Материалы по тегу: fpga
|
24.08.2023 [16:27], Владимир Мироненко
AMD приобрела французскую компанию Mipsology, разработчика ИИ-решений для FPGAAMD объявила о приобретении компании Mipsology из Палезо (Франция), специализирующейся в области программного обеспечения для искусственного интеллекта, с которой её связывают давние партнёрские отношения. Как ожидается, команда разработчиков Mipsology поможет AMD разработать полный стек ИИ-решений и упростит развёртывание ИИ на оборудовании AMD. Основанная в 2015 году компания Mipsology разрабатывает передовые решения для инференса и инструменты оптимизации нагрузок, адаптированные для оборудования AMD. Флагманское ПО Zebra компании поддерживает отраслевые платформы, включая TensorFlow, PyTorch и ONNX Runtime, и помогает ускорить развёртывание инференс-нагрузок на CPU и FPGA. Также ПО поддерживает программный стек AMD Unified AI (UAI). 
Источник изображения: AMD «ИИ является нашим главным стратегическим приоритетом и важным фактором роста спроса на полупроводники в ближайшее десятилетие. Приветствуя квалифицированную команду Mipsology в AMD, мы продолжим расширять возможности нашего программного обеспечения, чтобы позволить клиентам по всему миру использовать огромный потенциал повсеместного ИИ», — отметил представитель AMD в блоге компании.
24.07.2023 [17:16], Руслан Авдеев
Российская UDV Group анонсировала первый отечественный межсетевой экран на базе RISC-VUDV Group, российский разработчик решений в сфере кибербезопасности для промышленных и корпоративных клиентов представил первый, по его словам, в стране межсетевой экран, использующий архитектуру RISC-V. Как сообщает пресс-служба UDV, рабочий прототип UDV Industrial Firewall продемонстрировали на конференции IT IS conf в Екатеринбурге. Считается, что это уникальное для отечественного рынка ИБ-систем решение. UDV Industrial Firewall ориентирован на использование в промышленных сетях и предусматривает аппаратное ускорение обработки трафика. Он предназначен для разграничения доступа к сегментам сетей АСУ ТП с учётом режимов их работы и для глубокой фильтрации промышленных протоколов. В текущем квартале новинка будет тестироваться в сетях заказчиков, а в серийное производство она должна поступить во II квартале 2024 года. Пока фильтрация трафика осуществляется на скоростях до 1 Гбит/с, чего, как утверждают разработчики, вполне достаточно для промышленных сетей. Впрочем, в будущем в компании обещают поднять максимальную скорость до 40 Гбит/с благодаря использованию недорогих FPGA. Масштабировать функциональность планируется простым добавлением новых модулей расширения, способных на параллельную обработку трафика. 
Источник изображения: UDV Group В компании подчеркнули, что использование RISC-V обусловлено тем, что архитектура «не является проприетарной, а также устойчива к санкционным рискам». В UDV Group заявили, что используют процессоры китайского производства, не подпадающие под санкции, и уверены, что будущее на рынке российских процессоров за решениями на архитектуре RISC-V.
28.06.2023 [19:04], Алексей Степин
AMD представила царь-FPGA VP1902, самую большую в мире чиплетную ПЛИС для разработки новых чиповAMD активно развивает доставшиеся ей в наследство активы Xilinx в области создания программируемых матриц (FPGA), понимая, что применений таким чипам в современном мире очень много. Компания снова получила лавры создателя самой большой и сложной FPGA — ранее это была Xilinx VU19P, а сейчас речь идёт об AMD VP1902, пополнившей серию Versal Premium. Чиплетная технология захватывает индустрию — благодаря модульности становится возможным создание сверхсложных и сверхмощных решений. Относится к чиплетным и новая матрица Versal VP1902, состоящая из четырёх больших чиплетов, объединённых высокоскоростным программируемым интерконнектом (network-on-a-chip, NoC) в массив с габаритами 77 × 77 мм. 
Источник изображений здесь и далее: AMD Рост сложности FPGA обусловлен тем, что эмуляция всё более современных и мощных процессорных ядер требует большего количества логических ячеек. Здесь новинка вне конкуренции, поскольку включает 18,5 млн таких ячеек, что, по словам AMD, позволяет массиву таких FPGA эмулировать весьма мощные чипы. 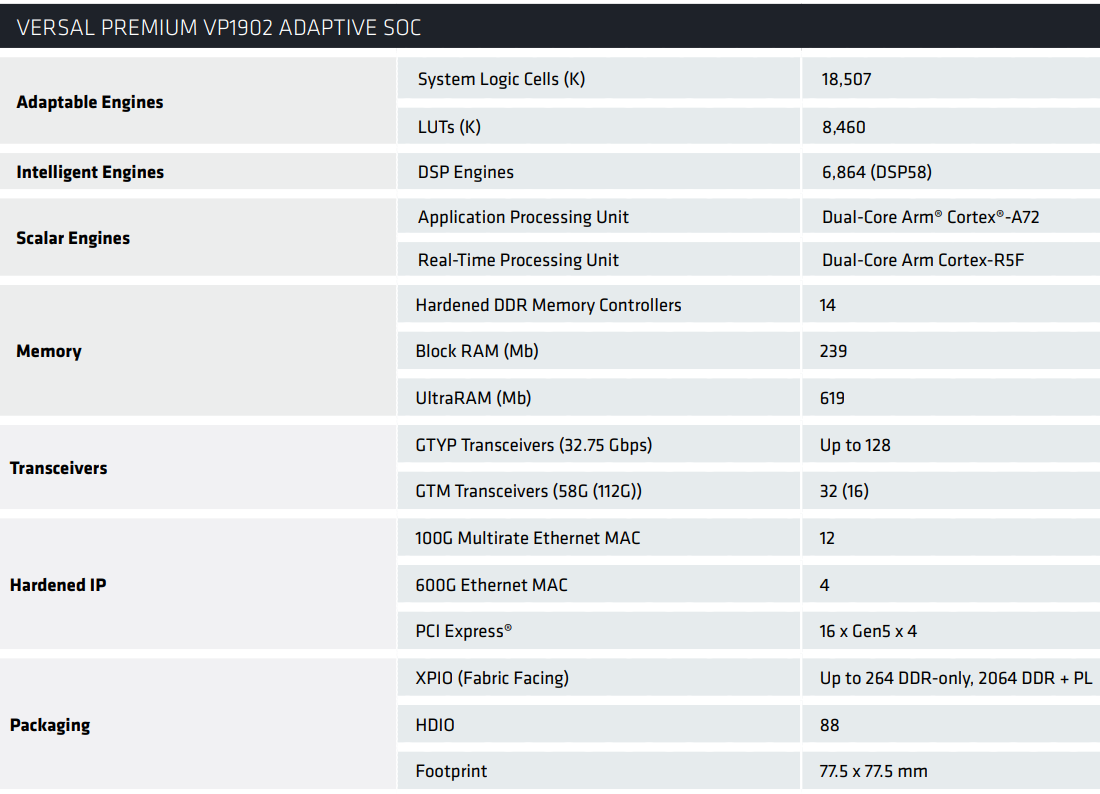 Помимо этого, в состав VP1902 входит 14 защищённых контроллеров DDR, четыре MAC-блока Ethernet класса 600G (100–400GbE) и 12 блоков 100G (10–100GbE), а также четыре фиксированных блока PCIe 5.0 x16. Для межчипового соединения используется интерконнект XPIO с пропускной способностью 5,6 Тбит/с, а совокупная пропускная способность 160 доступных трансиверов составляет 12,2 Тбит/с.  С совместимостью у новинки всё в порядке, она использует тот же комплект программного обеспечения Vivado ML, что и другие решения компании. По самой своей природе AMD VP1902 нацелена, в первую очередь, на рынок разработчиков сложных процессоров. 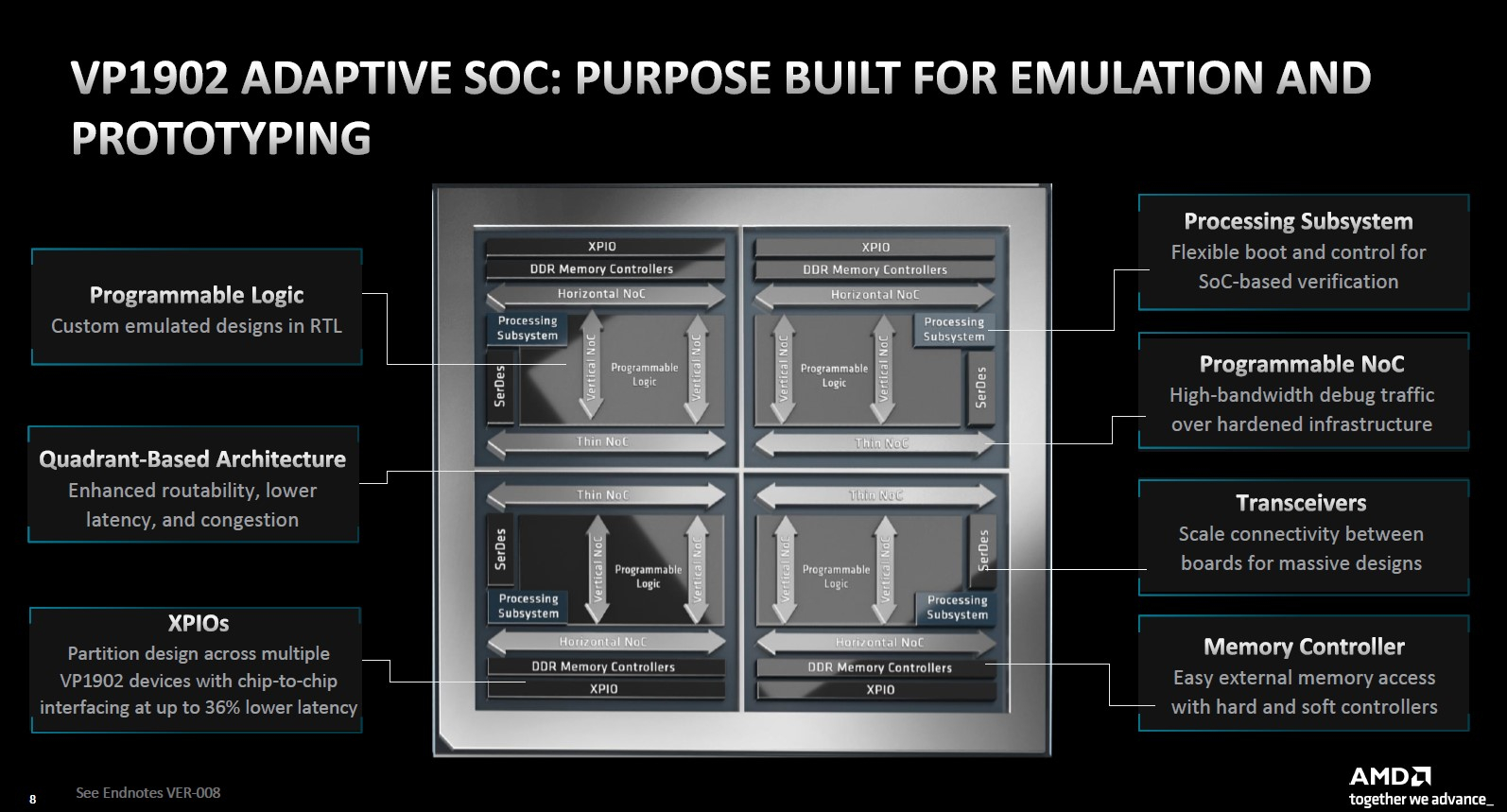 Однако сфера применения у неё намного шире — новинка отлично подойдёт и разработчикам прошивок, всевозможных блоков IP, впишется она в цикл прототипирования различных подсистем, валидации аппаратного обеспечения и другие подобные сценарии. Образцы VP1902 появятся в III квартале 2023 года, массовое производство начнётся в первой половине следующего года.
23.05.2023 [15:01], Сергей Карасёв
Intel выпустила первые FPGA Agilex 7 с поддержкой PCIe 5.0 и CXLКорпорация Intel в ходе суперкомпьютерной конференции ISC 2023 сообщила о начале производства программируемых вентильных матрицах (FPGA) семейства Agilex 7, предназначенных для ускорения выполнения различных задач, связанных с обработкой данных. Часть семейства Agilex 7 были анонсирована в марте нынешнего года. Решения имеют гетерогенную многокристальную архитектуру, в центре которой находится микросхема FPGA, соединённая с трансиверами посредством моста Intel Multi-Die Interconnect Bridge (EMIB). Каждый чиплет (в Intel их называют «плитками») отвечает за выполнение определённых функций. Intel приступила к выпуску версий Agilex 7, в состав которых входит «плитка» R-Tile. Она включает блоки PCIe 5.0 x16 и CXL 1.1/2.0, обеспечивая высокую гибкость при использовании в сетях передачи данных, в составе облачных платформ, ЦОД, систем НРС и пр. Достигается быстродействие до 32 GT/s в расчёте на одну линию. При производстве применятся 10-нм технология. 
Источник изображений: Intel 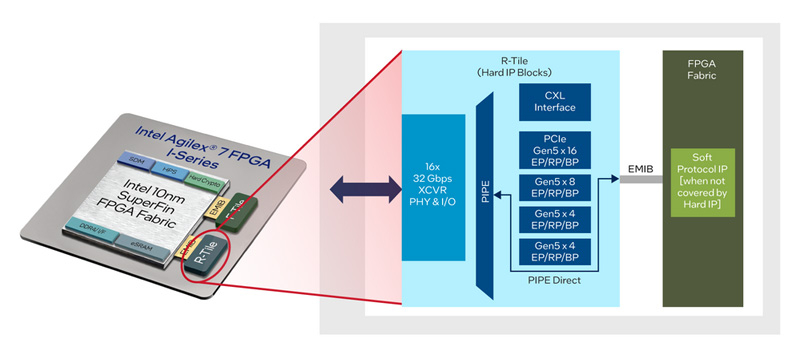 Отмечается, что настраиваемая и масштабируемая архитектура Agilex 7 позволяет заказчикам быстро разворачивать платформы в соответствии со своими специфичными потребностями. Это обеспечивает оптимальную производительность дата-центров и позволяет сократить затраты. Изделия Agilex 7 могут применяться в серверах на основе процессоров Intel Xeon Sapphire Rapids.
30.03.2023 [19:45], Владимир Мироненко
В 2023 году Intel выпустит Xeon Emerald Rapids и подготовит полтора десятка FPGA, а чипы Sierra Forest и Granite Rapids появятся уже в 2024 годуВ ходе мероприятия для инвесторов Intel подтвердила свои планы по противодействию процессорам AMD EPYC Bergamo, в которых будет использоваться архитектура с высокой плотностью ядер Zen4c, а также всё нарастающему давлению Arm. Intel придерживается планов по созданию собственных архитектур с производительными и энергоэффективными ядрами для чипов Xeon. Intel объявила, что рассчитывает выпустить следующее, пятое по счёту поколение процессоров Xeon Scalable под кодовым названием Emerald Rapids (EMR), преемников Sapphire Rapids (SPR), в IV квартале 2023 года. Компания также продемонстрировала чип Emeralds Rapids, состоящий из двух чиплетов (тайлов в терминологии Intel). Sapphire Rapids, напомним, имеется четыре тайла меньших размеров. Сообщается, что образцы Emerald Rapids уже доступны избранным заказчикам. Не вдаваясь особо в технические подробности, компания рассказала, что Emerald Rapids будет работать в том же диапазоне TDP, что и Sapphire Rapids, что повысит общую производительность платформы в пересчёте на Вт. 
Изображения: Intel Учитывая то, что Emerald Rapids будет использовать ту же платформу LGA 4677, что и Sapphire, заказчики смогут заменить Sapphire на Emerald в существующих решениях. Такой подход позволит легко модернизировать уже внедрённые системы, а в случае производителей оборудования — ускорить вывод Emerald Rapids на рынок. Emerald Rapids будет построен на том же техпроцессе Intel 7. Это означает, что прирост производительности должен быть обеспечен за счёт архитектурных улучшений. Intel сообщила о «повышенной плотности ядер», поэтому можно предположить, что у Emerald Rapids будет больше ядер в сравнении с Sapphire Rapids. 
Emerald Rapids Вслед за Emerald Rapids компания планирует начать в 2024 году поставки чипов следующего поколения Granite Rapids (GNR) на базе производительных P-ядер. Сообщается, что вычислительные тайлы Granite Rapids будут выпускаться с использованием техпроцесса Intel 3. Intel также впервые сообщила, что Granite Rapids будут поддерживать MCR DIMM (DDR5-8800+) и обеспечат ПСП в пределах 1,5 Тбайт/с (12 каналов памяти). Ещё одной особенностью станет полный переход на чиплетную компоновоку с независимым IO-тайлом. Первые образцы Granite Rapids уже тестируются некоторыми заказчиками. 
Emerald Rapids В первой половине 2024 года должен выйти и процессор Sierra Forest (SRF), первый Intel Xeon с энергоэффективными E-ядрами (следующее за Gracemont поколение) общим числом до 144 единиц. Сообщается, что Sierra Forest и Granite Rapids будут использовать одну и ту же платформу Birch Stream. Следует отметить, что чипы Sierra Forest появятся несколько раньше, чем Granite Rapids, и тоже будут использовать техпроцесс Intel 3, а также IO-тайлы. Отмечается, что Sierra Forest даже в текущем виде оказались на удивление стабильно работающими. Более того, их уже тестирует как минимум один заказчик Intel. 
Sierra Forest На смену Sierra Forest придут в 2025 году чипы Clearwater Forest (CWF), которые станут первыми в семействе Intel Xeon, основанными на техпроцессе Intel 18A. По словам Intel, её заказчики не хотят серверные процессоры смешанной архитектуры, то есть требуют чипы либо только с P-ядрами, либо только с E-ядрами. Sierra Forest сейчас является, пожалуй, наиболее важным продуктом для Intel и для демонстрации производственных возможностей, и для сохранения заказчиков среди гиперскейлеров.  Что касается ускорителей, то компания в этом году планирует подготовить сразу 15 различных FPGA в сериях Agilex и Stratix, а также eASIC. Intel, как уже говорилось ранее, не забрасывает работу над специализированными ускорителями Habana, но грядущие Gaudi3 от нынешних Gaudi2 будут отличаться переходом с 7-нм на 5-нм техпроцесс. Отменённых Rialto Bridge в планах более нет, да и Falcon Shores тоже не упоминаются. При этом Intel считает, что к 2027 году в области ИИ-чипов соотношение между CPU и GPU будет на уровне 60/40.
11.03.2023 [21:38], Алексей Степин
Intel представила FPGA Agilex 7 с высокоскоростными трансиверами F-TileFPGA остаются популярными как гибкие решения, пригодные для реализации широкого круга задач по ускорению обработки данных. Однако с ростом пропускной способности современных сетей растут соответствующие требования и к FPGA. Ответом на вызовы в этом сегменте стал выпуск новой серии ПЛИС Intel Agilex 7 с самыми быстрыми в мире FPGA трансиверами F-Tile. 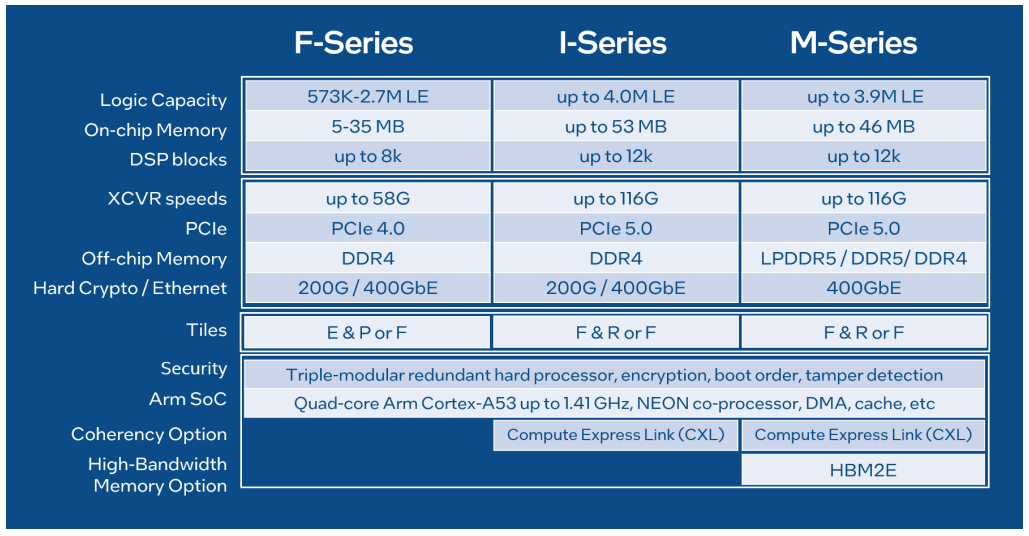
Источник изображений здесь и далее: Intel F-Tile — двухрежимный последовательный интерфейс, предлагающий схемы модуляции PAM4 и NRZ. Он может работать на скоростях до 116 Гбит/с. Также предлагается реализация Ethernet вплоть до 400GbE. Каждый тайл такого типа может содержать до четырёх высокоскоростных каналов FHT с поддержкой PAM4 и до 16 менее скоростных каналов FGT, ограниченных 58 Гбит/с в режиме PAM4 и 32 Гбит/с в режиме NRZ. Количество F-тайлов в составе Agilex 7 зависит от конкретной модели чипа. Наличие столь высокопроизводительных трансиверов в составе Agilex 7 делает новые ПЛИС Intel отлично подходящими для поддержки высокоскоростных сетей (в качестве DPU), в том числе беспроводных, или для ИИ-ускорителей. Производительностью Agilex 7 не обделены — для старшей серии M говорится о 38 Тфлопс, правда, в режиме FP16. 
Базируются новые ПЛИС на уже не слишком новом 10-нм техпроцессе Intel 7 Enhanced SuperFin, и в старшей серии M могут предоставить в распоряжение разработчику 3,85 млн логических элементов, 12300 блоков DSP и 370 Мбайт быстрой интегрированной памяти, а также до 32 Гбайт памяти в HBM2e-сборках. Также в составе присутствует квартет ядер Arm Cortex-A53. Agilex 7 поддерживают интерфейс PCI Express 5.0 и CXL 1.1 (посредством R-Tile). 
Таким образом, программируемые матрицы Intel Agilex 7 благодаря сочетанию быстрых трансиверов и интерфейсов HBM2e и LPDDR5 найдут применение в любых сценариях, где требуется обработка существенных массивов данных: в периферийных системах первичной обработки данных, решениях искусственного интеллекта, при развёртывании сетей 5G и даже в сфере HPC.
08.03.2023 [21:36], Алексей Степин
«ZIP-ускоритель»: Pure Storage представила карту расширения DirectCompress Accelerator для эффективного сжатия данных на летуКомпания Pure Storage делает всё для популяризации СХД класса All-Flash, в том числе продвигает такие решения в сегменты, где традиционно господствовала «механика». Вместе с новой системой FlashBlade//E производитель анонсировал ускоритель DirectCompress Accelerator для сжатия данных на лету, способный в некоторых случаях улучшить эффективность компрессии почти на треть, а также разгрузить центральный процессор хранилища. 
Источник изображений здесь и далее: Pure Storage Pure Storage использует в своих флеш-массивах как сжатие на лету (inline), так и отложенное (post-process). В последнем случае речь идёт о дополнительной компрессии уже после записи данных и при высвобождении процессорных мощностей. Однако иногда этот процесс конфликтует со сбором мусора, что снижает степень компрессии. Ускоритель DirectCompress Accelerator (DCA) призван избежать таких ситуаций. Плата расширения (PCIe x8) на базе FPGA полностью избавляет CPU флеш-массива от сжатия данных в режиме inline. 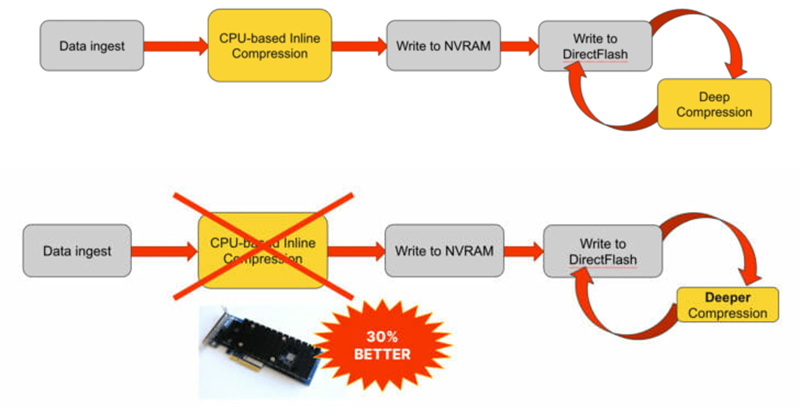
Схемы сжатия в массивах Pure Storage: без ускорителя (сверху) и с платой DCA Более того, разработчики сообщают, что применение DCA в некоторых случаях способно улучшить эффективность сжатия на 30 %, то есть выгадать серьёзный объём дополнительного пространства, а значит, уменьшить удельную стоимость хранения данных на флеш-массиве. В настоящее время ускоритель предлагается для массивов FlashArray//XL, включая приобретённые по подписке Evergreen. В дальнейшем Pure Storage планирует добавить поддержку DCA в другие серии массивов FlashArray.
27.02.2023 [16:23], Сергей Карасёв
FPGA для 5G: AMD представила Zynq UltraScale+ RFSoCКомпания AMD на выставке MWC 2023 анонсировала новые высокопроизводительные продукты для 5G-платформ. Отмечается, что экосистема партнёров AMD в области беспроводной связи расширилась вдвое в течение 2022 года благодаря интеграции продуктов AMD и Xilinx, а также формированию новой тестовой лаборатории Telco Solutions в сотрудничестве с VIAVI. AMD пополнила ассортимент цифровых устройств DFE (Digital Front-End) Zynq UltraScale+ RFSoC двумя изделиями: моделями Zynq UltraScale+ RFSoC ZU63DR и Zynq UltraScale+ RFSoC ZU64DR. Эти новые SoC позволят развёртывать станции 4G/5G в любой точке мира, где необходимы относительно недорогие вышки с низким энергопотреблением и широким спектром. 
Источник изображений: 3DNews Решение Zynq UltraScale + RFSoC ZU63DR ориентировано на устройства с четырьмя передающими и четырьмя приёмными (4T4R) двухдиапазонными радиоблоками начального уровня O-RAN (O-RU). Изделие Zynq UltraScale+ RFSoC ZU64DR, в свою очередь, предназначено для систем 8T8R. В рамках развития телекоммуникационной экосистемы компании AMD и Nokia совместно объявили о расширении сотрудничества, предусматривающего использование серверов на процессорах EPYC для предоставления решений Nokia Cloud RAN. 
Кроме того, в ходе MWC 2023 компания AMD продемонстрировала ускорители Xilinx T2 Telco и Napatech FPGA SmartNIC. Первый использует чип Zynq UltraScale+ RFSoC ZU48DR: он выполнен в виде карты расширения HHHL с интерфейсом PCIe 3.0 x16 / 4.0 x8. Пропускная способность в расчёте на ядро SD-FEC достигает 35 Гбит/с при кодировании информации и 12 Гбит/с при декодировании. В серию Napatech FPGA SmartNIC входят модели с различной пропускной способностью — до 100 Гбит/с.
25.11.2022 [14:37], Сергей Карасёв
Платформа Innodisk EXMU-X261FPGA с чипом Xilinx рассчитана на системы машинного зренияКомпания Innodisk анонсировала ИИ-платформу EXMU-X261FPGA, предназначенную для обработки задач машинного зрения в системах видеонаблюдения, устройствах промышленной автоматизации, встраиваемом оборудовании и т. п. В основу новинки положен FPGA-модуль AMD Xilinx Kria K26. Задействован чип Zynq UltraScale+ XCK26 FPGA MPSoC, содержащий четыре вычислительных ядра Arm Cortex-A53. Возможно кодирование/декодирование видеопотока в форматах H.264/265, а для вывода изображения служит коннектор HDMI 1.4. 
Источник изображения: Innodisk Решение оснащено слотом для карты microSD, разъёмами M.2 2230 E-Key (PCIe 2.0 x1, USB 2.0) и M.2 2242 M-Key (PCIe 3.0 x4), четырьмя портами USB 3.1 Gen1 Type-A, портом USB Type-C, а также сетевым портом 1GbE (RJ45). Доступны интерфейсы GPIO, UART, I2C. Для подачи питания служит DC-разъём (9–15 В); заявленное энергопотребление — около 12 Вт. Изделие Innodisk EXMU-X261FPGA имеет размеры 120 × 100 мм. Будут предлагаться коммерческий и индустриальный варианты исполнения: в первом случае диапазон рабочих температур простирается от 0 до +70 °C, во втором — от -40 до +85 °C. Говорится о поддержке операционных систем Linux 5.4.0 и Ubuntu 18.04, а также пакета Innodisk AI Suite SDK. О сроках начала продаж и ориентировочной цене информации пока нет. Более подробно о новинке можно узнать на этой странице.
25.11.2022 [10:28], Сергей Карасёв
AMD объявила о повышении цен на FPGA-чипы Xilinx — некоторые стали дороже сразу на 25 %Компания AMD распространила уведомление о грядущем повышении цен на FPGA разработки Xilinx. В некоторых случаях рост составит до 25 %. Связано это с инвестициями AMD в сеть поставок, а также с увеличением стоимости компонентов в сложившейся макроэкономической ситуации. С 9 января 2023 года цены на изделия серии Spartan 6 (45 нм) поднимутся на четверть. Стоимость продуктов семейства Versal (7 нм) не изменится, а все другие FPGA-устройства Xilinx подорожают на 8 %. 
Источник изображения: Xilinx Кроме того, AMD обнародовала информацию о сроках выполнения новых заказов на продукцию Xilinx. Так, на организацию поставок решений UltraScale+ (16 нм), UltraScale (20 нм) и 7-Series (28 нм) потребуется 20 недель с момента подписания соглашения о покупке. Причём такая ситуация сохранится до второго–третьего квартала 2023 года. В случае продуктов серии Spartan 6 нынешние сроки исполнения заказов сохранятся на протяжении следующего года, тогда как для Versal теперь обеспечиваются стандартные сроки отгрузок. Для всех прочих изделий Xilinx обычные сроки поставок будут обеспечены к концу первого квартала 2023-го. Сделку по приобретению Xilinx компания AMD завершила в начале текущего года. На момент объявления о поглощении сумма составляла $35 млрд. Покупка Xilinx позволила AMD в III квартале 2022 финансового года увеличить выручку в подразделении встраиваемых решений на 1549 %, или более чем в 16 раз: показатель достиг $1,3 млрд против $79 млн годом ранее. |
|

