Материалы по тегу: инференс
|
05.08.2023 [22:34], Сергей Карасёв
Hailo представила ИИ-ускорители Hailo-8 Century с производительностью до 208 TOPSСтартап Hailo Technologies, разработчик ИИ-чипов, анонсировал изделие начального уровня Hailo-8L, а также семейство ускорителей Hailo-8 Century, выполненных в виде карт расширения с интерфейсом PCle х16. Чип Hailo-8L предназначен для работы с приложениями, которым не требуется слишком высокое ИИ-быстродействие. Он обеспечивает производительность на уровне 13 TOPS. Выделяется простота интеграции с оборудованием; изделию не требуется внешняя память. Стандартное энергопотребление составляет 1,5 Вт. 
Источник изображения: Hailo Technologies Низкопрофильные карты Hailo-8 Century в зависимости от варианта исполнения имеют половинную или полную длину. Они несут на борту от 2 до 16 чипов Hailo-8, что обеспечивает быстродействие от 52 до 208 TOPS. Энергопотребление при этом варьируется от 10 до 65 Вт. Говорится, что ускорители Hailo-8 Century предоставляют лучшую в своём классе энергетическую эффективность с показателем 400 FPS/Вт в ResNet50. Стоимость Century начинается с $249 за версию с быстродействием 52 TOPS. Гарантирована совместимость с Linux и Windows, а также с фреймворками Tensorflow (Lite), Keras, Pytorch и ONNX. Все представленные изделия имеют широкий диапазон рабочих температур — от -40 до +85 °C. Решения уже доступны для предварительного заказа.
09.07.2023 [18:07], Алексей Степин
AMX и HBM2e обеспечивают Intel Xeon Max серьёзное преимущество в некоторых ИИ-нагрузкахВ Сети продолжают появляться новые данные о производительности процессоров Intel Xeon Max с набортной памятью HBM2e объёмом 64 Гбайт. На этот раз ресурс Phoronix опубликовал сравнительные результаты тестирования двухпроцессорных платформ Xeon Max 9480 в сравнении с решениями AMD EPYC 9004. Не секрет, что процессоры Intel Xeon существенно уступают по максимальному количеству ядер решениям AMD EPYC уже давно — даже у обычных Sapphire Rapids их не более 60, а у Xeon Max и вовсе в максимальной конфигурации лишь 56 ядер. Однако Intel в этом поколении старается взять своё не числом, а уменьем — поддержкой новых расширений, в частности, AMX. В новом тестировании ИИ-нагрузок, опубликованном Phoronix, приняла участие двухпроцессорная система на базе Xeon Max 9480 в различных режимах (только с HBM, без HBM или с HBM в режиме кеширования), а также две двухпроцессорные системы AMD на базе EPYC 9554 (128 ядер) и EPYC 9654 (192 ядра). В качестве бенчмарков были выбраны фреймворки OpenVINO (оптимизирован для AMX) и ONNX (без глубокой оптимизации). 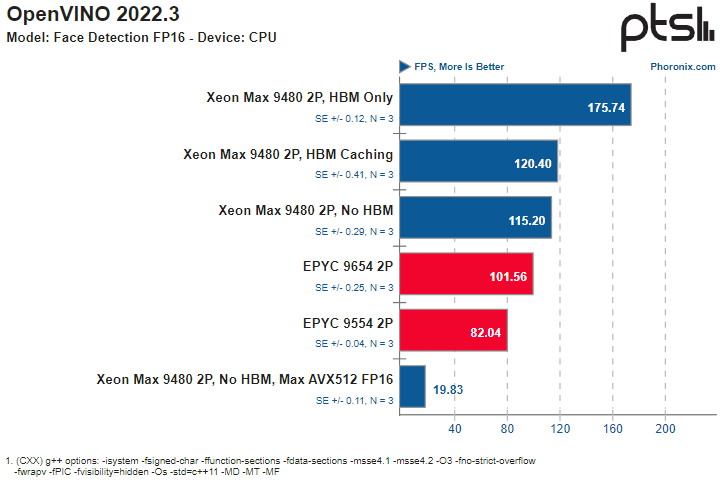
Источник здесь и далее: Phoronix В ряде тестов OpenVINO наивысший результат продемонстрирован платформой Xeon Max в режиме HBM Only, несмотря на огромное отставание по количеству ядер. И худший же результат принадлежит тоже Xeon Max, но при отключении HBM и переходу к AVX512 FP16 без использования AMX. 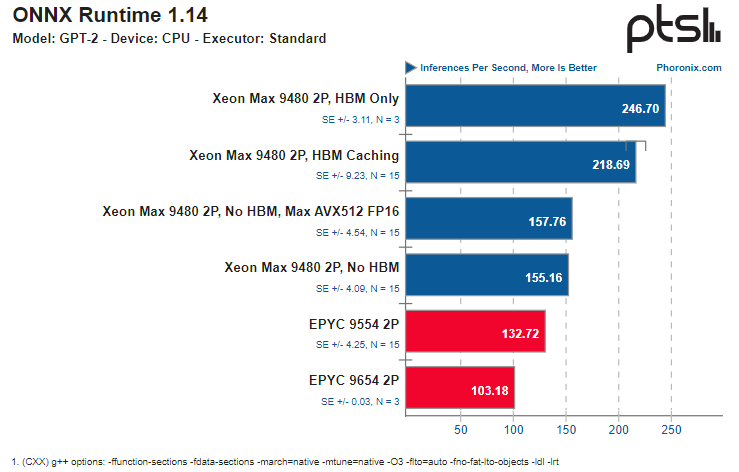 Иногда AMD удаётся взять реванш благодаря количеству ядер, причём отключение HBM2e не всегда спасает «красных» — с помощью AMX «синие» продолжают довольно уверенно лидировать во многих тестах. Тестирование в ONNX Runtime 1.14 на базе языковой модели GPT-2 также показало, что Xeon Max опережают EPYC Genoa — но серьёзный выигрыш достигается только при использовании HBM. 
Даже без HBM поддержка AMX помогает Xeon Max показать достойный результат Подход Intel демонстрирует отличные результаты: в ряде случаев переход от AVX512 к AMX позволяет поднять производительность в 2,5 раза. Благодаря HBM2e можно получить ещё около 25 %, а в целом прирост может достигать 3,13 раз. Впрочем, у AMD в запасе есть EPYC Genoa-X с огромным кешем 3D V-Cache, так что стоит подождать следующего раунда этой битвы.
30.06.2023 [12:30], Сергей Карасёв
Lightelligence представила оптический ускоритель HummingbirdКомпания Lightelligence, занимающаяся фотонными вычислениями, представила Hummingbird — специализированный оптический ускоритель, предназначенный для применения в системах, ориентированных на решение сложных задач, связанных с алгоритмами ИИ. Разработчик называет новинку «оптической сетью на чипе» (Optical Network-on-Chip, oNOC). Устройство объединяет в одном корпусе фотонный блок и традиционный электронный узел. Изделие призвано выполнять функции коммуникационного сетевого компонента для дата-центров и высоконагруженных платформ. 
Источник изображения: Lightelligence Hummingbird использует технологию Lightelligence oNOC, предназначенную для повышения производительности вычислений путём использования инновационных межсоединений на базе кремниевой фотоники. Благодаря применению света снижаются задержки и сокращается энергопотребление по сравнению с традиционными решениями. 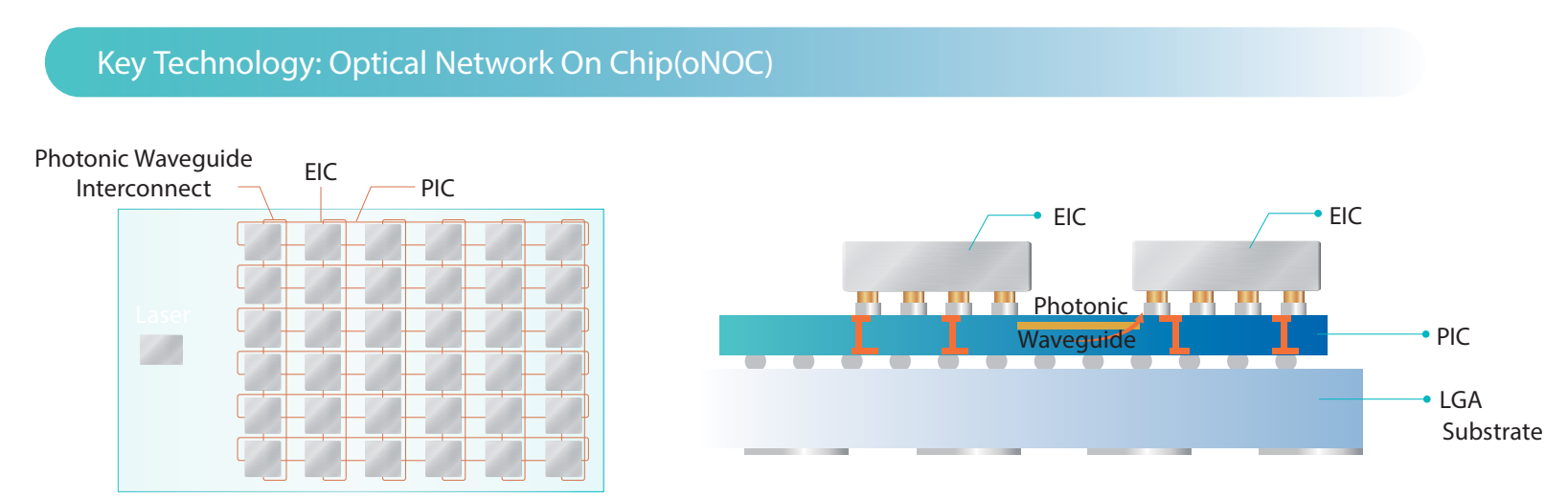
Источник изображения: Lightelligence В Hummingbird задействованы 64 передатчика и 512 приемников, 38 МиБ SRAM и 2 Гбайт DDR4. Ускоритель может стать одним из ключевых компонентов оптических сетей высокой плотности. Изделие выполнено в формате полноразмерной двухслотовой карты расширения с интерфейсом PCIe 3.0 x4, благодаря чему подходит для применения в существующих серверах. Разработчикам доступен комплект SDK для развёртывания различных приложений ИИ и машинного обучения.
05.06.2023 [22:19], Владимир Мироненко
Разработчик фотонных ИИ-ускорителей Lightmatter привлёк $154 млн инвестиций и втрое увеличил капитализациюСтартап Lightmatter сообщил о завершении раунда финансирования серии C, в результате которого он привлёк инвестиции на сумму $154 млн. В этом раунде приняли участие венчурные подразделения Alphabet и HPE, а также ряд других институциональных инвесторов. Сообщается, что после этого раунда утроилась нераскрытая оценка Lightmatter, которую стартап получил после проведения раунда финансирования в 2021 году. По словам Lightmatter, разработанный ею оптический интерконнект Passage обеспечивает до 100 раз большую пропускную способность, чем традиционные альтернативы. Ускорение перемещения данных в чипе и между чипами повышает производительность приложений. Lightmatter утверждает, что Passage занимает значительно меньше места, чем традиционные электрические соединения, и потребляет в пять раз меньше энергии. Кроме того, Passage упрощает работу с системой, позволяя автоматические менять конфигурацию интернконнекта менее чем 1 мс. 
Источник изображения: Lightmatter Lightmatter Passage является частью инференс-платформы Envise 4S, оптимизированной для работы с самыми крупными ИИ-моделями. По данным компании, система втрое быстрее, чем NVIDIA DGX A100, занимая при этом 4U-шасси и потребляя порядка 3 кВт. Сервер Envise 4S оснащён 16 фотонными ИИ-ускорителями Envise, каждый из которых содержит 500 Мбайт памяти, 400G-подключение к соседним чипам и 256 RISC-ядер общего назначения. Ускорители объединены оптической фабрикой производительностью 6,4 Тбит/с. Полученные в результате нового раунда средства компания планирует использовать для коммерциализации Passage и Envise, а также внедрения Idiom, программного инструментария, который упрощает написание приложений для Envise.
01.06.2023 [19:50], Сергей Карасёв
НТЦ «Модуль» представил серверный нейроускоритель NM Quad на отечественных чипахНаучно-технический центр (НТЦ) «Модуль» анонсировал изделие NM Quad — высокопроизводительное устройство для задач, связанных с обработкой ИИ-алгоритмов, машинным зрением, нейросетями и пр. Новинка может применяться в суперкомпьютерах и НРС-серверах. В основу NM Quad положены четыре DSP-процессора К1879ВМ8Я на базе оригинальной векторно-матричной архитектуры NeuroMatrix Core 4. В состав каждого DSP входят четыре независимых вычислительных кластера, насчитывающих по четыре ядра NMC4. Таким образом, общее количество ядер NeuroMatrixCore4 достигает 64 (FP32/64). Они функционируют на частоте до 1 ГГц. 
Источник изображения: НТЦ «Модуль» Пользователь может самостоятельно выбрать режим работы DSP — обрабатывать данные всеми четырьмя кластерами сразу, либо дать каждому из них собственную задачу. Таким образом, доступны 16 независимых вычислительных кластеров, каждый из которых может быть настроен на индивидуальную работу или задействован параллельно с другими. Заявленная FP32-производительность составляет 2 Тфлопс, FP64 — 0,5 Тфлопс. 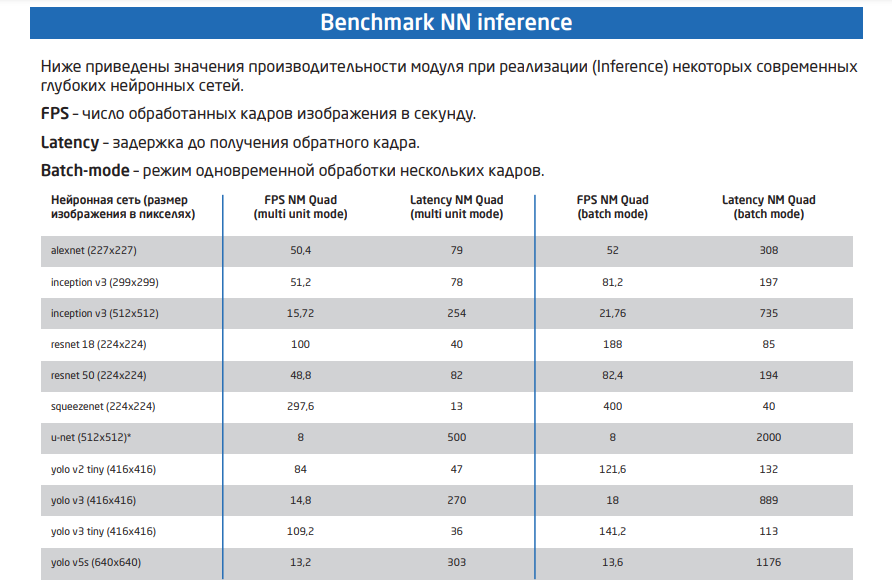
Источник: НТЦ «Модуль» Кроме того, в состав NM Quad входят 20 ядер Arm Cortex-A5 с частотой 800 МГц, 512 Кбайт кеша L2 в расчёте на процессор и 20 Гбайт памяти DDR3L. Суммарная пропускная способность интерфейсов межпроцессорного обмена достигает 160 Гбит/с. Модуль выполнен в виде двухслотовой карты расширения с интерфейсом PCIe x16 (PCIe 2.0 x4). Габариты составляют 277 × 143 × 39 мм. Заявленная потребляемая мощность не превышает 80 Вт (50 Вт при обычных нагрузках). 
Источник изображения: НТЦ «Модуль»
03.05.2023 [21:12], Владимир Мироненко
MosaicML представила инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation SeriesMosaicML, провайдер инфраструктуры генеративного искусственного интеллекта, основанный бывшими сотрудниками Intel и учёными-исследователями, анонсировал инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation Series, которые компании могут задействовать в качестве основы при создании собственных моделей ИИ. Как сообщается в пресс-релизе, это решение позволит разработчикам быстро, легко и по доступной цене развёртывать генеративные модели ИИ. «Благодаря добавлению возможностей инференса MosaicML теперь предлагает комплексное решение для обучения и развёртывания генеративного ИИ по наиболее эффективной цене, доступной на сегодняшний день», — отмечено в документе. Клиенты MosaicML отметили, что малые модели, обученные на собственных предметно-ориентированных данных, работают лучше, чем большие универсальные модели вроде GPT 3.5. 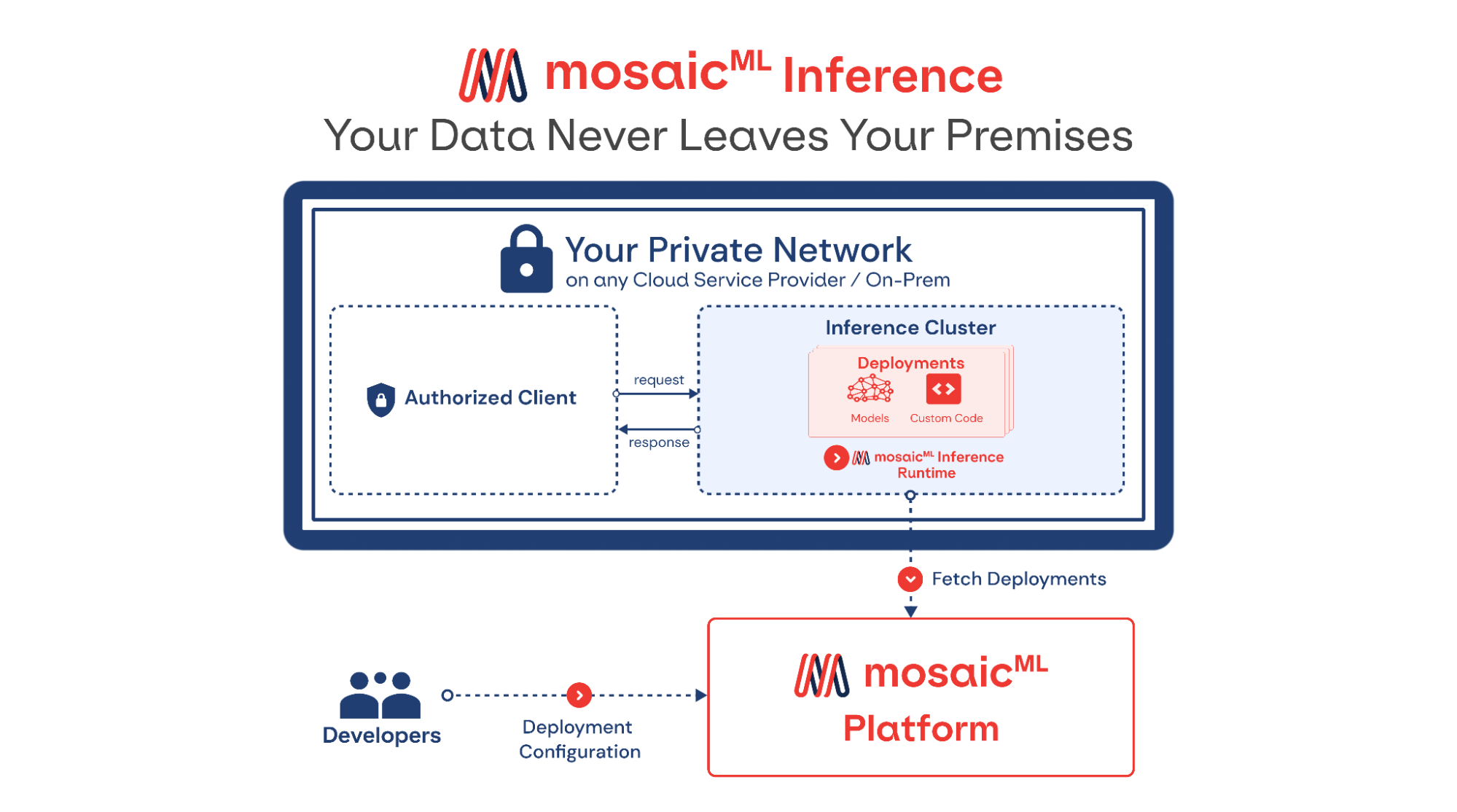
Источник изображений: MosaicML Гендиректор Навин Рао (Naveen Rao) сообщил ресурсу SiliconANGLE, что ценность решения компании для корпоративных клиентов включает два компонента: сохранение конфиденциальности и снижение затрат. Используя решение Inference от MosaicML, клиенты смогут развёртывать ИИ-модели с затратами в четыре раза меньше, чем при использовании большой языковой модели (LLM) от OpenAI, и в 15 раз дешевле при создании изображений, чем при использовании DALL-E 2 этой же компании. «Мы предоставляем инструменты, работающие в любом облаке, которые позволяют клиентам предварительно обучать, настраивать и обслуживать модели, — сказал Рао. — Если клиент обучает модель, он может быть уверен, что эта модель принадлежит ему». С запуском нового сервиса клиенты MosaicML получают доступ к ряду LLM с открытым исходным кодом, включая Instructor-XL, Dolly и GPTNeoX, которые они могут точно настроить в соответствии со своими потребностями. Все модели получат одинаковую оптимизацию и доступность, что позволит им функционировать с меньшими затратами при развёртывании с помощью MosaicML Inference. 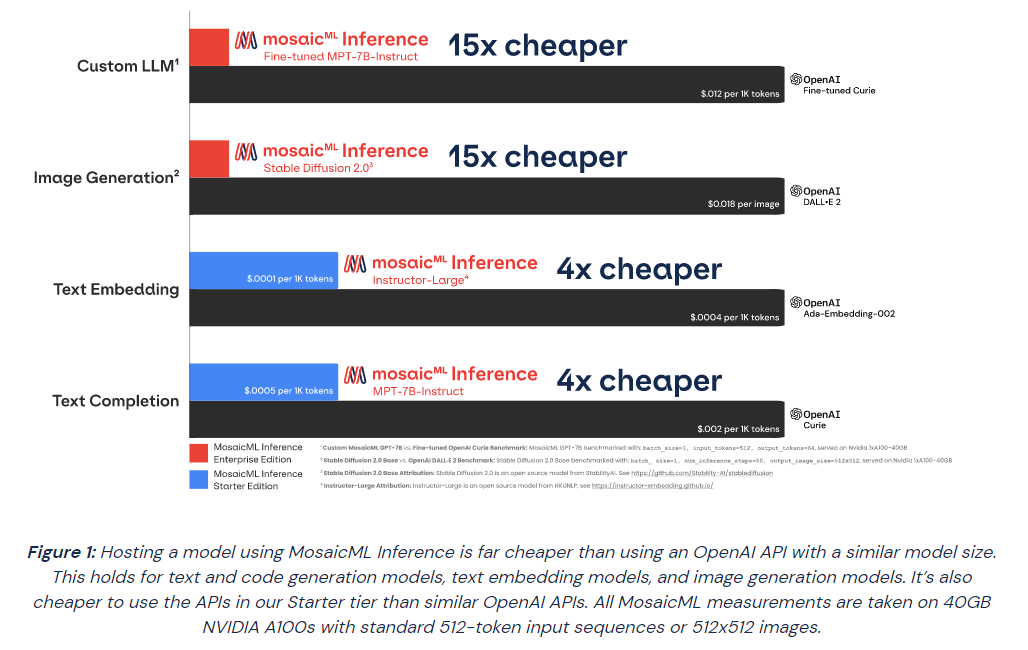 «Это модели с открытым исходным кодом, поэтому клиенты по определению могут настраивать и настраивать и обслуживать их с помощью наших инструментов, — сказал Рао. Компания готова помочь клиентам в работе с их ИИ-моделям. Разработчики смогут выполнять развёртывание в безопасном кластере локально или в облачной инфраструктуре AWS, CoreWeave, Lambda, OCI и GCP. Данные никогда не покидают защищённую среду. Также MosaicML Inference предлагает непрерывный мониторинг метрик кластера. Кроме того, компания предлагает модель MosaicML Foundational Model, одним из преимуществ которой является очень большое «контекстное окно» — более 64 тыс. токенов или около 50 тыс. слов. Для сравнения, максимальное количество токенов GPT-4 составляет 32 768 или около 25 тыс. слов. Чтобы продемонстрировать работу модели, Рао предоставил ей содержание «Великого Гэтсби» Ф. Скотта Фицджеральда и попросил написать эпилог.
14.04.2023 [01:03], Владимир Мироненко
AWS объявила о доступности EC2-инстансов Inf2 на базе фирменных ИИ-ускорителей Inferentia2AWS объявила об общедоступности недорогих и высокопроизводительных инференс-инстансов Amazon EC2 Inf2 для генеративного ИИ. Новинки используют фирменные ИИ-ускорители Inferentia2. Как утверждает AWS, это самый экономичный и энергоэффективный вариант запуска моделей генеративного ИИ, таких как GPT-J или Open Pre-Trained Transformer (OPT). По сравнению с инстансами Amazon EC2 Inf1 инстансы Inf2 обеспечивают до 4 раз более высокую пропускную способность и до 10 раз меньшую задержку (в таких же пределах ускорители Inferentia2 превосходят Inferentia). В настоящее время доступно четыре варианта инстансов Inf2, имеющих до 12 ускорителей AWS Inferentia2 со 192 vCPU, связанных интерконнектом NeuronLink v2. Их совокупная вычислительная мощность достигает 2,3 Пфлопс (BF16 или FP16). 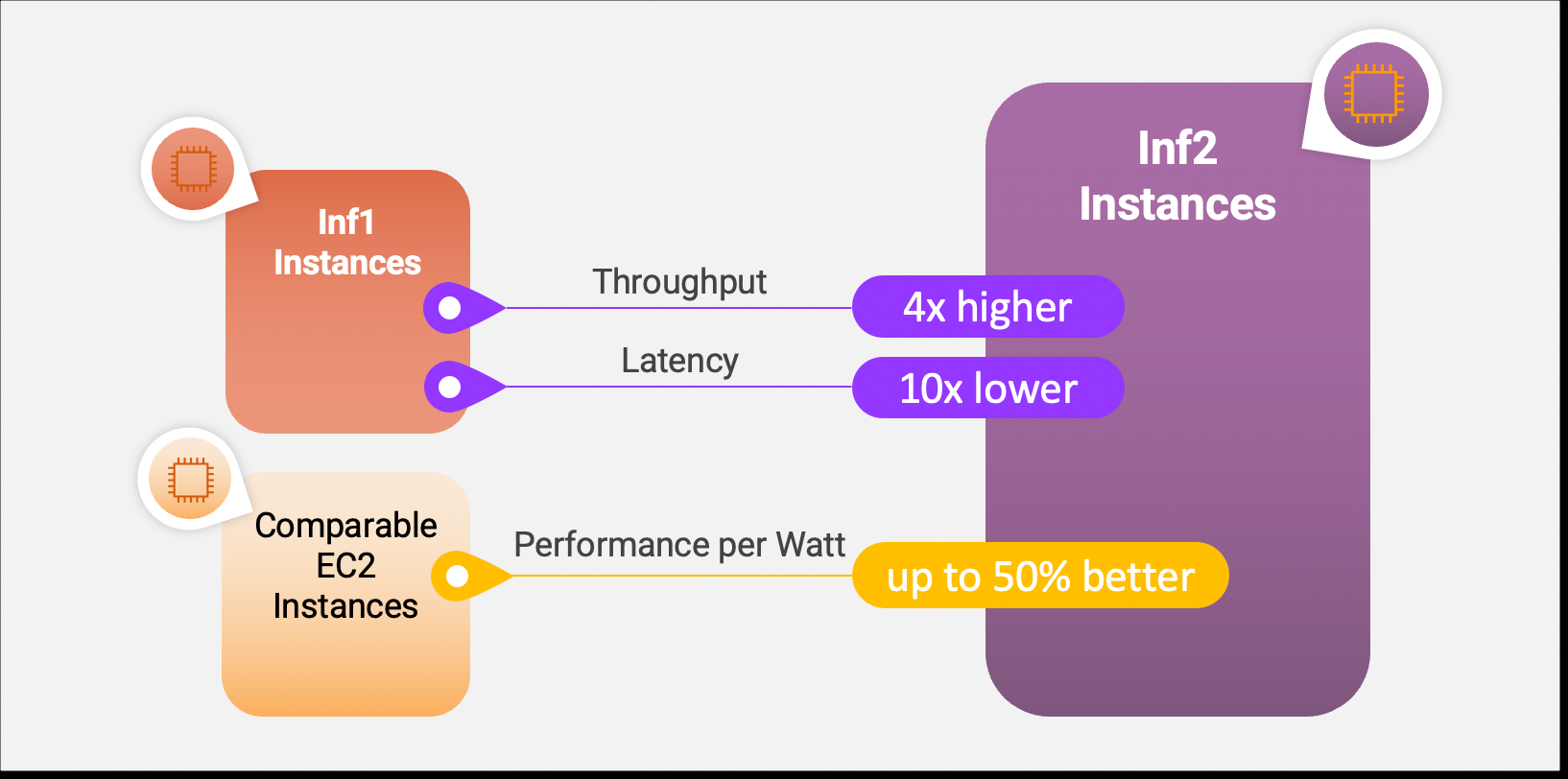
Источник изображений: AWS Инстансы Inf2 предлагают до 384 Гбайт общей памяти, по 32 Гбайт памяти HBM у каждого чипе Inferentia2, и общую пропускную способность памяти (ПСП) 9,8 Тбайт/с. Такая ПСП особенно важна для для исполнения больших языковых моделей (LLM). А поскольку чипы AWS Inferentia2 специально созданы для ИИ-нагрузок DL, инстансы Inf2 показывают не менее чем на 50 % лучшее соотношение производительности на Ватт по сравнению с другими сопоставимыми EC2-инстансами. 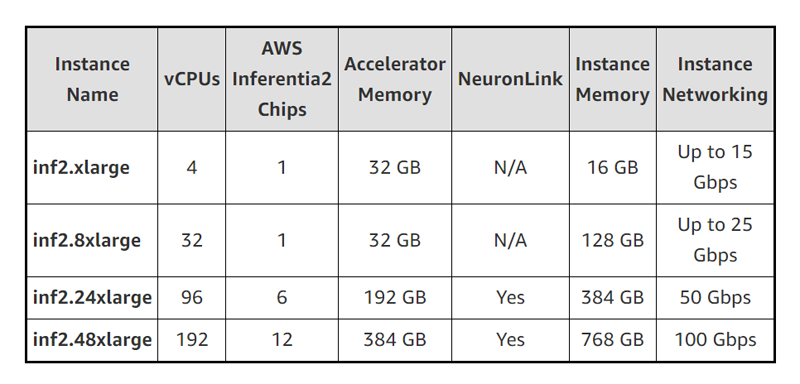 Как и ускоритель AWS Trainium, AWS Inferentia2 имеет два блока NeuronCore-v2, стеки HBM и выделенные механизмы коллективных вычислений для распараллеливания нагрузки на нескольких ускорителях. NeuronCore-v2 включает аппаратные движки для скалярных, векторных и тензорных (матричных) вычислений, а также 512-бит блок GPSIMD, блоки DSP, SRAM и некоторые другие узкоспециализированные движки. Ускоритель поддерживает выполнение кастомных обработчиков (C/C++, PyTorch). 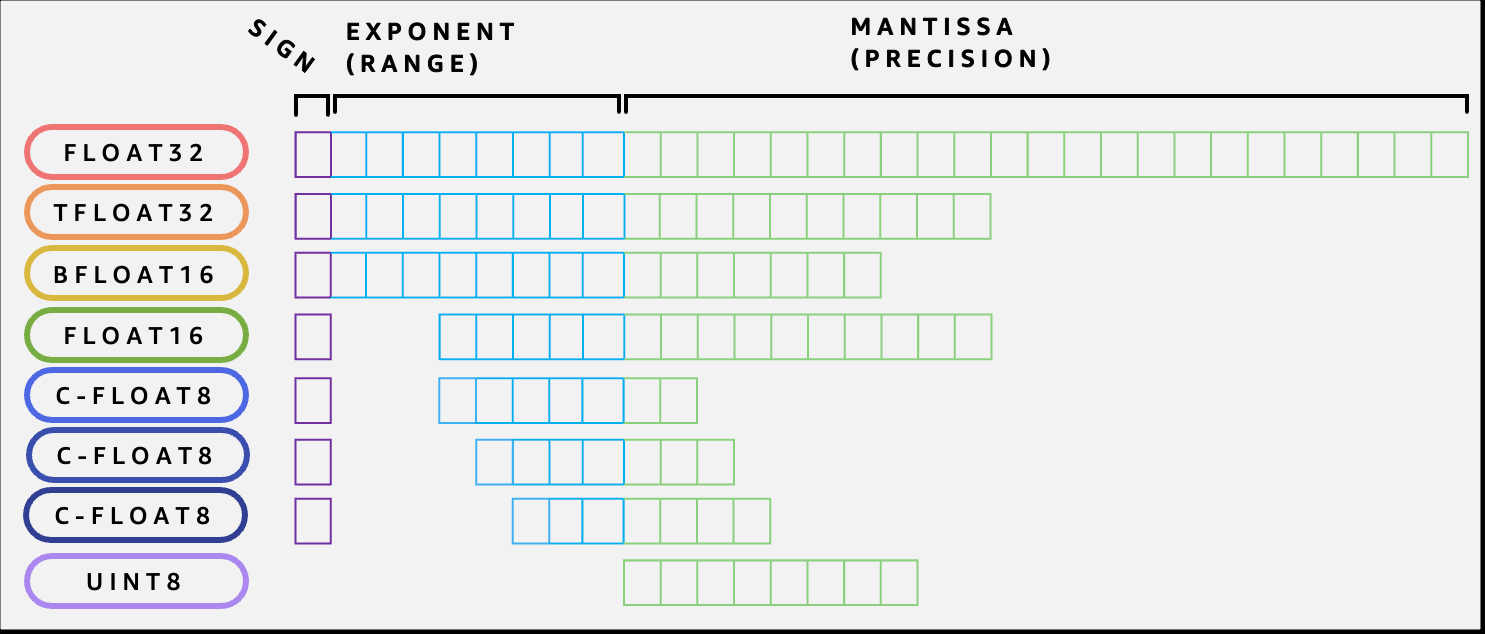 AWS Inferentia2 поддерживает широкий спектр типов данных, включая FP32, TF32, BF16, FP16 и UINT8, позволяя выбрать наиболее подходящий тип данных для своих рабочих нагрузок. Он также поддерживает новый настраиваемый тип данных FP8 (cFP8), который особенно актуален для больших моделей. По словам компании, такие гибкость и реконфигурируемость чипа позволяют добиться максимальной эффективности выполнения ИИ-нагрузок.
09.04.2023 [00:25], Владимир Мироненко
NVIDIA снова поставила рекорды в ИИ-бенчмарке MLPerf Inference, но конкурентов у неё становится всё большеОткрытый инженерный консорциум MLCommons опубликовал последние результаты ИИ-бенчмарка MLPerf Inference (v3.0). В этот раз поступили заявки на тестирование от 25 компаний, в то время как прошлой осенью в тестировании приняли участие 21 компания и 19 — прошлой весной. Ресурс HPCWire выделил наиболее примечательные результаты и обновления последнего раунда. Компании предоставили более 6700 результатов по производительности и более 2400 измерений производительности и энергоэффективности. В число участников вошли Alibaba, ASUS, Azure, cTuning, Deci.ai, Dell, Gigabyte, H3C, HPE, Inspur, Intel, Krai, Lenovo, Moffett, Nettrix, NEUCHIPS, Neural Magic, NVIDIA, Qualcomm, Quanta Cloud Technology, rebellions, SiMa, Supermicro, VMware и xFusion, причем почти половина из них также измеряла энергопотребление во время тестов. 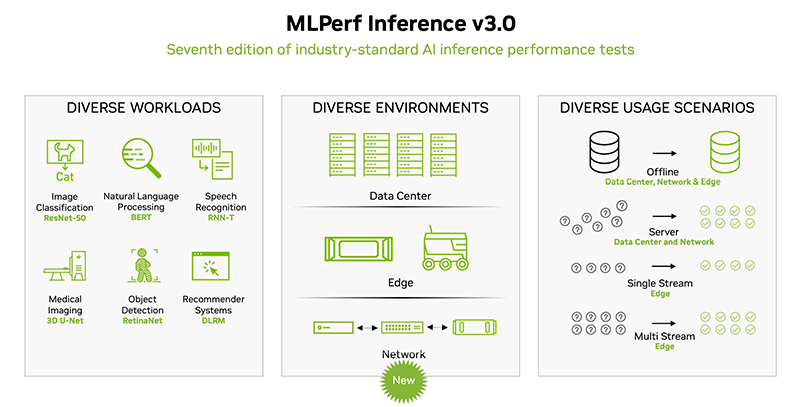
Источник изображений: hpcwire.com Отмечено, что компании cTuning, Quanta Cloud Technology, Relations, SiMa и xFusion предоставили свои первые результаты, компании cTuning, NEUCHIPS и SiMa провели первые измерения энергоэффективности, а неоднократно принимавшие участие вендоры HPE, NVIDIA и Qualcomm представили расширенные и обновлённые результаты тестов. 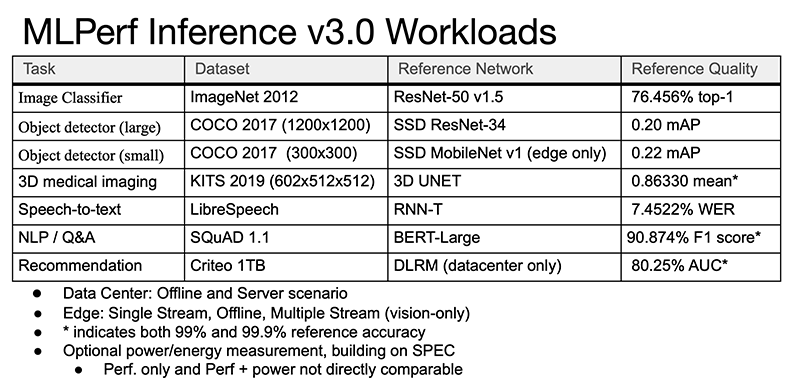 Набор тестов в MLPerf Inference 3.0 не изменился, но был добавлен новый сценарий — сетевой. Кроме того, были предоставлены улучшенные показатели инференса для Bert-Large, что представляет особый интерес, поскольку по своей природе он наиболее близок к большим языковым моделям (LLM), таким как ChatGPT. Хотя инференс, как правило, не требует столь интенсивных вычислений, как обучение, всё же является критически важным элементом в реализации ИИ. 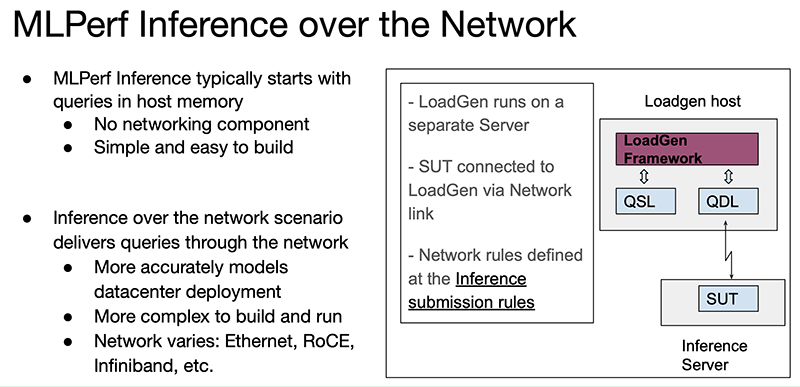 В целом, NVIDIA продолжает доминировать по показателям производительности, лидируя во всех категориях. Вместе с тем стартапы Neuchips и SiMa обошли NVIDIA по производительности в пересчёте на Ватт по сравнению с показателями NVIDIA H100 и Jetson AGX Orin соответственно. Ускоритель Qualcomm Cloud AI100 также показал хорошие результаты энергоэффективности в сравнении NVIDIA H100 в некоторых сценариях. NVIDIA продемонстрировала производительность нового ускорителя H100, а также недавно вышедшего L4. Как отметил директор NVIDIA по ИИ, бенчмаркингу и облачным технологиям, компании удалось добиться прироста производительности до 54 % по сравнению с первыми заявками шестимесячной давности. Отдельно подчёркивается более чем трёхкратный прирост производительности L4 в сравнении с T4, а также эффективность работы ПО с Transformer Engine. 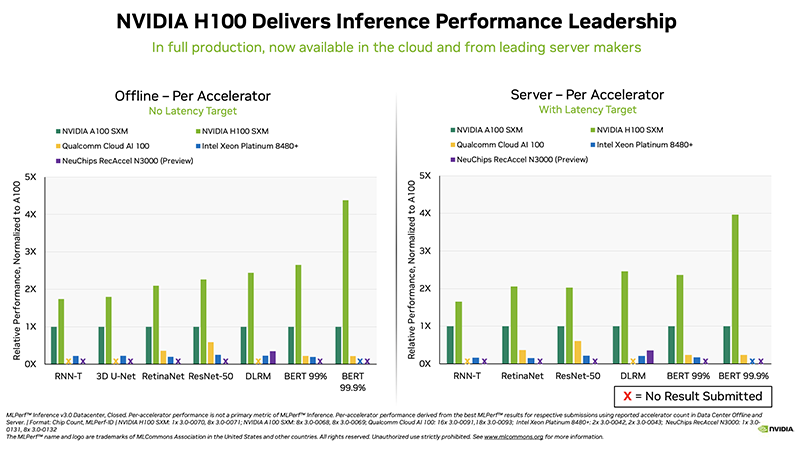 Наконец, ещё один любопытный отчёт совместно подготовили VMware, NVIDIA и Dell. Виртуализированная система с H100 «достигла 94 % из 205 % производительности bare metal», задействовав 16 vCPU и из 128 доступных. Оставшиеся 112 vCPU, как отмечается, могут быть использованы для других рабочих нагрузок и не влияют на производительность инференса.  В последнем раунде MLPerf Inference компания Intel также представила интересные результаты в предварительной категории, предназначенной для продуктов, выход которых ожидается в течение шести месяцев. В этом раунде Intel представила в закрытой заявке для ЦОД одноузловые системы (1-node-2S-SPR-PyTorch-INT8) с двумя процессорами Sapphire Rapids (Intel Xeon Platinum 8480+).  Qualcomm отметила, что её ускоритель Cloud AI 100 неизменно показывает хорошие результаты MLPerf, демонстрируя низкую задержку и высокую энергоэффективность. Компания сообщила, что ее результаты в MLPerf Inference 3.0 превзошли все её предыдущие рекорды по пиковой производительности в автономном режиме, энергоэффективности и более низким задержкам во всех категориях. Со времён MLPerf 1.0 производительность Cloud AI 100 выросла на 86 %, а энергоэффективность — на 52%. Всё это достигнуто благодаря оптимизации ПО, так что отказ Meta✴ в своё время от этих чипов выглядит обоснованным.
23.03.2023 [19:44], Алексей Степин
Google Cloud представила инстансы G2 с ускорителями NVIDIA L4На GTC 2023 корпорация NVIDIA анонсировала новые ускорители для инференс-систем — сверхмощный H100 NVL и компактный L4. Последний предлагает приличную производительность в форм-факторе HHHL. Google Cloud уже воспользовалась последней новинкой и объявила о доступности инстансов G2 с ускорителями NVIDIA L4. Инференс-задачи требуют от ускорителя быстрой обработки входных данных. Google Cloud предлагает использовать G2 именно в таком качестве и говорит о возможном снижении инфраструктурной стоимости на 40 %. Также говорится о повышении производительности в сравнении с NVIDIA T4, ускорителями аналогичного класса, но предыдущего поколения. 
NVIDIA L4 (Источник: NVIDIA) В зависимости от задачи прирост может варьироваться от двух до четырёх раз. Карта развивает почти 500 Топс (INT8/FP8) и несёт на борту 24 Гбайт памяти с ПСП 300 Гбайт/с. Впрочем, L4 достаточно универсален и может использоваться в любых сценариях, от HPC и рендеринга 3D-графики до параллельного транскодирования потокового видеоконтента. В том числе новинка поддерживает трассировку лучей, технологию масштабирования DLSS 3.0, а также аппаратное кодирование в формате AV1. В настоящее время новые виртуальные машины доступны в виде закрытого превью, количество используемых ускорителей — от 1 до 8. Инстансы G2 доступны в регионах us-central1, asia-southeast1, europe-west4, а запрос на доступ к ним можно оставить, использовав приведённую ссылку. Также новые ускорители вскоре станут доступны в Google Kubernetes Engine (GKE), Vertex AI и других облачных сервисах.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 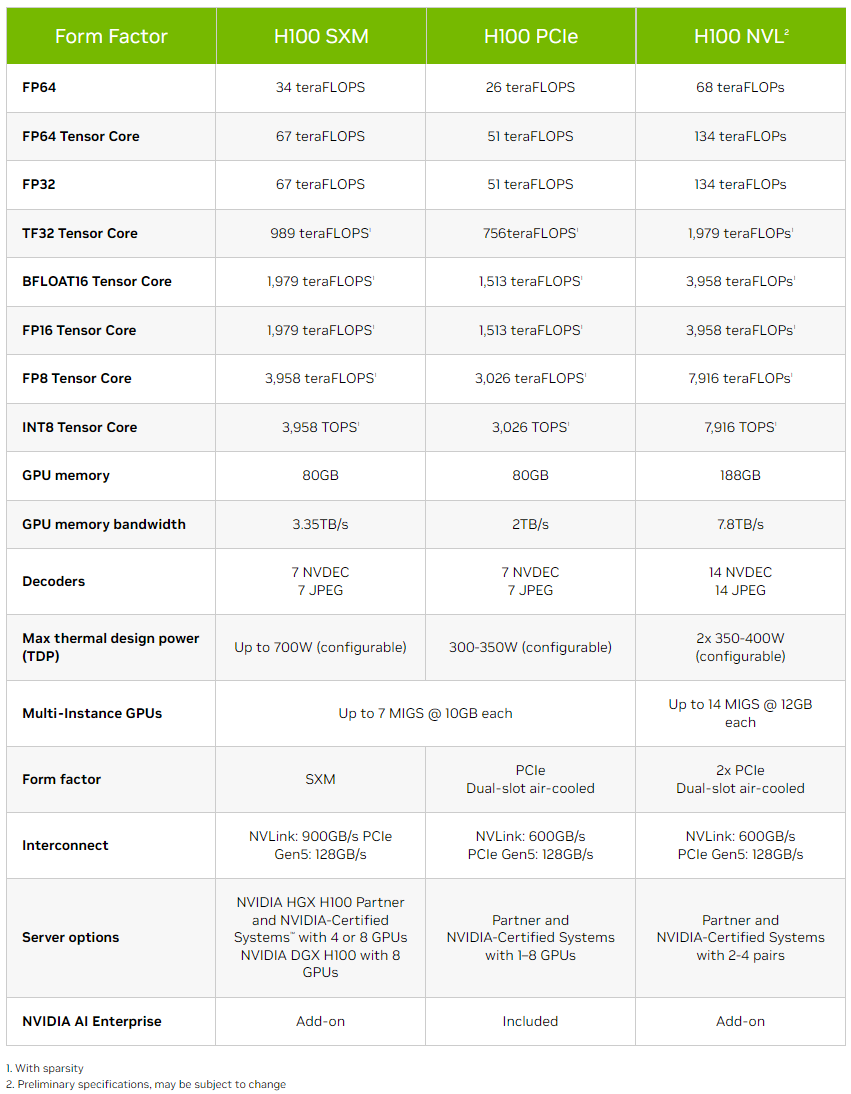 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 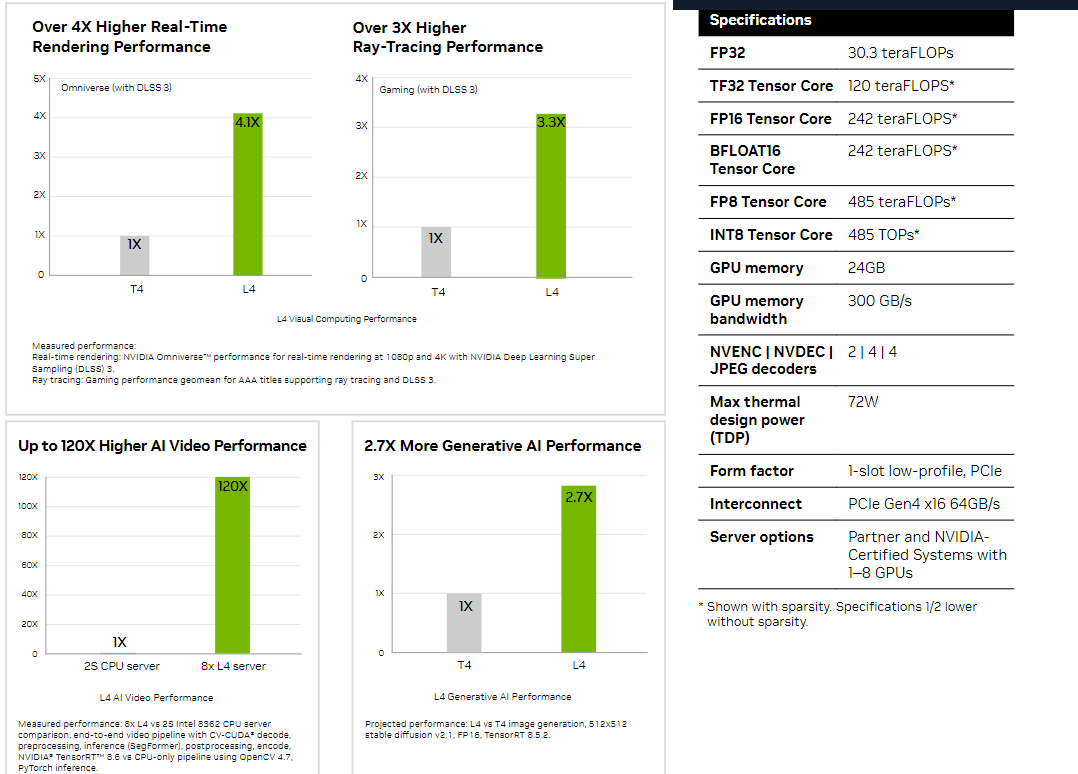 |
|

