Материалы по тегу: 400gbe
|
24.01.2024 [20:15], Сергей Карасёв
Fplus представила самый быстрый российский коммутатор — FDS-7532D1 с 32 портами 400GbEРоссийский производитель инфраструктурного IT-оборудования Fplus анонсировал устройство FDS-7532D1: это, как утверждается, самый быстрый на сегодняшний день коммутатор в России. Новинка оснащена 32 портами 400GbE (QSFP56-DD), а скорость коммутации при максимальной загрузке достигает 25,6 Тбит/с. Коммутаторы серии FDS предназначены для организации высокоскоростных сетей передачи данных. Решения подходят для современных дата-центров, а также для корпоративных и операторских инфраструктур, где могут применяться на уровне ядра. Используемые ASIC вендор предпочитает не раскрывать. Модель FDS-7532D1 выполнена в форм-факторе 1RU с габаритами 440 × 588 × 44 мм; масса составляет около 16 кг. Заявленное энергопотребление — 1600 Вт, максимальная рабочая температура — 45 °C. В конструкции применены шесть (5+1) съёмных блоков вентиляторов и два (1+1) блока питания. Интерфейсы управления OOB: один RJ-45 и два SFP+. Количество VLAN достигает 4 тыс., размер MAC FDB — 256 тыс. записей, количество ECMP-групп — 10 тыс. 
Источник изображения: Fplus Коммутаторы серии FDS построены на базе ASIC с неблокируемой матрицей коммутации. В устройствах могут использоваться трансиверы SFP, SFP+, SFP28, QSFP+, QSFP28, QSFP56 и QSFP56-DD. Упомянуты единый интерфейс командной строки (CLI) со стандартным для отрасли синтаксисом и широкий набор поддерживаемых типовых инструментов автоматизации управления. Коммутаторы серии FDS также поддерживают установку альтернативных операционных систем. В производстве коммутаторов задействовано несколько площадок, расположенных на территории России, в том числе собственный завод Fplus в Подмосковье. Разработкой устройств занимаются две RnD-команды: одна отвечает за аппаратную часть, вторая — за ПО. Fplus направила документы о включении коммутатора FDS-7532D1 в Единый реестр российской радиоэлектронной продукции Минпромторга.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 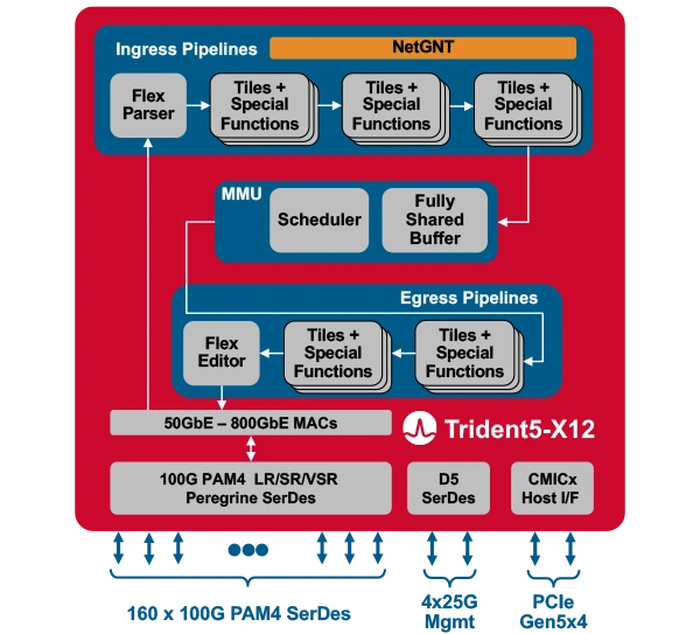 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для гипермасштабируемых ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
15.11.2023 [20:25], Алексей Степин
Cornelis Networks анонсировала семейство продуктов CN5000 для экосистемы Omni-Path 400GКак известно, уроненное Intel знамя Omni-Path подхватила компания Cornelis Networks, которая достаточно успешно и уверенно продолжает совершенствовать эту систему интерконнекта. Буквально на днях состоялся официальный анонс CN5000 — серии решений для экосистемы Omni-Path второго поколения, способных работать на скорости 400 Гбит/с. 
Источник изображений здесь и далее: Cornelis Networks О планах Cornelis Networks относительно CN5000 и следующих за ним поколений Omni-Path уже рассказывалось ранее. Во втором поколении разработчики отказались от Performance Scale Messaging и целиком перешли на открытый стек OFI (libfabric). По всей видимости, дела у Cornelis идут хорошо, поскольку анонс состоялся уже сейчас, хотя ранее выход CN5000 был запланирован на 2024 год. Никаких данных о сроках начала массовых поставок и ценах компания-разработчик пока не приводит, но потенциальным заказчикам уже предлагает связаться с отделом продаж.  Компания назвала главные достоинства новой технологии. Среди них высокая инфраструктурная эффективность, отличное соотношение цены и качеству, высокая защищённость соединений, реализация QoS, а также лучшая в своём классе латентность (менее 1 мкс), что особенно важно для рынков ИИ и HPC.  В основе инфраструктуры Omni-Path CN5000 лежат три ключевых продукта: хост-адаптеры PCIe 5.0, непосредственно устанавливаемые в узлы, 48-портовые 1U-коммутаторы и 576-портовые 17U-директоры. Для всех трёх доступно как воздушное, так и жидкостное охлаждение. Фабрика на базе CN5000 может содержать до 330 тыс. узлов, чего достаточно для построения крупномасштабных HPC-систем.
01.09.2023 [16:26], Алексей Степин
Cornelis Networks ускорит Omni-Path Express до 1,6 Тбит/сИнтерконнекту Omni-Path прочили в своё время светлое будущее, но в 2019 году компания Intel отказалась от своего детища и свернула поставки OPA-решений. Однако эстафету подхватила Cornelis Networks, так что технология не умерла — совсем недавно The Next Platform были опубликованы планы по дальнейшему развитию Omni-Path. В 2012 году Intel выкупила наработки по TruScale InfiniBand у QLogic, позднее дополнив их приобретением у Cray интерконнектов Gemini XT и Aries XC. Задачей было создание единого интерконнекта, могущего заменить PCIe, FC и Ethernet, а в основу была положена технология Performance Scale Messaging (PSM). PSM считалась более эффективной и пригодной в сравнении с verbs InfiniBand, однако самой технологии более 20 лет. В итоге Cornelis Networks отказалась от PSM и теперь развивает новый программный стек на базе libfabric. 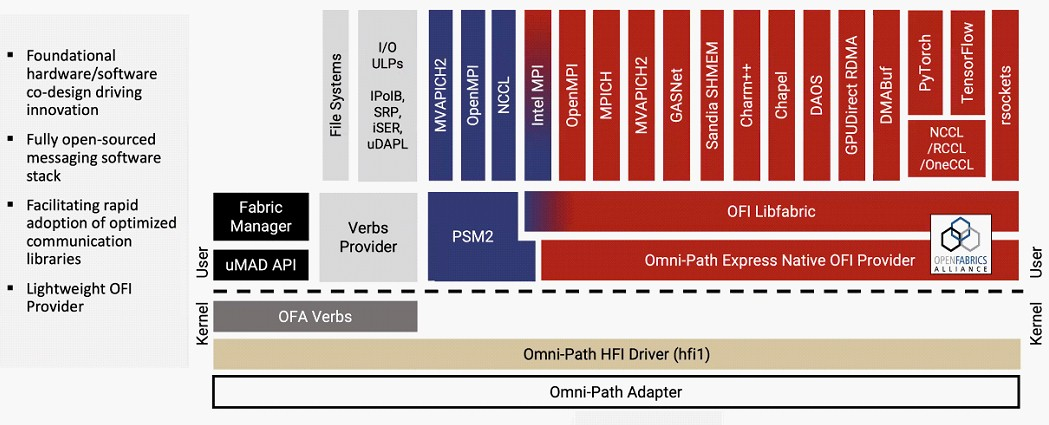
Источник изображений здесь и далее: Cornelis Networks (viaThe Next Platform) Уже первое поколение Omni-Path Express (OPX), работающее со скоростью 100 Гбит/с могло работать под управлением нового стека бок о бок с PSM2, а для актуальных 400G-продуктов Omni-Path Express CN5000 вариант OFI станет единственным. Скорее всего, в этом поколении будет также убрано всё, что работает на основе кода OFA Verbs. Останутся только части, выделенные на слайде выше красным. Как отмечает Cornelis Networks, главным отличием OPX от InfiniBand станет использование стека на базе полностью открытого кода с апстримом драйвера OFI в ядро Linux. 
Планы Cornelis Networks по развитию Omni-Path Планы компании простираются достаточно далеко: на 2024 год запланировано пятое поколение Omni-Path, включающее в себя не только адаптеры, но и необходимую инфраструктуру — 48-портовые коммутаторы и 576-портовые директоры. Предел масштабирования возрастёт практически на порядок, с 36,8 тыс. подключений для Omni-Path 100 до 330 тыс. Латентность при этом составит менее 1 мкс при потоке до 1,2 млрд сообщений в секунду. Появится поддержка топологий Dragonfly и Megafly, оптимизированных для применения в крупных HPC-системах, и динамическая адаптивная маршрутизация на базе данных телеметрии. 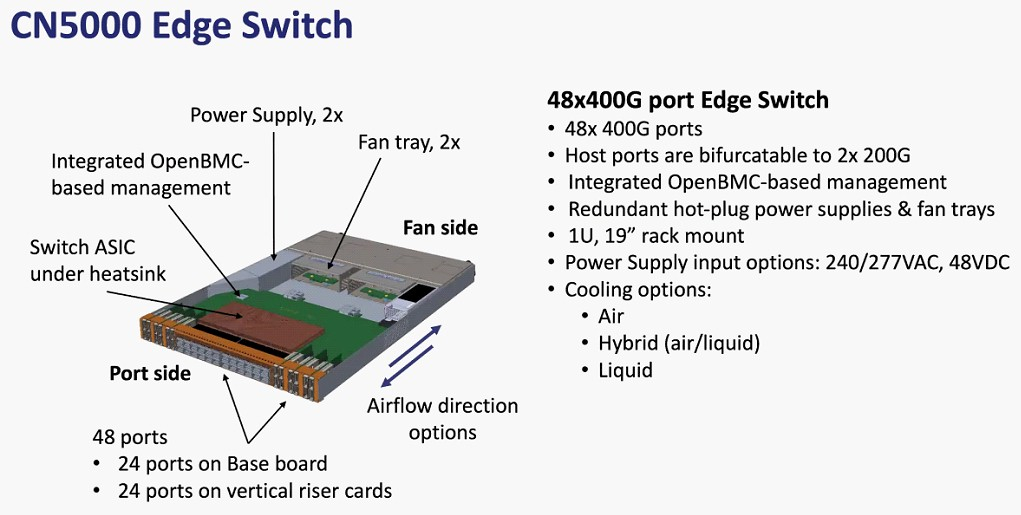 Характеристики и внутреннее устройство коммутаторов пятого поколения CN5000 компания публикует уже сейчас. Обычный периферийный коммутатор займёт высоту 1U, но при этом будет поддерживать как воздушное, так и жидкостное охлаждение, а модульный коммутатор класса director будет занимать 17U и получит внутренний интерконнект с топологией 2-tier Fat Tree. В нём будет предусмотрена горячая замена модулей и опция жидкостного охлаждения.  Базовый адаптер CN5000 выглядит как обычная плата расширения с интерфейсом PCIe 5.0 x16. Будут доступны варианты с одним и двумя портами 400G. Что интересно, опция жидкостного охлаждения предусмотрена и здесь. В 2026 году должно появиться шестое поколение решений Omni-Path CN6000 со скоростью 800 Гбит/с, включающее в себя не только базовые адаптеры и коммутаторы, но и первый в мире DPU для OPA, построенный на базе архитектуры RISC-V и поддерживающий CXL. Благодаря DPU будут реализованы более продвинутые опции разгрузки хост-системы и ускорения конкретных приложений. 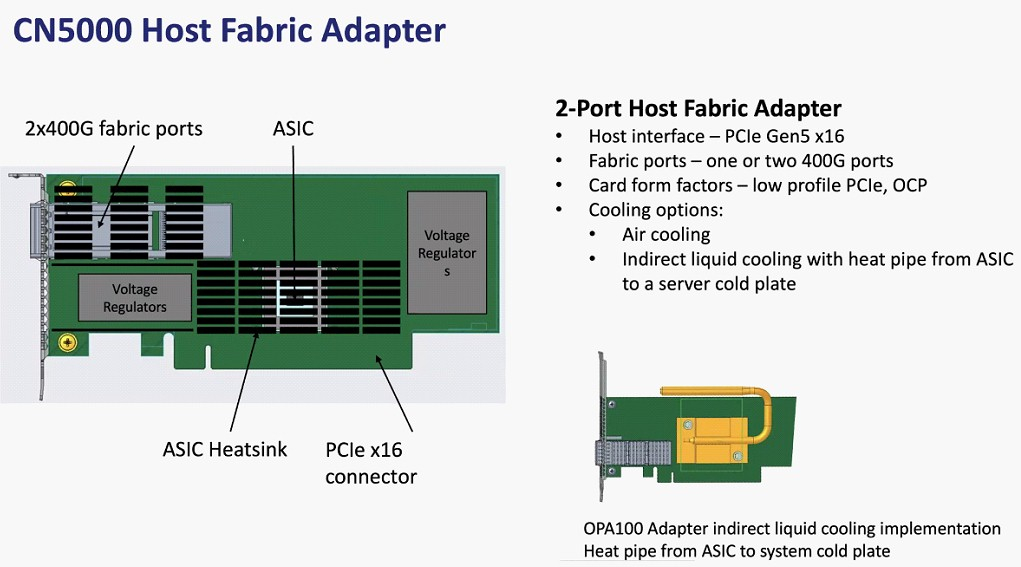 Наконец, в 2028 году в седьмом поколении CN7000 скоростной потолок поднимется с 800 до 1600 Гбит/с. Будет внедрена перспективная для крупномасштабных сетей поддержка топологии HyperX. Также ожидается появление чиплетов с интерфейсом UCIe и интегрированной фотоникой, что позволит интегрировать Omni-Path в решения сторонних производителей. Одной из главных целей Cornelis Networks, напомним, заявлено создание системы интерконнекта для суперкомпьютеров нового поколения экзафлопного класса. Разработка финансируется в рамках инициативы Exascale Computing Initiative (ECI). А первым суперкомпьютером, использующим Omni-Path пятого поколения (400G), станет техасский Stampede3.
29.07.2023 [09:52], Сергей Карасёв
Broadcom представила платформу Trident 4-X7 для 400GbE-коммутаторовКомпания Broadcom анонсировала платформу StrataXGS Trident 4 BCM56690 (Trident 4-X7), предназначенную для создания коммутаторов нового поколения с поддержкой 400GbE. Полностью программируемый чип обеспечивает пропускную способность до 4 Тбит/с. Изделие Trident 4-X7 обеспечивает поддержку подключения 400GbE в инфраструктурах Spine/Fabric следующего поколения, которые проникают из облаков в корпоративные дата-центры. Утверждается, что энергопотребление в расчёте на порт 100GbE снижается вдвое по сравнению с существующими решениями. 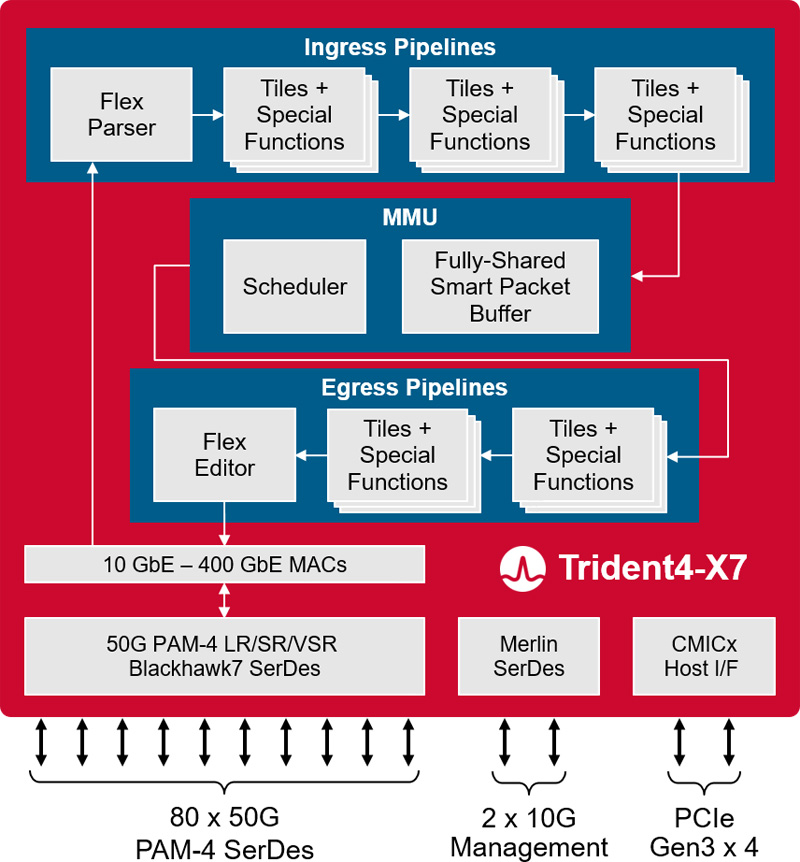
Источник изображения: Broadcom Платформа Trident 4-X7 предоставляет аппаратные функции для аналитики, диагностики и телеметрии, которые помогут облачным провайдерам автоматизировать многие операции в ЦОД. Это позволяет повысить надёжность при одновременном снижении эксплуатационных расходов. Возможность программирования даёт возможность настраивать чип под нужны конкретного оператора дата-центра. Решение поддерживает сетевую архитектуру 50G ToR (Top of Rack) в конфигурации 48 × 50G + 8 × 200G или 48 × 50G + 4 × 400G. При производстве чипа применяется технология 7-нм класса. Среди прочих преимуществ разработчик выделяет:
25.06.2023 [16:53], Алексей Степин
Cisco представила ASIC Silicon One G200: 51,2 Тбит/с для ИИКомпания Cisco успешно выпустила новые ASIC для сетевых коммутаторов с производительностью 51,2 Тбит/с. Как заявляют разработчики, коммутаторы на базе чипа серии G200 способны объединить в единый комплекс 32 тыс. ускорителей. Новое решение входит в портфолио Cisco Silicon One и изначально нацелено на рынок гиперскейлеров и создателей ИИ-кластеров. В новом чипе в два раза увеличено количество блоков SerDes с производительностью 112 Гбит/с (с 256 до 512), что и позволило довести общую коммутационную производительность до 51,2 Тбит/с. Доступны конфигурации 64×800GbE, 128×400GbE или 256×200GbE, всё зависит от желаемой плотности размещения и скорости портов. Это, в частности, позволяет избавиться от избыточных уровней в топологии сети. 
Источник изображений: Cisco Cisco отмечает, что новинка вдвое энергоэффективнее и имеет вдвое меньшую задержку в сравнении с G100. Кроме того, чипы предлагают расширенную телеметрию, поддержку языка P4 для обработки трафика на лету, а также возможность использования современных интерфейсов, в том числе интегрированную оптику или медные кабели длиной до 4 м, чего более чем достаточно для организации связи на уровне стойки. 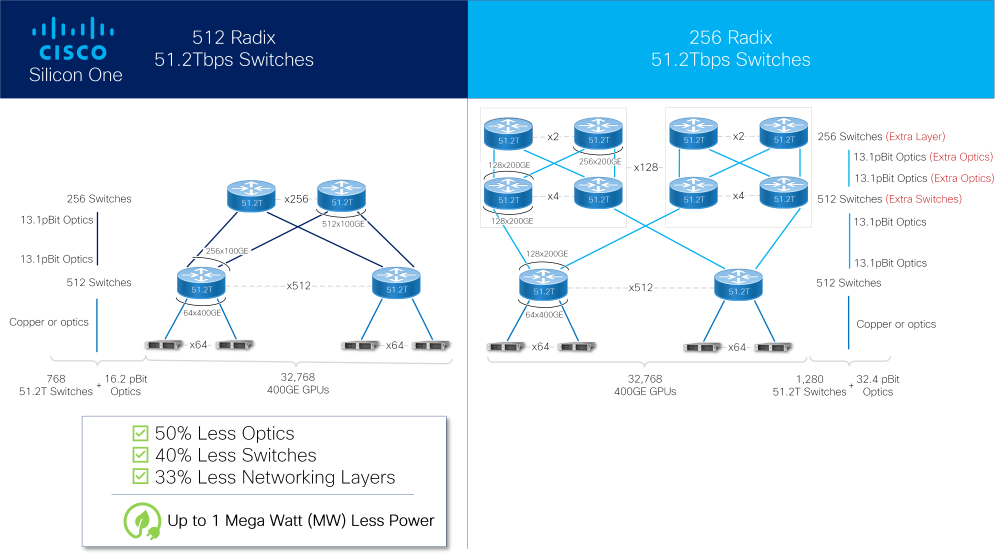 Как и Broadcom Tomahawk-5 или Jericho3-AI, Marvell Teralynx 10 и NVIDIA Spectrum-X, новый чип Cisco содержит возможности, востребованные в среде ИИ-систем, такие как продвинутые средства преодоления заторов в сети (congestion), технологии packet spraying и резервирование линков с возможностью мгновенного восстановления разорванного соединения. Новые чипы серии G200 уже поставляются, но компания пока не назвала даты появления на рынке коммутаторов Cisco на базе нового «кремния».
29.05.2023 [07:35], Сергей Карасёв
Ethernet для ИИ: NVIDIA представила 400G/800G-платформу Spectrum-XКомпания NVIDIA в ходе выставки Computex 2023 анонсировала передовую Ethernet-платформу Spectrum-X для облачных провайдеров: система поможет в масштабировании сервисов генеративного ИИ. Решение уже доступно гиперскейлерам и операторам крупных дата-центров. Платформа предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с) и 400GbE DPU NVIDIA BlueField-3. Отмечается, что BlueField-3 сочетает в себе большие вычислительные ресурсы, высокоскоростное сетевое соединение и обширные возможности программирования, что даёт возможность создавать программно-определяемые решения с аппаратным ускорением для самых требовательных задач. В результате, платформа Spectrum-X позволяет добиться 1,7-кратного увеличения производительности ИИ-нагрузок и повышения энергоэффективности по сравнению с другими решениями. 
Источник изображений: NVIDIA Для Spectrum-X заявлена возможность использования до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) на базе одного коммутатора или до 16 000 портов в случае архитектуры Spine-Leaf. В набор сопутствующего ПО входят SDK-комплекты для SDKCumulus Linux, SONiC и NetQ, а также фреймворк NVIDIA DOCA. С применением решений NVIDIA Mellanox LinkX возможно формирование сквозной 400GbE-фабрики, оптимизированной для облачных ИИ-сервисов.  Платформа Spectrum-X, в частности, будет применена в составе суперкомпьютера Israel-1, который NVIDIA строит в своём израильском дата-центре. Комплекс объединит серверы Dell PowerEdge XE9680 на основе NVIDIA HGX H100 (восемь GPU), изделия BlueField-3 DPU и коммутаторы Spectrum-4.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 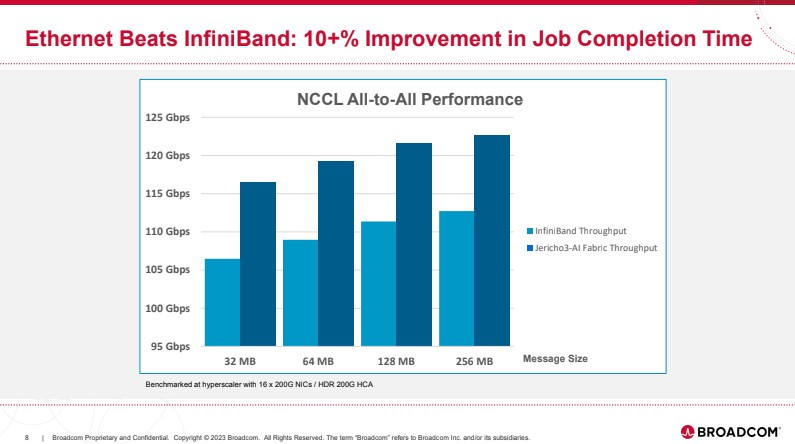 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
13.03.2023 [15:01], Сергей Карасёв
Мировые поставки коммутаторов для ЦОД в конце 2022 года установили новый рекорд, но Китай стал исключениемКомпания Dell'Oro Group обнародовала результаты исследования глобального рынка коммутаторов для дата-центров в последней четверти 2022 года. Сообщается, что отрасль пятый квартал подряд демонстрирует рост на двузначные числа процентов, что отражает продолжающееся развитие облачных провайдеров и площадок гиперскейлеров. В IV квартале 2022-го поставки ЦОД-коммутаторов поднялись на 15 % в годовом исчислении, установив новый рекорд. По итогам минувшего года в целом также зафиксированы рекордные показатели. Рост выручки наблюдался во всех регионах, кроме Китая, где падение в последней четверти 2020 года составило почти 20 %. До этого отрицательная динамика в КНР наблюдалась только в I квартале 2020-го, что объяснялось ограничениями в связи с пандемией COVID-19. Но тогда спад был незначительным, и за ним последовало быстрое восстановление. Ключевой вклад в рост выручки внесла компания Arista Networks, получившая крупный заказ от Meta✴. За Arista следует Juniper. Доля выручки Arista в течение IV квартала прошлого года выросла почти на 7 %, а по итогам 2022-го в целом превысила 20 %. Годовые поставки устройств класса 200G/400G достигли почти 10 млн портов, что составляет более 10 % от общего объёма продаж. В денежном выражении на такие решения пришлось почти 20 % выручки. Спрос на продукты 200G/400G остаётся высоким среди гиперскейлеров — Google, Amazon, Microsoft и Meta✴. 
Изображение: Meta/OCP «На поставщиков облачных услуг пришлось более 80 % роста продаж в течение квартала. Хотя эти сильные показатели соответствовали нашим ожиданиям, значительное снижение в Китае стало неожиданностью. Спад в КНР можно объяснить различными факторами, в том числе сокращением расходов крупных китайских поставщиков облачных услуг, таких как Alibaba и Tencent, ограничениями в связи с COVID-19 и влиянием обменных курсов валют», — отмечает Dell'Oro Group. |
|

