Материалы по тегу: dpu
|
23.04.2024 [11:43], Сергей Карасёв
MaxLinear повысит производительность и эффективность СХД Dell PowerMaxКомпании MaxLinear и Dell Technologies объявили о заключении соглашения о сотрудничестве, которое направлено на повышение производительности и эффективности систем хранения Dell PowerMax на основе накопителей NVMe SSD и процессоров Intel Xeon. В рамках партнёрства платформы PowerMax 2500 и 8500 будут оснащены ускорителем MaxLinear Panther III. Это решение было представлено в августе 2022 года. Изделие содержит 16 аппаратных движков для хеширования, шифрования/дешифрования, компрессии/декомпрессии и сквозной защиты данных (RTV). Утверждается, что пропускная способность превышает 200 Гбит/c. Кроме того, обеспечивается дедупликация данных вплоть до 12:1. В случае СХД семейства PowerMax применение MaxLinear Panther III позволит оптимизировать ресурсы хранения и снизить общую стоимость владения. Заявленный коэффициент сокращения объёмов данных достигает 5:1, тогда как эффективная вместимость массивов может достигать 18 Пбайт. При этом время отклика составляет менее 18 мкс. Обеспечивается высокий уровень безопасности, что важно при работе с критической информацией. 
Источник изображения: Dell Отмечается, что сотрудничество между MaxLinear и Dell знаменует собой важную веху в развитии решений хранения данных для бизнеса на основе ИИ. Утверждается, что массивы PowerMax 2500 и 8500 устанавливают новый стандарт для корпоративных СХД, позволяя организациям раскрыть весь потенциал своей инфраструктуры и стимулировать бизнес-инновации. Причём развёртываться СХД могут как в локальных ЦОД, так и в гибридных облачных средах.
19.04.2024 [22:51], Владимир Мироненко
Гиперщит с ИИ: Cisco представила систему безопасности HypershieldCisco представила комплексную распределённую систему безопасности нового поколения Hypershield, призванную укрепить защиту ЦОД и облачной инфраструктуры. Cisco Hypsershield предназначена для защиты приложений, устройств и данных в различных средах, включая государственные и частные ЦОД, облака и физические устройства. Как утверждает компания, благодаря интеграции ИИ новая технология позволяет добиться более высоких результатов в области безопасности, чем это было возможно с помощью людей. Hypershield использует постоянно дообучающийся ИИ, а платформа изначально построена и спроектирована как автономная система с возможностью прогнозирования. 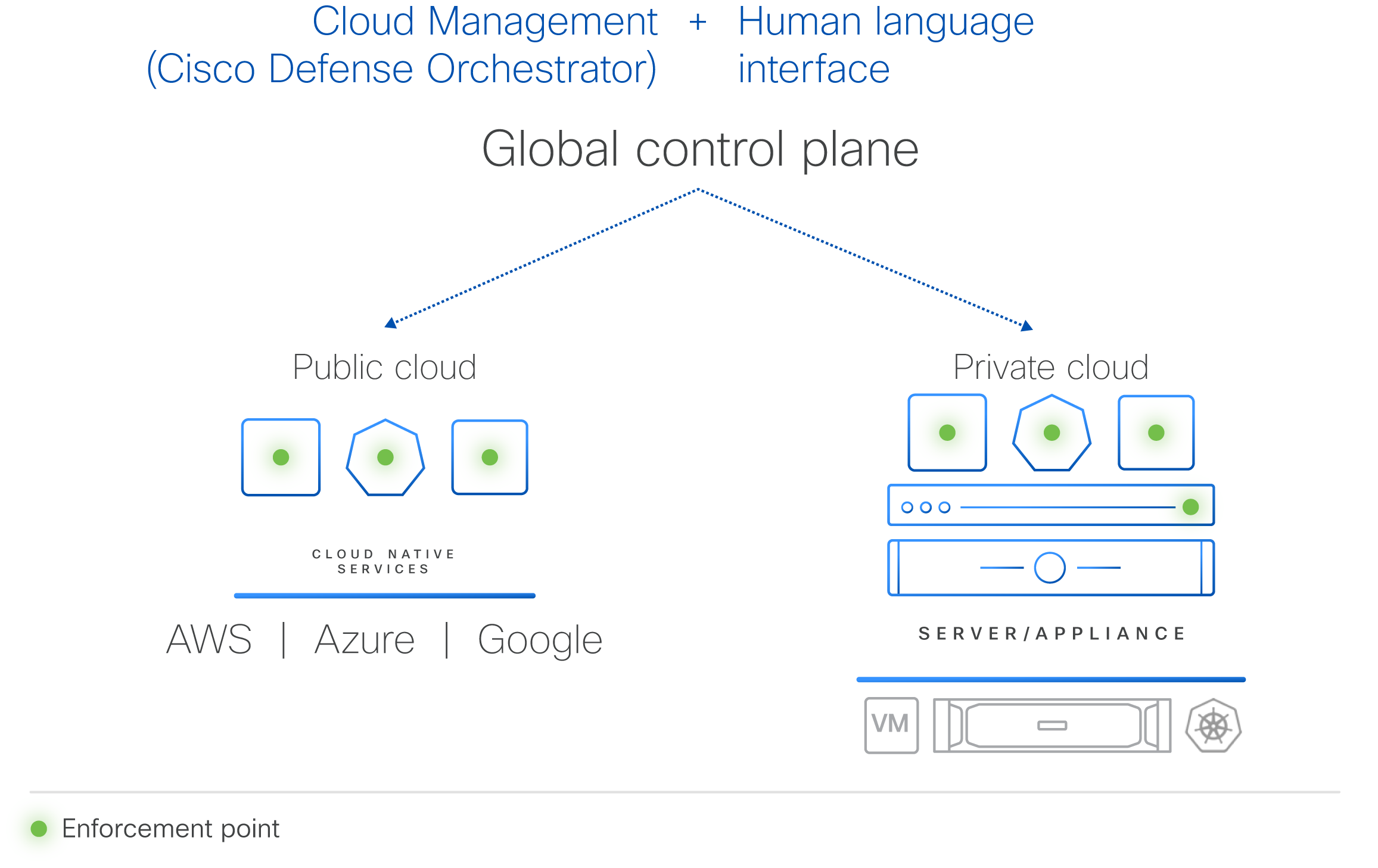
Источник изображения: Cisco Hypershield создана на основе технологии, изначально разработанной для гиперскейлеров. Система представляет собой скорее структуру безопасности, позволяющую применять политики безопасности везде, где это необходимо: для каждой службы приложений, кластера Kubernetes, контейнера, виртуальной машины или сетевого порта. По словам компании, Hypershield может обеспечить безопасность везде, где нужно клиенту — в программном окружении, на сервере и в будущем даже в сетевом коммутаторе. В распределённой системе, которая может включать сотни тысяч точек применения политик (Enforcement Point), упрощённое управление имеет решающее значение, отмечает Cisco. 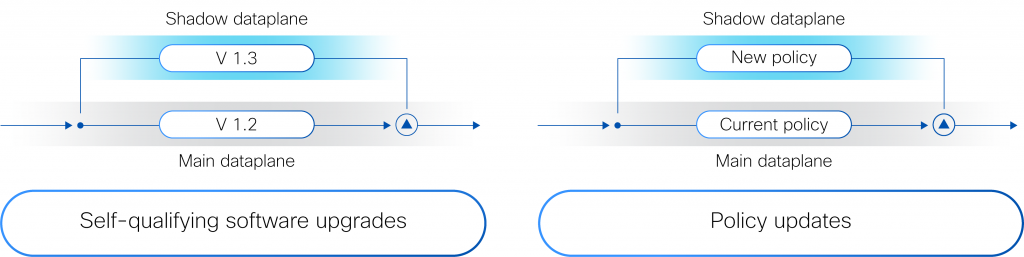 Hypershield предлагает распределённую защиту от эксплойтов, применяя в течение нескольких минут после появления информации об атаках различные компенсаторные механизмы, в том числе меняя конфигурацию сети на лету. В случае проникновения атакующего в сеть система автоматически делает сегментацию. Кроме того, Hypershield автономно тестирует обновление ПО и политик, применяя их сначала внутри цифрового двойника и оценивая последствия вносимых изменений. В программных средах Hypershield использует в первую очередь eBPF, причём ранее Cisco приобрела ведущего поставщика решений в этой области. На аппаратном уровне она позволяет задействовать DPU, в скором будущем компания представит новые коммутаторы с интегрированными DPU. Как ожидается, Cisco Hypershield станет доступна в августе этого года. Лицензию придётся покупать на каждую рабочую нагрузку, но точные критерии расчёта стоимости компания пока не раскрывает.
11.04.2024 [17:59], Алексей Степин
Сделано в Европе: Kalray представила ускоритель Turbocard4 для машинного зрения и обработки ИИ-данныхКомпания Kalray объявила о коммерческой доступности новых ускорителей Turbocard4 (TC4). Новинка позиционируется в качестве решения для ускорения работы систем машинного зрения, либо как акселератор «умной» индексации данных. На борту ускорителя, выполненного в формате FHFL установлено сразу четыре чипа DPU Coolidge 2 с фирменной архитектурой Kalray MPPA. Эти процессоры были анонсированы ещё летом прошлого года в качестве энергоэффективных DPU с производительностью до 1,5 Тфлопс в режиме FP32 и 50 Топс в характерном для инференса режиме INT8. 
Источник изображений здесь и далее: Kalray Выбор рынков не случаен: машинное зрение сегодня является быстро растущей отраслью, в 2023 году оцененной в более чем $20 млрд, а к 2032 году эта цифра обещает вырасти до $175 млрд. Про индексацию данных для генеративного ИИ нечего и говорить — на дворе бум подобных технологий, а объёмы наборов данных постоянно растут. Такие датасеты требуют эффективной предобработки, иначе растущее время выборки нужных данных будет сдерживать производительность и обучения, и инференса.  Интересно, что производятся TC4 в Европе, на французской фабрике Asteelflash, уже получившей первый заказ на сумму более $1 млн. В силу перспективности избранных направлений не следует удивляться, что европейская инициатива Kalray и Asteelflash поддержана французским правительством в рамках программы CARAIBE. Уже в 2025 году планируется довести темпы производства ускорителей TC4 с сотен до нескольких тысяч в месяц. 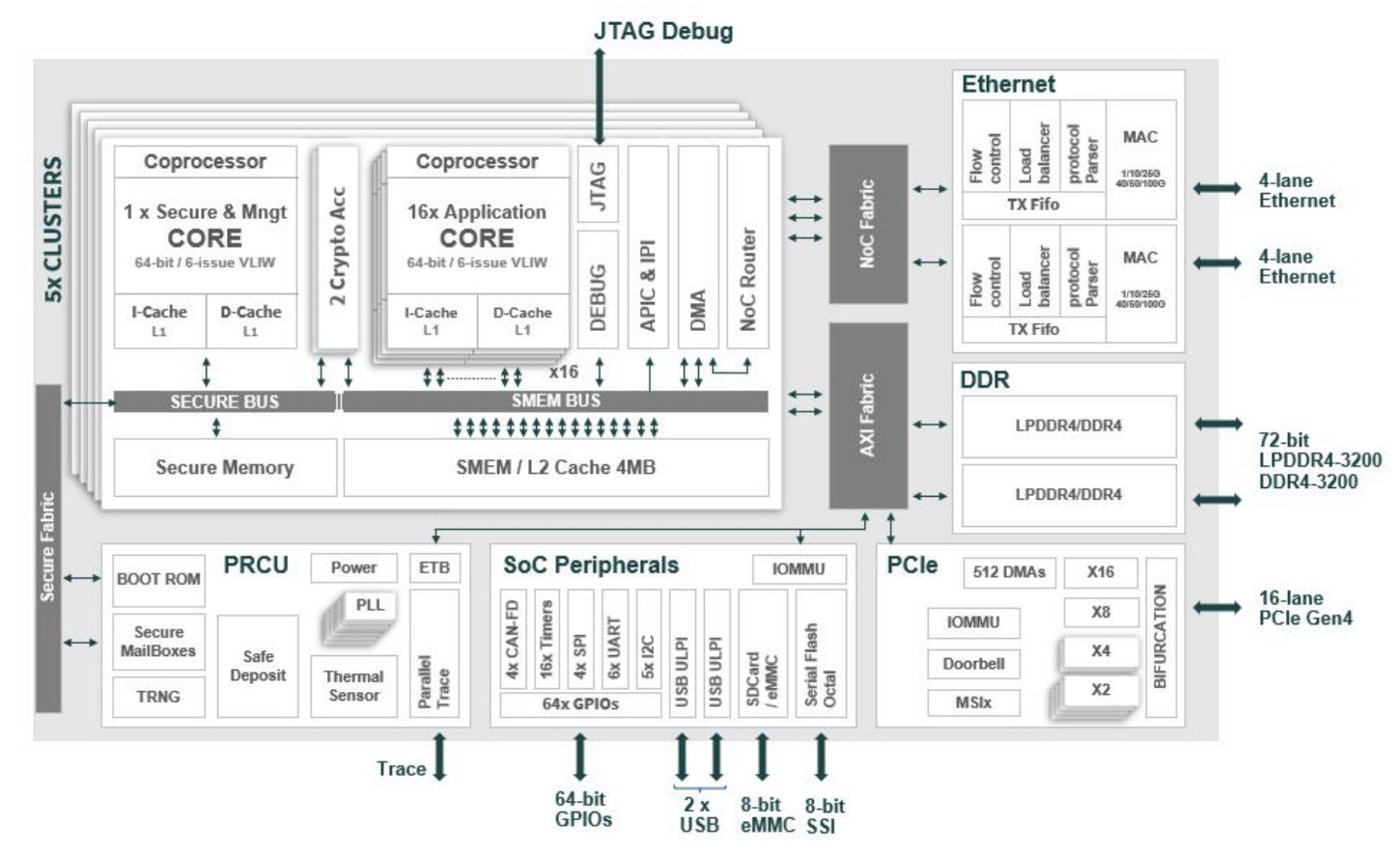 Coolidge 2, по словам создателей, представляет собой универсальное решение на базе архитектуры VLIW. Он имеет 80 ядер с частотой до 1,2 ГГц, причём каждое ядро располагает FPU (IEEE 754-2008). Имеются оптимизации для матричных операций и трансцендентных функций. Процессор разделён на 5 кластеров по 16 ядер, каждый кластер имеет дополнительное управляющее ядро, отвечающее также за функции безопасности. Дополняет Coolidge 2 кеш объёмом 8 Мбайт, двухканальный контроллер памяти DDR4-3200 и пара интерфейсов 100GbE с поддержкой RoCE. Чип поддерживает форматы INT8, FP16, FP32 и даже FP64. Поскольку на борту Turbocard4 работает сразу четыре Coolidge 2, речь идёт о 6 Тфлопс для FP32, 100 Тфлопс для FP16 и 200 Топс для INT8 при теплопакете в районе 120 Вт. Что касается программной поддержки, Kalray сопровождает свои решения SDK, базирующимся на открытых стандартах. Поддерживаются Linux и RTOS.
23.02.2024 [19:31], Сергей Карасёв
Senao Networks выпустила 25GbE-адаптеры SX904 SmartNIC на базе Xeon DКомпания Senao Networks анонсировала сетевые адаптеры серии SX904 SmartNIC, предназначенные для использования в составе облачных сервисов, edge-платформ, телекоммуникационных инфраструктур и корпоративных дата-центров. В основу новинок положены процессоры Intel Xeon D-1700. Адаптеры призваны снизить нагрузку на CPU серверов при выполнении различных сетевых задач. Это мониторинг трафика и обеспечение безопасности, DPI, шифрование данных, управление политиками с использованием протоколов динамической маршрутизации, организация VPN, приоритизация трафика, SD-WAN, NGFW, ZTNA, а также для OpenBMC. 
Источник изображения: Senao Networks Изделия выполнены в виде однослотовых карт расширения с интерфейсом PCIe 4.0 x8. В зависимости от модификации задействован процессор Xeon D-1713NT (4C/8T; до 3,5 ГГц, 45 Вт), Xeon D-1733NT (8C/16T; до 3,1 ГГц, 53 Вт) или Xeon D-1747NTE (10C/20T; до 3,5 ГГц, 80 Вт). Объём оперативной памяти DDR4-2933 ECC может достигать 32 Гбайт. Адаптеры наделены контроллером Intel Ethernet E810, а также ВМС-чипом AST2600 и модулем PFR (Platform Firmware Resilience) AST1060. Заявлена поддержка TPM 2.0. В оснащение может входить флеш-модуль eMMC вместимостью до 128 Гбайт. Есть два порта 25GbE SFP28, дополнительный разъём 1GbE RJ-45, по одному интерфейсу UART (mini-USB) и USB3.0 Type-A. Габариты составляют 266 × 98,4 × 20,4 мм, масса — около 1,1 кг. Для подачи питания предусмотрен дополнительный 8-контактный коннектор. Диапазон рабочих температур простирается от 0 до +50 °C.
22.02.2024 [14:34], Сергей Карасёв
Microsoft разрабатывает специализированную сетевую карту для ИИ-серверовКорпорация Microsoft, по сообщению The Information, проектирует кастомизированный сетевой адаптер для своих дата-центров, оборудованных ИИ-серверами с ускорителями. Предполагается, что внедрение новых изделий поможет увеличить производительность при обработке ресурсоёмких ИИ-задач и снизить затраты на закупку оборудования. Речь, как сообщается, идёт о создании аналога сетевого адаптера или DPU уровня NVIDIA ConnectX-7. Это решение предоставляет до четырёх портов, обеспечивая пропускную способность до 400 Гбит/с. Поддерживается аппаратное ускорение обработки трафика, работы СХД, систем безопасности и управления в ЦОД для облачных, телекоммуникационных и корпоративных нагрузок, а также ИИ. 
Источник изображения: Microsoft Известно, что на разработку новинки у Microsoft может уйти около года. Проект курирует Прадип Синдху (Pradeep Sindhu), соучредитель и бывший генеральный директор компании Juniper Networks, которую в январе нынешнего года купила корпорация HPE за $14 млрд. Microsoft намерена использовать собственный адаптер для управления сетевым трафиком ИИ-серверов, оснащённых ускорителями NVIDIA. Идея заключается в том, чтобы снизить нагрузку на CPU и поднять скорость обработки данных. В начале 2023 года корпорация приобрела разработчика DPU Fungible, который был основан господином Синдху. У Microsoft уже есть DPU MANA, основой которой является кастомизированный чип (SoC), разработанный специально с учётом обеспечения высокой пропускной способности. Также компания применяет DPU Pensando. Microsoft проектирует и другие компоненты для своих дата-центров. Это, в частности, 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100. А на днях стало известно, что Microsoft заказала у Intel Foundry производство кастомных чипов по техпроцессу Intel 18A.
15.02.2024 [12:34], Сергей Карасёв
NVIDIA, возможно, поглотила разработчика DPU NebulonВ интернете появилась информация о том, что компания NVIDIA, возможно, заключила сделку по поглощению стартапа Nebulon — разработчика специализированных ускорителей SPU (Services Processing Unit) и одного из пионеров концепции DPU. По имеющимся данным, сумма сделки могла составить около $15 млн. На текущий момент стороны официальные комментарии не дают. Фирма Nebulon, основанная в 2018 году, создала SPU на базе неназванного SoC, которые обеспечивают разгрузку, ускорение и изоляцию широкого спектра процессов, обеспечивающих работу сети, СХД и подсистемы безопасности, включая обнаружение программ-вымогателей. В основе изделий Medusa2 последнего поколения лежат уже DPU NVIDIA BlueField-3. 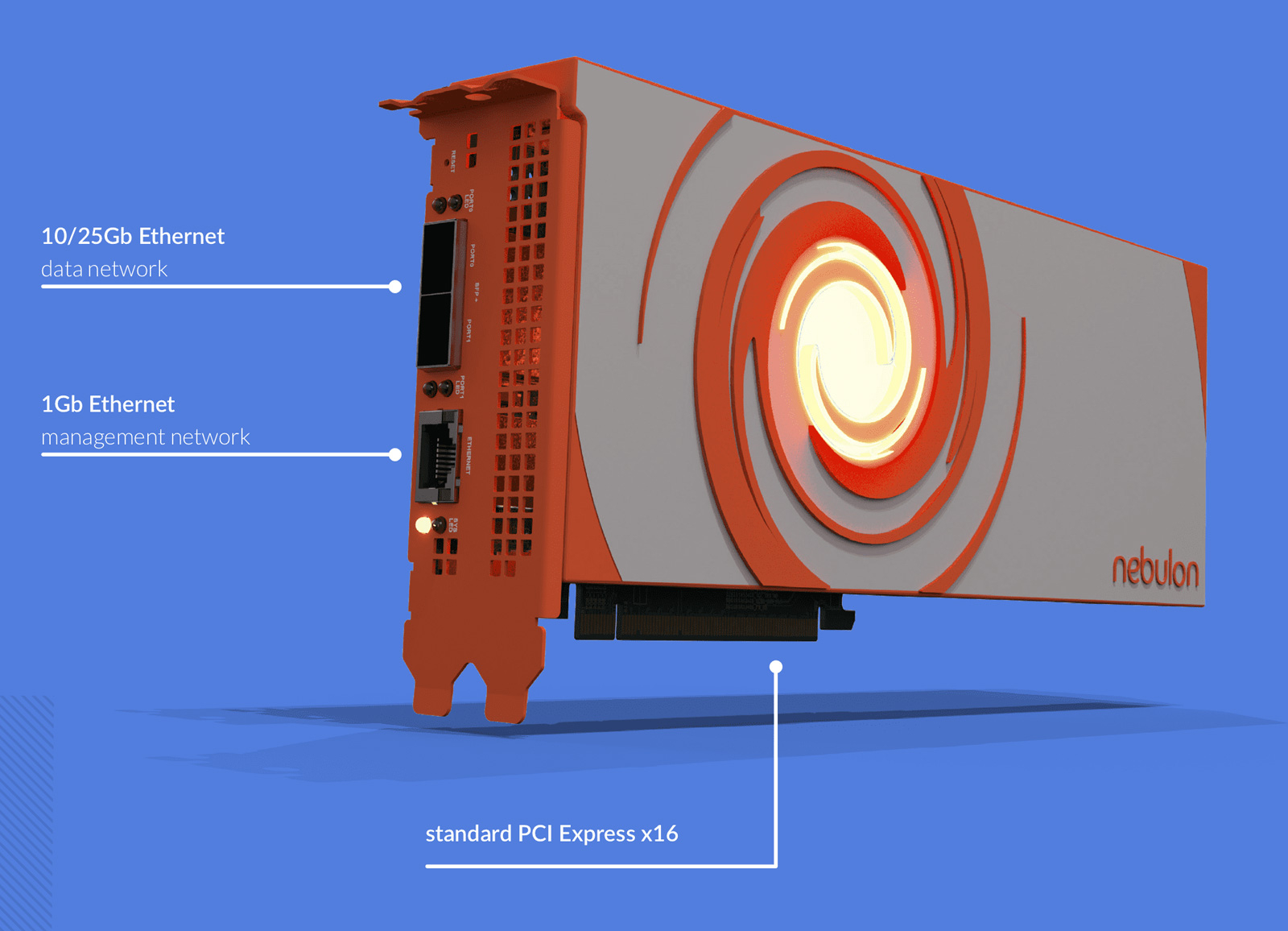
Источник изображения: Nebulon Буквально несколько дней назад, как сообщается, генеральный директор Nebulon Сиамак Назари (Siamak Nazari) на своей странице в соцсети LinkedIn объявил о переходе в NVIDIA. В эту компанию также перешли многие другие инженеры и специалисты стартапа, включая технического директора Nebulon Фила Хукера (Phil Hooker) и руководителя группы облачных вычислений Майкла Мигала (Michael Migal). Отмечается, что в течение некоторого времени 13 февраля при попытке посещения сайта Nebulon происходила переадресация на NVIDIA, однако затем работа ресурса восстановилась. По имеющимся данным, NVIDIA приобрела наработки и часть или же всю команду Nebulon. В 2018-м стартап привлёк $18,3 млн в рамках посевного раунда финансирования и программы Series A. Кроме того, был проведён раунд Series В на неназванную сумму — вероятно, около $5 млн. Однако впоследствии фирма столкнулась с трудностями из-за растущей конкуренции на рынке DPU. Объединив технологии и специалистов Nebulon со своими ресурсами, NVIDIA сможет расширить присутствие на DPU-рынке и предложить более комплексные решения для дата-центров.
28.01.2024 [00:15], Сергей Карасёв
NVMe RAID для начинающих: Graid представила ускоритель SupremeRAID SR-1001 на базе GPU для восьми SSDКомпания Graid Technology анонсировала новый RAID-ускоритель на базе GPU для формирования NVMe-хранилищ. Решение под названием SupremeRAID SR-1001 ориентировано на edge-оборудование, серверы башенного типа, а также на рабочие станции. Новинка представляет собой упрощённую модификацию модели SupremeRAID SR-1000 на базе NVIDIA T1000. Допускается использование до восьми NVMe SSD в четырёх группах (против 32 накопителей у SR-1000). Карта имеет интерфейс PCIe 3.0 х16. Ускоритель допускает формирование массивов RAID 0/1/5/6/10. Величина IOPS (операций ввода/вывода в секунду) при произвольном чтении данных блоками по 4 Кбайт достигает 6 млн, при произвольной записи — 500 тыс. Заявленная скорость последовательного чтения составляет до 80 Гбайт/с, скорость последовательной записи — до 30 Гбайт/с. 
Источник изображения: Graid Карта SupremeRAID SR-1001 имеет однослотовое исполнение. Максимальное энергопотребление — 30 Вт. Применена система активного охлаждения. Заявлена совместимость с широким спектром программных платформ, включая Windows Server 2019/2022, Windows 11, RHEL 9.0/9.1, Ubuntu 22.04 (ядро 5.15), SLES 15 SP2/SP3 (ядро 5.3), Oracle Linux 9.1, Debian 11.6 (ядро 5.10), CentOS 8.5 (ядро 4.18) и др.
09.12.2023 [23:30], Сергей Карасёв
Pliops готовит новый СУБД-ускоритель XDP с удвоенной производительностьюКомпания Pliops в рамках конференции Gartner приоткрыла завесу тайны над ускорителем Extreme Data Processor (XDP) следующего поколения. По заявления разработчика, новинка обеспечит приблизительно двукратное увеличение производительности по сравнению с предшественником. Изделия XDP предназначены для ускорения широкого спектра приложений. Среди них названы реляционные базы данных, разнородные СУБД NoSQL, резидентные базы данных, платформы 5G и IoT, задачи ИИ и машинного обучения, а также другие системы с интенсивным использованием информации. Сервисы XDP Data, работающие на базе ускорителей XDP, как отмечает Pliops, позволяют операторам дата-центров максимизировать инвестиции в свои инфраструктуры благодаря экспоненциальному увеличению производительности и надёжности хранилища, а также улучшению общей эффективности. Утверждается, в частности, что решение XDP-AccelDB обеспечивает десятикратное повышение быстродействия СУБД MongoDB и снижение совокупной стоимости владения до 95 %. 
Источник изображения: Pliops Для администраторов Mongo DB и IT-специалистов платформа Pliops обеспечивает такие преимущества, как оптимизация ёмкости на уровне узла и кластера; экономически эффективная масштабируемость; оптимизация операций с базой данных, включая резервное копирование и восстановление; инфраструктура, отвечающая требованиям приложений и производительности. Ускорители Pliops XDP для MongoDB станут доступны в I квартале 2024 года. Компания Pliops также сообщила о сотрудничестве с Lenovo по выводу на рынок новых решений для работы с данными.
08.12.2023 [16:17], Сергей Карасёв
Marvell представила новые DPU серии Octeon 10Компания Marvell расширила семейство чипов Octeon 10, анонсировав изделия CN102 и CN103, которые относятся к классу DPU (Data Processing Unit). Новинки предназначены для построения высокопроизводительного сетевого оборудования, в частности, брандмауэров, маршрутизаторов, устройств SD-WAN, малых сот 5G, коммутаторов и пр. Представленные чипы объединяют до восьми 64-битных ядер Arm Neoverse N2 с частотой до 2,7 ГГц. Объём кеш-памяти L2/L3 составляет 8/16 Мбайт. Заявлена поддержка DDR5-5600 и интерфейсов PCIe 3.0 (у CN102) и PCIe 5.0 (только CN103). Изделия производятся по 5-нм техпроцессу. Утверждается, что они обеспечивают в три раза более высокую производительность по сравнению с решениями Marvell DPU предыдущего поколения при одновременном снижении энергопотребления на 50 % — до 25 Вт. Чипы могут применяться в качестве разгрузочного сопроцессора или в качестве основного процессора в сетевых устройствах. 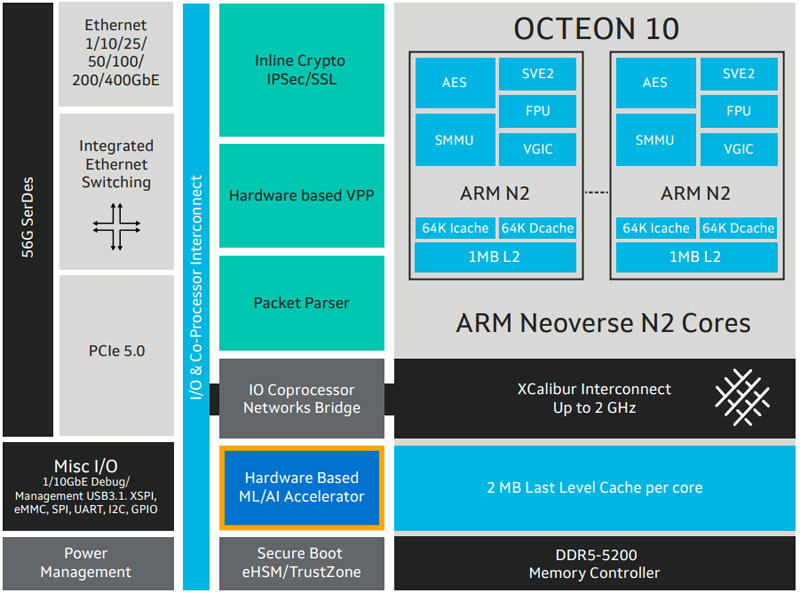
Источник изображения: Marvell Модель CN102 имеет поддержку сетевых портов в следующей конфигурации: 4 × 10GbE + 2 × 10GbE или 16 × 1GbE. У версии CN103 схема такова: 4 × 50/25/10GbE + 2 × 10GbE или 16 × 1GbE. Энергопотребление составляет соответственно 10–20 Вт и 10–25 Вт. Старшая версия получила SerDes-блоки 56G. Среди прочего упомянуты аппаратное ускорение пакетов с оптимизацией VPP, поддержка IPsec и Secure Boot. Показатель SPECint (2017) достигает 37. Поставки образов Octeon 10 CN102 и CN103 уже начались, а массовое производство запланировано на IV квартал 2023-го и на I четверть 2024 года соответственно.
26.11.2023 [22:48], Сергей Карасёв
Nebulon представила ускорители Medusa2 на базе DPU NVIDIA BlueField-3Компания Nebulon анонсировала специализированные ускорители обработки сервисов (Services Processing Unit, SPU) — устройства серии Medusa2. Эти решения обеспечивают разгрузку, ускорение и изоляцию широкого спектра процессов в работе сети, СХД и подсистемы безопасности, включая обнаружение программ-вымогателей. В основу Medusa2 лёг DPU BlueField-3 разработки NVIDIA с шестнадцатью ядрами Arm Cortex-A78, тогда как первое поколение укорителей, изначально называвшихся Storage Processing Unit, было выполнено на собственной аппаратной платформе. Nebulon Medusa2 представляют собой карты расширения с интерфейсом PCIe 5.0 (х8). Они оснащены 48 Гбайт памяти DDR5 с пропускной способностью до 80 Гбайт/с. SPU подключается напрямую к внутренним накопителям NVMe (а также SAS и SATA). Ускорители оснащены двумя сетевыми портами 10/25/50/100GbE и портом управления 1GbE. 
Источник изображения: Nebulon SPU создает на сервере безопасную зону, отделённую от ОС и приложений — область Nebulon Secure Enclave. При этом платформа nebOS разгружает ресурсы, беря на себя выполнение таких задач, как дедупликация и сжатие данных, шифрование (AES), моментальные снимки, зеркалирование и пр. Обеспечена интеграция со средами VMware vSphere, Microsoft Server/Hyper-V и Linux/KVM. Medusa2 SPU не зависит от ОС и приложений и не требует установки каких-либо дополнительных драйверов или программных агентов. Предусмотрен криптографический сопроцессор со сверхзащищенным аппаратным хранилищем ключей и криптографическими контрмерами, которые усиливают защиту от любых потенциальных угроз, связанных с ПО. Например, обнаружение программ-вымогателей осуществляется менее чем за 2,5 мин., а на восстановление после атак таких зловредов требуется менее 4 мин. Реализованы средства безопасной загрузки. В целом, компания сравнивает свои SPU с AWS Nitro. Также анонсирован компактный ускоритель Medusa2i для edge-серверов. Он, как и старший собрат, использует DPU BlueField-3, но количество ядер Cortex-A78 уменьшено до 8, а объём памяти DDR5 — до 24 Гбайт. Возможна установка четырёх SSD формата M.2 вместимостью до 32 Тбайт каждый. Утверждается, что благодаря Medusa2 количество рабочих нагрузок на один сервер может быть увеличено на 33 %, что снижает эксплуатационные расходы и затраты на приобретение лицензий на ПО. При этом требования к мощности и площади дата-центра снижаются на 25 %. Интерес к ускорителям проявили Dell, HPE, Lenovo и Supermicro. |
|

