Лента новостей
|
25.04.2024 [17:25], Владимир Мироненко
Из Git в RuStore: «РеСолют» интегрировала платформу GitFlic с российским магазином приложенийКомпания «РеСолют» (входит в «Группу Астра»), создатель платформы для работы с исходным кодом GitFlic, сообщила о разработке механизма, который обеспечит разработчикам приложений для RuStore возможность использования репозитория GitFlic для хранения, распространения кода и сборки бинарных пакетов. После сборки приложения будут в автоматическом режиме размещаться в магазине RuStore, используя авторизацию через API. Как сообщает компания, в настоящее время на GitFlic опубликованы все SDK для работы с RuStore. Зарегистрироваться в GitFlic и RuStore можно с помощью VK ID. Технический директор «РеСолют» сообщил, что стратегической целью сервиса, насчитывающего более 40 тыс. разработчиков, является желание стать единым центром взаимодействия для всех российских разработчиков, позволяющим управлять полным жизненным циклом разработки ПО. Сервис имеет необходимые инструменты отечественной разработки, охватывающих ключевые процессы создания и дистрибуции ПО. 
Источник изображения: GitFlic В свою очередь директор по продукту RuStore заявил, что развитие современной инфраструктуры для разработчиков — одна из главных целей RuStore. Он сообщил, что у магазина есть все необходимые SDK, включая популярные инструменты разработки и сервисы продвижения, на которые перешло уже более 1000 компаний. А сотрудничество с GitFlic обеспечит разработчикам возможность комфортной работы с SDK магазина и использования привычных решений для разработки приложений и публикации их в RuStore.
25.04.2024 [17:13], Сергей Карасёв
Вычислительный модуль Raspberry Pi Compute Module 4S получил до 8 Гбайт ОЗУКомпания Raspberry Pi анонсировала три новые модификации вычислительного модуля Compute Module 4S (CM4S), который впервые появился на рынке в 2022 году. Изделие может использоваться для создания всевозможных встраиваемых устройств, промышленного оборудования, систем медицинского мониторинга и пр. Модуль выполнен на архитектуре Raspberry Pi 4 Model B. Основой CM4S служит чип Broadcom BCM2711, который объединяет четыре вычислительных ядра Arm Cortex-A72 (Arm v8) с тактовой частотой 1,5 ГГц, а также блок VideoCore VI с поддержкой OpenGL ES 3.0 и Vulkan 1.1. Возможно декодирование видеоматериалов в формате H.265 (до 4Kp60). 
Источник изображения: Raspberry Pi Оригинальная модель CM4S была укомплектована всего 1 Гбайт оперативной памяти LPDDR4-3200 SDRAM с поддержкой ECC. Новые версии доступны с 2, 4 и 8 Гбайт ОЗУ. Вместимость флеш-чипа eMMC может составлять 8, 16 и 32 Гбайт. Модуль имеет размеры 67,6 × 31,0 мм и соответствует форм-фактору SO-DIMM. Говорится о поддержке следующих интерфейсов: HDMI 2.0 (до 4Kp60), MIPI DSI (2 линии и 4 линии), композитный ТВ-выход (PAL или NTSC), MIPI CSI (2 линии и 4 линии), USB 2.0, GPIO и SDIO 2.0 (только модификация CM4SLite без чипа eMMC). Производить вычислительные модули CM4S планируется как минимум до января 2034 года. Цена составляет от $25 при заказе партиями от 200 штук по программе Raspberry Pi Approved Resellers.
25.04.2024 [17:13], Руслан Авдеев
ЦОД на самообеспечении: Vantage намерена построить в Ирландии за $1 млрд кампус с собственной электростанциейОператор Vantage Data Centers готовится потратить €1 млрд ($1,07 млрд) на новый кампус ЦОД недалеко от Дублина. По данным Datacenter Dynamics, объект DUB1 построят в хабе Profile Park в 15 км к югу от ирландской столицы. Кампус площадью 38 тыс. м2 будет размещён на площадке около 9 га и на первых порах достигнет ёмкости 52 МВт. Первый объект ёмкостью 32 МВт введут в эксплуатацию к концу 2024 года, второй объект ёмкостью 20 МВт появится позднее. В Vantage заявляют, что PUE кампуса будет на уровне 1.2, при этом он практически не станет потреблять воду для охлаждения. На территории DUB1 будут развёрнуты генерирующие мощности на 100 МВА, способные работать с разными видами топлива, в том числе в комбинированных вариантах. Речь в первую очередь о гидрированном растительном масле (HVO) и газе, поставляемом Gas Networks Ireland. Пока в стране фактически действует мораторий на строительство новых ЦОД в Дублине и его ближайших окрестностях, энергетическая компания EirGrid утверждает, что не примет никаких заявок до 2028 года. Правительство подчеркнуло, что не намерено сокращать или ограничивать число ЦОД в стране, но существует проблема энергоснабжения, и ранее в этом месяце появилась информация об ограничении AWS в Ирландии вычислительных мощностей для клиентов. 
Источник изображения: Gregory DALLEAU/unsplash.com Vantage утверждает, что собственная электростанция позволит добиться оптимальной эффективности на фоне ограничений. При этом энергия будет передаваться в случае необходимости в национальную энергосеть — такая схема становится популярной во всём мире. Кроме того, компания намерена использовать растительное масло для своих резервных генераторов вместо дизельного топлива и намерена заключать соглашения о покупке «зелёной» энергии (PPA) у местных генерирующих компаний. По словам Vantage, возведение кампуса окажет благоприятное воздействие и на местное сообщество, поскольку будет привлечено до 1100 рабочих на пике строительных работ, а позже компания создаст 165 рабочих мест для управления ЦОД — в компании обещают быть «хорошим соседом». Строительство ЦОД приветствовали лидеры местного бизнеса, заявив, что компания не только внесёт вклад в местную экономику в виде налогов и рабочих мест, но и обеспечит безопасность данных местным компаниям в ближайшие годы. У Vantage уже имеются европейские кампусы — в Германии (Берлине и Франкфурте), Великобритании (Лондоне и Кардиффе), Италии (Милане), Польше (Варшава), Швейцарии (Цюрих), а также в Южной Африке (Йоханнесбурге). В прошлом году компания закрыла две инвестиционных сделки, предусматривающих вложение на континенте €2,5 млрд ($2,67 млрд) для дальнейшей экспансии. Разрешение на строительство двух зданий, который будут в первую очередь построены на территории DUB1, было выдано ещё в 2021 году. Тем не менее, в прошлом году оператору отказали в разрешении на снос жилого здания для строительства третьего объекта — компания намерена опротестовать решение. Ранее ирландские власти разрешили Microsoft пристроить к её дублинским ЦОД 170-МВт газовую электростанцию.
25.04.2024 [13:15], Сергей Карасёв
Seagate: надёжность HAMR HDD ничуть не хуже, чем у PMR-дисковHDD нового поколения, использующие технологию магнитной записи с подогревом (HAMR), по заявлениям Seagate, по надёжности сопоставимы с обычными накопителями, выполненными по методике перпендикулярной магнитной записи (PMR). Речь идёт об изделиях на платформе Mozaic 3+, которая была официально представлена в начале нынешнего года. Для Mozaic 3+ предусмотрено использование ряда инновационных разработок. Это «сверхрешётчатые» пластины из железоплатинового сплава, плазмонное записывающее устройство, спинтронный считывающий модуль Seagate седьмого поколения и пр. Столь значительное количество нововведений, по мнению некоторых специалистов, могло негативно отразиться на сроке службы устройств. Однако производитель заявляет об обратном. 
Источник изображения: Seagate Согласно тестам Seagate накопители на базе Mozaic 3+ могут похвастаться впечатляющими показателями долговечности: их головки чтения/записи в ходе испытаний обработали свыше 3,2 Пбайт данных за 6000 часов. Утверждается, что это более чем в 20 раз превышает типовую нагрузку на nearline-накопители. Фактически, как отмечается, за последние два года компоненты для HAMR-устройств продемонстрировали рост надёжности примерно на 50 %. Тесты в полевых условиях на выборке из 500+ тыс. накопителей при высоких нагрузках показали, что срок службы головок накопителей HAMR составляет более 7 лет. В большинстве случаев это превышает ожидаемый срок эксплуатации PMR-изделий, который обычно оценивается в 4–5 лет при средних нагрузках. Кроме того, для HDD на базе Mozaic 3+ компания Seagate указывает показатель MTBF (средняя наработка на отказ) на уровне 2,5 млн часов. Это эквивалентно значению для накопителей на базе PMR. Подчёркивается, что в целом решения на основе Mozaic 3+ соответствуют тем же требованиям качества, что и другие продукты Seagate корпоративного класса.
25.04.2024 [12:22], Сергей Карасёв
У Seagate упала квартальная выручка, но компания показала чистую прибыльКомпания Seagate отчиталась о работе в III четверти 2024 финансового года, которая была закрыта 29 марта. Один из крупнейших в мире поставщиков HDD показал смешанные результаты: выручка сократилась, но при этом показана чистая прибыль, тогда как годом ранее были зафиксированы значительные убытки. Продажи Seagate за трёхмесячный период составили $1,66 млрд. Это примерно на 11 % меньше результата за III квартал 2023 финансового года, когда компания получила $1,86 млрд. Чистая прибыль зафиксирована на отметке $25 млн, или 12 центов на одну ценную бумагу. Для сравнения: годом ранее Seagate потеряла $433 млн, что эквивалентно $2,09 на акцию. 
Источник изображения: Seagate В течение квартала Seagate отгрузила накопители суммарной вместимостью 99,1 Эбайт. Это на 16,5 % меньше по сравнению с результатом годичной давности. При этом средняя ёмкость HDD в годовом исчислении поднялась на 7 % — с 8,2 до 8,7 Тбайт. Устройства большой вместимости принесли $1,18 млрд в общем объёме выручки, что на 4,3 % меньше год к году. Около $178 млн пришлось на решения корпоративного класса и SSD, что соответствует спаду на 30,5 %. В начале года отмечено сезонное снижение спроса на определённые продукты, в частности, на HDD для систем видеонаблюдения. Но это снижение частично компенсировано увеличением продаж для облачного сегмента. В IV квартале 2024 финансового года компания рассчитывает показать выручку в размере $1,85 млрд ± $150 млн. Seagate продолжает развивать направление накопителей с технологией HAMR (магнитная запись с подогревом). Говорится, что выпуск устройств с пластинами ёмкостью 4 Тбайт запланирован на II половину 2025 календарного года. Решения HAMR третьего поколения обеспечат объём 5 Тбайт в расчёте на пластину и суммарную вместимость более 50 Тбайт.
25.04.2024 [12:00], Сергей Карасёв
Tesla в течение квартала инвестировала в ИИ-инфраструктуру около $1 млрдКомпания Tesla обнародовала показатели деятельности в I квартале 2024 года. Выручка производителя электромобилей составила $21,3 млрд, что на 9 % меньше результата годичной давности. Предприятие Илона Маска не смогло оправдать ожидания аналитиков, которые называли сумму на уровне $22,34 млрд. Показатели ухудшаются на фоне сокращения продаж автомобилей под давлением китайских конкурентов. Чистая квартальная прибыль Tesla составила $1,13 млрд. Это на 55 % меньше по сравнению с показателем за I четверть 2023-го, когда компания заработала $2,51 млрд. Как отмечает ресурс Datacenter Dynamics, в январе–марте 2024 года Tesla инвестировала в развитие ИИ-инфраструктуры около $1 млрд. По словам Маска, компании удалось преодолеть трудности в плане расширения мощностей для обучения ИИ. На текущий момент Tesla ввела в эксплуатацию ресурсы, эквивалентные по производительности 35 тыс. ускорителей NVIDIA H100. К концу года, согласно заявлениям Маска, этот показатель приблизится к 85 тыс. 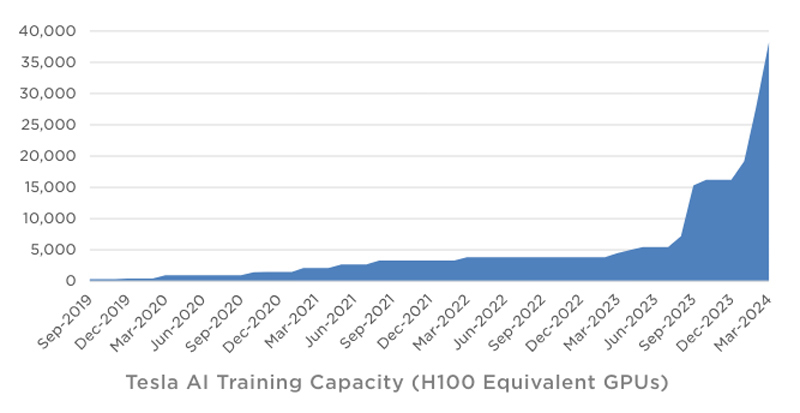
Источник изображения: Tesla Учитывая, что в презентации говорится об «эквиваленте Н100», компания может применять различные ИИ-решения, включая собственные чипы Tesla D1. В целом, Tesla увеличила мощности для обучения ИИ более чем на 130 % в I квартале 2024-го. Ожидается, что суперкомпьютер Dojo поможет увеличить рыночную стоимость Tesla на $500 млрд. Маск также сообщил, что в перспективе электромобили Tesla смогут выполнять функции распределённой edge-платформы для инференса. Идея заключается в том, чтобы задействовать вычислительные мощности автомобилей во время простоя для выполнения задач ИИ. Глава Tesla предлагает представить будущее, в котором по всему миру насчитывается 100 млн электромобилей компании. Каждый из них теоретически может обладать мощностью на уровне 1 кВт, что в сумме даёт 100 ГВт для инференса. Даже с учётом того, что каждая из этих машин будет эксплуатироваться около 7 часов ежедневно, остаётся более 100 часов в неделю для обслуживания ИИ-нагрузок.
25.04.2024 [11:40], Сергей Карасёв
IBM купит HashiCorp за $6,4 млрд для расширения облачных сервисовКорпорация IBM, как и предполагалось, объявила о заключении соглашения по приобретению компании HashiCorp, которая занимается разработкой набора открытых инструментов для управления облачной инфраструктурой. Сумма сделки составит приблизительно $6,4 млрд. По условиям договора, IBM покупает HashiCorp из расчёта $35 за одну ценную бумагу. Это соответствует премии в размере 42,6 % к стоимости акций компании на момент закрытия торгов 22 апреля 2024 года. 
Источник изображения: HashiCorp Отмечается, что продукты HashiCorp позволяют клиентам использовать средства автоматизации для управления жизненным циклом IT-инфраструктуры, а также помогают в формировании гибридных и мультиоблачных сред. При этом компании и организации могут применять облачные ресурсы различных провайдеров, создавая платформу, максимально соответствующую потребностям бизнеса. Для IBM сделка является частью масштабной инициативы, направленной на развитие концепции гибридного облака и повсеместное внедрение инструментов ИИ — это, как утверждается, две «преобразующие технологии». Решения HashiCorp в сочетании с продуктами IBM и Red Hat предоставят клиентам платформу для автоматизации развёртывания и координации рабочих нагрузок в различных инфраструктурах, включая гипермасштабируемые и частные облака, а также локальные среды. Советы директоров обеих сторон уже согласовали сделку. Теперь она должна получить одобрение со стороны акционеров HashiCorp и регулирующих органов. Ожидается, что сделка будет завершена к концу 2024 года.
25.04.2024 [11:38], Сергей Карасёв
Одноплатный компьютер ASRock SBC-262M-WT получил чип Intel Amston Lake и три коннектора M.2Компания ASRock Industrial анонсировала одноплатный компьютер SBC-262M-WT, предназначенный для создания встраиваемых устройств, промышленного оборудования, систем для умного города и пр. Новинка выполнена в 3,5″ форм-факторе с применением аппаратной платформы Intel Amston Lake. На плату установлен процессор Atom x7433RE с четырьмя ядрами (до 3,4 ГГц) и ускорителем Intel UHD Graphics (до 1 ГГц). Показатель TDP равен 9 Вт. Имеется один слот SO-DIMM для модуля оперативной памяти DDR5-4800 объёмом до 48 Гбайт. Накопитель может быть подключен к порту SATA-3. 
Источник изображения: ASRock Industrial Решение располагает коннектором M.2 Key E 2230 (PCIe x1, USB 2.0) для комбинированного адаптера Wi-Fi/Bluetooth, разъёмом M.2 Key B 3042/3052 (PCIe x1, USB 3.2, USB 2.0) для сотового модема 4G/5G (плюс слот для SIM-карты), а также коннектором M.2 Key M 2242/2280 (PCIe x1, SATA-3) для SSD. В оснащение входят сетевые контроллеры 2.5GbE (Intel I226IT) и 1GbE (Intel I210IT), звуковой кодек Realtek ALC256 HD и модуль TPM 2.0 (опционально). В набор разъёмов включены интерфейсы HDMI 2.0b и DisplayPort 1.4b с поддержкой разрешения до 4096 × 2160 пикселей (60 Гц), гнёзда RJ-45 для сетевых кабелей, два порта USB 3.2 Gen2 Type-A и 3-контактный коннектор Phoenix для подачи питания (9–36 В). Через разъёмы на плате можно задействовать четыре последовательных порта и четыре порта USB 2.0. Кроме того, упомянута поддержка интерфейсов LVDS (до 1920 × 1200 точек; 60 Гц) и eDP 1.4b (до 4096 × 2160 пикселей; 60 Гц). Одноплатный компьютер имеет габариты 147 × 102 × 24 мм. Диапазон рабочих температур простирается от -40 до +85 °C.
24.04.2024 [23:45], Владимир Мироненко
NVIDIA приобрела за $700 млн платформу оркестрации ИИ-нагрузок Run:aiКомпания NVIDIA объявила о приобретении стартапа Run:ai из Тель-Авива (Израиль), занимающегося разработкой ПО для управления рабочими нагрузками и оркестрации на базе Kubernetes, которое позволяет более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями. Стоимость сделки не раскрывается. По данным TechCrunch, покупка обошлась NVIDIA в $700 млн. Это одно из крупнейших приобретений Nvidia с момента покупки Mellanox за $6,9 млрд в марте 2019 года. Два года назад NVIDIA купила Bright Computing, разработчика решений для управления НРС-кластерами. NVIDIA отметила, что развёртывание ИИ-приложениЙ становится всё более сложным. Оркестрация генеративного ИИ, рекомендательных и поисковых систем, а также других рабочих нагрузок требует сложного планирования для оптимизации производительности. ПО Run:ai позволяет управлять и оптимизировать вычислительную инфраструктуру как локально, так и в облаке или в гибридных средах. 
Источник изображения: NVIDIA Созданная стартапом открытая платформа поддерживает все популярные варианты Kubernetes и интегрируется со сторонними инструментами и платформами ИИ. Компании из различных отраслей используют платформу Run:ai для управления кластерами ускорителей в масштабе ЦОД. Как сообщается, на относительно раннем этапе деятельности Run:ai удалось создать большую клиентскую базу из компаний из списка Fortune 500, что позволило привлечь венчурные инвестиции. Перед сделкой Run:ai привлекла капитал в размере $118 млн от ряда инвесторов, включая Insight Partners, Tiger Global, S Capital и TLV Partners. NVIDIA заявила, что в ближайшем будущем продолжит предлагать продукты Run:ai в рамках той же бизнес-модели, а также продолжит инвестировать в развитие Run:ai в рамках платформы NVIDIA DGX Cloud, предоставляющей корпоративным клиентам доступ к вычислительной инфраструктуре и ПО для обучения моделей генеративного и других форм ИИ. Решения Run:ai уже интегрированы с NVIDIA DGX, NVIDIA DGX SuperPOD, NVIDIA Base Command, контейнерами NGC, ПО NVIDIA AI Enterprise и другими продуктами. По словам NVIDIA, пользователи серверов и рабочих станций NVIDIA DGX, а также DGX Cloud также получат доступ к возможностям Run:ai, что особенно полезно при развёртывании генеративного ИИ в нескольких ЦОД.
24.04.2024 [20:50], Руслан Авдеев
Китайские телеком-гиганты потратят миллиарды долларов на оптовые закупки ИИ-серверовChina Mobile, одна из ключевых в Китае телеком-компаний, насчитывающая более миллиарда клиентов, намерена приобрести 8 тыс. ИИ-серверов. По информации The Register, представители IT-гиганта рассчитывают, что оборудование заработает до 2025 года. Приобретение планируют разбить на заказы для семи отдельных вендоров. Местные СМИ уже сообщают, что речь идёт о крупнейшей централизованной закупке ИИ-серверов в Китае за всю историю. Общая стоимость оборудования может перевалить за ¥15 млрд — $2 млрд. Причём компания не одинока в своём стремлении обзавестись передовыми аппаратными решениями. Спешно организуют закупки ИИ-серверов на фоне антикитайских санкций и другие телеком-гиганты Поднебесной. China Unicom, по слухам, в прошлом месяце занялась закупками 2,5 тыс. серверов, схожие действия предпринимались и China Telecom. Что именно компании намерены делать с полученными серверами, не уточняется. Впрочем, China Mobile выступает оператором крупного облака, поэтому ИИ-серверы компании безусловно пригодятся. Также не исключено, что бизнес будет использовать ИИ и для обслуживания клиентов, хотя нужно ли для этого такое количество серверов — вопрос отдельный. 
Источник изображения: Kvistholt Photography / Unsplash Главный интерес представляет даже не сфера применения ИИ-ускорителей, а их источники. В Китае пока не создано решений современного мирового уровня и даже передовые модели Huawei серии Ascend не способны на равных тягаться с новейшими решениями NVIDIA. Хотя в теории американские производители ускорителей могут получить от властей США экспортную лицензию, подав заявку в индивидуальном порядке, вряд ли такое разрешение получит подконтрольная государству China Mobile. Более того, она наряду с China Unicom и China Telecom отнесена Пентагоном к «структурам, идентифицированным как китайские военные компании», а санкции США декларировались именно как меры, призванные помешать военным КНР в получении передовых технологий. В числе официально доступных китайским телеком-компаниям вариантов — покупка западных ускорителей с искусственно ухудшенной функциональностью, не подпадающих под санкции. В числе неофициальных — обыкновенная контрабанда или, как ходят слухи, закупка через фирмы-прослойки готовых серверов с уже установленными ускорителями. |
|

