Материалы по тегу: fpga
|
11.04.2024 [14:47], Сергей Карасёв
AMD представила гибридные FPGA Versal Gen 2 для встраиваемых систем с ИИКомпания AMD анонсировала так называемые адаптивные SoC семейства Versal второго поколения (Gen 2), предназначенные для встраиваемых систем со средствами ИИ. Утверждается, что чипы обеспечивают до трёх раз более высокий показатель производительности TOPS/Вт по сравнению с решениями Versal AI Edge первого поколения. Дебютировали чипы серий Versal AI Edge Gen 2 и Versal Prime Gen 2. Изделия первого семейства, как утверждается, содержат оптимальный набор блоков для решения задач на встраиваемых системах с ИИ: это предварительная обработка данных с помощью программируемой логики FPGA, инференс и постобработка с использованием ядер Arm. 
Источник изображений: AMD Производительность INT8 у чипов Versal AI Edge Gen 2 в зависимости от модификации варьируется от 31 до 185 TOPS, быстродействие MX6 — от 61 до 370 TOPS. В составе процессора приложений задействованы ядра Arm Cortex-A78AE, количество которых может составлять 4 или 8. Кроме того, используются 4 или 10 ядер реального времени Arm Cortex-R52. Заявлена поддержка интерфейсов PCI Express 5.0 x4, USB 3.2, DisplayPort 1.4, 10GbE и 1GbE, UFS 3.1, CAN/CAN-FD, SPI, UART, USB 2.0, I2C/I3C, GPIO.
В свою очередь, решения Versal Prime Gen 2 предназначены для ускорения задач в традиционных встраиваемых системах, которые не работают с ИИ-приложениями. Они объединяют до восьми ядер Arm Cortex-A78AE и до 10 ядер реального времени Arm Cortex-R52. Набор поддерживаемых интерфейсов аналогичен изделиям Versal AI Edge Gen 2. Говорится о возможности многоканальной обработки видео в формате 8K. 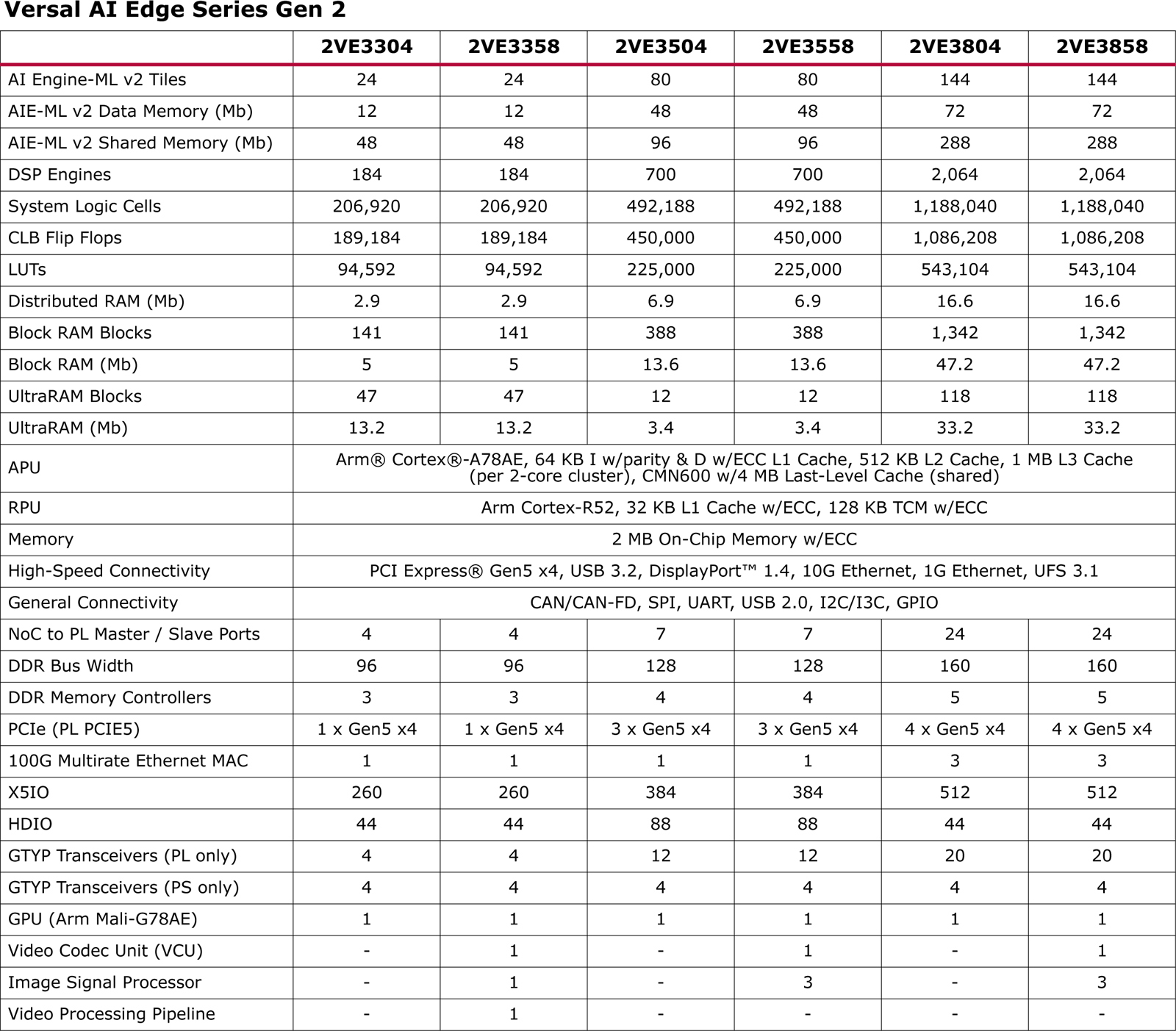 Отмечается, что новые процессоры лягут в основу систем для автомобильной, аэрокосмической и оборонной отраслей, промышленности, а также сфер машиностроения, здравоохранения, вещания и пр. Чипы позволяют разрабатывать высокопроизводительные продукты для периферийных вычислений. 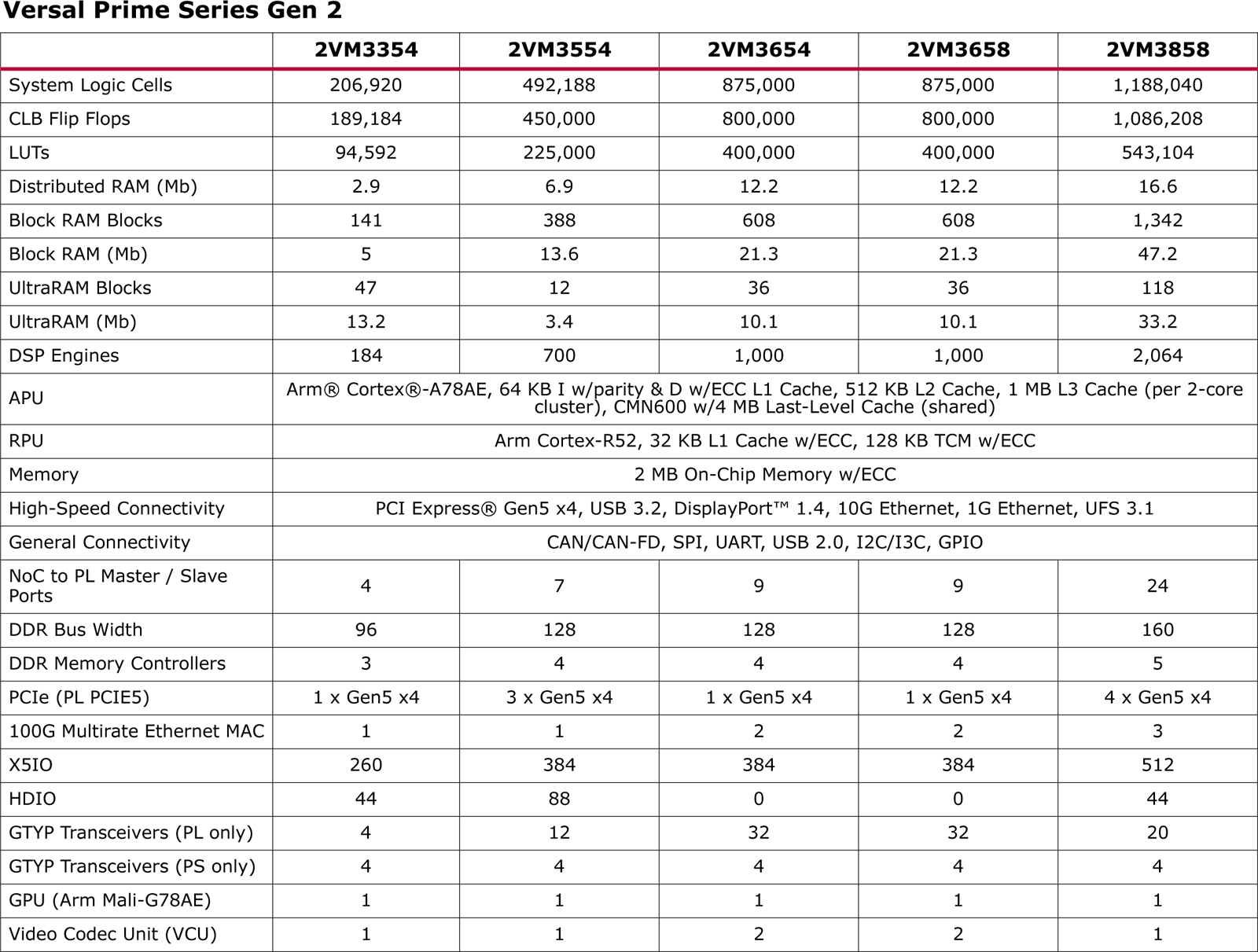
10.04.2024 [14:34], Сергей Карасёв
Intel и Altera представили Agilex 5 — первую FPGA с ИИ-архитектуройВозродив бренд Altera, корпорация Intel анонсировала FPGA серии Agilex 5, рассчитанные на широкий спектр применений. Это могут быть различные встраиваемые и промышленные устройства, решения для систем связи, обеспечения безопасности, видеоаналитики и пр. Intel называет Agilex 5 первыми в отрасли FPGA с ИИ-архитектурой. Изделия производятся по технологии Intel 7. Это первые FPGA в своём классе, оснащённые усовершенствованным (Enhanced) DSP с тензорным ИИ-блоком (AI Tensor Block), который отвечает за высокоэффективную обработку операций, связанных с ИИ. 
Источник изображений: Intel Кроме того, как утверждается, Agilex 5 — это первые на рынке FPGA с асимметричным блоком процессора приложений, состоящим из двух ядер Arm Cortex-A76 и двух ядер Cortex-A55. Такая конфигурация в зависимости от рабочих нагрузок позволяет оптимизировать производительность и энергоэффективность. Тактовая частота ядер Cortex-A76 достигает 1,8 ГГц, ядер Cortex-A55 — 1,5 ГГц. 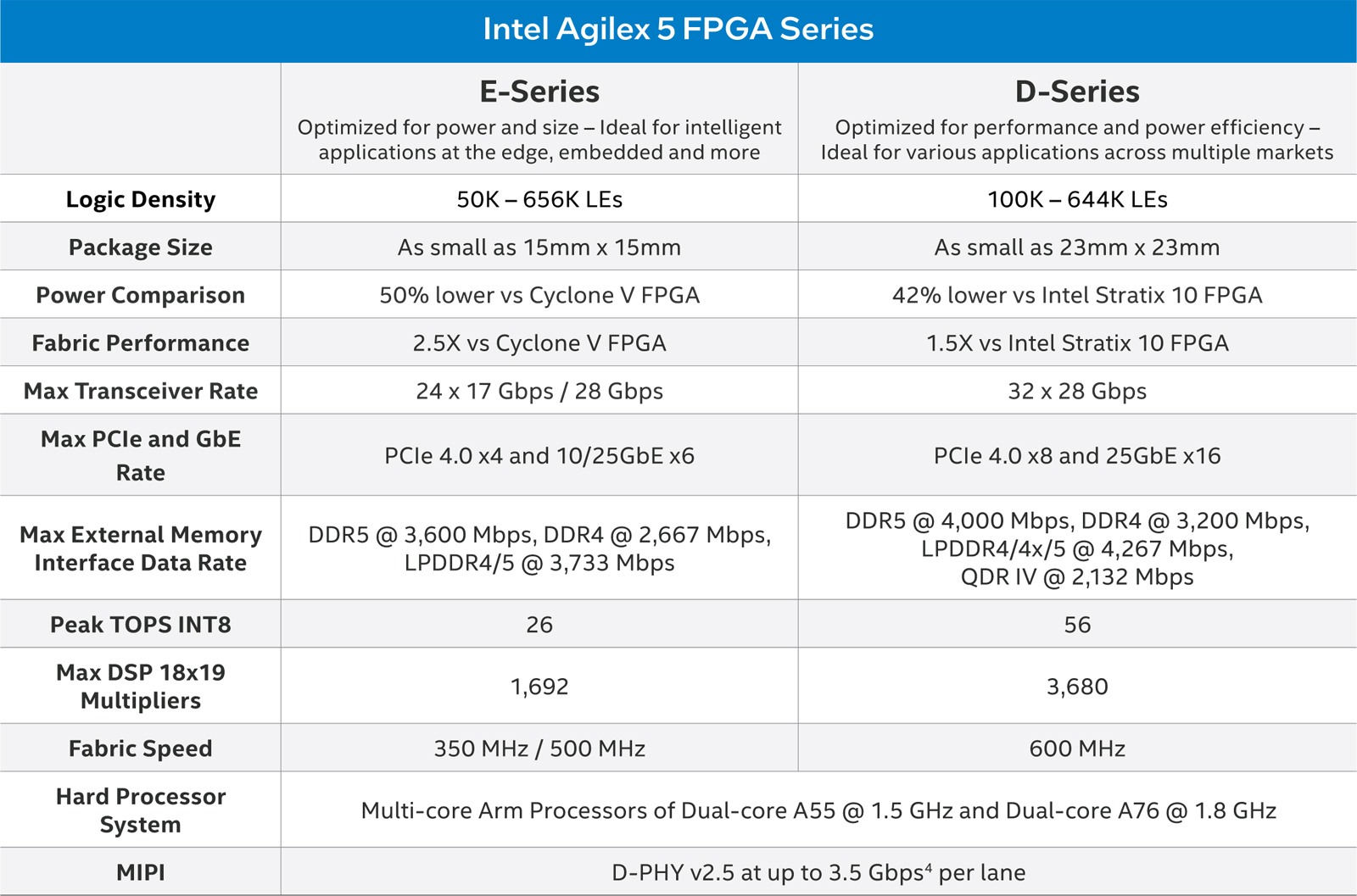 В семейство Agilex 5 вошли модели E-Series и D-Series. Первые оптимизированы для edge-устройств с небольшим энергопотреблением, а вторые предлагают более высокую производительность. Быстродействие INT8 достигает соответственно 26 и 56 TOPS. Решения E-Series могут работать с памятью DDR5-3600, DDR4-2667 и LPDDR4/5-3733. Реализована поддержка PCIe 4.0 x4 и шести интерфейсов 10/25GbE. В случае D-Series заявлена возможность использования памяти DDR5-4000, DDR4-3200, LPDDR4/4x/5-4267 и QDR-IV-2132. Обеспечена поддержка PCIe 4.0 x8 и 16 интерфейсов 25GbE.
07.03.2024 [22:21], Алексей Степин
AMD анонсировала новую серию FPGA Spartan UltraScale+AMD продолжает совершенствовать не только архитектуры Zen и Instinct, но и уделяет существенное внимание развитию технологий, полученных в наследство от Xilinx. Компания анонсировала новый модельный ряд FPGA Spartan UltraScale+, который должен заменить устаревшие серии Spartan 6 и Spartan 7. Новые ПЛИС относятся к категории энергоэффективных решений с достаточно невысокой стоимостью. В сравнении с предыдущими поколениями Spartan UltraScale+ стали не только более высокоплотными за счёт применения 16-нм техпроцесса, но и получили ряд новых возможностей и функций. 
Источник здесь и далее: AMD via ServeTheHome/Phoronix Сообщается, что на сегодняшний момент эти микросхемы обладают наибольшим числом каналов ввода-вывода к логическим ячейкам, что делает Spartan UltraScale+ подходящими для использования в сценариях с высоким I/O-трафиком. При этом благодаря переходу на 16-нм техпроцесс и внедрению готовых IP-блоков (без применения программируемой логики) PCIe и DDR энергопотребление удалось снизить на 30%.  Существенно расширены возможности в области обеспечения информационной безопасности: серия поддерживает работу с шифрованием, имеет на борту генератор случайных чисел (TRNG) и соответствует требованиям NIST к постквантовой криптографии. Дополнительным преимуществом является компактность новинок: они имеют габариты от 10 × 10 мм у младших моделей до 23 × 23 мм у старших. Доступны будут варианты упаковки BGA и CSP. 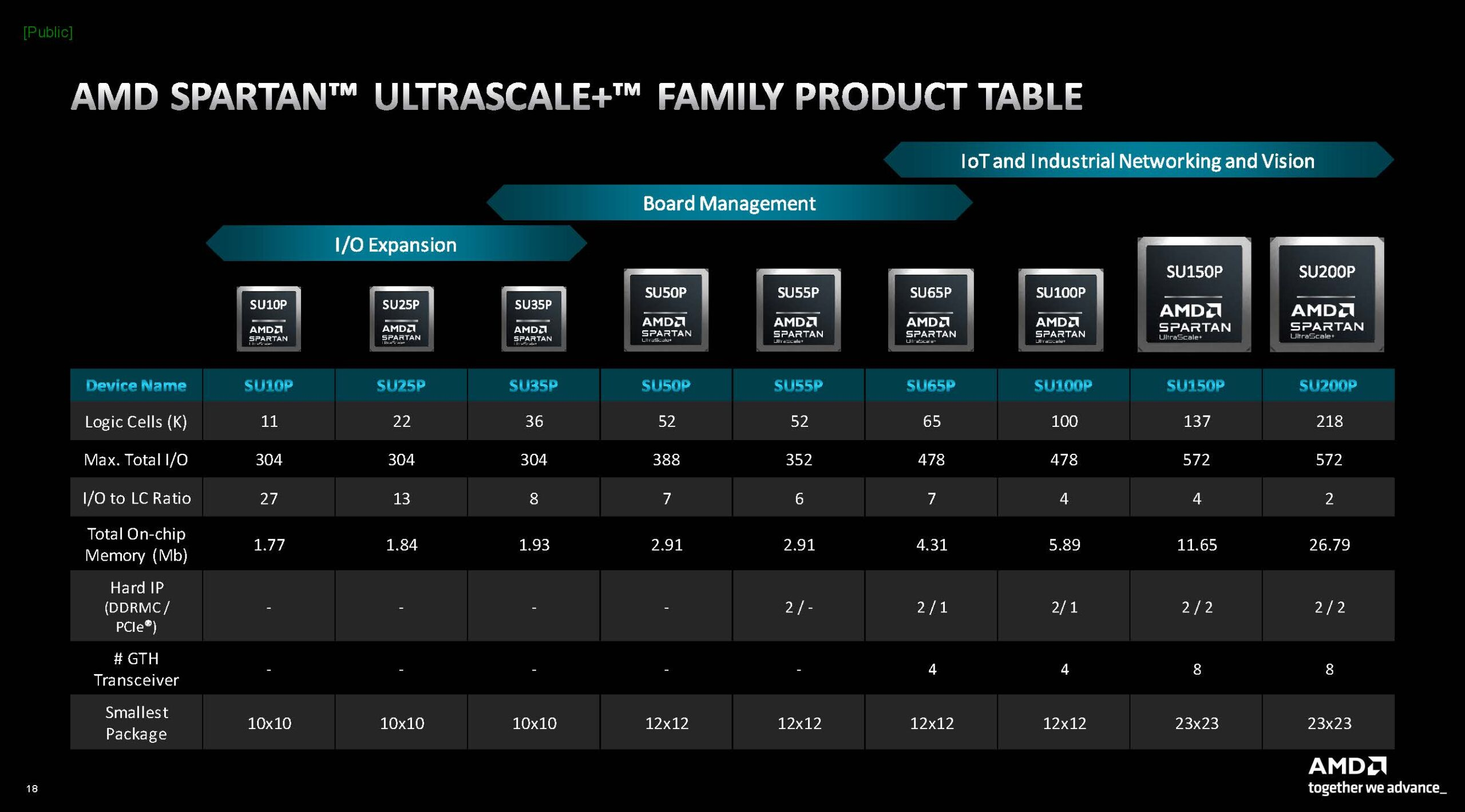 В серии представлены модели сложностью от 11 до 218 логических ячеек с быстрой набортной памятью объёмом от 1,77 до 26,8 Мбайт. Интерфейсы PCIe 4.0 и LPDDR4x/5 имеют не все модели, а лишь начиная с достаточно производительной SU65P. А вот полновесные 8 линий PCIe предоставляют лишь две старшие модели. 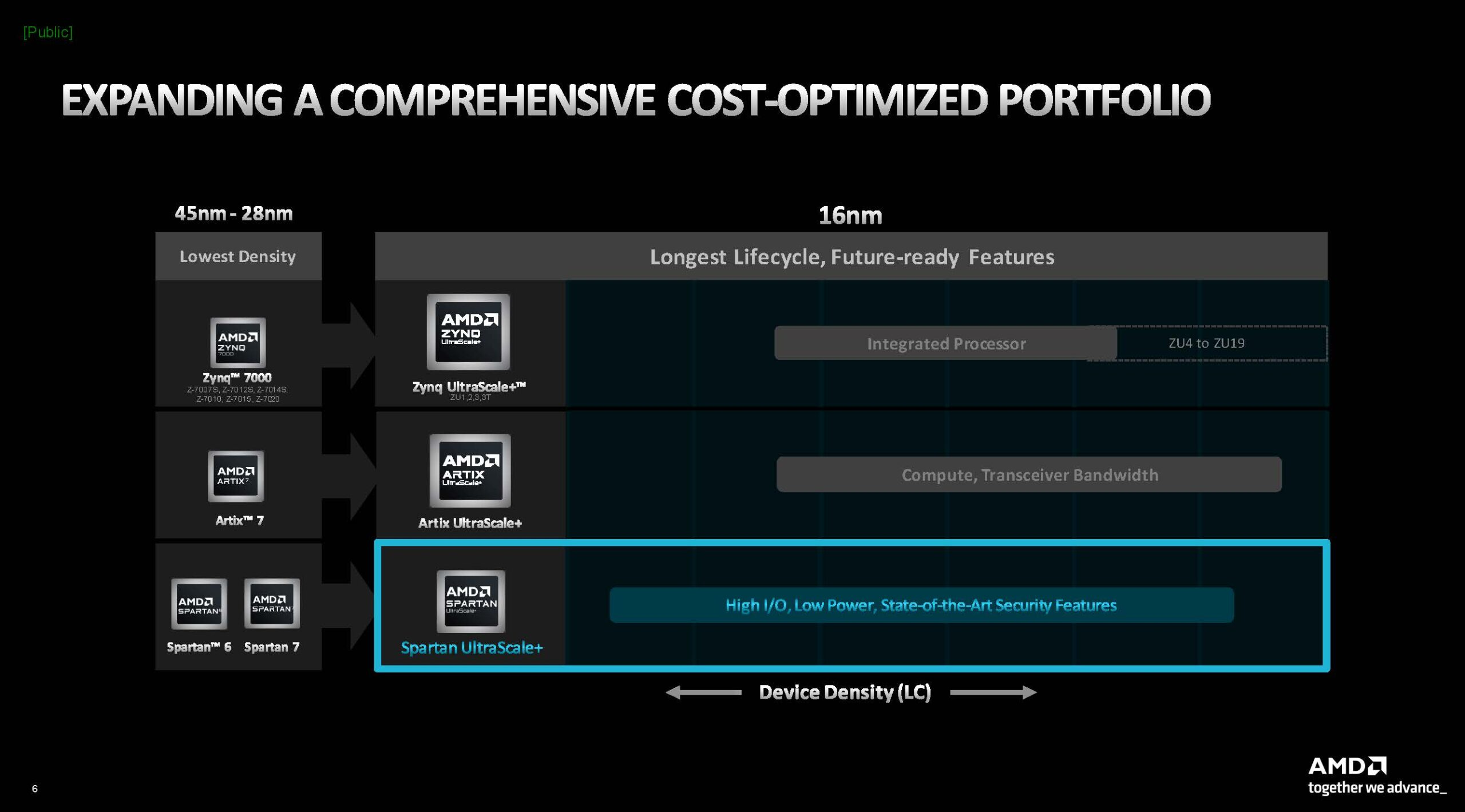 Новая серия Spartan UltraScale+ логичным образом дополняет модельные ряды Zynq UltraScale+ и Artix UltraScale+. С её анонсом портфолио 16-нм ПЛИС AMD обретает завершённый вид. Благодаря упору на развитую I/O-подсистему новинки найдут применение в соответствующих сценариях, став, например, BMC-контроллерами для серверов и GPU-комплексов или платформой для робототехнических манипуляторов с большим числом степеней свободы. 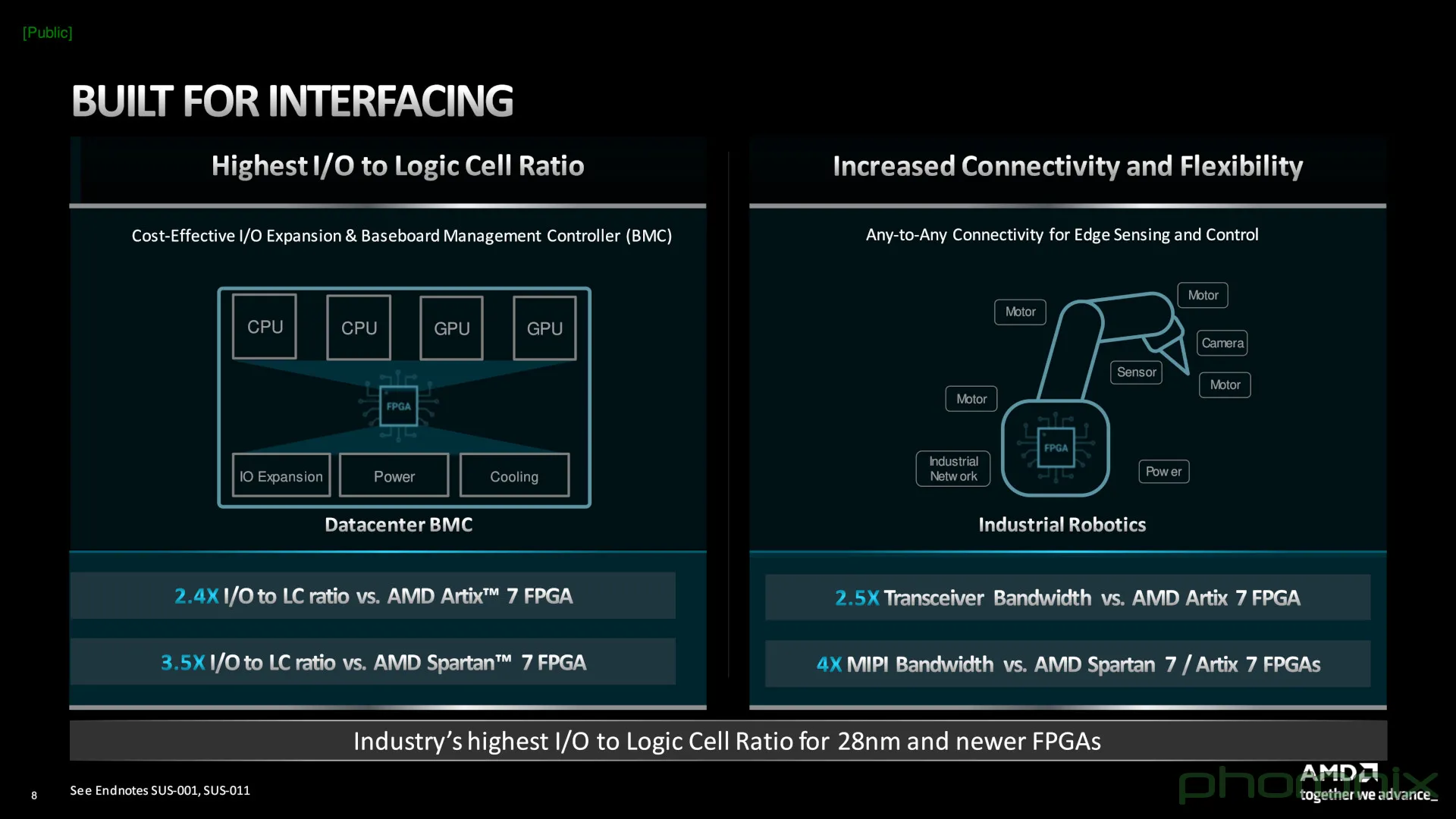 Документация на Spartan UltraScale+ доступна с момента анонса, средства разработки для новых ПЛИС появятся в IV квартале, а первых комплектов разработчика с актуальным «кремнием» на борту следует ожидать в I половине 2025 года. 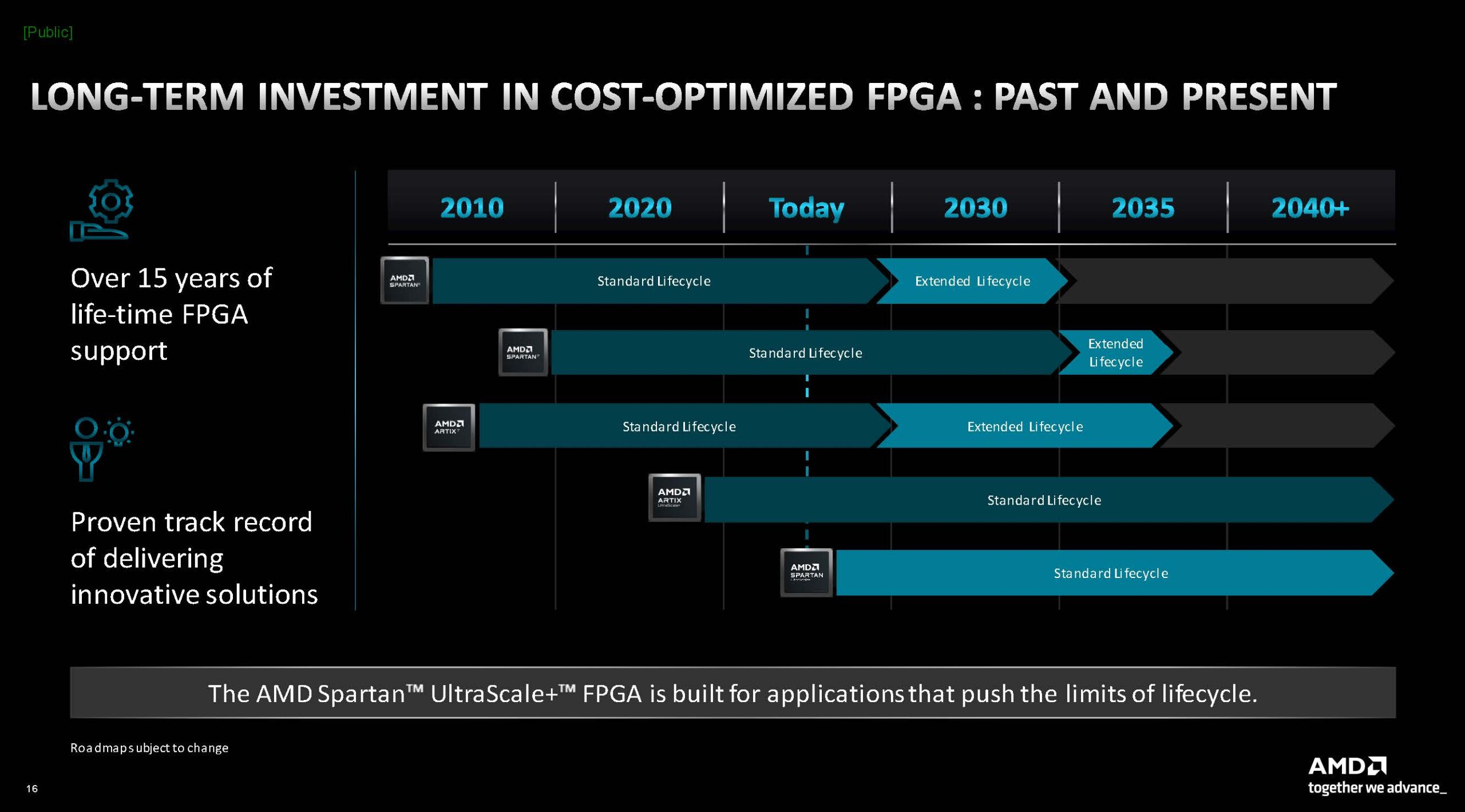 Компания также поделилась планами относительно жизненного цикла всех выпускаемых серий FPGA. Серии Spartan 6/7 и Artix 7 будут лишены поддержки в 2030–2035 гг., а решения модельного ряда UltraScale+ будут поддерживаться минимум до 2040 года, что важно для чипов, являющихся основой для промышленных платформ и долговременной ИТ-инфраструктуры.
03.03.2024 [23:22], Владимир Мироненко
Давай по новой: Intel возродила бренд AlteraIntel провела в минувший четверг онлайн-мероприятие, на котором выступила Сандра Ривера (Sandra Rivera), глава бывшего подразделения компании по выпуску ПЛИС (PSG), которое несколько месяцев назад было выделено в отдельное предприятие, пишет The Register. В своём выступлении Ривера сообщила о возрождении бренда Altera — компании, которую Intel приобрела в 2015 году за $16,7 млрд, а также поделилась планами по поводу дальнейшей работы. Ривера сообщила, что рынок FPGA вырастет в течение «следующих нескольких лет» до $55 млрд с нынешних $8–10 млрд, стремясь убедить инвесторов, что ажиотаж вокруг ИИ и оборудования для него не повлияет на перспективы и развитие ПЛИС. Отвоевать долю рынка у AMD, которая приобрела в 2020 году нынешнего лидера Xilinx, будет непросто, сообщили эксперты ресурсу The Register. По словам IDC, Xilinx лидирует с большим отрывом, контролируя около 55 % рынка. Altera занимает второе место, имея более 30 % рынка. Остальная часть приходится Lattice Semiconductor, Microchip и других более мелких компаний. 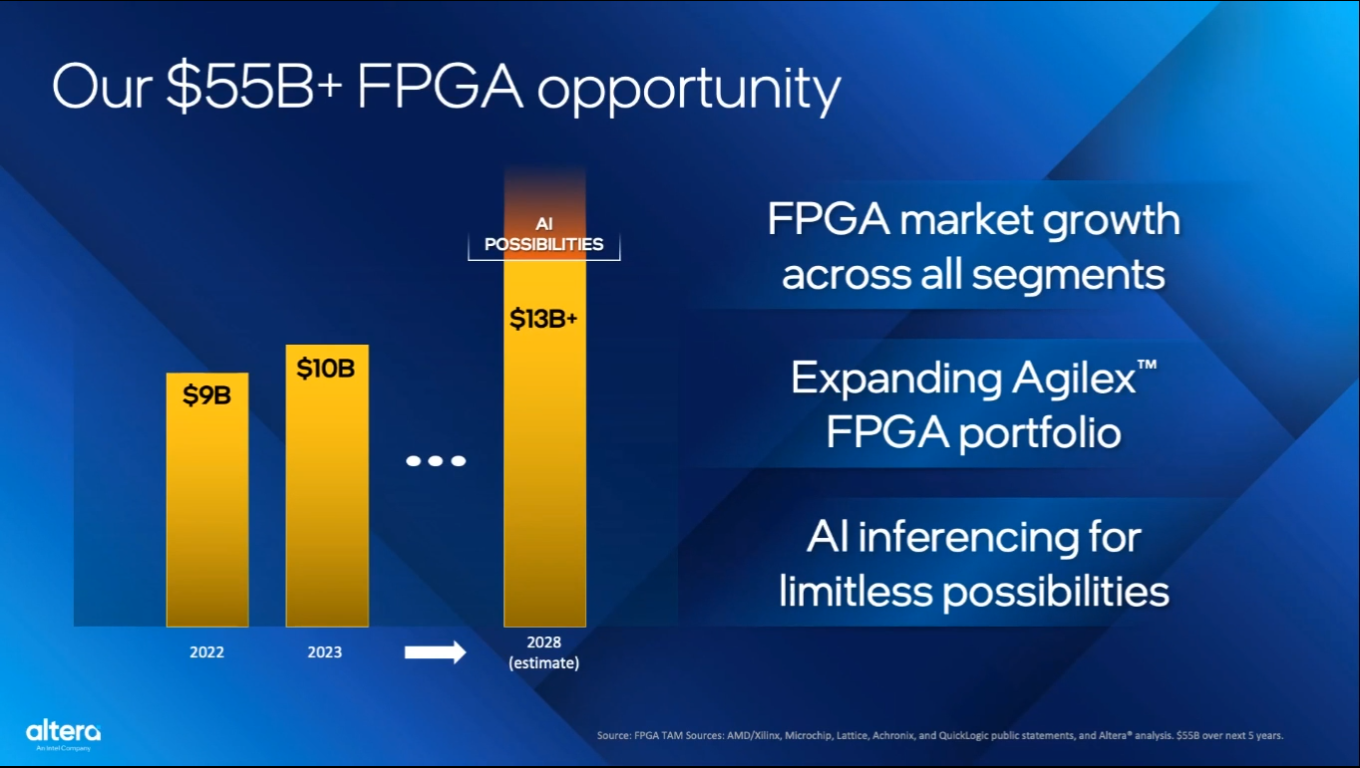
Источник изображений: Altera Gartner выделяет два основных сегмента рынка FPGA, где возможно развитие. Первый включает в себя высокопроизводительные FPGA, основанные на новейших техпроцессах и предназначенные для решения сложных нагрузок в составе, например, SmartNIC и базовых станций 5G. В этом сегменте клиенты больше обращают внимание на производительность и гибкость, чем на стоимость продукта. Выпуск FPGA для этих приложений, как правило, осуществляется в небольших объёмах и имеет высокую рентабельность. Второй сегмент гораздо шире и включает промышленные и встраиваемые решения для, например, Интернета вещей и робототехники. Здесь гибкость FPGA остаётся ключевой, но производительность отходит на второй план по сравнению с затратами. 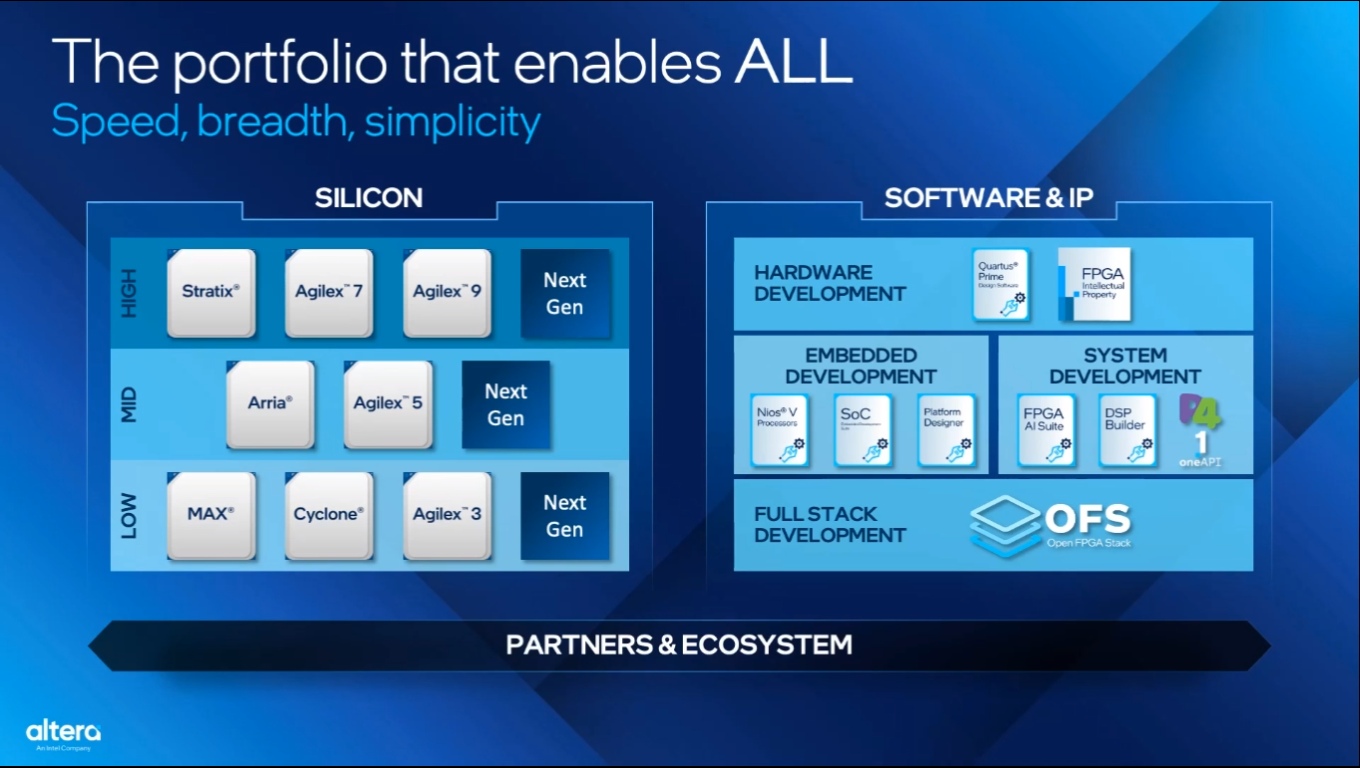 Именно второй, по словам Gartner, Intel практически игнорировала. Эта стратегия была признана ошибочной, подтвердил глава Intel Пэт Гелсингер (Pat Gelsinger). Поэтому Ривера первым делом объявила о планах Altera расширить ассортимент компании решениями среднего и начального ценового уровня. К ним относится серия Agilex 5, содержащая ряд встроенных ИИ-функций и имеющая оптимальную в своём классе производительность на Вт (в 1,6 раза выше, чем у конкурентов). Эти FPGA станут доступны уже в апреле 2024 года.  Подход Altera «сильно отличается от подхода конкурентов, у которых в составе решений есть некоторые блоки ИИ, но они используют другие инструменты и организацию рабочего процесса. Это новая кривая обучения, это всё просто сложнее интегрировать», говорит Ривера, подразумевая AMD Adaptive SoC, которые объединяют ядра Arm общего назначения, ИИ-движки и традиционные FPGA. Agilex 5 вместе с Arria ориентированы на средний ценовой сегмент. А для недорогих компактных решений с низким энергопотреблением, обычно встречающихся в промышленных средах, будет предложено семейство Agilex 3, более подробная информация о котором будет предоставлена позже в этом году.  По мнение экспертов, выпуск FPGA среднего и низкого ценового уровня должен сделать чипы Altera привлекательными для более широкого круга клиентов, но это вряд ли убедит давних заказчиков Xilinx отказаться от продукции AMD. Переход на FPGA другого вендора означает дорогостоящее освоение новых инструментов проектирования, отмечает IDC. Поэтому рост клиентской базы Altera будет обусловлен в первую очередь новыми и существующими клиентами. IDC предлагает Altera удвоить усилия по развитию ПО для разработчиков.  «Стоимость разработки и время выхода на рынок действительно являются ключевыми факторами», — поясняет аналитик. Если ПО Altera будет лучше или проще в работе, больше компаний будут использовать её FPGA. Ещё один фактор роста IDC видит в обширном портфеле интеллектуальной собственности Intel, поскольку клиентам проще получить готовый IP-блок, чем проектировать его с нуля. 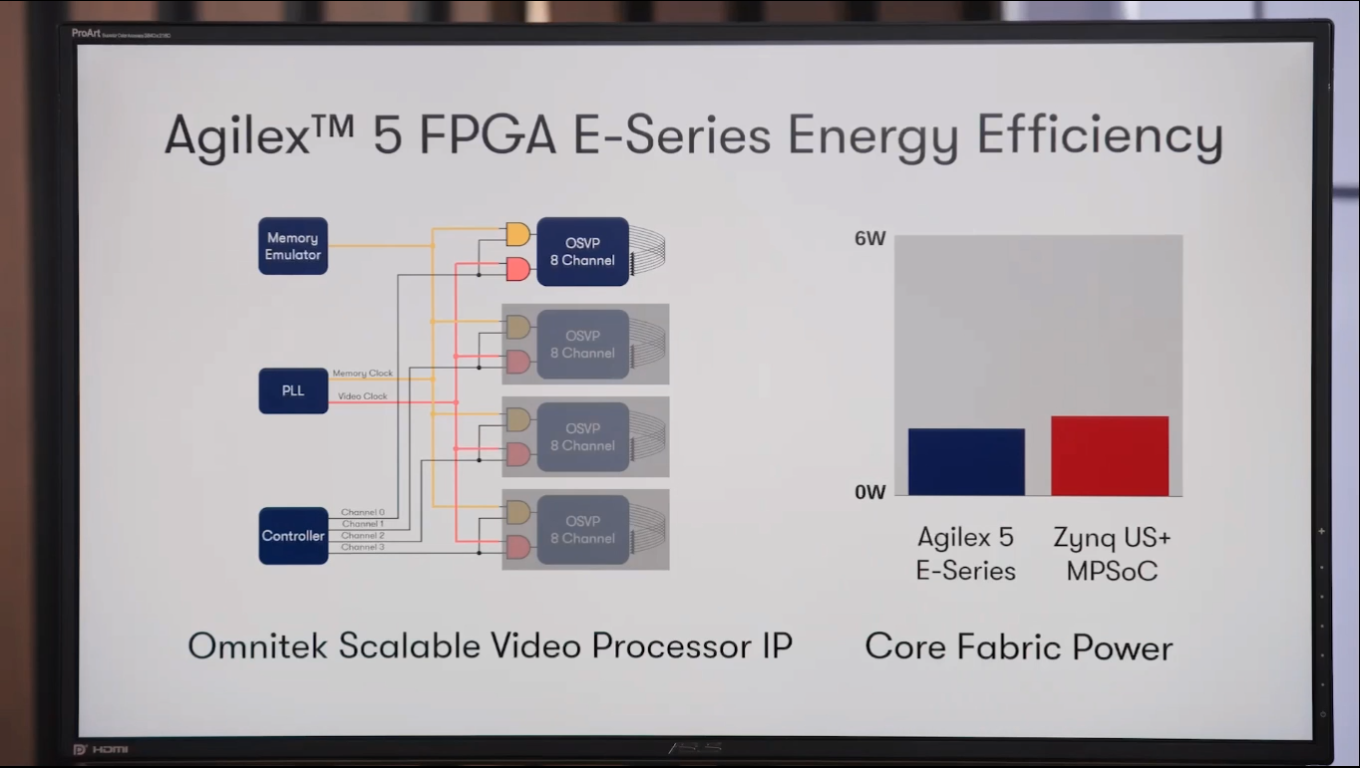 Как полагают эксперты, развитию рынка FPGA будут способствовать внедрение технологий 6G и всё более активная разработка чипов, для прототипирования которых требуются всё более мощные ПЛИС. И новая стратегия Intel относительно работы фабрик может сыграть только на руку. Вместе с тем аналитик Gartner не считает, что все эти факторы повлияют на доминирование AMD Xilinx на рынке FPGA.
19.02.2024 [09:38], Сергей Карасёв
Microchip выпустила комплект PolarFire SoC Discovery Kit на базе RISC-V для приложений реального времениКомпания Microchip, по сообщению ресурса CNX-Software, начала продажи одноплатного компьютера Polarfire SoC Discovery Kit, предназначенного для разработки Linux-программ и приложений реального времени. Новинка предлагается по ориентировочной цене $130, а со скидкой по академической программе Microchip её можно приобрести за $100. В основу положена программируемая пользователем вентильная матрица (FPGA) PolarFire SoC MPFS095T-1FCSG325E с пятью ядрами на архитектуре RISC-V. Это одно ядро RV64IMAC и четыре ядра RV64GC — все они работают на тактовой частоте 625 МГц. Чип содержит четыре блока SerDes со скоростью передачи данных 12,7 Гбит/с. 
Источник изображения: Microchip Изделие оснащено слотом microSD, сетевым контроллером 1GbE с разъёмом RJ-45, портом USB Type-C, коннектором mikroBUS, а также 40-контактной колодкой, совместимой с Raspberry Pi (GPIO, I2C, SPI, UART). Для вывода изображения может быть задействован интерфейс MIPI. Питание (5В / 3A) может подаваться через коннектор USB Type-C. Размеры платы составляют 104 × 84 мм. Предусмотрен встроенный программатор FlashPro5 (FP5) для настройки и отладки FPGA. Применяется софт Microchip Libero, а покупателям Polarfire SoC Discovery Kit предоставляется бесплатная лицензия Libero Silver.
07.02.2024 [20:00], Алексей Степин
Ryzen + Versal: AMD представила платформу Embedded+Как правило, основное внимание AMD привлекает своими процессорами с архитектурой x86, будь то Ryzen или EPYC. Тем не менее, другие направления, такие как встраиваемые платформы или решения для периферийных вычислений, для компании также играют важную роль. Вчера AMD анонсировала новую платформу Embedded+, главной особенностью которой является сочетание хорошо знакомой и отлично себя зарекомендовавшей архитектуры Zen+ с наработками бывшей Xilinx в лице SoC Versal AI Edge. 
Источник изображений: AMD via AnandTech В данном случае речь идёт об использовании соответствующих чипов в рамках одной системной платы, представляющей собой практически законченное изделие, предназначенное для использования в сценариях, требующих низкого энергопотребления при достаточно серьёзных вычислительных возможностях, особенно в традиционных для ИИ форматах. Сфера применения такого решения крайне широка и включает в себя любые задачи, требующие обработки массивов данных, поступающих в реальном времени с различных сенсорных систем и датчиков. Это могут быть как медицинские устройства, так и решения «умной промышленности» или автономный транспорт. 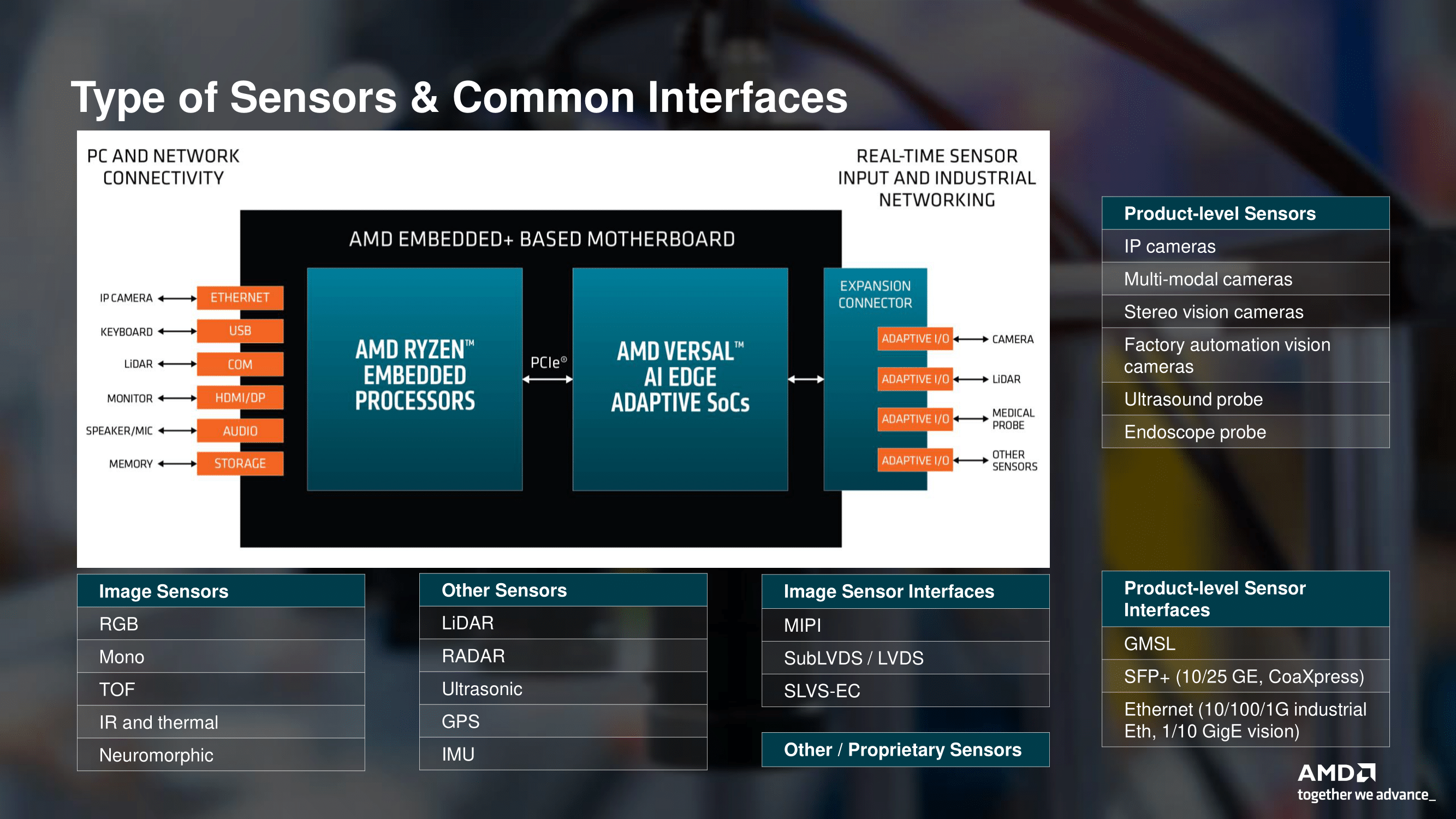 Во всех упомянутых случаях требуется низкая латентность, и платформа AMD Embedded+ соответствует подобного рода требованиям. Также она является поистине универсальной, поскольку несёт в своём составе как x86-ядра процессора Ryzen Embedded, так и ядра Arm в составе чипа Versal, а для уникальных задач можно использовать программируемую FPGA-логику. Новую платформу характеризует широкий спектр поддерживаемых интерфейсов ввода-вывода, начиная со стандартных Ethernet, USB и HDMI/Display Port, заканчивая интерфейсами различных сенсоров, такими, как MIPI и LVDS, а также GMSL. Речь идёт не только о сенсорах машинного зрения, но и о различных радарах, лидарах, ультразвуковых датчиках, приёмниках GPS и тому подобных устройствах.  Одновременно с анонсом самой платформы AMD представила готовое решение на её основе — плату Sapphire VPR-4616-MB. Решение имеет форм-фактор mini-ITX и несёт на борту Ryzen Embedded R2314 и Versal AI Edge 2302. Первый имеет конфигурацию с четырьмя x86-ядрами и шестью блоками Radeon Vega. В составе второго имеется по паре ядер Arm Cortex-A72 и Cortex-R5F, последние предназначены для работы в режиме реального времени. Программируемая часть содержит 329 тысяч логических ячеек и свыше 150 тысяч LUT. Чип способен развивать до 23 Топс на операциях в формате INT8 за счёт 34 собственных движков ИИ, ещё 5 Топс может выдать программируемая логика. 464 движка DSP делают данное решение хорошо подходящим для реализации машинного зрения, в том числе в системах автопилота. 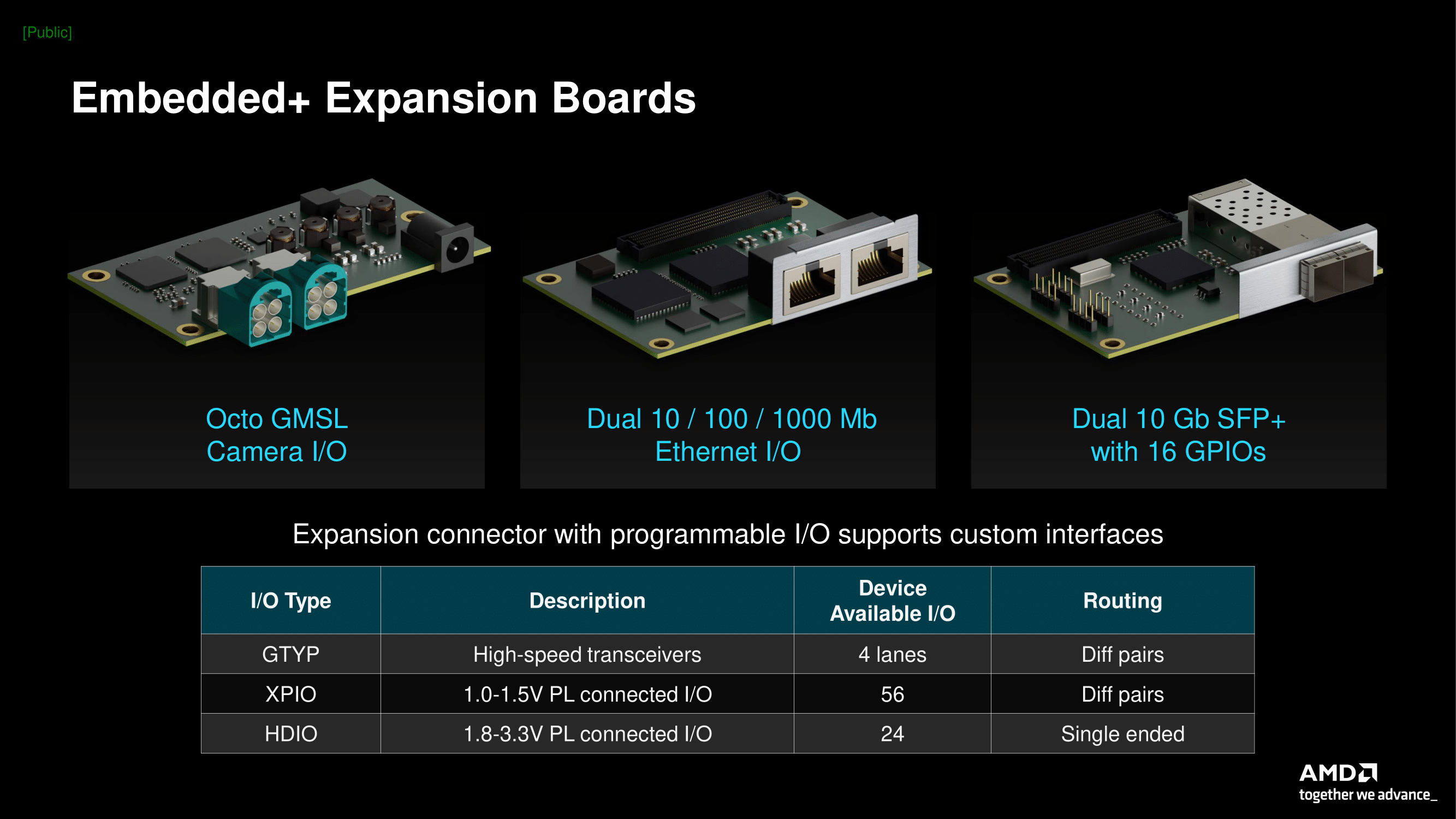 Плата имеет специальный разъём расширения, к нему подключаются различные модули с интерфейсами машинного зрения, Ethernet и GPIO. Объём оперативной памяти, которым можно укомплектовать решение, достигает 64 Гбайт, доступна установка накопителя M.2 и SATA, имеется отдельный слот M.2 2230 для реализации беспроводной связи.
14.12.2023 [22:30], Владимир Мироненко
FPGA + Orin: Lattice и NVIDIA будут сотрудничать в деле ускорения ИИ-вычислений на периферииLattice Semiconductor представила на конференции для разработчиков Lattice Developers Conference новую эталонную платформу для ускорения разработки периферийных ИИ-решений использованием платформ NVIDIA Jetson Orin и IGX Orin. Сотрудничество Lattice с NVIDIA нацелено на повышение эффективности подключения сенсоров к приложениям для ИИ-обработки, что позволит расширить возможности сообщества разработчиков открытых платформ. Согласно пресс-релизу, эталонная open source плата, основанная на энергоэффективных FPGA Lattice и аппаратной платформе NVIDIA Orin, предназначена для удовлетворения потребностей разработчиков в подключении к разнообразным датчикам и интерфейсам, при разработке масштабируемых высокопроизводительных периферийных ИИ-приложений с низким уровнем задержкидля нужд здравоохранения, робототехники, встраиваемых систем визуализации и т.д. Эталонная плата пока доступна лишь избранным клиентам, но Lattice планирует расширить доступ к решению и примерам приложений в I половине 2024 года. 
Источник изображения: Lattice Semiconductor «Мы рады сотрудничеству с NVIDIA, которое позволит расширить возможности наших эталонных решений, предлагая больше инноваций нашим клиентам и экосистеме, чтобы помочь упростить и ускорить внедрение периферийных приложений ИИ», — заявил директор по стратегии и маркетингу Lattice Semiconductor. В свою очередь директор по управлению встраиваемыми ИИ-продуктами NVIDIA отметил, что сотрудничество с Lattice позволит ускорить инновации в области обработки показаний датчиков и упростить развёртывание приложений ИИ «от периферии до облака».
04.10.2023 [17:55], Владимир Мироненко
Intel выделит FPGA-подразделение PSG, сформированное на базе Altera, в отдельную структуру с последующим IPOIntel объявила о предстоящем выделении с 1 января 2024 года группы программируемых решений (PSG), отвечающей за разработку Intel Agilex, Stratix и других продуктов FPGA, в отдельную бизнес-структуру, с последующим проведением в течение двух-трёх лет первичного размещения акций (IPO) с сохранением контрольного пакета за компанией. Также Intel надеется привлечь в 2024 году первого внешнего инвестора, который поможет своими ресурсами подготовить группу к IPO. Этот шаг даст PSG автономность и гибкость, которые необходимы для ускорения роста бизнес-единицы и более эффективной конкуренции в сфере производства FPGA, потребителями которых являются целый ряд отраслей, включая ЦОД, телеком-индустрию, а также промышленный, автомобильный, аэрокосмический и оборонный секторы. Подобным образом Intel поступила с Mobileye, сохранив контрольный пакет акций, но при этом обеспечив бизнес-подразделению достаточную независимость для более интенсивного роста. 
Источник изображения: Intel Гендиректором PSG назначена исполнительный вице-президент Intel Сандра Ривера (Sandra Rivera), являющаяся генеральным менеджером подразделения Intel Data Center and AI Group (DCAI), которое отвечает за продукты для ЦОД и платформ, и в которое в настоящее время входит PSG. Главным операционным директором PSG станет Шеннон Пулен (Shannon Poulin), ранее занимавший должность вице-президента PSG. Сообщается, что Intel и PSG останутся стратегически связанными, включая продолжение отношений PSG с Intel Foundry Services (IFS) в работе в ключевых областях рынка FPGA, которые также позволят PSG предоставить клиентам большую предсказуемость поставок в соответствии с их потребностями. Как полагает ресурс The Register, выделение PSG может помочь Intel в конкурентной борьбе с Xilinx, сделку по приобретению которой за $49 млрд AMD завершила в 2022 году. Напомним, что подразделение PSG было построено Intel на основе приобретённой в 2015 году за $16,7 млрд компании Altera. Глава Intel Пэт Гелсингер (Pat Gelsinger) проводит последовательную реструктуризацию. Под его руководством корпорация уже продала MiTAC (Tyan) свой бизнес по производству серверов, свернула разработку Optane, отказалась от развития коммутаторов, закрыла программу Pathfinder for RISC-V и, наконец, продала Bain Capital и TSMC доли в своей дочерней компании IMS Nanofabrication. При нём же компания отказалась от NAND-направления и ушла с рынка ASIC-майнеров.
02.10.2023 [15:57], Сергей Карасёв
AMD представила ускоритель Alveo UL3524 для брокерских и биржевых приложенийКомпания AMD анонсировала специализированный ускоритель Alveo UL3524 на базе FPGA, ориентированный на финтех-сферу. Решение, как утверждается, позволяет трейдерам, хедж-фондам, брокерским конторам и биржам совершать операции с задержками наносекундного уровня. В основу новинки положен чип FPGA Virtex UltraScale+, выполненный по 16-нм технологии. Конфигурация включает 64 трансивера с ультранизкой задержкой, 780 тыс. LUT и 1680 DSP. Отмечается, что Alveo UL3524 обеспечивает в семь раз меньшую задержку по сравнению с FPGA предыдущего поколения. В частности, инновационная архитектура трансиверов с оптимизированными сетевыми ядрами позволяет добиться показателя менее 3 нс. 
Источник изображения: AMD Ускоритель может использоваться в комплексе с платформой разработки Vivado Design Suite. AMD также предоставляет разработчикам среду FINN с открытым исходным кодом, что позволяет внедрять в высокопроизводительные трейдинговые системы модели ИИ с низкими задержками. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe 4.0 x16. Задействован система пассивного охлаждения, а показатель TDP заявлен на отметке 125 Вт. Предусмотрены четыре сетевых порта QSFP-DD. Карта несёт на борту 16 Гбайт памяти DDR4-2666 и 72 Мбайт памяти QDR II+. Весит ускоритель 832 г.
15.09.2023 [12:03], Сергей Карасёв
AMD начала производство мощных SoC Versal HBM для ИИ-задачКомпания AMD объявила об организации массового выпуска «адаптивных» однокристальных систем (SoC) серии Versal HBM, которые могут применяться в составе облачных платформ, ИИ-решений, а также на периферии. Как отражено в названии, изделия оснащены высокоскоростной памятью HBM (High-Bandwidth Memory). Применены чипы HBM2e. Утверждается, что по сравнению с существующими решениями Versal Premium SoC, оборудованными памятью DDR4, достигается шестикратное увеличение пропускной способности и сокращение энергопотребления приблизительно на 65 % в расчёте на бит. 
Источник изображения: AMD Для разработчиков, экспериментирующих с Versal HBM, компания AMD выпустила комплект VHK158 Evaluation Kit. Решение наделено 32 Гбайт памяти HBM, двумя слотами DDR4-3200 DIMM, интерфейсами PCIe 5.0 x8 и PCIe 4.0 x16. В качестве процессора приложений задействован чип с двумя вычислительными ядрами Arm Cortex-A72. Плата VHK158 Evaluation Kit располагает слотом microSD, трансиверами 112G PAM4, разъёмами QSFP28 и QSFP-DD, коннектором FMC+. Заявленная пропускная способность памяти HBM достигает 819,2 Гбайт/с. Габариты составляют 247 × 220 мм. Диапазон рабочих температур простирается от 0 до +45 °C. Стоит комплект приблизительно $15 тыс. |
|


