Материалы по тегу: smartnic
|
23.02.2024 [19:31], Сергей Карасёв
Senao Networks выпустила 25GbE-адаптеры SX904 SmartNIC на базе Xeon DКомпания Senao Networks анонсировала сетевые адаптеры серии SX904 SmartNIC, предназначенные для использования в составе облачных сервисов, edge-платформ, телекоммуникационных инфраструктур и корпоративных дата-центров. В основу новинок положены процессоры Intel Xeon D-1700. Адаптеры призваны снизить нагрузку на CPU серверов при выполнении различных сетевых задач. Это мониторинг трафика и обеспечение безопасности, DPI, шифрование данных, управление политиками с использованием протоколов динамической маршрутизации, организация VPN, приоритизация трафика, SD-WAN, NGFW, ZTNA, а также для OpenBMC. 
Источник изображения: Senao Networks Изделия выполнены в виде однослотовых карт расширения с интерфейсом PCIe 4.0 x8. В зависимости от модификации задействован процессор Xeon D-1713NT (4C/8T; до 3,5 ГГц, 45 Вт), Xeon D-1733NT (8C/16T; до 3,1 ГГц, 53 Вт) или Xeon D-1747NTE (10C/20T; до 3,5 ГГц, 80 Вт). Объём оперативной памяти DDR4-2933 ECC может достигать 32 Гбайт. Адаптеры наделены контроллером Intel Ethernet E810, а также ВМС-чипом AST2600 и модулем PFR (Platform Firmware Resilience) AST1060. Заявлена поддержка TPM 2.0. В оснащение может входить флеш-модуль eMMC вместимостью до 128 Гбайт. Есть два порта 25GbE SFP28, дополнительный разъём 1GbE RJ-45, по одному интерфейсу UART (mini-USB) и USB3.0 Type-A. Габариты составляют 266 × 98,4 × 20,4 мм, масса — около 1,1 кг. Для подачи питания предусмотрен дополнительный 8-контактный коннектор. Диапазон рабочих температур простирается от 0 до +50 °C.
12.03.2023 [14:18], Владимир Мироненко
100GbE и выше: рост популярности ИИ-ботов подстегнёт продажи SmartNIC/DPUРастущая популярность генеративного ИИ и поддержка интеллектуальных функций платформами виртуализации, такими как VMware vSphere, будут способствовать росту продаж боле скоростных сетевых адаптеров Ethernet, считают в аналитической фирме Dell'Oro Group. Согласно прогнозу Dell'Oro Group, к концу 2023 года сетевые адаптеры Ethernet со скоростью 100 Гбит/с или выше будут приносить почти половину всех доходов в этом сегменте, даже несмотря на то, что их доля в продажах сетевых карт составляет менее 20 %. Аналитики утверждают, что бум машинного обучения, отчасти вызванный ажиотажем вокруг ChatGPT, Midjourney и других моделей генеративного ИИ, будет стимулировать спрос на оборудование, обеспечивающее более быструю работу сети. По словам аналитика, поскольку рабочие нагрузки AI/ML часто распределяются между несколькими узлами или даже между несколькими стойками, для них обычно требуется более высокая пропускная способность. Например, ИИ/HPC-платформа NVIDIA DGX H100 оснащена восемью 400G-адаптерами, по одному на каждый из её ускорителей H100. 
Источник изображения: NVIDIA Ожидается, что в этом году SmartNIC будут применяться в большем количестве решений благодаря более широкому распространению программных платформ, способных использовать их преимущества. «Я думаю, что в этом году мы можем получить больше поддержки DPU и SmartNIC. Проекты вроде Project Monterey приносят много преимуществ», — отмечают в Dell'Oro Group. Dell'Oro прогнозирует, что в 2023 году выручка на рынке NIC достигнет двузначного роста, несмотря ожидаемое сокращение поставок на 9 % в годовом исчислении. По словам аналитиков, из-за снижения спроса провайдеры отдают предпочтение оборудованию более высокого класса с более скоростными интерфейсами на 100GbE, 200GbE или даже 400GbE и соответствующей функциональностью, которая обеспечивает более высокую среднюю цену. При этом у дорогих NIC стоимость обработки бита, как правило, ниже. Это означает, что сервер с поддержкой более высокой скорости передачи данных может оказаться дешевле нескольких серверов с установленными более дешёвыми и соответственно более медленными NIC. Аппаратное ускорение в SmartNIC также может позволить клиентам обойтись процессорами более низкого уровня, поскольку в этом случае часть задач адаптер забирает у CPU. Кроме того, поскольку большинство компаний покупают NIC в составе более крупной системы, они могут получить дополнительную экономию в виде скидки если не на сетевую карту, то на DRAM или SSD/HDD.
14.08.2022 [14:50], Владимир Мироненко
SmartNIC будут драйверами роста рынка Ethernet-адаптеров в ближайшие годыСогласно данным исследовательского центра Dell'Oro, SmartNIC будут одним из драйверов роста рынка Ethernet-адаптеров, объём которого, по его прогнозу, достигнет к 2026 году $5 млрд. Скорость подключения продолжит расти и на порты с поддержкой скорости 100 Гбит/с и выше будет приходиться почти половина поставок. В отчёте Dell'Oro «Ethernet Adapter & Smart NIC 5-Year Forecast» за июль 2022 года сообщается, что на SmartNIC будет приходиться растущая доля рынка Ethernet-адаптеров, особенно это относится к гиперескейлерам и сегменту высокопроизводительных приложений. По словам директора по исследованиям Dell'Oro Барона Фунга (Baron Fung), к 2026 году доля SmartNIC составит 38 % всего рынка контроллеров и адаптеров Ethernet. «SmartNIC заменят традиционные сетевые адаптеры для большей части облачной инфраструктуры гиперскейлеров для задач общего назначения и высокопроизводительных рабочих нагрузок», — сказал Фунг, отметив также перспективность использования SmartNIC облачными провайдерами второго эшелона, в корпоративных ЦОД и на телекоммуникационном рынке. SmartNIC позволяют разгрузить хост-систему, переложив на них часть задач, однако они всё ещё дороги, а сети на их основе сложны в реализации. 
Изображение: AMD Доходы от продаж SmartNIC, по прогнозам Dell'Oro, будут расти в течение ближайших пяти лет со среднегодовым темпом роста (CAGR) в 21 %, в то время как для традиционных сетевых адаптеров этот показатель составит 5 %. В Dell'Oro также ожидают, что стоимость высокоскоростных портов будет снижаться, поэтому пять лет около 44 % поставок будут приходиться на порты 100GbE+. Так, в США в течение следующих пяти лет в инфраструктуре основных гиперскейлеров — Amazon, Google, Meta✴ и Microsoft — будут преобладать порты 100GbE и 200GbE.
10.06.2022 [23:31], Алексей Степин
Решения Xilinx и Pensando помогут AMD завоевать рынок ЦОДО грядущих серверных APU MI300, сочетающих архитектуры Zen 4 и CDNA 3, и сразу нескольких сериях процессоров EPYC мы уже рассказали, но на мероприятии Financial Analyst Day 2022 компания поделилась и другими планами относительно серверного рынка, которые весьма обширны. Они включают в себя использование разработок и технологий Xilinx и Pensando. Фактически AMD теперь владеет полным портфолио аппаратных решений для ЦОД и рынка HPC: процессорами EPYC, ускорителями Instinct, SmartNIC и DPU на базе чипов Xilinx и Pensando и, наконец, FPGA всё той же Xilinx. Долгосрочные перспективы рынка ЦОД AMD оценивает в $125 млрд, из них на долю ускорителей приходится $64 млрд, а классические процессоры занимают лишь второе место с $42 млрд; остальное приходится на DPU, SmartNIC и FPGA. 
Источник: AMD Теперь у AMD есть полный спектр «умных» сетевых решений практически для любой задачи, включая сценарии, требующие сверхнизкой латентности. Эту роль берут на себя адаптеры Solarflare. Более универсальные ускорители Xilix Alveo обеспечат поддержку кастомных сетевых функций и блоков ускорения, а также высокую производительность обработки пакетов. Ускорители могут быть перепрограммированы, что потенциально позволит существенно оптимизировать затраты на сетевую инфраструктуру крупных ЦОД. 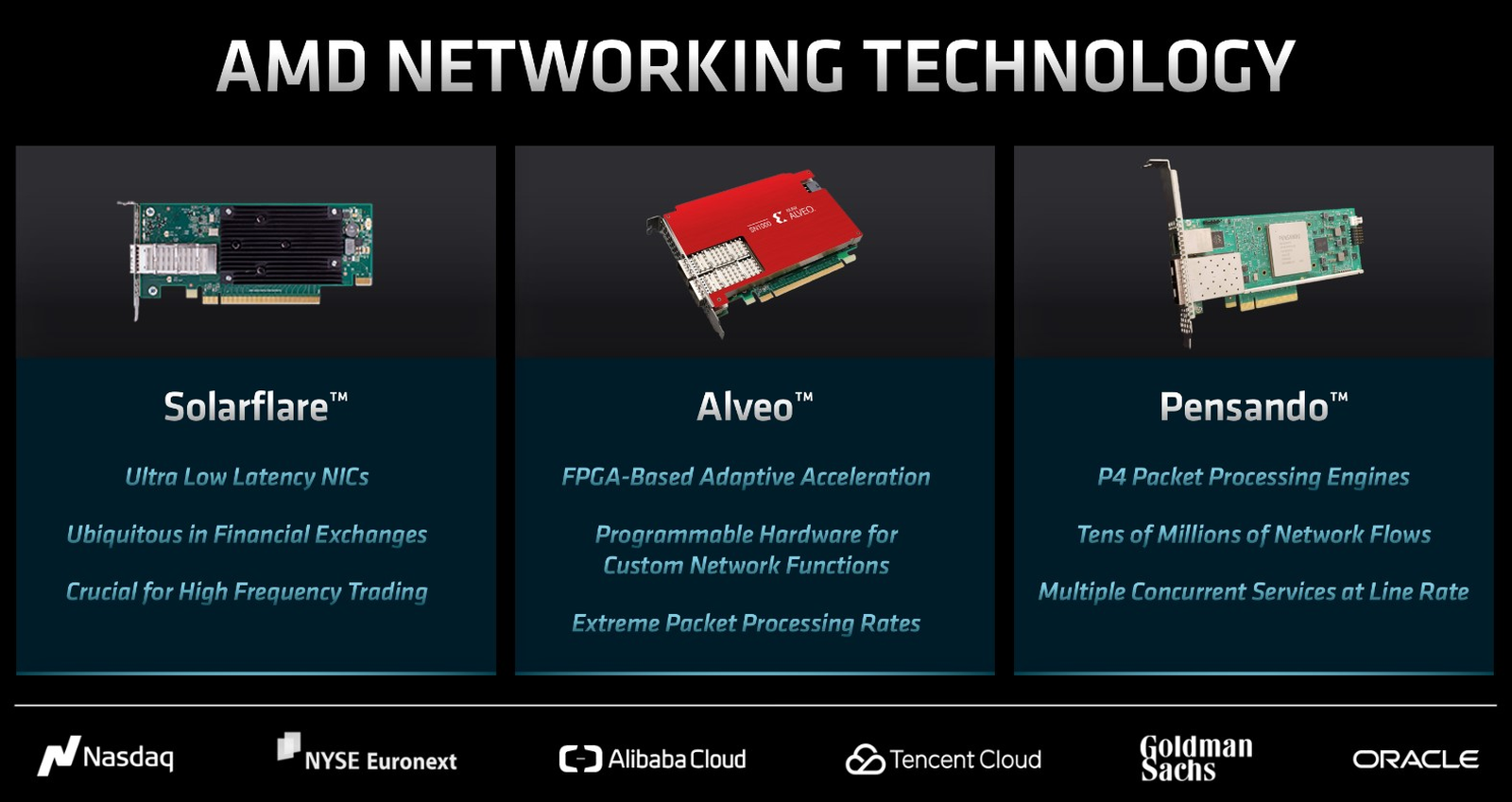
Источник: AMD  Гиперскейлерам они уже поставляются, в текущем виде они имеют до двух 200GbE-портов и совокупную скорость обработки до 400 млн пакетов в секунду. Следующее поколение должно увидеть свет в 2024 году, здесь AMD придерживается двухгодичного цикла. Выпускается и 7-нм DPU Pensando Elba, также предоставляющий пару 200GbE-портов. В отличие от Alveo, это более узкоспециализированное устройство, содержащее 144 P4-программируемых пакетных движка. Помимо них имеются выделенные аппаратные движки ускорения криптографии и сжатия/декомпрессии данных.  Уникальный программно-аппаратный стек Pensando, унаследованный AMD, обеспечивает ряд интересных возможностей, востребованных в крупных системах виртуализации на базе ПО VMware — например, полноценную поддержку виртуализации NVMe, поддержку NVMe-oF/RDMA, в том числе и NVMe/TCP, а также полноценное шифрование и туннели IPSec на полной линейной скорости 100 Гбит/с с временем отклика 3 мкс и джиттером в районе 35 нс. 
Источник: AMD  Разработки Pensando уже используются такими крупными поставщиками сетевого оборудования и СХД, как Aruba (коммутаторы с DPU) и NetApp (системы хранения данных). Таким образом, AMD вполне вправе говорить о том, что современный высокопроизводительный ЦОД может быть целиком построен на базе технологий компании, от процессоров и ускорителей до интерконнекта и специфических акселераторов. 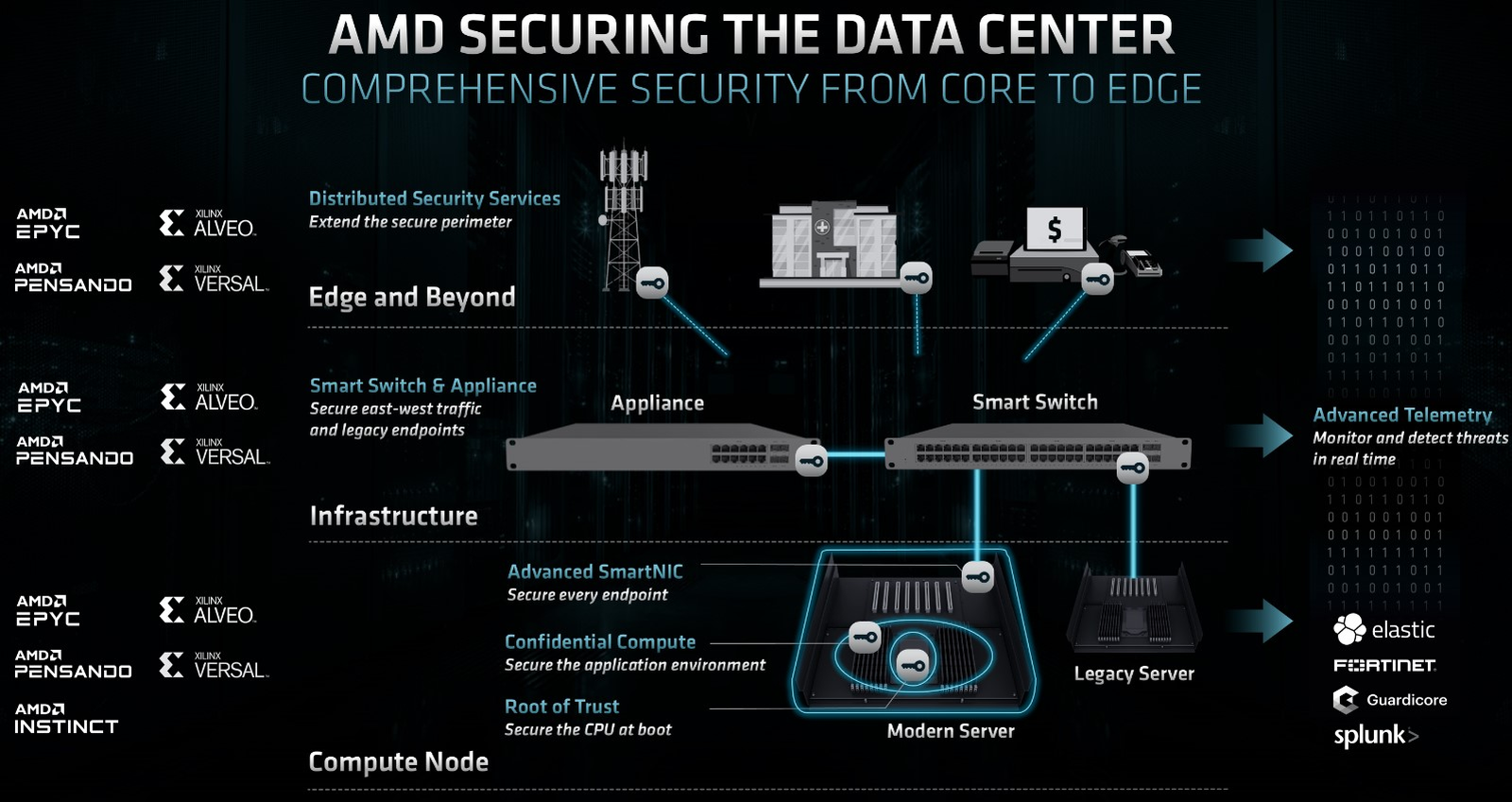
Современный безопасный ЦОД может быть целиком построен на базе технологий AMD. Источник: AMD Поддержка доверенных вычислений, включая полное шифрование содержимого памяти делает такие ЦОД и более безопасными, что немаловажно в современном мире, полном кибер-угроз. В том же направлении движутся NVIDIA BlueField и Intel IPU, а также целый ряд других игроков.
19.08.2021 [18:04], Алексей Степин
Intel представила IPU Mount Evans и Oak Springs Canyon, а также ODM-платформу N6000 Arrow CreekВесной Intel анонсировала свои первые DPU (Data Processing Unit), которые она предпочитает называть IPU (Infrastructure Processing Unit), утверждая, что такое именования является более корректным. Впрочем, цели у этого класса устройств, как их не называй, одинаковые — перенос части функций CPU по обслуживанию ряда подсистем на выделенные аппаратные блоки и ускорители. Классическая архитектура серверных систем такова, что при работе с сетью, хранилищем, безопасностью значительная часть нагрузки ложится на плечи центральных процессоров. Это далеко не всегда приемлемо — такая нагрузка может отъедать существенную часть ресурсов CPU, которые могли бы быть использованы более рационально, особенно в современных средах с активным использованием виртуализации, контейнеризации и микросервисов. 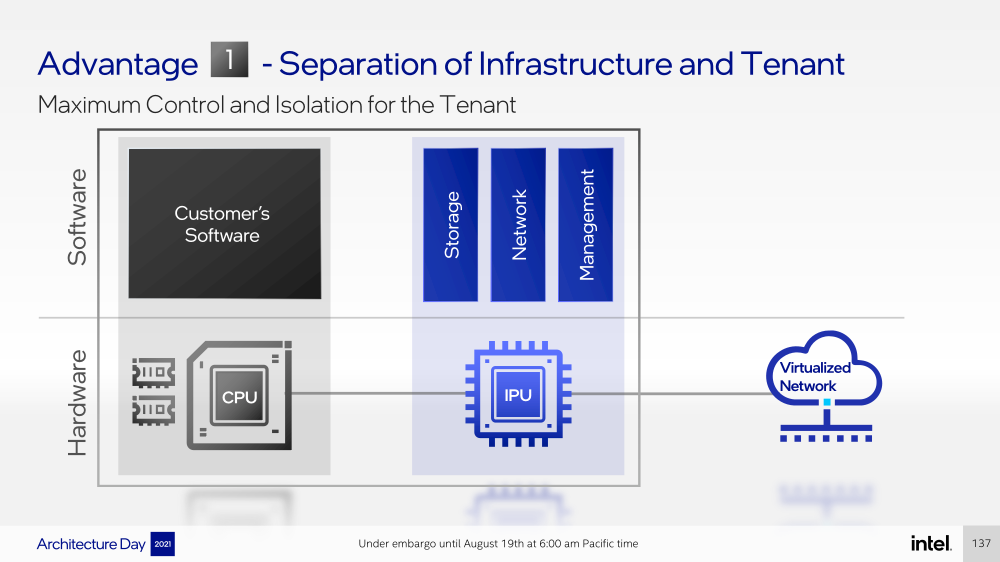 Для решения этой проблемы и были созданы DPU, которые эволюционировали из SmartNIC, бравших на себя «тяжёлые» задачи по обработке трафика и данных. DPU имеют на борту солидный пул вычислительных возможностей, что позволяет на некоторых из них запускать даже гипервизор. Однако Intel IPU имеют свои особенности, отличающие их и от SmartNIC, и от виденных ранее DPU. 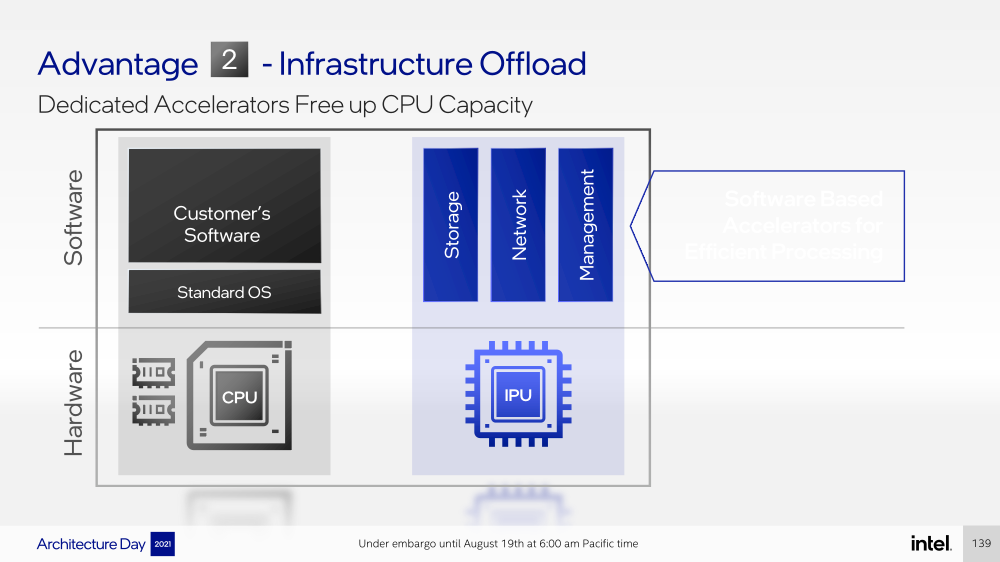 Новый класс сопроцессоров Intel должен взять на себя все заботы по обслуживанию инфраструктуры во всех её проявлениях, будь то работа с сетью, с подсистемами хранения данных или удалённое управление. При этом и DPU, и IPU в отличие от SmartNIC полностью независим от хост-системы. Полное разделение инфраструктуры и гостевых задач обеспечивает дополнительную прослойку безопасности, поскольку аппаратный Root of Trust включён в IPU. 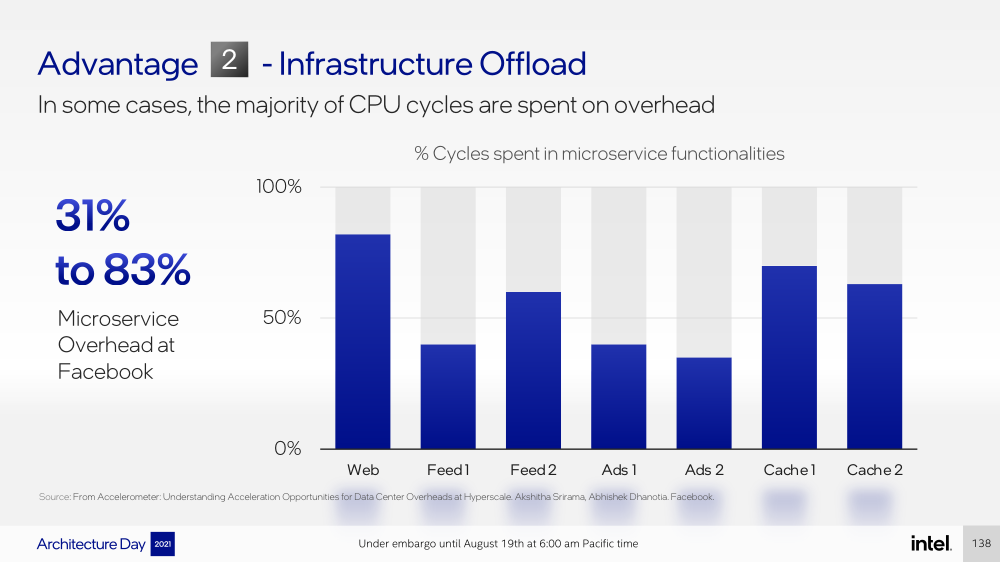 Это не единственное преимущество нового подхода. Компания приводит статистику Facebook✴, из которой видно, что иногда более 50% процессорных тактов серверы тратят на «обслуживание самих себя». Все эти такты могут быть пущены в дело, если за это обслуживание возьмётся IPU. Кроме того, новый класс сетевых ускорителей открывает дорогу к бездисковой серверной инфраструктуре: виртуальные диски создаются и обслуживаются также чипом IPU. 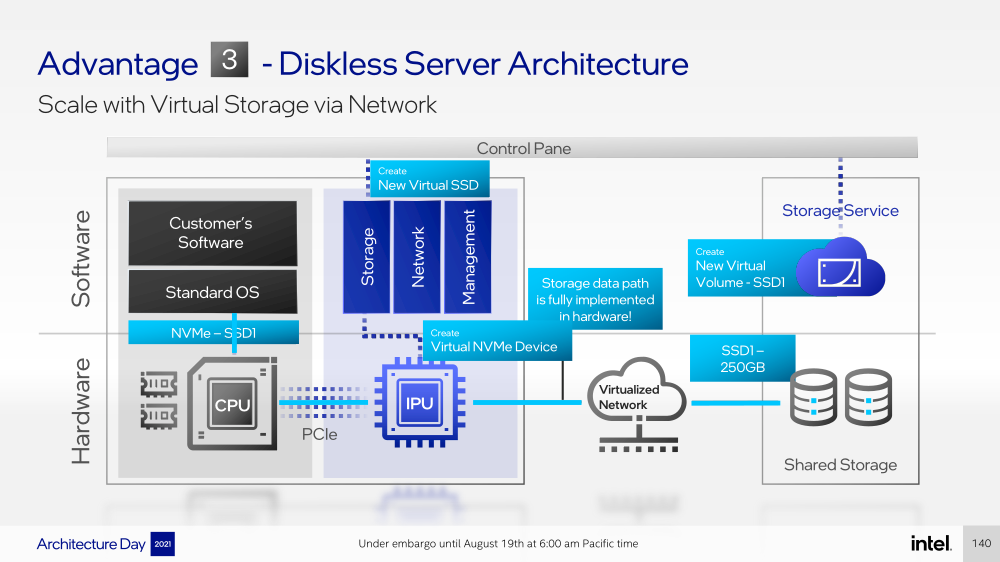 Первый чип в новом семействе IPU, получивший имя Mount Evans, создавался в сотрудничестве с крупными облачными провайдерами. Поэтому в нём широко используется кремний специального назначения (ASIC), обеспечивающий, однако, и нужную степень гибкости, За основу взяты ядра общего назначения Arm Neoverse N1 (до 16 шт.), дополненные тремя банками памяти LPDRR4 и различными ускорителями. 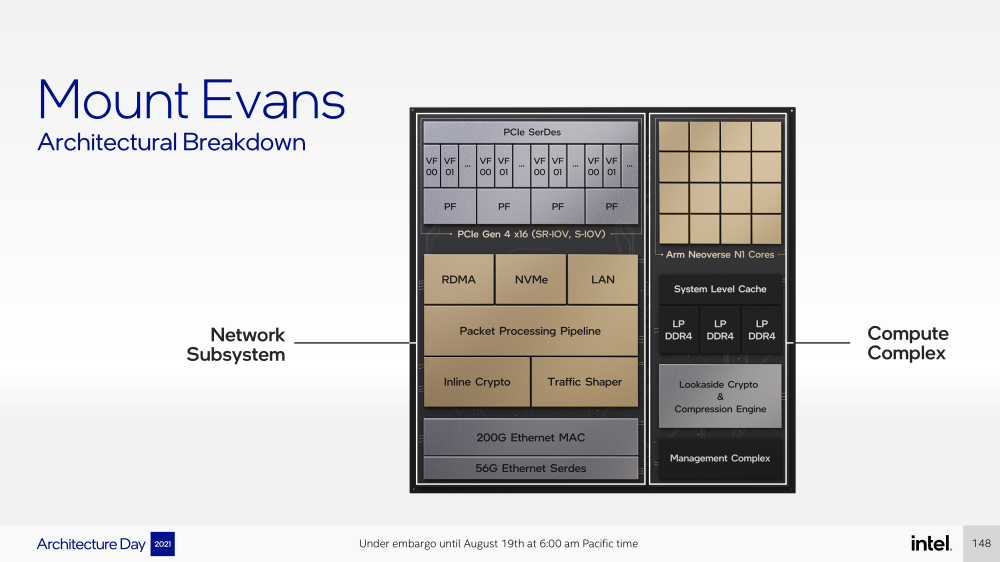 Сетевая часть представлена 200GbE-интерфейсом с выделенным P4-программируемым движком для обработки сетевых пакетов и управления QoS. Дополняет его выделенный IPSec-движок, способный на лету шифровать весь трафик без потери скорости. Естественно, есть поддержка RDMA (RoCEv2) и разгрузки NVMe-oF, причём отличительной чертой является возможность создавать для хоста виртуальные NVMe-накопители — всё благодаря контроллеру, который был позаимствован у Optane SSD.  Дополняют этот комплекс ускорители (де-)компресии и шифрования данных на лету. Они базируются на технологиях Intel QAT и, в частности, предложат поддержку современного алгоритма сжатия Zstandard. Наконец, у IPU будет выделенный блок для независимого внешнего управления. Работать с устройством можно будет посредством привычных SPDK и DPDK. Один IPU Mount Evans может обслуживать до четырёх процессоров. В целом, новинку можно назвать интересной и более доступной альтернативной AWS Nitro.  Также Intel представила платформу Oak Springs Canyon с двумя 100GbE-интерфейсами, которая сочетает процессоры Xeon-D и FPGA семейства Agilex. Каждому чипу которых полагается по 16 Гбайт собственной памяти DDR4. Платформа может использоваться для ускорения Open vSwitch и NVMe-oF с поддержкой RDMA/RocE, имеет аппаратные криптодвижки т.д. Наличие FPGA позволяет выполнять специфичные для конкретного заказчика задачи, но вместе с тем совместимость с x86 существенно упрощает разработку ПО для этой платформы. В дополнение к SPDK и DPDK доступны и инструменты OFS.  Наконец, компания показала и референсную плаформу для разработчиков Intel N6000 Acceleration Development Platform (Arrow Creek). Она несколько отличается от других IPU и относится скорее к SmartNIC, посколько сочетает FPGA Agilex, CPLD Max10 и сетевые контроллеры Intel Ethernet 800 (2 × 100GbE). Дополняет их аппаратный Root of Trust, а также PTP-блок.  Работать с устройством можно также с помощью DPDK и OFS, да и функциональность во многом совпадает с Oak Springs Canyon. Но это всё же платформа для разработки конечных решений ODM-партнёрами Intel, которые могут с её помощью имплементировать какие-то специфические протоколы или функции с ускорением на FPGA, например, SRv6 или Juniper Contrail. IPU могут стать частью высокоинтегрированной ЦОД-платформы Intel, и на этом поле она будет соревноваться в первую очередь с NVIDIA, которая активно продвигает DPU BluefIeld, а вскоре обзаведётся ещё и собственным процессором. Из ближайших интересных анонсов, вероятно, стоит ждать поддержку Project Monterey, о которой уже заявили NVIDIA и Pensando.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 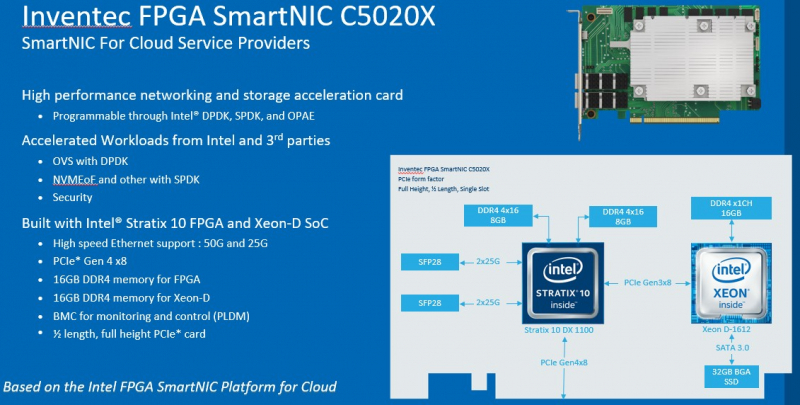 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет. |
|

