Материалы по тегу: xilinx
|
11.04.2024 [14:47], Сергей Карасёв
AMD представила гибридные FPGA Versal Gen 2 для встраиваемых систем с ИИКомпания AMD анонсировала так называемые адаптивные SoC семейства Versal второго поколения (Gen 2), предназначенные для встраиваемых систем со средствами ИИ. Утверждается, что чипы обеспечивают до трёх раз более высокий показатель производительности TOPS/Вт по сравнению с решениями Versal AI Edge первого поколения. Дебютировали чипы серий Versal AI Edge Gen 2 и Versal Prime Gen 2. Изделия первого семейства, как утверждается, содержат оптимальный набор блоков для решения задач на встраиваемых системах с ИИ: это предварительная обработка данных с помощью программируемой логики FPGA, инференс и постобработка с использованием ядер Arm. 
Источник изображений: AMD Производительность INT8 у чипов Versal AI Edge Gen 2 в зависимости от модификации варьируется от 31 до 185 TOPS, быстродействие MX6 — от 61 до 370 TOPS. В составе процессора приложений задействованы ядра Arm Cortex-A78AE, количество которых может составлять 4 или 8. Кроме того, используются 4 или 10 ядер реального времени Arm Cortex-R52. Заявлена поддержка интерфейсов PCI Express 5.0 x4, USB 3.2, DisplayPort 1.4, 10GbE и 1GbE, UFS 3.1, CAN/CAN-FD, SPI, UART, USB 2.0, I2C/I3C, GPIO.
В свою очередь, решения Versal Prime Gen 2 предназначены для ускорения задач в традиционных встраиваемых системах, которые не работают с ИИ-приложениями. Они объединяют до восьми ядер Arm Cortex-A78AE и до 10 ядер реального времени Arm Cortex-R52. Набор поддерживаемых интерфейсов аналогичен изделиям Versal AI Edge Gen 2. Говорится о возможности многоканальной обработки видео в формате 8K. 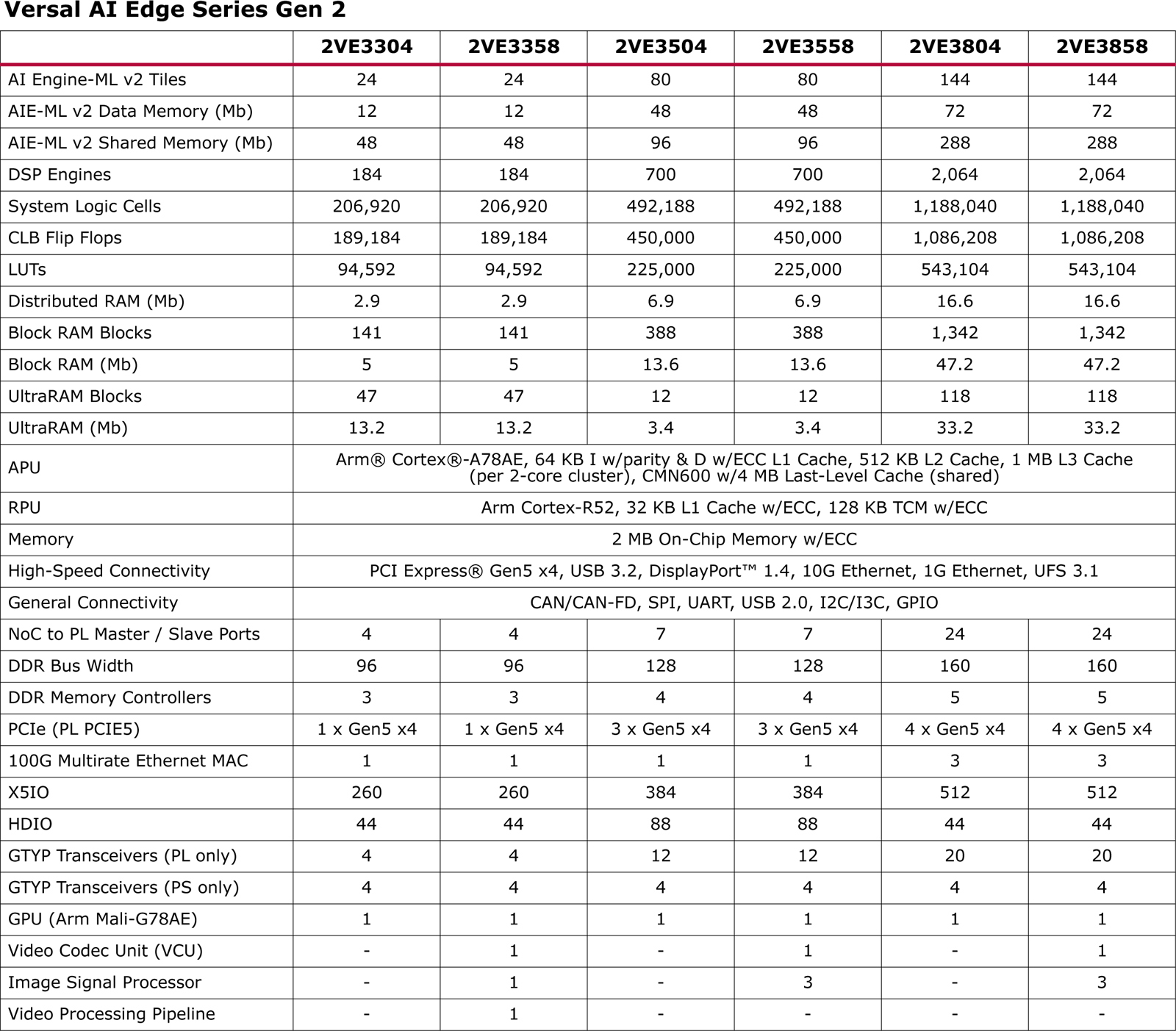 Отмечается, что новые процессоры лягут в основу систем для автомобильной, аэрокосмической и оборонной отраслей, промышленности, а также сфер машиностроения, здравоохранения, вещания и пр. Чипы позволяют разрабатывать высокопроизводительные продукты для периферийных вычислений. 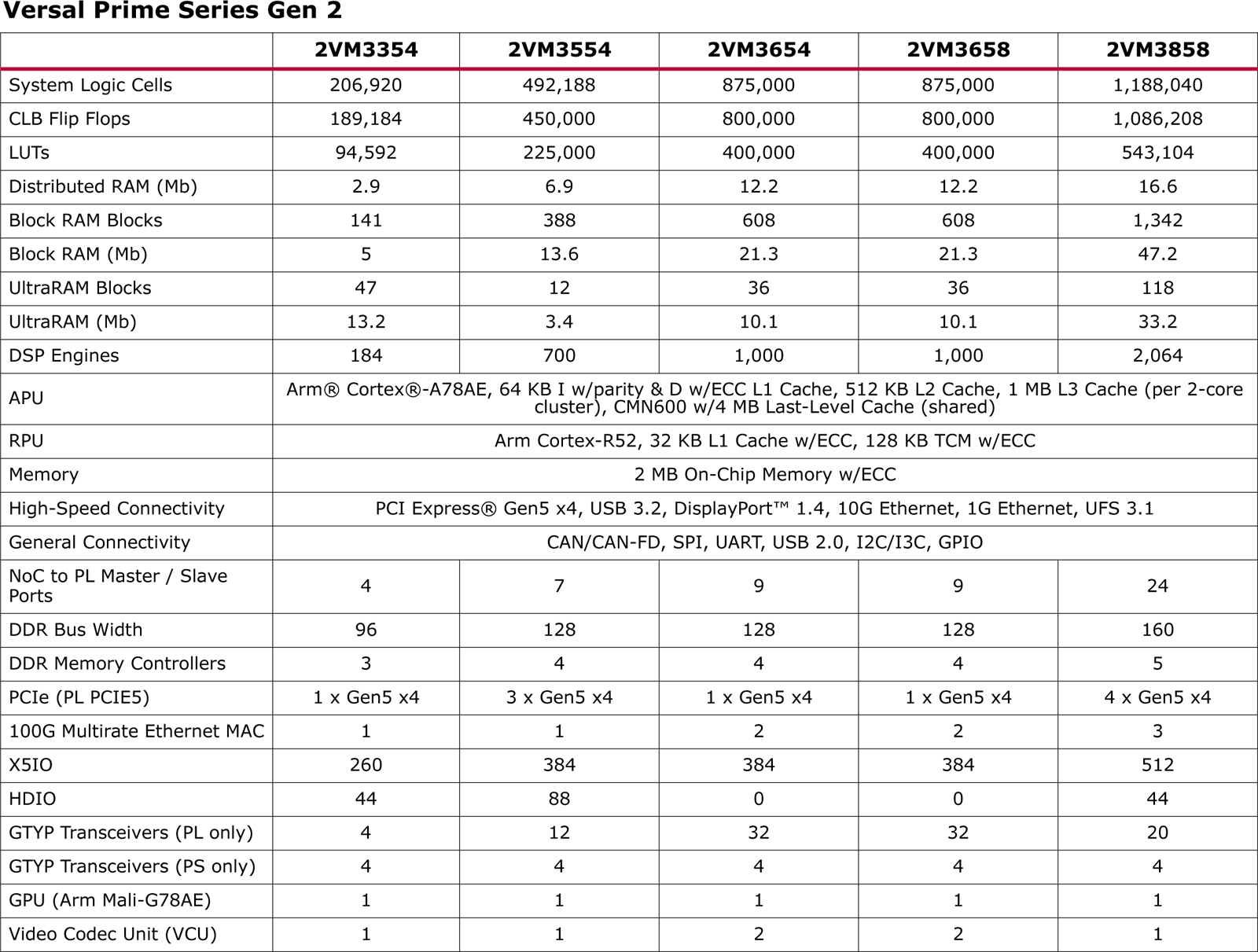
07.03.2024 [22:21], Алексей Степин
AMD анонсировала новую серию FPGA Spartan UltraScale+AMD продолжает совершенствовать не только архитектуры Zen и Instinct, но и уделяет существенное внимание развитию технологий, полученных в наследство от Xilinx. Компания анонсировала новый модельный ряд FPGA Spartan UltraScale+, который должен заменить устаревшие серии Spartan 6 и Spartan 7. Новые ПЛИС относятся к категории энергоэффективных решений с достаточно невысокой стоимостью. В сравнении с предыдущими поколениями Spartan UltraScale+ стали не только более высокоплотными за счёт применения 16-нм техпроцесса, но и получили ряд новых возможностей и функций. 
Источник здесь и далее: AMD via ServeTheHome/Phoronix Сообщается, что на сегодняшний момент эти микросхемы обладают наибольшим числом каналов ввода-вывода к логическим ячейкам, что делает Spartan UltraScale+ подходящими для использования в сценариях с высоким I/O-трафиком. При этом благодаря переходу на 16-нм техпроцесс и внедрению готовых IP-блоков (без применения программируемой логики) PCIe и DDR энергопотребление удалось снизить на 30%.  Существенно расширены возможности в области обеспечения информационной безопасности: серия поддерживает работу с шифрованием, имеет на борту генератор случайных чисел (TRNG) и соответствует требованиям NIST к постквантовой криптографии. Дополнительным преимуществом является компактность новинок: они имеют габариты от 10 × 10 мм у младших моделей до 23 × 23 мм у старших. Доступны будут варианты упаковки BGA и CSP. 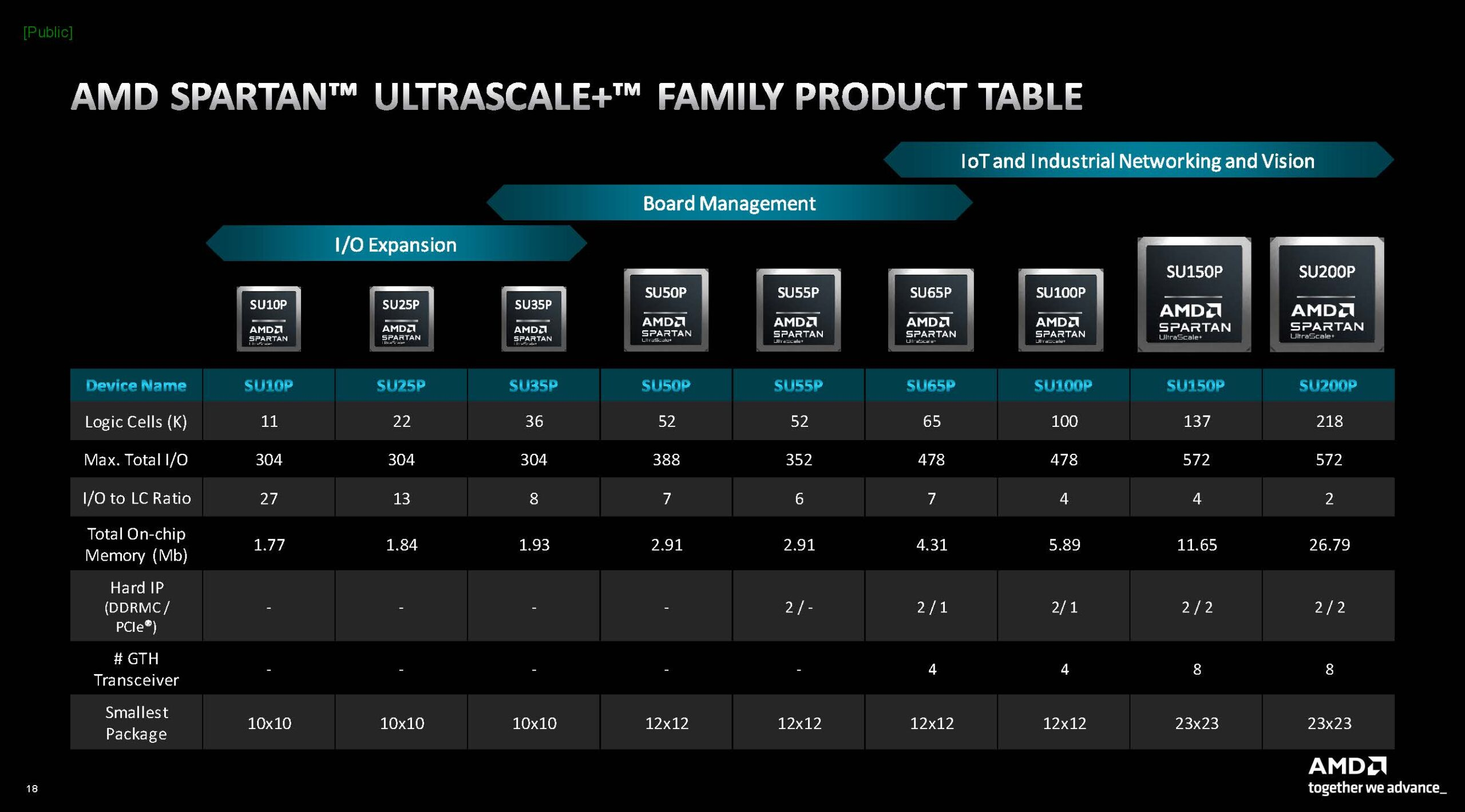 В серии представлены модели сложностью от 11 до 218 логических ячеек с быстрой набортной памятью объёмом от 1,77 до 26,8 Мбайт. Интерфейсы PCIe 4.0 и LPDDR4x/5 имеют не все модели, а лишь начиная с достаточно производительной SU65P. А вот полновесные 8 линий PCIe предоставляют лишь две старшие модели.  Новая серия Spartan UltraScale+ логичным образом дополняет модельные ряды Zynq UltraScale+ и Artix UltraScale+. С её анонсом портфолио 16-нм ПЛИС AMD обретает завершённый вид. Благодаря упору на развитую I/O-подсистему новинки найдут применение в соответствующих сценариях, став, например, BMC-контроллерами для серверов и GPU-комплексов или платформой для робототехнических манипуляторов с большим числом степеней свободы. 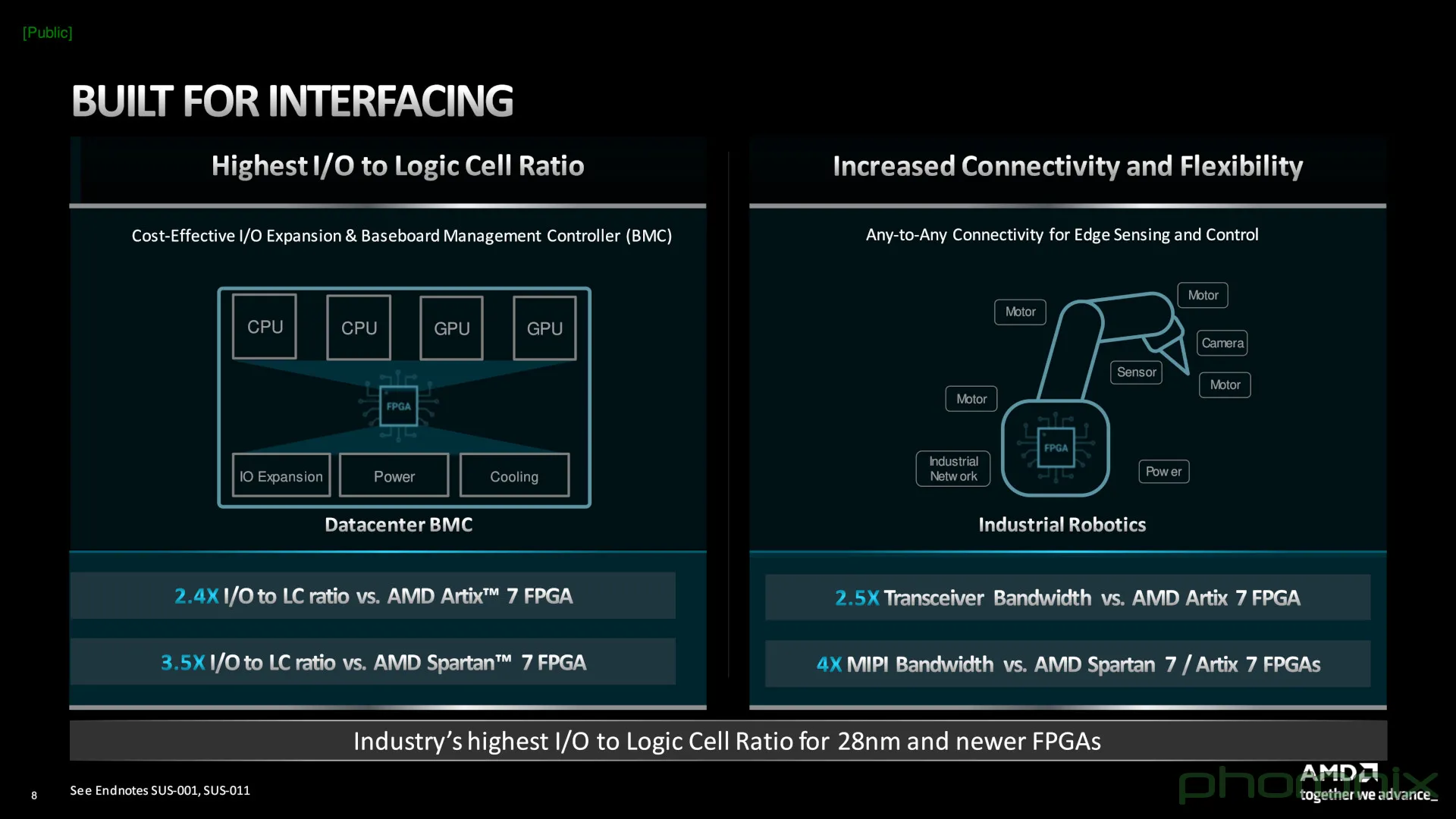 Документация на Spartan UltraScale+ доступна с момента анонса, средства разработки для новых ПЛИС появятся в IV квартале, а первых комплектов разработчика с актуальным «кремнием» на борту следует ожидать в I половине 2025 года. 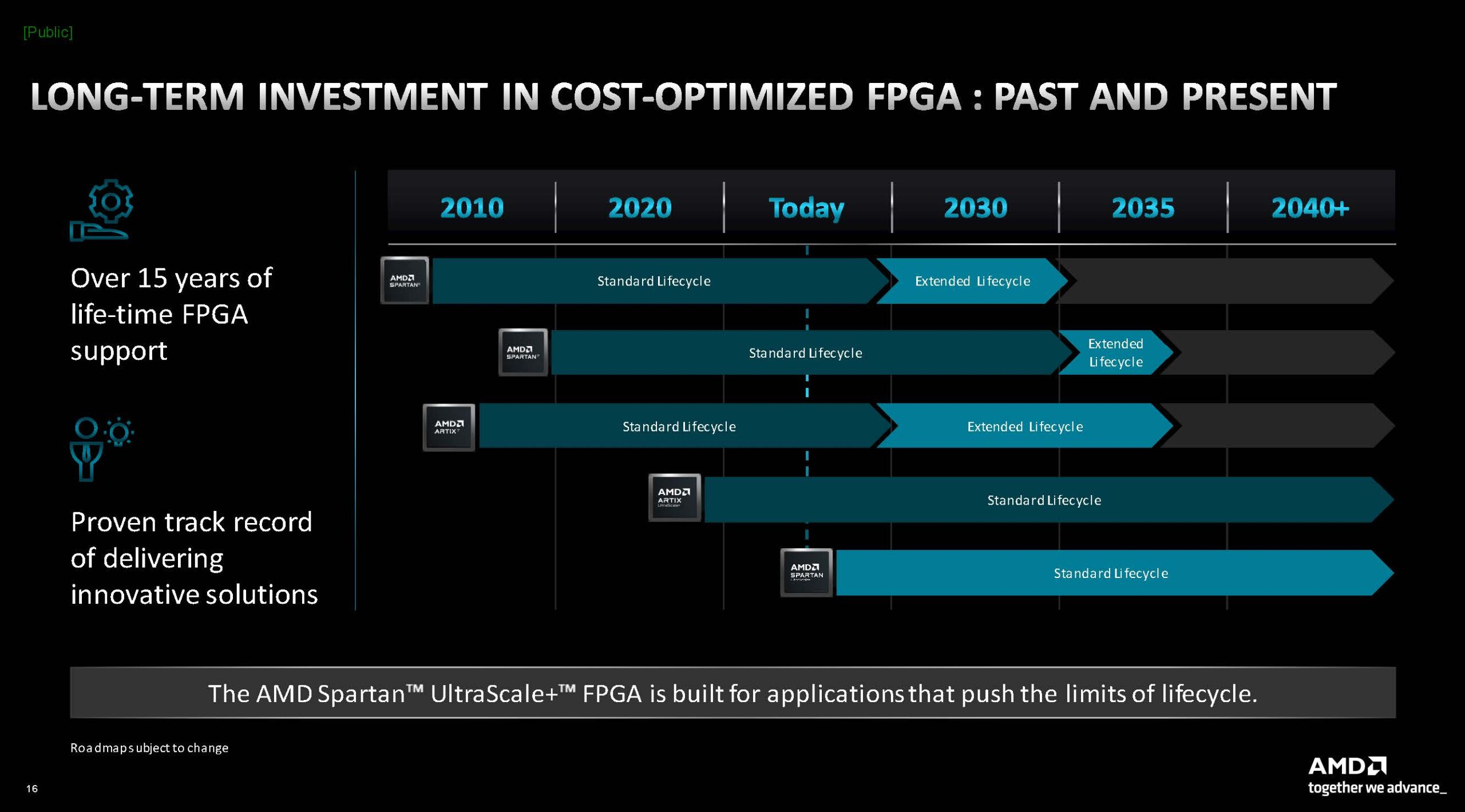 Компания также поделилась планами относительно жизненного цикла всех выпускаемых серий FPGA. Серии Spartan 6/7 и Artix 7 будут лишены поддержки в 2030–2035 гг., а решения модельного ряда UltraScale+ будут поддерживаться минимум до 2040 года, что важно для чипов, являющихся основой для промышленных платформ и долговременной ИТ-инфраструктуры.
02.10.2023 [15:57], Сергей Карасёв
AMD представила ускоритель Alveo UL3524 для брокерских и биржевых приложенийКомпания AMD анонсировала специализированный ускоритель Alveo UL3524 на базе FPGA, ориентированный на финтех-сферу. Решение, как утверждается, позволяет трейдерам, хедж-фондам, брокерским конторам и биржам совершать операции с задержками наносекундного уровня. В основу новинки положен чип FPGA Virtex UltraScale+, выполненный по 16-нм технологии. Конфигурация включает 64 трансивера с ультранизкой задержкой, 780 тыс. LUT и 1680 DSP. Отмечается, что Alveo UL3524 обеспечивает в семь раз меньшую задержку по сравнению с FPGA предыдущего поколения. В частности, инновационная архитектура трансиверов с оптимизированными сетевыми ядрами позволяет добиться показателя менее 3 нс. 
Источник изображения: AMD Ускоритель может использоваться в комплексе с платформой разработки Vivado Design Suite. AMD также предоставляет разработчикам среду FINN с открытым исходным кодом, что позволяет внедрять в высокопроизводительные трейдинговые системы модели ИИ с низкими задержками. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe 4.0 x16. Задействован система пассивного охлаждения, а показатель TDP заявлен на отметке 125 Вт. Предусмотрены четыре сетевых порта QSFP-DD. Карта несёт на борту 16 Гбайт памяти DDR4-2666 и 72 Мбайт памяти QDR II+. Весит ускоритель 832 г.
15.09.2023 [12:03], Сергей Карасёв
AMD начала производство мощных SoC Versal HBM для ИИ-задачКомпания AMD объявила об организации массового выпуска «адаптивных» однокристальных систем (SoC) серии Versal HBM, которые могут применяться в составе облачных платформ, ИИ-решений, а также на периферии. Как отражено в названии, изделия оснащены высокоскоростной памятью HBM (High-Bandwidth Memory). Применены чипы HBM2e. Утверждается, что по сравнению с существующими решениями Versal Premium SoC, оборудованными памятью DDR4, достигается шестикратное увеличение пропускной способности и сокращение энергопотребления приблизительно на 65 % в расчёте на бит. 
Источник изображения: AMD Для разработчиков, экспериментирующих с Versal HBM, компания AMD выпустила комплект VHK158 Evaluation Kit. Решение наделено 32 Гбайт памяти HBM, двумя слотами DDR4-3200 DIMM, интерфейсами PCIe 5.0 x8 и PCIe 4.0 x16. В качестве процессора приложений задействован чип с двумя вычислительными ядрами Arm Cortex-A72. Плата VHK158 Evaluation Kit располагает слотом microSD, трансиверами 112G PAM4, разъёмами QSFP28 и QSFP-DD, коннектором FMC+. Заявленная пропускная способность памяти HBM достигает 819,2 Гбайт/с. Габариты составляют 247 × 220 мм. Диапазон рабочих температур простирается от 0 до +45 °C. Стоит комплект приблизительно $15 тыс.
28.06.2023 [19:04], Алексей Степин
AMD представила царь-FPGA VP1902, самую большую в мире чиплетную ПЛИС для разработки новых чиповAMD активно развивает доставшиеся ей в наследство активы Xilinx в области создания программируемых матриц (FPGA), понимая, что применений таким чипам в современном мире очень много. Компания снова получила лавры создателя самой большой и сложной FPGA — ранее это была Xilinx VU19P, а сейчас речь идёт об AMD VP1902, пополнившей серию Versal Premium. Чиплетная технология захватывает индустрию — благодаря модульности становится возможным создание сверхсложных и сверхмощных решений. Относится к чиплетным и новая матрица Versal VP1902, состоящая из четырёх больших чиплетов, объединённых высокоскоростным программируемым интерконнектом (network-on-a-chip, NoC) в массив с габаритами 77 × 77 мм. 
Источник изображений здесь и далее: AMD Рост сложности FPGA обусловлен тем, что эмуляция всё более современных и мощных процессорных ядер требует большего количества логических ячеек. Здесь новинка вне конкуренции, поскольку включает 18,5 млн таких ячеек, что, по словам AMD, позволяет массиву таких FPGA эмулировать весьма мощные чипы. 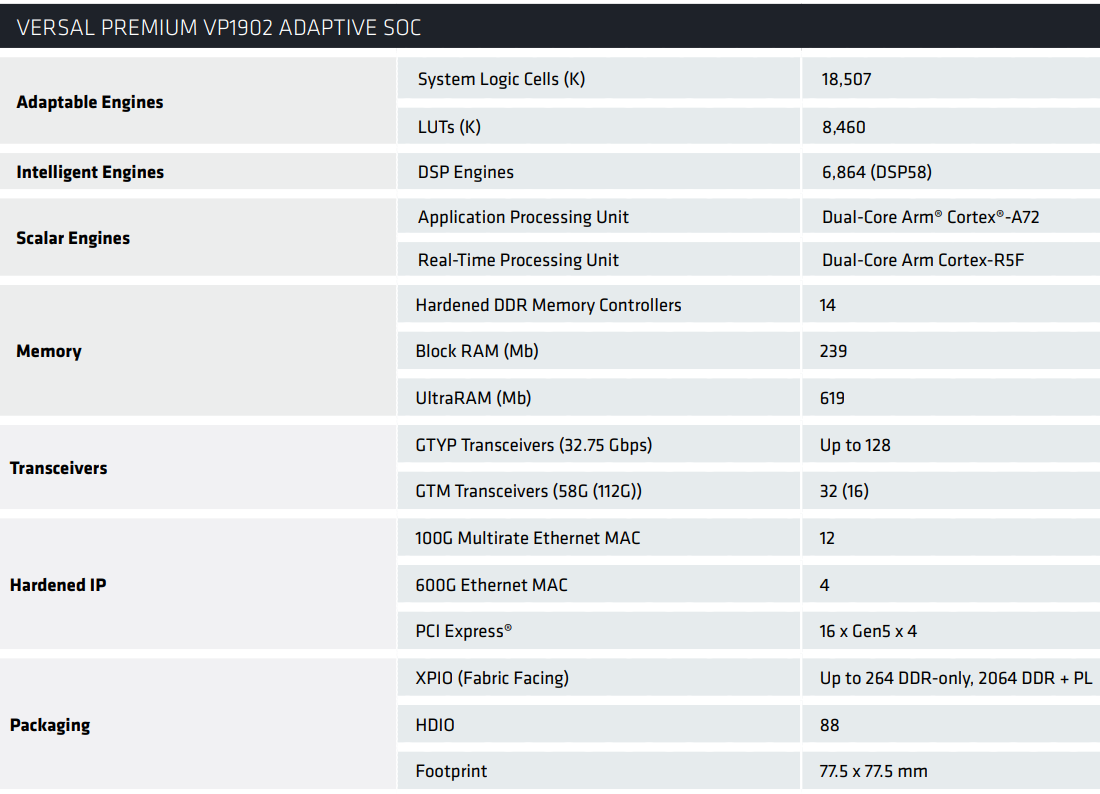 Помимо этого, в состав VP1902 входит 14 защищённых контроллеров DDR, четыре MAC-блока Ethernet класса 600G (100–400GbE) и 12 блоков 100G (10–100GbE), а также четыре фиксированных блока PCIe 5.0 x16. Для межчипового соединения используется интерконнект XPIO с пропускной способностью 5,6 Тбит/с, а совокупная пропускная способность 160 доступных трансиверов составляет 12,2 Тбит/с.  С совместимостью у новинки всё в порядке, она использует тот же комплект программного обеспечения Vivado ML, что и другие решения компании. По самой своей природе AMD VP1902 нацелена, в первую очередь, на рынок разработчиков сложных процессоров. 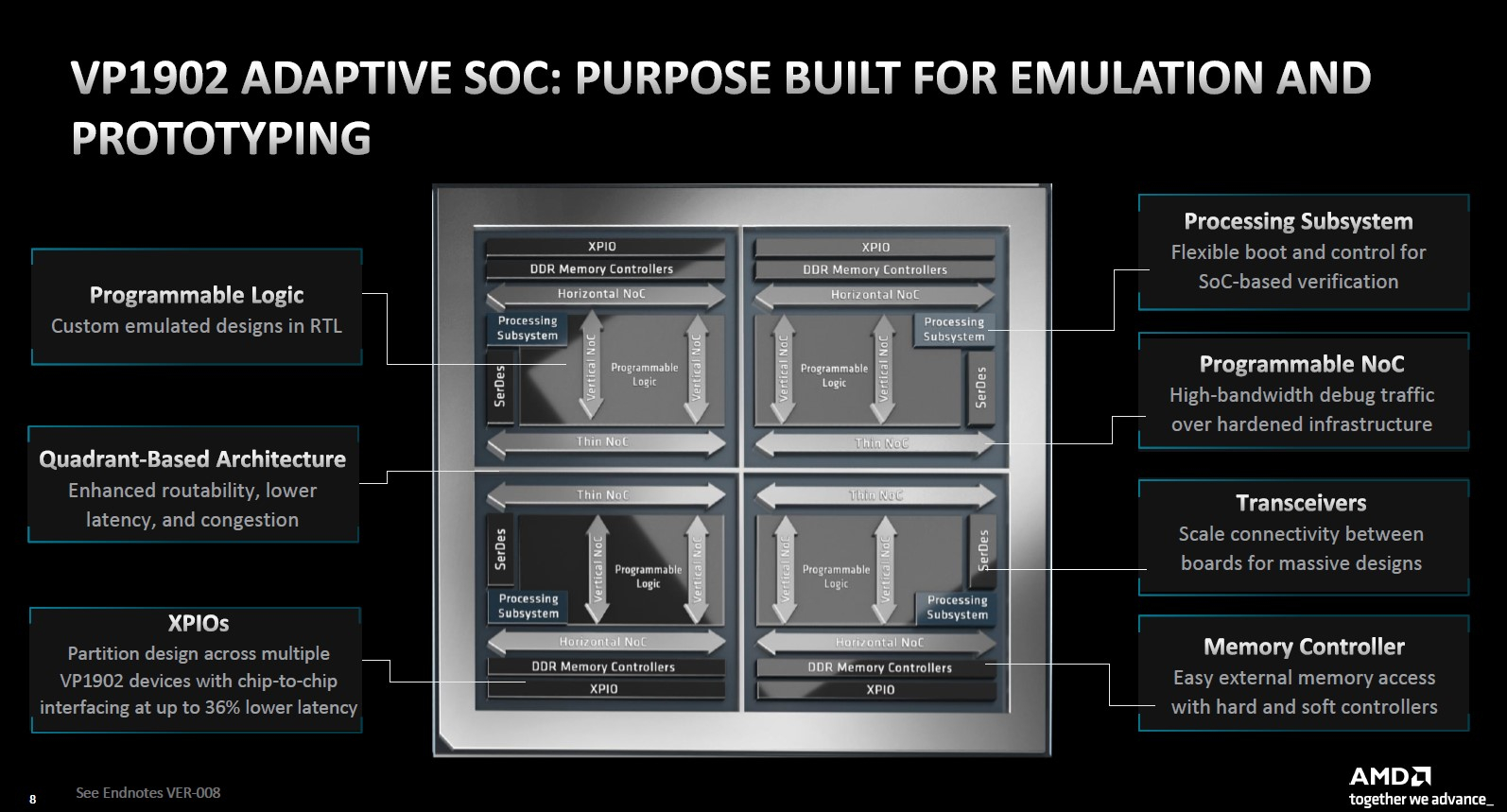 Однако сфера применения у неё намного шире — новинка отлично подойдёт и разработчикам прошивок, всевозможных блоков IP, впишется она в цикл прототипирования различных подсистем, валидации аппаратного обеспечения и другие подобные сценарии. Образцы VP1902 появятся в III квартале 2023 года, массовое производство начнётся в первой половине следующего года.
07.04.2023 [20:38], Сергей Карасёв
AMD представила ускоритель Alveo MA35D для «умного» кодирования AV1-видеоAMD анонсировала специализированный ускоритель Alveo MA35D для работы с видеоматериалами. Новинка приходит на смену FPGA Alveo U30 компании Xilinx, которую AMD поглотила в начале 2022 года. По сравнению с предшественником модель Alveo MA35D привносит поддержку AV1 и 8K, а также обещает четырёхкратное увеличение количества одновременно обрабатываемых видеопотоков. Решение может одновременно обрабатывать до 32-х потоков 1080p60, до восьми потоков 4Kp60 или до четырёх потоков 8Kp30. В основу ускорителя положены два VPU-блока на базе 5-нм ASIC, разработка которых началась ещё в недрах Xilinix, но которые не имеют отношения к FPGA. Каждый модуль VPU включает два «полноценных» кодировщика с поддержкой AV1/VP9/H.264/H.265 и два — только с AV1. Каждый из VPU использует 8 Гбайт собственной памяти LPDDR5, а для связи с CPU служит интерфейс PCIe 5.0 x8 (по x4 для каждого модуля). В состав VPU также входят четыре ядра общего назначения с архитектурой RISC-V. Для новинки доступен SDK-комплект с поддержкой широко используемых видеофреймворков FFmpeg и Gstreamer. 
Источник изображений: AMD (via AnandTech) Интересной особенностью является наличие выделенного ИИ-ускорителя (22 Топс) для предварительной обработки видеопотока и улучшения качества и скорости кодирования. Ускоритель покадрово определяет, какие части изображения (лица, текст и т.д.) должны быть закодированы с повышенными качестовом, а какие — нет. Также он определяет повреждённые кадры и по возможности восстанавливает или удаляет их до передачи кодировщику. При этом задержка при 4К-стриминге составляет приблизительно 8 мс. 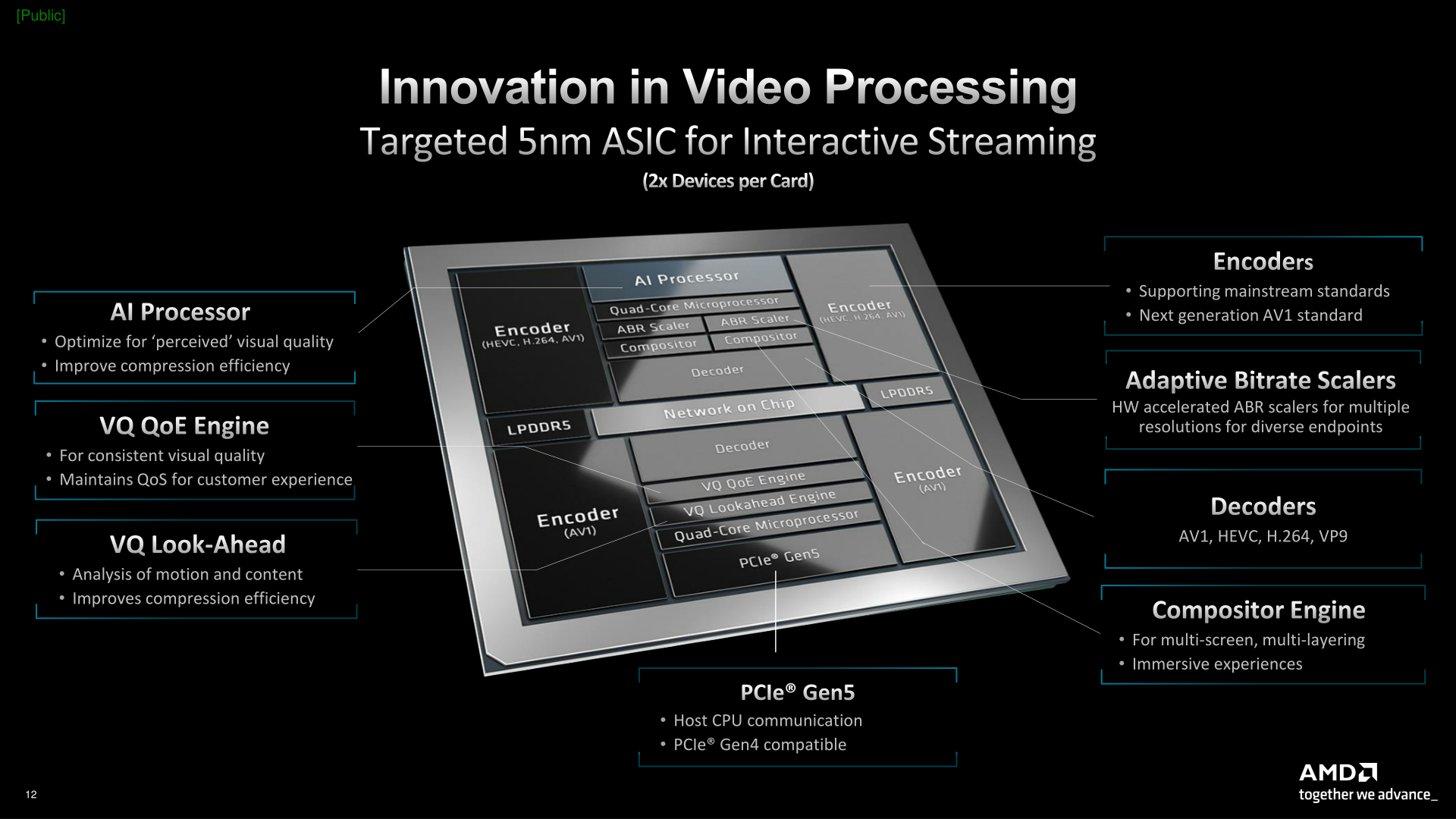 Заявленное энергопотребление составляет 1 Вт в расчёте на один канал 1080p60. Показатель TDP составляет 50 Вт, но, по заявлениям AMD, в обычных условиях он не превышает 35 Вт. Ускоритель выполнен в виде низкопрофильной однослотовой PCIe-карты. Задействована пассивная система охлаждения. В один 1U-сервер могут быть установлены до восьми таких ускорителей, что позволит одновременно обрабатывать до 256 видеопотоков. Пробные поставки карты уже начались, а массовые отгрузки намечены на III квартал 2023 года. Рекомендованная цена составляет $1595.  AMD подчёркивает, что новый (де-)кодер разработан с нуля, а не позаимствован из её же GPU. В этом отличие подхода от Intel и NVIDIA, которые предлагают использовать более универсальные GPU Flex и L4 соответственно. Alveo MA35D рассчитан на стриминговые площадки, видеохостинги и т.д. При этом Google, например, уже разработала собственные ASIC Argos, а Meta✴ заручилась поддержкой Broadcom для той же цели.
27.02.2023 [16:23], Сергей Карасёв
FPGA для 5G: AMD представила Zynq UltraScale+ RFSoCКомпания AMD на выставке MWC 2023 анонсировала новые высокопроизводительные продукты для 5G-платформ. Отмечается, что экосистема партнёров AMD в области беспроводной связи расширилась вдвое в течение 2022 года благодаря интеграции продуктов AMD и Xilinx, а также формированию новой тестовой лаборатории Telco Solutions в сотрудничестве с VIAVI. AMD пополнила ассортимент цифровых устройств DFE (Digital Front-End) Zynq UltraScale+ RFSoC двумя изделиями: моделями Zynq UltraScale+ RFSoC ZU63DR и Zynq UltraScale+ RFSoC ZU64DR. Эти новые SoC позволят развёртывать станции 4G/5G в любой точке мира, где необходимы относительно недорогие вышки с низким энергопотреблением и широким спектром. 
Источник изображений: 3DNews Решение Zynq UltraScale + RFSoC ZU63DR ориентировано на устройства с четырьмя передающими и четырьмя приёмными (4T4R) двухдиапазонными радиоблоками начального уровня O-RAN (O-RU). Изделие Zynq UltraScale+ RFSoC ZU64DR, в свою очередь, предназначено для систем 8T8R. В рамках развития телекоммуникационной экосистемы компании AMD и Nokia совместно объявили о расширении сотрудничества, предусматривающего использование серверов на процессорах EPYC для предоставления решений Nokia Cloud RAN. 
Кроме того, в ходе MWC 2023 компания AMD продемонстрировала ускорители Xilinx T2 Telco и Napatech FPGA SmartNIC. Первый использует чип Zynq UltraScale+ RFSoC ZU48DR: он выполнен в виде карты расширения HHHL с интерфейсом PCIe 3.0 x16 / 4.0 x8. Пропускная способность в расчёте на ядро SD-FEC достигает 35 Гбит/с при кодировании информации и 12 Гбит/с при декодировании. В серию Napatech FPGA SmartNIC входят модели с различной пропускной способностью — до 100 Гбит/с.
02.02.2023 [01:15], Владимир Мироненко
Чипы EPYC принесли AMD значительную выручку, хотя прибыль упала на 98 %Несмотря на падение продаж ПК, выручка AMD за IV квартал 2022 года выросла в годовом исчислении на 16 % до $5,6 млрд, превзойдя прогнозы экспертов, ожидавших рост до $5,5 млрд. Увеличения выручки удалось добиться в основном благодаря увеличению дохода в сегментах встраиваемых систем и ЦОД, тогда как в клиентском и игровом сегментах наблюдалось снижение выручки. Выручка сегмента ЦОД составила за квартал $1,7 млрд при прогнозе аналитиков $1,6 млрд, что на 42 % больше, чем в прошлом году, причём основным драйвером продаж были серверные процессоры EPYC. Операционная прибыль сегмента равняется $444 млн или 27 % выручки, в то время годом ранее эти показатели были равны $369 млн и 32 % соответственно. Увеличение операционной прибыли было в основном обусловлено более высокой выручкой, часть которой была израсходована на более крупные инвестиции в исследования и разработки. 
Источник изображений: AMD В сегменте встраиваемых систем отмечен рост выручки на 1868 % по сравнению с прошлым годом, составившей $1,4 млрд (прогноз аналитиков — $1,3 млрд), что было достигнуто в основном за счёт включения в этот объём выручки от решений Xilinx. Операционная прибыль составила $699 млн или 50 % выручки, тогда как год назад эти показатели были равны $18 млн и 25 %. Увеличение операционной прибыли и маржи в основном было обусловлено ростом выручки.  Выручка клиентского сегмента упала по сравнению с предыдущим годом на 51 % до $903 млн, что было обусловлено сокращением поставок процессоров из-за спада спроса на рынке ПК и значительной корректировки товарно-материальных запасов по всей цепочке поставок. Прогноз аналитиков равнялся $995 млн. Выручка игрового сегмента тоже упала, но не так сильно — на 7 % в годовом исчислении до $1,6 млрд (прогноз аналитиков — $1,5 млрд) из-за более низких продаж игровой графики, частично компенсированных более высокими доходами от полузаказных продуктов. 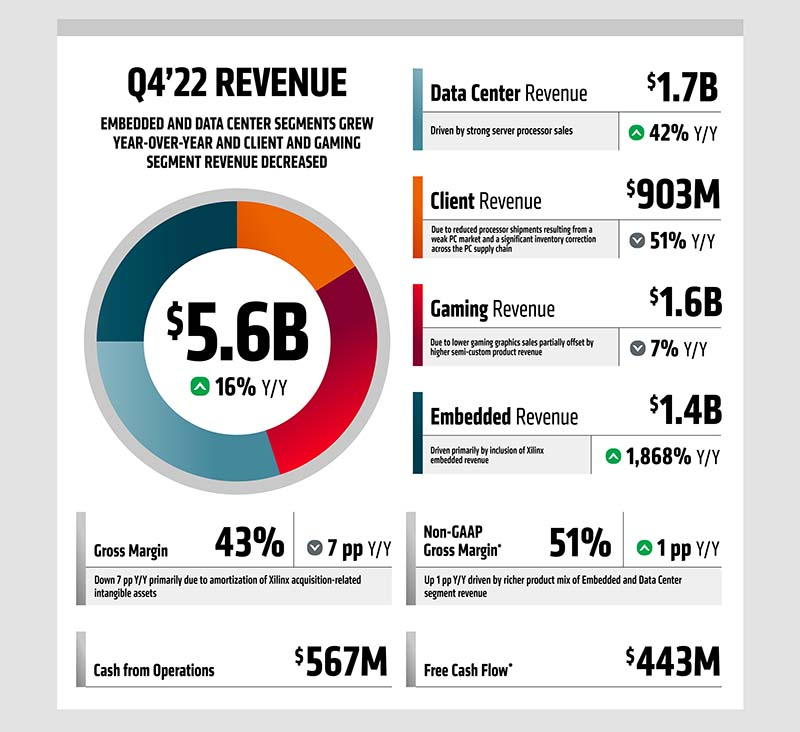 В IV квартале валовая прибыль AMD составила 43 %. Компания сообщила об операционных убытках в размере $149 млн, хотя годом ранее у неё была операционная прибыль $1,2 млрд — это в основном вызвано амортизацией нематериальных активов, в значительной степени связанной с приобретением Xilinx. Чистая прибыль составила $21 млн, что на 98 % меньше прошлогоднего показателя, равного $974 млн.  По итогам 2022 года выручка AMD составила $23,6 млрд, что на 44 % показателя 2021 года, равного $16,4 млрд. Валовая прибыль равна 45 %, операционная прибыль — $1,3 млрд, что меньше показателя предыдущего года, равного $3,6 млрд, на 65 %. Чистая прибыль составила $1,3 млрд, сократившись по сравнению с предыдущим годом на 58 %, когда прибыль равнялась $3,2 млрд. Разводненная прибыль на акцию равняется $0,84 — на 67 % меньше показателя 2021 года, равного $2,57.  «2022 год был успешным для AMD, поскольку мы продемонстрировали лучший в своём классе рост и рекордную выручку, несмотря на слабую среду ПК во второй половине года», — заявила председатель и гендиректор AMD д-р Лиза Су (Lisa Su). «Несмотря на неоднозначную со спросом, мы уверены в своей способности увеличить долю рынка в 2023 году и обеспечить долгосрочный рост на основе нашего дифференцированного портфеля продуктов», — добавила она. В I квартале 2023 года AMD прогнозирует выручку в размере $5,3 млрд (±$300 млн), что примерно на 10 % меньше, чем в аналогичном периоде прошлого года. Как ожидается, клиентский и игровой сегменты будут сокращаться, что будет частично компенсировано увеличением выручки в сегментах встраиваемых систем и ЦОД. AMD прогнозирует, что в I квартале 2023 года её валовая прибыль (non-GAAP) составит примерно 50 %.
25.11.2022 [14:37], Сергей Карасёв
Платформа Innodisk EXMU-X261FPGA с чипом Xilinx рассчитана на системы машинного зренияКомпания Innodisk анонсировала ИИ-платформу EXMU-X261FPGA, предназначенную для обработки задач машинного зрения в системах видеонаблюдения, устройствах промышленной автоматизации, встраиваемом оборудовании и т. п. В основу новинки положен FPGA-модуль AMD Xilinx Kria K26. Задействован чип Zynq UltraScale+ XCK26 FPGA MPSoC, содержащий четыре вычислительных ядра Arm Cortex-A53. Возможно кодирование/декодирование видеопотока в форматах H.264/265, а для вывода изображения служит коннектор HDMI 1.4. 
Источник изображения: Innodisk Решение оснащено слотом для карты microSD, разъёмами M.2 2230 E-Key (PCIe 2.0 x1, USB 2.0) и M.2 2242 M-Key (PCIe 3.0 x4), четырьмя портами USB 3.1 Gen1 Type-A, портом USB Type-C, а также сетевым портом 1GbE (RJ45). Доступны интерфейсы GPIO, UART, I2C. Для подачи питания служит DC-разъём (9–15 В); заявленное энергопотребление — около 12 Вт. Изделие Innodisk EXMU-X261FPGA имеет размеры 120 × 100 мм. Будут предлагаться коммерческий и индустриальный варианты исполнения: в первом случае диапазон рабочих температур простирается от 0 до +70 °C, во втором — от -40 до +85 °C. Говорится о поддержке операционных систем Linux 5.4.0 и Ubuntu 18.04, а также пакета Innodisk AI Suite SDK. О сроках начала продаж и ориентировочной цене информации пока нет. Более подробно о новинке можно узнать на этой странице.
25.11.2022 [10:28], Сергей Карасёв
AMD объявила о повышении цен на FPGA-чипы Xilinx — некоторые стали дороже сразу на 25 %Компания AMD распространила уведомление о грядущем повышении цен на FPGA разработки Xilinx. В некоторых случаях рост составит до 25 %. Связано это с инвестициями AMD в сеть поставок, а также с увеличением стоимости компонентов в сложившейся макроэкономической ситуации. С 9 января 2023 года цены на изделия серии Spartan 6 (45 нм) поднимутся на четверть. Стоимость продуктов семейства Versal (7 нм) не изменится, а все другие FPGA-устройства Xilinx подорожают на 8 %. 
Источник изображения: Xilinx Кроме того, AMD обнародовала информацию о сроках выполнения новых заказов на продукцию Xilinx. Так, на организацию поставок решений UltraScale+ (16 нм), UltraScale (20 нм) и 7-Series (28 нм) потребуется 20 недель с момента подписания соглашения о покупке. Причём такая ситуация сохранится до второго–третьего квартала 2023 года. В случае продуктов серии Spartan 6 нынешние сроки исполнения заказов сохранятся на протяжении следующего года, тогда как для Versal теперь обеспечиваются стандартные сроки отгрузок. Для всех прочих изделий Xilinx обычные сроки поставок будут обеспечены к концу первого квартала 2023-го. Сделку по приобретению Xilinx компания AMD завершила в начале текущего года. На момент объявления о поглощении сумма составляла $35 млрд. Покупка Xilinx позволила AMD в III квартале 2022 финансового года увеличить выручку в подразделении встраиваемых решений на 1549 %, или более чем в 16 раз: показатель достиг $1,3 млрд против $79 млн годом ранее. |
|


