Материалы по тегу: h200
|
02.11.2023 [21:49], Руслан Авдеев
Британия получит 200-Пфлопс ИИ-суперкомпьютер Isambard-AI на гибридных Arm-чипах NVIDIA GH200Правительство Великобритании о выделении £225 млн ($273 млн) на строительство самого мощного в стране суперкомпьютера Isambard производительностью более 200 Пфлопс в FP64-вычислениях и более 21 Эфлопс в ИИ-задачах. Как сообщает The Register, новая машина на базе тысяч гибридных Arm-суперчипов NVIDIA Grace Hopper (GH200) разместится в Бристольском университете и будет построена HPE. Ожидается, что машина будет введена в эксплуатацию в следующем году и поможет в выполнении самых разных задач, от автоматизированной разработки лекарств до анализа климатических изменений, от изучения и внедрения нейросетей в робототехнике до задач, связанных с обеспечением национальной безопасности и обработкой больших данных. Isambard-AI войдёт в десятку самых быстрых суперкомпьютеров мира. Пока что самый быстрый суперкомпьютер Великобритании — это 20-Пфлопс система Archer2, занимающая 30-ю позицию в рейтинге TOP500 и введённая в строй всего пару лет назад. Isambard-AI получит 5448 гибридных чипов NVIDIA GH200 GraceHopper с 96/144 Гбайт HBM-памяти. Используется платформа HPE Cray EX с интерконнектом Slingshot 11 и СЖО. 25-Пбайт хранилище использует СХД Cray ClusterStor E1000. Система будет размещена в ЦОД с автономным охлаждением, а система утилизации избыточного тепла позволит обогревать близлежащие здания. Первыми выгодоприобретателями проекта Isambard-AI станут команды Frontier AI Task Force и AI Safety Institute, намеренные смягчить угрозу со стороны ИИ национальной безопасности Великобритании. 
Изображение: HPE Компанию Isambard-AI составит ранее анонсированный Arm-суперкомпьютер Isambard-3, который также построит HPE. Эту машину введут в эксплуатацию следующей весной, она обеспечит британским учёным ранний доступ к вычислительным мощностям на первом этапе реализации проекта Isambard-AI. Isambard-3 получит 384 суперчипа NVIDIA Grace, а его пиковое быстродействие в FP64-вычислениях составит 2,7 Пфлопс. Всего в различные ИИ-проекты британские власти вложат порядка £900 млн ($1,1 млрд). В частности, вместе с Isambard-AI был объявлен и суперкомпьютер Dawn, который разместится в Кембридже. Хотя ранее NVIDIA описывала Isambard-AI как самый быстрый в стране, создатели Dawn утверждают, что быстрейшим будет именно он. Система будет полагаться на серверы Dell PowerEdge XE9640 с процессорами Sapphire Rapids и ускорителями Max.
19.10.2023 [21:34], Сергей Карасёв
Supermicro выпустила первые в отрасли ИИ-системы NVIDIA MGX на базе гибридных суперчипов GH200 Grace HopperКомпания Supermicro сообщила о начале поставок первых в отрасли серверов на базе суперчипа NVIDIA GH200 Grace Hopper, предназначенных для поддержания ресурсоёмких нагрузок ИИ. Дебютировали стоечные решения в форм-факторах 1U и 2U с воздушным и жидкостным охлаждением. Серверы используют модульную платформу NVIDIA MGX, которая специально разработана для упрощения создания ИИ-систем. Разработчики на этапе проектирования выбирают базовую архитектуру для шасси, после чего добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. В общей сложности выпущены шесть систем (см. характеристики в таблицах ниже). Все они допускают установку накопителей стандарта E1.S с возможностью горячей замены и SSD формата M.2. Есть слоты PCIe 5.0 x16 с поддержкой NVIDIA BlueField-3 и ConnectX-7. Питание обеспечивают два или три блока мощностью 2000 или 2700 Вт. 
Источник изображений: Supermicro В список анонсированных серверов входят:

 Supermicro отмечает, что заказчики могут использовать новые серверы в комплексе с софтом NVIDIA, включая NVIDIA AI Enterprise, для решения разнообразных задач в области генеративного ИИ, компьютерного зрения, речевых приложений и машинного обучения. А набор NVIDIA HPC SDK содержит компиляторы, библиотеки и программные инструменты, необходимые для организации высокопроизводительных вычислений.
10.10.2023 [23:20], Сергей Карасёв
NVIDIA выпустит ускорители GB200 и GX200 в 2024–2025 гг.Компания NVIDIA, по сообщению ресурса VideoCardz, раскрыла планы по выпуску ускорителей нового поколения, предназначенных для применения в ЦОД и на площадках гиперскейлеров. NVIDIA указывает лишь ориентировочные сроки выхода решений, поскольку фактические даты зависят от многих факторов, таких как макроэкономическая обстановка, готовность сопутствующего ПО, доступность производственных мощностей и пр. В конце мая нынешнего года NVIDIA объявила о начале массового производства суперчипов Grace Hopper GH200, предназначенных для построения НРС-систем и платформ генеративного ИИ. Эти изделия содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100 с 96 Гбайт памяти HBM3. Как сообщается, ориентировочно в конце 2024-го или в начале 2025 года на смену Grace Hopper GH200 придет решение Blackwell GB200. Характеристики изделия пока не раскрываются. Но отмечается, что архитектура Blackwell будет применяться как в ускорителях для дата-центров, так и в потребительских продуктах для игровых компьютеров (предположительно, серии GeForce RTX 50). На 2025 год, согласно обнародованному графику, намечен анонс загадочной архитектуры «Х». Речь, в частности, идёт о решении с обозначением GX200. Изделия GB200 и GX200 подойдут для решения задач инференса и обучения моделей. Примечательно, что старшие чипы также получат NVL-версии. Вероятно, вариант GH200 с увеличенным объёмом набортной памяти как раз и будет называться GH200NVL. 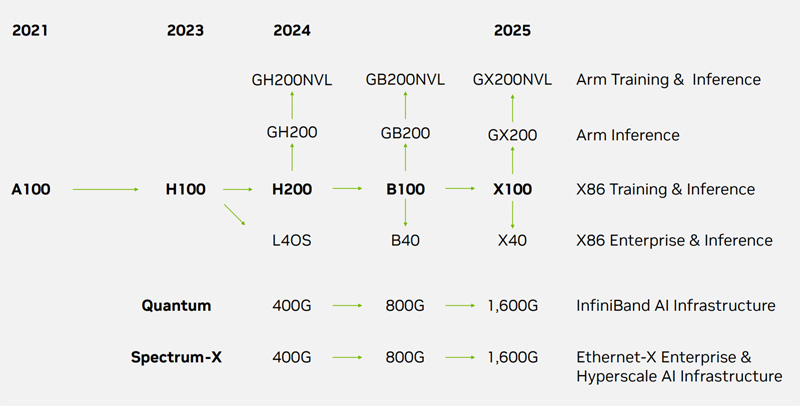
Источник изображения: NVIDIA При этом теперь компания разделяет продукты на Arm- и x86-направления. Первое, судя по всему, так и будет включать гибридные решения GB200 и GX200, а второе, вероятно, вберёт в себя в первую очередь ускорители в форм-факторе PCIe-карт и универсальные ускорители начального уровня серии 40: B40 и X40. Сопутствовать новым чипам будут сетевые решения Quantum (InfiniBand XDR/GDR) и Spectrum-X (Ethernet) классов 800G и 1600G (1.6T). И если в области InfiniBand компания фактически является монополистом, то в Ethernet-сегменте она несколько отстаёт от, например, Broadcom, у которой теперь есть даже выделенные ИИ-решения, Cisco и Marvell. А вот про будущее NVLink компания пока ничего не рассказала.
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 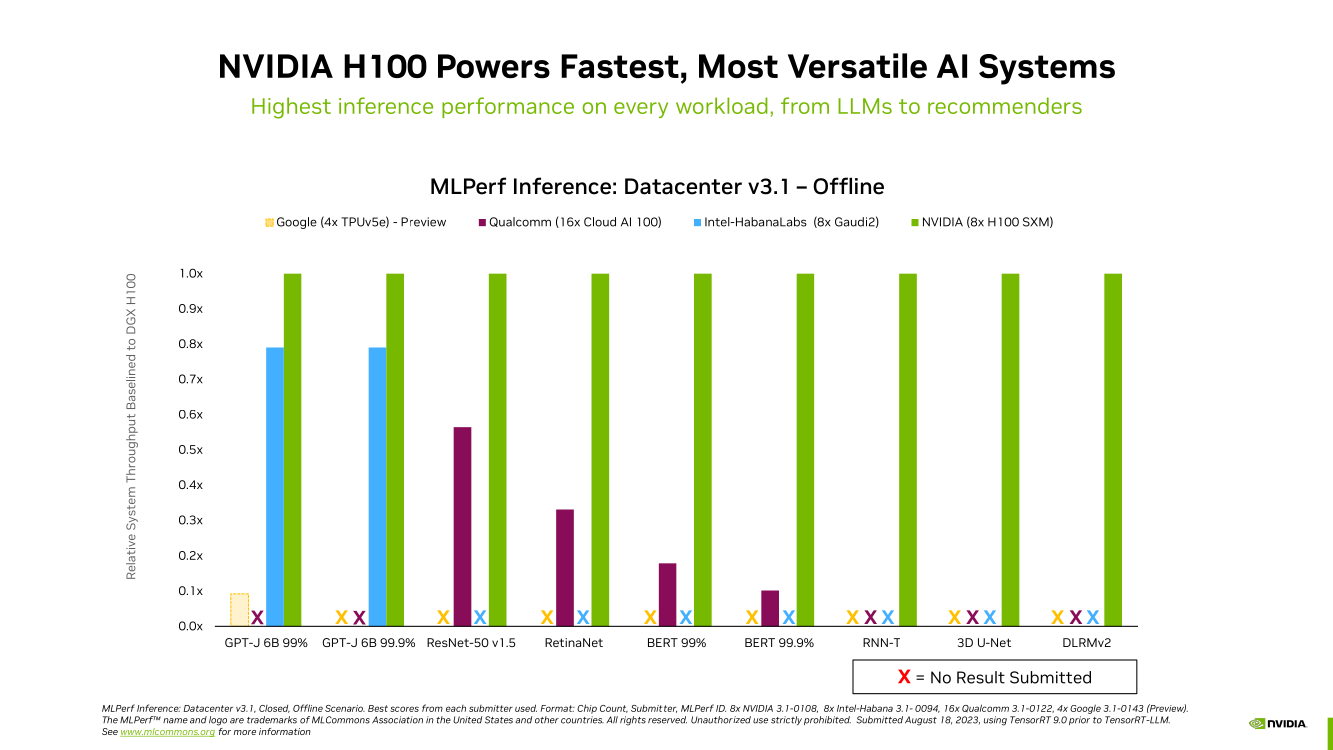 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU. 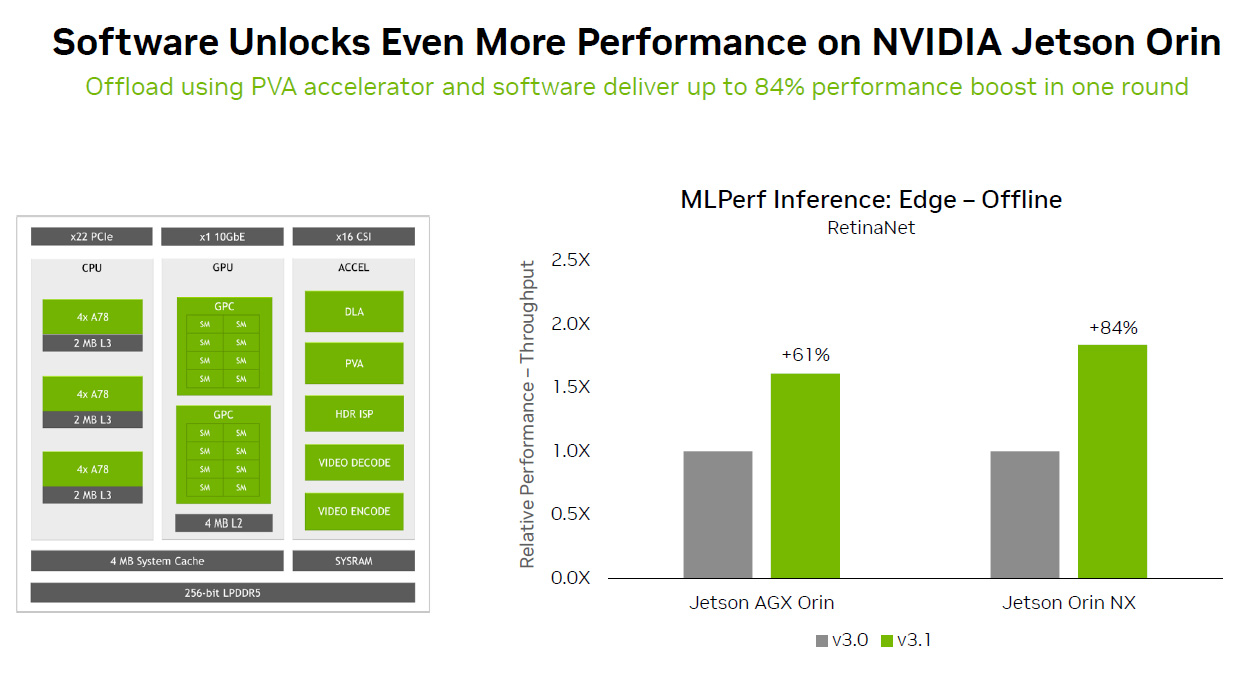 Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
09.09.2023 [11:27], Сергей Карасёв
NVIDIA и индийская Tata развернут масштабную ИИ-инфраструктуруКомпания NVIDIA и индийский транснациональный конгломерат Tata Group объявили о заключении расширенного соглашения о сотрудничестве, в рамках которого планируется создание масштабной инфраструктуры и платформ для реализации проектов в области ИИ. Говорится, что благодаря партнёрству тысячи организаций, предприятий и научных коллективов, а также сотни стартапов в Индии получат доступ к передовым ресурсам для создания ИИ-приложений. Проектом предусмотрено развёртывание НРС-системы на основе суперчипов NVIDIA GH200 Grace Hopper. Речь идёт о создании в Индии облачной инфраструктуры, использующей глобальную сеть Tata Communications для обеспечения высокоскоростной передачи данных. Платформа позволит решать ресурсоёмкие задачи в области генеративного ИИ и больших языковых моделей. Похожий проект реализуется и с Reliance. 
Источник изображения: NVIDIA Новую систему, в частности, намерена применять компания Tata Consultancy Services (TCS), предоставляющая услуги в области IT и консалтинга. На базе готовящейся облачной среды TCS планирует разворачивать приложения генеративного ИИ. Сотрудничество с NVIDIA, как ожидается, поможет TCS повысить квалификацию своих сотрудников, штат которых насчитывает около 600 тыс. человек. В целом, партнёрство будет способствовать ИИ-трансформации различных компаний в составе Tata Group — от производства до потребительского бизнеса.
09.09.2023 [11:27], Сергей Карасёв
NVIDIA и Reliance создадут большую языковую модель для Индии и развернут ИИ-инфраструктуру мощностью до 2 ГВтКомпании NVIDIA и Reliance Industries сообщили о заключении соглашения о сотрудничестве, которое предусматривает разработку большой языковой модели для Индии. Она будет обучена на различных языках страны и адаптирована для приложений генеративного ИИ. Кроме того, будет построена отдельная ИИ-инфраструктура мощностью до 2000 МВт. Внедрением системы займутся специалисты компании Jio. Партнёры намерены развернуть аппаратную ИИ-инфраструктуру, которая по производительности более чем на порядок превзойдёт самый мощный суперкомпьютер Индии. Для этого планируется задействовать суперчипы NVIDIA GH200 Grace Hopper, а также облачный сервис DGX Cloud. Говорится, что платформа NVIDIA станет основой ИИ-вычислений для Reliance Jio Infocomm, телекоммуникационного подразделения Reliance Industries. В рамках партнёрства Reliance будет создавать приложения и услуги на основе ИИ для примерно 450 млн клиентов Jio, а также предоставит энергоэффективную ИИ-инфраструктуру учёным, разработчикам и стартапам по всей Индии. 
Источник изображения: Reliance Industries Применять ИИ планируется в самых разных отраслях — в сельском хозяйстве, медицине, климатологии и пр. В частности, приложения нового типа помогут предсказывать циклонические штормы, а также улучшат экспертную диагностику симптомов тех или иных заболеваний. Похожий проект реализуется и с Tata Group.
08.08.2023 [23:15], Игорь Осколков
NVIDIA представила обновлённый вариант гибридного ускорителя GH200 с 141 Гбайт памяти HBM3eВсего два с небольшим месяца назад NVIDIA объявила о начале массового производства гибридных суперчипов Grace Hopper GH200 и анонсировала 1-Эфлопс ИИ-суперкомпьютер на их основе. Первые решения на базе этих чипов станут доступны до конца текущего года, а уже во II квартале 2024 года появится новая версия Grace Hopper, которая получит 141 Гбайт набортной памяти HBM3e. В этом и заключается их отличие от оригинальных GH200, которые оснащаются 96 Гбайт HBM3. Помимо увеличения объёма памяти выросла и её пропускная способность, с 4 до 5 Тбайт/с. Ну и если заявленный объём LPDDR5x в 500 Гбайт не является округлением исходных 480 Гбайт, то и здесь тоже есть небольшой прирост. При этом производительность новой версии осталась на прежнем уровне — 4 Пфлопс с Transformer Engine (без явного указания точности вычислений). Тем не менее, прирост ПСП и объёма памяти положительно скажется как на процессе обучения ИИ-моделей, так и, что особенно важно, на инференсе. 
Изображение: NVIDIA Прочие технические характеристики новинок компания пока не раскрыла, но сообщила о сохранении совместимости с платформой NVIDIA MGX и возможности объединения множества суперчипов и узлов посредством NVLink. Новинке придётся соревноваться с ускорителями AMD Instinct MI300A, которые должны появиться на рынке чуть раньше.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 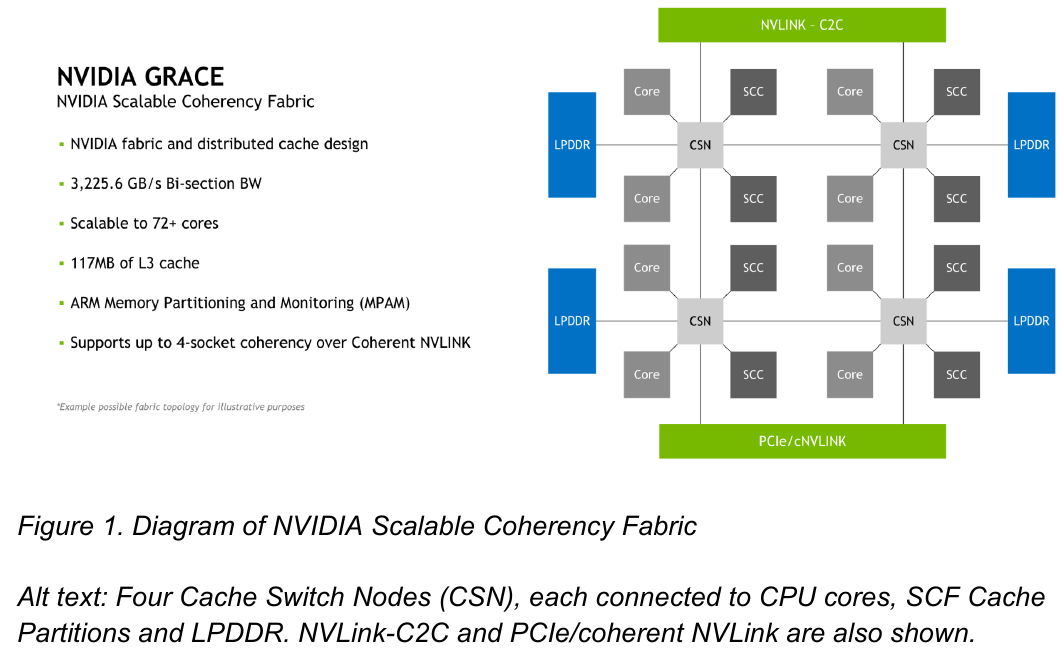
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 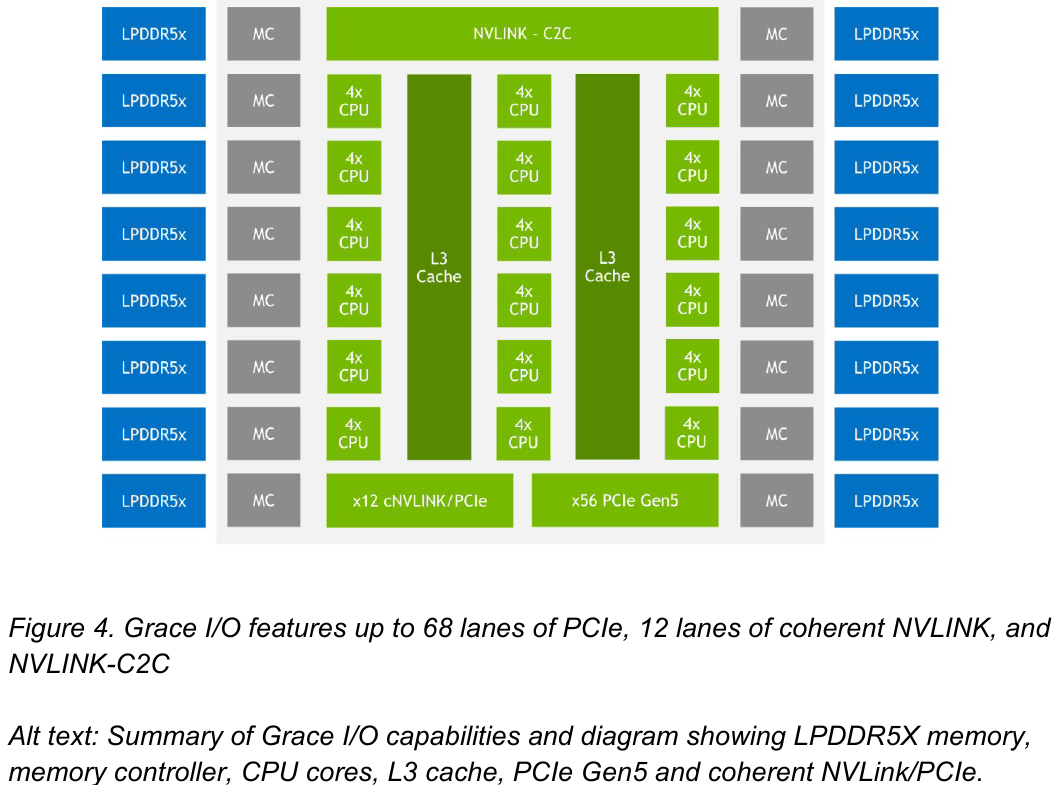
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 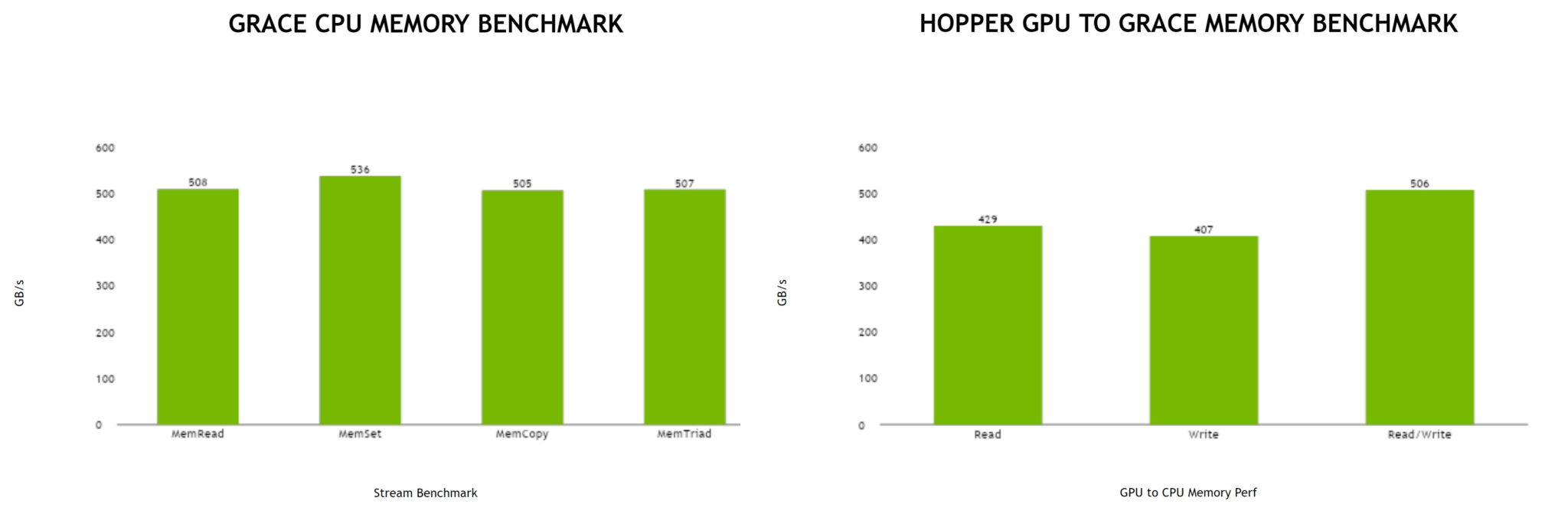
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 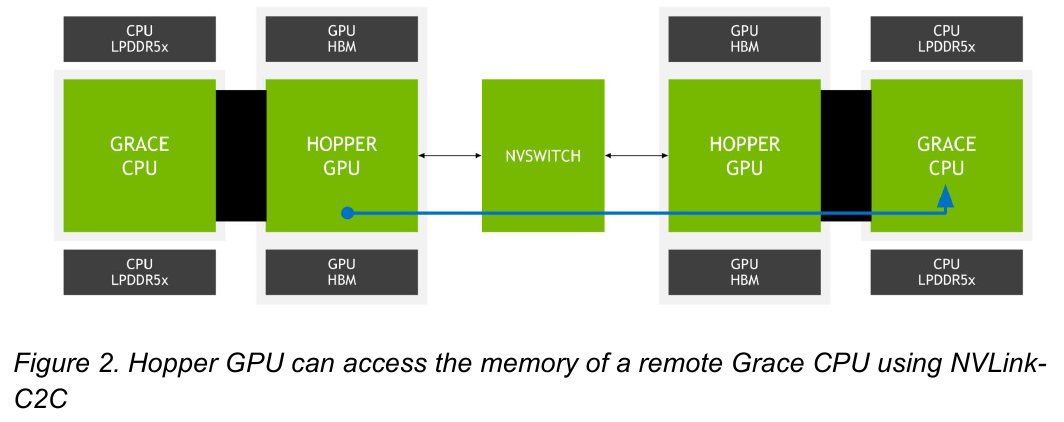
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 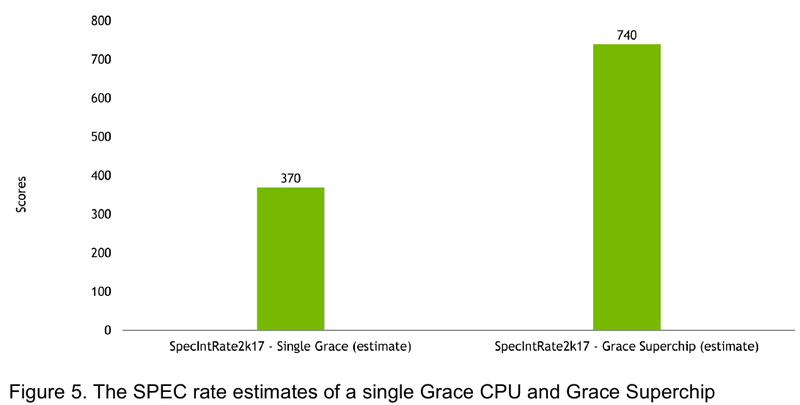
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 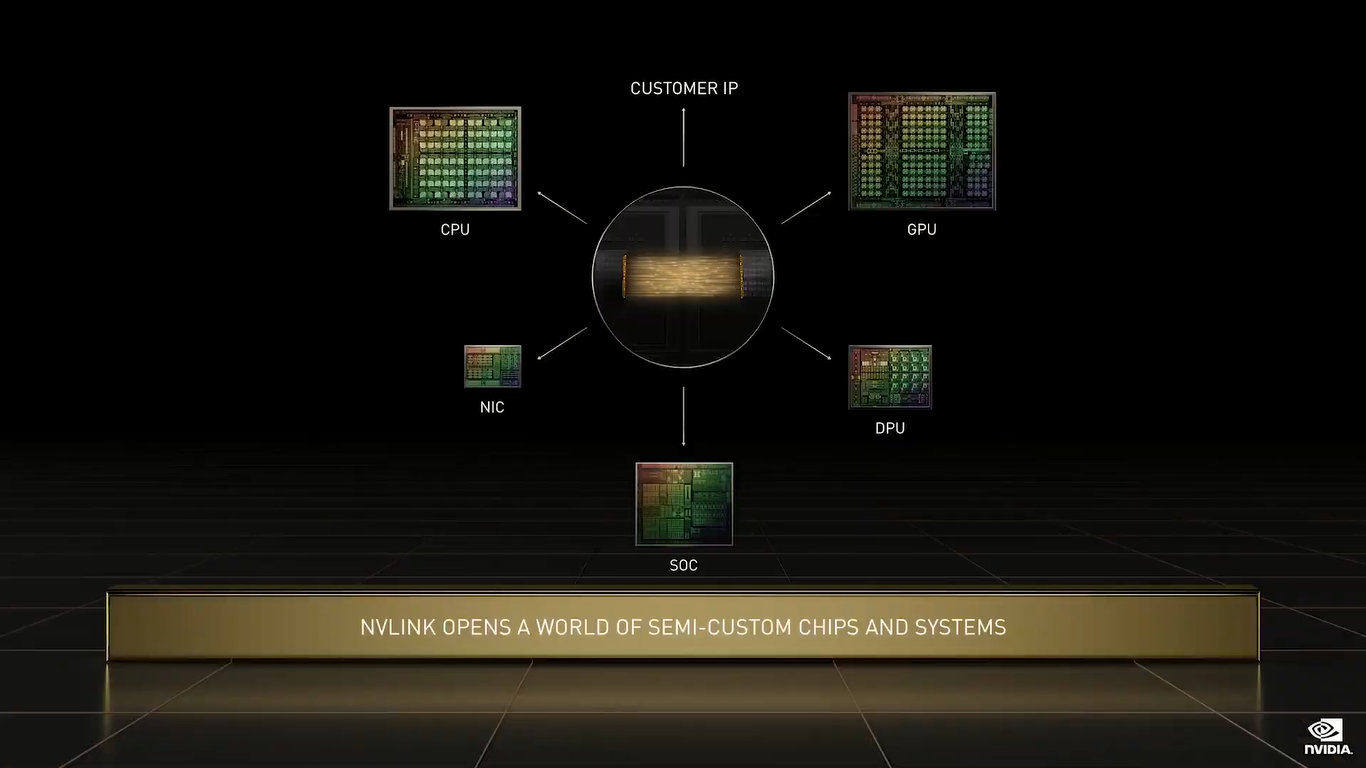 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 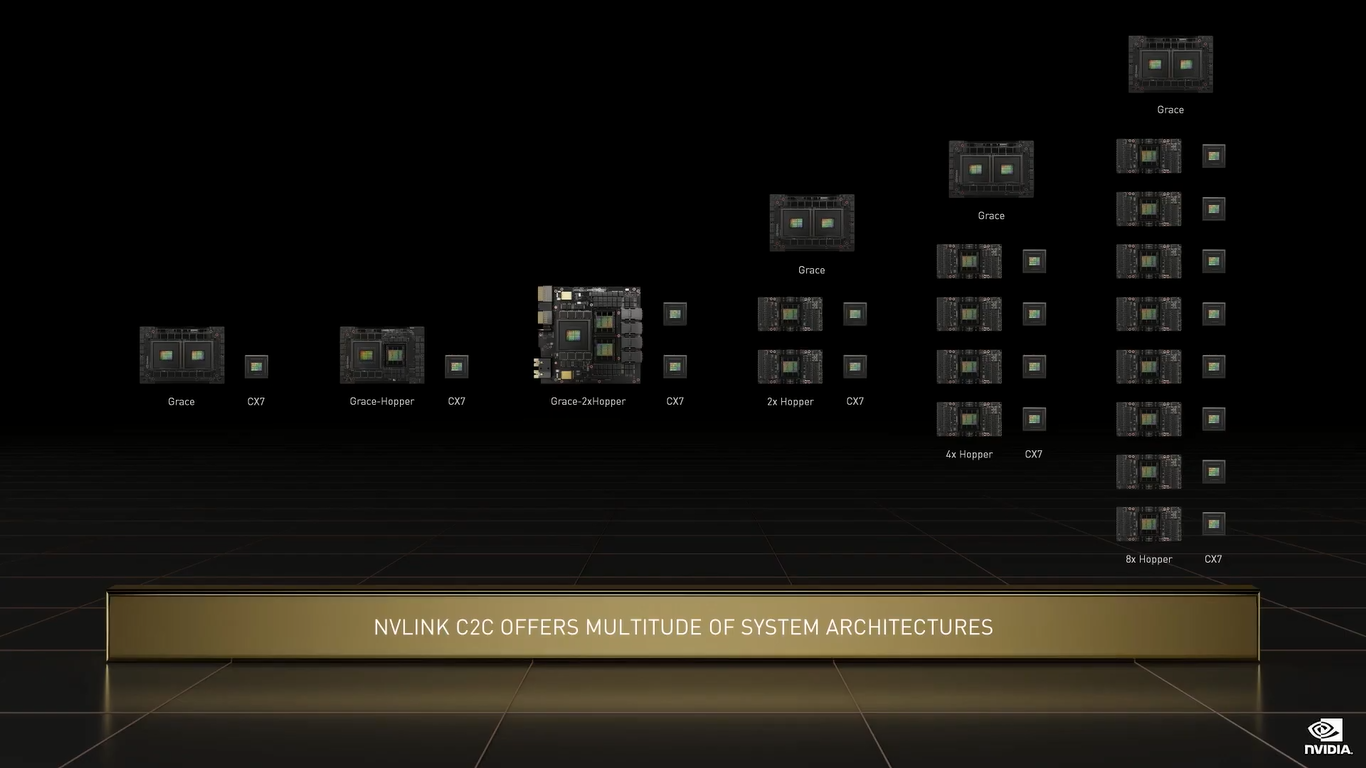 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe. |
|

