Материалы по тегу: ipu
|
05.07.2023 [14:50], Владимир Мироненко
Gcore и Graphcore запустили в Великобритании облачный ИИ-кластер на базе BOW IPUПровайдер облачных и периферийных сервисов Gcore объявил о запуске облачного ИИ-кластера AI Cloud в Ньюпорте (Уэльс, Великобритания). Кластер был построен с использованием ИИ-решений Graphcore Intelligence (IPU) — Graphcore Bow-Pod, IPU-Pod и Bow-vPod, предназначенных для выполнения задач и алгоритмов машинного обучения. Как сообщает ресурс Data Center Dynamics, во время тестирования производительности Bow Pod16 позволил обучить нейросеть EfficientNET-B4 менее чем за 14 часов, в то время как новейшим GPU для этого требовалось 70,5 часа. Производительность в задачах Dynamic Temporal Graph Network также была в 10 раз выше. Общая производительность этих кластеров ИИ не разглашается. 
Источник изображений: Gcore «Открытие облачного кластера Gcore AI Cloud в Ньюпорте в партнёрстве с Graphcore является важным шагом на пути к созданию одной из первых европейских инфраструктур искусственного интеллекта. Этот шаг позволит компаниям любого размера интегрировать инновации и легко получить доступ к передовым технологиям искусственного интеллекта», — заявил Всеволод Вайнер (Seva Vayner), директор подразделения Edge Cloud Stream компании Gcore. 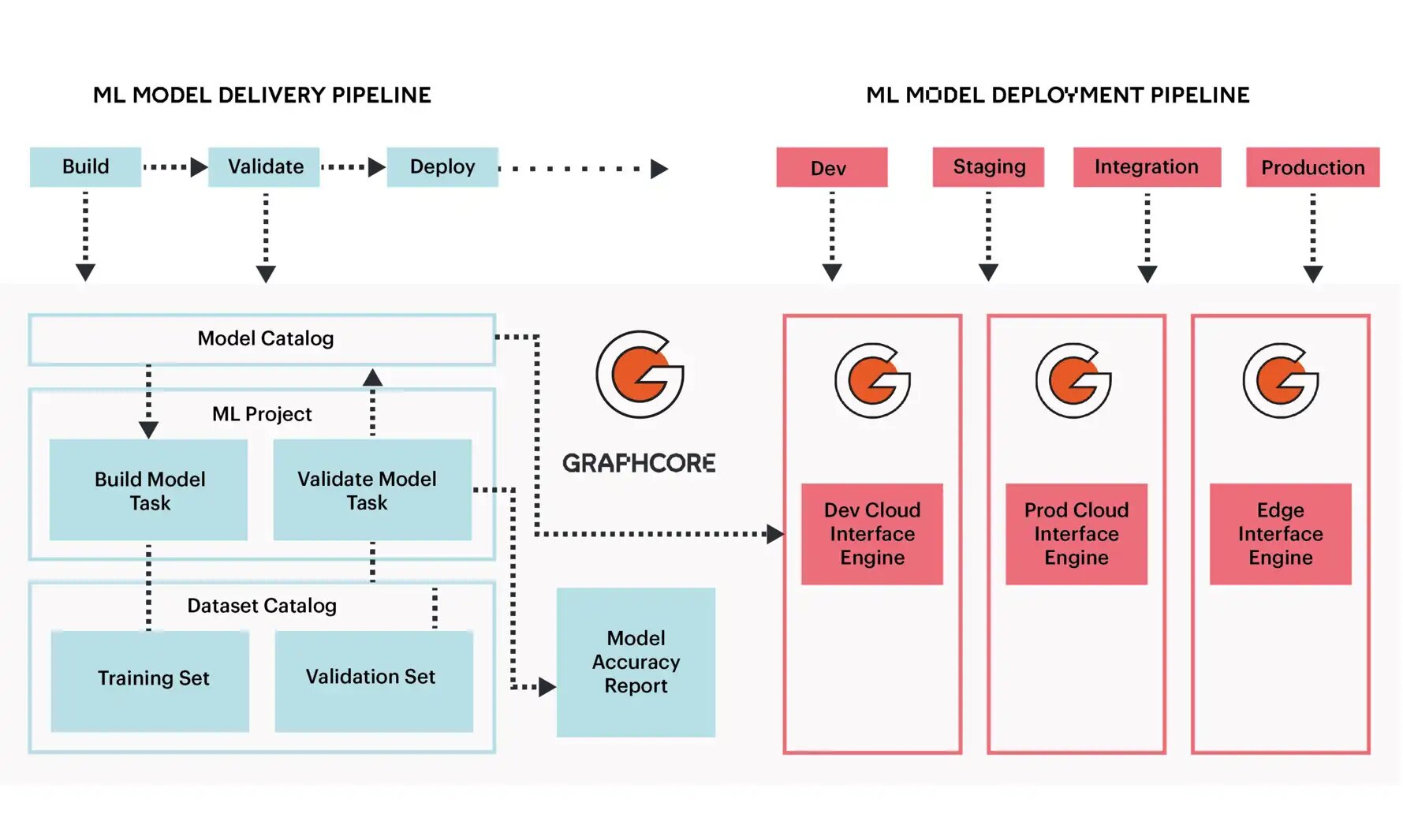 Новый IaaS обеспечивает доступ к ИИ-оборудованию Graphcore с поминутной оплатой. Gcore AI Cloud также включает целый ряд инструменов, таких как PyTorch, Keras, TensorFlow, Hugging Face, Paddle и ONNX, используемых для поддержки машинного обучения и приложений ИИ. Это третья точка присутствия (PoP) AI Cloud Gcore после Нидерландов и Люксембурга. Всего Gcore имеет точки присутствия в более чем в 140 регионах, а также более чем 20 облачных локаций.
26.06.2023 [18:23], Татьяна Золотова
Softline объявила о партнерстве с новичком рынка SofinetГК Softline заключила соглашение о сотрудничестве с российским разработчиком сетевого оборудования для корпоративных сетей Sofinet, который был зарегистрирован только в январе 2023 года. Softline получит доступ к портфолио Sofinet с локальной поддержкой и складcкими запасами, а также сможет расширить присутствие как в России, так и на дружественных рынках. В соответствии с данными ЕГРЮЛ, ООО «Софинет» зарегистрировано 23 января 2023 года в Орловской области. При этом на сайте компании говорится, что она работает уже не первый год. Основной вид деятельности включает производство коммуникационного оборудования. Уставный капитал составляет 300 тыс. руб. В продуктовой линейке Sofinet пока что представлены коммутаторы уровня доступа серии SFN2200/3600/3300/7400 для создания сетевых решений, коммутаторы ЦОД (серии SFN8500) и оптические модули. В марте 2023 года компанияанонсировала коммутатор SFN7300-24X2Q в дополнение к серии коммутаторов L3 уровня ядра предприятия. 
Источник: Sofinet Партнерский портфель новичка пока еще мал. В мае 2023 года Sofinet начал сотрудничать с OCS Distribution (ООО «О-Си-Эс Центр»), в сентябре 2022 года перешедшего в российскую юрисдикцию. В июне 2023 года компания «Свет компьютерс» также стала партнером Sofinet. По неофициальным данным, OEM-вендором для Sofinet является Maipu.
02.12.2022 [17:51], Сергей Карасёв
Graphcore представила ИИ-ускоритель C600 PCIe на чипе Colossus Mk2 GC200, предназначенный для Китая и СингапураБританская компания Graphcore анонсировала ускоритель C600 в виде карты расширения PCIe, предназначенный для задач ИИ и машинного обучения. Изделие поначалу будет доступно только на рынках Китая и Сингапура — о возможности организации поставок в другие регионы пока ничего не сообщается. В основу новинки положен двухлетний чип IPU (Intelligence Processing Unit) Colossus Mk2 GC200. В основе IPU лежат не традиционные ядра, а так называемые «тайлы» — это области кристалла, содержащие как вычислительную логику, так и быструю память. В случае изделия Colossus Mk2 задействованы 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. 
Источник изображения: Graphcore Ускоритель Graphcore C600 имеет двухслотовое исполнение; используется интерфейс PCIe 4.0 x8. Показатель TDP равен 185 Вт. Заявленная производительность достигает 280 Тфлопс при FP16-вычислениях и 560 Тфлопс при вычислениях FP8. В одно серверное шасси могут устанавливаться до восьми ускорителей C600, связанных интерконнектом Graphcore IPU-Link, который обеспечивает пропускную способность до 256 Гбайт/с. Компания Graphcore отмечает, что появление нового ускорителя является ответом на запросы клиентов, у которых конфигурации дата-центров, включая форматы стоек и подсистемы питания, могут сильно различаться. Релиз C600 состоялся на фоне ухудшения положения Graphcore. В сентябре стартап заявил, что планирует сокращение рабочих мест из-за крайне сложной макроэкономической ситуации. Вместе с тем инвесторы снизили оценку Graphcore на $1 млрд из-за финансовых проблем, включая расторжение сделки с Microsoft. Нужно отметить, что в связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай производители стали намеренно снижать быстродействие чипов. Так, производитель серверов Inspur начал применять вместо ускорителя NVIDIA A100 решение A800, разработанное NVIDIA специально для Китая в соответствии с санкциями. Пока не ясно, распространяется ли подобная практика на изделие Colossus Mk2.
16.11.2022 [19:57], Сергей Карасёв
В Аргоннской национальной лаборатории появится ИИ-система Graphcore Bow IPUИсследователи со всего мира в скором времени смогут получить доступ к новой вычислительной ИИ-системе компании Graphcore, которая будет установлена в Аргоннской национальной лаборатории Министерства энергетики США. Речь идёт о комплексе Bow Pod Intelligence Processing Unit (IPU). Напомним, основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и быструю память. В случае решения Bow применён кристалл второго поколения Colossus Mk2. Конфигурация включает 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Подробнее об изделии можно узнать в нашем материале. 
Источник изображения: Аргоннская национальная лаборатория В Аргоннской национальной лаборатории расположится система Bow Pod64 с производительностью 22 Пфлопс. Доступ к ней обеспечит площадка ALCF AI Testbed, на базе которой тестируются многие передовые технологии в области ИИ и глубокого обучения. Ранее в лаборатории уже была смонтирована другая система Graphcore — IPU-M2000. Она тестировалась на научных приложениях машинного обучения, в частности, BraggNN (анализ данных рентгеновских экспериментов) и CANDLE Uno (исследования в области злокачественных образований). Специалисты пришли к выводу, что IPU «хорошо подходит для обычных задач машинного обучения и нерегулярных нагрузок». Добавим, что в Аргоннской национальной лаборатории вскоре также заработает другая тестовая ИИ-система — комплекс DataScale нового поколения, который поставит молодая компания SambaNova Systems.
05.03.2022 [01:28], Алексей Степин
Graphcore анонсировала ИИ-ускорители BOW IPU с 3D-упаковкой кристаллов WoWРазработка специализированных ускорителей для задач и алгоритмов машинного обучения в последние несколько лет чрезвычайно популярна. Ещё в 2020 году британская компания Graphcore объявила о создании нового класса ускорителей, которые она назвала IPU: Intelligence Processing Unit. Их архитектура оказалась очень любопытной. Основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и некоторое количество быстрой памяти с пропускной способностью в районе 45 Тбайт/с (7,8 Тбайт/с между тайлами). В первой итерации чип Graphcore получил 1216 таких тайлов c 300 Мбайт памяти, а сейчас компания анонсировала следующее поколение своих IPU. 
Изображения: Graphcore Новый чип, получивший название BOW, можно условно отнести к «поколению 2,5». Он использует кристалл второго поколения Colossus Mk2: 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Этот кристалл по-прежнему производится с использованием 7-нм техпроцесса TSMC, но теперь Graphcore перешла на использование более продвинутой упаковки типа 3D Wafer-on-Wafer (3D WoW). Новый IPU стал первым в индустрии чипом высокой сложности, использующем новый тип упаковки, причём технология 3D WoW была совместно разработана Graphcore и TSMC с целью оптимизации подсистем питания. Процессоры такой сложности отличаются крайней прожорливостью, а «накормить» их при этом не просто. В итоге обычная упаковка не позволяет добиться от чипа уровня Colossus Mk2 максимальной производительности — слишком велики потери и паразитный нагрев. 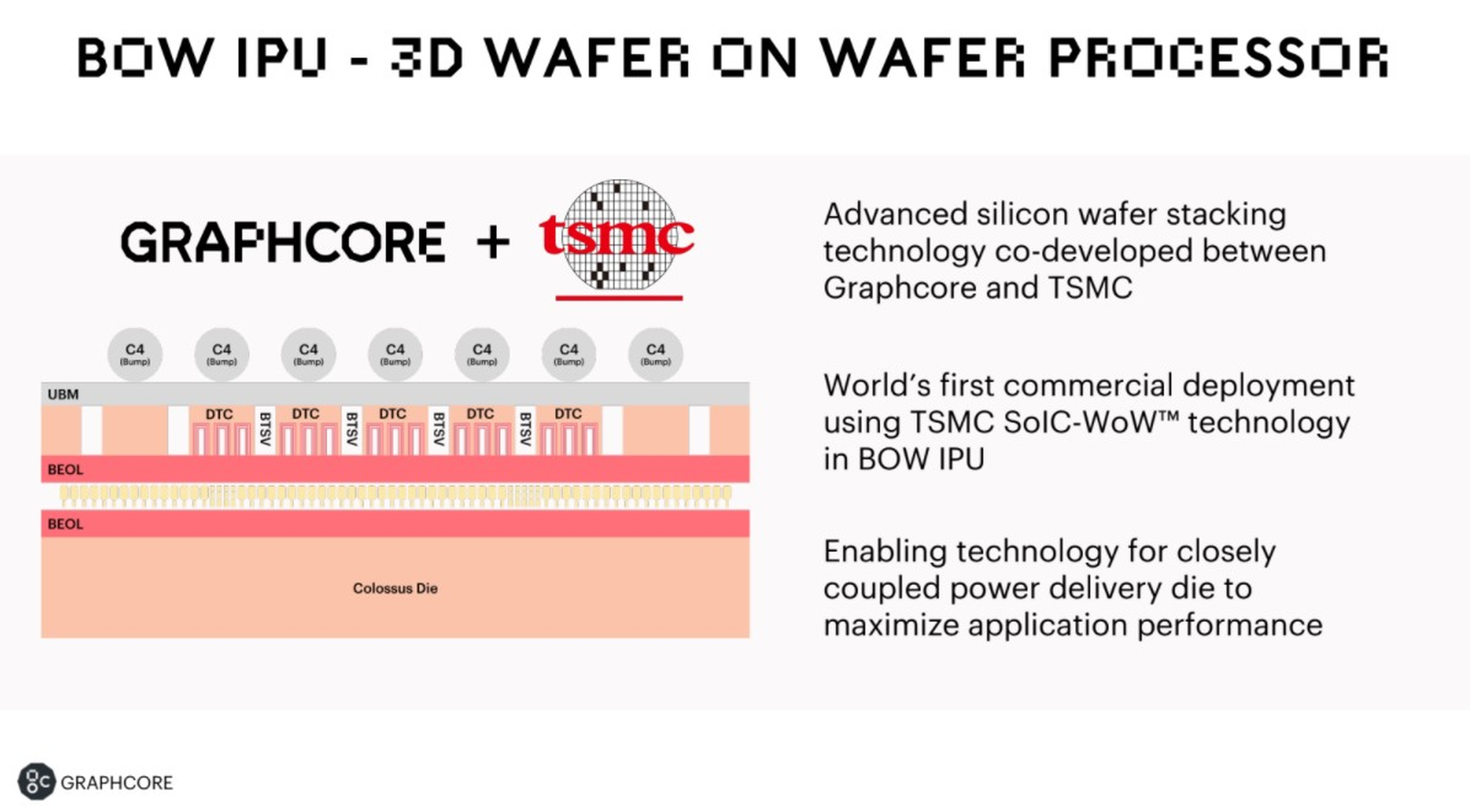 Реализована 3D WoW во многом аналогично технологии, применённой AMD в серверных чипах Milan-X. Упрощённо говоря, медные структуры-стержни пронизывают кристалл и позволяют соединить его напрямую с другим кристаллом, причём «склеиваются» они друг с другом благодаря. В случае с BOW роль нижнего кристалла отводится распределителю питания с системой стабилизирующих конденсаторов, который питает верхний кристалл Colossus Mk2. За счёт перехода с плоских структур на объёмные можно как увеличить подводимый ток, так и сделать путь его протекания более короткими. В итоге компании удалось дополнительно поднять частоту и производительность BOW, не прибегая к переделке основного процессора или переводу его на более тонкий и дорогой техпроцесс. Если у оригинального IPU второго поколения максимальная производительность составляла 250 Тфлопс, то сейчас речь идёт уже о 350 Тфлопс — для системы BOW-2000 с четырьмя чипами заявлено 1,4 Пфлопс совокупной производительности. И это хороший выигрыш, полученный без критических затрат. 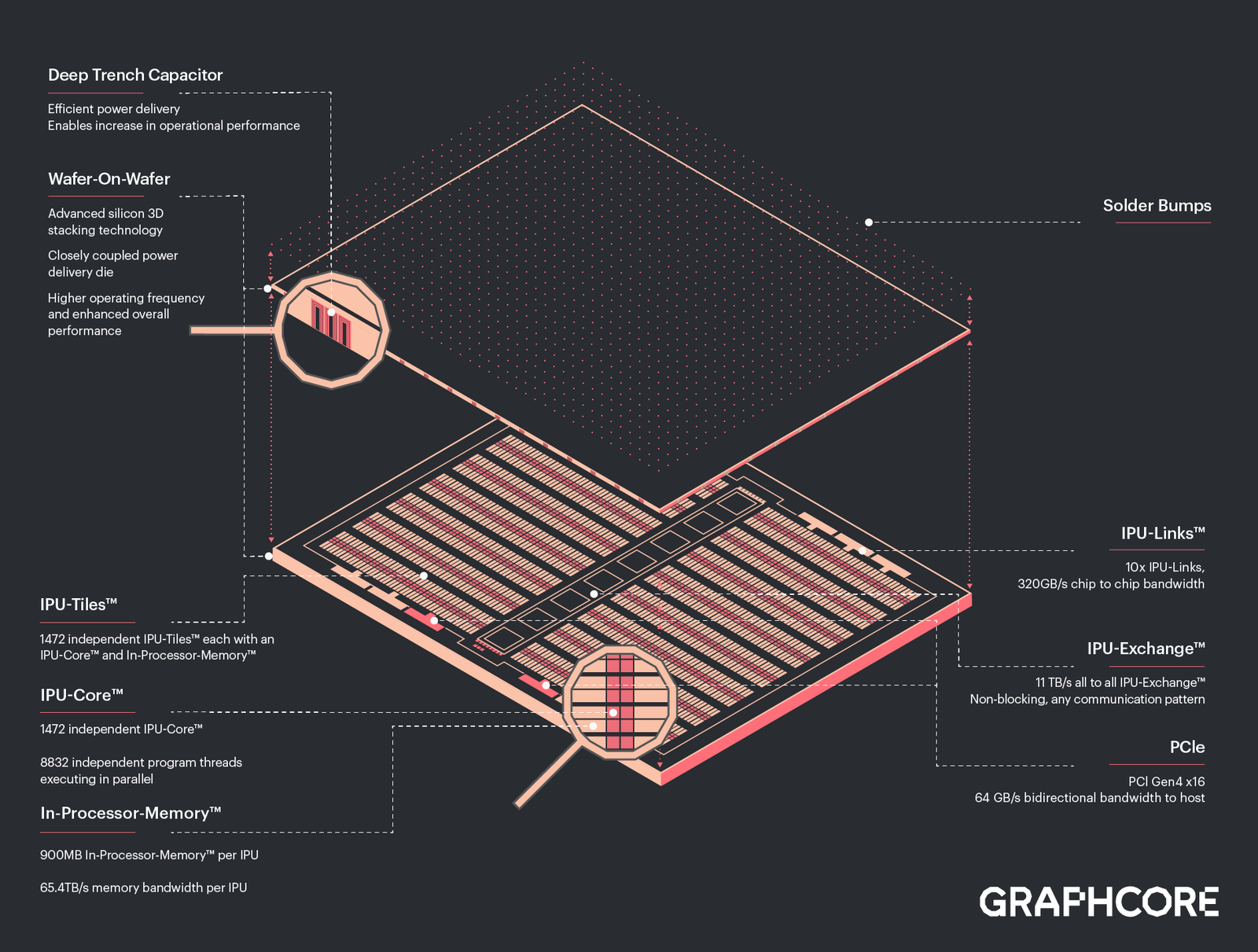 С внешним миром IPU общается по-прежнему посредством 10 каналов IPU-Link (320 Гбайт/с). Внутренней памяти в такой системе уже почти 4 Гбайт, причём работает она на скорости 260 Тбайт/с — критически важный параметр для некоторых задач машинного обучения, которые требуют всё большие по объёму наборов данных. Ёмкость набортной памяти далека от предлагаемой NVIDIA и AMD, но выигрыш в скорости даёт детищу Graphcore серьёзное преимущество. Узлы BOW-2000 совместимы с узлами предыдущей версии. Четыре таких узла (BOW POD16) с управляющим сервером — всё в 5U-шасси — имеют производительность до 5,6 Пфлопс. А полная стойка с 16 узлами BOW-2000 (BOW POD64) даёт уже 22,4 Пфлопс. По словам компании, производительность новой версии возросла на 30–40 %, а прирост энергоэффективности составляет от 10 % до 16 %. 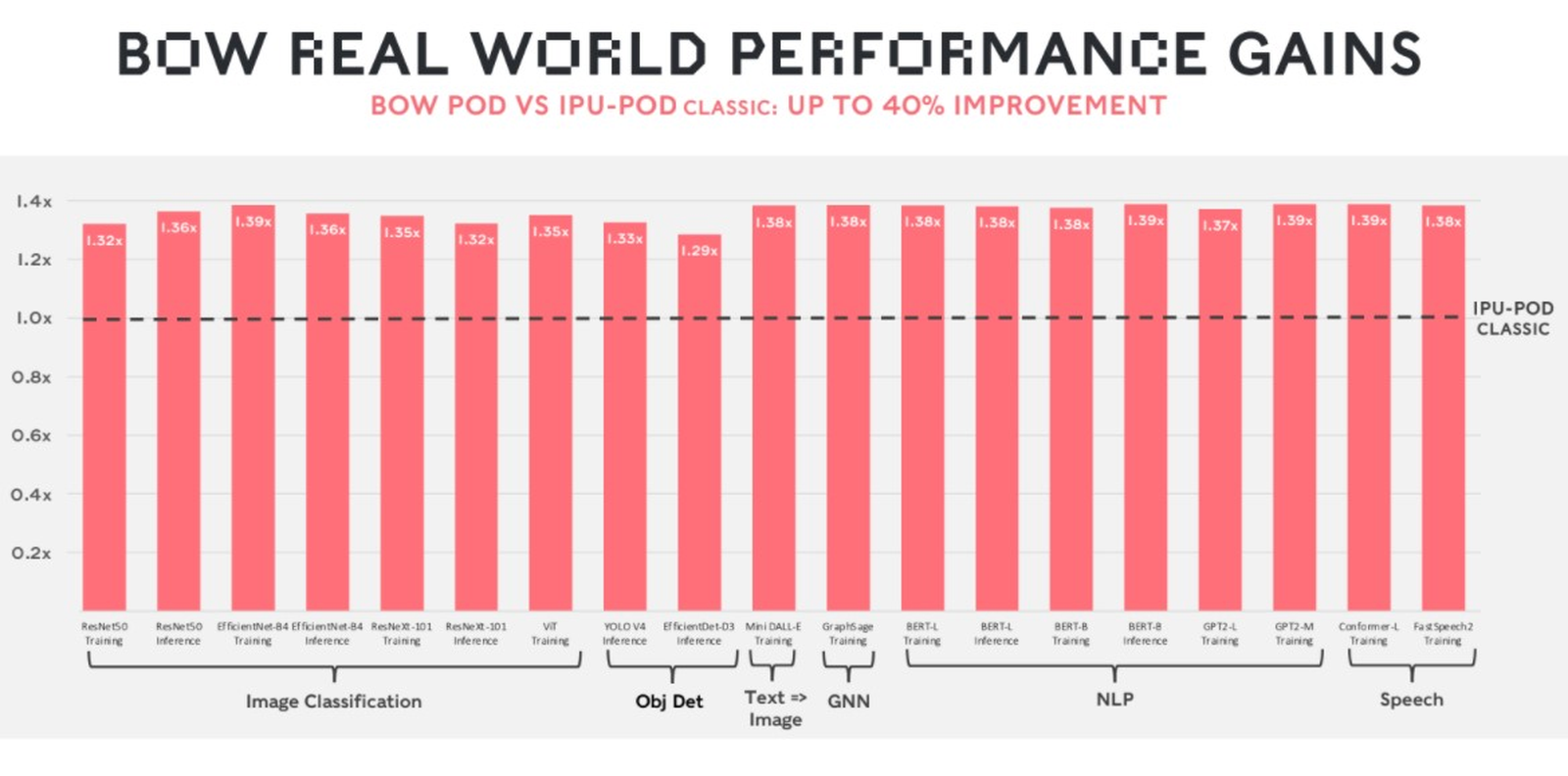 Graphcore говорит о десятикратном превосходстве BOW POD16 над NVIDIA DGX-A100 в полной стоимости владения (TCO). Cтоит BOW POD16 вдвое дешевле DGX-A100. К сожалению, говорить о завоевании рынка машинного обучения Graphcore рано: клиентов у компании уже довольно много, но среди них нет таких гигантов, как Google или Baidu. В долгосрочной перспективе ситуация для Graphcore далеко не безоблачна, но компания уже готовит третье поколение IPU на базе 3-нм техпроцесса.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 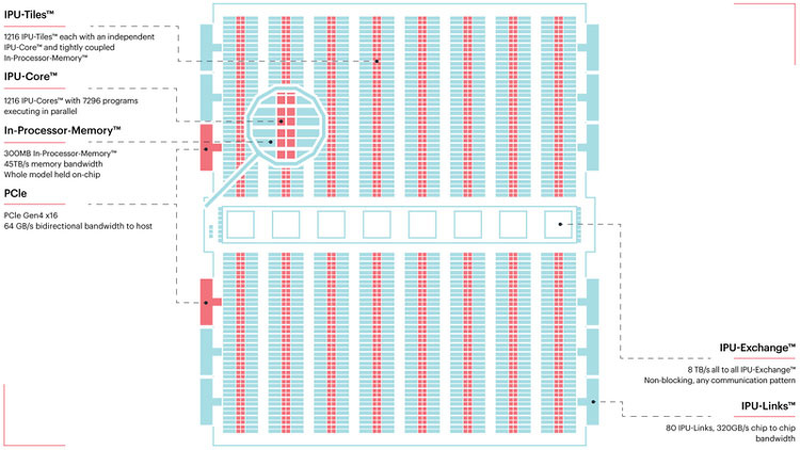
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 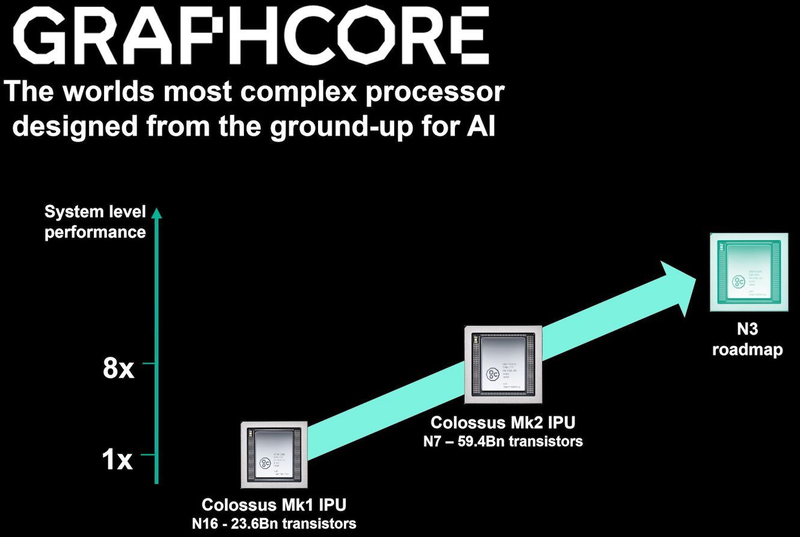
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC. |
|

