Материалы по тегу: интерконнект
|
25.01.2023 [18:30], Алексей Степин
GigaIO FabreX обещает удвоить эффективность использования ресурсов ускорителей для платформ на базе Sapphire RapidsКомпания GigaIO, разработчик компонуемой платформы FabreX также поддержала выпуск новых процессоров Intel Xeon. Сертифицированная платформа GigaIO GigaPod на базе Sapphire Rapids показала возросший на 106 % уровень утилизации ускорителей в сравнении с платформой NVIDIA DGX, использующей InfiniBand. 
Коммутатор FabreX. Источник здесь и далее: GigaIO Конфигурация тестовой системы включала в себя сервер на базе Sapphire Rapids, к которому с помощью FarbeX были подключены 16 ускорителей NVIDIA A100. Как показало тестирование, такая конфигурация куда эффективнее использует ресурсы, нежели в случае традиционного подхода, когда ускорители «раскиданы» по нескольким серверам и коммуникация между ними осуществляется посредством высокоуровневой сети вроде InfiniBand. 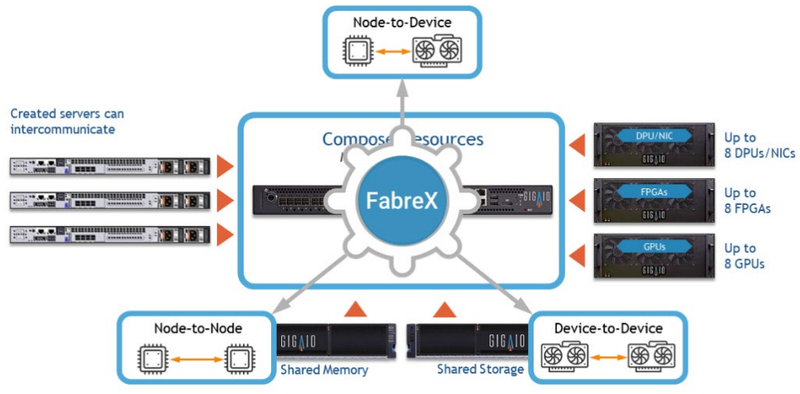
Интерконнект GigaIO FabreX универсален и поддерживает подключение любых типов устройств в рамках платформы GigaPod Глава GigaIO отметил, что в классическом варианте уровень загрузки ускорителей может опускаться до 15 %, и это при том, что стоимость мощных ускорителей иногда составляет до 80 % стоимости всей системы. Финальный выигрыш в стоимости GigaPod в версии с процессорами Sapphire Rapids может достигать 30 % в пользу решения GigaIO. Компонуемая архитектура, продвигаемая GigaIO, существенно эффективнее традиционных: в её основе лежит PCI Express, что гарантирует задержку на уровне менее 1 мкс. По этому показателю FabreX превосходит и InfiniBand, и NVIDIA NVLink. При этом полностью поддерживается DMA. 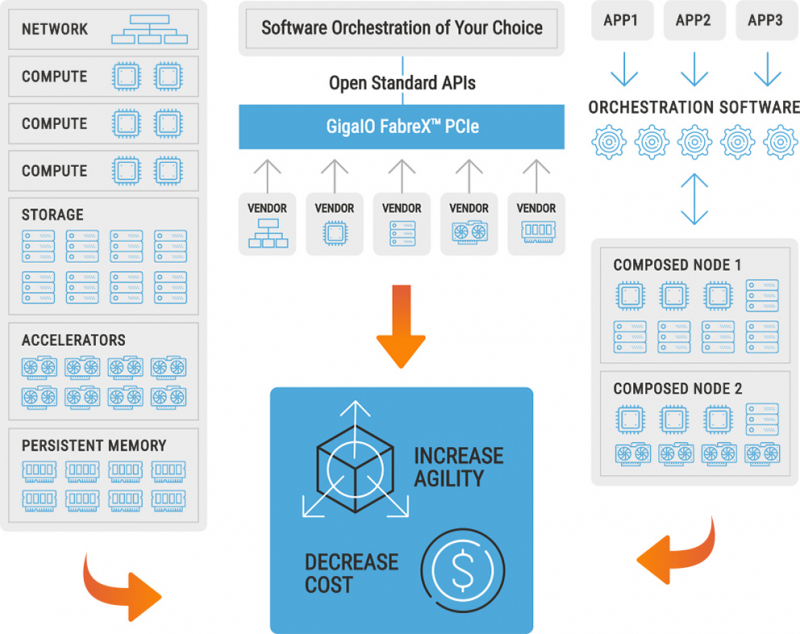
Программная архитектура FabreX Платформа FabreX универсальна, она позволяет подключать к системе практически любые компоненты, от GPU до пулов памяти и FPGA, в том числе с CXL. Ещё на SC20 компания продемонстрировала 5U-шасси, вмещающие до 10 ускорителей с интерфейсом PCIe 4.0. Архитектура GigaIO является программно-определяемой и совместима с большей частью современного ПО для управления и распределения нагрузки, в ней реализован набор открытых API Redfish.
16.10.2022 [10:55], Владимир Мироненко
Lockheed Martin будет использовать кремниевую фотонику Ayar Labs в разработках военного назначенияРазработки Ayar Labs в сфере кремниевой фотоники заинтересовали американскую военно-промышленную корпорацию Lockheed Martin, объявившую о планах использовать её технологию для оптического ввода-вывода в своих будущих оборонных платформах. Компании сотрудничают с 2020 года, когда Lockheed Martin объявила о «стратегических инвестициях» в стартап с целью дальнейшей разработки чиплета-трансивера TeraPHY. Lockheed Martin сообщила, что технология Ayar Lab может в конечном итоге найти применение во многих системах Министерства обороны США для захвата, оцифровки, транспортировки и обработки спектральной информации с меньшей задержкой и на более дальние расстояния по сравнению с существующими решениями. Lockheed Martin не стала конкретизировать направления применения этой технологии, лишь отметила возможность её использования для военной разведки и обработки радиосигналов. 
Источник: Ayar Labs Ранее говорилось об использовании оптического интерконнекта в цифровых радиолокационных приложениях для поддержки больших объёмов данных. Тем не менее, военная разведка включает в себя широкий спектр технологий, обычно используемых в оборудовании для наблюдения, таких как дроны, спутники-шпионы и радарные массивы — во все эти области Lockheed Martin инвестирует значительные средства. Технический директор Lockheed Martin Стив Уокер (Steve Walker) отметил, что для успеха миссий её клиентов требуются инновационные системные архитектуры в сочетании с искусственным интеллектом и методами машинного обучения. «Решение Ayar Labs для оптических интерконнектов обеспечивает необходимую технологию для обработки спектральной информации с большей скоростью и меньшей задержкой для систем следующего поколения», — добавил он.
04.10.2022 [16:29], Алексей Степин
Intel показала универсальный оптический разъём для соединения чиповКремниевая фотоника продолжает бурно развиваться: уже созданы все основные компоненты, а на Hot Chips 34 компания Lightmatter продемонстрировала полноценный внутричиповый фотонный интерконнект. Однако широкое распространение фотоники немыслимо без соответствующей оптико-механической инфраструктуры, в частности, кабелей и разъёмов. И именно такой разъём, способный стать основой нового стандарта, на мероприятии Intel Innovation 2022, и был продемонстрирован в действии. За основу Intel взяла оптический модуль MPO/MTP, сделав его более компактным для удобного использования в качестве межчипового соединителя. 
Источник изображений: Serve The Home Применение такого разъёма позволит гибридным чипам избавиться от ненадёжных волоконно-оптических «хвостов» с более крупными соединителями на концах. При повреждении хотя бы одного волокна в «хвосте» фотонные чипы старого типа фактически приходят в негодность, особенно если излом произошёл непосредственно в месте выхода волокна из упаковки. А вот с новым разъёмом достаточно будет заменить кабель. 
Фотоника интегрирована в чип, но «хвосты» неудобны и потенциально ненадёжны В своей демонстрации Intel показала гибридный чип XPU, оснащённый новым разъёмом и не требующий электрических межчиповых соединений, на которые приходится солидная доля электрической мощности и тепловыделения, особенно в современных высокоскоростных коммутаторах. При этом отчетливо видны посадочные места для пары аналогичных разъёмов. 
Intel XPU. Рядом с новым оптическим разъёмом видны места для двух аналогичных соединителей Теоретически использование такой технологии способно сильно преобразить внутренний вид и архитектуру вычислительных систем нового поколения — вся периферия, включая память, накопители и ускорители будет подключаться к процессору посредством новых оптических разъёмов без традиционных электрических дорожек на печатных платах. Это существенно упростит конструкцию, а также снизит энергопотребление и тепловыделение таких систем. Также широкое применение интегрированной фотоники позволит добиться большей гибкости: к примеру, если сейчас объём высокоскоростной памяти типа HBM ограничен габаритами упаковки чипа, то в будущем дополнительные модули с интегрированным фотонным трансивером можно будет просто подключать с помощью системы оптических разъёмов, разработанной Intel. В числе прочего, внедрение нового межчипового оптического интерконнекта облегчит путь к построению HPC-систем зеттафлопсного класса.
06.09.2022 [22:47], Алексей Степин
Кремниевая фотоника Lightmatter Passage объединит чиплеты на скорости 96 Тбайт/сНа конференции Hot Chips 34 компания Lightmatter, занимающаяся созданием фотонного ИИ-процессора, рассказала о своей новой разработке, Lightmatter Passage, открывающей для чиплетов эру фотоники. Как известно, переход на чиплеты позволил разработчикам сложных чипов сравнительно малой кровью обойти ограничения, накладываемые технологиями на создание монолитных кристаллов большой площади. Однако современный высокоскоростной межчиплетный интерконнект всё равно весьма сложен и потребляет сравнительно много энергии. И по мере роста количества чиплетов на общей подложке проблема будет лишь обостряться. 
Изображения: Lightmatter (via ServeTheHome) Но технология Lightmatter Passage, призванная заменить электрический интерконнект оптическим, позволит эту проблему обойти. По сути, Passage — универсальная кремниевая прослойка, содержащая в своём составе лазеры, оптические модуляторы, фотодетекторы, волноводы, а также классические транзисторы для сопутствующей логики. Поверх этой прослойки Lightmatter и предлагает размещать чиплеты любой архитектуры. 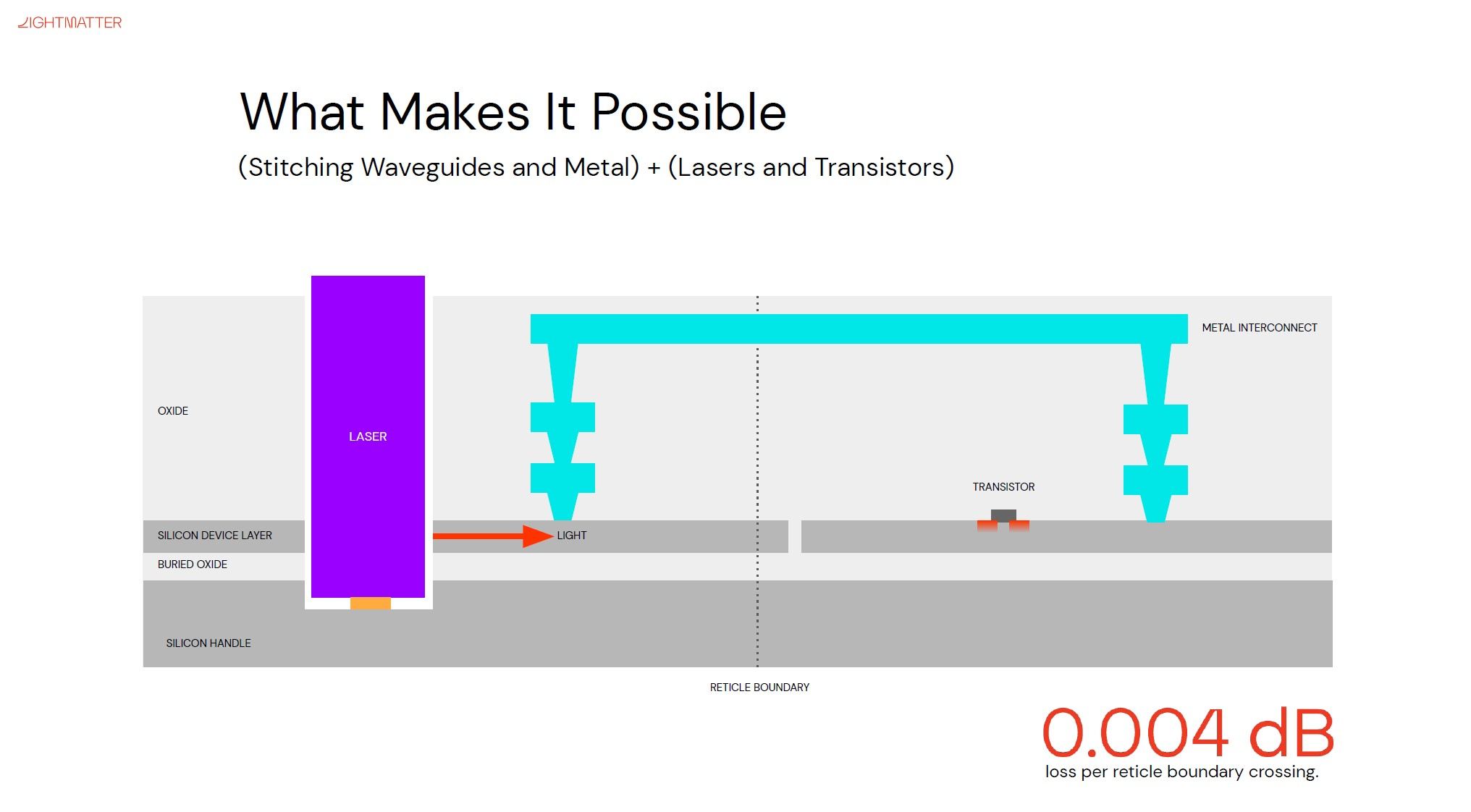 Электрическая часть Passage имеет изменяемую конфигурацию и в текущей реализации поддерживает установку до 48 чиплетов (в виде матрицы 6×8). Производится такая прослойка из 300-мм кремниевой пластины SOI, верхний и нижний слои Passage имеют классические контакты для чиплетов и установки на PCB соответственно. При этом максимальная подводимая электрическая мощность может достигать 700 Вт. Вся же коммуникация чиплетов между собой происходит внутри и является оптической. 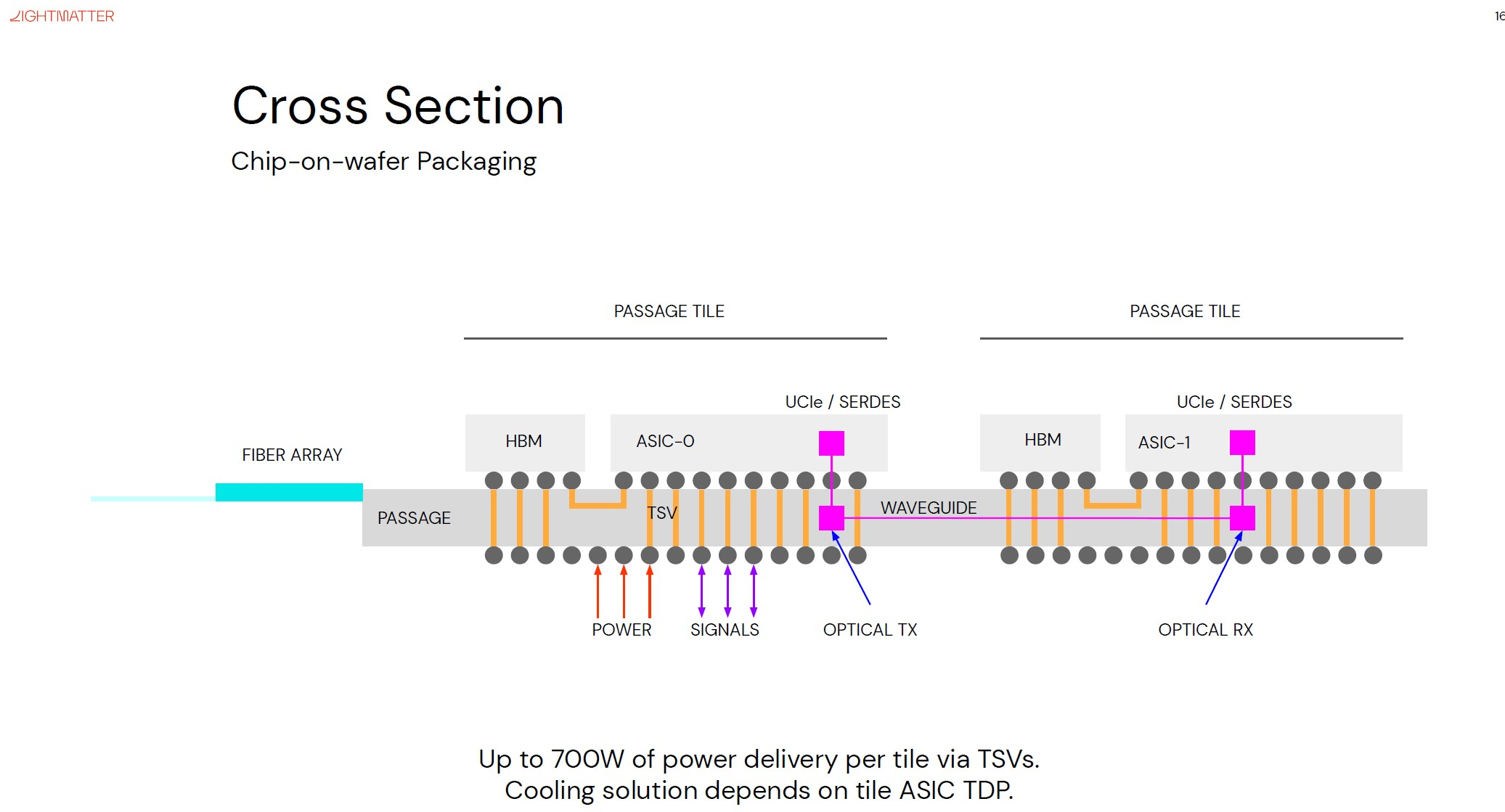 Матрица фотонных волноводов, плотность которой в 40 раз выше, чем у традиционных оптоволоконные технологий, обеспечивает латентность одного перехода на уровне менее 2 нс. Как заявляют разработчики, расстояние между чиплетами при этом роли не играет — для любого сочетания пары точек «входа» и «выхода» сигнала значение задержки одинаково. Высокая плотность волноводов позволяет «накормить» каждый чиплет потоком данных до 96 Тбайт/с, а внешние каналы Passage позволяют связать чипы с другими компонентами системы на скоростях до 16 Тбайт/с. 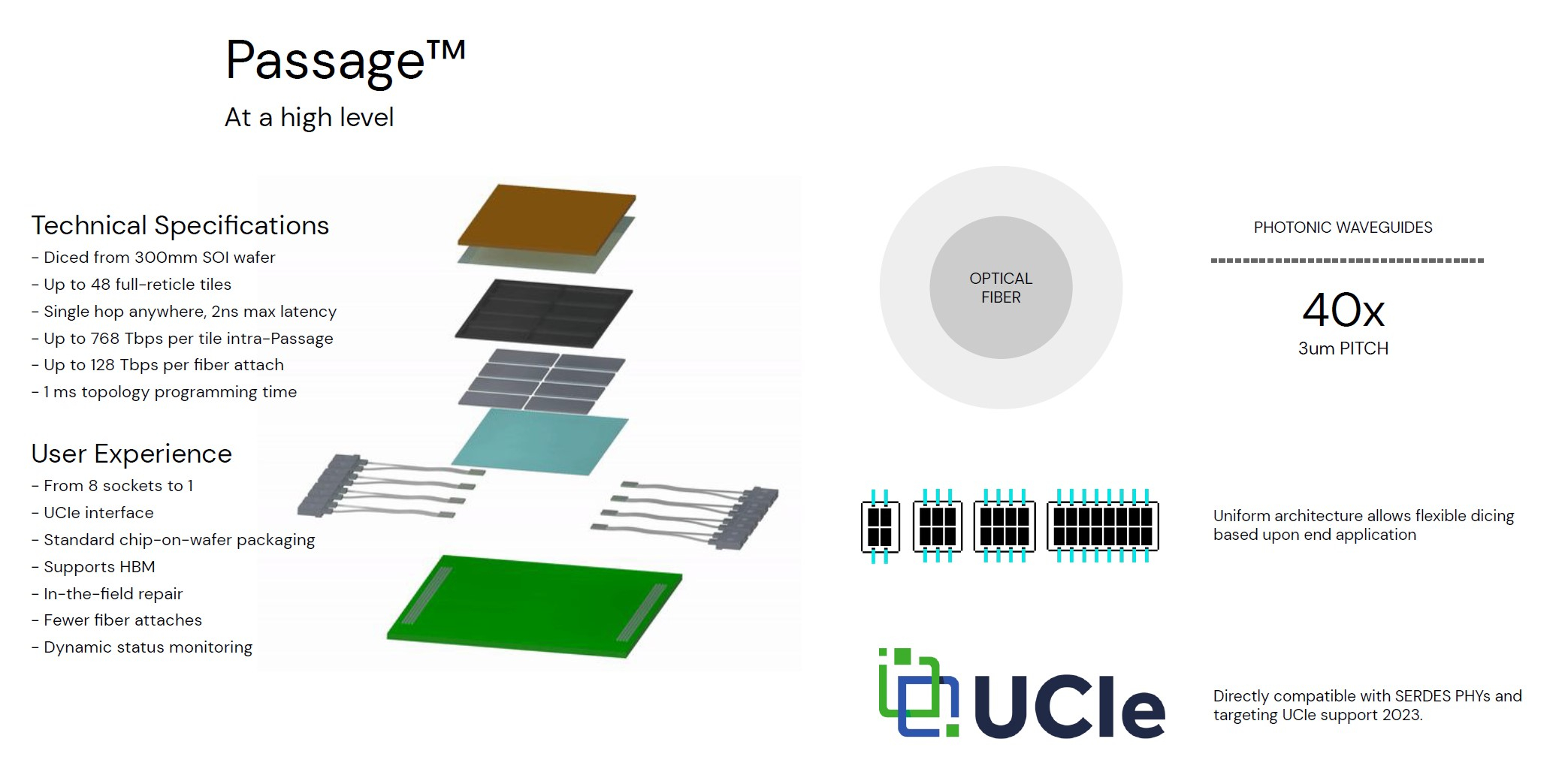 Основой данной технологии является фирменная разработка компании, позволяющая точно «сшивать» в пределах нескольких слоев SOI-кремния электрические соединения с многочисленными волноводами. Уже существующая в кремнии тестовая реализация Passage потребляет 21 Вт, позволяет устанавливать до 48 чиплетов площадью по 800 мм2, обеспечивает каждое посадочное место 32 каналами с пропускной способностью 1024 Тбит/с, причём топологию интерконнекта можно динамически менять.  Тестовя подложка Passage, полученная из 300-мм пластины, содержит 288 лазеров мощностью 50 мВт каждый. Всего в состав системы входит 150 тыс. компонентов, и это заявка на абсолютный рекорд для фотонных чипов. Кроме того, новая технология совместима со стандартом UCIe — говорится о скорости 32 Гбит/с на линию. Впрочем, в случае простого SerDes-соединения, как считают создатели, этот показатель можно поднять до 112 Гбит/с.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла.  Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с).  При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 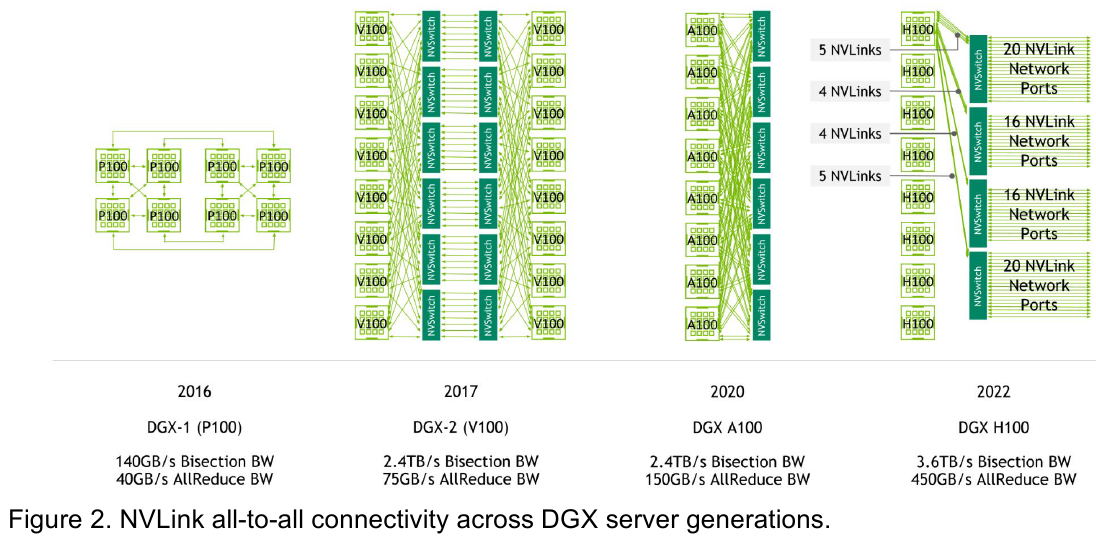 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 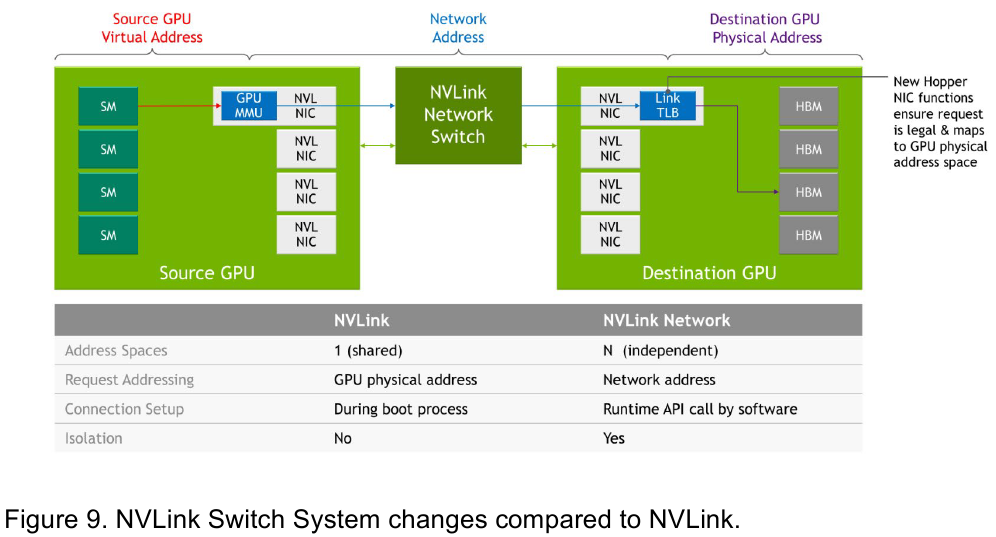 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
03.08.2022 [13:46], Владимир Мироненко
NVIDIA и Alibaba присоединились к консорциуму UCIeКонсорциум Universal Chiplet Interconnect Express (UCIe), возглавивший работу по стандартизации универсального интерконнекта для чиплетов, объявил о пополнении правления двумя новыми участниками — NVIDIA и Alibaba. Они присоединились к десяти компаниям-основателям консорциума, включая AMD, Arm, Advanced Semiconductor Engineering (ASE), Google Cloud, Intel, Meta✴ (материнская компания Facebook✴), Microsoft, Qualcomm, Samsung и TSMC. 
Изображения: UCIe Consortium NVIDIA объявила о намерении присоединиться к группе стандартов UCIe ещё в марте. Во время конференции GTC гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) сообщил ресурсу HPCwire, что, как только спецификация UCIe будет стабилизирована, компания добавит её в свои чипы «так быстро, насколько возможно».  Хотя NVIDIA использует проприетарный стандарт NVLink-C2C в своих платформах HGX/DGX и Grace Superchips, она также будет применять стандарт UCIe для заказных решений. По словам Хуанга, UCIe позволяет клиентам создавать кастомные чипы, которые подключаются к чипам NVIDIA (CPU, GPU и DPU) с «небольшими инженерными усилиями» и экономически эффективным способом.  Также консорциумом было объявлено о создании шести рабочих групп — пяти технических и одной по маркетингу. Рабочие группы будут заниматься электрической частью, протоколами, форм-факторами и совместимостью, управляемостью и безопасностью, системами и ПО.  Как отметил Дебендра Дас Шарма (Debendra Das Sharma), старший научный сотрудник и соруководитель отдела Memory and I/O Technologies в Intel и сопредседатель технической рабочей группы консорциума CXL, аналогичным образом построена организация консорциума CXL. По его словам, нынешний состав совета директоров не будет меняться четыре года для обеспечения стабильности, но консорциум открыт для новых участников.
02.08.2022 [16:00], Алексей Степин
Опубликованы спецификации Compute Express Link 3.0Мало-помалу стандарт Compute Express Link пробивает себе путь на рынок: хотя процессоров с поддержкой ещё нет, многие из элементов инфраструктуры для нового интерконнекта и базирующихся на нём концепций уже готово — в частности, регулярно демонстрируются новые контроллеры и модули памяти. Но развивается и сам стандарт. В версии 1.1, спецификации на которую были опубликованы ещё в 2019 году, были только заложены основы. Но уже в версии 2.0 CXL получил массу нововведений, позволяющих говорить не просто о новой шине, но о целой концепции и смене подхода к архитектуре серверов. А сейчас консорциум, ответственный за разработку стандарта, опубликовал свежие спецификации версии 3.0, ещё более расширяющие возможности CXL. 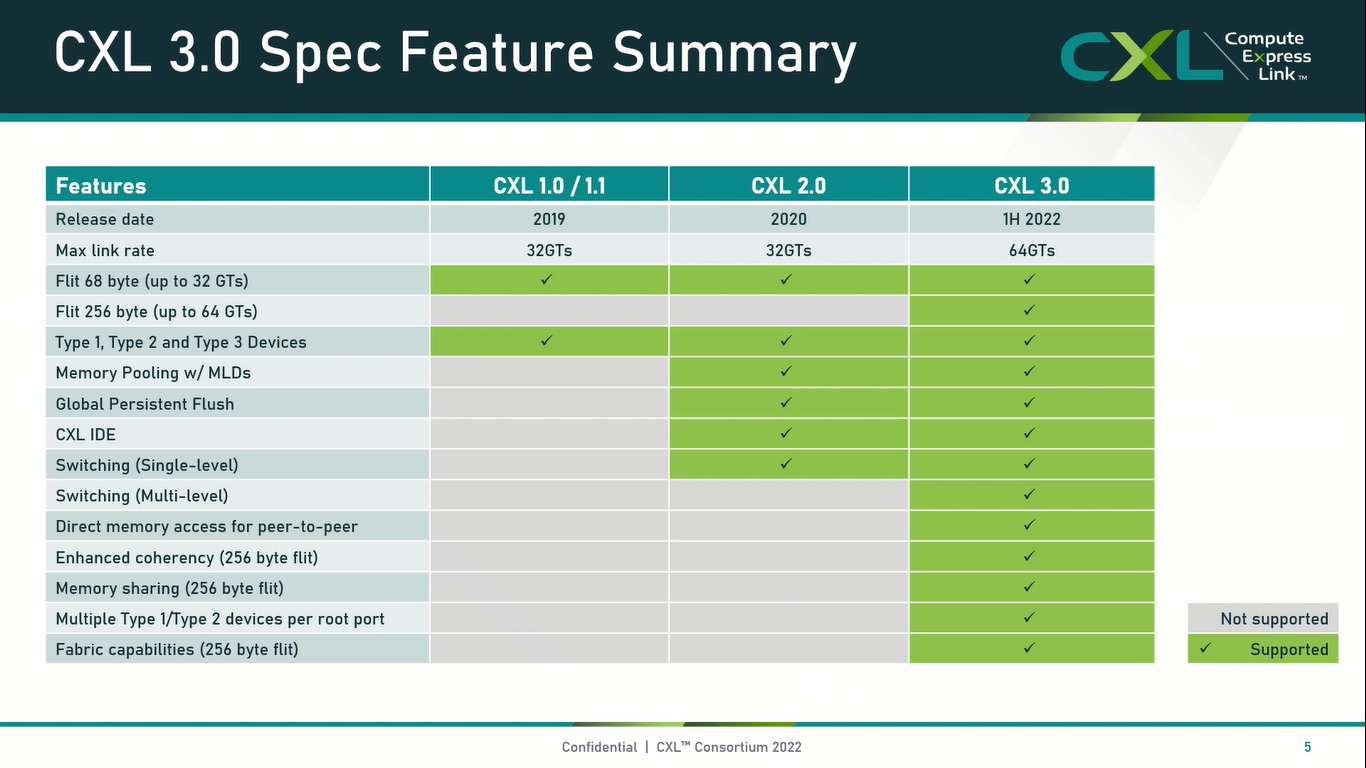
Источник: CXL Consortium И не только расширяющие: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Что неудивительно, поскольку в основе лежит стандарт PCIe 6.0. Но основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. 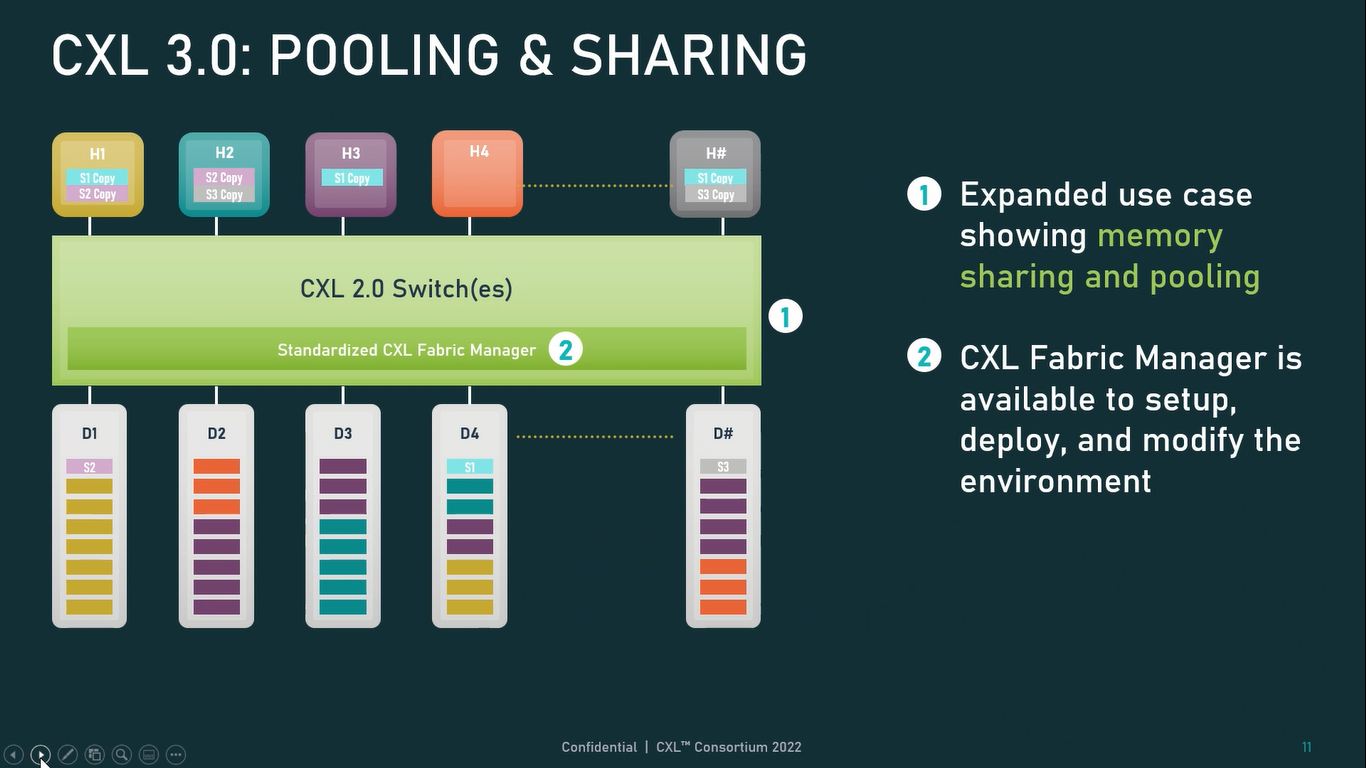 Сама фабрика CXL 3.0 теперь допускает создание и подключение «многоголовых» (multi-headed) устройств, расширены возможности по управлению фабрикой, улучшена поддержка пулов памяти, введены продвинутые режимы когерентности, а также появилась поддержка многоуровневой коммутации. При этом CXL 3.0 сохранил обратную совместимость со всеми предыдущими версиями — 2.0, 1.1 и даже 1.0. В этом случае часть имеющихся функций попросту не будет активирована. 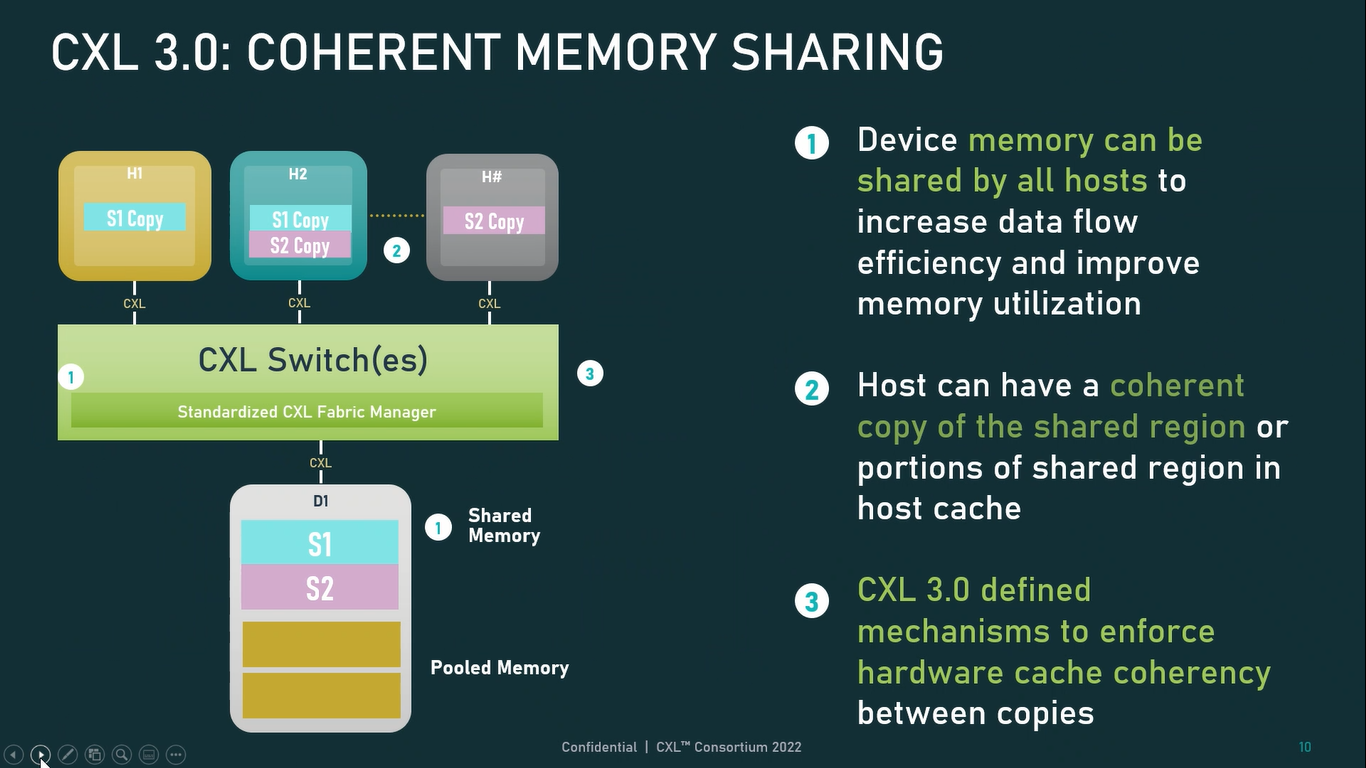 Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня. При этом каждый корневой порт процессора поддерживает одновременное подключение через коммутатор устройств различных типов в любой комбинации.  Ещё одним интересным нововведением стала поддержка прямого доступа к памяти типа peer-to-peer (P2P). Проще говоря, несколько ускорителей, расположенных, к примеру, в соседних стойках, смогут напрямую общаться друг с другом, не затрагивая хост-процессоры. Во всех случаях обеспечивается защита доступа и безопасность коммуникаций. Кроме того, есть возможность разделить память каждого устройства на 16 независимых сегментов.  При этом поддерживается иерархическая организация групп, внутри которых обеспечивается когерентность содержимого памяти и кешей (предусмотрена инвалидация). Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности. Организация пулов теперь не отдаётся на откуп стороннему ПО, а осуществляется посредством стандартизированного менеджера фабрики.  Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей. При этом возможность адресовать до 4096 точек подключения скорее упрётся в физические лимиты фабрики. 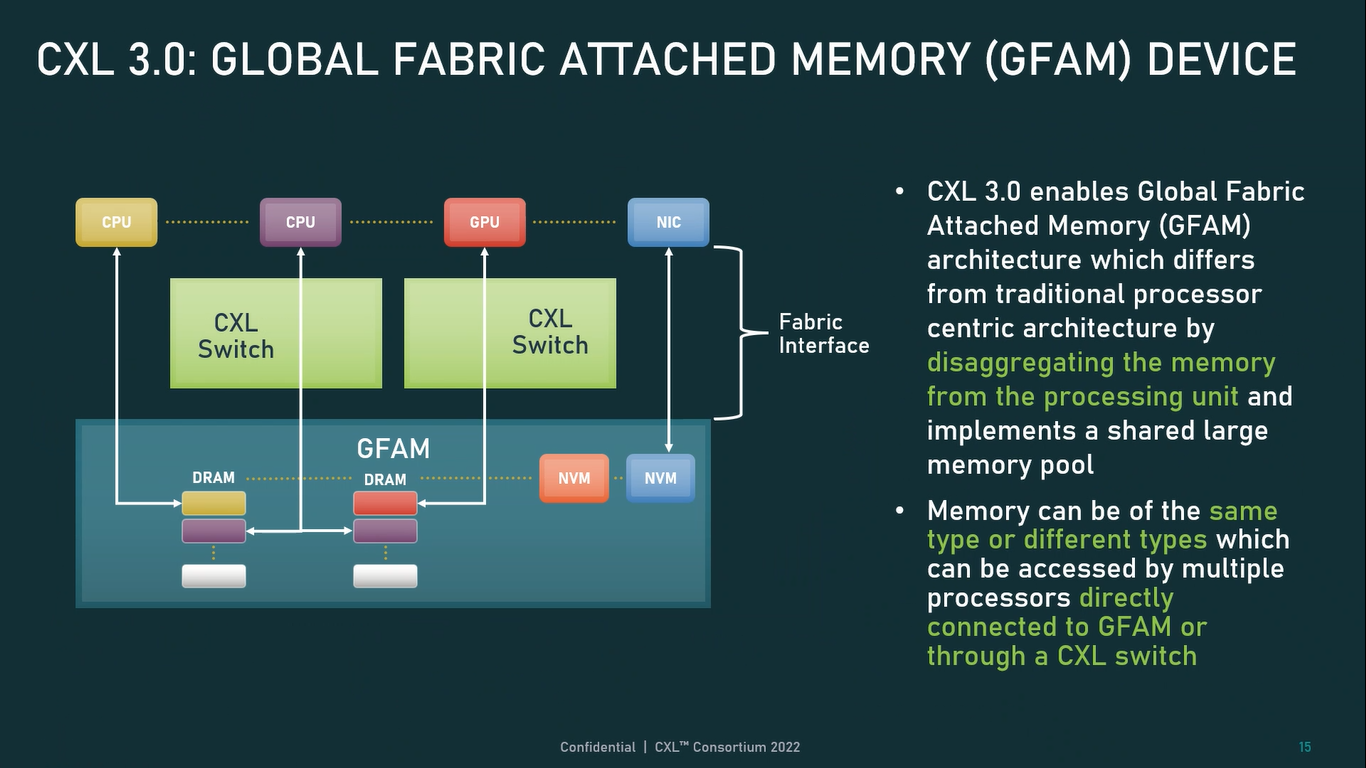 Пул может содержать разные типы памяти — DRAM, NAND, SCM — и подключаться к вычислительным мощностями как напрямую, так и через коммутаторы CXL. Предусмотрен механизм сообщения самими устройствами об их типе, возможностях и прочих характеристиках. Подобная архитектура обещает стать востребованной в мире машинного обучения, в котором наборы данных для нейросетей нового поколения достигают уже поистине гигантских размеров. 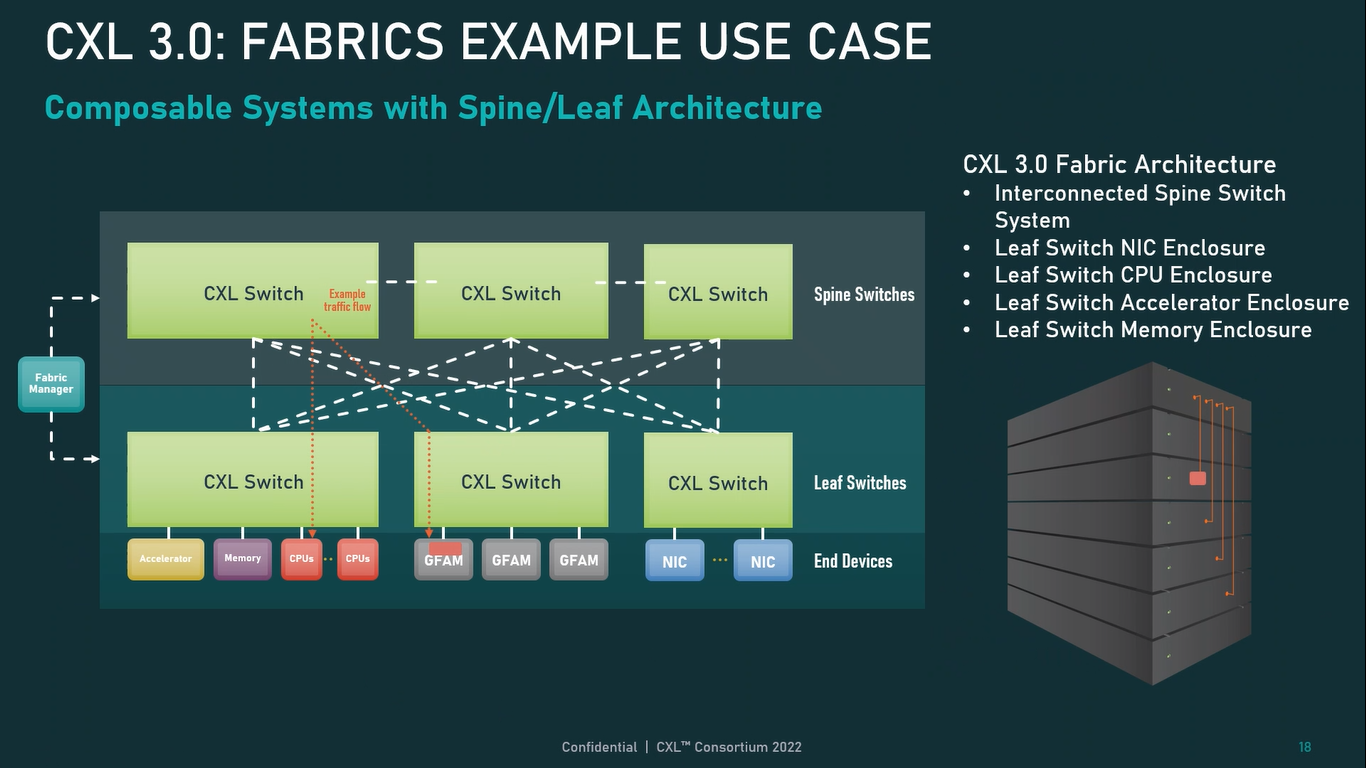 В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta✴, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC.
04.07.2022 [22:18], Алексей Степин
Intel разработала фотонный техпроцесс с интегрированным мультиволновым массивом лазеровФотоника сулит немалые преимущества, и особенно ярко они проявятся в случае достижения высокой степени интеграции — если внешний источник лазерного излучения может существенно усложнить систему и сделать её более дорогой, то интегрированный на кремниевую пластину, напротив, многое упрощает. Неудивительно, что разработчики, бьющиеся над созданием гибридных фотонных чипов, нацелены именно на такой вариант. Ранее мы рассказывали о варианте Synopsys и Juniper Networks, которые также планируют использовать интегрированные лазеры в рамках возможностей техпроцесса PH18DA компании Tower Semiconductor, а сейчас успеха добилась корпорация Intel. 
Традиционные оптические модуляторы достаточно громоздки. Источник: Intel Labs Научно-исследовательское подразделение компании, Intel Labs, сообщает, что на базе «существующего кремниевого-фотонного техпроцесса для пластин диаметром 300 мм» удалось создать интегрированный лазерный массив, работающий с восемью длинами волн. Это хорошо отработанная технология, на её основе Intel уже производит оптические трансиверы, что открывает дорогу к достаточно быстрому началу производству фотонных чипов со встроенными лазерными массивами. 
Вариант Intel использует компактные кольцевые микромодуляторы. Источник: Intel Labs В технологии используются лазерные диоды с распределённой схемой обратной связи (distributed feedback, DFB), которая позволяет добиться высокой точности как в мощности излучения в пределах 0,25 дБ, так и в спектральных характеристиках, где отклонения в границах используемых спектров не превышают 6,5%. Достигнутые параметры превышают аналогичные показатели классических полупроводниковых лазеров. Компания также отмечает, что применённая ей новая технология кольцевых микромодуляторов, отвечающих за конверсию электрического сигнала в оптический, существенно компактнее более традиционных решений других разработчиков. Такой подход позволяет поднять удельную плотность фотонных линий передачи данных, то есть, при прочих равных условиях, чип, оснащённый интерконнектом Intel, будет иметь более «широкую» оптическую шину с более высокой пропускной способностью. 
В технологии используется массив из 8 лазеров. Источник: Intel Labs Технология гибридной фотоники со встроенными лазерами, использующая мультиплексирование с разделением по длине волны (dense wavelength division multiplexing, DWDM), делает высокоскоростной оптический интерконнект возможным, но до успеха Intel данная технология упиралась именно в точность разделения спектра и в достаточно высокое энергопотребление источников излучения. В настоящее время уже ведутся работы по созданию специального чиплета, который позволит вывести оптический интерконнект за пределы кремниевой пластины, а это в перспективе даст возможность как для фотонного соединения между центральным процессором и памятью или GPU, так и для реализации будущих ещё более скоростных версий стандарта PCI Express или его наследника. 
Дорога к высокоскоростному оптическому интерконнекту открыта! Источник: Intel Labs Ayar Labs, один из пионеров в освоении гибридных электронно-оптических технологий однако считает, что у подхода Intel есть и недостатки. Сам по себе оптический интерконнект, конечно, может быть производительнее классического, и к тому же он не подвержен помехам. Однако лазерные диоды по природе своей достаточно капризны, а глубокая интеграция источника излучения в чип при выходе хотя бы одного лазера из строя делает всю схему бесполезной. В своих решениях Ayar Labs полагается на внешний лазерный модуль SuperNova.
21.06.2022 [21:59], Игорь Осколков
Консорциум PCI-SIG анонсировал PCI Express 7.0: 512 Гбайт/c к 2025 годуPCI-SIG официально анонсировал следующую версию шины PCI Express — 7.0. Подробности о новом стандарте будут представлены позднее, ну а пока было объявлено самое главное — консорциум придерживается прежнего темпа в деле удвоения скорости передачи данных с каждым новым поколением, так что теперь одна линия PCIe 7.0 сможет предложить 128 ГТ/с (по 16 Гбайт/c в обе стороны без учёта накладных расходов). А 16 линий PCIe 7.0 — впечатляющие 512 Гбайт/с в дуплексе! Столь высокие скорости помогут удовлетворить всё возрастающие требования к HPC-нагрузкам, машинному обучению, сетям (800GbE и выше) и прочим корпоративным задачам. Этому поможет и поддержка будущих версий стандарта CXL, который позволит в значительной степени переработать архитектуру вычислительных систем и хранилищ. Правда, появится новый стандарт только в 2025 году, а его освоение займёт ещё некоторое время. 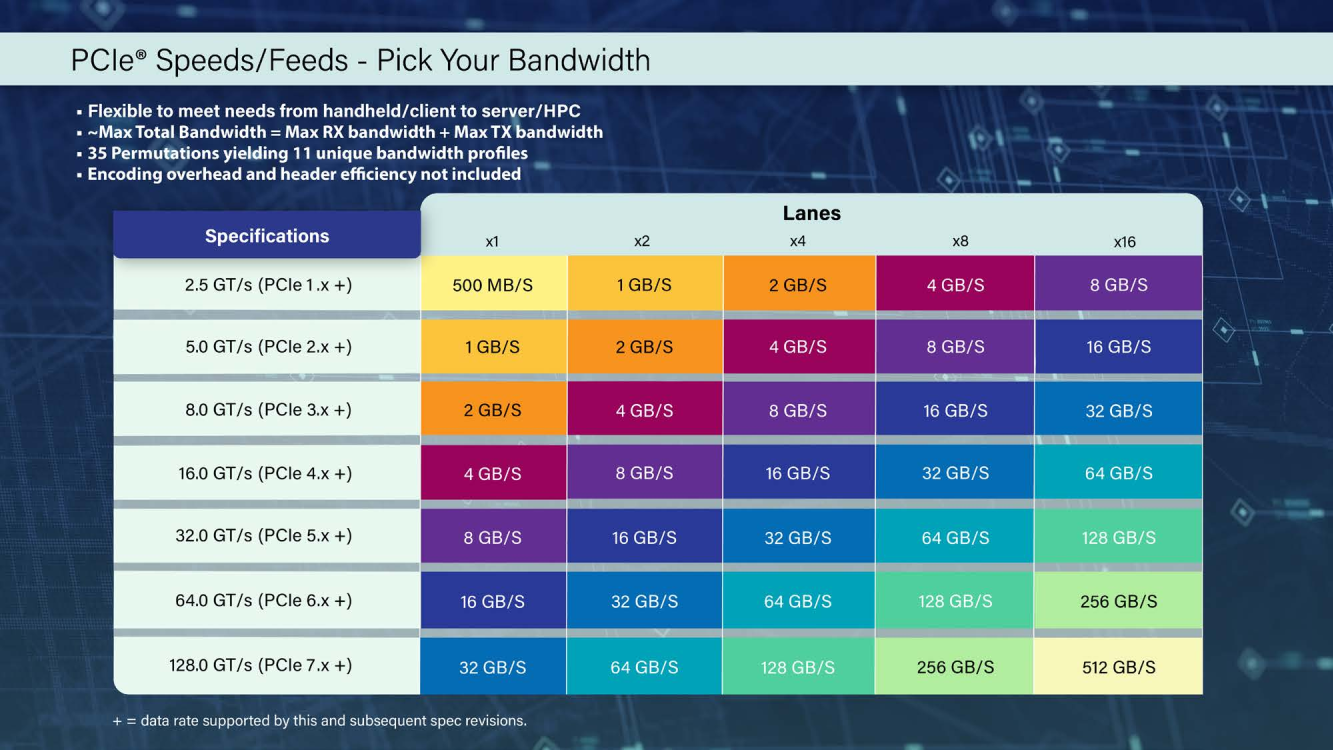
Изображения: PCI-SIG Финальные спецификации PCIe 6.0, напомним, были утверждены только в январе текущего года. Ряд вендоров уже представил первые блоки и контроллеры с поддержкой этого стандарта, однако даже PCIe 5.0 начнёт распространяться только в этом и следующем году, вместе с выходом следующего поколения процессоров AMD, Ampere Computing, Intel и т.д. При этом для нового стандарта понадобится более сложная и дорогая разводка плат. 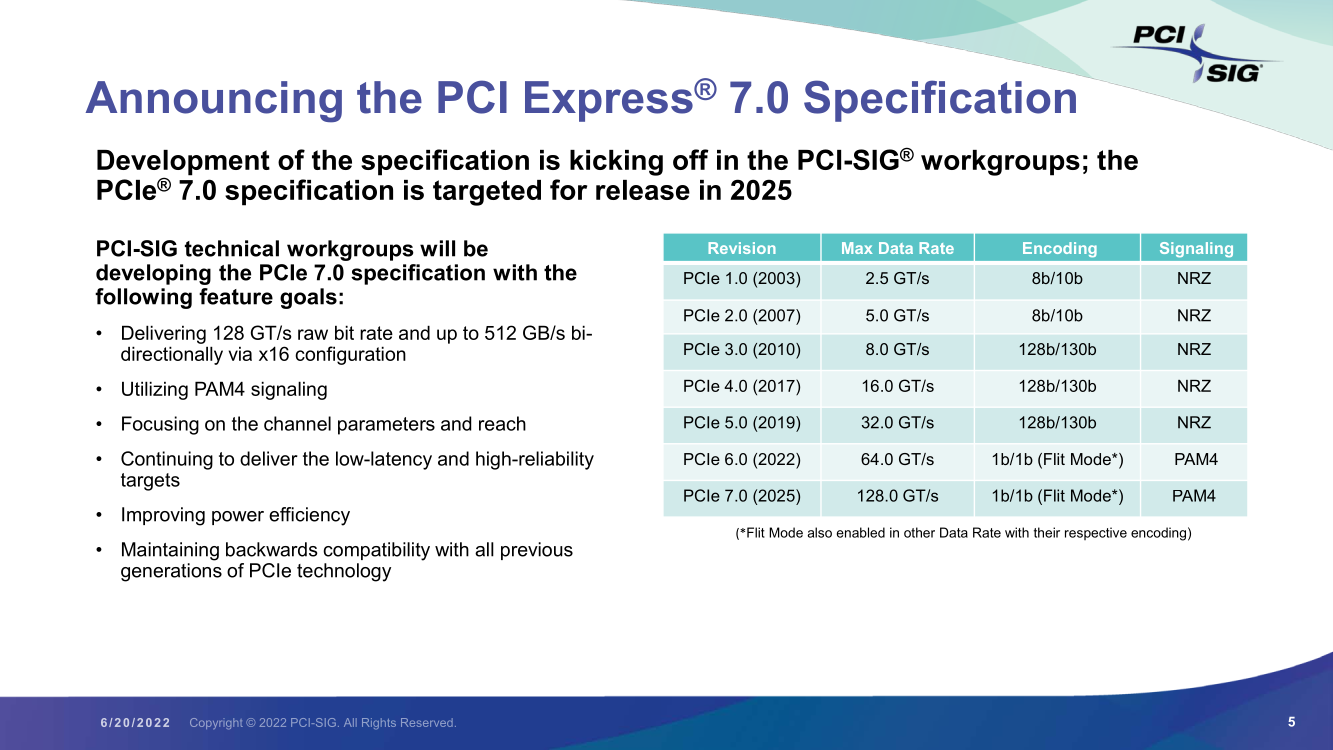 И с приходом эта проблема вряд ли уйдёт PCIe 7.0, если только разработчики не начнёт переходить, например, на оптические соединения. Впрочем, PCI-SIG говорит о том, что выбор числа линий остаётся за производителем, поскольку не всегда нужно x16-подключение, да и в целом шина может легко масштабироваться и найдёт применение и в мобильных устройствах, и в суперкомпьютерах. 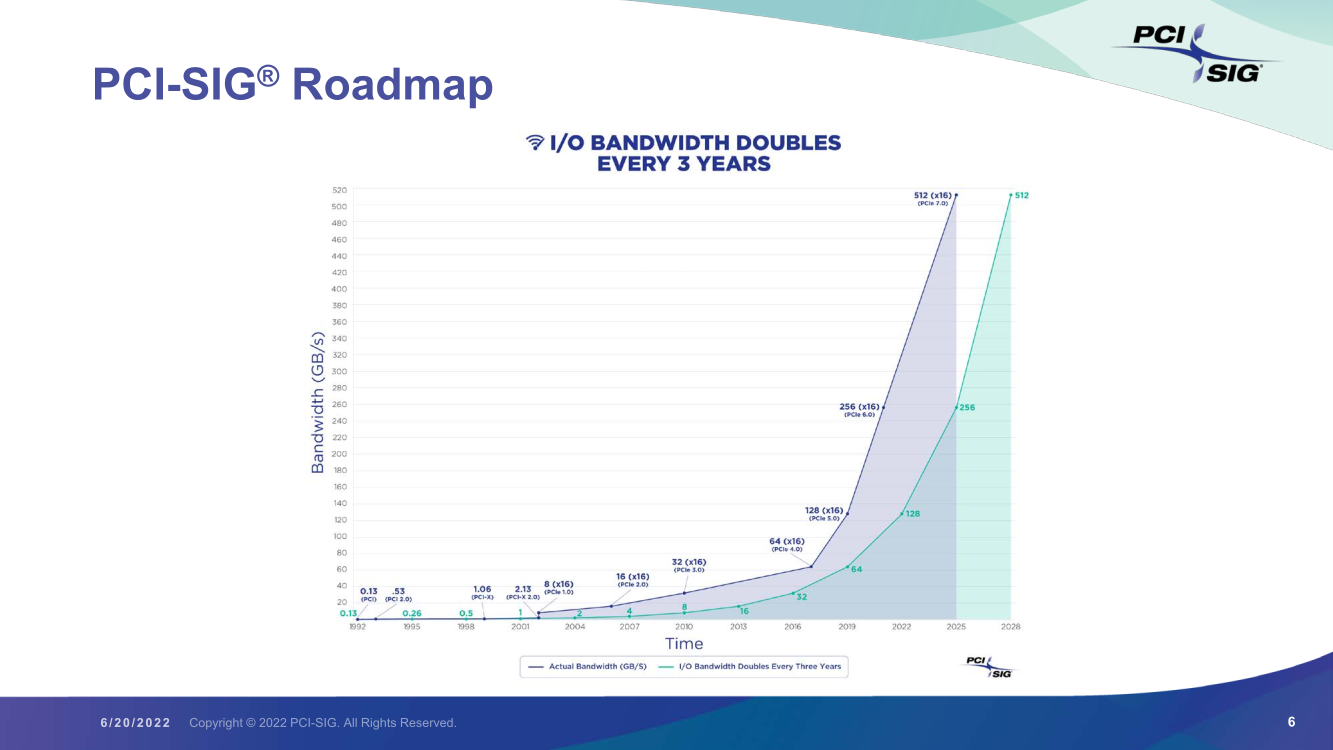 Но у PCIe есть конкуренты. Вместе с анонсом ускорителей Hopper и процессоров Grace компания NVIDIA представила шину NVLink 4.0 с пропускной способностью 900 Гбайт/с. По словам компании, она в 25 раз энергоэффективнее PCIe 5.0 и почти на два порядка экономичнее относительно площади используемого «кремния». При этом сохранена совместимость с CXL и UCIe. Первые продукты самой NVIDIA с этой шиной появятся в следующем году, но «зелёные» готовы сотрудничать с другими разработчиками и вендорами.
08.06.2022 [18:20], Алексей Степин
Synopsys и Juniper Networks объединились для освоения кремниевой фотоникиЗа фотоникой будущее сетей и интерконнектов, это становится всё очевиднее по мере того, как игроки на рынке микроэлектроники создают альянсы для освоения этой «территории». Уже известен союз Ayar Labs и NVIDIA, теперь очередь дошла до Synopsys и крупного производителя сетевого оборудования Juniper Networks. Эти компании объявили о заключении стратегического союза в области освоения фотонных технологий. Детищем альянса стала новая компания, названная OpenLight, в её состав вошло одно из подразделений Juniper, однако 75% активов OpenLight принадлежит Synopsys. 
Источник: OpenLight Название хорошо отражает цели OpenLight — речь идёт о разработке архитектурно открытых решений кремниевой фотоники, которые могут создаваться силами сторонних компаний на мощностях Tower Semiconductor. В планах компании создание высокопроизводительных фотонных чипов для рынка телекоммуникаций, систем лазерной навигации, здравоохранения, высокопроизводительных вычислений и оптических процессоров. Сердцем этих разработок станет электронно-оптический модулятор на основе фосфида индия (InP), обеспечивающий меньшие потери сигнала и лучшие характеристики в сравнении с традиционными кремниевыми аналогами. Ключевой особенностью также считается использование интегрированного лазера, чего нет, например, у Ayar Labs. Технологический процесс PH18DA, используемый Tower Semiconductor позволит добиться такой интеграции, что в перспективе сделает кремниевую фотонику дешевле и доступнее. 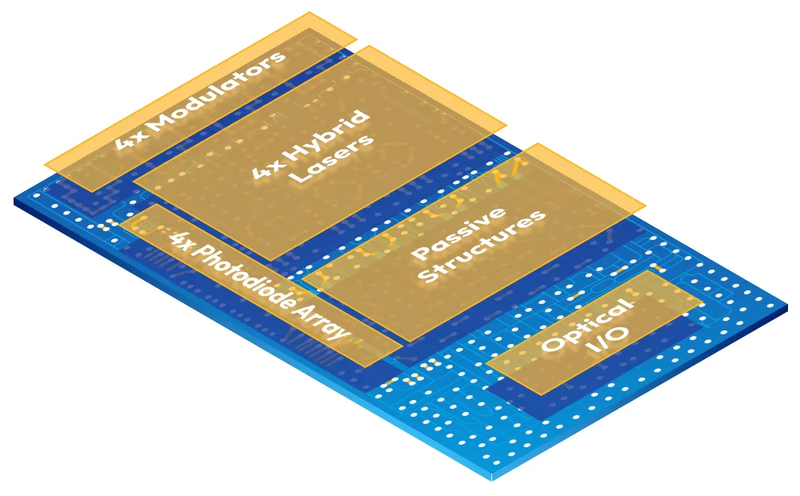
Технологии OpenLight позволят создавать монолитные электронно-оптические чипы. Источник: OpenLight Рабочие образцы первых оптических трансиверов класса 400G/800G на базе новой технологии, по словам представителей OpenLight, можно будет ожидать уже летом этого года. Тогда же компания обещает выпустить и первый многокомпонентный «кремний» на базе техпроцесса PH18DA — на одной пластине будут находиться чипов разных разработчиков. Такой подход позволит оптимизировать производственные расходы и снизить себестоимость готовых изделий. Стоит отметить, что Tower Semiconductor вскоре будет приобретена Intel, которая (как и NVIDIA) кровно заинтересована в разработке кремниево-фотонных технологий и уже успела инвестировать в Ayar Labs вместе с GlobalFoundries, HPE, NVIDIA и Lockheed Martin. В прошлом году Cisco, ещё один крупный производитель сетевого оборудования, поглотил Acacia, компанию-разработчика в области кремниевой фотоники. |
|

