Материалы по тегу: инференс
|
29.09.2023 [13:05], Сергей Карасёв
Разработчик ИИ-чипов Kneron получил $49 млн инвестицийКомпания Kneron, специализирующаяся на разработке ИИ-технологий, объявила о проведении расширенного раунда инвестиций Series B, в ходе которого на развитие привлечено $49 млн. Таким образом, общая сумма вложений в рамках указанной финансовой программы достигла $97 млн. Стартап Kneron из Сан-Диего разрабатывает чипы, которые можно использовать в умных автомобилях, роботах и других подключённых устройствах с ИИ-функциями. Компания заявляет, что приложения машинного обучения, использующие её чипы, могут стабильно работать даже без доступа в интернет. 
Источник изображения: Kneron Одно из изделий Kneron — специализированный ИИ-чип KL730. Он объединяет четырёхъядерный CPU на архитектуре Arm и акселератор для задач инференса. Реализована поддержка интерфейсов SD, USB и Ethernet. Заявленная производительность достигает 4 TOPS. При этом обеспечивается высокая энергоэффективность. Средства на развитие в ходе раунда Series B предоставили Foxconn and HH-CTBC Partnership (Foxconn Co-GP Fund), Alltek, Horizons Ventures, Liteon Technology Corp, Adata и Palpilot. Деньги будут использованы в том числе для ускорения разработки ИИ-решений для автомобильной сферы. В целом, на сегодняшний день стартап Kneron получил финансовую поддержку в размере $190 млн.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 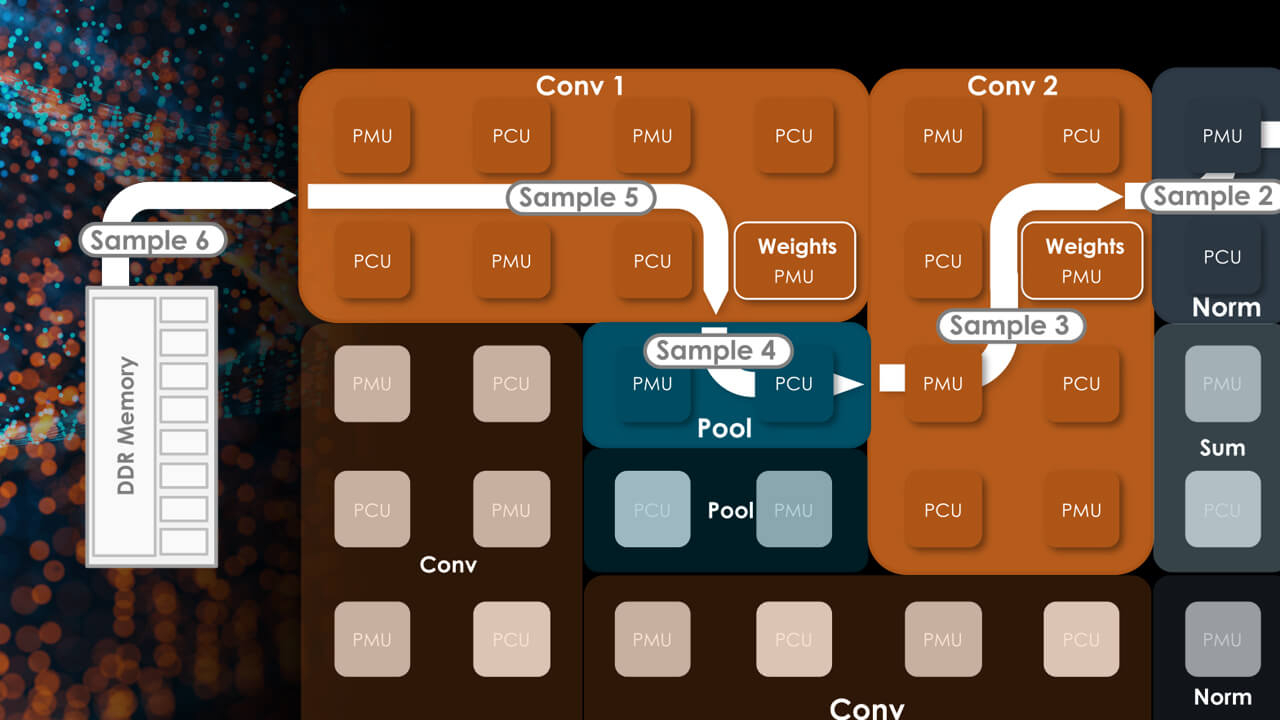
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
16.09.2023 [21:40], Сергей Карасёв
Cadence представила 7-нм ИИ-ядро Neo NPU с производительностью до 80 TOPSКомпания Cadence Design Systems, разработчик IP-блоков, по сообщению CNX-Software, создала ядро Neo NPU (Neural Processing Unit) — нейропроцессорный узел, предназначенный для решения ИИ-задач с высокой энергетической эффективностью. Решение подходит для создания SoC умных сенсоров, IoT-устройств, носимых гаджетов, систем оказания помощи водителю при движении (ADAS) и пр. Утверждается, что производительность Neo NPU может масштабироваться от 8 GOPS до 80 TOPS в расчёте на ядро. В случае многоядерных конфигураций быстродействие может исчисляться сотнями TOPS. Ядро Neo NPU способно справляться как с классическими ИИ-задачами, так и с нагрузками генеративного ИИ. Говорится о поддержке INT4/8/16 и FP16 для свёрточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров. 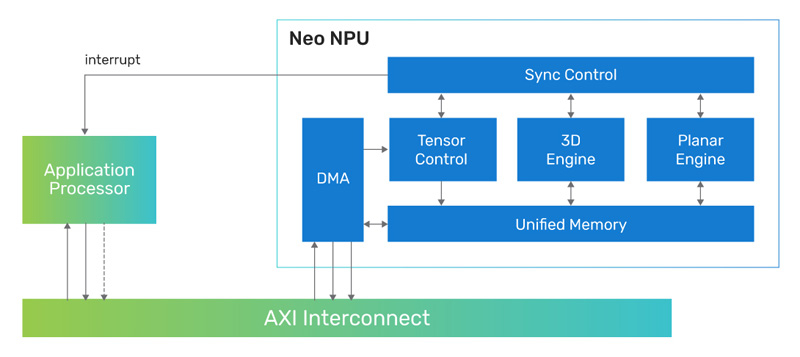
Источник изображения: Cadence Для Neo NPU предполагается применение 7-нм технологии производства. Стандартная тактовая частота — 1,25 ГГц. Утверждается, что по сравнению с ядрами первого поколения Cadence AI IP изделие Neo NPU обеспечивает 20-кратный прирост производительности. Скорость инференса в расчёте на ватт в секунду возрастает в 5–10 раз. Разработчикам будет предлагаться комплект NeuroWeave (SDK) с поддержкой TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet, JAX, а также Android Neural Network Compiler, TF Lite Delegates и TensorFlow Lite Micro. Решение Neo NPU станет доступно в декабре 2023 года.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 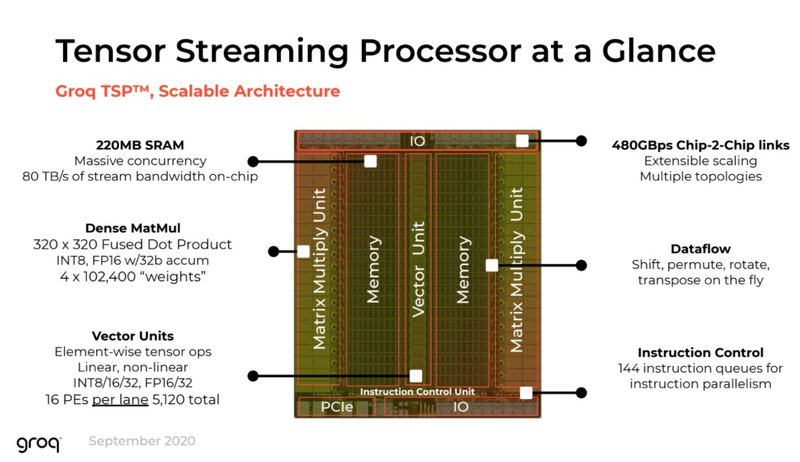 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 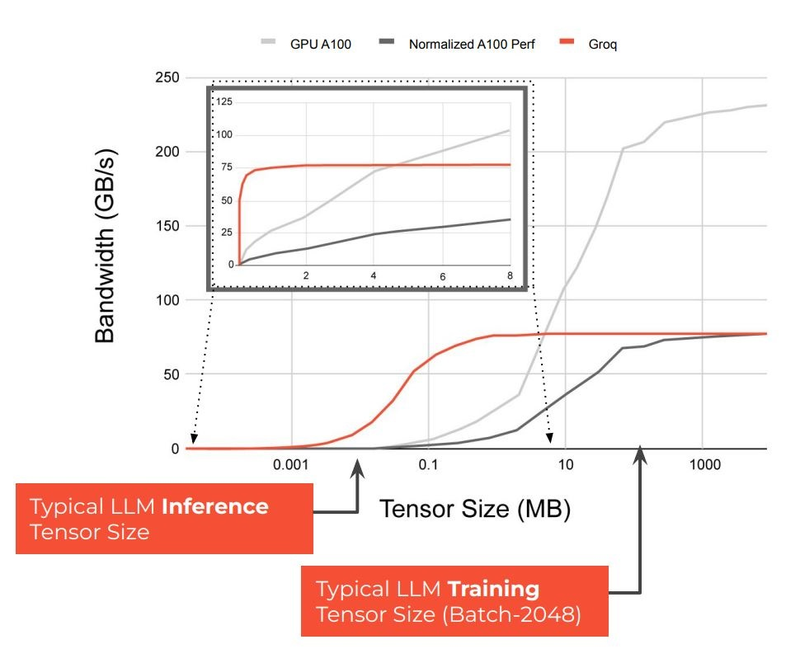 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 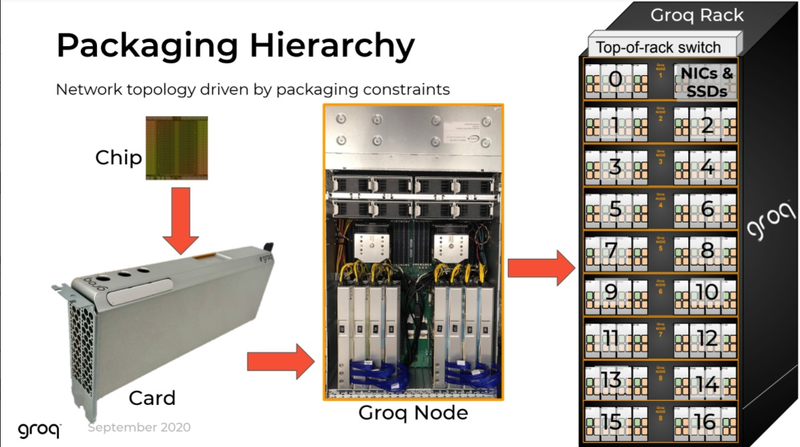 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 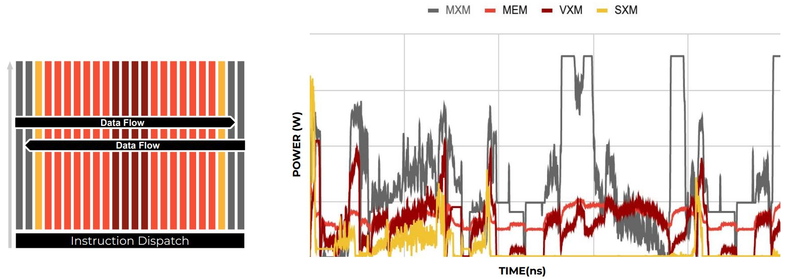
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 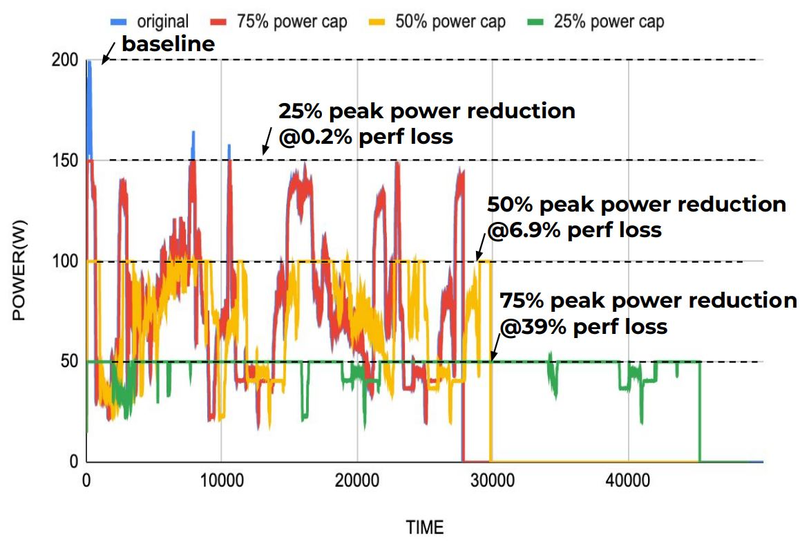
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту.
14.09.2023 [16:55], Сергей Карасёв
Конкуренцию NVIDIA H100 в MLPerf пока может составить только Intel Habana Gaudi2Корпорация Intel обнародовала результаты тестирования ускорителя Habana Gaudi2 в бенчмарке GPT-J (входит в MLPerf Inference v3.1), основанном на большой языковой модели (LLM) с 6 млрд параметров. Полученные данные говорят о том, что это изделие может стать альтернативой решению NVIDIA H100 на ИИ-рынке. В частности, в тесте GPT-J ускоритель H100 демонстрирует сравнительно небольшое преимущество в плане производительности по сравнению с Gaudi2 — ×1,09 в серверном режиме и ×1,28 в оффлайн-режиме. При этом Gaudi2 превосходит ускоритель NVIDIA A100 в 2,4 раза в режиме server и в 2 раза в оффлайн-режиме. Кроме того, решение Intel опережает H100 на моделях BridgeTower. Этот тест обучен на 4 млн изображений. Говорится, что точность Visual Question Answering (VQAv2) достигает 78,73 %. При масштабировании модель имеет ещё более высокую точность — 81,15 %, превосходя модели, обученные на гораздо более крупных наборах данных. 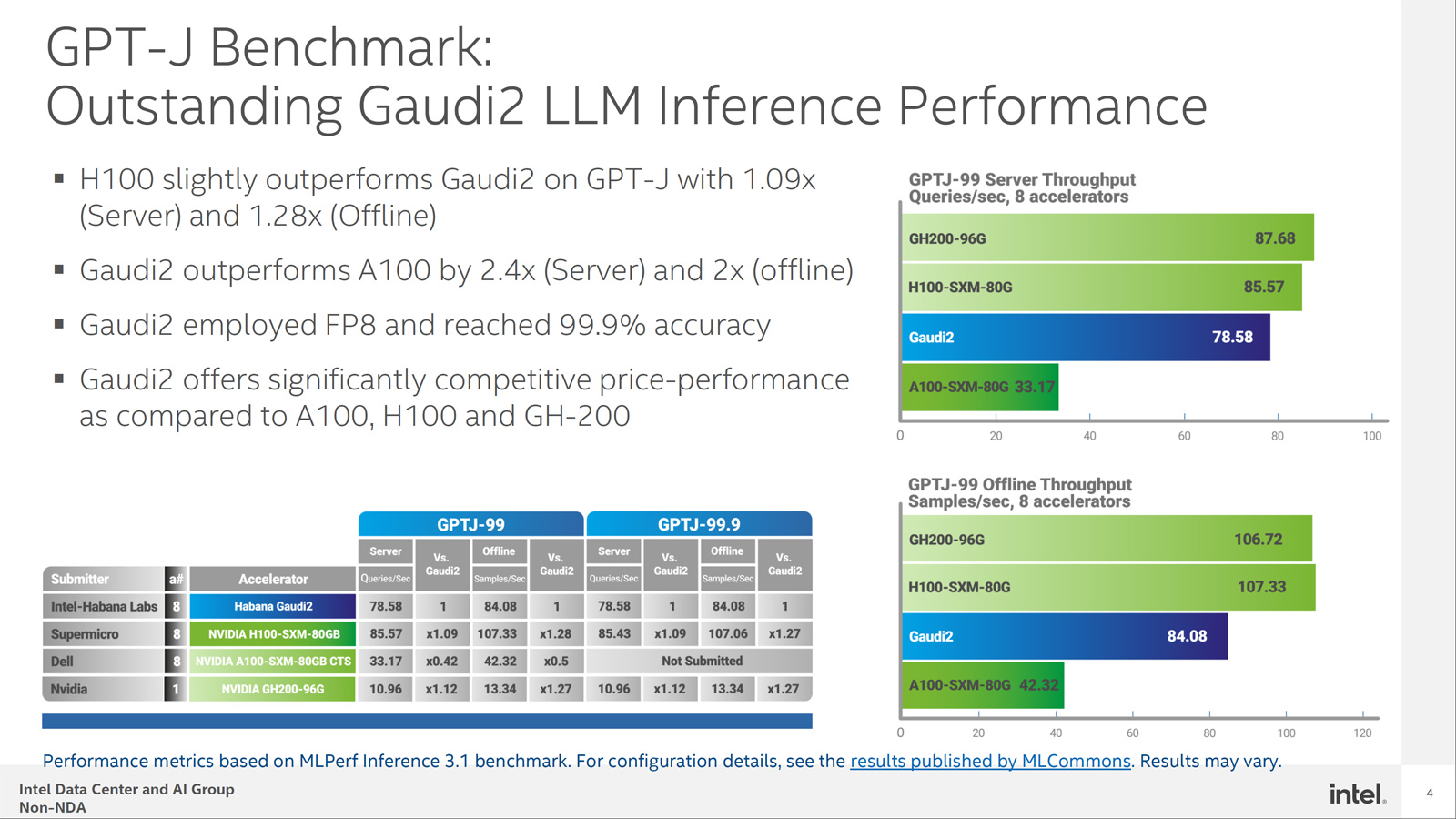
Источник изображений: Intel Тест GPT-J говорит о конкурентоспособности Habana Gaudi2. При онлайн-обработке запросов этот ускоритель достигает производительности 78,58 выборки в секунду, а в автономном режиме — 84,08 выборки в секунду. Для сравнения: у NVIDIA H100 эти показатели равны соответственно 85,57 и 107,33 выборки в секунду.  В дальнейшем Intel планирует повышать производительность и расширять охват моделей в тестах MLPerf посредством регулярных обновлений программного обеспечения. Но Intel всё равно остаётся в догоняющих — NVIDIA подготовила открытый и бесплатный инструмент TensorRT-LLM, который не только вдвое ускоряет исполнение LLM на H100, но и даёт некоторый прирост производительности и на старых ускорителях.
13.09.2023 [15:04], Сергей Карасёв
ИИ-стартап Axelera представил платформу Metis AI для периферийных вычисленийМолодая компания Axelera AI B.V. сообщила о начале поставок платформы Metis AI, разработанной специально для ускорения ИИ-задач на периферии. Стартап, основанный в 2021 году, получил финансирование на сумму более $50 млн. Чип Axelera основан на открытой архитектуре RISC-V. В базовом варианте платформа Metis AI обеспечивает производительность до 39,3 TOPS. Увеличив тактовую частоту, быстродействие можно довести до 48,16 TOPS. Изделие предлагается в различных вариантах исполнения, включая карты расширения PCIe (FHHL), модули М.2 2280 и полноценные системы для задач машинного зрения. В частности, карты PCIe AI Edge доступны в версиях с одним и несколькими чипами с общей производительностью до 856 TOPS. Утверждается, что платформа Metis AI обладает высокой энергетической эффективностью — это важно при организации ИИ-вычислений на периферии. 
Источник изображений: Axelera AI B.V. Изделия Metis AI используют чипы Axelera Metis AIPU, содержащие четыре ядра для in-memory вычислений. Объём SRAM-кеша L1 составляет 16 Мбайт, кеша L2 — 32 Мбайт. Диапазон рабочих температур простирается от -40 до +85 °C. Гарантирована совместимость с Ubuntu 20.04/22.04 и Yocto. Разработчикам доступен набор инструментов Voyager SDK и фирменный компилятор TVM, который включает в себя средства оптимизации.  Модуль Axelera M.2 в формате 2280 наделён 512 Мбайт памяти LPDDR4x и одним чипом Axelera Metis AIPU. Энергоэффективность достигает 15 TOPS в расчёте на 1 Вт. Задействовано пассивное охлаждение; интерфейс подключения — PCIe 3.0 х4. Цена составляет €150. В свою очередь, карты Axelera PCIe AI Edge доступны в версиях с одним (+1 Гбайт набортной RAM) и четырьмя чипами Axelera Metis AIPU: в первом случае быстродействие достигает 214 TOPS (INT8), во втором — 856 TOPS. Устройства выполнены в виде однослотовых карт с интерфейсом PCIe 3.0 х4 и PCIe 3.0 х16. Применена система активного охлаждения с вентилятором. Цена составляет около €200 и €500 соответственно.
09.09.2023 [14:38], Сергей Карасёв
Сила оптимизации ПО: NVIDIA вдвое ускорила исполнение языковых моделей на H100 с помощью TensorRT-LLMКомпания NVIDIA анонсировала программное обеспечение TensorRT-LLM с открытым исходным кодом, специально разработанное для ускорения исполнения больших языковых моделей (LLM). Платформа станет доступна в ближайшие недели. Отмечается, что NVIDIA тесно сотрудничает с такими компаниями, как Meta✴, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (входит в состав Databricks), OctoML, Tabnine и Together AI, для ускорения и оптимизации LLM. Однако большой размер и уникальные характеристики LLM могут затруднить их эффективное внедрение. Библиотека TensorRT-LLM как раз и призвана решить проблему. 
Источник изображений: NVIDIA ПО включает в себя компилятор глубокого обучения TensorRT, оптимизированные ядра (kernel), инструменты предварительной и постобработки, а также компоненты для повышения производительности на ускорителях NVIDIA. Платформа позволяет разработчикам экспериментировать с новыми LLM, не требуя глубоких знаний C++ или CUDA. Применяется открытый модульный API Python для определения, оптимизации и выполнения новых архитектур и внедрения усовершенствований по мере развития LLM. По оценкам NVIDIA, применение TensorRT-LLM позволяет вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). При использовании модели Llama2 прирост быстродействия по сравнению с А100 достигает 4,6x. TensorRT-LLM уже включает полностью оптимизированные версии многих популярных LLM, включая Meta✴ Llama 2, OpenAI GPT-2 и GPT-3, Falcon, Mosaic MPT, BLOOM и др. 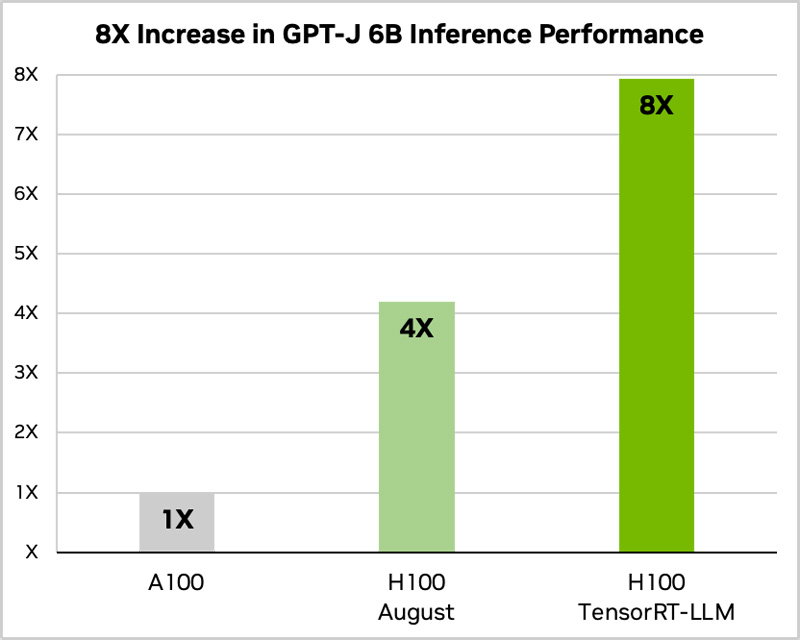 Софт TensorRT-LLM использует тензорный параллелизм — тип параллелизма моделей, при котором отдельные весовые матрицы разделяются между устройствами. При этом TensorRT-LLM автоматически распределяет нагрузка между несколькими ускорителями, связаннными посредством NVLink, или множественными узлами, объединёнными NVIDIA Quantum 2 InfiniBand. Это позволяет легко масштабировать задачи инференса с одного ускорителя до целой стойки. Для управления нагрузками TensorRT-LLM использует специальный метод планирования — пакетную обработку в реальном времени, которая позволяет асинхронно обслуживать множество мелких запросов совместно с единичными большими на одном и том же ускорителе. Эта функция доступна для всех актуальных ускорителей NVIDIA, причём именно она даёт двукратный прирост производительности инференса в случае H100. 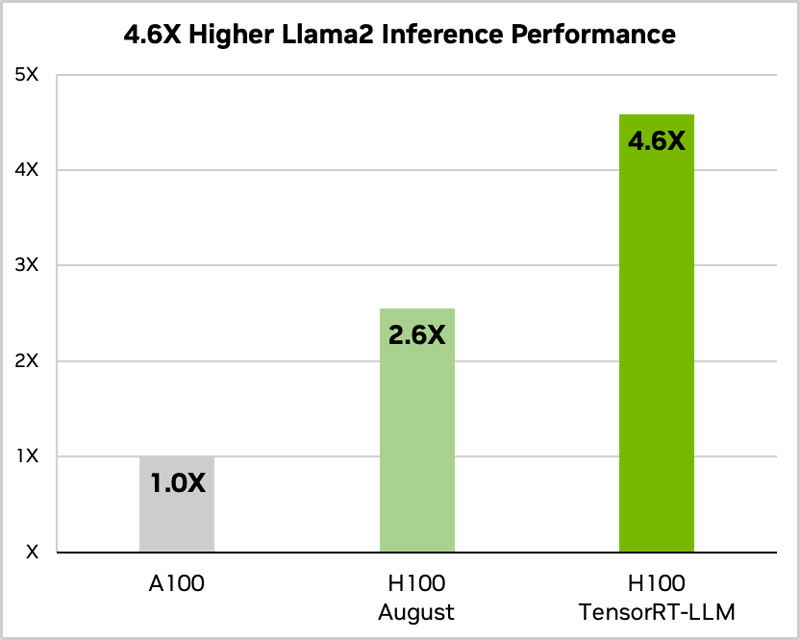 Наконец, конкретно в случае H100 библиотека активно использует возможностиTransformer Engine, позволяющего динамически привести вычисления к FP8-формату, что ускоряет и обработку и снижает потребление памяти без ухудшения точности итогового результата. Одна эта функция позволяет добиться четырёхкратного прироста быстродействия H100 в сравнении с A100.
24.08.2023 [16:27], Владимир Мироненко
AMD приобрела французскую компанию Mipsology, разработчика ИИ-решений для FPGAAMD объявила о приобретении компании Mipsology из Палезо (Франция), специализирующейся в области программного обеспечения для искусственного интеллекта, с которой её связывают давние партнёрские отношения. Как ожидается, команда разработчиков Mipsology поможет AMD разработать полный стек ИИ-решений и упростит развёртывание ИИ на оборудовании AMD. Основанная в 2015 году компания Mipsology разрабатывает передовые решения для инференса и инструменты оптимизации нагрузок, адаптированные для оборудования AMD. Флагманское ПО Zebra компании поддерживает отраслевые платформы, включая TensorFlow, PyTorch и ONNX Runtime, и помогает ускорить развёртывание инференс-нагрузок на CPU и FPGA. Также ПО поддерживает программный стек AMD Unified AI (UAI). 
Источник изображения: AMD «ИИ является нашим главным стратегическим приоритетом и важным фактором роста спроса на полупроводники в ближайшее десятилетие. Приветствуя квалифицированную команду Mipsology в AMD, мы продолжим расширять возможности нашего программного обеспечения, чтобы позволить клиентам по всему миру использовать огромный потенциал повсеместного ИИ», — отметил представитель AMD в блоге компании.
05.08.2023 [22:34], Сергей Карасёв
Hailo представила ИИ-ускорители Hailo-8 Century с производительностью до 208 TOPSСтартап Hailo Technologies, разработчик ИИ-чипов, анонсировал изделие начального уровня Hailo-8L, а также семейство ускорителей Hailo-8 Century, выполненных в виде карт расширения с интерфейсом PCle х16. Чип Hailo-8L предназначен для работы с приложениями, которым не требуется слишком высокое ИИ-быстродействие. Он обеспечивает производительность на уровне 13 TOPS. Выделяется простота интеграции с оборудованием; изделию не требуется внешняя память. Стандартное энергопотребление составляет 1,5 Вт. 
Источник изображения: Hailo Technologies Низкопрофильные карты Hailo-8 Century в зависимости от варианта исполнения имеют половинную или полную длину. Они несут на борту от 2 до 16 чипов Hailo-8, что обеспечивает быстродействие от 52 до 208 TOPS. Энергопотребление при этом варьируется от 10 до 65 Вт. Говорится, что ускорители Hailo-8 Century предоставляют лучшую в своём классе энергетическую эффективность с показателем 400 FPS/Вт в ResNet50. Стоимость Century начинается с $249 за версию с быстродействием 52 TOPS. Гарантирована совместимость с Linux и Windows, а также с фреймворками Tensorflow (Lite), Keras, Pytorch и ONNX. Все представленные изделия имеют широкий диапазон рабочих температур — от -40 до +85 °C. Решения уже доступны для предварительного заказа.
09.07.2023 [18:07], Алексей Степин
AMX и HBM2e обеспечивают Intel Xeon Max серьёзное преимущество в некоторых ИИ-нагрузкахВ Сети продолжают появляться новые данные о производительности процессоров Intel Xeon Max с набортной памятью HBM2e объёмом 64 Гбайт. На этот раз ресурс Phoronix опубликовал сравнительные результаты тестирования двухпроцессорных платформ Xeon Max 9480 в сравнении с решениями AMD EPYC 9004. Не секрет, что процессоры Intel Xeon существенно уступают по максимальному количеству ядер решениям AMD EPYC уже давно — даже у обычных Sapphire Rapids их не более 60, а у Xeon Max и вовсе в максимальной конфигурации лишь 56 ядер. Однако Intel в этом поколении старается взять своё не числом, а уменьем — поддержкой новых расширений, в частности, AMX. В новом тестировании ИИ-нагрузок, опубликованном Phoronix, приняла участие двухпроцессорная система на базе Xeon Max 9480 в различных режимах (только с HBM, без HBM или с HBM в режиме кеширования), а также две двухпроцессорные системы AMD на базе EPYC 9554 (128 ядер) и EPYC 9654 (192 ядра). В качестве бенчмарков были выбраны фреймворки OpenVINO (оптимизирован для AMX) и ONNX (без глубокой оптимизации). 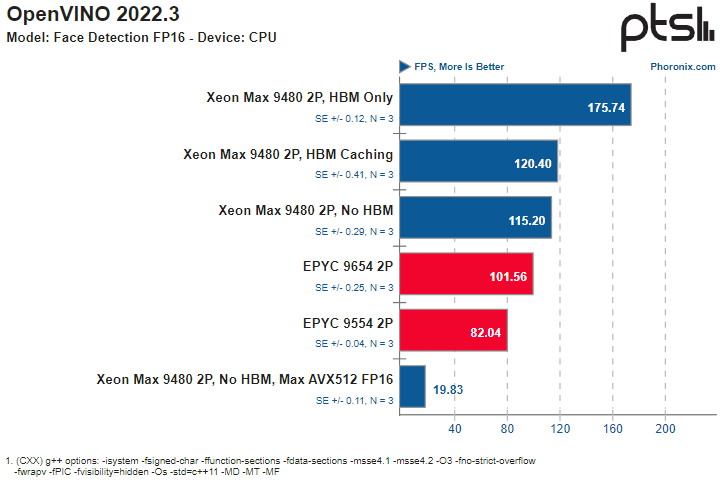
Источник здесь и далее: Phoronix В ряде тестов OpenVINO наивысший результат продемонстрирован платформой Xeon Max в режиме HBM Only, несмотря на огромное отставание по количеству ядер. И худший же результат принадлежит тоже Xeon Max, но при отключении HBM и переходу к AVX512 FP16 без использования AMX. 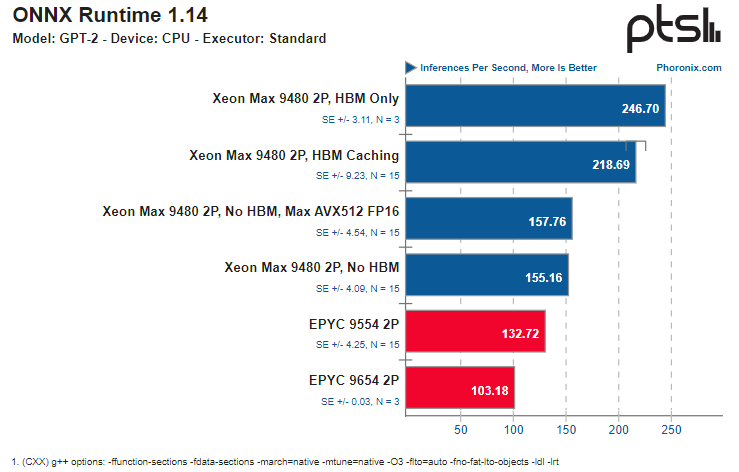 Иногда AMD удаётся взять реванш благодаря количеству ядер, причём отключение HBM2e не всегда спасает «красных» — с помощью AMX «синие» продолжают довольно уверенно лидировать во многих тестах. Тестирование в ONNX Runtime 1.14 на базе языковой модели GPT-2 также показало, что Xeon Max опережают EPYC Genoa — но серьёзный выигрыш достигается только при использовании HBM. 
Даже без HBM поддержка AMX помогает Xeon Max показать достойный результат Подход Intel демонстрирует отличные результаты: в ряде случаев переход от AVX512 к AMX позволяет поднять производительность в 2,5 раза. Благодаря HBM2e можно получить ещё около 25 %, а в целом прирост может достигать 3,13 раз. Впрочем, у AMD в запасе есть EPYC Genoa-X с огромным кешем 3D V-Cache, так что стоит подождать следующего раунда этой битвы. |
|

