Материалы по тегу: cxl
|
11.03.2023 [21:38], Алексей Степин
Intel представила FPGA Agilex 7 с высокоскоростными трансиверами F-TileFPGA остаются популярными как гибкие решения, пригодные для реализации широкого круга задач по ускорению обработки данных. Однако с ростом пропускной способности современных сетей растут соответствующие требования и к FPGA. Ответом на вызовы в этом сегменте стал выпуск новой серии ПЛИС Intel Agilex 7 с самыми быстрыми в мире FPGA трансиверами F-Tile. 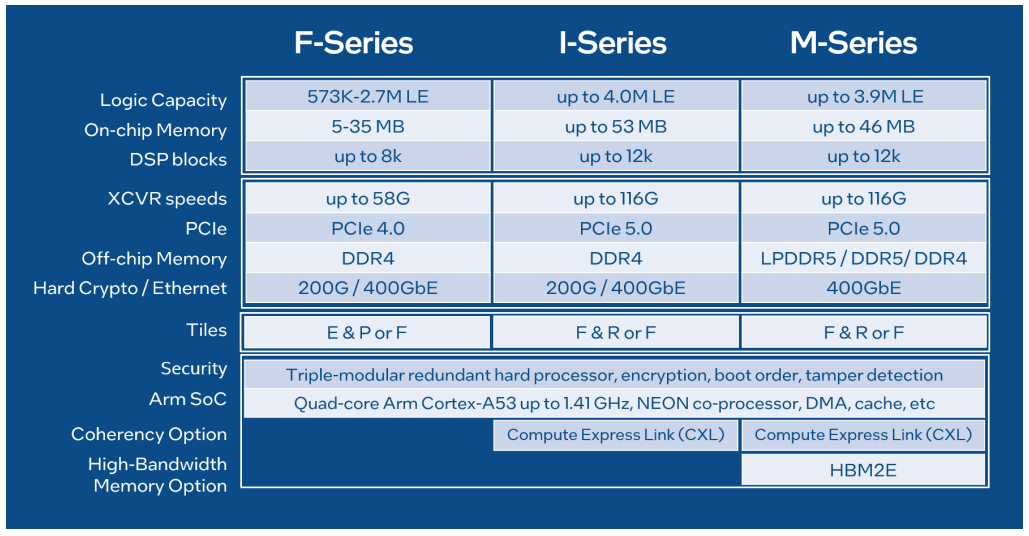
Источник изображений здесь и далее: Intel F-Tile — двухрежимный последовательный интерфейс, предлагающий схемы модуляции PAM4 и NRZ. Он может работать на скоростях до 116 Гбит/с. Также предлагается реализация Ethernet вплоть до 400GbE. Каждый тайл такого типа может содержать до четырёх высокоскоростных каналов FHT с поддержкой PAM4 и до 16 менее скоростных каналов FGT, ограниченных 58 Гбит/с в режиме PAM4 и 32 Гбит/с в режиме NRZ. Количество F-тайлов в составе Agilex 7 зависит от конкретной модели чипа. Наличие столь высокопроизводительных трансиверов в составе Agilex 7 делает новые ПЛИС Intel отлично подходящими для поддержки высокоскоростных сетей (в качестве DPU), в том числе беспроводных, или для ИИ-ускорителей. Производительностью Agilex 7 не обделены — для старшей серии M говорится о 38 Тфлопс, правда, в режиме FP16. 
Базируются новые ПЛИС на уже не слишком новом 10-нм техпроцессе Intel 7 Enhanced SuperFin, и в старшей серии M могут предоставить в распоряжение разработчику 3,85 млн логических элементов, 12300 блоков DSP и 370 Мбайт быстрой интегрированной памяти, а также до 32 Гбайт памяти в HBM2e-сборках. Также в составе присутствует квартет ядер Arm Cortex-A53. Agilex 7 поддерживают интерфейс PCI Express 5.0 и CXL 1.1 (посредством R-Tile). 
Таким образом, программируемые матрицы Intel Agilex 7 благодаря сочетанию быстрых трансиверов и интерфейсов HBM2e и LPDDR5 найдут применение в любых сценариях, где требуется обработка существенных массивов данных: в периферийных системах первичной обработки данных, решениях искусственного интеллекта, при развёртывании сетей 5G и даже в сфере HPC.
19.02.2023 [20:34], Алексей Степин
SNIA представила стандарт Smart Data Accelerator Interface 1.0В связи с активным развитием всевозможных ускорителей и новых подходов к работе с памятью острее встаёт вопрос стандартизации процедур перемещения крупных объёмов данных между подобными устройствами. Консорциум SNIA предлагает в качестве решения новый стандарт Smart Data Accelerator Interface (SDXI), призванный заменить устоявшиеся методы работы с памятью, равно как и всевозможные проприетарные DMA-движки. На днях SNIA опубликовала первые «чистовые» спецификации SDXI, имеющие версию 1.0. В них описывается следующий набор возможностей:
Также следует отметить, что SDXI изначально разрабатывается, как технология, не зависящая от конкретных технологий интерконнекта, но изначально во многом подразумевается использование CXL. 
SDXI упрощает процедуру перемещения содержимого памяти и поддерживает многоуровневые пулы (Изображения: SNIA) 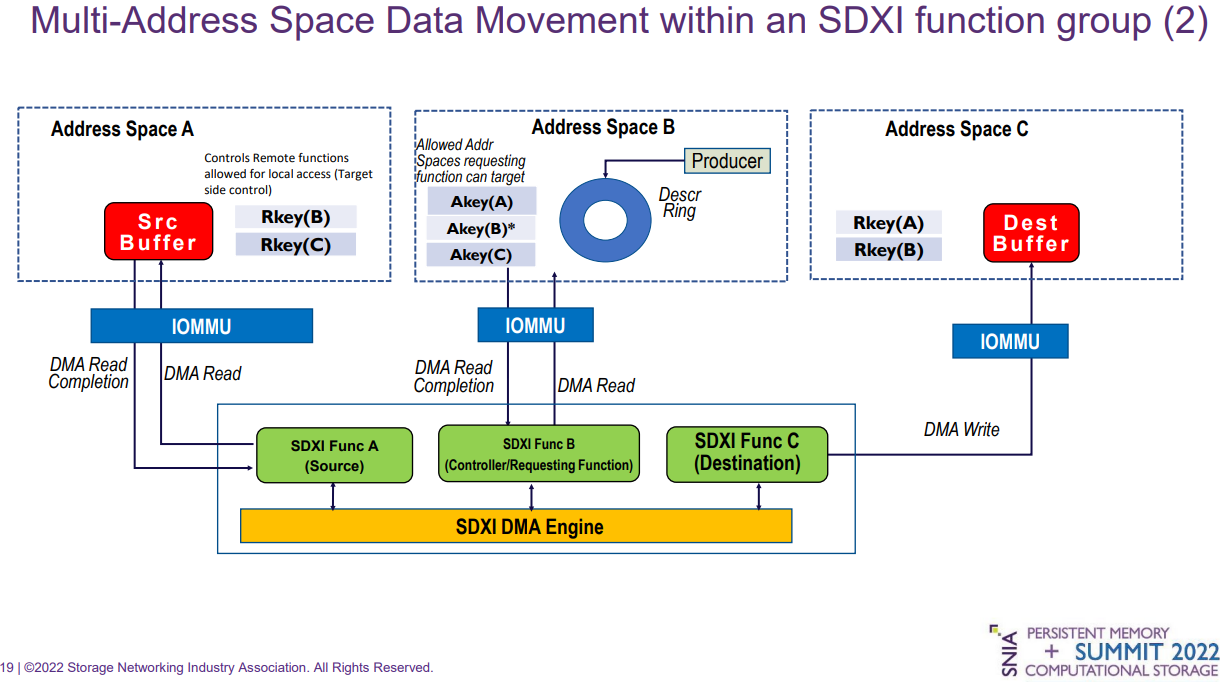
Поддержка DMA гарантирует высокую производительность механизмов SDXI Стандарт SDXI находится в разработке с сентября 2020 года. Первая публичная предварительная версия за номером 0.9 была опубликована в июле 2021. В настоящее время в состав рабочей группы SNIA SDXI Technical Work Group входят представители 23 компаний. Со спецификациями SDXI 1.0 можно ознакомиться в соответствующем разделе сайта SNIA.
01.02.2023 [18:39], Сергей Карасёв
Astera Labs поможет во внедрении CXL-решенийКомпания Astera Labs сообщила о расширении возможностей своей облачной лаборатории Cloud-Scale Interop Lab с целью обеспечения надёжного тестирования функциональной совместимости между платформой Leo Memory Connectivity Platform и экосистемой решений на базе CXL. «CXL зарекомендовала себя как важнейшая технология соединения памяти в системах, ориентированных на данные. Однако многочисленные варианты использования и быстрорастущая экосистема оказываются серьёзной проблемой для масштабного внедрения решений CXL», — отметил глава Astera Labs. Сообщается, что площадка Cloud-Scale Interop Lab использует комплексный набор стресс-тестов памяти, проверок протокола CXL и измерений электрической надёжности для проверки производительности и совместимости между CPU, контроллерами Leo Smart Memory и различными модулями памяти в реальных сценариях использования. Тестирование охватывает ключевые области — от физического уровня до приложений, включая электрическую составляющую PCIe, память, требования CXL и испытания на уровне всей системы. 
Источник изображения: Astera Labs Добавим, что в августе 2022 года была представлена спецификация CXL 3.0. Поддержку в развитии технологии оказывают Комитет инженеров в области электронных устройств JEDEC, а также некоммерческая организация PCI-SIG (PCI Special Interest Group).
16.01.2023 [22:51], Алексей Степин
Unifabrix: использование CXL повышает эффективность работы многоядерных системИзраильский стартап UnifabriX показал, что разработанный его силами пул Smart Memory Node с поддержкой CXL 3.0 может не только расширять объём доступной системам оперативной памяти, но и повышать эффективность её использования, а также общую производительность серверных платформ. На конференции SC22, прошедшей в конце прошлого года, компания продемонстрировала работу Smart Memory Node в комплексе с несколькими серверами на базе Sapphire Rapids. 
UnifabriX Smart Memory Node. Использование E-EDSFF E3 позволяет легко наращивать объём пула (Источник здесь и далее: Blocks & Files) UnifabriX делает основной упор не на непосредственном увеличении доступного объёма оперативной памяти с помощью CXL, а на том, что эта технология повышает общую пропускную способность подсистемы памяти, что позволяет процессорным ядрам использовать её более эффективно. Как показывает приведённый график, со временем число ядер в современных процессорах активно росло, но доступная каждому ядру ПСП снижалась. 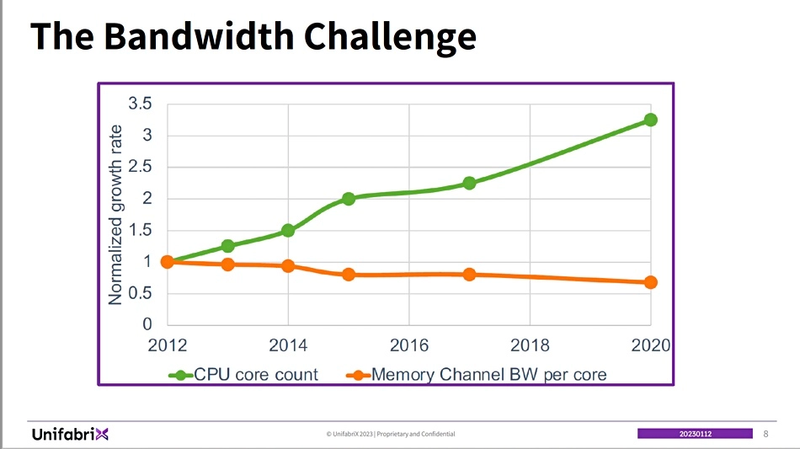
По мере увеличения количества ядер, каждому ядру достаётся всё меньше памяти. На SC22 компания провела тестирование с помощью HPC-бенчмарка HPCG (High Performance Conjugate Gradient), который оценивает не только «голую» производительность вычислений, но и работу с памятью, что не менее важно в современных нагрузках. Без использования пула Smart Memory Node максимальная производительность была достигнута при загрузке процессорных ядер не более 50 %, то есть вычислительные ресурсы у системы ещё были, но для их использования катастрофически не хватало пропускной способности памяти! 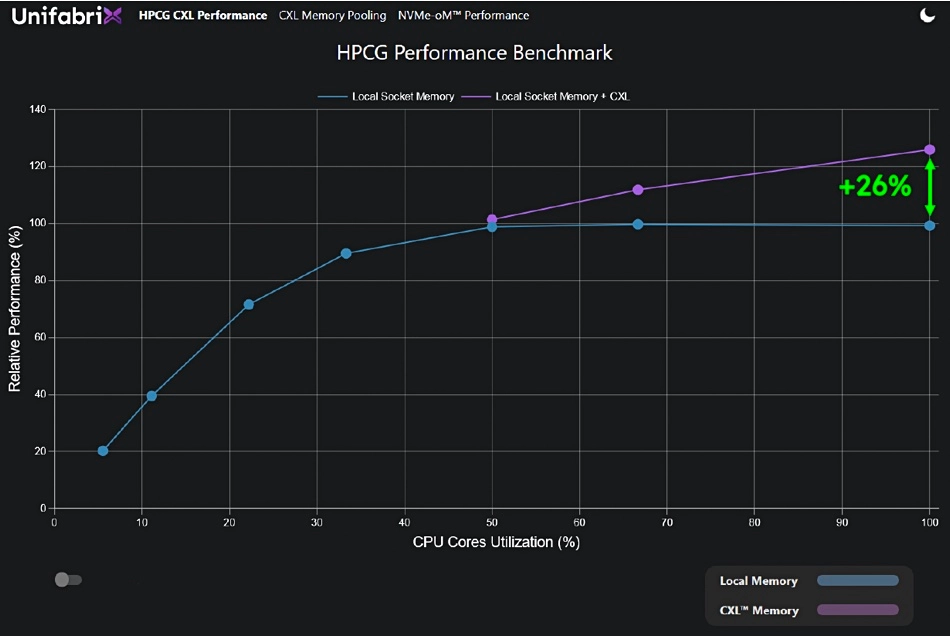
Подключение пулов CXL позволило поднять производительность на 26 %. В реальных сценариях выигрыш может оказаться ещё больше Компания считает, что в случае с такими процессорами, как AMD EPYC Genoa, использование только локальной DRAM выведет систему «на плато» уже при 20 % загрузке. Подключение же пулов Smart Memory Node позволило, как минимум, на 26 % повысить загрузку процессорных ядер, поскольку предоставило в их распоряжение дополнительную пропускную способность. К локальным 300 Гбайт/с, обеспечиваемым DDR5, добавилось ещё 256 Гбайт/с, «прокачиваемых» через PCIe 5.0/CXL. 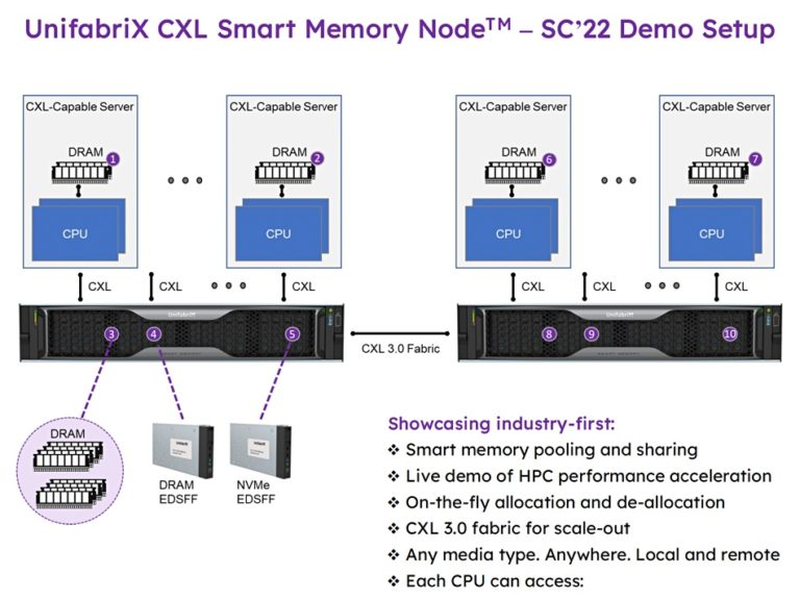
Схема тестовой платформы, показанной на SC22 В тестовом сценарии на SC22 были использованы системы на базе Xeon Max. UnifabriX Smart Memory Node имеет в своём составе сопроцессор RPU (Resource Processing Unit), дополненный фирменным ПО. Устройство использует модули EDSFF E3 (такие есть у Samsung и SK hynix), максимальная совокупная ёмкость памяти может достигать 128 Тбайт. UnifabriX умеет отслеживать загрузку каналов памяти каждого процессора из подключённых к нему систем, и в случае обнаружения нехватки ПСП перенаправляет дополнительные ресурсы туда, где они востребованы. Каждое такое устройство оснащено 10 портами CXL/PCIe 5.0. 
Smart Memory Node имеет 10 портов CXL, совместимых с PCI Express 5.0/6.0 Таким образом, UnifabriX наглядно указала на основное узкое место современных NUMA-систем и показала, что использование CXL позволяет обойти накладываемые ограничения и использовать многоядерные комплексы более эффективно. Речь идёт как об обеспечении каждого ядра в системе дополнительной ПСП, так и о повышении эффективности подсистем хранения данных, ведь один пул Smart Memory Node может содержать 128 Тбайт данных.
15.01.2023 [01:54], Алексей Степин
MemVerge наделила Memory Machine поддержкой Sapphire RapidsПроизводители серверного оборудования и разработчики специализированного программного обеспечения один за другим объявляют о поддержке новых процессоров Xeon Sapphire Rapids. Компания MemVerge, известная своей технологией виртуализации массивов памяти Memory Machine, заявила, что её разработка станет первой в своём роде программной платформой для разработки CXL-решений, поддерживающей новые Xeon. Эти процессоры обладают рядом интересных возможностей, делающих их привлекательными в качестве новой серверной платформы. В частности, это поддержка DDR5, PCI Express 5.0, а также наличие специфических ускорителей, в частности, Data Streaming Accelerator (DSA), ускоряющего процессы перемещения данных между ядрами, кешами, подсистемами хранения данных и сетью. 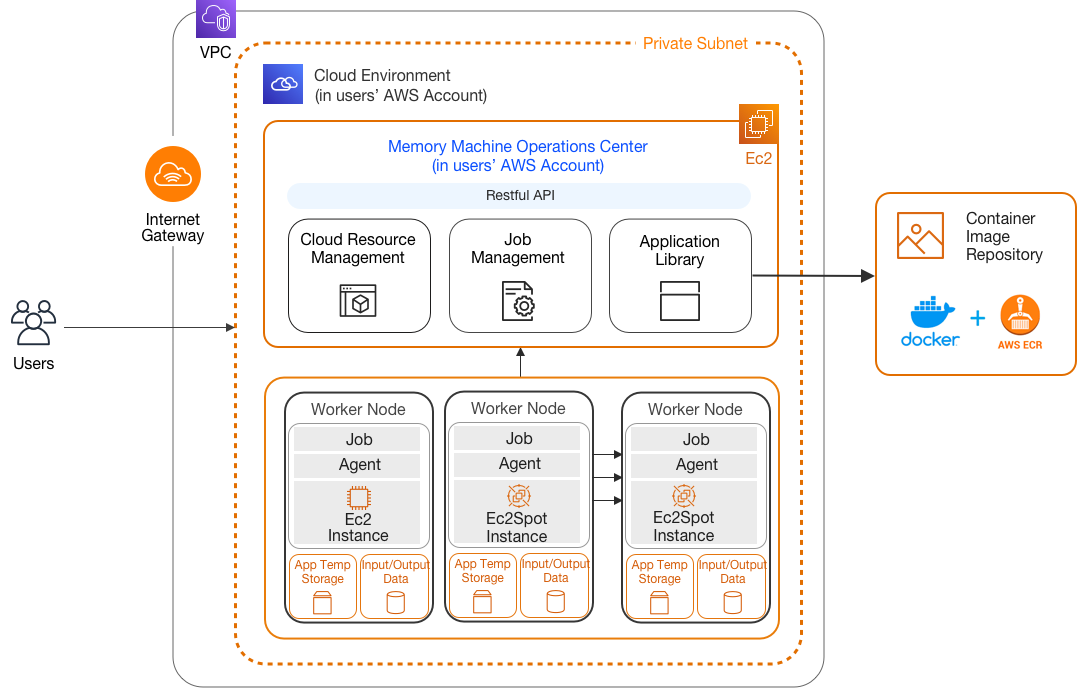
Архитектура платформы MemVerge Memory Machine. Источник: MemVerge С учётом поддержки CXL выбор MemVerge понятен: компания одной из первых поддержала инициативу, разработав унифицированное средство для виртуализации крупных массивов RAM, включая гибридные. Memory Machine позволяет создавать единое когерентное пространство памяти, включающее в себя как локальные ресурсы каждого процессора, так и CXL-экспандеры. Memory Viewer Demo Напомним, что программно-определяемая платформа MemVerge работает полностью прозрачно для пользовательского ПО, вне зависимости от того, использует ли массив памяти из DRAM или же является гибридным и включает в себя CXL-модули. При этом наиболее востребованные данные автоматически размещаются в самом производительном сегменте пула Memory Machine. Также компания объявила о поддержке новых процессоров инструментарием Memory Viewer, помогающего определять наилучшее сочетание цены и производительности при расширении памяти посредством CXL-памяти. Компания не без оснований полагает, что сочетание её технологий и платформы Sapphire Rapids идеально для сценариев HPC, в частности, в генетических исследованиях при секвенировании геномов.
26.10.2022 [12:43], Сергей Карасёв
Rambus представила блоки PCIe 6.0 для серверных чиповКомпания Rambus сообщила о доступности своих решений PCI Express (PCIe) 6.0, которые ориентированы на серверные SoC, а также ИИ-чипы. Анонсированное решение включает микросхему PHY и контроллер. ИнтерфейсRambus PCIe 6.0, как утверждается, полностью оптимизирован для удовлетворения потребностей гетерогенных вычислительных архитектур. Упомянута поддержка CXL 3.0 и обратная совместимость с PCIe 5.0, 4.0 и 3.0/3.1. Контроллер Rambus PCIe 6.0 содержит движок IDE (Integrity and Data Encryption), который осуществляет мониторинг и защиту линий PCIe от физических атак. Реализованы различные механизмы для повышения эффективности работы интерфейса и технология коррекции ошибок FEC. Полная поддержка CXL 3.0 на стороне PHY обеспечивает улучшенные возможности по работе с пулами памяти, продвинутые режимы когерентности, а также многоуровневую коммутацию. 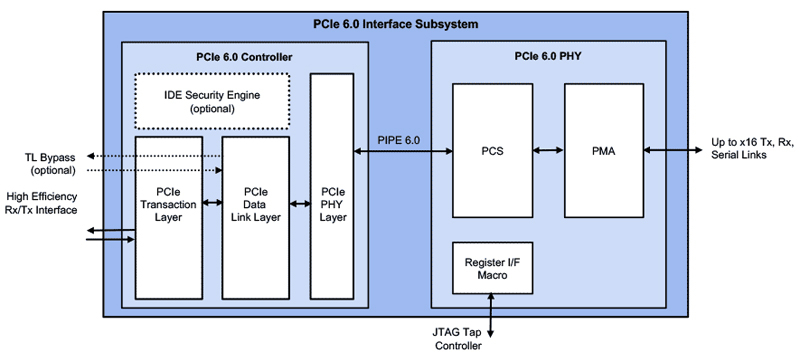
Источник изображения: Rambus «Быстрое развитие ИИ, машинного обучения и нагрузок с интенсивным использованием данных стимулирует непрерывную эволюцию архитектур ЦОД, для которых необходима всё более высокая производительность. Подсистема Rambus PCIe 6.0 способна удовлетворить потребности дата-центров следующего поколения в плане задержек, мощности, занимаемой площади и безопасности», — заявляет Rambus.
25.10.2022 [14:28], Сергей Карасёв
В OCP сформирована группа Composable Memory Systems для работы над новыми технологиями памятиОрганизация Open Compute Project Foundation (OCP) объявила о создании группы Composable Memory Systems (CMS), участники которой займутся работой над архитектурами памяти для ЦОД следующего поколения. Отмечается, что исследования в рамках нового проекта формально начались ещё в феврале 2021 года, когда была запущена инициатива Future Technologies — Software Defined Memory (SDM). ОСР отмечает, что по мере внедрения технологий ИИ и машинного обучения растёт востребованность систем с большим объёмом памяти, которая играет важную роль в энергопотреблении, производительности и общей стоимости владения ЦОД. Поэтому необходима разработка новых технологий интерконнекта вроде CXL (Compute Express Link). CXL позволяет избавиться от жёсткой привязки к CPU и вывести дезагрегацию ресурсов для повышения эффективности их использования на новый уровень. 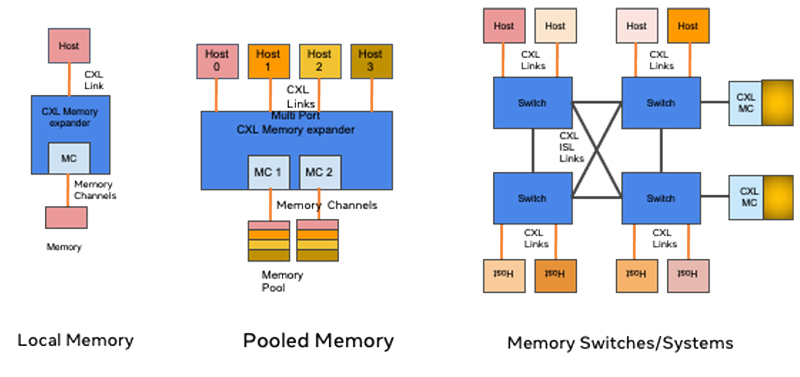
Источник изображения: OCP Проект CMS предусматривает использование стратегии совместной разработки аппаратных и программных решений с целью внедрения технологий многоуровневой и гибридной памяти. Инициатива призвана объединить сообщество операторов ЦОД, разработчиков приложений, производителей оборудования и полупроводниковых изделий для создания архитектуры и номенклатуры, которые будут опубликованы группой в качестве части спецификации компонуемой памяти. Кроме того, будут предложены эталонные тесты. К проекту уже присоединились многие члены ОСР, включая Meta✴, Microsoft, Intel, Micron, Samsung, AMD, VMware, Uber, ARM, SMART Modular, Cisco и MemVerge.
23.10.2022 [00:42], Алексей Степин
Astera Labs представила портфолио решений для CXL-памятиНа саммите OCP 2022 компанией Astera Labs озвучены любопытные цифры: уже к 2025 году 49% данных и 59% всех серверов в мире будут располагаться в публичных облаках. Серьёзную лепту в этот рост привносит рынок ИИ — размеры моделей удваиваются каждые 3,5 месяца, а в денежном выражении объём этого сектора рынка к тому же 2025 году должен превысить $60 млрд. А помочь в развитии подходящих аппаратных инфраструктур, по мнению Astera Labs, может CXL. Первым достаточно масштабным применением CXL станут системы расширения памяти, которые полезны уже в системах с поддержкой лишь CXL 1.1, тогда как создание пулов DRAM потребует CXK 2.0. Однако у Astera Labs уже есть полноценные ASIC для этих задач — решения серий Leo E и Leo P. 
Изображения: Astera Labs Leo E представляет собой экспандер, связующее звено между PCI Express и DDR. На основе этого чипа компания разработала платы расширения Aurora c 8 и 16 линиями CXL на базе чипов CM5082E и CM5162E, соответственно. В отличие от решений некоторых других разработчиков, осваивающих CXL, Astera Labs предлагает не FPGA-реализацию, а полноценную платформу, которую можно использовать в практических целях уже сейчас. 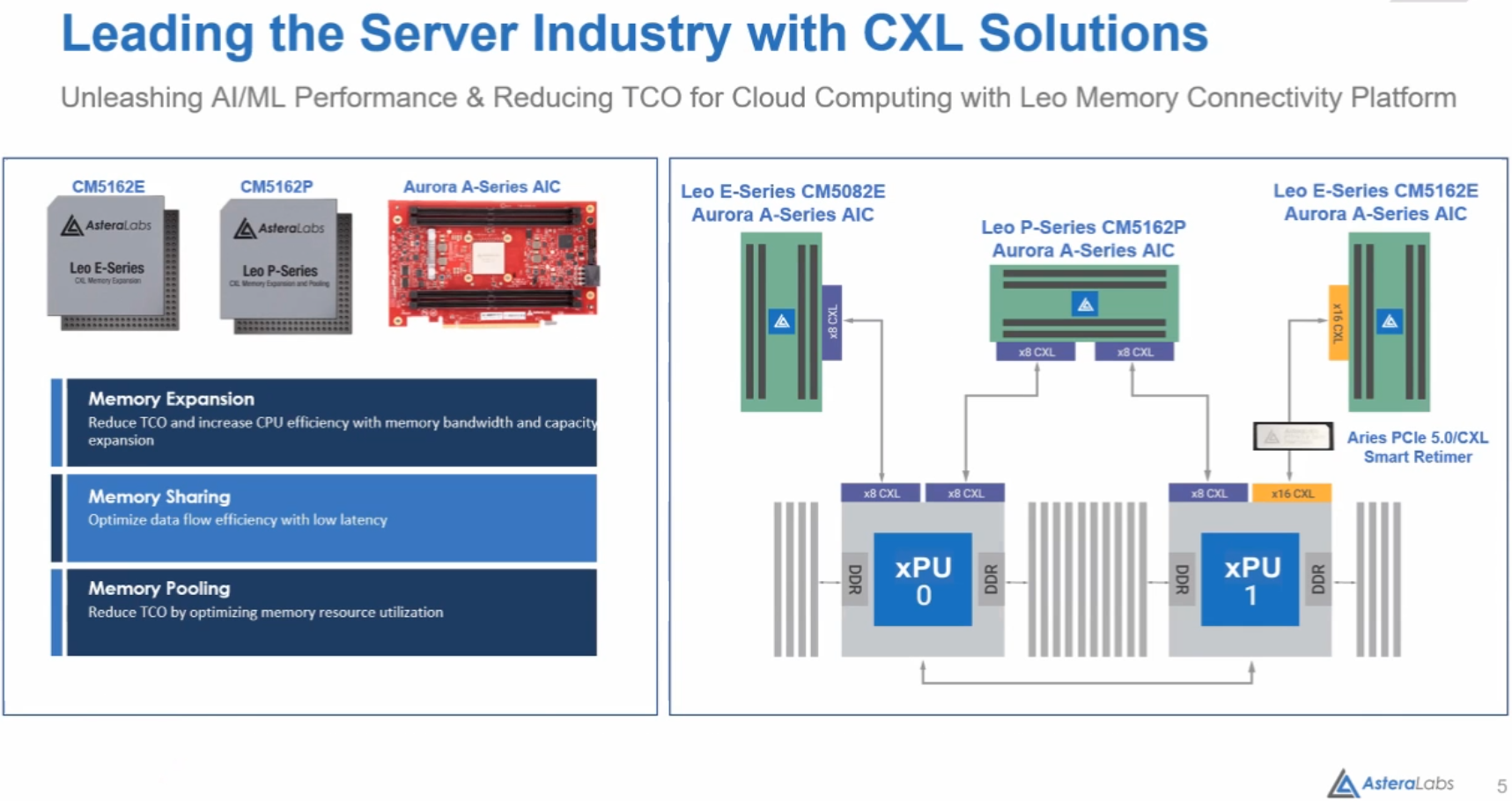 В серии Leo наибольший интерес представляет чип CM5162P — это уже не просто мост между процессором, PCIe и банками DRAM на плате расширения, а полноценное решение для пулинга памяти с поддержкой CXL 2.0. Оно включает в себя контроллеры физических уровней CXL 2.0 и JEDEC DDRx, блоки обеспечения функций безопасности и кастомизации. Контроллеры совместимы с любой стандартной памятью со скоростями до 5600 МТ/с. 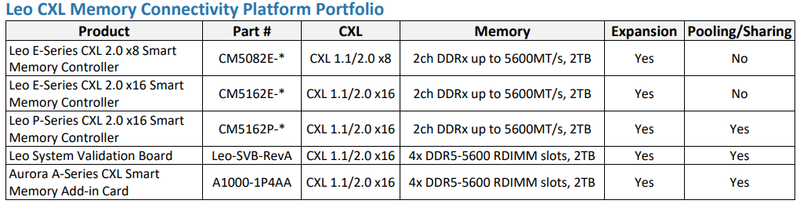 Плата Aurora на базе CM5162P может использовать физический интерфейс PCIe x16 как два интерфейса CXL x8 и, таким образом, общаться одновременно с обоими процессорами в классическом двухпроцессорном сервере. Максимальный объём пула DRAM составляет 2 Тбайт в четырёх модулях DDR5 RDIMM — солидная прибавка к возможностям контроллеров памяти в CPU.  Кроме того, в арсенале компании есть и подходящие ретаймеры серии Aries, совместимые с PCIe 4.0/5.0 и CXL. Эти чипы поддерживают гибкую бифуркацию шины и соответствуют спецификациям Intel PCIe Standard Retimer Footprint. А возможности интегрированных приёмопередатчиков заведомо превышают минимальные требования PCIe Base Specification, что позволяет создавать на базе Aries действительно разветвлённые системы расширения и пулинга DRAM. Таким образом, Astera Labs уже можно назвать одним из пионеров практического освоения рынка CXL-решений: у компании есть законченное портфолио, включающее в себя всё необходимое, от ASIC и ретаймеров до плат расширения, готовых к использованию в ИИ-платформах и облачных системах.
16.10.2022 [00:49], Алексей Степин
TrendForce: производители памяти сфокусируют свои усилия на создании CXL-экспандеровСогласно опубликованному исследовательской компанией TrendForce отчёту, изначальной целью создания CXL было объединение вычислительных ресурсов различных процессоров, сопроцессоров, ускорителей и иных компонентов с целью оптимизации стоимости «больших» систем, кластеров и суперкомпьютеров. Однако пока поддержка этого стандарта остаётся привязана к CPU. Кроме того, Intel Xeon Sapphire Rapids и AMD EPYC Genoa смогут похвастаться только поддержкой CXL 1.1, тогда как как ряд критически важных особенностей, позволяющих достичь вышеупомянутой цели и значительно расширить спектр возможностей CXL, доступен только в версии CXL 2.0. Поэтому основным продуктом на первой стадии внедрения CXL станут экспандеры оперативной памяти (CXL Memory Expander), считает TrendForce. Чипы для CXL-экспандеров уже производят Montage, Marvell, Microchip и некоторыми другими, поэтому массовое внедрение CXL со временем положительно отразится на их прибыли. 
CXL-экспандеры используют PCIe для наращивания объёма памяти. Источник: SK hynix О полноценной дезагрегации, подразумевающей, например, создание выделенных пулов памяти речи в силу ограничений версии 1.1 не идёт. Особой популярности экспандеры памяти в обычных серверах не найдут: если верить исследованию, типовой двухпроцессорный сервер обычно использует 10-12 модулей RDIMM при максимуме в 16 модулей. Таким образом, реальная востребованность CXL-экспандеров сейчас есть на рынке ИИ и HPC, но на общий рынок DRAM это влияние не окажет. 
CXL-экспандеры, продемонстрированные Корейским институтом передовых технологий (KAIST). Источник: KAIST/CAMELab Тем не менее, в будущем при распространии CXL-пулинга возможно снижение спроса на модули RDIMM. В настоящее время CXL-экспандеры поддерживают DDR5, но их скорость ограничивается возможностями PCI Express 5.0. Полностью потенциал DDR5 можно будет реализовать лишь с распространением PCIe 6.0. Об этом уже упоминалось в материале, посвящённом анонсу спецификаций CXL 3.0. Со временем, тем не менее, основными потребителями CXL-продуктов, как ожидается станут крупные провайдеры облачных услуг и гиперскейлеры. В итоге, приходят к выводу исследователи TrendForce, внедрение CXL позволит переломить ситуацию со стагнацией производительности серверов, а переход к CXL 2.0 — избавиться от узких мест традиционной архитектуры. Такого рода реформа откроет путь новым, ещё более сложным архитектурам, активно использующим различные сопроцессоры и массивные общие пулы памяти. Это, в свою очередь, поспособствует не только к появлению новых сервисов, но и к снижению TCO.
29.08.2022 [18:34], Алексей Степин
AMD представила DPU-платформу 400G Adaptive Exotic SmartNICНа конференция Hot Chips 34 AMD представила новую платформу 400G Adaptive Exotic SmartNIC. В самой концепции формально нет ничего нового, поскольку DPU уже снискали популярность в среде гиперскейлеров, но вариант AMD сочетает достоинства не двух, а трёх миров: классического ASIC, программируемой логики на базе FPGA и Arm-процессора общего назначения. На деле процессор (PSX) новинки AMD устроен ещё интереснее: он делится на два домена. В первом домене имеется шестнадцать ядер Arm Cortex-A78, организованных в четыре кластера по четыре ядра. Сюда же входят аппаратные движки для ускорения TLS 1.3. Второй домен состоит из четырёх ядер Arm Cortex-R52 и различных контроллеров низкоскоростных шин, таких как UART, USB 2.0, I2C/I3C, SPI, MIO и прочих. 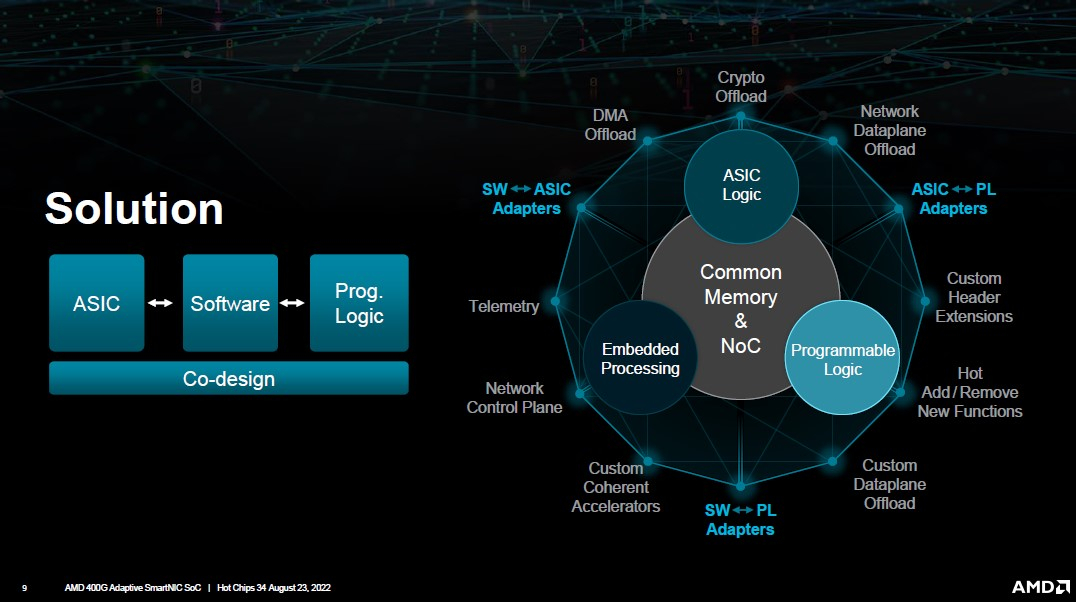
Изображения: AMD (via ServeTheHome) Посредством высокоскоростной программируемой внутренней шины блок PSX соединён с другими компонентами: модулем взаимодействия с хост-системой (CPM5N), подсистемой памяти, сетевым модулем HNICX и блоком программируемой логики. CPM5N реализует поддержку PCIe 5.0/CXL 2.0, причём доступен режим работы в качестве корневого (root) комплекса PCIe. Тут же находится настраиваемый DMA-движок. 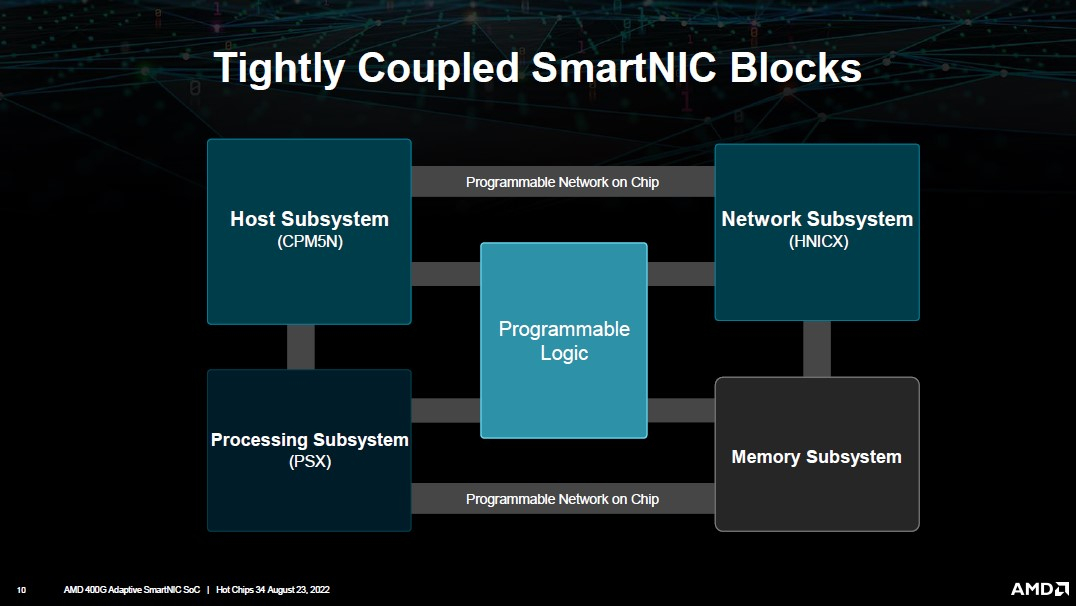 Блок фиксированных сетевых функций представляет собой классический ASIC, обслуживающий пару портов 200GbE. Подсистема памяти представлена 8 каналами DDR5/LPDDR5 с поддержкой 32-бит DDR5-5600 ECC или 160-бит LPDDR5-6400, но говорится и совместимости с другими вариантами памяти, в то числе SCM. Здесь же имеется блок шифрования содержимого памяти с поддержкой стандартов AES-GCM/AES-XTS. 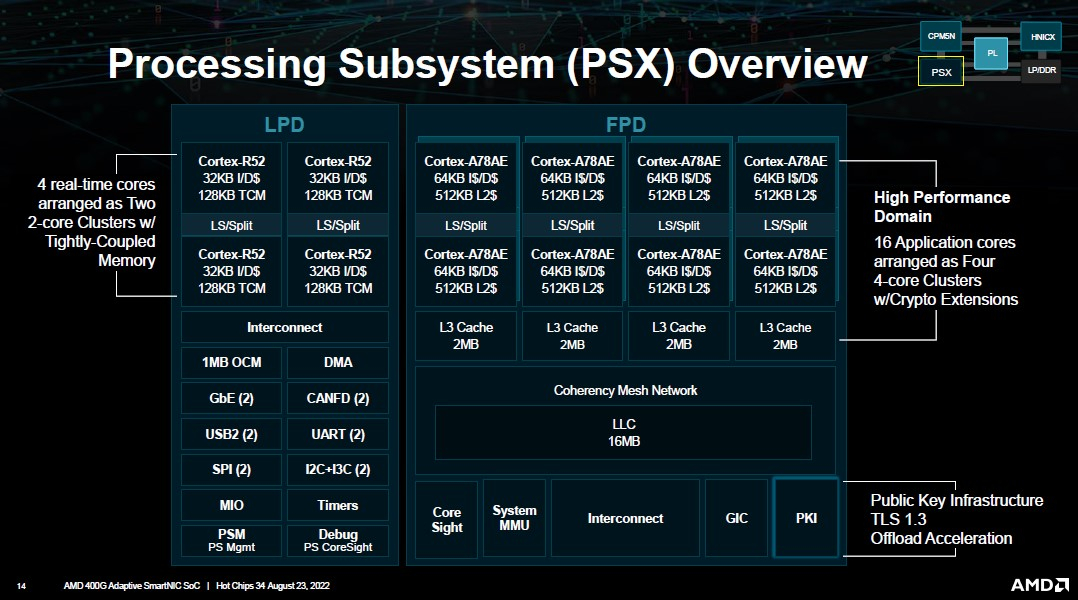 400G Adaptive Exotic SmartNIC имеет развитую поддержку VirtIO и OVS. Также поддерживается виртуализация NVMe-устройств, тоже с шифрованием. Особое внимание AMD уделила тесному взаимодействию всех частей Adaptive Exotic SmartNIC: наличие выделенных линков между блоками хост-контроллера, PSX и FPGA обеспечивает работу на полной скорости в средах, действительно требующих прокачки данных на скоростях в районе 400 Гбит/с. 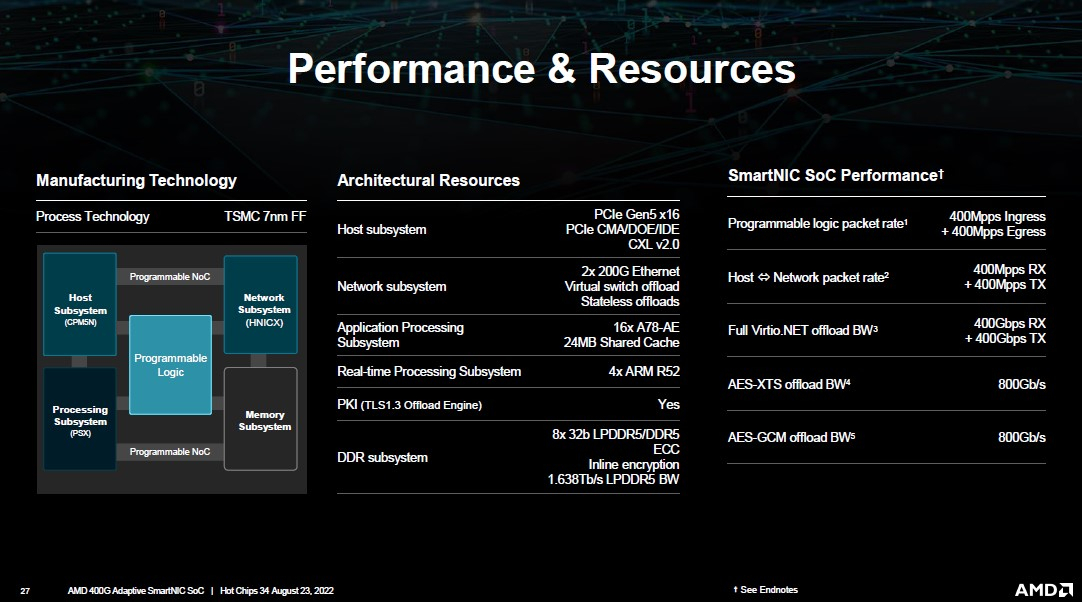 Благодаря наличию FPGA-части 400G новинка можно легко адаптировать к новым требованиям со стороны заказчиков. В частности, решения на базе ПЛИС Xilinx активно поставляются в Китай, где требования к шифрованию существенно отличаются от предъявляемых к аппаратному обеспечению в Европе или США, но наличие блока FPGA позволяет решить эту проблему. У Intel уже есть в сём-то похожая платформа, но более скромная по техническим характеристикам — Oak Springs Canyon (C6000X). |
|

