Материалы по тегу: компьютер
|
21.03.2024 [00:51], Владимир Мироненко
Облачный ИИ-суперкомпьютер AWS Project Ceiba получит 21 тыс. суперчипов NVIDIA GB200
aws
b100
dgx cloud
gb200
gtc 2024
hardware
nvidia
ии
инференс
информационная безопасность
облако
суперкомпьютер
Amazon Web Services (AWS) и NVIDIA объявили о расширении сотрудничества, в рамках которого ускорители GB200 и B100 вскоре появятся в облаке AWS. Кроме того, компании объявили об интеграции Amazon SageMaker с NVIDIA NIM для предоставления клиентам более быстрого и дешёвого инференса, о появлении в AWS HealthOmics новых базовых моделей NVIDIA BioNeMo, а также о поддержке AWS обновлённой платформы NVIDIA AI Enterprise. Сотрудничество двух компаний позволило объединить в единую инфраструктуру их новейшие технологии, в том числе многоузловые системы на базе чипов NVIDIA Blackwell, ПО для ИИ, AWS Nitro, сервис управления ключами AWS Key Management Service (AWS KMS), сетевые адаптеры Elastic Fabric (EFA) и кластеры EC2 UltraCluster. Предложенная инфраструктура и инструменты позволят клиентам создавать и запускать LLM с несколькими триллионами параметров быстрее, в больших масштабах и с меньшими затратами, чем позволяли EC2-инстансы с ускорителями NVIDIA прошлого поколения. AWS предложит кластеры EC2 UltraClusters из суперускорителей GB200 NVL72, которые позволят объединить тысячи чипов GB200. GB200 будут доступны и в составе инстансов NVIDIA DGX Cloud. AWS также предложит EC2 UltraClusters с ускорителями B100. Amazon отмечает, что сочетание AWS Nitro и NVIDIA GB200 ещё больше повысит защиту ИИ-моделей: GB200 обеспечивает шифрование NVLink, EFA шифрует данные при передаче между узлами кластера, а KMS позволяет централизованно управлять ключами шифрования. 
Источник изображения: NVIDIA Аппаратный гипервизор AWS Nitro, как и прежде, разгружает CPU узлов, беря на себя обработку IO-операций, а также защищает код и данные во время работы с ними. Эта возможность, доступная только в сервисах AWS, была проверена и подтверждена NCC Group. Инстансы с GB200 поддерживают анклавы AWS Nitro Enclaves, что позволяет напрямую взаимодействовать с ускорителем и данными в изолированной и защищённой среде, доступа к которой нет даже у сотрудников Amazon. 
Источник изображения: NVIDIA Чипы Blackwell будут использоваться в обновлённом облачном суперкомпьютере AWS Project Ceiba, который будет использоваться NVIDIA для исследований и разработок в области LLM, генерация изображений/видео/3D, моделирования, цифровой биологии, робототехники, беспилотных авто, предсказания климата и т.д. Эта первая в своём роде машина на базе GB200 NVL72 будет состоять из 20 736 суперчипов GB200, причём каждый из них получит 800-Гбит/с EFA-подключение. Пиковая FP8-производительность системы составит 414 Эфлопс.
20.03.2024 [15:25], Руслан Авдеев
BNY Mellon стал первым транснациональным банком, внедрившим ИИ-суперкомпьютер NVIDIA на базе DGX SuperPOD H100Банк Bank of New York Mellon Corporation (BNY Mellon) стал первой структурой подобного профиля и масштаба, приступившей к внедрению собственного ИИ-суперкомпьютера на основе систем NVIDIA. Банку получил кластер DGX SuperPOD из нескольких десятков систем DGX H100, объединённых интерконнектом NVIDIA InfiniBand. Основанный в 2007 году в результате слияния The Bank of New York и Mellon Financial Corporation банк намерен использовать новый суперкомпьютер вкупе с NVIDIA AI Enterprise для создания и внедрения ИИ-приложений и управления ИИ-инфраструктурой своего бизнеса. Банк уже использует более 20 ИИ-решений, в том числе для прогнозирования в сфере депозитов, автоматизации платежей, предиктивной торговой аналитики и т.д. Всего же компания нашла более 600 вариантов использования ИИ в своей банковской системе. Как заявляют в руководстве BNY Mellon, внедрение ИИ-суперкомпьютера увеличит возможности по обработке данных и запуску ИИ-проектов, помогающих управлять активами клиентов и обеспечивать их защиту. 
Источник изображения: NVIDIA Компания пока не сообщила, где будет расположен суперкомпьютер и его полные характеристики. Ранее банку принадлежал дата-центр в Нью-Джерси, также он управлял IT-объектами в Пенсильвании и Теннесси.
20.03.2024 [13:49], Сергей Карасёв
OVHcloud приобрела 2-кубитный квантовый компьютер MosaiQКомпания OVHcloud, европейский поставщик облачных услуг, сообщила о вводе в эксплуатацию своего первого квантового компьютера — системы MosaiQ, разработанной парижской фирмой Quandela. Вычислительный комплекс смонтирован в дата-центре в Круа во Франции. Квантовый компьютер MosaiQ были приобретён компанией OVHcloud ровно год назад — в марте 2023-го. Его компоненты были доставлены в ЦОД во Франции в конце прошлого года, ещё несколько месяцев потребовалось на установку и настройку. 
Источник изображения: OVHcloud MosaiQ представляет собой систему с фотонным процессором. Для поддержания работы комплекса требуется его охлаждение до -265 °C. Утверждается, что система подходит для прототипирования, разработки и реализации нового поколения алгоритмов и протоколов квантовых вычислений. Архитектура MosaiQ позволяет задействовать от двух до 12 кубитов. В случае установки, приобретённой OVHcloud, речь идёт о младшей 2-кубитной реализации. OVHcloud хочет предоставить своему отделу исследований и разработок передовые инструменты для экспериментов в области квантовых технологий. Ранее компания заявила о намерении предлагать доступ к квантовым вычислениям по облачной модели через несколько эмуляторов, включая Perceval — фреймворк, разработанный специалистами Quandela. Подчёркивается, что OVHcloud стала первым в Европе поставщиком облачных услуг, который ввёл в эксплуатацию квантовый компьютер с фотонным процессором.
20.03.2024 [13:42], Сергей Карасёв
От $0,5/с: IQM запустила облачный сервис квантовых вычислений ResonanceКомпания IQM Quantum Computers объявила о запуске облачной платформы Resonance, призванной ускорить исследования в области квантовых вычислений. Сервис предоставляет разработчикам и учёным доступ к системам IQM для планирования, тестирования и оценки эффективности квантовых алгоритмов. Посредством Resonance обеспечивается доступ к квантовым компьютерам, расположенным в дата-центрах IQM в Эспоо (Финляндия) и Мюнхене (Германия). При этом пользователи могут работать с различными топологиями квантовых процессоров (QPU). 
Источник изображения: IQM Говорится, что на сегодняшний день через облачную платформу доступны 6-кубитный квантовый компьютер IQM Deneb и 20-кубитная система IQM Garnet. IQM заявляет, что платформа Resonance предоставляет безопасный доступ к квантовым компьютерам с новейшими QPU без необходимости инвестиций в квантовое оборудование. Стоимость услуги начинается с $0,5 в секунду. Также предлагается бесплатный пробный доступ длительностью 1 час. Среди областей применения облачного сервиса названы машинное обучение, кибербезопасность, моделирование квантовых датчиков, исследования в области передовых химических соединений, разработка новых фармацевтических препаратов и пр. В сервисе используется модель подписки на временные интервалы. Помимо облачного сервиса, компания IQM предлагает локальные квантовые компьютеры. В частности, на днях Юлихский суперкомпьютерный центр в Германии (JSC) объявил о приобретении у IQM 5-кубитной системы Spark, ввести которую в эксплуатацию планируется в июле нынешнего года. Кроме того, компания IQM заявила о планах создания Radiance — квантового компьютера на 150 кубитов, который будет запущен в I квартале 2025-го. IQM развернула локальные квантовые системы в Суперкомпьютерном центре Лейбница в Германии (LRZ) и в Центре технических исследований VTT в Финляндии.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее.
19.03.2024 [15:06], Сергей Карасёв
Юлихский суперкомпьютерный центр получил 5-кубитную квантовую систему IQMВ июле нынешнего года Юлихский суперкомпьютерный центр в Германии (JSC) намерен ввести в эксплуатацию новый квантовый компьютер — 5-кубитную систему Spark немецко-финского производителя IQM Quantum Computers. Новая система станет частью Унифицированной инфраструктуры квантовых вычислений Юлиха (Jülich UNified Infrastructure for Quantum Computing, JUNIQ). Spark будет работать в тандеме с классическими суперкомпьютерами, что позволит исследователям изучать различные варианты использования гибридных вычислений. Базовая версия IQM Spark стоит менее €1 млн. Система разработана специально для проведения экспериментов, а также для применения в образовательных целях. В этом компьютере кубиты (квантовые биты) генерируются с помощью сверхпроводящих электронных резонансных цепей. Для этого их необходимо охлаждать до температур, близких к абсолютному нулю (-273,15 °C). Платформа IQM Spark отличается гибкими возможностями в плане расширения и подключения, что делает её идеально подходящей для использования в составе инфраструктуры JUNIQ. 
Источник изображения: IQM Отмечается, что квантовые компьютеры способны решать определённые задачи гораздо быстрее, чем это возможно с помощью классических НРС-комплексов. Это может быть, например, моделирование сложных химических реакций и молекул, оптимизация процессов в финансовом секторе и пр. Однако квантовые компьютеры всё ещё находятся на ранней стадии развития. Проект JUNIQ поможет найти новые практические применения концепции гибридных квантово-классических вычислений. IQM развернула локальные квантовые системы в некоторых других университетах и исследовательских институтах, включая Суперкомпьютерный центр Лейбница в Германии (LRZ) и Центр технических исследований VTT в Финляндии.
19.03.2024 [01:02], Сергей Карасёв
Ускорители NVIDIA H100 лягут в основу японского суперкомпьютера ABCI-Q для квантовых вычисленийКомпания NVIDIA сообщила о том, что её технологии лягут в основу нового японского суперкомпьютера ABCI-Q, предназначенного для проведения исследований в области квантовых вычислений. Платформа, в частности, будет использоваться для тестирования гибридных систем, объединяющих классические и квантовые технологии. Развёртыванием комплекса займётся корпорация Fujitsu. Машина расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). Ввод ABCI-Q в эксплуатацию намечен на начало 2025 года. В состав суперкомпьютера войдут более 500 узлов, насчитывающих в общей сложности свыше 2000 ускорителей NVIDIA H100. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также NVIDIA CUDA Quantum — открытой платформы для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Комплекс ABCI-Q проектируется с прицелом на возможность добавления будущих аппаратных компонентов для квантовых вычислений. 
Источник изображения: NVIDIA Ожидается, что ABCI-Q позволит проводить высокоточное квантовое моделирование в рамках исследовательских проектов в различных отраслях. Учёные смогут тестировать приложения нового типа с целью ускорения их практического внедрения. Кроме того, специалисты смогут прорабатывать передовые алгоритмы для решения специфичных задач. NVIDIA и AIST также планируют сотрудничать при разработке промышленных приложений на базе ABCI-Q. В целом, ABCI-Q является частью стратегии Японии в области квантовых технологий, задачей которой является создание новых возможностей для бизнеса и общества, а также получение выгоды от квантовых технологий, в том числе посредством исследований в области ИИ, энергетики и биологии.
15.03.2024 [23:27], Сергей Карасёв
Миссии NASA задерживаются из-за устаревших и перегруженных суперкомпьютеровHPC-инфраструктура NASA нуждается в серьёзной модернизации, поскольку в текущем виде не в состоянии удовлетворить потребности организаций в составе национального управления по аэронавтике и исследованию космического пространства США. К такому выводу, как сообщает The Register, пришло в ходе аудита Управление генерального инспектора. Отмечается, что НРС-инфраструктура NASA морально устарела и не в состоянии эффективно поддерживать современные рабочие нагрузки. Например, в Центре передовых суперкомпьютеров NASA задействованы 18 тыс. CPU и только 48 ускорителей на базе GPU. 
Источник изображения: NASA Кроме того, текущих вычислительных мощностей не хватает для всех потребителей. Поэтому некоторые отделы и научные центры NASA вынуждены закупать собственное оборудование и формировать локальную НРС-инфраструктуру. В частности, одна только команда Space Launch System ежегодно тратит на эти цели $250 тыс. вместо того, чтобы подключаться к централизованной системе. Фактически каждое структурное подразделение NASA, за исключением Центра космических полетов Годдарда и Космического центра Стенниса, имеет собственную независимую вычислительную инфраструктуру. Ещё одной причиной развёртывания локальных мощностей является путаница вокруг облачных ресурсов и политики NASA, из-за которой возникают сложности с планированием и оценкой финансовых затрат. Аудит также показал, что есть вопросы к безопасности суперкомпьютерного парка NASA. Например, нет должного мониторинга некоторых систем, доступ к которым имеют иностранные пользователи. В целом, наблюдающаяся картина приводит к задержкам в реализации космических миссий и дополнительным расходам. Для устранения недостатков руководству NASA рекомендовано провести комплексную реформу НРС-сектора, включающую инвентаризацию активов, выявление технологических пробелов и киберрисков. Необходимо также разработать стратегию по улучшению распределения имеющихся вычислительных мощностей.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 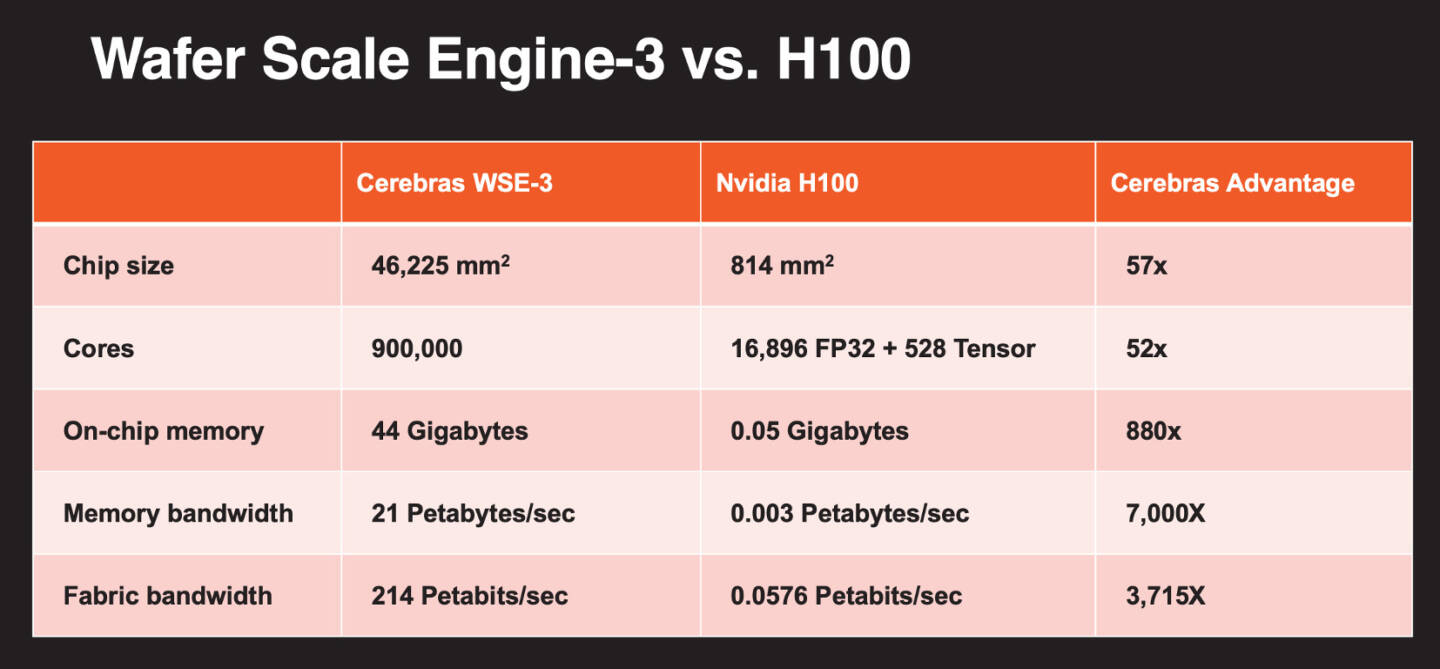 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 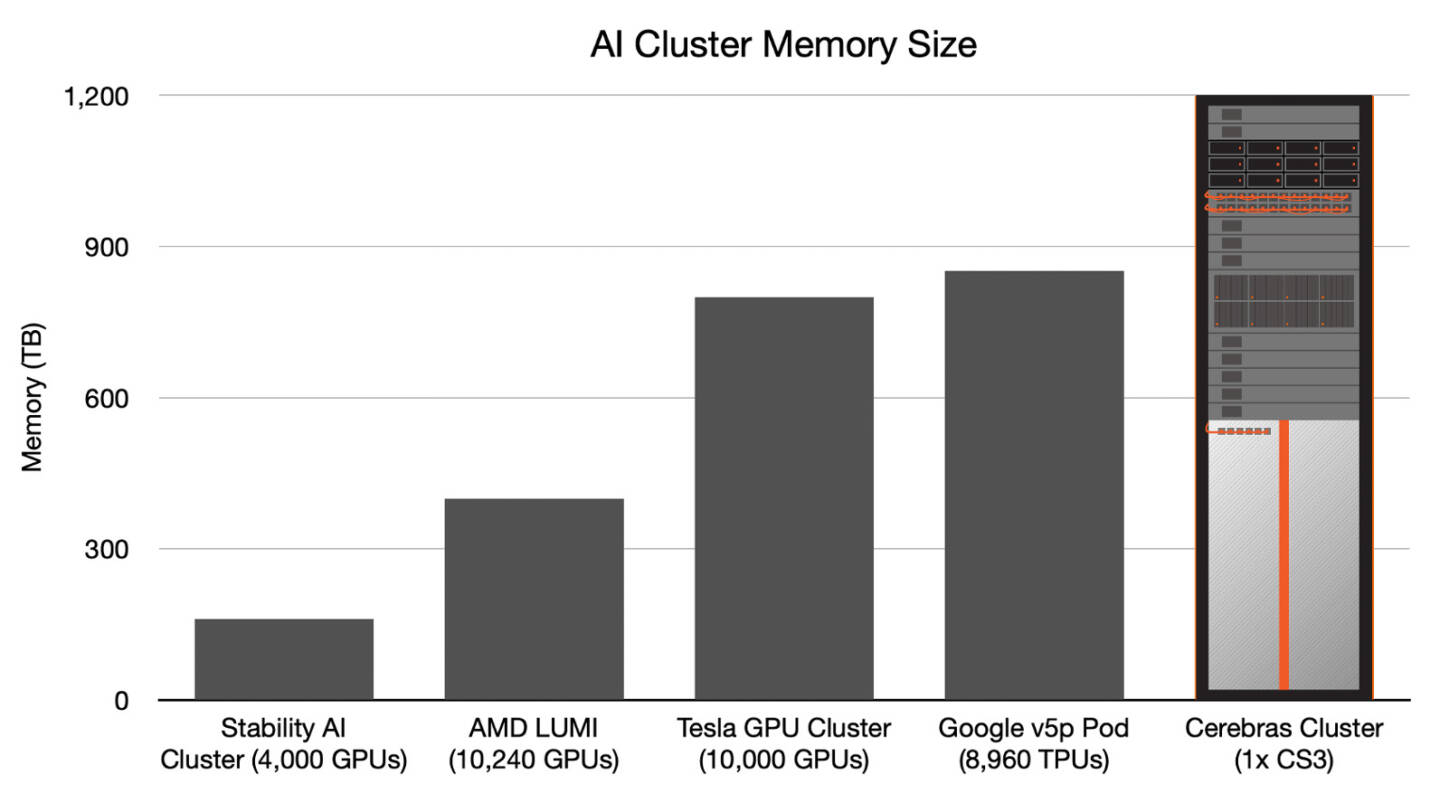 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 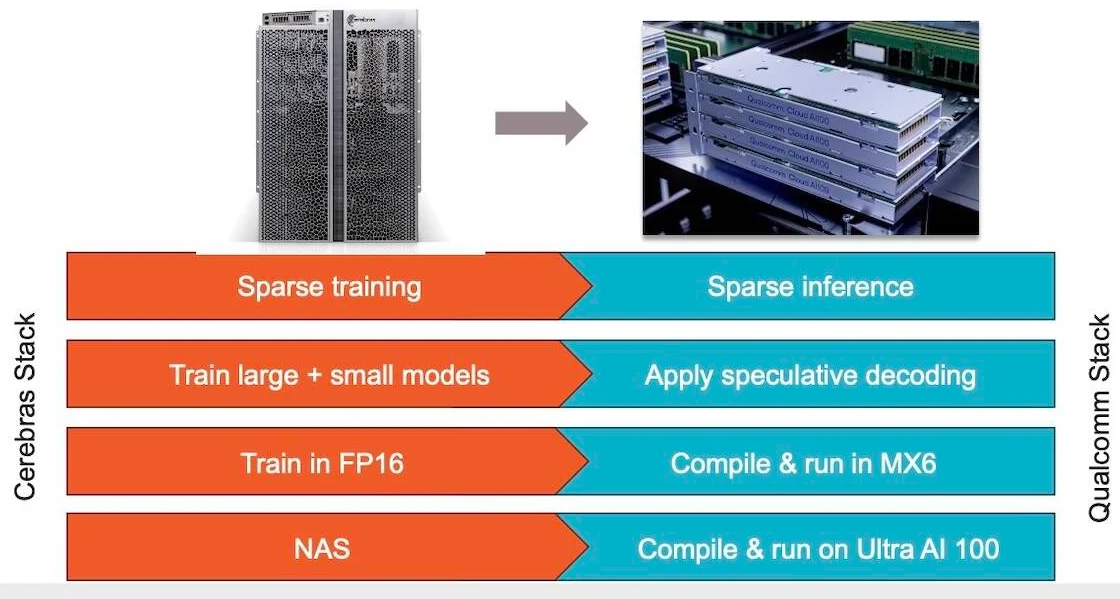 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
12.03.2024 [13:15], Сергей Карасёв
К 2030 году объём мирового рынка ИИ-суперкомпьютеров достигнет $6,43 млрдМаркетинговая и консалтинговая фирма 360iResearch прогнозирует быстрый рост мирового рынка суперкомпьютеров для ИИ-задач. Под такими системами аналитики понимают специализированные платформы с большими вычислительными ресурсами для быстрой обработки огромных объёмов данных. По оценкам 360iResearch, в 2023 году объём глобальной отрасли ИИ-суперкомпьютеров составил приблизительно $1,90 млрд. В 2024-м, как ожидается, затраты поднимутся до $2,26 млрд. В дальнейшем прогнозируется CAGR (среднегодовой темп роста в сложных процентах) на уровне 18,97 %. В результате к 2030 году расходы в рассматриваемом сегменте могут достичь $6,43 млрд. 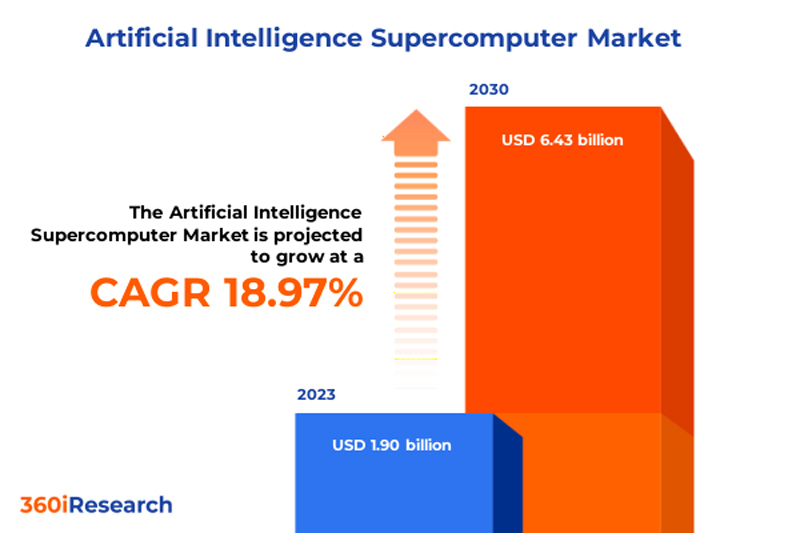
Источник изображения: 360iResearch Эксперты выделяют несколько ключевых факторов, способствующих быстрому росту рынка. Это, в частности, цифровая трансформация, стремительное увеличение объёма генерируемых данных и потребность в вычислительных мощностях для эффективного использования бизнес-информации. Другими драйверами отрасли названы достижения в области машинного и глубокого обучения, а также нейронных сетей. В свете внедрения различных технологий ИИ растёт потребность в НРС-вычислениях. Плюс к этому реализуются инициативы по поддержке ИИ-рынка на государственном уровне. С другой стороны, существует и ряд сложностей. Сектор ИИ-суперкомпьютеров сталкивается с такими препятствиями, как высокие затраты на исследования, разработки и внедрение, проблемы конфиденциальности и безопасности данных, этические вопросы, нехватка квалифицированных кадров и ограниченные возможности в развивающихся регионах. Аналитики отмечают, что дальнейшему росту во многом будут способствовать достижения в области квантовых компьютеров и вычислительных систем экзафлопсного уровня. В целом, рынок ИИ-суперкомпьютеров демонстрирует рост во всех ключевых регионах. В Северной и Южной Америке, особенно в США, этому способствует внедрение ИИ в различных секторах, включая здравоохранение, финансовые услуги и автомобилестроение. В регионе EMEA (Европа, Ближний Восток и Африка) развитие отрасли стимулируется активными исследованиями в области ИИ и внедрением соответствующих технологий на предприятиях, которые стремятся повысить свою эффективность. В Азиатско-Тихоокеанском регионе наблюдается растущее внедрение ИИ-технологий в электронной коммерции, автомобилестроении и производстве. |
|

