Материалы по тегу: ethernet
|
22.04.2024 [09:09], Сергей Карасёв
От LTO к iSCSI: Atto представила мост XstreamCORE 8100TКомпания Atto представила устройство XstreamCORE 8100T — специализированный мост, позволяющий подключать ленточные накопители к сети 10GbE iSCSI. Таким образом, упрощается формирование систем для резервного копирования и восстановления информации. Новинка заключена в корпус с габаритами 30,5 × 103,5 × 240 мм и весит около 0,91 кг. К одному мосту могут быть подключены до четырёх приводов стандартов LTO-9, LTO-8 и LTO-7 с интерфейсом SAS-3 (порт mini-SAS HD). Для подключения к сети есть два порта 10GbE. При этом в составе IT-инфраструктуры можно задействовать несколько мостов. Анонсированы модификации устройства XCET-8100-TS0 и XCET-8100-TN0. Первая использует порты SFP+, вторая предлагает RJ-45/SFP. Заявленная установившаяся скорость передачи данных в обоих случаях достигает 2 Гбайт/с, а технология SpeedWrite оптимизирует использование доступной полосы пропускания. Предусмотрен выделенный порт управления 1GbE RJ-45. 
Источник изображения: Atto Диапазон рабочих температур — от +5 до +40 °C. Энергопотребление у модели XCET-8100-TS0, согласно техническим характеристикам, не превышает 25 Вт, у модификации XCET-8100-TN0 — 29 Вт. Стоят эти устройства $2895 и $3095 соответственно. Для управления служит веб-интерфейс; мосты могут использоваться в составе инфраструктур с любыми ОС. Разработчик говорит о простоте развёртывания.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 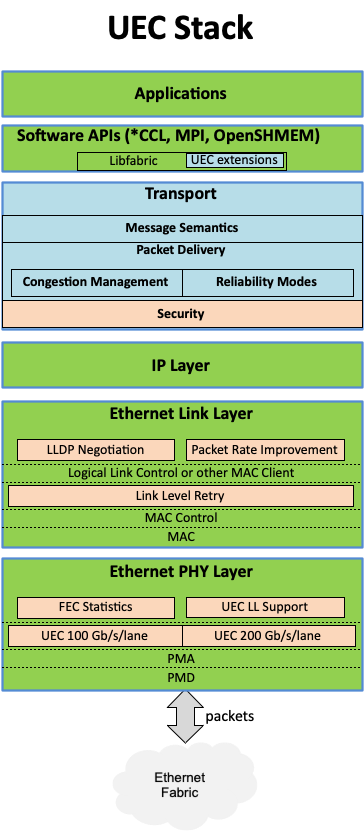
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 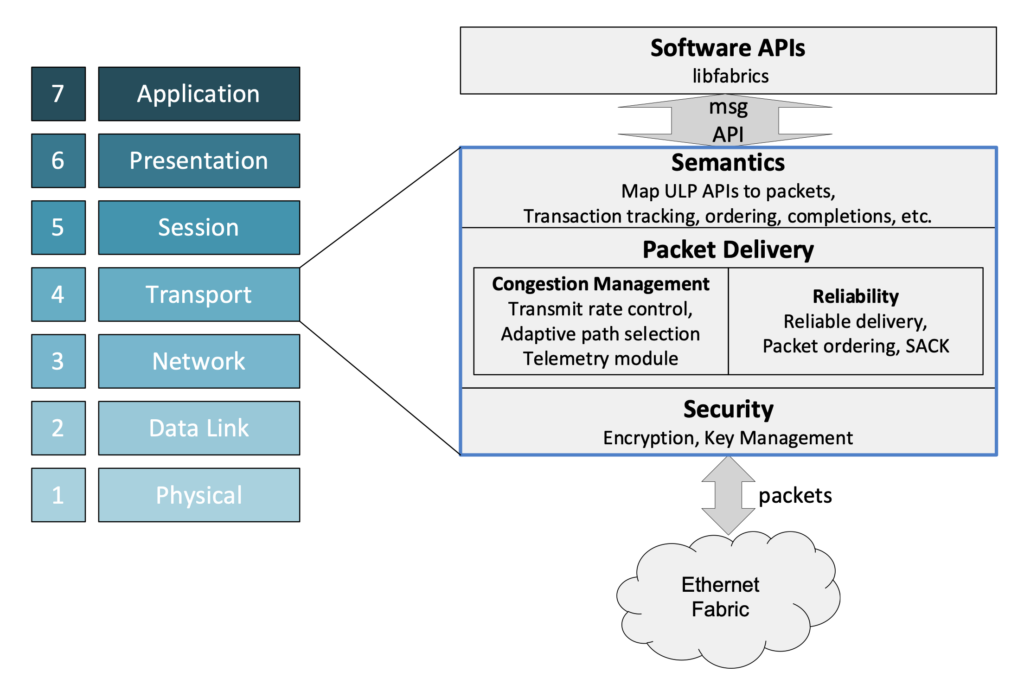
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
11.03.2024 [16:47], Алексей Степин
Synopsys завершила разработку платформы Ethernet 1,6 Тбит/сИзвестный разработчик микроэлектроники, компания Synopsys сообщила о завершении работ над новым сверхскоростным вариантом Ethernet, способным работать на скорости 1,6 Тбит/с, что вдвое превышает достигнутые коммерческими решениями на сегодня скорости. Эта разработка нацелена главным образом на рынок крупных ЦОД, особенно связанных с ИИ-технологиями, предъявляющими высокие требования к характеристикам сетевых каналов и интерконнектов. В настоящее время стандарт 1.6TbE не ратифицирован IEEE, и случится это не ранее 2026 года, но Synopsys считает, что применение её наработок в этой области позволит производителям микрочипов начать работу над созданием соответствующих контроллеров уже сейчас. Предварительная версия стандарта 802.3dj, описывающего базовые характеристики таких устройств, должна быть завершена уже в этом году. 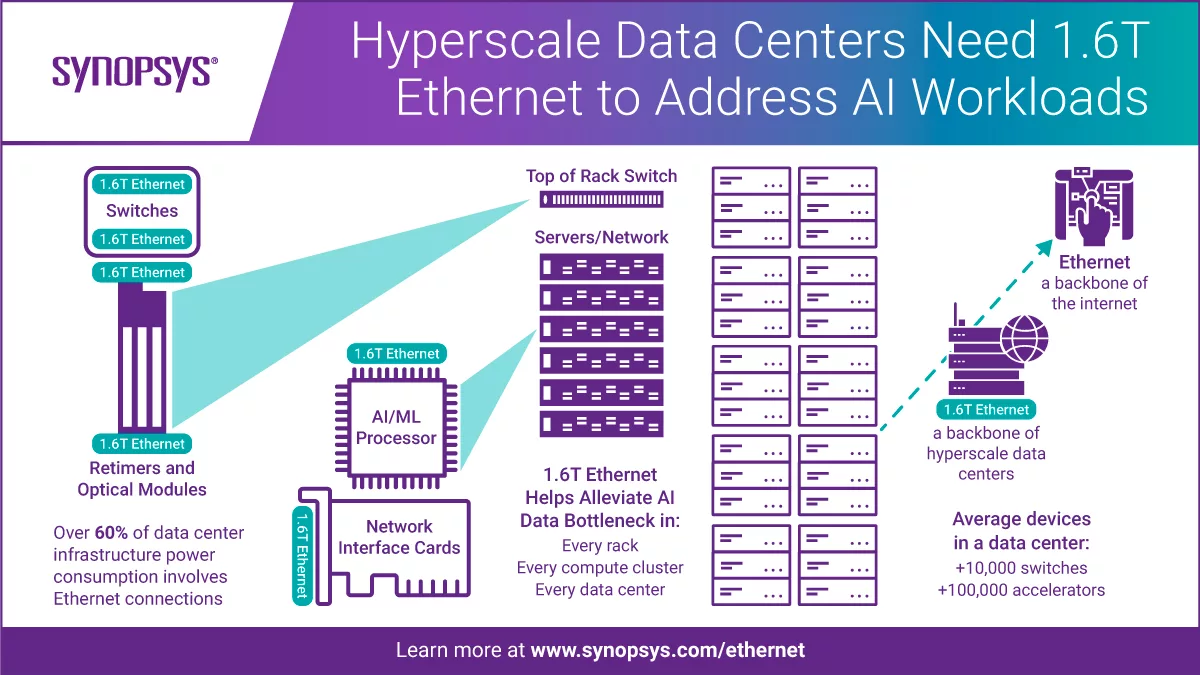
Источник здесь и далее: Synopsys Дизайн IP-блоков, созданный Synopsys, базируется именно на 802.3dj. Он предусматривает скорости 4 × 400 Гбит/с, 2 × 800 Гбит/с, либо один канал со скоростью 1,6 Тбит/с. В разработке используются блоки SerDes со скоростью 112 и 224 Гбит/с, отвечающие спецификациям OIF-112G и OIF-224G соответственно. В IP-решении Synopsys используются трансмиттеры PAM4, в которых реализована продвинутая обработка сигнала (feed-forward equalization), ресиверы же содержат продвинутый DSP. Это сочетание позволяет соединению работать при потере сигнала в канале, составляющей 45 дБ. Synopsys утверждает, что её технологии позволят реализовать Ethernet со скоростью 1,6 Тбит/с с 50 % экономией площади кремния. Продвинутая архитектура коррекции ошибок при этом должна обеспечить латентность на 40 % ниже в сравнении с классической реализацией.  В состав решения Synopsys входят блоки MAC, PCS, контроллер физического уровня (PHY) на основе прошедших тестирование и доказавших свою эффективность SerDes-блоков 224G, а также IP-модуль верификации, который должен помочь разработчикам чипов ускорить и упростить разработку новых сверхскоростных Ethernet-чипов. Все IP-компоненты доступны сейчас и ими уже воспользовались многочисленные клиенты, сообщает Synopsys. Новая разработка Synopsys получила одобрение со стороны консорциума Ethernet.
27.02.2024 [21:27], Сергей Карасёв
«Морион» наладил в Перми серийное производство отечественных управляемых Ethernet-коммутаторовМинистерство промышленности и торговли Пермского края сообщило о том, что местный разработчик и производитель оборудования связи «Морион» организовал серийный выпуск управляемых Ethernet-коммутаторов для построения высокопроизводительных сетей связи. Организовано серийное производство коммутаторов КРМ-5960 и КАМ-3284. Устройства первого семейства относятся к моноблочному типу: они оснащены 20 портами 1GbE RJ-45, четырьмя разъёмами 1GbE RJ-45/SFP и четырьмя портами 10GbE SFP+. Диапазон рабочих температур в зависимости от модификации простирается от 0 до +50 °C или от +5 до +40 °C. Решения КАМ-3284 представлены в блочно-модульном исполнении: они содержат по четыре оптических или электрических порта на модуль — до 24 портов в блоке. Эти коммутаторы могут эксплуатироваться при температурах от -10 до +55 °C при воздействии вибрации, многократных ударов и соляного тумана. Устройства можно применять в подвижных комплексах связи, в прибрежных морских зонах, на надводных лодках и пр. 
Источник изображения: Министерство промышленности и торговли Пермского края Упомянуты функции контроля доступа с высоким уровнем безопасности и ограничением трафика, в том числе при работе с инфраструктурой, построенной на базе российской платформы Astra Linux. Отмечается, что изделия изготавливаются преимущественно из российских комплектующих — уровень локализации составляет 70 %. Правда, не уточняется, о каких именно компонентах идёт речь. «Морион» уже поставляет коммутаторы для ведомственных и технологических сетей связи нефте- и газотранспортных предприятий, железнодорожных и сетевых компаний энергетической системы. В 2024 году планируется выпуск более 140 моделей управляемых коммутаторов. Инвестиции в проект превышают 140 млн руб. Из них 46 млн руб. предоставил федеральный Фонд развития промышленности (ФРП), ещё 20 млн руб. — региональный ФРП Пермского края. Нужно отметить, что выпуск коммутаторов наладили и многие другие российские компании. В их число входят производитель инфраструктурного IT-оборудования Fplus, поставщик сетевого телекоммуникационного оборудования операторского класса N3COM, дочернее предприятие Росатома «ТВЭЛ» и «Аквариус».
07.02.2024 [21:05], Владимир Мироненко
Серверы и сети: Cisco и NVIDIA расширили сотрудничество, чтобы упростить клиентам развёртывание ИИ-инфраструктурыCisco и NVIDIA объявили о расширении сотрудничества, чтобы предложить корпоративным клиентам масштабируемое и автоматизированное управление кластерами искусственного интеллекта (ИИ), автоматическое устранение неполадок, высокое качество обслуживания и многое другое, сообщается в пресс-релизе NVIDIA. Интегрированное ПО и сетевое оборудование двух компаний упростит клиентам развёртывание инфраструктуры для поддержки приложений ИИ. Соглашение предусматривает расширение роли сетей Ethernet в обработке рабочих нагрузок ИИ на предприятии, а также обеспечивает компаниям доступ к системам продаж друг друга и возможность взаимной поддержки. 
Источник изображения: NVIDIA Специализированные сетевые решения Cisco и NVIDIA на базе Ethernet будут продаваться через обширный глобальный канал Cisco, предлагая профессиональные услуги и поддержку через ключевых партнёров. Клиентам будут доступны новейшие ускорители NVIDIA в стоечных и блейд-серверах Cisco M7 UCS, включая Cisco UCS X-Series и UCS X-Series Direct, для поддержки ИИ и рабочих нагрузок с интенсивным использованием данных в ЦОД и на периферии. Интегрированный пакет, который станет доступен во II квартале, будет включать ПО NVIDIA AI Enterprise с программными платформами, предварительно обученными моделями и инструментами разработки. Совместно проверенные эталонные архитектуры Cisco Validated Designs (CVD) упростят развёртывание и управление кластерами ИИ в любом масштабе в широком спектре вариантов использования: виртуализированные и контейнерные среды, конвергентные и гиперконвергентные системы. CVD для FlexPod и FlashStack для генеративного ИИ с ПО NVIDIA AI Enterprise будут доступны в этом месяце. 
Источник изображения: Cisco Cisco упростила управление и эксплуатацию ИИ-инфраструктуры за счёт локального и облачного управления посредством Cisco Nexus Dashboard и Cisco Intersight. А поддержка Cisco ThousandEyes Digital Experience Monitoring поможет обеспечить аналитику на основе ИИ и автоматическое устранение проблем в сетях. Наконец, расширяемая платформа Cisco Observability Platform использует ИИ для контекстуализации и корреляции телеметрии в реальном времени. Как отметил ресурс Network World, NVIDIA внедрила множество реализаций ИИ, основанных на сети InfiniBand. Теперь компания также участвует в отраслевых усилиях по обеспечению того, чтобы Ethernet стал важнейшей основой для поддерживающих ИИ сетей в будущем. В частности, прошлой осенью компания, наконец, представила SuperNIC — 400GbE DPU для ИИ-нагрузок.
24.01.2024 [20:15], Сергей Карасёв
Fplus представила самый быстрый российский коммутатор — FDS-7532D1 с 32 портами 400GbEРоссийский производитель инфраструктурного IT-оборудования Fplus анонсировал устройство FDS-7532D1: это, как утверждается, самый быстрый на сегодняшний день коммутатор в России. Новинка оснащена 32 портами 400GbE (QSFP56-DD), а скорость коммутации при максимальной загрузке достигает 25,6 Тбит/с. Коммутаторы серии FDS предназначены для организации высокоскоростных сетей передачи данных. Решения подходят для современных дата-центров, а также для корпоративных и операторских инфраструктур, где могут применяться на уровне ядра. Используемые ASIC вендор предпочитает не раскрывать. Модель FDS-7532D1 выполнена в форм-факторе 1RU с габаритами 440 × 588 × 44 мм; масса составляет около 16 кг. Заявленное энергопотребление — 1600 Вт, максимальная рабочая температура — 45 °C. В конструкции применены шесть (5+1) съёмных блоков вентиляторов и два (1+1) блока питания. Интерфейсы управления OOB: один RJ-45 и два SFP+. Количество VLAN достигает 4 тыс., размер MAC FDB — 256 тыс. записей, количество ECMP-групп — 10 тыс. 
Источник изображения: Fplus Коммутаторы серии FDS построены на базе ASIC с неблокируемой матрицей коммутации. В устройствах могут использоваться трансиверы SFP, SFP+, SFP28, QSFP+, QSFP28, QSFP56 и QSFP56-DD. Упомянуты единый интерфейс командной строки (CLI) со стандартным для отрасли синтаксисом и широкий набор поддерживаемых типовых инструментов автоматизации управления. Коммутаторы серии FDS также поддерживают установку альтернативных операционных систем. В производстве коммутаторов задействовано несколько площадок, расположенных на территории России, в том числе собственный завод Fplus в Подмосковье. Разработкой устройств занимаются две RnD-команды: одна отвечает за аппаратную часть, вторая — за ПО. Fplus направила документы о включении коммутатора FDS-7532D1 в Единый реестр российской радиоэлектронной продукции Минпромторга.
09.12.2023 [23:32], Сергей Карасёв
Продажи Ethernet-коммутаторов корпоративного класса растут, а маршрутизаторов — падаютКомпания International Data Corporation (IDC) подвела квартальные итоги исследования мирового рынка сетевого оборудования корпоративного класса — коммутаторов Ethernet и маршрутизаторов. Отрасль показала смешанные результаты, несмотря на смягчение проблем с цепочками поставок, которые начались во время пандемии COVID-19. Продажи Ethernet-коммутаторов в III четверти 2023 года составили $11,7 млрд, что на 15,8 % больше год к году. В сегменте устройств для дата-центров выручка поднялась на 7,2 %, в сегменте решений для прочих корпоративных заказчиков — на 22,2 %. В рейтинг ведущих поставщиков коммутаторов Ethernet входят Cisco, Arista Networks, Huawei, HPE и H3C с долями соответственно 45,1 %, 10,6 %, 9,6 %, 7,7 % и 4,1 %. 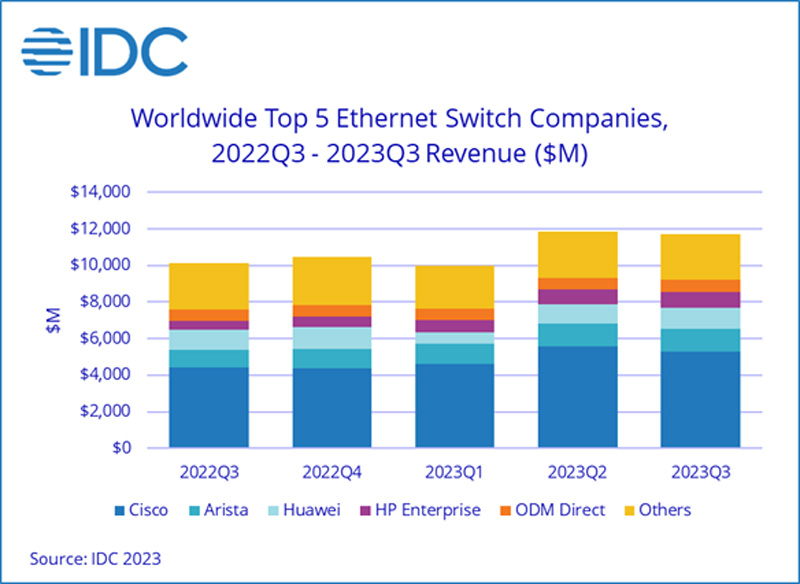
Источник изображения: IDC Поставки коммутаторов стандартов 200/400GbE для ЦОД выросли на 44,0 % по сравнению с прошлым годом, а количество реализованных портов поднялось на 63,9 %. Спрос на решения 100GbE увеличился на 6,0 % год к году, на модели 25/50GbE — на 26,3 %. По направлению коммутаторов для сегментов, не связанных с ЦОД, поставки устройств 1GbE прибавили 18,3 %, моделей 10GbE — 5,8 %. Выручка от оборудования 2,5/5GbE показала рост на 92,0 %. С географической точки зрения спрос на коммутаторы Ethernet увеличился в большинстве регионов мира. В США продажи в годовом исчислении поднялись на 26,7 %, в Канаде — на 28,6 %. В Латинской Америке зафиксирована прибавка на уровне 25,9 %, в Западной Европе — на 12,0 %, в Центральной и Восточной Европе — на 17,8%. В Азиатско-Тихоокеанском регионе (за исключением Японии и Китая) показан рост на 14,1 %. При этом в КНР продажи упали на 12,4 %, а в Японии — поднялись на 2,9 %. Что касается маршрутизаторов, то их отгрузки в III квартале 2023 года уменьшились на 9,4 %, составив $3,7 млрд. С региональной точки зрения продажи в Америке сократились на 7,3 %, в Азиатско-Тихоокеанском регионе — на 11,1 %, в Европе, на Ближнем Востоке и в Африке — на 10,4 %.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 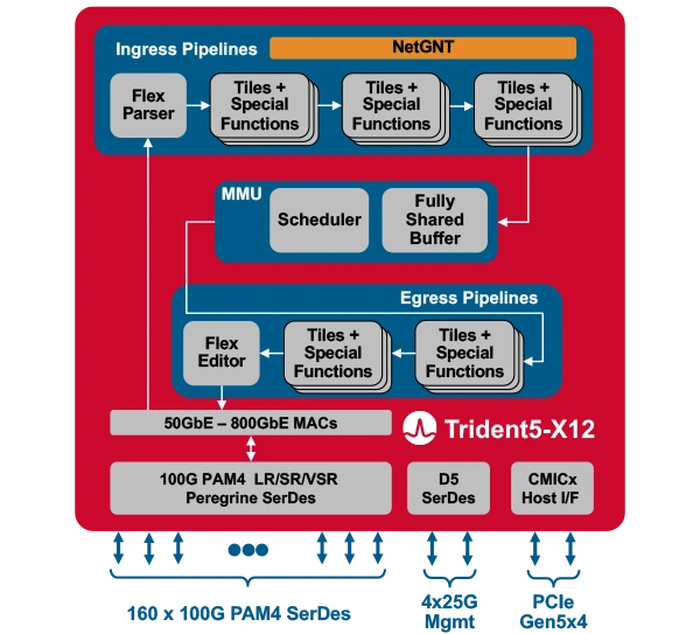 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
23.11.2023 [01:01], Владимир Мироненко
Nokia поможет консорциуму Ultra Ethernet в разработке новых спецификаций Ethernet для систем ИИNokia объявила о поддержке консорциума Ultra Ethernet Consortium (UEC), созданного с целью объединения усилий компаний для обновления спецификаций Ethernet и разработки API, позволяющих удовлетворить растущие сетевые требований систем ИИ и HPC. Компания отметила, что почти универсальный протокол для сетей передачи данных Ethernet способен удовлетворить широкие потребности систем ИИ в производительности, а благодаря поддержке Nokia консорциум сможет разрабатывать новые стандарты, лучшие практики и архитектуры для специализированных сетей ЦОД с ИИ. Nokia добилась больших успехов в разработке сверхмасштабируемых сетевых решений с низкой задержкой для ЦОД и интерконнекта. Компания планирует использовать накопленный опыт при участии в нескольких рабочих группах UEC, помогая обеспечить соответствие продуктов консорциума критическим потребностям всех своих клиентов. 
Источник изображения: Nokia «Используя наше широкое присутствие в сфере коммуникаций, корпоративных и веб-сетей, мы стремимся сделать Ultra Ethernet высоко совместимой, недорогой и функционально интероперабельной частью будущих стеков приложений искусственного интеллекта и высокопроизводительных вычислений», — заявил глава IP-подразделения Nokia. |
|

