Материалы по тегу: h200
|
13.05.2024 [11:12], Сергей Карасёв
Supermicro представила ИИ-серверы на базе Intel Gaudi3 и AMD Instinct MI300XКомпания Supermicro анонсировала новые серверы для задач ИИ и НРС. Дебютировали системы высокой плотности с жидкостным охлаждением, а также устройства, оборудованные высокопроизводительными ускорителями AMD, Intel и NVIDIA. 
Источник изображений: Supermicro В частности, представлены серверы SYS-421GE-TNHR2-LCC и AS-4125GS-TNHR2-LCC в форм-факторе 4U, оснащённые СЖО. Первая из этих моделей рассчитана на установку двух процессоров Intel Xeon Emerald Rapids или Xeon Sapphire Rapids (до 385 Вт), а также 32 модулей DDR5-5600. Второй сервер поддерживает два чипа AMD EPYC 9004 Genoa с показателем TDP до 400 Вт и 24 модуля DDR5-4800.  Обе новинки могут быть оборудованы восемью ускорителями NVIDIA H100 (SXM). В одной стойке могут размещаться до восьми серверов, что в сумме даст 64 ускорителя. При этом общая заявленная производительность такого кластера на операциях FP16 превышает 126 Пфлопс. Серверы оборудованы восемью фронтальными отсеками для SFF-накопителей NVMe. Питание обеспечивают четыре блока мощностью 5250 Вт с сертификатом Titanium. Слоты расширения выполнены по схеме 8 × PCIe 5.0 x16 LP и 2 × PCIe 5.0 x16 FHHL.  На ISC 2024 компания Supermicro также демонстрирует сервер типоразмера 8U, оборудованный ускорителями Intel Gaudi3. Это одна из первых систем такого рода. Кроме того, представлена система AS-8125GS-TNMR2 формата 8U, рассчитанная на восемь ускорителей AMD Instinct MI300X. Этот сервер может комплектоваться двумя процессорами EPYC 9004 с TDP до 400 Вт, 24 модулями оперативной памяти DDR5-4800, фронтальными накопителями SFF (16 × NVMe и 2 × SATA), двумя модулями M.2 NVMe. Установлены шесть блоков питания на 3000 Вт с сертификатом Titanium. Наконец, Supermicro готовит серверы формата 4U с жидкостным охлаждением, которые могут оснащаться восемью ускорителями NVIDIA H100 и H200. Компания демонстрирует на конференции ISC 2024 и другие системы для приложений ИИ, а также задач НРС.
13.05.2024 [09:00], Сергей Карасёв
Более 200 Эфлопс для ИИ: NVIDIA представила новые НРС-системы на суперчипах Grace HopperКомпания NVIDIA рассказала о новых высокопроизводительных комплексах на основе суперчипов Grace Hopper для задач ИИ и НРС. Отмечается, что суммарная производительность этих систем превышает 200 Эфлопс. Суперкомпьютеры предназначены для решения самых разных задач — от исследований в области изменений климата до сложных научных проектов. Одним из таких НРС-комплексов является EXA1 — HE, который является совместным проектом Eviden (дочерняя структура Atos) и Комиссариата по атомной и альтернативным видам энергии Франции (СЕА). Система использует 477 вычислительных узлов на базе Grace Hopper, а пиковое быстродействие достигает 104 Пфлопс. Ещё одной системой стал суперкомпьютер Alps в Швейцарском национальном компьютерном центре (CSCS). Он использует в общей сложности 10 тыс. суперчипов Grace Hopper. Заявленная производительность на операциях ИИ достигает 10 Эфлопс, и это самый быстрый ИИ-суперкомпьбтер в Европе. Утверждается, что по энергоэффективности Alps в 10 раз превосходит систему предыдущего поколения Piz Daint. 
Источник изображений: NVIDIA В свою очередь, комплекс Helios, созданный компанией НРЕ для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша), содержит 440 суперчипов NVIDIA GH200 Grace Hopper. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс.  В список систем на платформе Grace Hopper также входит Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. Кроме того, в список вошёл комплекс DeltaAI на основе GH200 Grace Hopper, созданием которого занимается Национальный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США).  В числе прочих систем названы суперкомпьютер Miyabi в Объединённом центре передовых высокопроизводительных вычислений в Японии (JCAHPC), Isambard-AI в Бристольском университете в Великобритании (5280 × GH200), а также суперкомпьютер в Техасском центре передовых вычислений при Техасском университете в Остине (США), комплекс Venado в Лос-Аламосской национальной лаборатории США (LANL) и суперкомпьютер Recursion BioHive-2 (504 × H100).
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000.
27.03.2024 [22:29], Алексей Степин
Новый бенчмарк — новый рекорд: NVIDIA подтвердила лидерские позиции в MLPerf InferenceКомпания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям. Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию». 
Источник изображений: NVIDIA Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel). 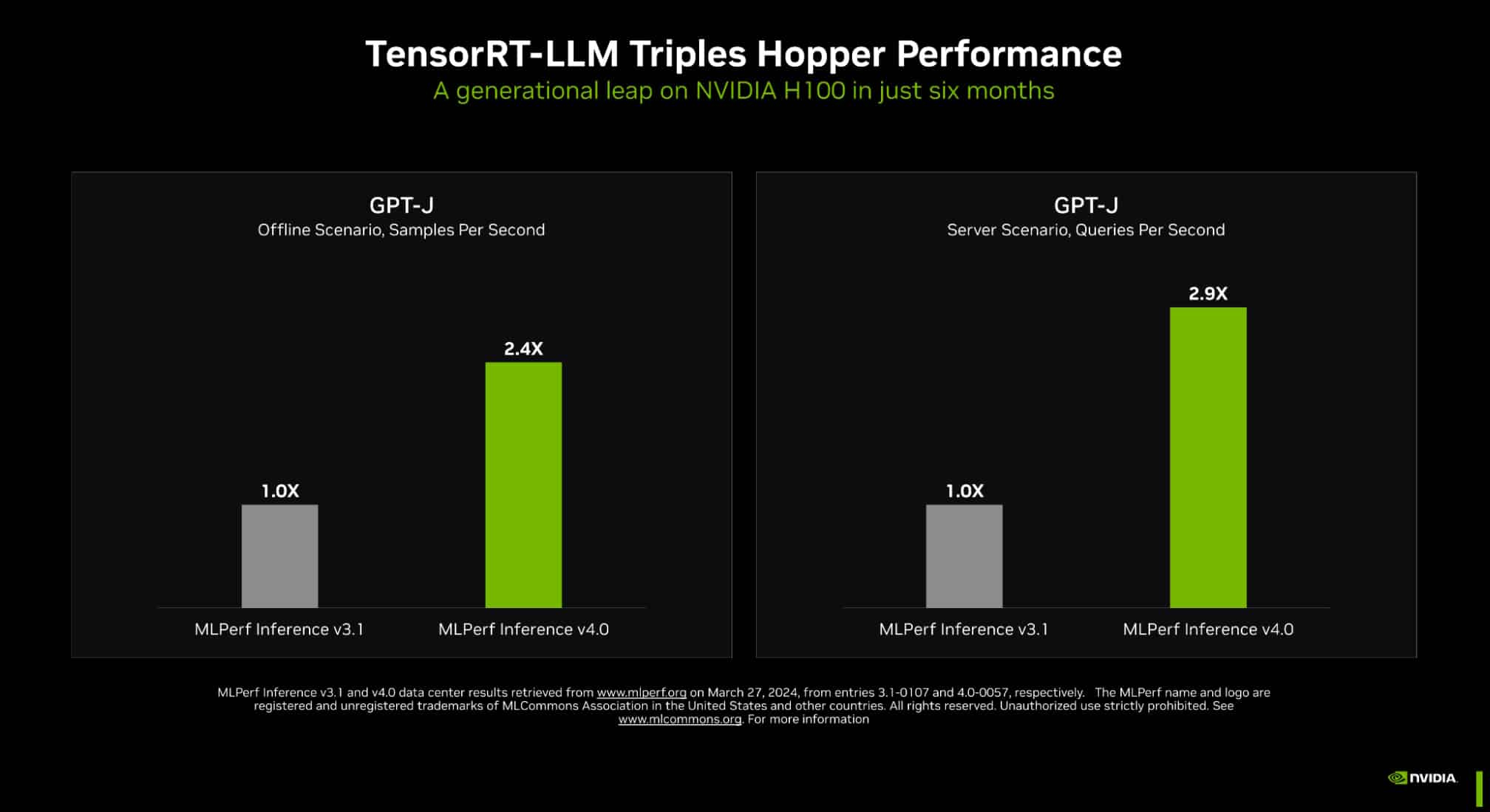 В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %. 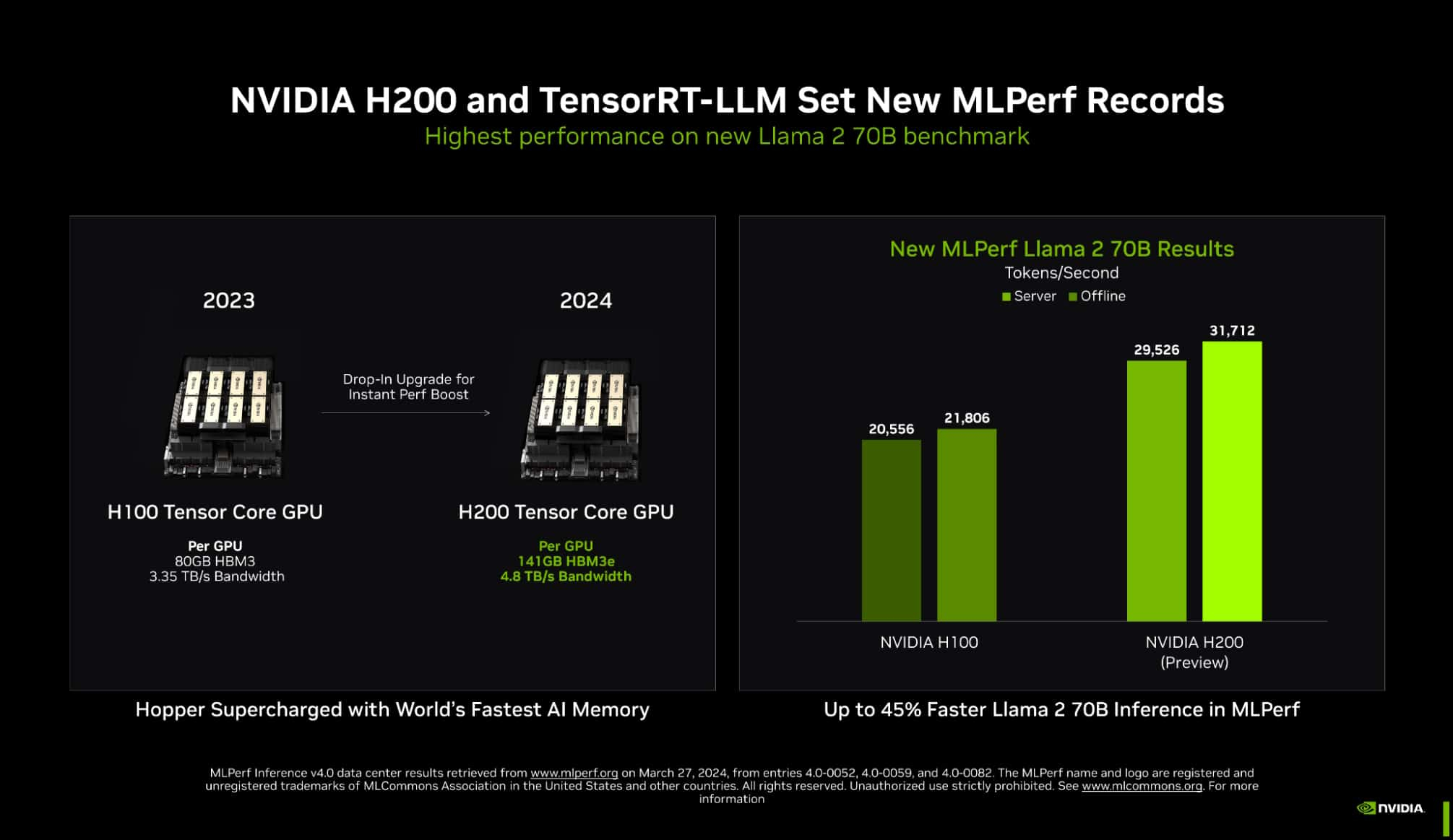 В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности. На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
23.03.2024 [16:02], Сергей Карасёв
Supermicro представила ИИ-системы SuperCluster с ускорителями NVIDIA H100/H200 и суперчипами GH200Компания Supermicro анонсировала вычислительные кластеры SuperCluster с ускорителями NVIDIA, предназначенные для обработки наиболее ресурсоёмких приложений ИИ и обучения больших языковых моделей (LLM). Дебютировали системы, оснащённые жидкостным и воздушным охлаждением. В частности, представлен комплекс SuperCluster в составе пяти стоек на основе 4U-узлов СЖО. Каждый из узлов может нести на борту два процессора Intel Xeon Sapphire Rapids / Xeon Emerald Rapids или два чипа AMD EPYC 9004 (Genoa), дополненные памятью DDR5-5600. Доступны восемь фронтальных отсеков для SFF-накопителей NVMe и два слота M.2 NVMe. Каждый из узлов рассчитан на установку восьми ускорителей NVIDIA H100 или H200. Таким образом, в общей сложности SuperCluster с 32 узлами насчитывает до 256 ускорителей. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также Ethernet-технологии NVIDIA Spectrum-X. Используется платформа для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая теперь включает микросервисы на базе загружаемых контейнеров. 
Источник изображений: Supermicro Ещё одна система SuperCluster предусматривает конфигурацию из девяти стоек с узлами в форм-факторе 8U с воздушным охлаждением. У таких узлов во фронтальной части находятся 12 отсеков для SFF-накопителей NVMe и три отсека для SFF-устройств с интерфейсом SATA. В остальном характеристики аналогичны решениям типоразмера 4U. Общее количество узлов в системе равно 32.  Кроме того, вышел комплекс SuperCluster с девятью стойками на основе узлов 1U с воздушным охлаждением. Эти узлы комплектуются суперчипом NVIDIA GH200 Grace Hopper. Есть восемь посадочных мест для накопителей E1.S NVMe и два коннектора M.2 NVMe. В кластере объединены 256 узлов. Отмечается, что данная система оптимизирована для задач инференса в облачном масштабе.
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
27.02.2024 [16:08], Сергей Карасёв
Supermicro анонсировала ИИ- и телеком-серверы на базе AMD EPYC Siena, Intel Xeon Emerald Rapids и NVIDIA Grace Hopper
5g
amd
emerald rapids
epyc
gh200
grace
hardware
intel
mwc 2024
nvidia
siena
supermicro
ии
периферийные вычисления
сервер
Компания Supermicro представила на выставке мобильной индустрии MWC 2024 в Барселоне (Испания) новые серверы для телекоммуникационной отрасли, 5G-инфраструктур, задач ИИ и периферийных вычислений. Дебютировали модели с процессорами AMD EPYC 8004 Siena, Intel Xeon Emerald Rapids и с суперчипами NVIDIA GH200 Grace Hopper.  В частности, анонсирована стоечная система ARS-111GL-NHR высокой плотности в форм-факторе 1U на базе GH200. Устройство наделено двумя слотами PCIe 5.0 x16, восемью фронтальными отсеками для накопителей E1.S NVMe и двумя коннекторами для модулей M.2 NVMe. Сервер предназначен для работы с генеративным ИИ и большими языковыми моделями (LLM). На периферийные 5G-платформы ориентировано решение SYS-211E ультрамалой глубины — 298,8 мм. Модель рассчитана на один процессор Xeon Emerald Rapids в исполнении LGA-4677. Есть восемь слотов для модулей DDR5-5600 общей ёмкостью до 2 Тбайт и до шести слотов PCIe 5.0 в различных конфигурациях для карт расширения. Модификация SYS-211E-FRDN13P для сетей Open RAN предлагает 12 портов 25GbE и поддерживает технологию Intel vRAN Boost.  Ещё одна новинка — сервер AS-1115S-FWTRT формата 1U с возможностью установки одного процессора EPYC 8004 Siena (до 64 ядер). Реализована поддержка до 576 Гбайт памяти DDR5-4800 (шесть слотов), двух портов 10GbE, двух слотов PCIe 5.0 x16 FHFL и одного слота PCIe 5.0 x16. Решение предназначено для edge-приложений.
Представлены также многоузловая платформа SYS-211SE-31D/A и система высокой плотности SYS-221HE: обе модели выполнены в формате 2U на процессорах Xeon Emerald Rapids. Второй из этих серверов допускает монтаж до трёх двухслотовых ускорителей NVIDIA H100, A10, L40S, A40 или A2. Наконец, анонсирован сервер AS-1115SV типоразмера 1U с поддержкой процессоров EPYC 8004 Siena, 576 Гбайт памяти DDR5, трёх слотов PCIe 5.0 x16 и 10 накопителей SFF.
27.02.2024 [13:24], Сергей Карасёв
ASRock Rack представила MECAI-GH200 — самый компактный в мире сервер с суперчипом NVIDIA GH200Компания ASRock Rack продемонстрировала сервер MECAI-GH200: это, как утверждается, самая компактная в мире система, оснащённая гибридным суперчипом NVIDIA GH200 Grace Hopper с 72-ядерным Arm-процессором NVIDIA Grace и ускорителем NVIDIA H100 с 96 Гбайт памяти HBM3. Новинка выполнена в 2U-корпусе небольшой глубины. Доступны два посадочных места для накопителей формата E1.S (PCIe 5.0 х4), два коннектора для модулей М.2 (PCIe 5.0 х4) и два слота для карт расширения FHFL с интерфейсом PCIe 5.0 х16. Питание обеспечивают два блока мощностью 1600 Вт. Глубина MECAI-GH200 составляет 450 мм. Сервер предназначен для решения ИИ-задач на периферии. Прочие характеристики сервера пока не раскрываются.  «В ASRock Rack мы стремимся обеспечить возможность повсеместного использования ИИ. Для достижения этой цели мы создаём надёжные серверные решения в различных форм-факторах и для различных сценариев», — говорит вице-президент компании Хантер Чен (Hunter Chen).  ASRock Rack также представила на выставке MWC 2024 новые barebone-системы и материнские платы для процессоров Intel, AMD и Ampere. Например, впервые демонстрируется плата SIENAD8UD-2L2Q с поддержкой чипов AMD EPYC 8004 Siena и двумя сетевыми портами 25GbE SFP28.
23.02.2024 [19:07], Сергей Карасёв
Австралийский суперкомпьютерный центр внедрит суперчипы NVIDIA Grace Hopper для квантовых исследованийАвстралийский суперкомпьютерный центр Pawsey начнёт использовать решение NVIDIA CUDA Quantum — открытую платформу для интеграции и программирования CPU, GPU и квантовых компьютеров (QPU). Ожидается, что это поможет ускорить развитие перспективного направления квантовых вычислений. Pawsey развернёт в своём Национальном центре инноваций в области суперкомпьютеров и квантовых вычислений восемь узлов с суперчипами NVIDIA GH200. Эти изделия содержат 72-ядерный Arm-процессор Grace и ускоритель H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с. Сообщается, что узлы проектируемой системы будут использовать модульную архитектуру NVIDIA MGX, которая предназначена для построения HPC-систем и комплексов ИИ. Предполагается, что высокопроизводительная гибридная платформа с CPU, GPU и QPU позволит выполнять высокоточные и гибко масштабируемые квантовые симуляции. В рамках проекта будет применяться специализированное ПО NVIDIA cuQuantum для разработки квантовых решений. 
Источник изображения: NVIDIA Национальное научное агентство Австралии (CSIRO) оценивает размер внутреннего рынка квантовых вычислений в $2,5 млрд в год с потенциалом создания до 10 тыс. новых рабочих мест к 2040-му. Для достижения таких показателей необходимо внедрение квантовых вычислений в различных областях, включая астрономию, науки о жизни, медицину, финансы и пр.
10.02.2024 [20:32], Алексей Степин
Опубликованы результаты тестирования рабочей станции на базе NVIDIA GH200Поскольку NVIDIA со своим проектом Grace явно метит в мир высокопроизводительных многоядерных процессоров, результаты тестирования новых чипов представляют существенный интерес для всех, кто интересуется решениями подобного класса. Ресурс Phoronix опубликовал результаты проведённого тестирования NVIDIA GH200, причём в составе рабочей станции. Это, напомним, гибридное решение, включающее в себя 72-ядерный Arm-процессор и ускоритель H100. Сборка также включает в себя 480 Гбайт памяти LPDDR5 для процессорной части, а ускоритель располагает собственной высокоскоростной памятью HBM3e объёмом 96 Гбайт или 144 Гбайт. Связаны CPU и GPU высокоскоростной шиной NVLink-C2C с пропускной способностью 900 Гбайт/с. С периферийными устройствами GH200 может общаться посредством четырёх комплексов PCIe 5.0 по 16 линий каждый, а со стороны ускорителя имеется 18 линий NVLink 4 (900 Гбайт/с совокупно). 
Фото: GPTshop.ai Систему на тестирование предоставил магазин GPTshop.ai, позиционирующий решения на базе GH200 в качестве «настольных суперкомпьютеров». Рабочая станция в башенном корпусе включает в себя модуль GH200 на плате QCT и два блока питания мощностью 2000 Ватт, твердотельные накопители и сетевые карты NVIDIA ConnectX/Bluefield — по желанию заказчика. Стоимость стартует с отметки €47,4 тыс. 
Фото: GPTshop.ai В качестве ОС может использоваться любой дистрибутив Linux с поддержкой AArch64. В Phoronix использовали Ubuntu 23.10 с ядром версии 6.5 и стоковым компилятором GCC 13. В сравнении приняли участия системы на базе Intel Xeon Emerald Rapids, AMD EPYC и Ampere Altra Max. 
Источник: Phoronix В зависимости от сценария система на базе GH200 выступила с переменным успехом, но в среднем производительность процессорной части оказалась примерно на уровне 64-ядерных x86-процессоров — Xeon Platinum 8592+ или EPYC 9554. А 128-ядерный Altra Max M128-30 решение от NVIDIA уверенно обгоняет за счёт и более совершенной архитектуры, и более производительной подсистемы памяти. 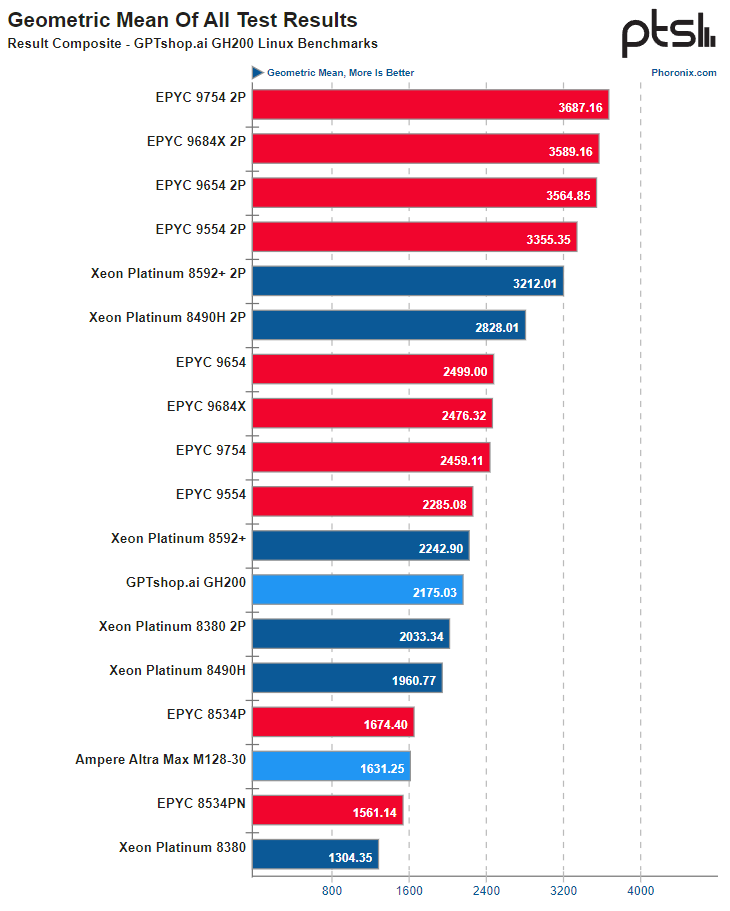
Источник: Phoronix К сожалению, вопрос энергоэффективности пока остался непроясненным, поскольку система не предоставляет интерфейсов RAPL/PowerCap/HWMON в Linux и точных метрик потребления получить невозможно, доступно лишь примерное значение потребления системы в целом через IPMI. Потенциал у GH200, определённо, есть, хотя временами и сказывается недостаточная оптимизация программного обеспечения под архитектуру AArch64. Конкуренции двухпроцессорным решениям Intel или AMD GH200 не составляет, однако в распоряжении NVIDIA имеется и 144-ядерный вариант Grace Superchip. Тестирование такой системы уже значится в планах Phoronix. |
|


