Материалы по тегу: l4
|
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 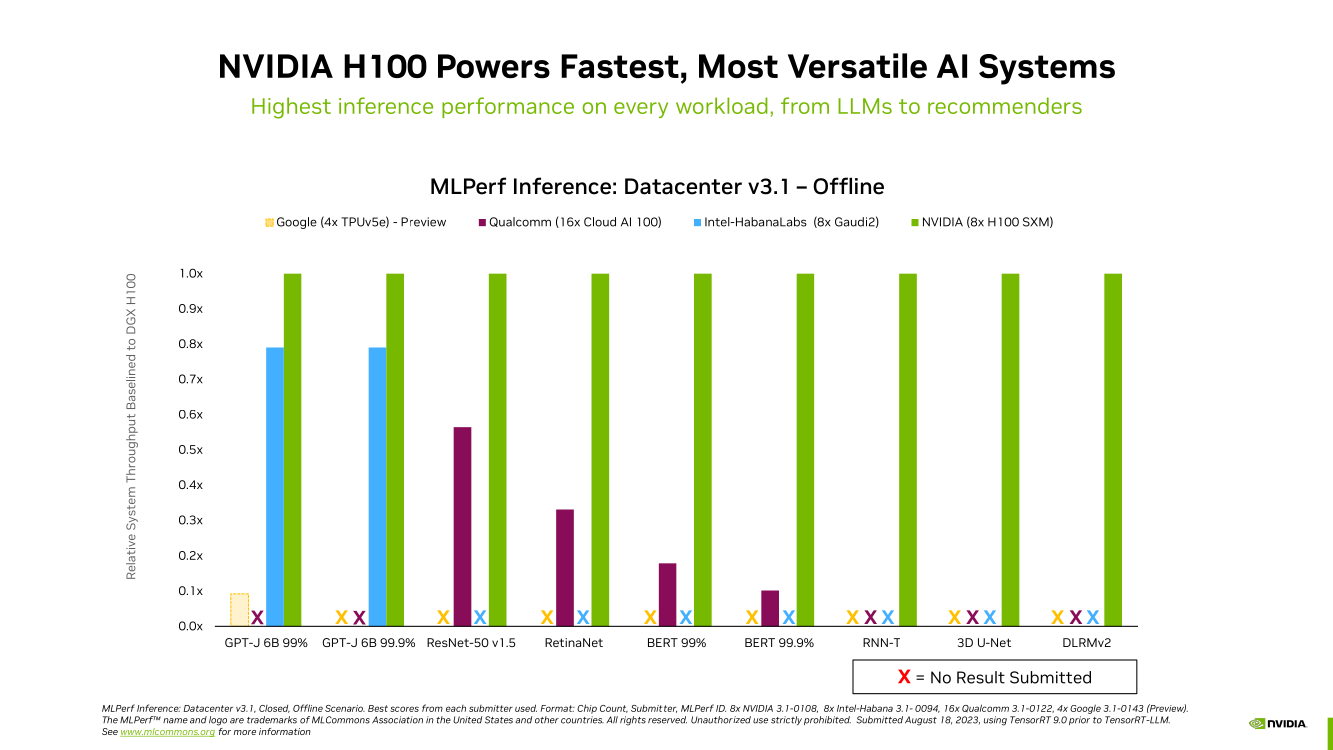 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU. 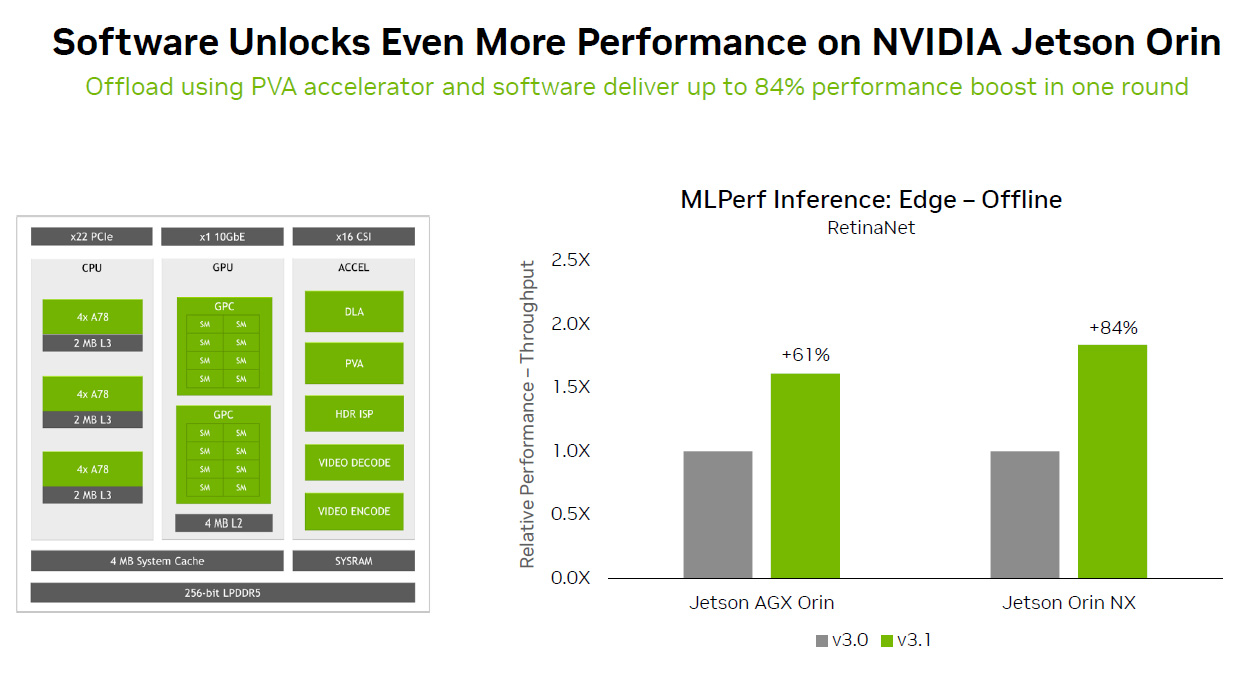 Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
23.03.2023 [19:44], Алексей Степин
Google Cloud представила инстансы G2 с ускорителями NVIDIA L4На GTC 2023 корпорация NVIDIA анонсировала новые ускорители для инференс-систем — сверхмощный H100 NVL и компактный L4. Последний предлагает приличную производительность в форм-факторе HHHL. Google Cloud уже воспользовалась последней новинкой и объявила о доступности инстансов G2 с ускорителями NVIDIA L4. Инференс-задачи требуют от ускорителя быстрой обработки входных данных. Google Cloud предлагает использовать G2 именно в таком качестве и говорит о возможном снижении инфраструктурной стоимости на 40 %. Также говорится о повышении производительности в сравнении с NVIDIA T4, ускорителями аналогичного класса, но предыдущего поколения. 
NVIDIA L4 (Источник: NVIDIA) В зависимости от задачи прирост может варьироваться от двух до четырёх раз. Карта развивает почти 500 Топс (INT8/FP8) и несёт на борту 24 Гбайт памяти с ПСП 300 Гбайт/с. Впрочем, L4 достаточно универсален и может использоваться в любых сценариях, от HPC и рендеринга 3D-графики до параллельного транскодирования потокового видеоконтента. В том числе новинка поддерживает трассировку лучей, технологию масштабирования DLSS 3.0, а также аппаратное кодирование в формате AV1. В настоящее время новые виртуальные машины доступны в виде закрытого превью, количество используемых ускорителей — от 1 до 8. Инстансы G2 доступны в регионах us-central1, asia-southeast1, europe-west4, а запрос на доступ к ним можно оставить, использовав приведённую ссылку. Также новые ускорители вскоре станут доступны в Google Kubernetes Engine (GKE), Vertex AI и других облачных сервисах.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 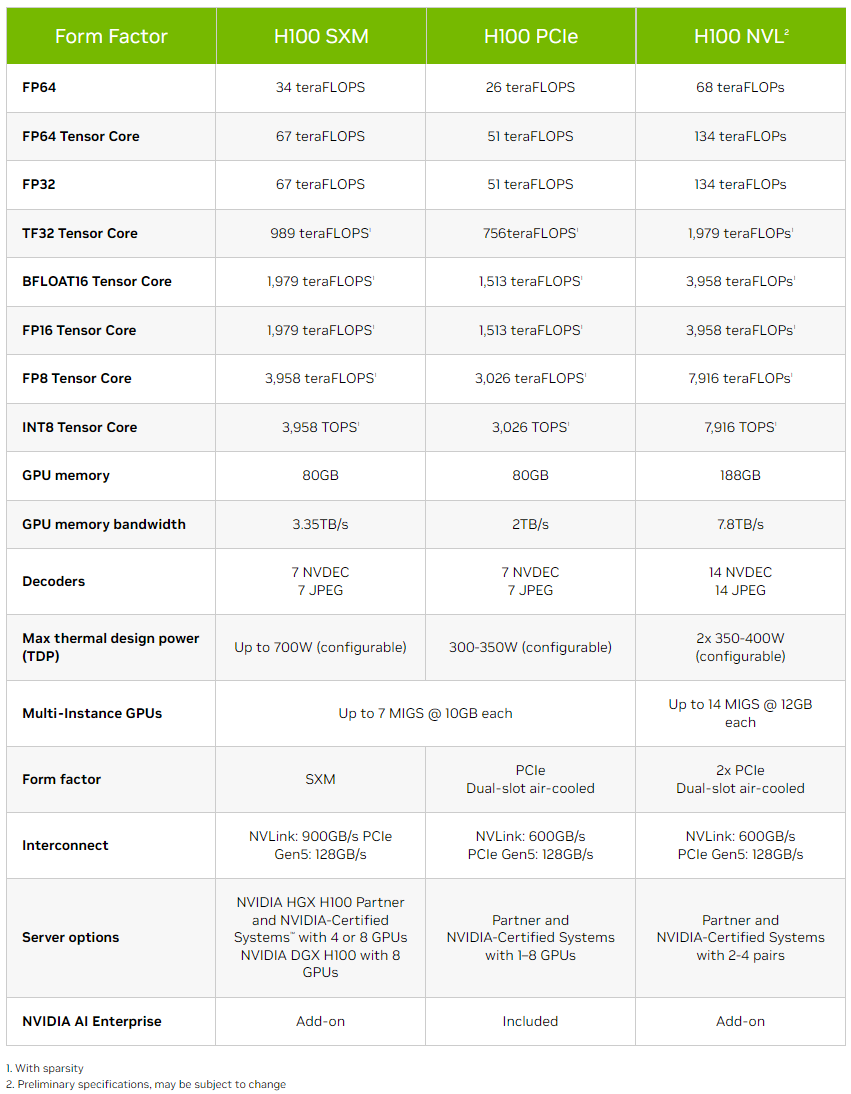 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 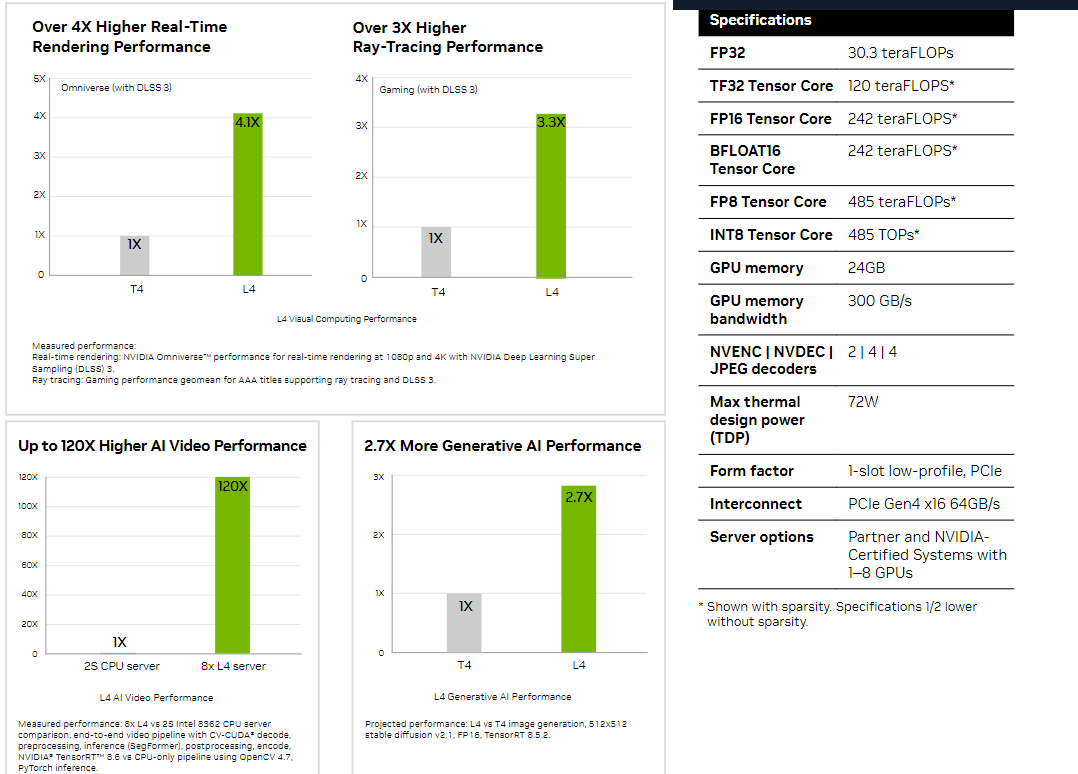 |
|

