Материалы по тегу: hpc
|
10.04.2024 [19:53], Руслан Авдеев
Индия и Евросоюз наконец договорились о развитии совместных HPC-проектовИндия и ЕС договорились о главных этапах совместного HPC-проекта, соглашение о реализации которого было заключено почти два года назад. Однако подвижки в этой сфере наметились только сейчас, когда Евросоюз начал недвусмысленно намекать, что пора бы взяться за дело, передаёт The Register. Соответствующий пакт был подписан в ноябре 2022 года. На тот момент Индия и ЕС намеревались углубить технологическое сотрудничество в квантовых вычислениях и HPC и обозначили основные цели, включая совместное продвижение исследований в области HPC-технологий. Правда, после этого долгое время практически ничего не происходило. В феврале 2024 года Евросоюз выпустил со своей стороны призыв к развитию сотрудничества в области HPC с Индией, оптимизации и совместной разработке HPC-приложений в сферах общего интереса, а также к обмену исследователями и инженерами между регионами. 
Источник изображения: Akash Choudhary/unsplash.com В Евросоюзе рассчитывают на:
При этом в документе не указывается, какими именно способами будут достигаться названные цели. Впрочем, у Индии уже есть соображения на этот счёт. Министерство электроники и информационных технологий страны призвало исследователей предложить варианты использования HPC для анализа климатических изменений, применения в биоинформатике, для борьбы со стихийными бедствиями вроде пожаров, цунами, оползнями и землетрясениями. Также в министерстве надеются получить предложения по разработке интегрированной системы раннего предупреждения для борьбы с «каскадными» эффектами комплексных угроз. Предложения должны уделять внимание оптимизации специализированных приложений и кодов, чёткому планированию работ, учёту KPI и демонстрации убедительных результатов выгоды от сотрудничества. Претендентам рекомендуется сосредоточиться на конкретных технических задачах. В заявке должен быть чётко оговорен вклад как индийских учёных, так и их коллег из Евросоюза. В заявке следует указать сферы и методики разработки, а также потенциальных пользователей готовых продуктов в Индии и ЕС. Одобренные предложения обеспечат возможность ускоренного доступа к HPC-мощностям как в Индии, так и в Евросоюзе. Индийская Суперкомпьютерная миссия (Supercomputing Mission) располагает 28 суперкомпьютерами, но из них только семь имеют производительность более 1 Пфлопс. В рамках EuroHPC уже развёрнуто восемь суперкомпьютеров, причём одна только система LUMI имеет производительность 386 Пфлопс. Ни в Индии, ни в Евросоюзе не сообщали, когда и как именно будут реализованы одобренные предложения учёных и специалистов.
09.04.2024 [12:45], Сергей Карасёв
Hyperion Research: спрос на облачные НРС-услуги будет быстро растиКомпания Hyperion Research, по сообщению ресурса HPC Wire, сделала прогноз по мировому рынку облачных HPC-решений. По мнению аналитиков, спрос на такие услуги в ближайшие годы будет быстро расти, что объясняется стремительным внедрением ИИ, генеративных сервисов и других современных решений. Говорится, что значение CAGR (среднегодовой темп роста в сложных процентах) на рынке облачных НРС-сервисов в перспективе пяти лет составит 18,1 %. При этом, как отмечается, данный показатель не в полной мере учитывает значительное влияние ИИ на увеличение спроса на технические вычисления в облаке. Аналитики отмечают, что обучение ИИ-моделей, имеющее большое значение, может быть отодвинуто на второй план из-за роста потребностей в инференсе. Дело в том, что обучение требует значительных вычислительных ресурсов, но на относительно небольшие периоды времени. Кроме того, обучение выполняет сравнительно небольшое количество пользователей. Вместе с тем инференс востребован среди широкого круга заказчиков для самых разных приложений. 
Источник изображения: pixabay.com В исследовании также говорится, что рост использования генеративного ИИ продолжится, тогда как его темпы внедрения стабилизируются. В сегменте больших языковых моделей (LLM) популярность начнут обретать фреймворки. В плане аппаратного обеспечения, как полагают аналитики Hyperion Research, резко возрастёт востребованность Arm-процессоров. В сегменте НРС выручка от Arm-систем в 2024 году поднимется в два раза по отношению к предыдущему году. Кроме того, ожидается рост популярности чипов с открытой архитектурой RISC-V. Прогнозируется также увеличение интереса к локальным квантовым компьютерам, которые будут дополнять квантовые вычисления через облако.
08.04.2024 [11:35], Сергей Карасёв
BSC и NVIDIA займутся совместной разработкой HPC- и ИИ-решенийБарселонский суперкомпьютерный центр (Centro Nacional de Supercomputación, BSC-CNS) и NVIDIA объявили о заключении многолетнего соглашения о сотрудничестве, целью которого является совместная разработка инновационных решений, объединяющих технологии НРС и ИИ. Договор рассчитан на пять лет с возможностью последующего продления. При этом каждые шесть месяцев стороны намерены уточнять и оптимизировать направления сотрудничества. Новое соглашение будет действовать параллельно с ранее подписанным документом, касающимся совместных исследований в области сетевых решений. Первоначально сотрудничество между BSC и NVIDIA будет сосредоточено на разработке больших языковых моделей (LLM), а также приложений для метеорологии и анализа изменений климата. Кроме того, стороны займутся адаптацией вычислительной модели цифрового двойника сердца, разработанной в рамках проекта Alya, к различным платформам. Ещё одно направление работ — программная оптимизация процессов для GPU и архитектуры NVIDIA Grace с ядрами Arm, специально разработанной для ИИ и крупномасштабных суперкомпьютерных приложений. 
Источник изображения: BSC Предполагается также, что научный потенциал BSC вкупе с технологическими достижениями и опытом NVIDIA позволят максимизировать вычислительные возможности суперкомпьютера MareNostrum 5, который был запущен в Испании в конце 2023 года. Эта система, использующая ускорители NVIDIA H100, обладает производительностью 314 Пфлопс.
05.04.2024 [14:30], Владимир Мироненко
Представлены российские HPC-узлы «РСК Экзастрим ИИ» с восемью ускорителями и фирменной СЖОГруппа компаний РСК представила модульное решение «РСК Экзастрим ИИ», предназначенное, как видно из названия, для развития ИИ-инфраструктуры в России. Новинка представляет собой серверный узел высотой 2U на базе Intel Xeon Sapphire Rapids, который включает до восьми ускорителей, например, NVIDIA H100. 32 слота DDR5 позволяют установить до 8 Тбайт RAM. В узел можно установить до восьми SSD в форм-факторе EDSFF E1.S общим объёмом до 20 Тбайт. Надлежащий температурный режим обеспечивает фирменная СЖО РСК с температурой хладоносителя +40–+50 °C. Спецификации устройства также включают до четырёх подключений Infiniband HDR/NDR, поддержку сети 10GbE и фирменный блок питания с жидкостным охлаждением. 
Источник изображений: РСК Пиковая производительность «РСК Экзастрим ИИ» при использовании ускорителей NVIDIA H100 составляет 208/408 Тфлопс (FP64/TF64). В универсальном шкафу «РСК Экзастрим» высотой 42U можно разместить до 21 вычислительного узла «РСК Экзастрим ИИ», благодаря чему суммарная пиковая производительного такой стойки составит 4,368/8,568 Пфлопс (FP64/TF64) при энергопотреблении всего 115 кВт.
30.03.2024 [13:56], Сергей Карасёв
Microsoft и OpenAI хотят создать ИИ ЦОД Stargate мощностью 5 ГВт за $100 млрдКомпании Microsoft и OpenAI, по сообщению ресурса The Information, обсуждают проект строительства масштабного кампуса ЦОД для решения самых сложных и ресурсоёмких задач в области ИИ. Проект получил кодовое название Stargate, а ввод комплекса в эксплуатацию состоится не ранее 2028 года. Скорее всего, речь всё же идёт о сети ЦОД, а не об одном-единственном объекте. По имеющимся сведениям, Microsoft и OpenAI реализуют комплексную программу по развитию ИИ-инфраструктуры, охватывающую период до 2030 года. Инициатива разделена на несколько этапов. В частности, в 2026-м должен быть запущен новый ИИ-суперкомпьютер, после чего планируется развернуть комплекс Stargate стоимостью около $100 млрд. Отмечается, что мощность объектов в составе Stargate может достигать суммарно 5 ГВт. Для их питания рассматриваются альтернативные источники, включая ядерную энергию. В январе нынешнего года стало известно, что Microsoft формирует команду для работы над малыми атомными реакторами. В свою очередь, глава OpenAI Сэм Альтман (Sam Altman) поддерживает компанию Oklo, которая занимается проектами в области атомной энергетики, в том числе для ЦОД. 
Источник изображения: Microsoft Архитектура Stargate пока не раскрывается. Могут быть задействованы ускорители NVIDIA или AMD следующего поколения или изделия собственной разработки. Ранее говорилось, что Microsoft и OpenAI создают свои ИИ-чипы с тем, чтобы уменьшить зависимость от продукции сторонних поставщиков. В частности, Microsoft уже представила фирменный ИИ-ускоритель Maia 100. Кроме того, редмондская корпорация проектирует DPU для ИИ-серверов. Вместе с тем OpenAI назначила бывшего руководителя Google TPU Ричарда Хо (Richard Ho) главой отдела аппаратного обеспечения. Помимо ИИ-чипов и сетевых компонентов, для проекта Stargate также потребуются серверные стойки высокой плотности, способные поддерживать большую мощность. Что касается ИИ-суперкомпьютера, который планируется запустить в 2026 году, то он расположится в Маунт Плезант (Висконсин, США). В 2023-м Microsoft начала здесь строительство ЦОД стоимостью $1 млрд. В совокупности все предстоящие проекты Microsoft и OpenAI могут стоить около $115 млрд.
29.03.2024 [21:54], Сергей Карасёв
Eviden увеличит производительность французского суперкомпьютера Jean Zay более чем втроеФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI) и Национальный центр научных исследований (CNRS) заключили соглашение с компанией Eviden (дочерняя структура Atos) о модернизации НРС-комплекса Jean Zay. Ожидается, что производительность этого суперкомпьютера увеличится приблизительно в 3,5 раза. В рамках проекта Eviden оборудует комплекс 1456 ускорителями NVIDIA H100 в дополнение к 416 ускорителям NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. Модернизация предполагает использование 14 стоек суперкомпьютерной платформы Eviden BullSequana XH3000. В общей сложности будут задействованы 364 двухпроцессорных узла на базе Intel Xeon Sapphire Rapids с 48 ядрами. Каждый сервер получит 512 Гбайт оперативной памяти и четыре ускорителя NVIDIA H100 SXM5. Говорится об использовании адаптеров NVIDIA ConnectX-7. 
Источник изображения: Eviden Проект также предусматривает комплексное обновление подсистемы хранения данных. Она будет состоять из флеш-массива вместимостью 4,3 Пбайт со скоростями чтения/записи свыше 1 Тбайт/с и дискового массива ёмкостью 39 Пбайт со скоростями чтения/записи более 300 Гбайт/с. Компоненты СХД поставит компания DataDirect Networks (DDN). Для обоих уровней хранения предусмотрено использование файловой системы Lustre. 
Фото: Photothèque CNRS/Cyril Frésillon Ожидается, что модернизация позволит увеличить пиковую производительность Jean Zay с 36,85 до 125,9 Пфлопс. Проект получил финансирование в рамках национальной инвестиционной программы «Франция 2030». Усовершенствованный суперкомпьютер будет использоваться для решения ресурсоёмких задач, в том числе в области ИИ. Отмечается, что Jean Zay — это один из наиболее экологичных суперкомпьютеров в Европе. Отчасти это достигается благодаря использованию генерируемого машиной тепла для обогрева более 1000 зданий в кампусе Париж-Сакле.
28.03.2024 [21:03], Руслан Авдеев
Nautilus запустила линейку инфраструктурных решений EcoCore для модульных ЦОДNautilus Data Technologies запустила новую серию решений для модульных дата-центров на основе разработанных ранее технологий охлаждения. По данным Datacenter Dynamics, новый проект предлагает варианты для ЦОД ёмкостью до 2,5 МВт. По словам Nautilus, EcoCore расширяет эффективность сборных конструкций и упрощает процесс строительства, позволяя интегрировать рабочее пространство с техническими помещениями и размещать MEP-компоненты (электрику, водоснабжение и вентиляцию) на крыше. Конструкция использует четыре CDU-установки для кондиционирования, каждая из которых способна отводить до 833 кВт тепла. Система поддерживает как традиционные варианты охлаждения, так и современные жидкостные. Основной модуль электропитания (PEU) обеспечивает мощность 1250 кВт (415 В, три фазы), но есть и точно такой же резервный (N+1). Новинка будет развёрнута в Start Campus в Синише (Португалия) — впервые за пределами собственных мощностей Nautilus. EcoCore, по словам компании, соответствует запросам Start по организации бесперебойной работы серверов высокой плотности с СЖО. Компании договорились о сотрудничестве в прошлом году и заключили «многомегаваттное» соглашение. Первый модуль EcoCore будет развёрнут в ходе первой фазы строительства кампуса Start. В Nautilus и Start заявляют, что экобезопасные технологии первой задают новый стандарт в индустрии, обеспечивая непревзойдённые эффективность и адаптивность. 
Источник изображения: Nautilus Nautilus известна прежде всего проектами плавучих ЦОД и системой охлаждения дата-центров речной или морской водой. Пока компания выступает лишь оператором ЦОД-баржи в Стоктоне (Калифорния), но планирует построить и наземный объект в Мэне. Также в работе находятся и другие проекты в США, Франции и Ирландии. Меморандумы о взаимопонимании заключены в Таиланде и на Филиппинах. Впрочем, появление EcoCore, похоже, указывает на желание стать поставщиком решений для других операторов. Принадлежащая инвестиционному фонду Davidson Kempner и британской British Pioneer Point Partners компания Start намерена построить 495-МВт кампус площадью 60 га в Португалии. Компании заявили, что Nautilus поставит охладительные системы и для второй фазы проекта, предусматривающего расширение на 120 МВт. Ранее Start оказалась вовлечена в коррупционный скандал.
28.03.2024 [14:43], Сергей Карасёв
DDN создала хранилище с быстродействием 4 Тбайт/с для ИИ-суперкомпьютера NVIDIA EOSКомпания DataDirect Networks (DDN), специализирующаяся на платформах хранения данных для НРС-задач, сообщила о создании высокопроизводительного хранилища на базе DDN EXAScaler AI (A3I — Accelerated, Any-Scale AI) для ИИ-суперкомпьютера NVIDIA EOS производительностью 18,4 Эфлопс (FP8). Речь идёт о кластере, объединяющем 576 систем NVIDIA DGX H100. Компания DDN заявляет, что разработала для NVIDIA EOS систему хранения с высокими показателями быстродействия и энергетической эффективности. Объединены 48 устройств A3I, которые сообща занимают менее трёх серверных стоек. Потребляемая мощность заявлена на отметке 100 кВт. 
Источник изображения: DDN Задействованы 250-Тбайт массивы NVMe-накопителей. Суммарная ёмкость СХД составляет 12 Пбайт. Общая пропускная способность, по заявлениям разработчика, достигает 4 Тбайт/с. Таким образом, система способна справляться с самыми ресурсоёмкими рабочими нагрузками ИИ, большими языковыми моделями, комплексным моделированием и пр. «Наша цель — обеспечение максимальной эффективности всей платформы, а не просто предоставление эффективного хранилища. Благодаря интеграции с суперкомпьютером NVIDIA EOS наше решение демонстрирует способность сократить время окупаемости при одновременном снижении рисков как для локальных, так и для облачных партнёров», — говорит президент и соучредитель DDN.
27.03.2024 [22:34], Сергей Карасёв
Lenovo создаст для Великобритании ИИ-суперкомпьютер производительностью 44,7 ПфлопсСовет по науке и технологиям Великобритании (STFC), по сообщению The Register, заключил с Lenovo соглашение о создании нового НРС-комплекса, ориентированного на решение задач в области ИИ. Речь идёт о суперкомпьютере с жидкостным охлаждением, производительность которого составит приблизительно 44,7 Пфлопс (точность вычислений не уточняется). Система будет смонтирована в принадлежащем STFC Вычислительном центре имени Хартри в Дарсбери (графство Чешир). Ожидается, что по быстродействию новый комплекс примерно в 10 раз превзойдёт нынешнюю НРС-систему центра под названием Scafell Pike. 
Источник изображения: Lenovo В основу суперкомпьютера лягут серверы Lenovo ThinkSystem с технологией прямого водяного охлаждения (DWC) Neptune. Применение СЖО, как ожидается, поможет снизить потребление энергии примерно на 40 % по сравнению с воздушным охлаждением и дополнительно повысить производительность на 10 %. Технические характеристики будущего суперкомпьютера не раскрываются, но известно, что он будет использовать узлы с ускорителями на базе GPU. Технология Neptune, в частности, применяется в серверах ThinkSystem SD650-N V3, которые комплектуются процессорами Intel Xeon Emerald Rapids и ускорителями NVIDIA HGX H100 (SXM). Ожидается, что новый суперкомпьютер, который пока не получил имя, будет применяться для решения сложных задач, связанных с ИИ. Это моделирование погоды и глобальных изменений климата, инициативы в области чистой энергетики, разработка передовых лекарственных препаратов, новые материалы, автомобильные технологии и пр. Система Lenovo станет частью программы Национального центра цифровых инноваций Хартри (HNCDI) стоимостью около $265 млн, которая предполагает поддержку предприятий и организаций государственного сектора, внедряющих средства ИИ.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 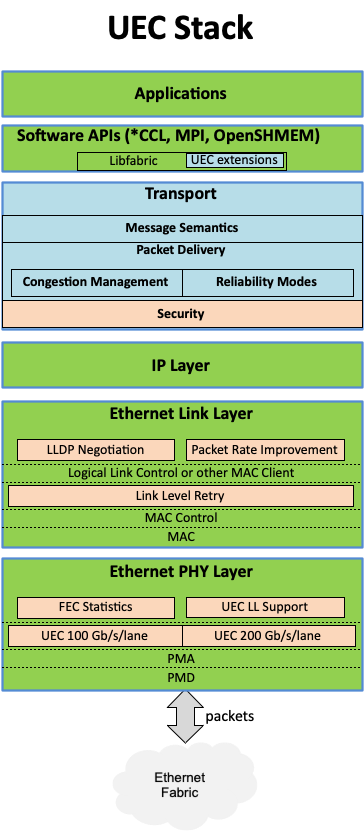
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 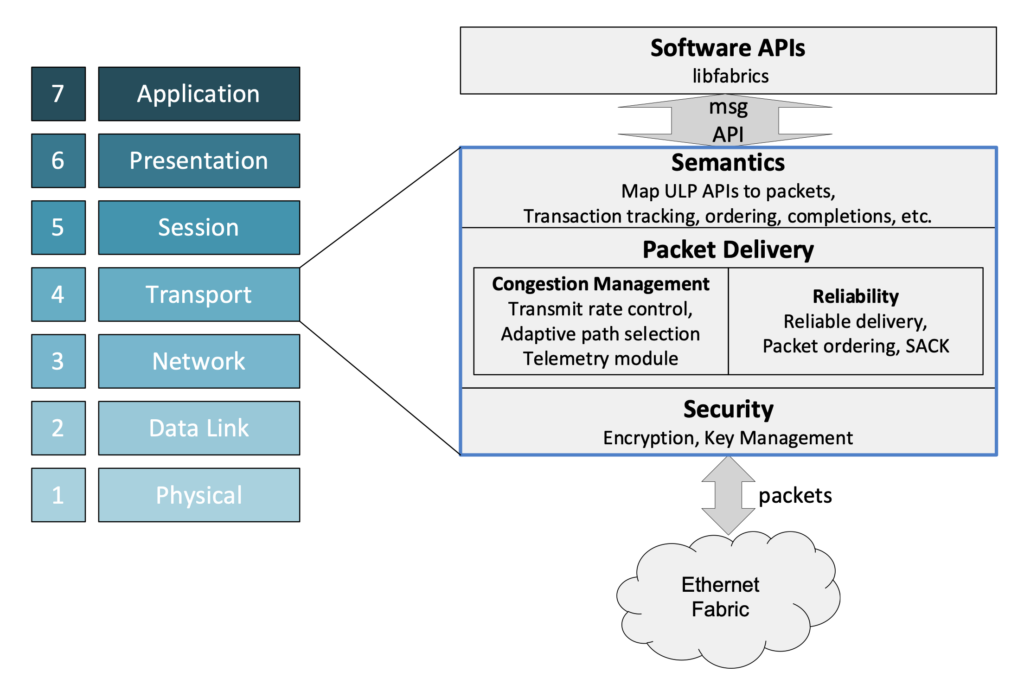
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы. |
|

