Материалы по тегу: tesla
|
25.04.2024 [12:00], Сергей Карасёв
Tesla в течение квартала инвестировала в ИИ-инфраструктуру около $1 млрдКомпания Tesla обнародовала показатели деятельности в I квартале 2024 года. Выручка производителя электромобилей составила $21,3 млрд, что на 9 % меньше результата годичной давности. Предприятие Илона Маска не смогло оправдать ожидания аналитиков, которые называли сумму на уровне $22,34 млрд. Показатели ухудшаются на фоне сокращения продаж автомобилей под давлением китайских конкурентов. Чистая квартальная прибыль Tesla составила $1,13 млрд. Это на 55 % меньше по сравнению с показателем за I четверть 2023-го, когда компания заработала $2,51 млрд. Как отмечает ресурс Datacenter Dynamics, в январе–марте 2024 года Tesla инвестировала в развитие ИИ-инфраструктуры около $1 млрд. По словам Маска, компании удалось преодолеть трудности в плане расширения мощностей для обучения ИИ. На текущий момент Tesla ввела в эксплуатацию ресурсы, эквивалентные по производительности 35 тыс. ускорителей NVIDIA H100. К концу года, согласно заявлениям Маска, этот показатель приблизится к 85 тыс. 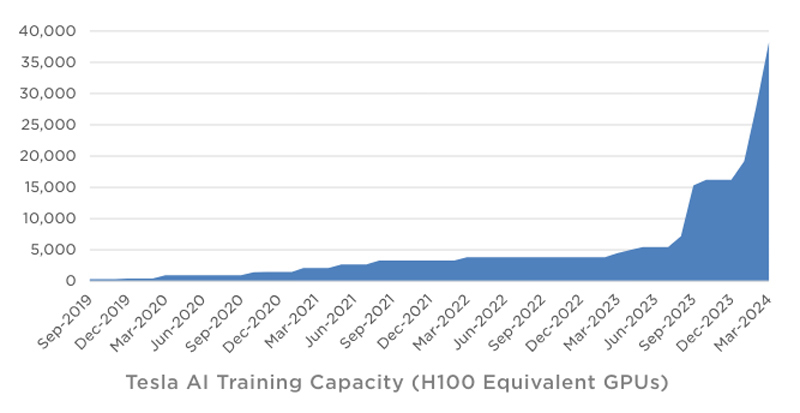
Источник изображения: Tesla Учитывая, что в презентации говорится об «эквиваленте Н100», компания может применять различные ИИ-решения, включая собственные чипы Tesla D1. В целом, Tesla увеличила мощности для обучения ИИ более чем на 130 % в I квартале 2024-го. Ожидается, что суперкомпьютер Dojo поможет увеличить рыночную стоимость Tesla на $500 млрд. Маск также сообщил, что в перспективе электромобили Tesla смогут выполнять функции распределённой edge-платформы для инференса. Идея заключается в том, чтобы задействовать вычислительные мощности автомобилей во время простоя для выполнения задач ИИ. Глава Tesla предлагает представить будущее, в котором по всему миру насчитывается 100 млн электромобилей компании. Каждый из них теоретически может обладать мощностью на уровне 1 кВт, что в сумме даёт 100 ГВт для инференса. Даже с учётом того, что каждая из этих машин будет эксплуатироваться около 7 часов ежедневно, остаётся более 100 часов в неделю для обслуживания ИИ-нагрузок.
19.04.2024 [09:10], Сергей Карасёв
Tesla столкнулась с трудностями при строительстве дата-центра для ИИ-суперкомпьютера DojoКомпания Tesla, по сообщению ресурса The Information, не укладывается в намеченный график строительства ЦОД в Остине (Техас, США), в котором планируется разместить узлы ИИ-суперкомпьютера Dojo стоимостью $1 млрд. Эта площадка будет использоваться для решения сложных задач в области ИИ и машинного обучения, в частности, связанных с системами автопилотирования. К строительству дата-центра, о котором идёт речь, компания Илона Маска приступила в октябре 2023 года. Известно, что по своей конструкции этот ЦОД будет напоминать бункер. Однако, как стало известно, при возведении комплекса Tesla столкнулась с рядом трудностей. В середине апреля Маск посетил строительную площадку и «пришёл в ярость» из-за увиденного. Вопреки ожиданиям, у объекта отсутствуют большая часть первого этажа и крыша. Наблюдаются сложности с доставкой необходимых материалов, из-за чего возникают задержки при строительстве. Кроме того, ситуация усугубляется из-за того, что основанная Маском компания Boring Company должна проложить под площадкой ЦОД туннель для передвижения электрических пикапов Cybertruck, но эти работы не выполнены. Поэтому невозможно полноценное завершение возведения даже первого этажа. 
Источник изображения: Tesla После своего визита Маск уволил директора по строительной инфраструктуре проекта. После этого Tesla сократила более 14 тыс. сотрудников — свыше 10 % от своего штата, насчитывавшего около 140 тыс. человек. Кроме того, компанию покинули несколько топ-менеджеров. О сроках завершения строительства ЦОД в Остине ничего не сообщается. Возникшие задержки, как считается, отражают более широкие проблемы в автомобильной отрасли.
15.10.2023 [01:15], Сергей Карасёв
Бункер для ИИ: Tesla начала строительство дата-центра для суперкомпьютера DojoКомпания Tesla, по сообщению ресурса The Information, приступила к созданию нового ЦОД, в котором в перспективе расположатся узлы суперкомпьютера Dojo. Площадка НРС находится в штаб-квартире Tesla в Остине (Техас, США), но точные сроки её ввода в эксплуатацию не раскрываются. Компания Илона Маска приступила к формированию комплекса Dojo в июле нынешнего года. В основу системы лягут специализированные чипы собственной разработки — Tesla D1. К концу 2024 года, как ожидается, производительность ИИ-систем Tesla может достичь 100 Эфлопс. Стоимость проекта оценивается в $1 млрд. Подробности о дата-центре Tesla в Остине не раскрываются. Отмечается лишь, что по своей конструкции он напоминает бункер. В этом ЦОД будет размещена часть вычислительных модулей Dojo. Суперкомпьютер компания намерена применять для разработки инновационных технологий автопилотирования. Речь идёт о решении ресурсоёмких задач, связанных с ИИ. Кроме того, ранее господин Маск говорил, что некоторые мощности Dojo могут предоставляться сторонним заказчикам по модели облачных услуг. 
Источник изображения: Karpathy / Tesla. По оценкам, запуск Dojo может увеличить рыночную стоимость Tesla на $500 млрд: то есть, капитализация компании поднимется примерно на 60 %. Параллельно Tesla развивает и другие НРС-проекты. Так, недавно компанией был запущен один из мощнейших ИИ-суперкомпьютеров в мире: система с 10 тыс. ускорителей NVIDIA H100 обеспечивает пиковую производительность в 340 Пфлопс FP64 для технических вычислений и 39,58 Эфлопс INT8 для приложений ИИ.
12.09.2023 [13:42], Сергей Карасёв
Суперкомпьютер Dojo может увеличить рыночную стоимость Tesla на $500 млрдАналитики Morgan Stanley, по сообщению Datacenter Dynamics, полагают, что запуск суперкомпьютера Dojo позволит Tesla увеличить свою рыночную стоимость на $500 млрд. Иными словами, капитализация компании Илона Маска может подняться приблизительно на 60 %. Tesla намерена до конца 2024 года потратить на проект Dojo более $1 млрд. Этот вычислительный комплекс поможет в разработке инновационных технологий для роботизированных автомобилей. В составе системы будут применяться чипы собственной разработки Tesla D1. В перспективе производительность Dojo планируется довести до 100 Эфлопс. По состоянию на сентябрь 2023 года рыночная капитализация Tesla составляет около $778 млрд при стоимости ценных бумаг примерно $248. Отмечается, что цена акций компании в течение нынешнего года уже выросла более чем вдвое после снижения в 2022-м. Morgan Stanley прогнозирует, что после ввода системы Dojo в эксплуатацию стоимость ценных бумаг Tesla поднимется примерно на 60 % — до $400. 
Источник изображения: Tesla «Чем больше мы анализировали проект Dojo, тем больше осознавали потенциальную возможность недооценки акций Tesla», — сказал аналитик Morgan Stanley Адам Джонас (Adam Jonas). Предполагается, что Dojo поможет ускорить развитие технологий автопилотирования, а также усилит позиции Tesla в сегменте облачных сервисов. Ранее генеральный директор Tesla Илон Маск заявлял, что компания разрабатывает систему отчасти из-за того, что не может получить достаточное количество ускорителей на базе GPU для удовлетворения своих потребностей.
29.08.2023 [17:50], Сергей Карасёв
10 тыс. ускорителей NVIDIA H100: Tesla запустила один из мощнеших ИИ-суперкомпьютеров в миреКомпания Tesla, по сообщению Tom's Hardware, в минувший понедельник, 28 августа 2023 года, запустила вычислительный кластер для решения ресурсоемких задач, связанных с ИИ. В основу платформы положены 10 тыс. ускорителей NVIDIA H100. Отмечается, что система обеспечивает пиковую производительность в 340 Пфлопс FP64 для технических вычислений и 39,58 Эфлопс INT8 для приложений ИИ. Таким образом, по производительности FP64 кластер превосходит суперкомпьютер Leonardo, который располагается на четвёртой позиции в нынешнем рейтинге Тор500 с показателем 304 Пфлопс. Фактически кластер Tesla на базе NVIDIA H100 является одной из самых мощных платформ в мире. Он подходит не только для обработки алгоритмов ИИ, но и для НРС-задач. Благодаря данной системе Tesla значительно расширит свои ресурсы для создания полноценного автопилота. А это поможет компании Илона Маска получить конкурентные преимущества перед другими разработчиками умных транспортных средств. На формирование кластера потрачено около $300 млн. 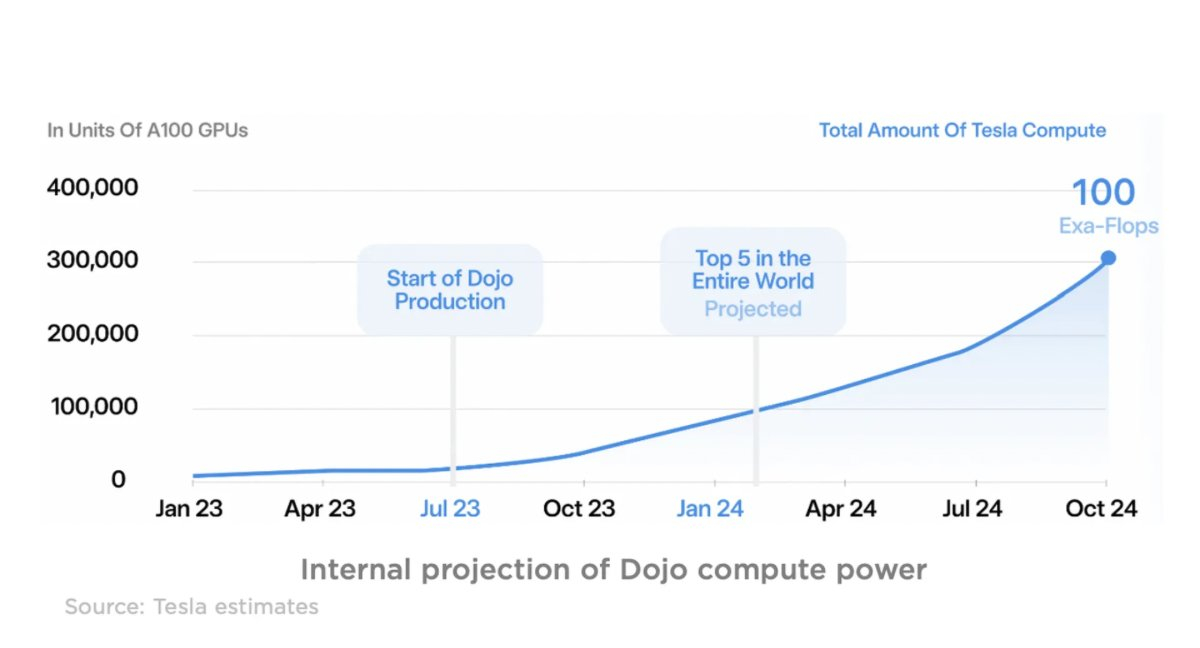
Изображение: Twitter / Sawyer Merritt Однако на рынке сформировался дефицит ускорителем NVIDIA H100. На этом фоне Tesla создаёт ИИ-суперкомпьютер Dojo, в основу которого лягут специализированные чипы собственной разработки — Tesla D1. К концу следующего года, по словам Илона Маска, производительность ИИ-систем Tesla может быть доведена до 100 Эфлопс. Стоимость проекта оценивается в $1 млрд. На обучение ИИ-моделей Tesla намерена потратить более $2 млрд в текущем году и примерно такую же сумму в 2024-м.
22.07.2023 [14:57], Сергей Карасёв
Tesla начала создание ИИ-суперкомпьютера Dojo стоимостью $1 млрдКомпания Tesla, по сообщению The Register, до конца 2024 года потратит более $1 млрд на создание мощного вычислительного комплекса Dojo, который поможет в разработке инновационных технологий для роботизированных автомобилей. В основу Dojo лягут специализированные чипы собственной разработки — Tesla D1. 25 таких ускорителей в виде массива 5 × 5 объединяются в рамках одного узла, который в Tesla называют «системой на пластине» (System On Wafer). Как отмечает The Verge, компания Tesla намерена совместить в одном шасси шесть таких «систем на пластине», тогда как одна стойка будет включать два шасси. В такой конфигурации производительность на стойку превысит 100 Пфлопс (BF16/CFP8). Таким образом, система из десяти шкафов позволит преодолеть экзафлопсный барьер. Более того, уже к концу следующего года, по словам главы Tesla Илона Маска, производительность может быть доведена до 100 Эфлопс. 
Источник изображения: Tesla В своём отчете за II квартал 2023 года Tesla обозначила «четыре основных технологических столпа», необходимых для решения проблемы автономности транспортных средств: это чрезвычайно большой набор реальных данных, обучение нейронных сетей, аппаратные компоненты и ПО. «Мы разрабатываем каждый из этих столпов собственными силами. В этом месяце мы делаем ещё один шаг к более быстрому и дешёвому обучению нейронной сети с началом производства нашего суперкомпьютера Dojo», — говорится в заявлении компании.
13.06.2023 [15:57], Руслан Авдеев
Tesla переедет в ЦОД, от которого по настоянию Маска отказался TwitterКомпания Tesla арендовала мощности ЦОД оператора NTT Global Data Centers в Сакраменто (США), ранее использовавшиеся компанией Twitter, сообщает DataCenter Dynamics. В конце 2022 года социальная сеть отказалась от данного ЦОД, так что у неё теперь осталось только два основных дата-центра. Занявшая её место Tesla не просто займёт освободившиеся мощности, но и арендует дополнительные. К счастью, «родственная» компания стала новым клиентом очень вовремя. Поскольку Twitter отказалась от ЦОД до конца срока аренды, компании необходимо было найти «преемника», чтобы максимально безболезненно разорвать соглашение. Впрочем, роль Маска в выборе ЦОД неизвестна — в декабре прошлого года миллиардер назвал Сакраменто «возможно, худшим местом для ЦОД». Именно этот дата-центр Twitter вышел из строя в прошлом сентябре из-за жары. 
Источник изображения: Austin Ramsey/unsplash.com Позицию самого владельца Twitter вряд ли можно назвать особенно взвешенной, поскольку помимо отказа от ЦОД в Сакраменто для оптимизации расходов социальной сети он пошёл на ряд крайне непопулярных шагов, от массовых увольнений сотрудников до неплатежей компаниям-партнёрам. Сообщалось, что Twitter отказывается платить за сервисы Google Cloud. А ранее компания отказалась платить AWS, но пошла на попятную, когда Amazon пригрозила отказаться от рекламы в социальной сети. Судя по намерениям Tesla, планирующей нарастить мощности ЦОД, дела у компании обстоят значительно лучше, чем у Twitter, стоимость которой, если верить Fidelity, упала с $44 млрд до $15 млрд. Считается, что Tesla будет использовать новый ЦОД для машинного обучения, включая симуляции с участием систем автономного вождения. У Tesla и без того большие планы. Компания уже анонсировала собственный процессор D1, который станет основой ИИ-суперкомпьютера Dojo.
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 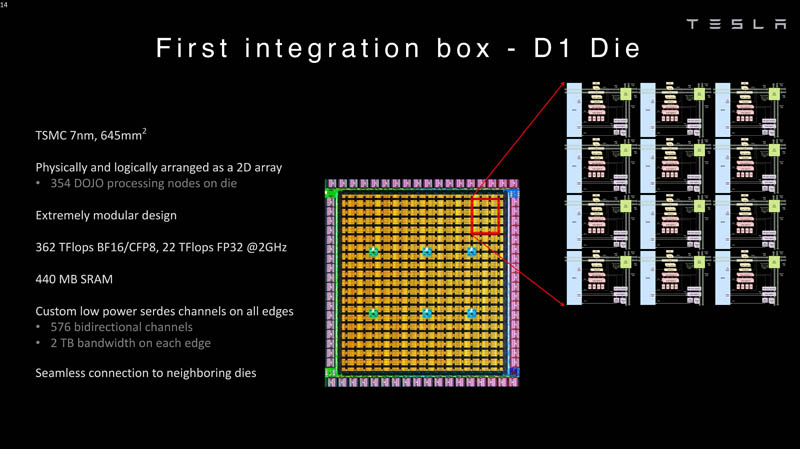
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 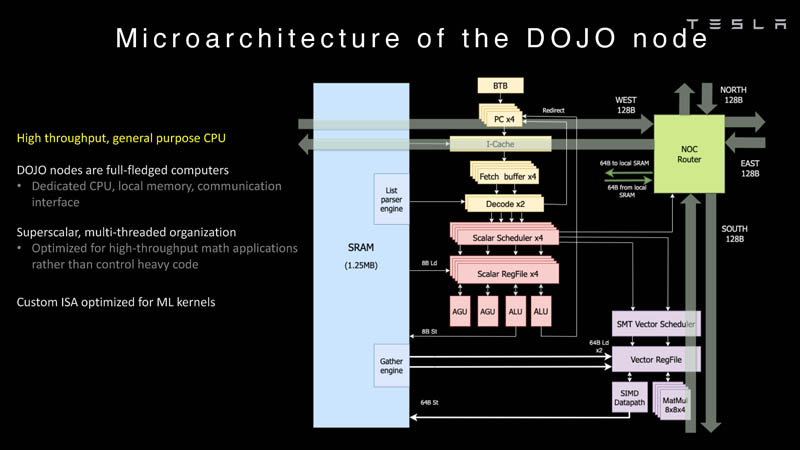 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 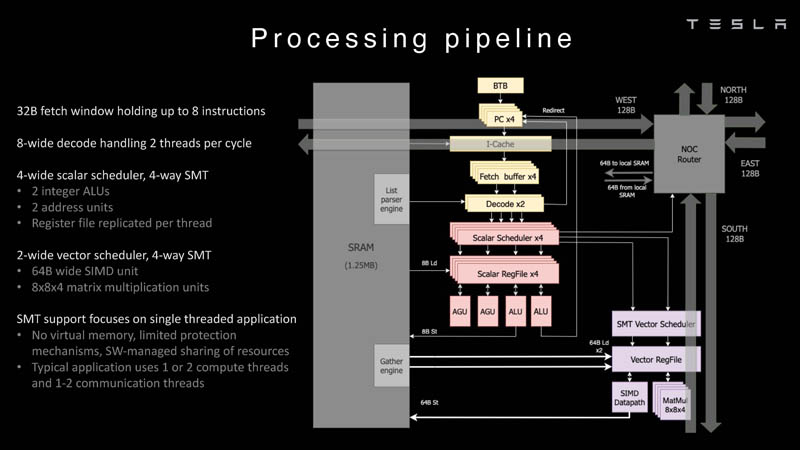 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 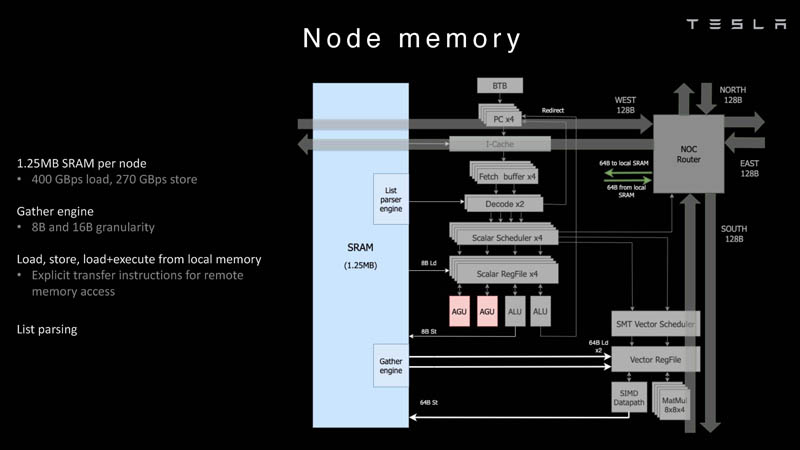 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 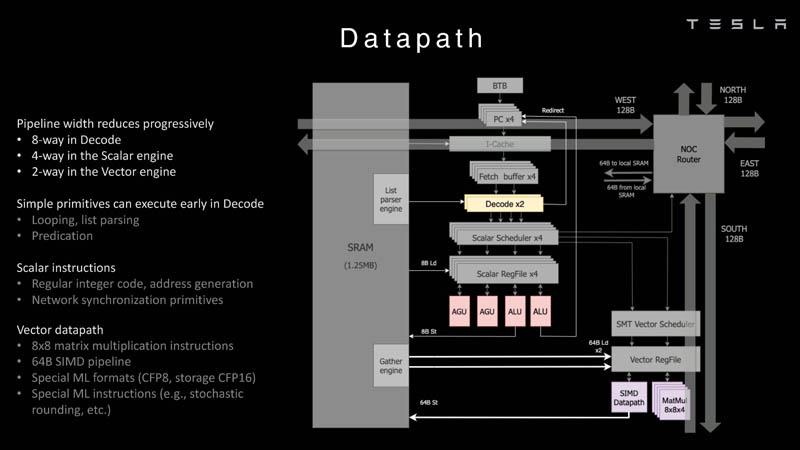 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 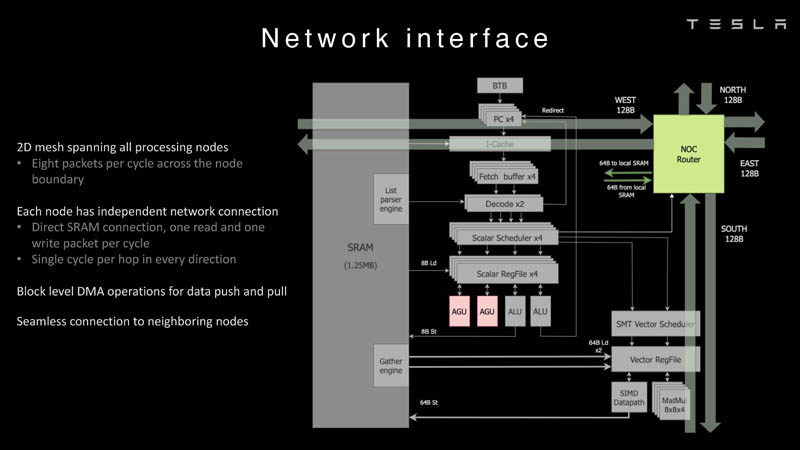 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 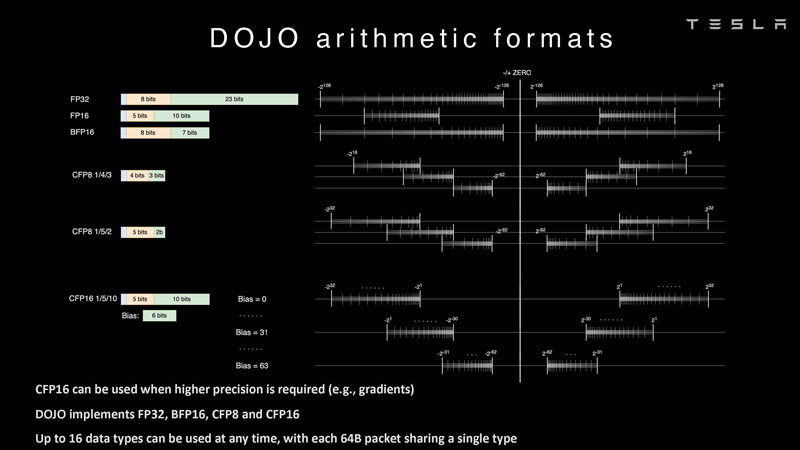 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 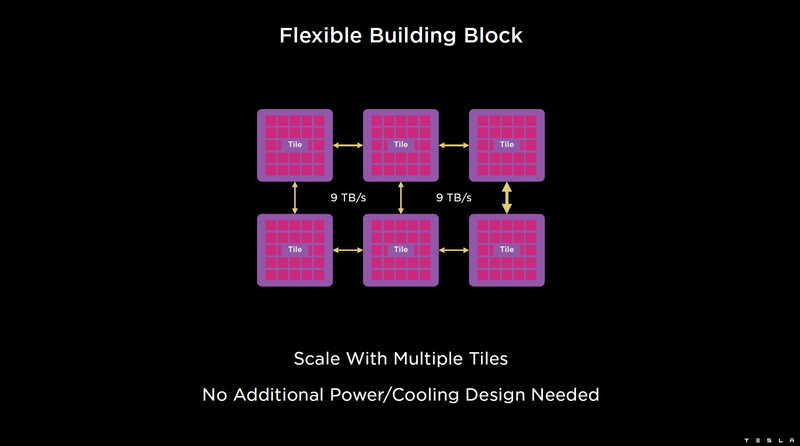 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 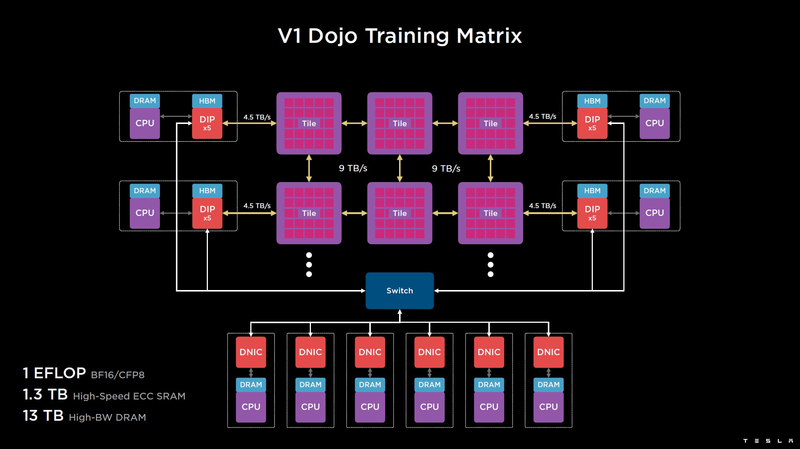 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 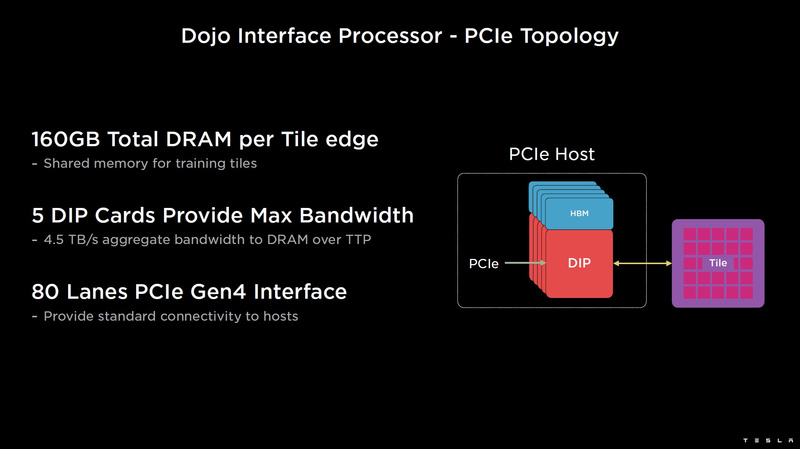 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее.  В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
15.08.2022 [19:25], Сергей Карасёв
Tesla похвасталась седьмым по величине GPU-суперкомпьютером в миреТим Заман, руководитель отдела искусственного интеллекта и средств автопилотирования Tesla, сообщил о том, что компания Илона Маска в настоящее время эксплуатирует седьмой по величине суперкомпьютер в мире. Правда, речь идёт лишь о числе используемых в системе ускорителей. По словам господина Замана, вычислительный комплекс Tesla недавно подвергся апгрейду. В результате общее число задействованных акселераторов NVIDIA A100 (80 Гбайт) выросло до 7360 шт. В прошлом году Tesla представила свой новый кластер, насчитывающий 720 узлов, каждый из которых оборудован восемью ускорителями A100. Таким образом, в общей сложности на момент анонса использовались 5760 акселераторов. Заявленное быстродействие достигало 1,8 Эфлопс (FP16). 
Источник изображения: Tim Zaman В рамках обновления система получила ещё 1600 шт. таких же ускорителей. Результирующую производительность Tesla пока не раскрывает, но она могла увеличиться примерно на четверть. Система предназначена для обучения ИИ-моделей, отвечающих за работу средств автопилотирования в электромобилях компании. Попутно Tesla разрабатывает суперкомпьютер Dojo. Он будет оснащён собственными 7-нм чипами D1 (FP32). Каждый чип будет иметь площадь 645 мм2 и содержать 50 млрд транзисторов. |
|

