Материалы по тегу: a100
|
15.04.2024 [14:23], Сергей Карасёв
Стартап в области децентрализованных облачных ИИ-вычислений GPUnet получил на развитие $5,25 млнМолодая компания GPUnet, занимающаяся технологиями облачных вычислений, сообщила о проведении раунда финансирования Series A, в ходе которого привлечено $5,25 млн. В число инвесторов вошли Momentum6, Spicy Capital, Exnetwork, Blackdragon, Zephyrus Capital, Aza Ventures, F7 Foundation, Halvings Capital и Bigger than Race. Стартап GPUnet создаёт платформу децентрализованных облачных вычислений на базе GPU. Отмечается, что в свете стремительного развития технологий ИИ ускорители на базе GPU превратились в дефицитный ресурс. Вместе с тем в мировом масштабе четыре крупнейших поставщика облачных услуг — Amazon, Google, Microsoft и Oracle — контролируют 80 % соответствующих мощностей. В результате компании и исследовательские организации вынуждены либо подписываться на сервисы по значительной цене, либо закупать собственное оборудование. Но во втором случае требуются навыки управления ЦОД, а поставки ускорителей занимают много времени. GPUnet рассчитывает решить перечисленные проблемы путём объединения в единую сеть ресурсов независимых операторов дата-центров, которые специализируются на «вычислениях для проектов Web3», в частности, для майнинга. Отмечается, что такие операторы зачастую располагают ценными вычислительными ресурсами в небольших кластерах. GPUnet планирует использовать архитектуру распределённых вычислений, чтобы объединить кластеры в единую экосистему, создав удобную облачную среду для разработчиков и исследователей. 
Источник изображения: GPUnet На веб-сайте GPUnet говорится, что посредством новой платформы клиенты получают доступ к ускорителям NVIDIA. В частности, стоимость аренды H100 составляет $5/час, A100 — $1,5/час, А10 — $1/час. К 2030 году GPUnet рассчитывает объединить в своей экосистеме до 1 млн GPU.
21.03.2024 [22:16], Сергей Карасёв
HP оснастит рабочие станции ускорителями NVIDIA A800, предназначавшимися для КитаяКомпания HP, по сообщению ресурса Tom's Hardware, готовит к выпуску новые рабочие станции серии Z, рассчитанные на приложения ИИ. В оснащение этих компьютеров войдут ускорители NVIDIA A800, которые изначально создавались для Китая в качестве «урезанной» версии А100 (40 Гбайт). Предполагалось, что операторы дата-центров в КНР смогут закупать решения A800, которые проектировались специально с учётом санкционных ограничений со стороны США. Стоимость этих ускорителей, по имеющимся данным, на начальном этапе составляла $14,5 тыс. Однако в связи с введением новых экспортных ограничений США на поставку в Китай современных технологий отгрузки A800 в Поднебесную стали невозможны. Вместо них NVIDIA подготовила ускорители H20, L20 и L2. А выпущенные A800 пришлось перераспределять в другие регионы. Однако из-за того, что у A800 пропускная способность интерконнекта NVLink в угоду санкциям снижена до 400 Гбайт/с против 600 Гбайт/с у А100, «урезанные» ускорители оказались не слишком популярны среди заказчиков. В такой ситуации установка A800 в рабочие станции НР поможет NVIDIA реализовать имеющиеся запасы продукции. 
Источник изображения: NVIDIA Характеристики систем НР серии Z пока не раскрываются. Высказываются предположения, что в их основу лягут либо процессоры Intel Xeon Emerald Rapids (или, возможно, Xeon Sapphire Rapids), либо чипы AMD Ryzen Threadripper Pro 7000 WX. Сама NVIDIA ещё в ноябре 2023 года фактически анонсировала A800 для западных рынков, заявив, что это «идеальная платформа для рабочих станций для ИИ, анализа данных и высокопроизводительных вычислений». В числе партнёров NVIDIA, которые занимаются продвижением A800, значатся PNY, Colfax International, ASK и Elsa.
06.11.2023 [23:56], Владимир Мироненко
NVIDIA определилась, куда поставлять предназначавшиеся для Китая ускорители A800В связи с введением новых экспортных ограничений США на поставку в Китай современых технологий компания NVIDIA начала перераспределять в другие регионы поставки ускорителей A800, изначально созданных для Поднебесной взамен NVIDIA А100 (40 Гбайт) с учётом предыдущих ограничений по производительности и пропускной способности интерконнекта, установленных в октябре 2022 года. Как сообщает ресурс CRN, на прошлой неделе американский производитель электроники PNY Technologies и системный интегратор Colfax International начали продвигать на рынке ускоритель NVIDIA A800 Active PCIe 40GB, который чип-мейкер охарактеризовал на своём сайте как «идеальную платформу для рабочих станций для ИИ, анализа данных и высокопроизводительных вычислений». 
Источник изображения: Acro Представитель PNY сообщил CRN, что компания с прошлого понедельника начала продажи нового ускорителя через партнёров в Северной Америке, Латинской Америке, Европе, Африке и Индии. Исключение составляют подсанкционные государства: Китай, Россия и большинство стран Ближнего Востока. В числе партнёров NVIDIA, которые также занимаются продвижением NVIDIA A800 Active PCIe 40GB, есть японские компании ASK Corp. и Elsa, а также индийская Acro. 
Источник изображения: NVIDIA Введение ограничений власти США объясняют намерением помешать Китаю получить доступ к новейшим технологиям для укрепления своих вооружённых сил. Ограничения коснулись и недавно выпущенного ускорителя NVIDIA L40S, который в ряде задач является неплохой альтернативой A100, а также чипов Intel и AMD. Ранее газета The Wall Street Journal сообщила, что из-за санкций NVIDIA пришлось отменить заказы на поставку ускорителей китайским фирмам в следующем году на сумму более $5 млрд. 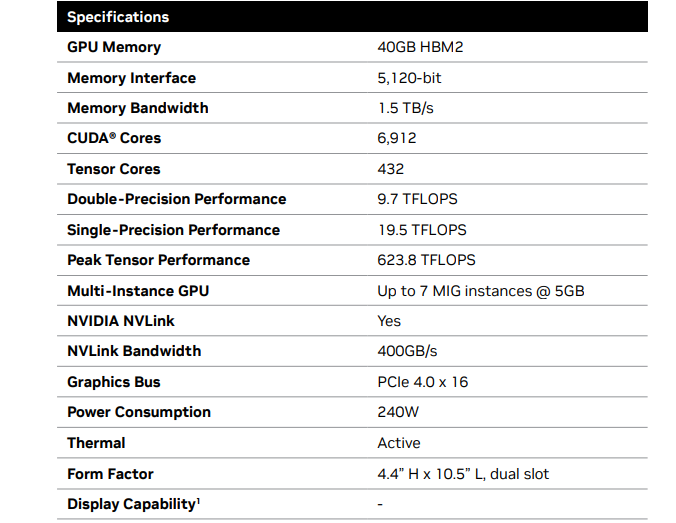
Источник: NVIDIA Следует уточнить, что NVIDIA A800 40 GB Active представляет собой двухслотовую PCIe-карту с активным охлаждением, но ускоритель A800 также предлагался в форм-факторе SXM. Ускоритель имеет 40 Гбайт памяти HBM2 с ПСП на уровне 1,5 Тбайт/с, а также поддерживает объединение двух карт посредством мостика NVLink, пропускная способность которого в угоду санкциям была урезана с 600 до 400 Гбайт/с. TDP составляет 240 Вт.
21.10.2023 [16:44], Сергей Карасёв
Gcore развернула кластер генеративного ИИ с ускорителями NVIDIAПровайдер облачных и периферийных сервисов Gcore, по сообщению ресурса Datacenter Dynamics, запустил вычислительный кластер для решения задач в области генеративного ИИ. Площадка, расположенная в Люксембурге, использует ускорители NVIDIA. Ранее Gcore уже развернула в Люксембурге ИИ-платформу на базе Graphcore IPU (Intelligence Processing Unit). Кроме того, компания оперирует такими системами в Амстердаме (Нидерланды) и Уэльсе (Великобритания). Новый кластер позволит клиентам ускорить решение задач в сферах генеративного ИИ и машинного обучения. Запущенная в Люксембурге площадка объединяет 20 серверов с ускорителями NVIDIA A100. До конца текущего года будут добавлены 128 узлов на базе NVIDIA H100 и ещё 25 серверов с изделиями A100. О текущей и планируемой производительности кластера данных пока нет. Отмечается лишь, что заказчики смогут разворачивать на базе платформы крупномасштабные ИИ-модели. 
Источник изображения: NVIDIA На сегодняшний день Gcore имеет точки присутствия в более чем в 140 регионах на шести континентах, а также более чем 20 облачных локаций. Компания была основана в 2014 году, а услуги CDN и хостинга начала предоставлять в 2016 году.
20.10.2023 [14:46], Сергей Карасёв
Три поколения EPYC, A100, L40 и немного Xeon: HPE создала для Франции ИИ-суперкомпьютер Austral на базе Cray XD2000Компания Hewlett Packard Enterprise (HPE) объявила о вводе в эксплуатацию нового ИИ-суперкомпьютера под названием Austral, разработанного в интересах Регионального центра информатики и цифровых приложений Нормандии (CRIANN) во Франции. В основу вычислительного комплекса положена платформа Cray XD2000. Задействованы 11 двухпроцессорных узлов на базе AMD EPYC 7543 Milan (32 ядра на сокет; 2,8 ГГц; 512 Гбайт оперативной памяти DDR4-3200). Каждый из этих узлов использует восемь ускорителей NVIDIA A100 с 80 Гбайт памяти. Кроме того, в состав суперкомпьютера входят 124 двухпроцессорных узла с чипами AMD EPYC 9654 Genoa (96 ядер на сокет; 2,4 ГГц; 768 Гбайт оперативной памяти DDR5-4800). Есть и один специализированный узел с процессором AMD EPYC 7313P Rome (16 ядер; 3,0 ГГц; 96 Гбайт оперативной памяти DDR4-3200). Плюс к этому установлены пять двухсокетных узлов визуализации на основе AMD EPYC 9654 — каждый с двумя ускорителями NVIDIA L40 с 48 Гбайт памяти и 768 Гбайт ОЗУ DDR5-4800. Наконец, предусмотрен один узел HPE Superdome Flex 280 с восемью чипами Intel Xeon 8376H (28 ядер; 2,6 ГГц) и 6 Тбайт оперативной памяти DDR4-3200. Применяется 200G-интерконнект HPE Slingshot. Ёмкость хранилища достигает 2 Пбайт. Программная платформа основана на решениях Red Hat. 
Источник изображения: HPE Заявленная пиковая FP64-производительность составляет 966 Тфлопс для CPU-части DP и 1034 Тфлопс — для GPU-блока. Применять суперкомпьютер планируется для проведения моделирования и анализа в таких областях, как изменения климата, биотехнологии, здравоохранение и материаловедение.
28.08.2023 [17:09], Сергей Карасёв
ITGLOBAL.COM предлагает доступ к облачным ИИ-серверам на базе NVIDIA A800Российский интегратор и поставщик IT-услуг ITGLOBAL.COM объявил о том, что клиентам в России стал доступен сервис AI Cloud, в рамках которого можно арендовать облачные серверы на базе высокопроизводительных ускорителей. Эти системы предназначены прежде всего для решения задач в области ИИ и машинного обучения. Облачные серверы построены на платформе VMware, а виртуальные машины работают с ускорителями NVIDIA A800, которые из-за санкций США были специально созданы для китайского рынка. Это, как утверждается, обеспечивает высокое быстродействие и отказоустойчивость среды. Сервис AI Cloud развёрнут в России, Казахстане и Нидерландах. Заказчикам доступны шесть конфигураций: 1vGPU.10GB (один vGPU, 10 Гбайт памяти), 1vGPU.20GB, 2vGPU.20GB, 3vGPU.40G, 4vGPU.40G и 7vGPU.80GB. 
Источник изображения: ITGLOBAL.COM Задействованы серверы vStack-R-SY4105G-D12R-G3, которые несут на борту два процессора Intel Xeon Gold 6242 (Cascade Lake-SP) с тактовой частотой 2,8 ГГц и 1 Тбайт оперативной памяти DDR4-3200. Применяется СХД на базе старших моделей NetApp All Flash FAS (AFF), в том числе A700. Для резервного копирования используются СХД NetApp семейства FAS и E-Series.
20.07.2023 [17:35], Алексей Степин
К2Тех развернула в Новосибирском университете 47-Тфлопс суперкомпьютер с российским интерконнектом «Ангара»
a100
hardware
hpc
ice lake-sp
intel
nvidia
xeon
ангара
к2тех
новосибирск
россия
сделано в россии
суперкомпьютер
Компания K2Tex объявила о создании суперкомпьютерного вычислительного комплекса для центра Центра Национальной технологической инициативы (НТИ) по Новым функциональным материалам на базе Новосибирского государственного университета (НГУ). 
Источник здесь и далее: Новосибирский государственный университет Новый кластер базируется на отечественных вычислительных узлах, и что немаловажно, объединён интерконнектом российской же разработки — речь идёт о решении «Ангара», созданном АО «НИЦЭВТ». В данном случае используется вариант с пропускной способностью 75 Гбит/с на линк с подключением через неблокирующий коммутатор и модуль синхронизации. С помощью этого же интерконнекта подключено и внешнее NFS-хранилище, состоящее из двух выделенных серверов с дисковой полкой, оснащённой 24 дисками SAS (2,4 Тбайт, 10k RPM). Ёмкость хранилища — не менее 40 Тбайт. Сами вычислительные узлы построены на базе Intel Xeon Scalable Ice Lake-SP: каждый узел содержит по паре 28-ядерных процессоров, 256 Гбайт RAM и пару локальных 480-Гбайт SSD. Отдельный GPU-узел включает пару ускорителей NVIDIA A100 (80GB). Всего в системе 11 узлов, а общее количество доступных для вычислений процессорных ядер составляет 392. Заявленный пиковый уровень производительности достигает 47 Тфлопс (FP64).  Также в системе задействована отечественная платформа виртуализации zVirt, развёрнутая на двух управляющих узлах кластера. На основе zVirt реализованы средства автоматического развёртывания, подсистема входа пользователей, сервис планировщика заданий, средства аутентификации и мониторинга. Новый кластер потребовался для решения стратегических задач, в том числе для разработки новых материалов с заданными свойствами, в частности, композиционных электрохимических покрытий, перспективных магнитных материалов и огнеупорных материалов. Также новый суперкомпьютер будет использоваться в ключевых проектах, связанных с ИИ и машинным обучением. Сюда входит, например, разработка цифровых паспортов для материалов и создание цифровых двойников технологических процессов.
22.06.2023 [17:04], Алексей Степин
NVIDIA AX800: ИИ-сервер для 5G в форм-факторе PCIe-картыВ форм-факторе плат расширения PCIe существует множество устройств, включая, к примеру, маршрутизаторы. Но NVIDIA AX800 выводит это понятие на новый уровень — здесь плата расширения являет собой полноценный высокопроизводительный сервер. Плата включает DPU BlueField-3, который располагает 16 ядрами Cortex Arm-A78, дополненных 32 Гбайт RAM, а также ускоритель A100 (80 Гбайт). Новинкая является наследницей карты A100X, но с гораздо более производительным DPU. 
Источник изображений здесь и далее: NVIDIA На борту также имеется eMMC объёмом 40 Гбайт, два 200GbEпорта (QSFP56). Плата выполнена в форм-факторе FHFL, имеет пассивное охлаждение и предельный теплопакет 350 Вт. Дополнительно предусмотрен порт 1GbE для удалённого управления для BMC ASPEED AST2600, так что речь действительно идёт о полноценном сервере. На PCB имеются гребёнки разъёмов NVLink — данное решение может работать не в одиночку, а в составе высокоплотного многопроцессорного сервера. 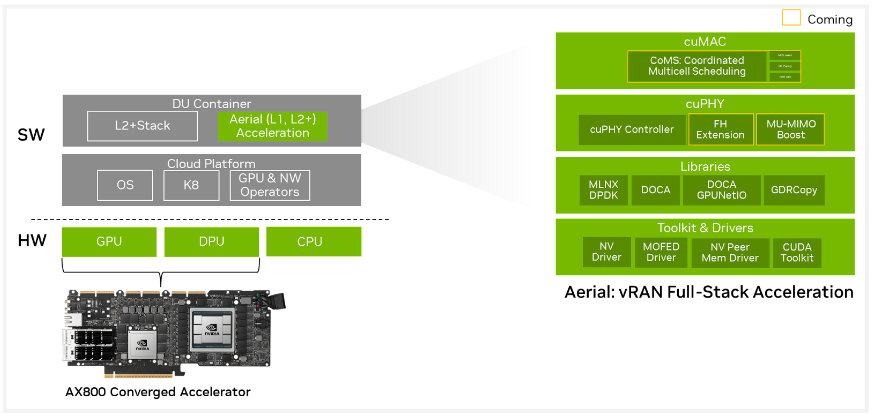
NVIDIA AX800 позволяет построить полностью ускоряемый стек 5G vRAN NVIDIA позиционирует новинку как решение для систем 5G vRAN, но также она может найти место и в высокоплотных системах периферийных системах для ИИ-задач. В качестве программной платформы предлагается Aerial 5G vRAN. Плата ускоряет обработку L1/L2-трафика 5G и способна предложить до 36,56 и 4,794 Гбит/с нисходящей и восходящей пропускной способности (4T4R). Платформа поддерживает масштабирование от 2T2R до 64T64R (massive MIMO). А поддержка MIG позволяет гибко перераспределять нагрузки ИИ и 5G.
09.05.2023 [01:01], Сергей Карасёв
Ускоритель NVIDIA A800 для Китая стоит около $14,5 тыс.В интернете, по сообщению ресурса VideoCardz, появились подробности о характеристиках ускорителя NVIDIA A800 — урезанной версии NVIDIA А100, созданной специально для китайского рынка. Это решение предлагается по ориентировочной цене $14,5 тыс. На аналогичный шаг с выпуском особых версий ускорителей для Китая пошла и Intel. В условиях жёстких американских санкций в отношении Китая компания NVIDIA вынуждена создавать специализированные ускорители для рынка КНР с ограниченной производительностью. Снижение производительности в случае A800 объясняется прежде всего ограничениями в плане масштабируемости: можно использовать до восьми SXM-изделий против 16 для А100. Кроме того, пропускная способность интерконнекта NVLink составляет 400 Гбайт/с против 600 Гбайт/с у оригинальной версии. 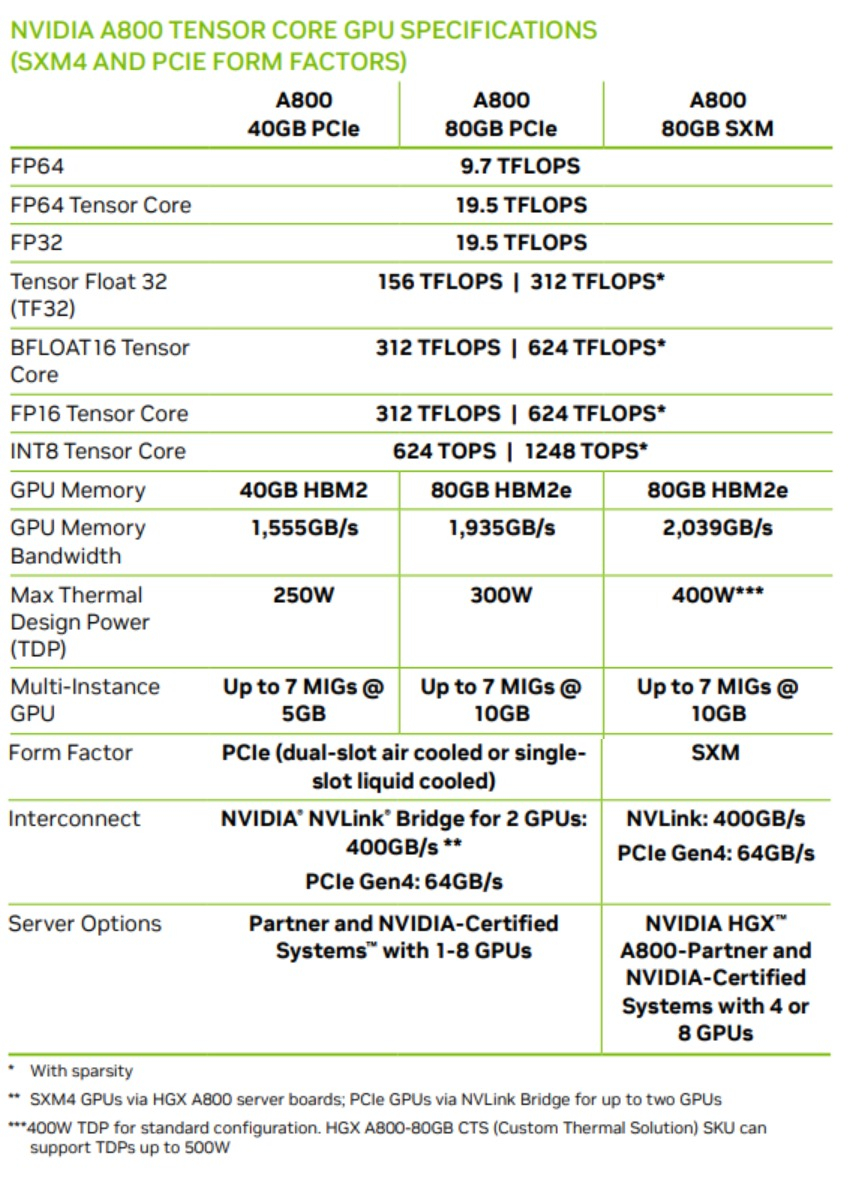
Источник: VideoCardz Хотя вычислительная мощность на нагрузках FP32 и FP64 оказывается сопоставимой. У А800 показатели, по данным NVIDIA, достигают соответственно 19,5 Тфлопс и 9,7 Тфлопс, что и у A100. Тензорные ядра для BF16/FP16 выдают те же 312 Тфлопс (624 Тфлопс с разреженностью). Ускорители серии NVIDIA A800 существуют в вариантах PCIe с 40 и 80 Гбайт памяти HBM2e (с воздушным или жидкостным охлаждением), а также в модификации SXM с 80 Гбайт памяти.
15.02.2023 [19:03], Алексей Степин
SK Telecom удвоила мощность ИИ-суперкомпьютера Titan, ответственного за работу корейского варианта GPT-3Южная Корея — одна из стран, наиболее активно вкладывающих массу ресурсов в развитие собственной суперкомпьютерной инфраструктуры, в том числе, в разработку собственных процессоров и ускорителей. Уделяет она серьёзное внимание и модернизации существующих HPC-систем, что актуально в свете бурного развития ИИ, особенно нейросетевых языковых моделей. Крупный южнокорейский телеком-провайдер, компания SK Telecom объявила серьёзной модернизации суперкомпьютера Titan, который является «мозгом» для ИИ-модели Aidat (A dot) — корейского варианта знаменитой GPT-3. Впервые эта сеть дебютировала в мае прошлого года в качестве ИИ-помощника SK, помогающего с рекомендациями для выбора аудио- и видеоконтента владельцам смартфонов. 
Источник: SK Telecom Titan не имеет отношения к уже демонтированному кластеру Окриджской национальной лаборатории — это система, базирующаяся на серверах HPE Apollo 6500 с процессорами AMD EPYC 7763 (64C/128T, 2,45 ГГц) и в ноябре 2022 года занявшая 92 место в TOP500 с результатом 6,29 Пфлопс. Суперкомпьютер использует ускорители NVIDIA A100 (80 Гбайт) и интерконнект InfiniBand HDR. Деталей о обновлении системы SK Telecom практически не раскрывает, но известно, что количество ускорителей доведено до 1040, и это позволило достичь модернизированному кластеру пиковой производительности на уровне 17,1 Пфлопс, что более чем вдвое превосходит предыдущий показатель. Компания отмечает, что апгрейд позволит использовать ещё более сложные модели, что должно улучшить качество ответов Aidat. |
|

