Материалы по тегу: интерконнект
|
01.09.2023 [16:26], Алексей Степин
Cornelis Networks ускорит Omni-Path Express до 1,6 Тбит/сИнтерконнекту Omni-Path прочили в своё время светлое будущее, но в 2019 году компания Intel отказалась от своего детища и свернула поставки OPA-решений. Однако эстафету подхватила Cornelis Networks, так что технология не умерла — совсем недавно The Next Platform были опубликованы планы по дальнейшему развитию Omni-Path. В 2012 году Intel выкупила наработки по TruScale InfiniBand у QLogic, позднее дополнив их приобретением у Cray интерконнектов Gemini XT и Aries XC. Задачей было создание единого интерконнекта, могущего заменить PCIe, FC и Ethernet, а в основу была положена технология Performance Scale Messaging (PSM). PSM считалась более эффективной и пригодной в сравнении с verbs InfiniBand, однако самой технологии более 20 лет. В итоге Cornelis Networks отказалась от PSM и теперь развивает новый программный стек на базе libfabric. 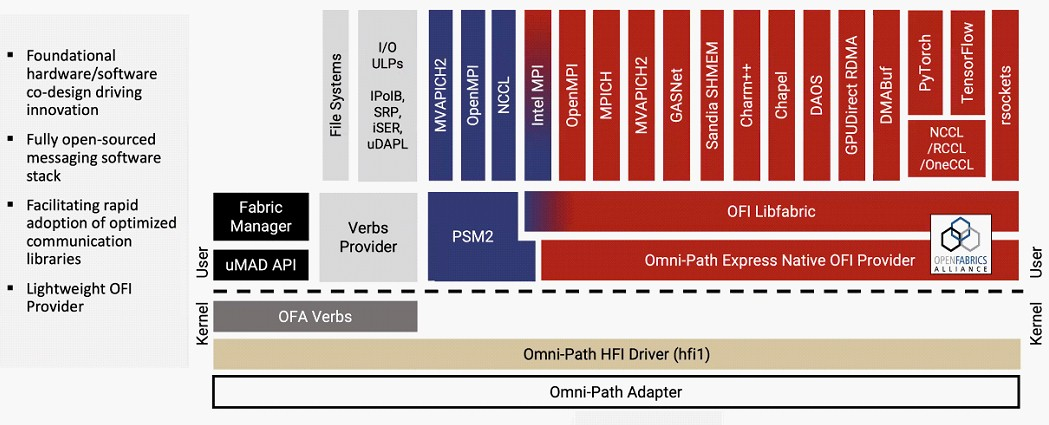
Источник изображений здесь и далее: Cornelis Networks (viaThe Next Platform) Уже первое поколение Omni-Path Express (OPX), работающее со скоростью 100 Гбит/с могло работать под управлением нового стека бок о бок с PSM2, а для актуальных 400G-продуктов Omni-Path Express CN5000 вариант OFI станет единственным. Скорее всего, в этом поколении будет также убрано всё, что работает на основе кода OFA Verbs. Останутся только части, выделенные на слайде выше красным. Как отмечает Cornelis Networks, главным отличием OPX от InfiniBand станет использование стека на базе полностью открытого кода с апстримом драйвера OFI в ядро Linux. 
Планы Cornelis Networks по развитию Omni-Path Планы компании простираются достаточно далеко: на 2024 год запланировано пятое поколение Omni-Path, включающее в себя не только адаптеры, но и необходимую инфраструктуру — 48-портовые коммутаторы и 576-портовые директоры. Предел масштабирования возрастёт практически на порядок, с 36,8 тыс. подключений для Omni-Path 100 до 330 тыс. Латентность при этом составит менее 1 мкс при потоке до 1,2 млрд сообщений в секунду. Появится поддержка топологий Dragonfly и Megafly, оптимизированных для применения в крупных HPC-системах, и динамическая адаптивная маршрутизация на базе данных телеметрии. 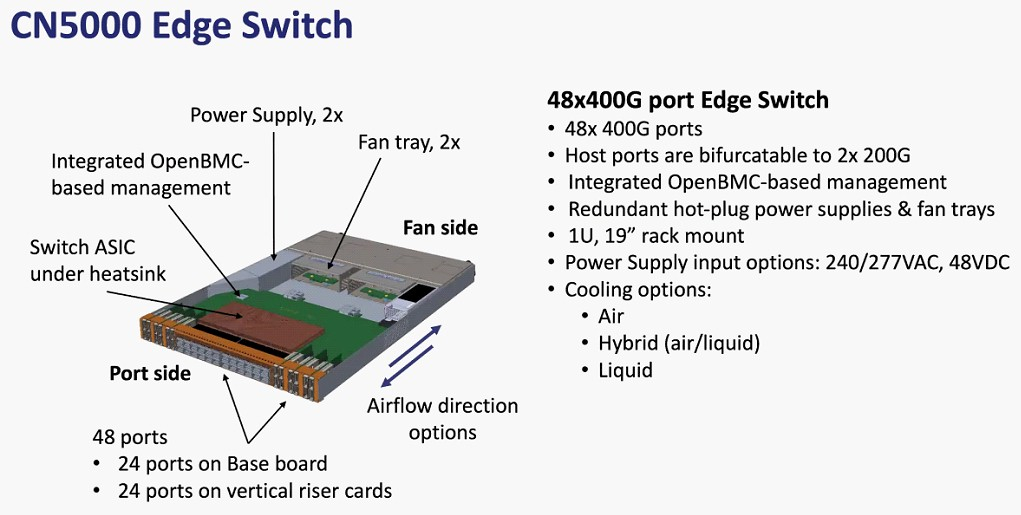 Характеристики и внутреннее устройство коммутаторов пятого поколения CN5000 компания публикует уже сейчас. Обычный периферийный коммутатор займёт высоту 1U, но при этом будет поддерживать как воздушное, так и жидкостное охлаждение, а модульный коммутатор класса director будет занимать 17U и получит внутренний интерконнект с топологией 2-tier Fat Tree. В нём будет предусмотрена горячая замена модулей и опция жидкостного охлаждения.  Базовый адаптер CN5000 выглядит как обычная плата расширения с интерфейсом PCIe 5.0 x16. Будут доступны варианты с одним и двумя портами 400G. Что интересно, опция жидкостного охлаждения предусмотрена и здесь. В 2026 году должно появиться шестое поколение решений Omni-Path CN6000 со скоростью 800 Гбит/с, включающее в себя не только базовые адаптеры и коммутаторы, но и первый в мире DPU для OPA, построенный на базе архитектуры RISC-V и поддерживающий CXL. Благодаря DPU будут реализованы более продвинутые опции разгрузки хост-системы и ускорения конкретных приложений. 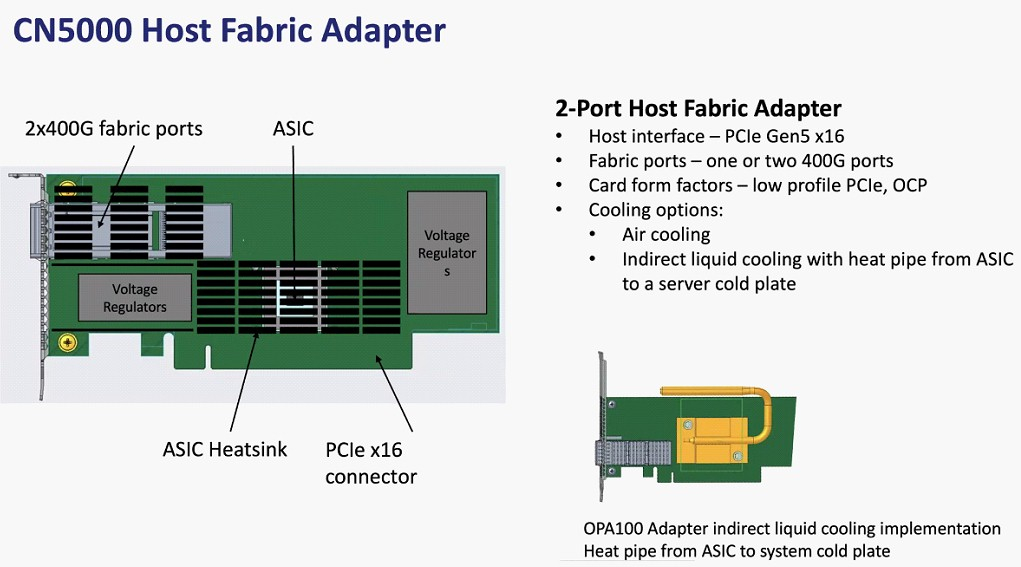 Наконец, в 2028 году в седьмом поколении CN7000 скоростной потолок поднимется с 800 до 1600 Гбит/с. Будет внедрена перспективная для крупномасштабных сетей поддержка топологии HyperX. Также ожидается появление чиплетов с интерфейсом UCIe и интегрированной фотоникой, что позволит интегрировать Omni-Path в решения сторонних производителей. Одной из главных целей Cornelis Networks, напомним, заявлено создание системы интерконнекта для суперкомпьютеров нового поколения экзафлопного класса. Разработка финансируется в рамках инициативы Exascale Computing Initiative (ECI). А первым суперкомпьютером, использующим Omni-Path пятого поколения (400G), станет техасский Stampede3.
09.08.2023 [18:28], Алексей Степин
Lightelligence представила оптический CXL-интерконнект PhotowaveКомпания Lightelligence, специализирующаяся в области фотоники и оптических вычислений, анонсировала любопытную новинку — систему оптического интерконнекта для ЦОД нового поколения. Решение под названием Photowave реализовано на базе стандарта CXL и призвано упростить и сделать более надёжными системы с композитной инфраструктурой, заменив традиционные медные кабели оптоволокном. Решение Photowave — дальнейшее развитие парадигмы Lightelligence, уже представившей ранее первый оптический ускоритель Hummingbird для ИИ-систем. Сердцем Photowave является оптический трансивер oNET на базе фирменных технологий компании. Согласно заявлениям Lightelligence, уровень задержки составляет менее 20 нс на уровне адаптера, кабель добавляет к этой цифре менее 1 нс. 
Источник изображений здесь и далее: Lightelligence Серия Photowave включает в себя трансиверы в разных форм-факторах — как в виде традиционной платы расширения PCI Express, так и в виде карты OCP 3.0 SFF. Платы трансиверов поддерживают CXL 2.0/PCIe 5.0 с числом линий от 2 до 16. Пропускная способность каждой линии составляет 32 Гбит/с.  Как уже упоминалось, главная задача Photowave — создание эффективных и надёжных композитных инфраструктур в ЦОД нового поколения, где благодаря всесторонней поддержки CXL будет достигнута высокая степень дезагрегации вычислительных ресурсов, а также памяти и хранилищ.
02.08.2023 [18:00], Сергей Карасёв
Светлое будущее: у PCIe появится версия с оптическими соединениями — создана рабочая группа для разработки технологииКонсорциум PCI-SIG объявил о формировании рабочей группы PCI-SIG Optical Workgroup, которая займётся реализацией интерфейса PCI Express (PCIe) по оптическим соединениям. Это, как ожидается, станет важным этапом развития соответствующей экосистемы. Внедрение оптических соединений для PCIe по сравнению с существующими решениями обеспечит более высокую пропускную способность, пониженное энергопотребление, увеличенную дальность действия и меньшие задержки. 
Источник изображения: pixabay.com Новая технология, как ожидается, будет востребована в облачных дата-центрах, системах НРС и на площадках гиперскейлеров. Речь идёт о создании системы, поддерживающей широкий спектр оптических технологий. Консорциум PCI-SIG призывает всех своих участников присоединиться к Optical Workgroup, поделиться опытом и помочь определить конкретные цели рабочей группы и требования к аппаратным компонентам. Новая рабочая группа сосредоточит усилия над тем, чтобы сделать архитектуру PCIe более подходящей для оптических сетей. Между тем, как отмечается, продолжаются работы над спецификацией PCIe 7.0, которая предусматривает увеличение производительности до 128 ГТ/с по одной линии.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
04.07.2023 [20:05], Алексей Степин
HBM по оптике: фотонный интерконнект Celestial AI Photonic Fabric обеспечит плотность до 7,2 Тбит/с на кв. ммCelestial AI, получившая $100 млн инвестиций, объявила о разработке интерконнекта Photonic Fabric, покрывающего все ниши: межкристалльного (chip-to-chip), межчипового (package-to-package) и межузлового (node-to-node) обмена данными. На рынке уже есть решения вроде Lightmatter Passage или Ayar Labs TeraPhy I/O. Тем не менее, Celestial AI привлекла внимание множества инвесторов, в том числе Broadcom. Последняя поможет в разработке прототипов, которые должны увидеть свет в течение 18 месяцев. В основе технологий Celestial AI лежит сочетание кремниевой фотоники и техпроцесса CMOS (TSMC, 4 или 5 нм), разработанных совместно с Broadcom. При этом речь идёт не об обычном «глупом» интерконнекте — разработчики говорят о блоках маршрутизации и коммутации на любом «конце» волокна. Разработка позволит объединить в одной упаковке несколько ASIC или даже SoC посредством оптического интерпозера или моста OMIB (multi-chip interconnect bridge). Celestial AI утверждает, что её технологии эффективнее, чем у конкурентов, и позволяет объединить несколько чипов с теплопакетами в районе сотен ватт. 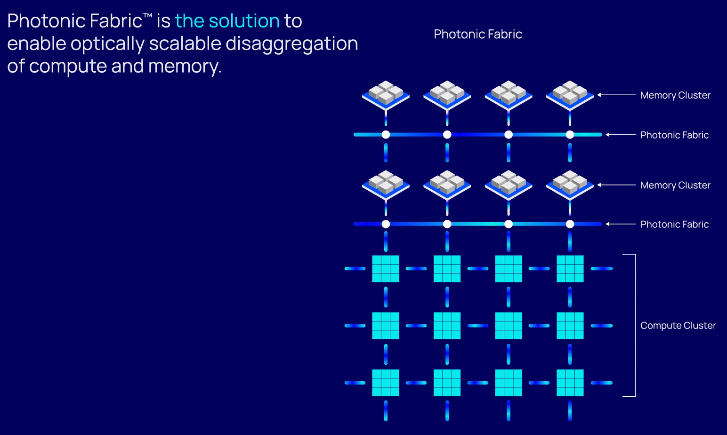
Источник здесь и далее: Celestial AI Пока что технология опирается на 56-Гбит/с трансиверы SerDes. С четырьмя портами на узел и четырьмя линиями на порт речь идёт о пропускной способности до 1,8 Тбит/с на 1 мм2 чипа, что позволяет «прокормить» полноценную сборку из четырёх кристаллов HBM3. Второе поколение Photonic Fabric будет использовать уже 112-Гбит/с SerDes-блоки, что поднимет пропускную способность вчетверо, до 7,2 Тбит/с на мм2.  Интерконнект Celestial AI не зависит от проприетарных протоколов, в его основе лежат стандарты Compute Express Link (CXL) и Universal Chiplet Interconnect (UCIe), а также JEDEC HBM. В настоящее время сдерживающим фактором разработчики называют сами шины PCIe и UCIe. Их интерконнект, считают они, способен на большее.
29.06.2023 [13:33], Сергей Карасёв
Разработчик оптического интерконнекта Celestial AI привлёк на развитие $100 млнСтартап Celestial AI, специализирующийся на разработке технологий оптической передачи данных, объявил о проведении раунда финансирования Series B, в ходе которого привлечено $100 млн. Деньги будут направлены на дальнейшее развитие экосистемы оптического интерконнекта. Celestial AI отмечает, что в эпоху ИИ и больших языковых моделей, таких как GPT-4 (лежит в основе ChatGPT), традиционные электрические соединения становятся узким местом. Сравнительно низкая пропускная способность и высокие задержки препятствуют росту прибыльных бизнес-моделей ИИ. 
Источник изображения: pixabay.com Компания Celestial AI в тесном сотрудничестве с гиперскейлерами и другими участниками рынка создала платформу оптических соединений Photonic Fabric. Утверждается, что данное решение обеспечивает в 25 раз более высокую пропускную способность при в 10 раз меньших задержках и энергопотреблении, нежели любая другая оптическая альтернатива, такая как, например, Co-Packaged Optics (CPO). При помощи Photonic Fabric данные могут доставляться непосредственно в точку потребления. Предложенная технология совместима с существующими отраслевыми стандартами, включая CXL, PCIe, UCIe, JEDEC HBM, а также с проприетарными электрическими коммуникационными системами. Доступ к Photonic Fabric предоставляется по программе лицензирования. Раунд финансирования Series B проведён под предводительством IAG Capital Partners, Koch Disruptive Technologies (KDT) и Temasek Xora Innovation. В нём также приняли участие Samsung Catalyst, Smart Global Holdings (SGH), Porsche Automobil Holding SE, The Engine Fund, imec.xpand, M Ventures и Tyche Partners.
05.06.2023 [22:19], Владимир Мироненко
Разработчик фотонных ИИ-ускорителей Lightmatter привлёк $154 млн инвестиций и втрое увеличил капитализациюСтартап Lightmatter сообщил о завершении раунда финансирования серии C, в результате которого он привлёк инвестиции на сумму $154 млн. В этом раунде приняли участие венчурные подразделения Alphabet и HPE, а также ряд других институциональных инвесторов. Сообщается, что после этого раунда утроилась нераскрытая оценка Lightmatter, которую стартап получил после проведения раунда финансирования в 2021 году. По словам Lightmatter, разработанный ею оптический интерконнект Passage обеспечивает до 100 раз большую пропускную способность, чем традиционные альтернативы. Ускорение перемещения данных в чипе и между чипами повышает производительность приложений. Lightmatter утверждает, что Passage занимает значительно меньше места, чем традиционные электрические соединения, и потребляет в пять раз меньше энергии. Кроме того, Passage упрощает работу с системой, позволяя автоматические менять конфигурацию интернконнекта менее чем 1 мс. 
Источник изображения: Lightmatter Lightmatter Passage является частью инференс-платформы Envise 4S, оптимизированной для работы с самыми крупными ИИ-моделями. По данным компании, система втрое быстрее, чем NVIDIA DGX A100, занимая при этом 4U-шасси и потребляя порядка 3 кВт. Сервер Envise 4S оснащён 16 фотонными ИИ-ускорителями Envise, каждый из которых содержит 500 Мбайт памяти, 400G-подключение к соседним чипам и 256 RISC-ядер общего назначения. Ускорители объединены оптической фабрикой производительностью 6,4 Тбит/с. Полученные в результате нового раунда средства компания планирует использовать для коммерциализации Passage и Envise, а также внедрения Idiom, программного инструментария, который упрощает написание приложений для Envise.
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 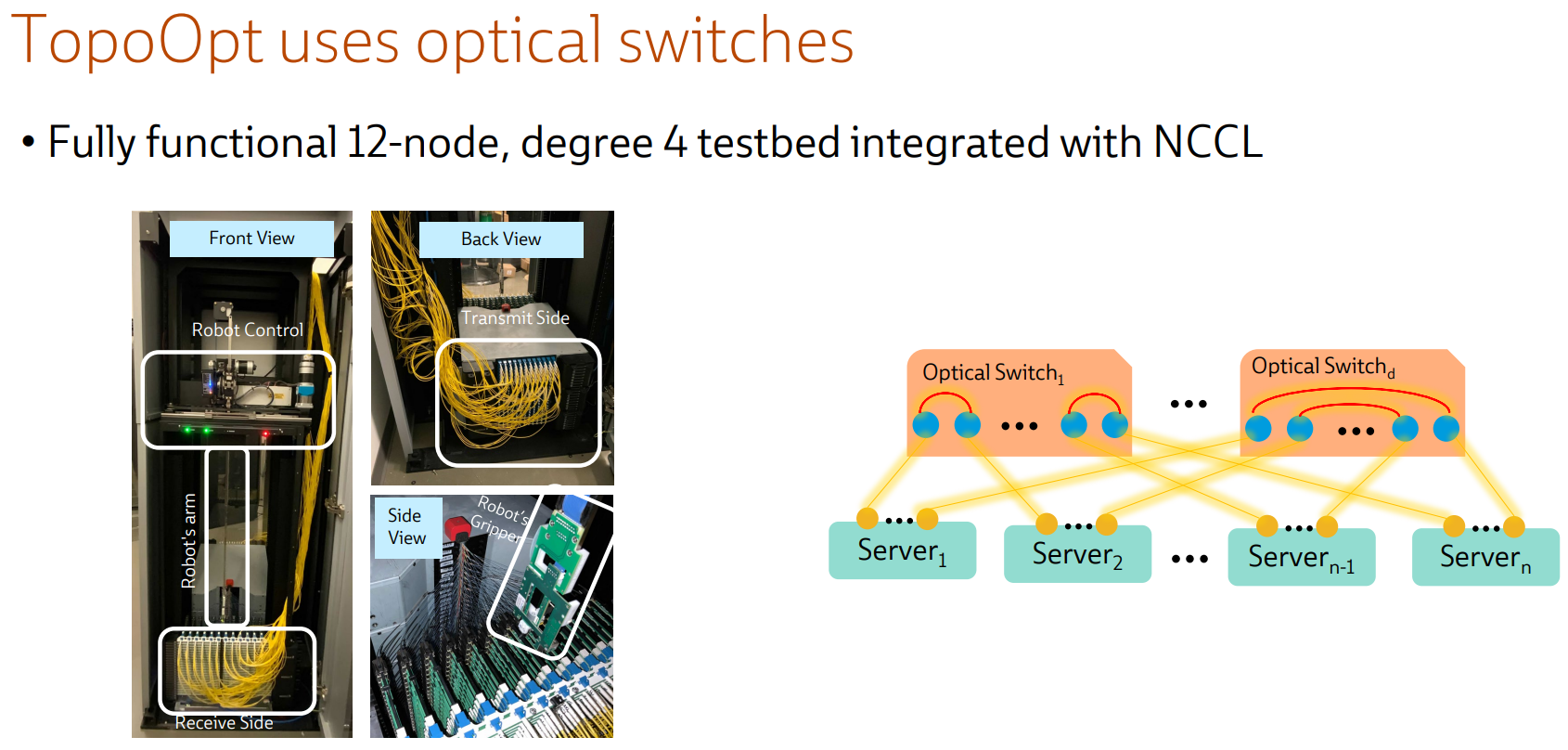
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 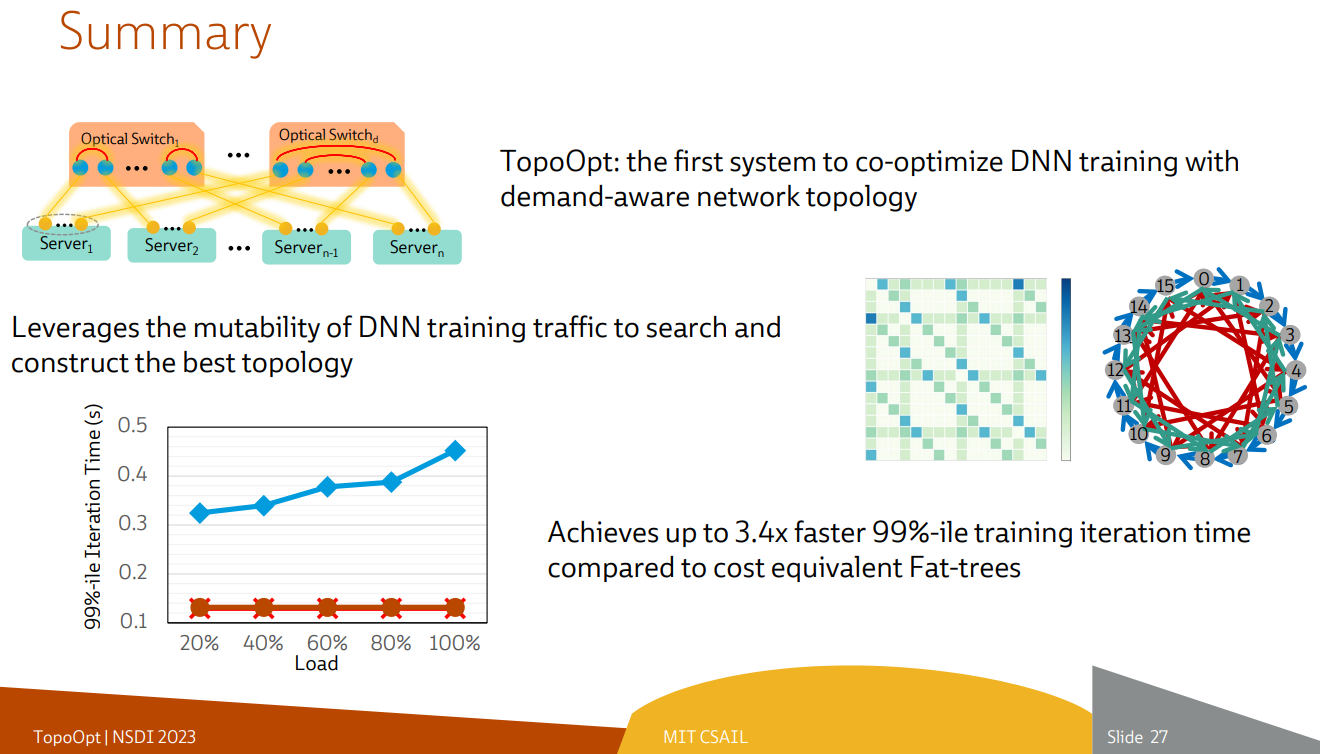
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
01.02.2023 [18:39], Сергей Карасёв
Astera Labs поможет во внедрении CXL-решенийКомпания Astera Labs сообщила о расширении возможностей своей облачной лаборатории Cloud-Scale Interop Lab с целью обеспечения надёжного тестирования функциональной совместимости между платформой Leo Memory Connectivity Platform и экосистемой решений на базе CXL. «CXL зарекомендовала себя как важнейшая технология соединения памяти в системах, ориентированных на данные. Однако многочисленные варианты использования и быстрорастущая экосистема оказываются серьёзной проблемой для масштабного внедрения решений CXL», — отметил глава Astera Labs. Сообщается, что площадка Cloud-Scale Interop Lab использует комплексный набор стресс-тестов памяти, проверок протокола CXL и измерений электрической надёжности для проверки производительности и совместимости между CPU, контроллерами Leo Smart Memory и различными модулями памяти в реальных сценариях использования. Тестирование охватывает ключевые области — от физического уровня до приложений, включая электрическую составляющую PCIe, память, требования CXL и испытания на уровне всей системы. 
Источник изображения: Astera Labs Добавим, что в августе 2022 года была представлена спецификация CXL 3.0. Поддержку в развитии технологии оказывают Комитет инженеров в области электронных устройств JEDEC, а также некоммерческая организация PCI-SIG (PCI Special Interest Group). |
|

