Материалы по тегу: gpu
|
16.04.2024 [15:17], Сергей Карасёв
Akamai запустила облако с ускорителями NVIDIA RTX для обработки видеоCDN-провайдер Akamai Technologies объявил о запуске нового облачного сервиса, оптимизированного для задач по обработке видеоматериалов. Услуга ориентирована прежде всего на компании в сфере медиа и развлечений, которым необходимы ресурсы для быстрого и эффективного создания контента. В основу системы положены ускорители NVIDIA RTX 4000 поколения Ada. Согласно результатам тестирования Akamai, использование этих GPU позволяет повысить производительность при кодировании и транскодировании видео примерно в 25 раз по сравнению с CPU. Akamai отмечает, что в настоящее время облачные инфраструктуры на базе ускорителей NVIDIA ориентированы в первую очередь на большие языковые модели (LLM) и приложения ИИ, тогда как медиасегменту уделяется недостаточное внимание. Новое облако как раз и призвано удовлетворить потребности заказчиков, которые работают с мультимедийным контентом, включая потоковое видео. Утверждается, что ускорители NVIDIA RTX 4000 обеспечивают скорость и энергоэффективность, необходимые для решения сложных творческих и инженерных задач по созданию цифрового контента, 3D-моделированию, рендерингу и пр. 
Источник изображения: NVIDIA Отмечается, что GPU-ускорители позволяют выполнять транскодирование видеоматериалов со скоростью, превышающей потребности сервисов реального времени: благодаря этому значительно улучшается качество потоковой передачи. Кроме того, может осуществляться одновременное кодирование и декодирование материалов. Новый облачный сервис также подходит для работы с приложениями виртуальной (VR) и дополненной (AR) реальности. Хотя Akamai оптимизировала платформу для медиарынка, она может применяться для анализа данных и научных вычислений, рендеринга графики, задач ИИ и машинного обучения, моделирования и других ресурсоёмких операций. При этом Akamai всё быстрее превращается в распределённого облачного провайдера, а не просто оператора CDN.
10.04.2024 [14:14], Сергей Карасёв
Intel представила видеокарты Arc для встраиваемых решенийКорпорация Intel анонсировала видеокарты серии Arc Aхx0E, предназначенные для применения в различных встраиваемых устройствах и системах небольшого форм-фактора. В общей сложности дебютировали шесть моделей: Arc A310E, Arc A350E, Arc A370E, Arc A380E, Arc A580E и Arc A750E. В основном это встраиваемые версии видеокарт, которые уже доступны на рынке. При этом изделия подверглись некоторым доработкам с учётом сферы их применения. Ускорители насчитывают от 6 до 28 ядер Xe. Количество исполнительных блоков варьируется от 96 до 448. Объём памяти GDDR6 у младших вариантов составляет 4 Гбайт, а пропускная способность памяти у версий начального уровня составляет 112 Гбайт/с. Для A380E указаны 6 Гбайт и 186 Гбайт/с. А вот для A580E и A750E параметры памяти не указаны. 
Источник изображения: Advantech Производительность INT8 варьируется от 49 до 235 TOPS. Быстродействие на операциях FP16 составляет от 24,6 до 117,6 Тфлопс, на операциях FP32 — от 3,1 до 14,7 Тфлопс. Говорится о совместимости с Windows 10/11, Windows 10 LTSC и Linux. 
Источник изображения: Intel В зависимости от модификации видеокарты Arc Aхx0E могут использоваться для решения таких задач, как распознавание лиц и речи, приложения ИИ, обработка медиаданных и пр. Поставки начнутся в текущем месяце. Решение будут доступны для заказа в течение пяти лет. 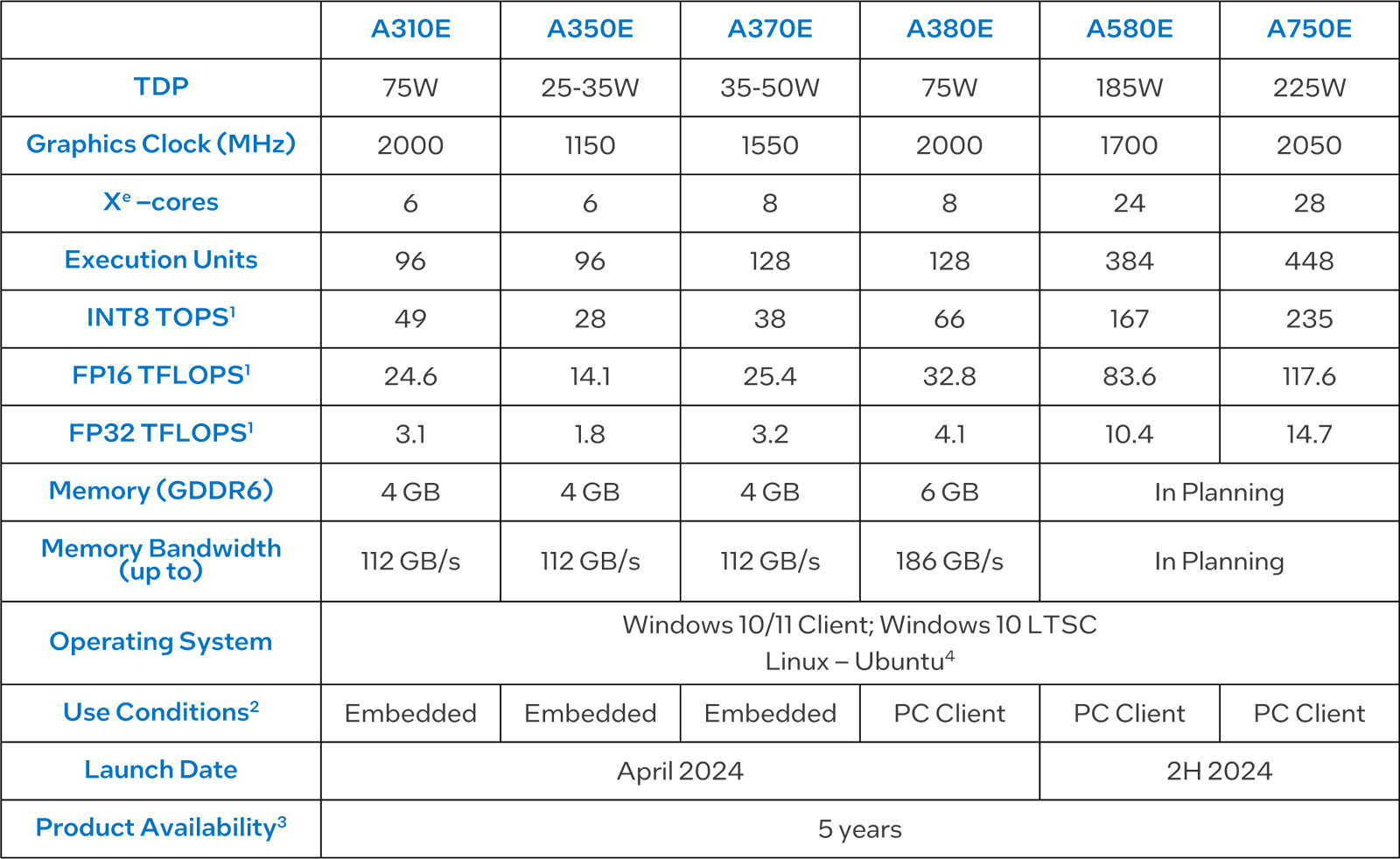
Источник изображения: Intel
05.04.2024 [20:53], Владимир Мироненко
В реестр Минпромторга включили первый отечественный ИИ-сервер с поддержкой нескольких ускорителейВ реестре радиоэлектронной продукции Минпромторга появился первый отечественный сервер для работы ИИ с поддержкой подключения нескольких ускорителей — Delta Sprut от ООО «Дельта компьютерс» (Delta Computers), позволяющий подключить до 16 ускорителей, пишет ресурс «Ведомости». С его помощью можно выполнять «тяжёлые» технические задачи, включая связанные с обучением генеративных ИИ-моделей, распознаванием и синтезом речи, работой цифровых ассистентов или распознаванием лиц в видеопотоке. Delta Sprut включили в реестр 22 февраля 2024 года. До этого в перечне были только серверы с возможностью подключения одного ускорителя для выполнения более простых задач, таких как рендеринг фото- и видеоизображений. Следует отметить, что несмотря на включение в отечественный реестр, серверы Delta используют иностранные ускорители — в стране аналогов пока нет. 
Источник изображения: Delta Computers В России разработкой серверов с возможностью подключения ускорителей также занимаются компании «Тринити» и Yadro, но это более простые и маломощные устройства, сообщил лидер по ИИ и управлению данными ФКУ «Гостех» Михаил Федоров. По его мнению, в числе потребителей модуля Delta Computers могут быть госструктуры, поскольку он технически аттестован для использования федеральными и региональными органами власти. Также его можно использовать на «ГосТехе» при построении информсистем. По словам представителя «ГосТеха», платформа пока не использует серверы с поддержкой ускорителей. В свою очередь, директор НОЦФНС России и МГТУ им. Н. Э. Баумана, эксперт рынка НТИ TechNet Алексей Бородулин отметил, что для дальнейшего развития «ГосТеха» потребуется большое количество ускорителей для решения высоконагруженных задач и распараллеливания вычислительных процессов. С 1 января 2024 г. на платформу «ГосТеха» перевели не только федеральные, но и региональные ведомства, в связи с чем назрела необходимость увеличения вычислительных мощностей.
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
15.03.2024 [22:50], Сергей Карасёв
Zotac анонсировала GPU-серверы с поддержкой до 10 ускорителейКомпания Zotac объявила о выходе на рынок оборудования корпоративного класса: дебютировали рабочие станции Bolt Tower Workstation башенного типа, а также стоечные GPU-серверы типоразмера 4U и 8U. Устройства рассчитаны на визуализацию данных, обучение ИИ-моделей, моделирование и пр. Новинки получили модульный дизайн, что облегчает замену или установку дополнительных компонентов. Говорится о поддержке различных дистрибутивов Linux корпоративного уровня, включая Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu. 
Источник изображений: Zotac Продукты разделены на три категории: Essential, Advanced и Premier. В первую входят башенные рабочие станции и серверы 4U, ориентированные на системных интеграторов и предприятия, которым требуется оборудование с оптимальным соотношением цены и производительности. Возможна установка процессоров Intel Xeon Sapphire Rapids и Xeon Emerald Rapids. Системы Bolt Tower Workstation могут нести на борту материнскую плату типоразмера ATX/E-ATX/Micro-ATX/EBB и два блока питания. Возможно развёртывание жидкостного охлаждения.  В серию Advanced включены 4U-серверы для более ресурсоёмких приложений. В зависимости от модификации допускается монтаж до 10 ускорителей. Поддерживаются модели в исполнении SXM/OAM. Подсистема питания может быть выполнена по схеме резервирования 4+1 или 2+2. Семейство Premier объединяет наиболее производительные серверы 4U и 8U для самых сложных рабочих нагрузок, таких как большие языковые модели (LLM) и облачный ИИ. Есть до 12 слотов PCIe для высокоскоростных сетевых карт (10 Гбит/с) или DPU. Для некоторых серверов возможно применение процессоров AMD.
12.01.2024 [13:21], Сергей Карасёв
GPU-сервер Gigabyte G493-SB0 на базе Emerald Rapids допускает установку восьми FHFL-ускорителейКомпания Gigabyte представила GPU-сервер G493-SB0, предназначенный для решения ресурсоёмких задач, таких как генеративный ИИ, виртуализация, рендеринг и 3D-графика. Система может нести на борту до восьми ускорителей формата FHFL с интерфейсом PCIe 5.0 x16. Применена материнская плата MSB3-G40 на наборе логики Intel C741. Есть возможность установки двух процессоров Intel Xeon Sapphire Rapids / Xeon Emerald Rapids с показателем TDP до 350 Вт. Для модулей DDR5-4800/5600 доступны 32 слота, а максимально поддерживаемый объём ОЗУ составляет 8 Тбайт. Сервер выполнен в формате 4U с габаритами 448 × 176 × 880 мм. Во фронтальной части расположены 12 отсеков для накопителей LFF/SFF в конфигурации 8 × NVMe/SATA и 4 × SATA. Возможно формирование массивов SATA RAID 0/1/10/5. Имеется коннектор для модуля М.2 2280/22110 с интерфейсом PCIe 3.0 x1. В оснащение входят контроллер Aspeed AST2600 и сетевой адаптер Intel X710-AT2, на базе которого реализованы два порта 10GbE. Есть выделенный сетевой порт управления. 
Источник изображения: Gigabyte Применена система воздушного охлаждения с 12 вентиляторами диаметром 60 мм (до 23 000 об/мин). Диапазон рабочих температур — от +10 до +35 °C. На фронтальную панель выведены три порта USB 3.2 Gen1, интерфейс D-Sub и гнезда RJ-45. Установлены четыре блока питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium.
27.12.2023 [18:48], Сергей Карасёв
До 16 GPU на один сервер: представлен российский OCP-модуль Delta SprutКомпания Delta Computers объявила о выпуске первой отечественной аппаратной OCP-платформы для ИИ-ускорителей — решения под названием Delta Sprut. Это специализированный модуль расширения (JBOG), допускающий подключение дополнительных PCIe-устройств к вычислительным узлам. Модуль Delta Sprut, выполненный в форм-факторе 2OU поддерживает интерфейс PCIe 4.0. Имеются четыре разъёма PCIe 4.0 x16 с возможностью установки четырёх карт HHHL или двух изделий FHFL мощностью до 350 Вт. Говорится о совместимости с вычислительными узлами Delta Tioga Pass и Delta Bright Lake. Допускается подключение к двум хостам. 
Источник изображений: Delta Computers Модуль Delta Sprut позволяет в режиме каскадирования подключать к одному вычислительному блоку до восьми GPU двойной или до 16 GPU стандартной высоты, что, как утверждается, устанавливает рекорд плотности в 160 GPU в одном OCP-шасси. В частности, могут быть задействованы ускорители NVIDIA А100 и NVIDIA H100, а также AMD Instinct. Для устройств NVIDIA поддерживается попарное объединение мостами NVLink.  Среди ключевых областей применения Delta Sprut названы системы ИИ и машинного обучения, платформы класса ChatGPT, HPC и 3D VDI. Имеется возможность расширения подсистемы хранения на базе Delta Argut — до 120 U.2-накопителей NVMe SSD. Модульная конструкция упрощает доступ ко всем его компонентам: для обслуживания не требуются инструменты. Ожидается, что в январе 2024 года Delta Sprut войдёт в реестр Минпромторга РФ.
29.11.2023 [09:09], Алексей Степин
Экологичные GPU-серверы: HOSTKEY развернула новую площадку в Исландии на базе «зелёного» ЦОД Verne GlobalКомпания HOSTKEY, оказывающая услуги по размещению, аренде и обслуживанию серверного оборудования, объявила о запуске новой хост-площадки, на этот раз не совсем обычной. Речь идёт о дата-центре Verne Global уровня Tier III в Исландии, полностью запитанному от возобновляемых источников энергии. Благодаря тому, что исландский ЦОД питается исключительно от ГЭС и геотермальных станций с низкой стоимостью электроэнергии, а относительно низкая «забортная» температура упрощает и удешевляет охлаждение, его можно назвать действительно «зелёным». Сочетание этих качеств позволяет без лишних затрат размещать в ЦОД мощные серверы, в том числе с ускорителями для ИИ и HPC-задач. Собственно говоря, именно это теперь и предлагает HOSTKEY, причём, как и прежде, она готова принимать оплату в рублях. Речь идёт о серверах — как выделенных (VDS), так и виртуальных (VPS) — с графическими ускорителями. В настоящее время сообщается только о решениях NVIDIA, но спектр доступных GPU достаточно широк — в него входят как игровые видеокарты GeForce RTX 3080/3090/4090, так и профессиональные RTX A4000/A5000/A6000. Некоторые конфигурации включают до четырёх GPU, в том числе с NVLink-подключением. 
Источник: Verne Global Объём оперативной памяти стартует с отметки 32 Гбайт (VPS) и может достигать 384 Гбайт (выделенный сервер), количество выделенных ядер в VPS-варианте — от 8. Все системы оснащены SSD, а в старших конфигурациях предлагаются NVMe-накопители. В зависимости от конфигурации в системе могут быть использованы процессоры Intel Core i9, AMD Ryzen или AMD EPYC. Доступны индивидуальные конфигурации, а выделенные серверы оснащены IPMI. 
Источник: Verne Global Кроме того, есть и традиционные VPS без ускорителей: 1–32 ядра (Intel Xeon E5-26xx или Cascade Lake-SP Refresh 6226R), 1–32 Гбайт RAM, 15–480 Гбайт SSD (в том числе NVMe). Время развёртывания для VPS, по словам HOSTKEY, начинается от 15 минут, а для выделенных вариантов со сложной конфигурации оно не превышает 4 часов. GPU-серверам по умолчанию полагается подключение 1 Гбит/с и 50 Тбайт трафика ежемесячно, а обычным VPS — такое же подключение, но только 3 Тбайт трафика. Как и во всех других регионах, в Исландии доступен маркетплейс, который позволяет быстро развернуть различное ПО. ЦОД Verne Global оснащён системой резервного питания по схеме N+1, предусмотрено двойное резервирование (2N) от источника питания до стойки. Также Verne Global говорит, что на площадке развёрнуты высокочувствительная система HSSD/VESDA с газовым тушением, система круглосуточного наблюдения и обнаружения вторжения, а также предусмотрен зональный контроль доступа. Кампус подключён к кабельным системам DANICE, FARICE-1, Greenland Connect, Hibernia Express, Iceland Connect и Sea-Me-We 5. Заявлена защита от DDoS-атак.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
09.06.2023 [22:52], Сергей Карасёв
Анонсирован китайский ускоритель Metax Xisi N100 для ИИ и потоковой обработки видеоКитайская компания Metax, по сообщению ресурса ITHome, разработала ускоритель Xisi N100, предназначенный для решения задач, связанных с обработкой видеоматериалов, алгоритмами ИИ и пр. Новинка уже готова к серийному производству и в скором времени поступит на местный рынок. Технических подробностей относительно Xisi N100 пока не слишком много. Известно, что основой ускорителя служит GPU с обозначением MXN100. Обеспечивается 128-канальное кодирование и 96-канальное декодирование. Заявлена поддержка форматов HEVC, H.264, AV1 и AVS2, а также разрешений вплоть до 8К. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe. Применено пассивное охлаждение. Заявленное быстродействие достигает 160 TOPS при вычислениях INT8 и 80 Тфлопс на операциях FP16. 
Источник изображений: ITHome Metax намерена в 2025 году выпустить GPU для игровых приложений. Чип получит поддержку всех основных методов рендеринга графики и сможет использовать современные API. Кроме того, Metax обещает предоставить оптимизированное ПО и необходимые драйверы: это, как ожидается, поможет в продвижении продукта на коммерческом рынке.  Разработка собственных GPU важна для Китая в условиях торговой войны с США. Из-за американских санкций NVIDIA прекратила поставки в Поднебесную ускорителей A100 и H100: компании пришлось выпустить экспортные варианты названных изделий, не подпадающие под ограничения. |
|

