в том числе посредством исследований в области ИИ, энергетики и биологии.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 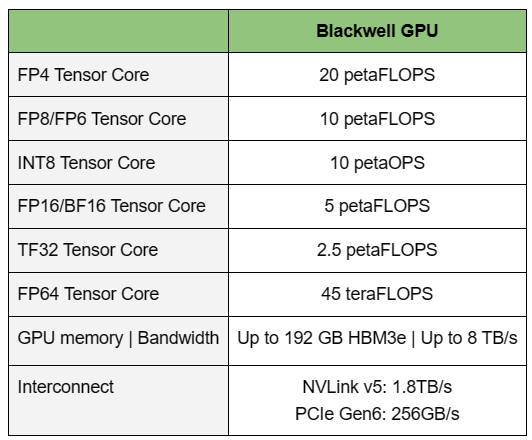 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 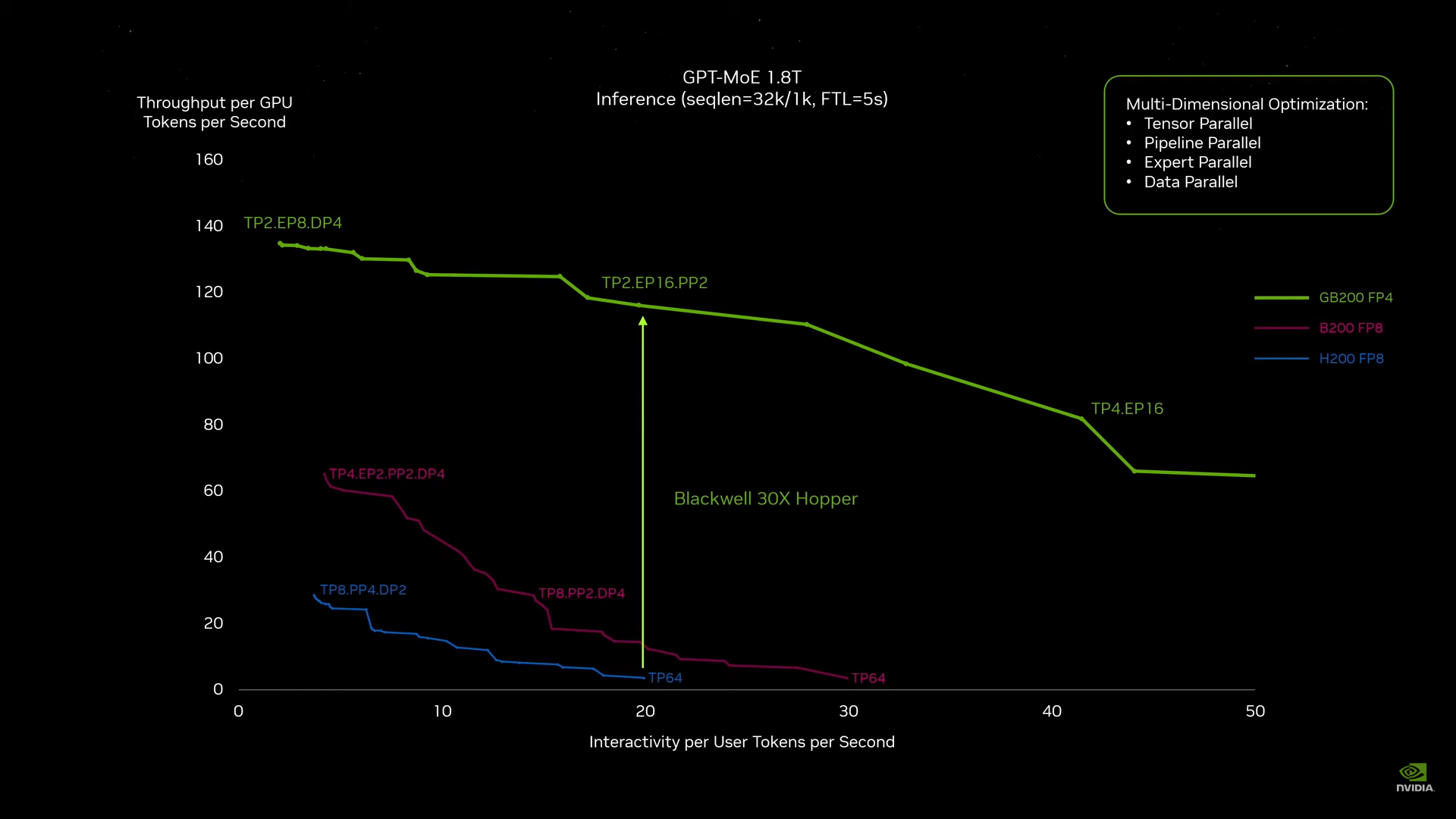 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 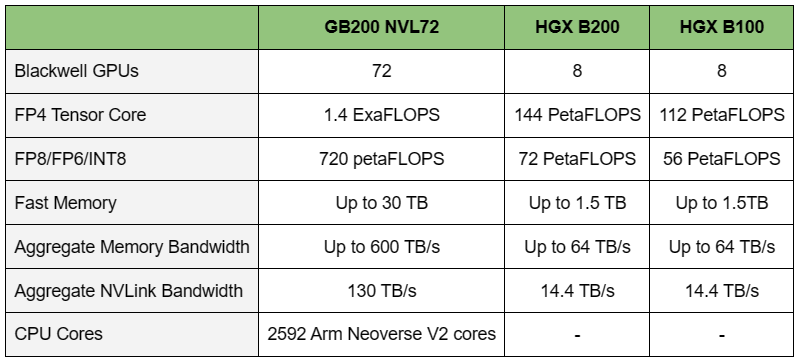 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
16.03.2024 [21:46], Сергей Карасёв
Великобритания рассчитывает снизить стоимость ИИ-инфраструктур в 1000 разАгентство перспективных исследований и инноваций Великобритании (ARIA), по сообщению Datacenter Dynamics, инициировало проект стоимостью приблизительно $53,5 млн, целью которого является «переосмысление парадигмы вычислений». Учёные рассчитывают разработать новые технологии и архитектуры, которые позволят снизить стоимость ИИ-инфраструктур в 1000 раз по сравнению с сегодняшними системами. Стремительный рост востребованности ИИ-приложений и НРС-решений приводит к резкому увеличению нагрузки на дата-центры. Это вынуждает операторов и гиперскейлеров закупать мощные дорогостоящие ускорители, которые оказываются в дефиците. Одновременно растут энергозатраты ЦОД. По оценкам, на дата-центры приходится до 1,5 % мирового потребления электроэнергии и 1 % глобальных выбросов CO2. 
Источник изображения: pixabay.com Компании по всему миру предпринимают различные меры по решению проблемы, включая внедрение СЖО и разработку принципиально новых сверхэффекттивных ИИ-чипов. Проект ARIA в данной сфере получил название Scaling Compute — AI at 1/1000th the cost, или «Масштабирование вычислений — ИИ за 1/1000 стоимости». Руководитель проекта Сурадж Брамхавар (Suraj Bramhavar) говорит, что на протяжении более чем 60 лет человечество «извлекало выгоду из экспоненциального увеличения вычислительной мощности при уменьшении затрат». Но, по его словам, такой подход больше не соответствует современным реалиям — особенно в свете повсеместного внедрения ресурсоёмких приложений ИИ. Брамхавар говорит, что специализированные решения, используемые для обучения масштабных ИИ-моделей, невероятно дороги, что может иметь далеко идущие экономические, геополитические и социальные последствия. Например, генеральный директор OpenAI Сэм Альтман ранее заявлял, что обучение GPT-4 обошлось его компании более чем в $100 млн. В рамках нового проекта ARIA будет оказывать финансовую поддержку научным коллективам и компаниям, разрабатывающим перспективные технологии, которые в дальнейшем помогут снизить стоимость ИИ-инфраструктур на порядки. Речь идёт о решениях, сочетающих высокое быстродействие, эффективность и простоту производства. «Природа предоставляет нам, по крайней мере, одно доказательство того, что фундаментально возможно выполнять сложную обработку информации с высокой эффективностью», — отмечает Брамхавар, имея в виду человеческий мозг. |
|

