Материалы по тегу: инференс
|
19.11.2023 [03:00], Сергей Карасёв
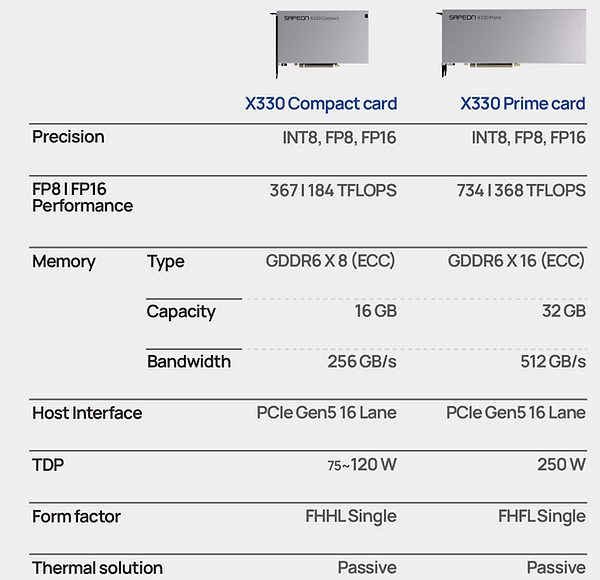
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт. 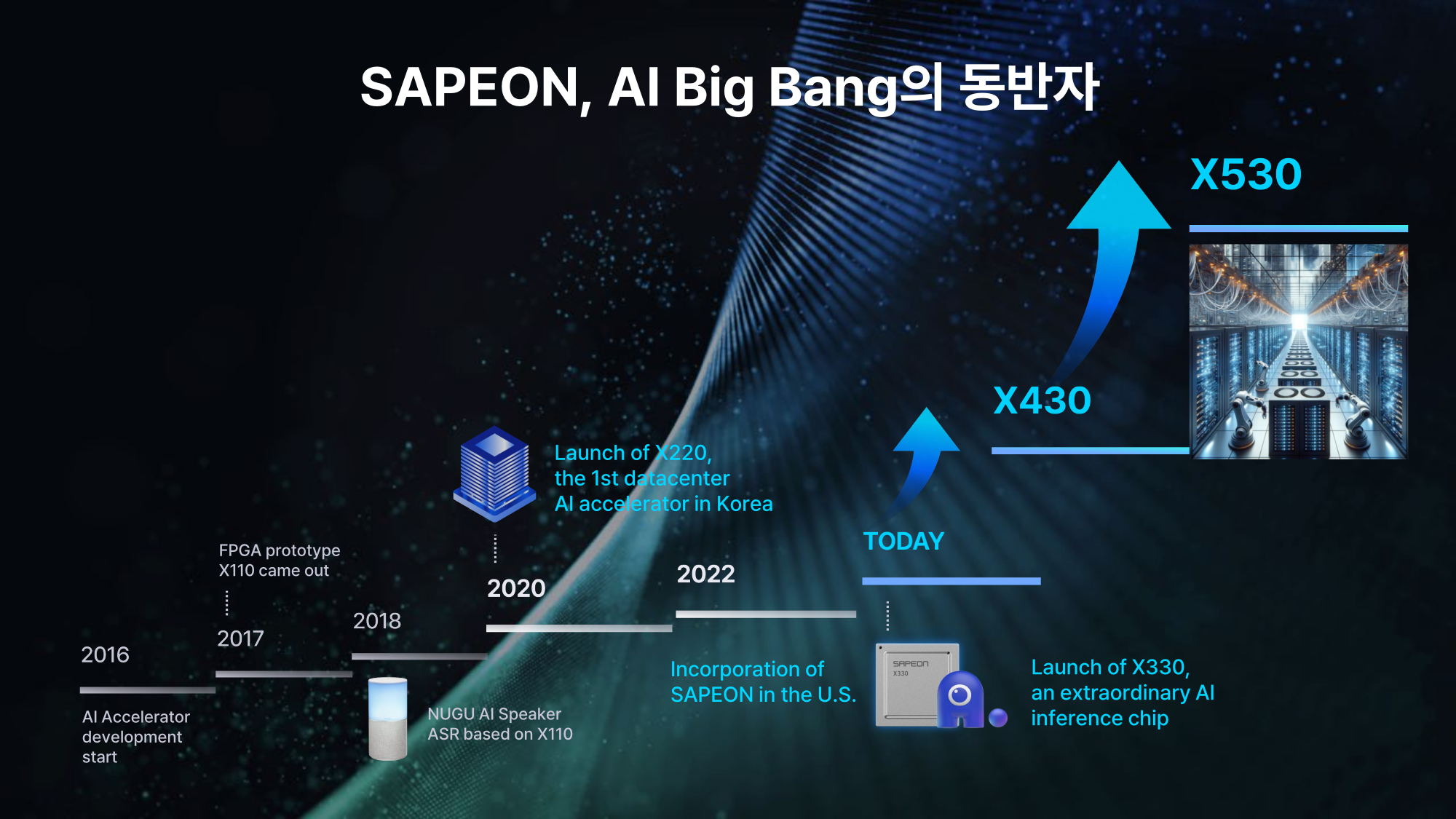 Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
19.11.2023 [01:46], Сергей Карасёв
В облаке Cirrascale появились ИИ-ускорители Qualcomm Cloud AI 100Компания Cirrascale Cloud Services сообщила о том, что в её облаке AI Innovation Cloud стали доступны инстансы на основе специализированных ИИ-ускорителей Qualcomm Cloud AI 100. Сервис предназначен для инференса, обработки больших языковых моделей (LLM), генеративных ИИ-систем, приложений машинного зрения и т. п. Решение Qualcomm Cloud AI 100, выполненное в виде однослотовой 75-Вт карты PCIe с пассивынм охлаждением. Ускоритель поддерживает вычисления FP16/32 и INT8/16. Задействованы 16 ядер Qualcomm AI Cores и 16 Гбайт памяти LPDDR4x-2133 с пропускной способностью 136,5 Гбайт/с. Qualcomm Cloud AI 100 обеспечивает быстродействие до 350 TOPS на операциях INT8 и до 175 Тфлопс при вычислениях FP16. Cirrascale Cloud Services предлагает инстансы на базе одной, двух, четырёх и восьми карт Qualcomm Cloud AI 100. Количество vCPU варьируется от 12 до 64, объём оперативной памяти — от 48 до 384 Гбайт. Во всех случаях задействован SSD вместимостью 1 Тбайт (NVMe). 
Источник изображения: Qualcomm / Lenovo Разработчики могут использовать комплект Qualcomm Cloud AI SDK, который предлагает различные инструменты в области ИИ — от внедрения предварительно обученных моделей до развёртывания приложений глубокого обучения. Стоимость инстансов варьируется от $329 до $2499 в месяц (при оформлении годовой подписки — от $259 до $2019 в месяц).
15.11.2023 [15:52], Сергей Карасёв
NeuReality представила «сервер на чипе» и другие аппаратные ИИ-решения для инференсаКомпания NeuReality на конференции по высокопроизводительным вычислениям SC23 представила полностью интегрированное решение NR1 AI Inference, предназначенное для ИИ-платформ. Изделие спроектировано специально для ускорения инференса и снижения нагрузки на аппаратные ресурсы. Утверждается, что благодаря использованию технологий NeuReality операторы крупных дата-центров могут на 90 % сократить затраты на выполнение операций ИИ. При этом производительность по сравнению с традиционными системами на основе CPU больше на порядок. Впрочем, конкретные цифры не приводятся. 
Источник изображений: NeuReality В продуктовое семейство NeuReality входит решение NR1, которое разработчик называет «сервером на чипе» со встроенным нейросетевым движком. По заявлениям NeuReality, это первый в мире «сетевой адресуемый процессор» — NAPU (Network Addressable Processing Unit). Этот специализированный чип, ориентированный на задачи инференса, обладает возможностями виртуализации и сетевыми функциями.  Изделие NR1 является основой вычислительного модуля NR1-M AI Inference Module, выполненного в виде полноразмерной двухслотовой карты расширения PCIe. Модуль может подключаться к внешнему ускорителю глубокого обучения (DLA). Наконец, анонсирован сервер NR1-S AI Inference Appliance, который оснащается картами NR1-M AI Inference Module. NeuReality отмечает, что данная система позволяет снизить стоимость и энергопотребление почти в 50 раз на операциях инференса по сравнению со стандартными платформами.
01.11.2023 [13:43], Руслан Авдеев
Из-за нехватки ИИ-ускорителей NVIDIA южнокорейский IT-гигант Naver Corporation вынужден перейти на CPU IntelСпрос на ИИ-ускорители NVIDIA так высок, что производитель чипов не может удовлетворить его в полной мере. В результате, как сообщает The Korean Economic Daily, создатель ведущего поискового портала Южной Кореи — компания Naver Corporation — для ряда ИИ-нагрузок перешла с использования ускорителей NVIDIA на Intel Xeon Sapphire Rapids, как из-за дефицита, так и по причине роста цен на продукцию. По данным СМИ, Naver Corp. начала использовать решения Intel для ИИ-серверов картографического сервиса Naver Place. Корейский IT-гигант использует ИИ-модель для распознавания ложных данных в случаях, когда пользователи ведут поиск по ключевым запросам вроде «ближайшие рестораны» в приложении Naver Map. Ранее именно продукты NVIDIA применялись для обработки таких данных. Впрочем, речь идёт в первую очередь об инференсе, а для обучения моделей компания всё равно вынуждена использовать ИИ-ускорители. Приобрести ИИ-ускорители NVIDIA, включая H100, стало очень сложно, а цены на последние с начала года выросли в Южной Корее вдвое. Но даже если у вас есть средства, время с момента размещения заказа на ускорители до их получения уже увеличилось до 52 недель, так что быстро обновить парк серверов не выйдет. При этом ускорители способны справляться с ИИ-задачами на порядок быстрее CPU. 
Источник изображения: Naver Как утверждают отраслевые эксперты, Intel усовершенствовала технологии работы с ИИ-системами, желая угодить клиентам, ищущим альтернативы ускорителям NVIDIA. Например, Naver в течение месяца тестировала ИИ-сервер на основе процессоров компании перед его вводом в эксплуатацию. Вероятно, южнокорейский IT-гигант продолжит использовать CPU Intel новых поколений. По мнению экспертов, сотрудничество Naver и Intel может привести к ослаблению позиций NVIDIA на рынке чипов для ИИ-вычислений. По некоторым данным, Microsoft объединила усилия с AMD, чтобы помочь последней в экспансии на рынке ИИ-процессоров. Компании сотрудничают для конкуренции с NVIDIA, контролирующей около 80 % мирового рынка ИИ-чипов.
11.10.2023 [15:39], Сергей Карасёв
Untether AI выпустила ИИ-ускоритель tsunAImi tsn200 с производительностью 500 TOPSКомпания Untether AI анонсировала специализированный ИИ-ускоритель tsunAImi tsn200, предназначенный для выполнения задач инференса за пределами дата-центров и облачных платформ. Изделие, как утверждается, обеспечивает лучшее в отрасли соотношение производительности, потребляемой энергии и цены. Решение выполнено в виде низкопрофильной карты расширения с интерфейсом PCIe 4.0 х16. В основу положен чип runAI200, изготовленный по 16-нм технологии. Он имеет динамически изменяемую частоту, которая достигает 840 МГц. 
Источник изображения: Untether AI Ускоритель несёт на борту 204 Мбайт памяти SRAM с пропускной способностью до 251 Тбайт/с. Производительность на ИИ-операциях, согласно техническим характеристикам, достигает 500 TOPS (INT8). Типовое энергопотребление заявлено на уровне 40 Вт, максимальное — 75 Вт. Задействована система пассивного охлаждения. Диапазон рабочих температур простирается от 0 до +55 °C. Питание подаётся через дополнительный коннектор PCIe на плате. Ускоритель, как утверждается, позволяет осуществлять вычисления ЦОД-класса без привязки к облаку. Изделие может применяться для видеоаналитики в режиме реального времени, обнаружения и классификации объектов, проверки сетевых пакетов с целью регулирования и фильтрации трафика и для других задач.
06.10.2023 [01:01], Владимир Мироненко
Dell расширила набор комплексных решений и сервисов для «локализации» генеративного ИИDell объявила о расширении портфеля решений Dell Generative AI Solutions с целью поддержки компаний в трансформации методов работы с генеративным искусственным интеллектом (ИИ). Первоначально в разработанном совместно с NVIDIA решении Dell Validated Design for Generative AI основное внимание уделялось обучению ИИ, но теперь продукт также поддерживает тюнинг моделей и инференс. Это, в частности, означает, что у клиентов есть возможность развёртывать модели в собственных ЦОД, передаёт StorageReview. Dell Validated Design for Generative AI with NVIDIA for Model Customization предлагает предварительно обученные модели, которые извлекают знания из данных компания без необходимости создания моделей с нуля и обеспечивают безопасность информации. Благодаря масштабируемой схеме тюнинга у организаций теперь есть множество способов адаптировать модели генеративного ИИ для выполнения конкретных задач с использованием своих собственных данных. 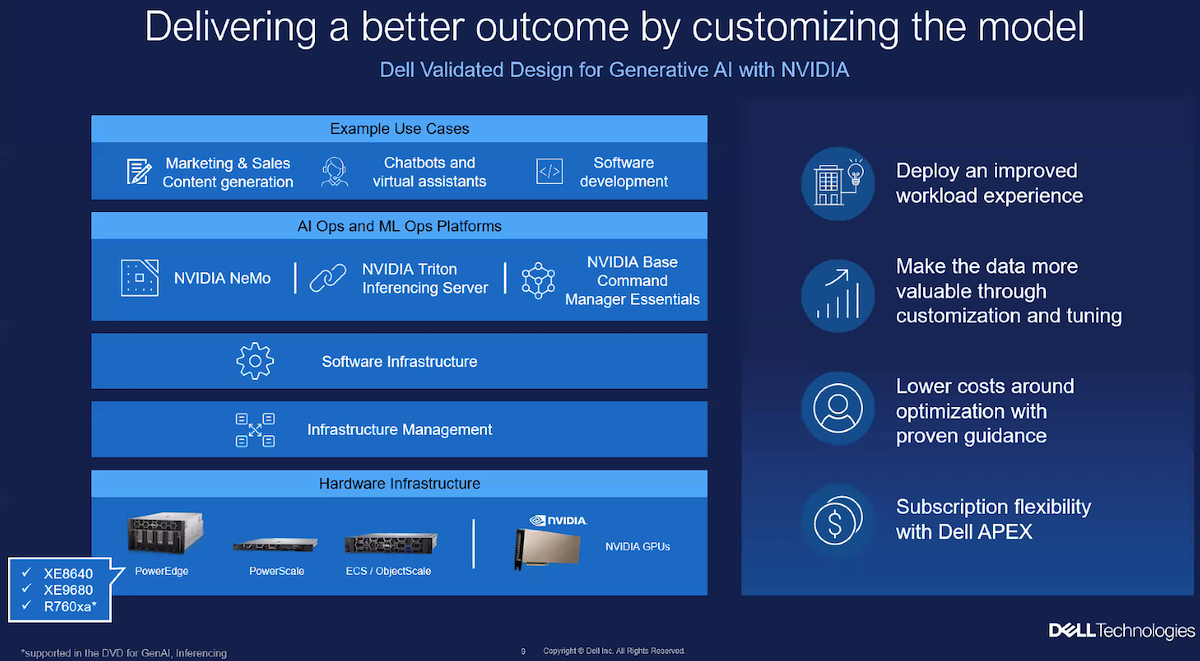
Изображения: Dell (via StorageReview) Инфраструктура базируется на GPU-серверах Dell PowerEdge XE9680 и PowerEdge XE8640 с ускорителями NVIDIA, стеком NVIDIA AI Enterprise и фирменным ПО Dell. Компания позиционирует это как идеальное решение для компаний, которые хотят создавать генеративные ИИ-модели, сохраняя при этом безопасность своих данных на собственных серверах. Для хранения данных предлагаются различные конфигурации Dell PowerScale и Dell ObjectScale. Доступ к этой инфраструктуре также возможен по подписке в рамках Dell APEX. 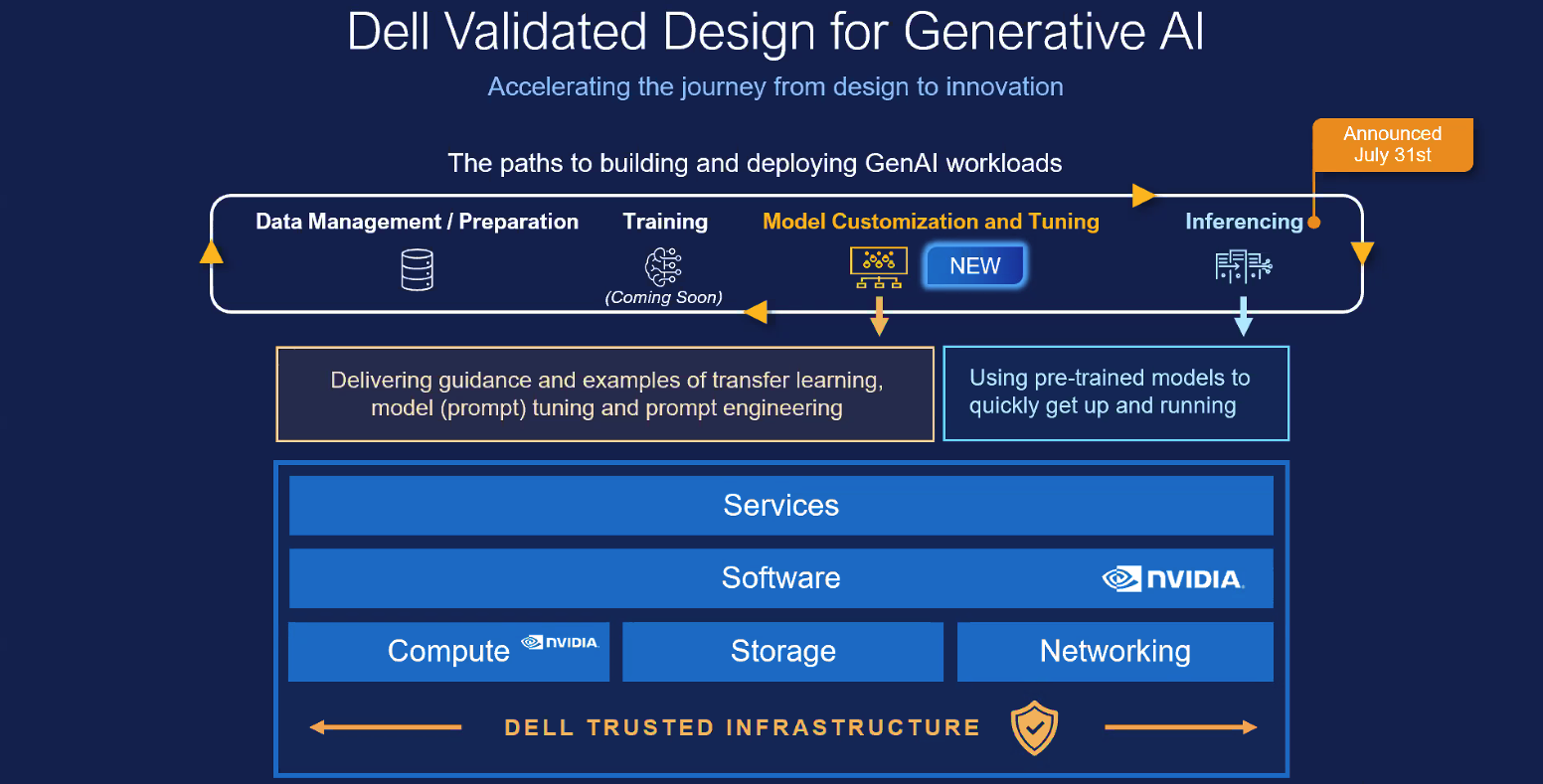 Dell также расширила портфолио профессиональных сервисов. Так, появились сервисы по подготовке данных (Data preparation Services), разработанные специально для предоставления клиентам тщательно подготовленных, очищенных и корректно отформатированных наборов данных. А с помощью сервисов по внедрению (Dell Implementation Services) для компании в короткие сроки создадут полностью готовую платформу генеративного ИИ, оптимизированную для инференса и подстройки моделей. 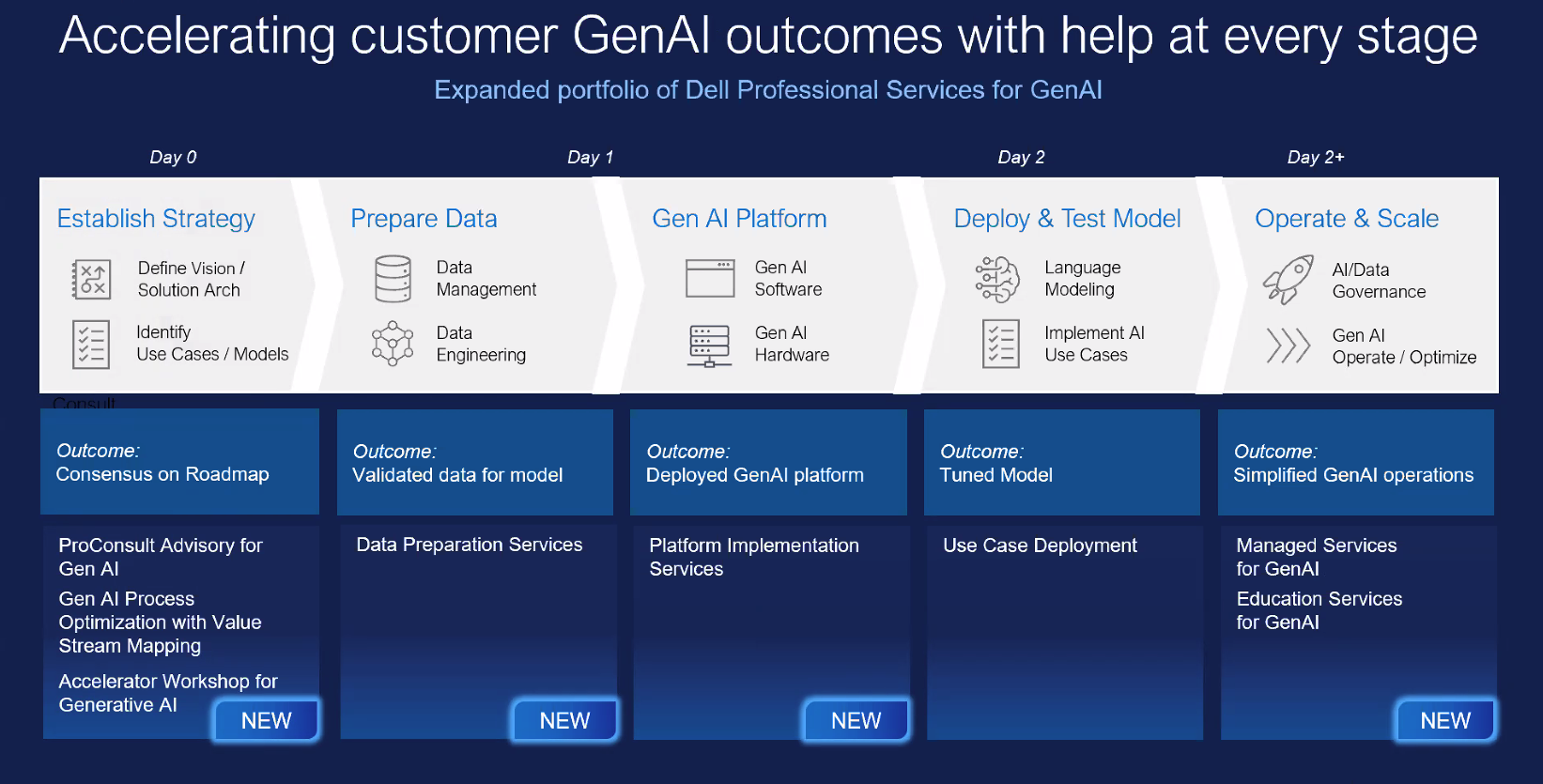 Dell также предлагает новые образовательные сервисы (Education Services) для клиентов, которые хотят обучить своих сотрудников современным ИИ-технологиям. Наконец, было объявлено о партнёрстве Dell и Starburst, в рамках которого Dell интегрирует платформы PowerEdge и СХД с аналитическим ПО Starburst, чтобы помочь клиентам создать централизованное хранилище данных и легче извлекать необходимую информацию из своих данных. 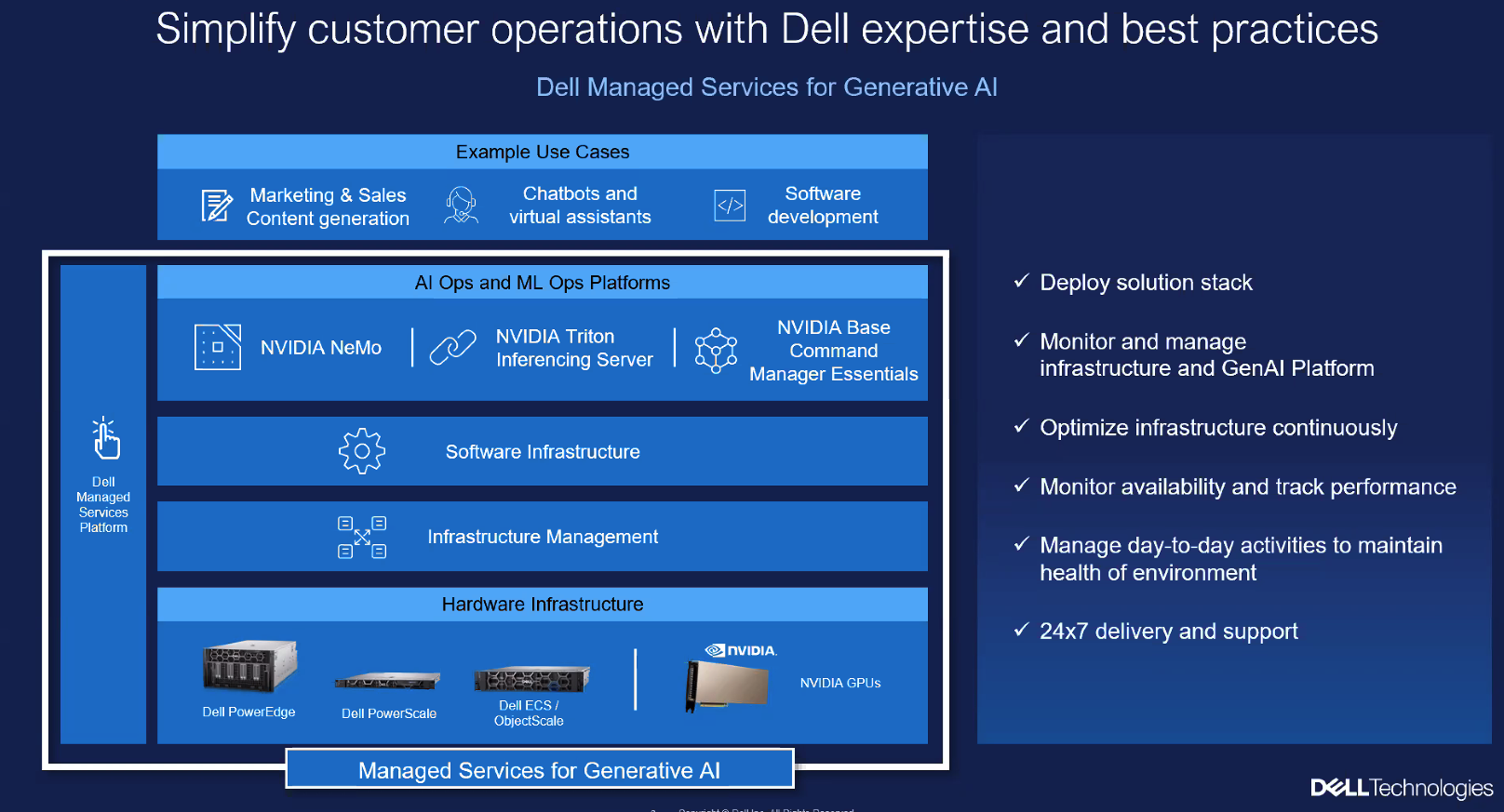 Энди Турай (Andy Thurai), вице-президент и главный аналитик Constellation Research, сообщил в интервью SiliconANGLE, что наиболее мощные LLM, такие как GPT-4, обучаются в специально созданных облачных окружениях из-за их огромных размеров и требований к ресурсам. Вместе с тем некоторые компания ищут способы обучения своих собственных, гораздо меньших по размеру LLM в локальных средах. Турай отметил, что Dell потребуется время, чтобы добиться каких-либо успехов в «локализации» генеративного ИИ, поскольку настройка инфраструктуры, перемещение подгтовка данных — занятие не для слабонервных. Как сообщается, решение Dell Validated Design for Generative AI with NVIDIA for Model Customization будет доступно глобально позже в октябре. Профессиональные сервисы появятся тогда же, но только в некоторых странах. А решение Dell для озера данных на базе Starburst станет глобально доступно в I половине 2024 года. Фактически новые решения Dell являются развитием совместной с NVIDIA инициативы Project Helix.
30.09.2023 [23:18], Алексей Степин
Intel отказалась от ИИ-ускорителей Habana GrecoОдним из столпов своей ИИ-платформы Intel сделала разработки поглощённой когда-то Habana Labs. Но если ускорители Gaudi2 оказались конкурентоспособными, то ветку инференс-решений Goya/Greco было решено свернуть. Любопытно, что на мероприятии Intel Innovation 2023 имя Habana Labs не упоминалось, а использовалось исключительно название Intel Gaudi. Дела у данной платформы, базирующейся на ускорителе Gaudi2, обстоят неплохо. Так, в частности, она имеет поддержку FP8-вычислений и, согласно данным Intel, не только серьёзно опережает NVIDIA A100, но успешно соперничает с H100. Фактически в тестах MLPerf только Intel смогла составить хоть какую-то серьёзную конкуренцию NVIDIA. 
Изображение: Intel Однако не все разработки Habana имеют счастливую судьбу. В 2022 году одновременно с Gaudi2 был анонсирован и инференс-ускоритель Greco, поставки которого должны были начаться во II полугодии 2023 года. Но сейчас, похоже, данная платформа признана бесперспективной. Intel не только убрала все упоминания Greco со своего сайта и ни словом не обмолвилась о них на мероприятии, но и подчистила Linux-драйвер несколько дней назад. А вот появление Gaudi3 уже не за горами.
29.09.2023 [13:05], Сергей Карасёв
Разработчик ИИ-чипов Kneron получил $49 млн инвестицийКомпания Kneron, специализирующаяся на разработке ИИ-технологий, объявила о проведении расширенного раунда инвестиций Series B, в ходе которого на развитие привлечено $49 млн. Таким образом, общая сумма вложений в рамках указанной финансовой программы достигла $97 млн. Стартап Kneron из Сан-Диего разрабатывает чипы, которые можно использовать в умных автомобилях, роботах и других подключённых устройствах с ИИ-функциями. Компания заявляет, что приложения машинного обучения, использующие её чипы, могут стабильно работать даже без доступа в интернет. 
Источник изображения: Kneron Одно из изделий Kneron — специализированный ИИ-чип KL730. Он объединяет четырёхъядерный CPU на архитектуре Arm и акселератор для задач инференса. Реализована поддержка интерфейсов SD, USB и Ethernet. Заявленная производительность достигает 4 TOPS. При этом обеспечивается высокая энергоэффективность. Средства на развитие в ходе раунда Series B предоставили Foxconn and HH-CTBC Partnership (Foxconn Co-GP Fund), Alltek, Horizons Ventures, Liteon Technology Corp, Adata и Palpilot. Деньги будут использованы в том числе для ускорения разработки ИИ-решений для автомобильной сферы. В целом, на сегодняшний день стартап Kneron получил финансовую поддержку в размере $190 млн.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 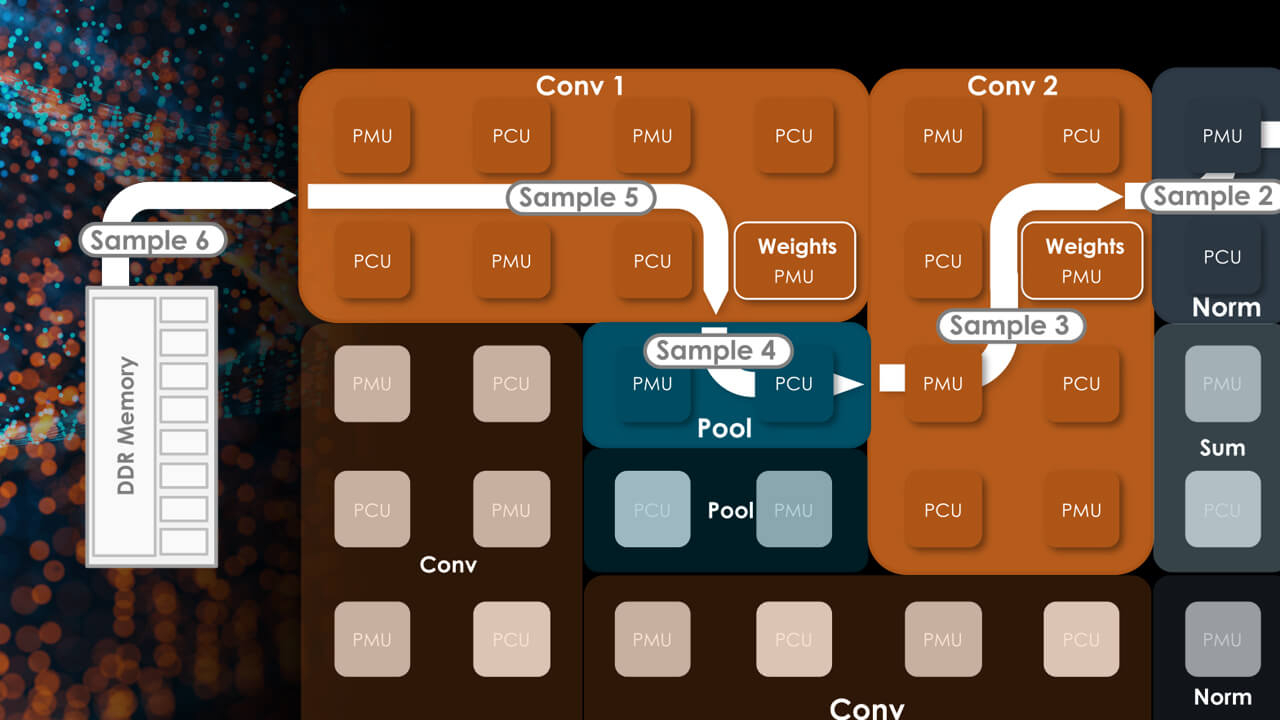
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
16.09.2023 [21:40], Сергей Карасёв
Cadence представила 7-нм ИИ-ядро Neo NPU с производительностью до 80 TOPSКомпания Cadence Design Systems, разработчик IP-блоков, по сообщению CNX-Software, создала ядро Neo NPU (Neural Processing Unit) — нейропроцессорный узел, предназначенный для решения ИИ-задач с высокой энергетической эффективностью. Решение подходит для создания SoC умных сенсоров, IoT-устройств, носимых гаджетов, систем оказания помощи водителю при движении (ADAS) и пр. Утверждается, что производительность Neo NPU может масштабироваться от 8 GOPS до 80 TOPS в расчёте на ядро. В случае многоядерных конфигураций быстродействие может исчисляться сотнями TOPS. Ядро Neo NPU способно справляться как с классическими ИИ-задачами, так и с нагрузками генеративного ИИ. Говорится о поддержке INT4/8/16 и FP16 для свёрточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров. 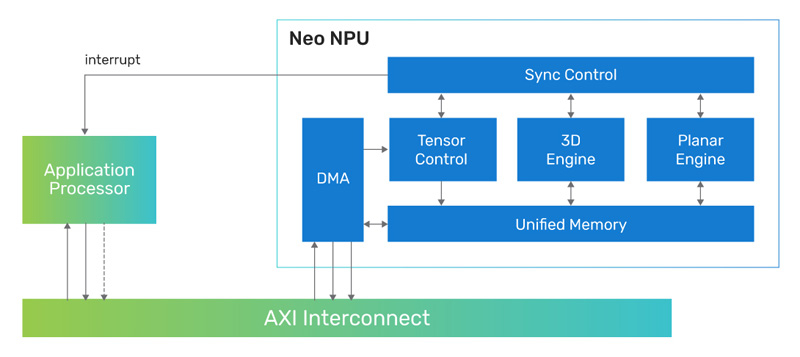
Источник изображения: Cadence Для Neo NPU предполагается применение 7-нм технологии производства. Стандартная тактовая частота — 1,25 ГГц. Утверждается, что по сравнению с ядрами первого поколения Cadence AI IP изделие Neo NPU обеспечивает 20-кратный прирост производительности. Скорость инференса в расчёте на ватт в секунду возрастает в 5–10 раз. Разработчикам будет предлагаться комплект NeuroWeave (SDK) с поддержкой TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet, JAX, а также Android Neural Network Compiler, TF Lite Delegates и TensorFlow Lite Micro. Решение Neo NPU станет доступно в декабре 2023 года. |
|


{kind=link}