Материалы по тегу: 800gbe
|
15.04.2024 [22:28], Руслан Авдеев
Обновлённому коллайдеру — обновлённая сеть: Nokia и SURF «разогнали» до 800 Гбит/с имеющуюся оптическую сеть БАКФинская Nokia и научно-образовательное IT-объединение SURF из Нидерландов успешно добились скорости передачи данных 800 Гбит/с на существующей трансграничной оптоволоконной сетевой инфраструктуре SURF. По информации Nokia, новых скоростей удалось добиться благодаря применению платформы Photonic Service Engine (PSE-6s). Ожидается, что внедрение нового решения поможет обмениваться большими массивами данных между Большим адронным коллайдером (БАК), исследовательскими мощностями NL Tier-1 (NL T1) группы SURF и нидерландским институтом NIKHEF, занимающимся атомной энергетикой и смежными проектами. Отмечается, что повысить скорость удалось на старых ВОЛС. Испытание провели на линии протяжённостью 1648 км между Амстердамом и Женевой, которая пересекает Бельгию и Францию. Это часть сети SURF, связывающая научно-образовательные институты в Нидерландах и других странах мира, включая собственную оптическую сеть БАК (LHC Optical Private Network, LHCOPN). Последняя обеспечивает доступ к данным БАК в CERN. CERN, NIKHEF, SURF и эксперимент ATLAS объединили усилия для испытаний высокоскоростных соединений, которые понадобятся обновлённому варианту БАК HL-LHC. 
Источник изображения: Nokia SERF уже готовит свои сети к росту нагрузок, поскольку обновлённый коллайдер HL-LHC должен заработать в 2029 году. Ожидается, что такая модернизация позволит сделать ещё больше открытий — но данных придётся обрабатывать намного больше, чем это делается сегодня. В Nokia подчёркивают, что эксперимент демонстрирует важнейшую роль сетей передачи данных в инициативах, способных раскрыть секреты вселенной.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 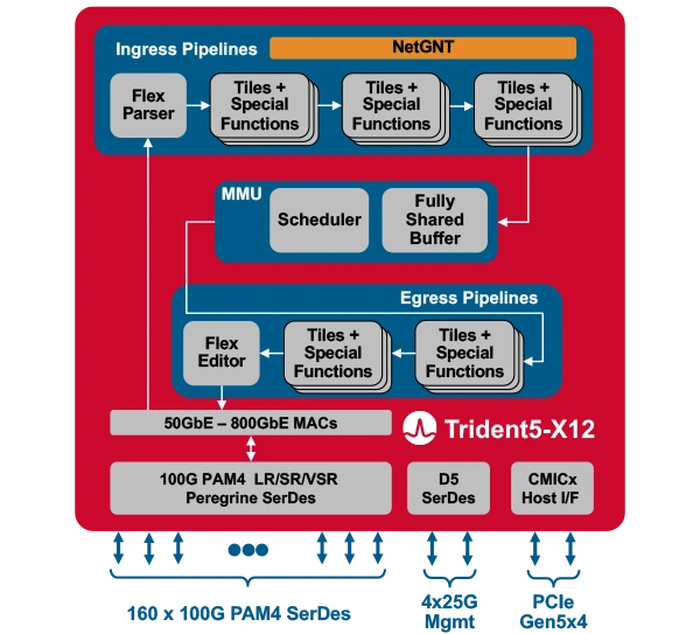 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
24.10.2023 [14:49], Алексей Степин
Broadcom представила первый в индустрии одночиповый маршрутизатор класса 25,6 Тбит/сBroadcom объявила о расширении серии одночиповых маршрутизаторов StrataDNX. Новинка, сетевой процессор Qumran3D, стал первым в мире высокоинтегрированным маршрутизатором с пропускной способностью 25,6 Тбит/с. Чип BCM88870 производится с использованием 5-нм техпроцесса. Решения на его основе, по словам Broadcom, позволят сэкономить 66 % энергии и 80 % стоечного пространства в сравнении с аналогичными по классу решениями предыдущих поколений. Новый чип также должен помочь в освоении высокоскоростного Ethernet — он может быть сконфигурирован для работы с портами от 100GbE до 800GbE. Поддерживается стандарт 800ZR+. Qumran3D располагает 256 линками, реализованными с помощью PAM4-блоков SerDes класса 100G. 
Источник изображений здесь и далее: Broadcom В устройстве реализовано шифрование MACSec и IPSec, работающее на полной скорости на всех сетевых портах. Наличие интегрированной памяти HBM обеспечивает расширенную буферизацию, гарантирующую отсутствие потери пакетов даже в самых нагруженных сетях. Причём объёма достаточно и для хранения расширенных политик и обширных таблиц маршрутизации, что освобождает решения на базе Qumran3D от необходимости использования дополнительных чипов, а значит, и удешевляет их дизайн.  Как и ряд других решений Broadcom, Qumran3D использует реконфигурируемые сетевые движки Elastic Pipe, позволяющие гибко настраивать сценарии маршрутизации с учётом требований заказчика, а также по необходимости вводить поддержку новых протоколов. Наличие движка иерархической приоритизации гарантирует стабильную пропускную полосу для заданных типов трафика, что делает Qumran3D подходящим в качестве провайдерского решения. Новый чип Broadcom имеет широкую область применения, но в первую очередь, он нацелен на рынок провайдеров сетевых услуг, ЦОД и облачных систем. Qumran3D уже поставляется избранным заказчикам, но дата начала массовых поставок пока не названа.
11.10.2023 [15:43], Сергей Карасёв
Nokia установила новый рекорд скорости при трансокеанской передаче данных — 800 Гбит/с на одной длине волныИсследователи Nokia Bell Labs установили новый мировой рекорд скорости передачи данных через трансокеанскую оптическую линию связи. Инженеры смогли достичь 800 Гбит/с на расстоянии 7865 км при использовании одной длины волны. Названная дистанция, как отмечается, в два раза больше расстояния, которое обеспечивает современное оборудование при работе с указанной пропускной способностью. Значение примерно равно географическому расстоянию между Сиэтлом и Токио, т.е. новая технология позволит эффективно связать континенты 800G-каналами. Исследователи Nokia Bell Labs установили рекорд при использовании испытательного стенда оптических коммуникаций в Париже-Сакле (Франция). Кроме того, специалисты Nokia Bell Labs совместно с сотрудниками дочерней компании Nokia Alcatel Submarine Networks (ASN) показали ещё один рекорд. Они продемонстрировали пропускную способность в 41 Тбит/с на расстоянии 291 км через систему передачи данных в C-диапазоне без повторителей. Такие каналы обычно используются для соединения островов и морских платформ друг с другом и с материком. Предыдущий рекорд для подобных систем — 35 Тбит/с на том же расстоянии. 
Источник изображения: pixabay.com Оба достижения стали возможными благодаря повышению бодрейта. В случае трансокеанских систем связи такое увеличение скорости передачи данных позволит, к примеру, удвоить протяжённость трансокеанских каналов при сохранении прежней пропускной способности, а на коротких расстояних снизить количество трансиверов при увеличении ёмкости без задействования дополнительных частотных диапазанов.
10.10.2023 [22:33], Алексей Степин
Опубликованы первичные спецификациии InfiniBand XDR: 200 Гбит/с на линию, 800 — на портАссоциация IBTA (InfiniBand Trade Association), ответственная за развитие данного стандарта, опубликовала новые спецификации, утверждающие характеристики стандарта InfiniBand XDR. Хотя Ethernet активно вытесняет другие сетевые стандарты благодаря быстрому росту скоростей и активному освоению всё новых технологий вроде RDMA, InfiniBand (IB) зачастую продолжает оставаться предпочтительным выбором для HPC-систем благодаря низкому уровню задержек, особенно критичному в случае крупномасштабной сети. Согласно данным Naddod, задержи у InfiniBand составляют не более 150–200 нс, в то время как для Ethernet этот показатель обычно составляет 500 нс и более. Проблему с отставанием в пропускной способности должны решить новые спецификации, опубликованные IBTA в виде томов Volume 1 Release 1.7 (ядро архитектуры InfiniBand) и Volume 2 release 1.5 (аспекты физической реализации). Наиболее важным в новых спецификациях является первичное введение и описание стандарта XDR, предусматривающего скорость передачи данных 200 Гбит/с на каждую линию. Это автоматически даёт 800 Гбит/с на стандартный IB-порт из четырёх линий, а для связи между коммутаторами может быть использован канал на восемь линий, что даёт 1600 Гбит/с. 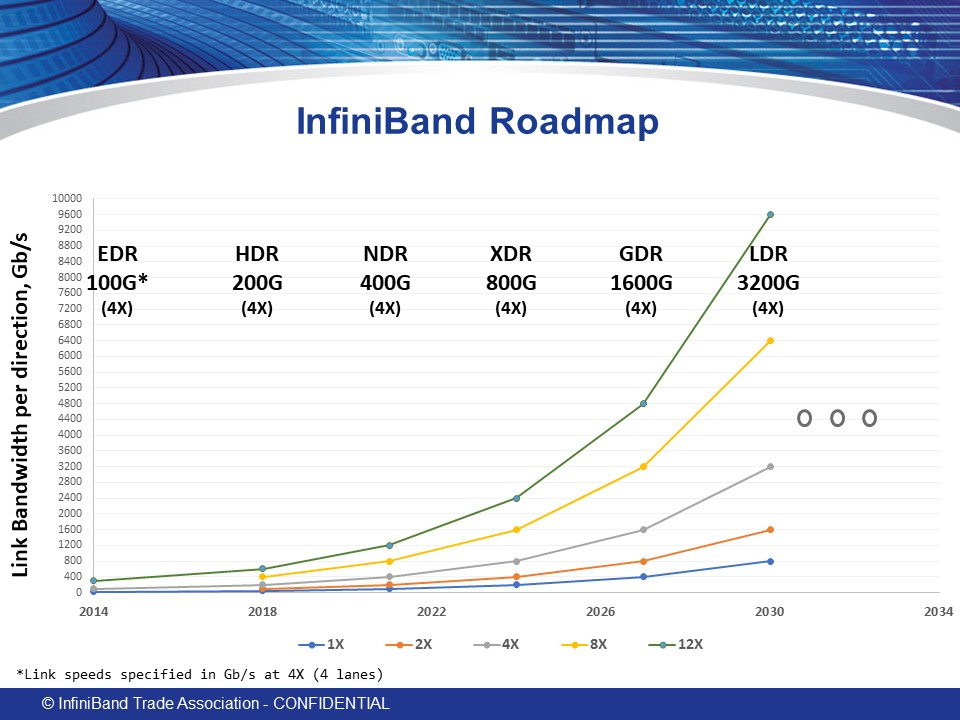
Текущие планы IBTA по развитиию InfiniBand. Источник: InfiniBand Trade Association Также тома содержат финальные спецификации физического уровня для InfiniBand NDR (100 Гбит/с на линию, 400 Гбит/с на порт). В данный момент полные тексты спецификаций доступны только для зарегистрированных пользователей на сайте IBTA. С кратким обзором Volume 1 Release 1.7 можно ознакомиться здесь. Помимо этого, в обновлениях описывается улучшенная поддержка крупных многопортовых коммутаторов (radix switches), а также механизмы, улучшающие обработку сетевых заторов (congestion control). Как отмечает IBTA, InfiniBand XDR должен стать новым золотым стандартом в среде ИИ и HPC благодаря оптимальному сочетанию высокой пропускной способности с низким уровнем задержек и энергоэффективностью. Дальнейшие планы IBTA включают освоение ещё более скоростных стандартов GDR и LDR к 2026 и 2030 гг. соответственно.
01.09.2023 [16:26], Алексей Степин
Cornelis Networks ускорит Omni-Path Express до 1,6 Тбит/сИнтерконнекту Omni-Path прочили в своё время светлое будущее, но в 2019 году компания Intel отказалась от своего детища и свернула поставки OPA-решений. Однако эстафету подхватила Cornelis Networks, так что технология не умерла — совсем недавно The Next Platform были опубликованы планы по дальнейшему развитию Omni-Path. В 2012 году Intel выкупила наработки по TruScale InfiniBand у QLogic, позднее дополнив их приобретением у Cray интерконнектов Gemini XT и Aries XC. Задачей было создание единого интерконнекта, могущего заменить PCIe, FC и Ethernet, а в основу была положена технология Performance Scale Messaging (PSM). PSM считалась более эффективной и пригодной в сравнении с verbs InfiniBand, однако самой технологии более 20 лет. В итоге Cornelis Networks отказалась от PSM и теперь развивает новый программный стек на базе libfabric. 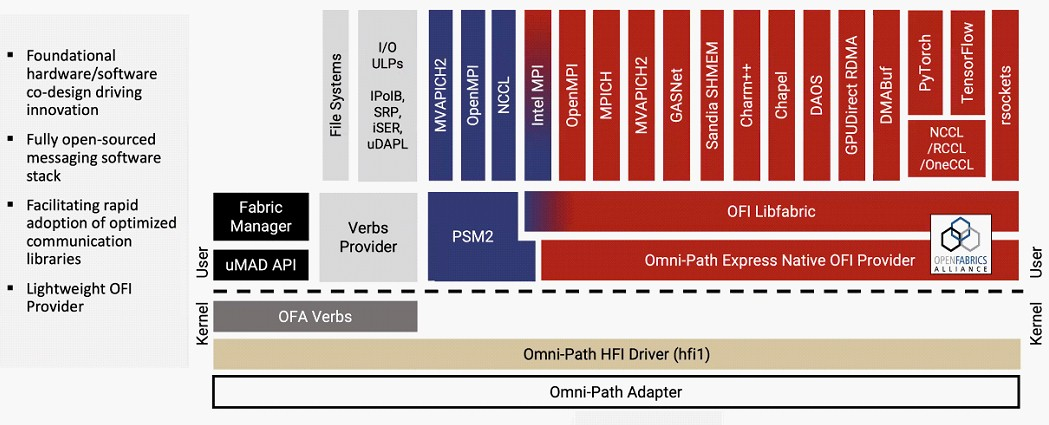
Источник изображений здесь и далее: Cornelis Networks (viaThe Next Platform) Уже первое поколение Omni-Path Express (OPX), работающее со скоростью 100 Гбит/с могло работать под управлением нового стека бок о бок с PSM2, а для актуальных 400G-продуктов Omni-Path Express CN5000 вариант OFI станет единственным. Скорее всего, в этом поколении будет также убрано всё, что работает на основе кода OFA Verbs. Останутся только части, выделенные на слайде выше красным. Как отмечает Cornelis Networks, главным отличием OPX от InfiniBand станет использование стека на базе полностью открытого кода с апстримом драйвера OFI в ядро Linux. 
Планы Cornelis Networks по развитию Omni-Path Планы компании простираются достаточно далеко: на 2024 год запланировано пятое поколение Omni-Path, включающее в себя не только адаптеры, но и необходимую инфраструктуру — 48-портовые коммутаторы и 576-портовые директоры. Предел масштабирования возрастёт практически на порядок, с 36,8 тыс. подключений для Omni-Path 100 до 330 тыс. Латентность при этом составит менее 1 мкс при потоке до 1,2 млрд сообщений в секунду. Появится поддержка топологий Dragonfly и Megafly, оптимизированных для применения в крупных HPC-системах, и динамическая адаптивная маршрутизация на базе данных телеметрии. 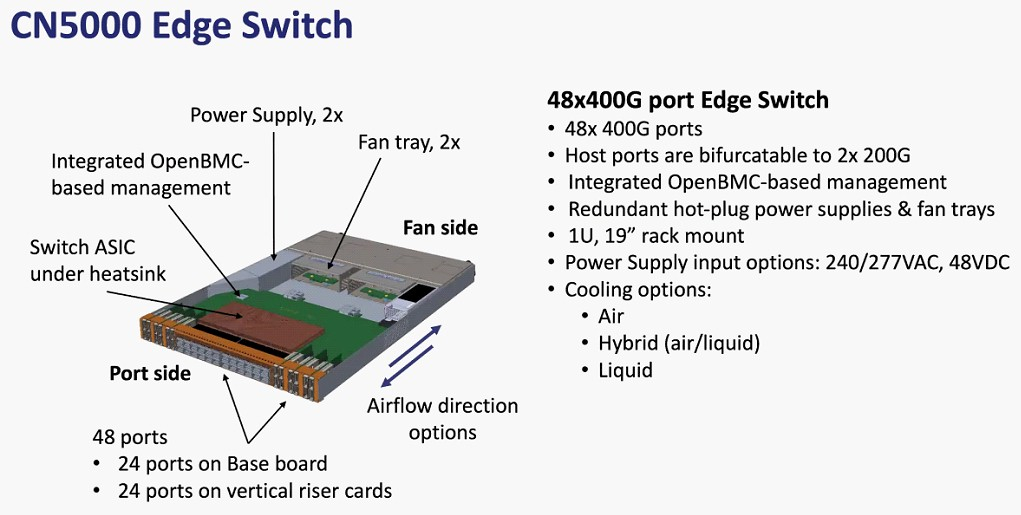 Характеристики и внутреннее устройство коммутаторов пятого поколения CN5000 компания публикует уже сейчас. Обычный периферийный коммутатор займёт высоту 1U, но при этом будет поддерживать как воздушное, так и жидкостное охлаждение, а модульный коммутатор класса director будет занимать 17U и получит внутренний интерконнект с топологией 2-tier Fat Tree. В нём будет предусмотрена горячая замена модулей и опция жидкостного охлаждения.  Базовый адаптер CN5000 выглядит как обычная плата расширения с интерфейсом PCIe 5.0 x16. Будут доступны варианты с одним и двумя портами 400G. Что интересно, опция жидкостного охлаждения предусмотрена и здесь. В 2026 году должно появиться шестое поколение решений Omni-Path CN6000 со скоростью 800 Гбит/с, включающее в себя не только базовые адаптеры и коммутаторы, но и первый в мире DPU для OPA, построенный на базе архитектуры RISC-V и поддерживающий CXL. Благодаря DPU будут реализованы более продвинутые опции разгрузки хост-системы и ускорения конкретных приложений. 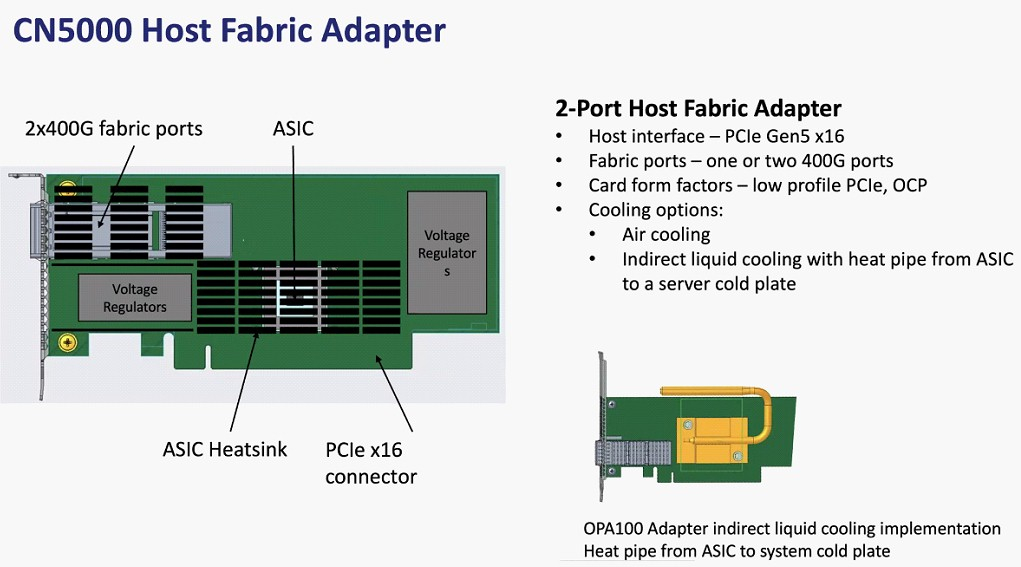 Наконец, в 2028 году в седьмом поколении CN7000 скоростной потолок поднимется с 800 до 1600 Гбит/с. Будет внедрена перспективная для крупномасштабных сетей поддержка топологии HyperX. Также ожидается появление чиплетов с интерфейсом UCIe и интегрированной фотоникой, что позволит интегрировать Omni-Path в решения сторонних производителей. Одной из главных целей Cornelis Networks, напомним, заявлено создание системы интерконнекта для суперкомпьютеров нового поколения экзафлопного класса. Разработка финансируется в рамках инициативы Exascale Computing Initiative (ECI). А первым суперкомпьютером, использующим Omni-Path пятого поколения (400G), станет техасский Stampede3.
25.08.2023 [18:57], Алексей Степин
Marvell представила высокоинтегрированные оптические модули COLORZ 800Производители сетевого оборудования продолжают активно осваивать скоростной диапазон 800 Гбит/с. Компания Marvell, как передаёт ServeTheHome, анонсировала оптические модули COLORZ 800 на базе нового 5-нм сигнального процессора Orion. Эти модули помогут объединить крупные, но разнесённые друг от друга ЦОД сетью класса 800G. Они подойдут как операторам, так и облакам. В основу новых модулей Marvell COLORZ 800 легли наработки, полученные компанией от приобретения активов Inphi Corporation в 2021 году, и главный результат этих наработок — новый сигнальный процессор (DSP) Marvell Orion. Он изначально рассчитан на работу в сетях класса 800G с интерфейсами OSFP-ZR/ZR+. Модули этого стандарта базируются на открытом стеке технологий OpenZR+. 
Источник изображений здесь и далее: Marvell (via ServeTheHome) Также в серии COLORZ 800 возросла мощность приёмопередатчиков, что позволило нарастить максимальную дистанцию установления связи до 2000 км. О скорости 800 Гбит/с на таком расстоянии речи, конечно же, не идёт — она составит 400 Гбит/с, а 600 Гбит/с можно будет достигнуть на дальности до 1200 км. Для устойчивого соединения 800 Гбит/с эта цифра скромнее и составляет 500 км. 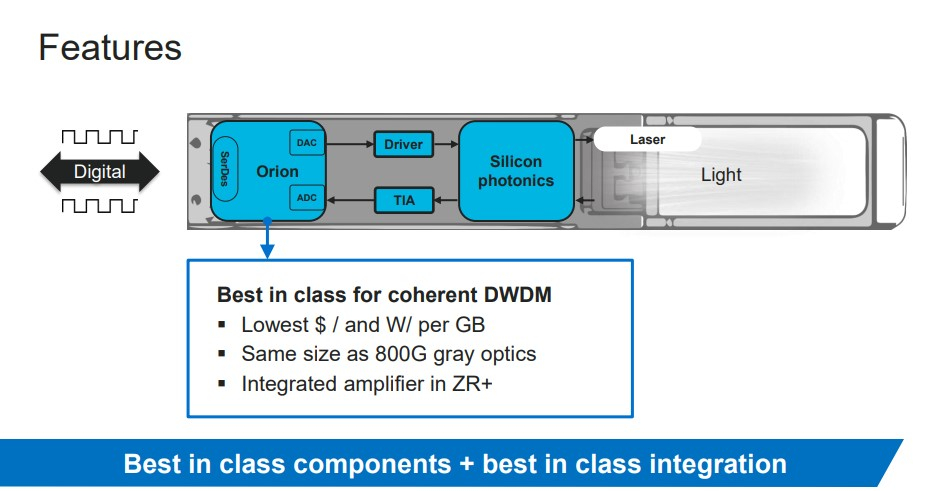 Как правило, для соединения крупных ЦОД используют не столь компактные и экономичные решения, но высокоинтегрированная платформа COLORZ 800 меняет правила игры. Компания будет предлагать новые модули в форм-факторах QSFP-DD и OSFP, однако платформа Orion также будет доступна и другим производителям оптических модулей. Первые поставки ожидаются в IV квартале.  По сути, новинка умещает целый комплекс аппаратуры в форм-факторе обычного подключаемого (pluggable) оптического модуля, что, по словам Marvell, позволяет сократить стоимость линка между ЦОД на 75 %. При этом COLORZ 800 вдвое быстрее даже на предельных дистанциях и на 30 % лучше в показателях стоимости передачи и энергопотребления на бит в сравнении с оборудованием предыдущего поколения.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
25.06.2023 [16:53], Алексей Степин
Cisco представила ASIC Silicon One G200: 51,2 Тбит/с для ИИКомпания Cisco успешно выпустила новые ASIC для сетевых коммутаторов с производительностью 51,2 Тбит/с. Как заявляют разработчики, коммутаторы на базе чипа серии G200 способны объединить в единый комплекс 32 тыс. ускорителей. Новое решение входит в портфолио Cisco Silicon One и изначально нацелено на рынок гиперскейлеров и создателей ИИ-кластеров. В новом чипе в два раза увеличено количество блоков SerDes с производительностью 112 Гбит/с (с 256 до 512), что и позволило довести общую коммутационную производительность до 51,2 Тбит/с. Доступны конфигурации 64×800GbE, 128×400GbE или 256×200GbE, всё зависит от желаемой плотности размещения и скорости портов. Это, в частности, позволяет избавиться от избыточных уровней в топологии сети. 
Источник изображений: Cisco Cisco отмечает, что новинка вдвое энергоэффективнее и имеет вдвое меньшую задержку в сравнении с G100. Кроме того, чипы предлагают расширенную телеметрию, поддержку языка P4 для обработки трафика на лету, а также возможность использования современных интерфейсов, в том числе интегрированную оптику или медные кабели длиной до 4 м, чего более чем достаточно для организации связи на уровне стойки. 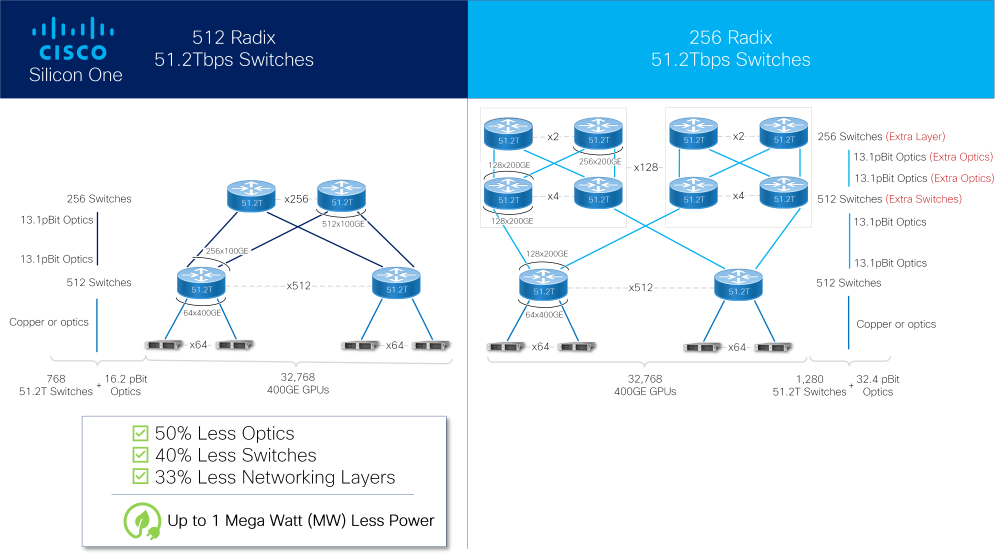 Как и Broadcom Tomahawk-5 или Jericho3-AI, Marvell Teralynx 10 и NVIDIA Spectrum-X, новый чип Cisco содержит возможности, востребованные в среде ИИ-систем, такие как продвинутые средства преодоления заторов в сети (congestion), технологии packet spraying и резервирование линков с возможностью мгновенного восстановления разорванного соединения. Новые чипы серии G200 уже поставляются, но компания пока не назвала даты появления на рынке коммутаторов Cisco на базе нового «кремния». |
|

