Материалы по тегу: mlperf
|
27.06.2023 [19:00], Владимир Мироненко
NVIDIA похвасталась рекордами H100 в новом бенчмарке MLPerf для генеративного ИИNVIDIA сообщила, что во всех восьми ИИ-бенчмарках MLPerf Training v3.0 её ускорители H100 установили новые рекорды, причём как по отдельности, так и в составе кластеров. В частности, коммерчески доступный кластер из 3584 ускорителей H100, созданным стартапом Inflection AI и облаком CoreWeave, смог завершить обучение ИИ-модели GPT-3 менее чем за 11 минут. Компания Inflection AI, основанная в 2022 году, использовала возможности решений NVIDIA для создания продвинутой большой языкой модели (LLM) для своего первого проекта под названием Pi. Компания планирует выступать в качестве ИИ-студии, создавая персонализированные ИИ, с которыми пользователи могли бы взаимодействовать простыми и естественными способомами. Inflection AI намерена в сотрудничестве с CoreWeave создать один из крупнейших в мире ИИ-кластеров на базе ускорителей NVIDIA. «Сегодня наши клиенты массово создают современные генеративные ИИ и LLM благодаря тысячам ускорителей H100, объединённых быстрыми сетями InfiniBand с малой задержкой, — сообщил Брайан Вентуро (Brian Venturo), соучредитель и технический директор CoreWeave. — Наша совместная с NVIDIA заявка MLPerf наглядно демонстрирует их высокую производительность». Отдельно подчёркивается, что благодаря NVIDIA Quantum-2 InfiniBand облачный кластер CoreWeave обеспечил такую же производительность, что и локальный ИИ-суперкомпьютер NVIDIA. 
Источник изображений: NVIDIA NVIDIA отметила, что H100 показали высочайшую производительность во всех тестах MLPerf, включая LLM, рекомендательные системы, компьютерное зрение, обработка медицинских изображений и распознавание речи. «Это были единственные чипы, которые прошли все восемь тестов, продемонстрировав универсальность ИИ-платформы NVIDIA» — сообщила компания. А благодаря оптимизации всего стека NVIDIA удалось добиться в тесте LLM практически линейного роста производительности при увеличении количества ускорителей с сотен до тысяч. Отдельно компания напомнила об энергоэффективности H100. 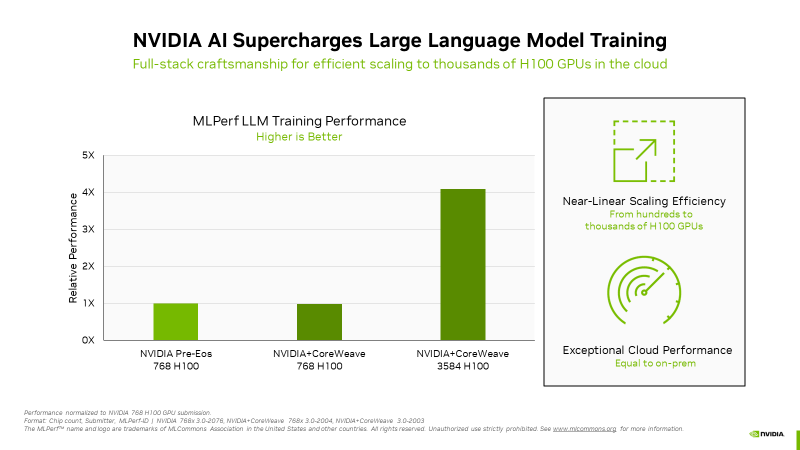 Также сообщается, что обновлённый бенчмарк MLPerf для рекомендательных систем использует больший набор данных и более современную модель, что позволяет лучше отразить проблемы, с которыми сталкиваются провайдеры облачных услуг. NVIDIA была единственной компанией, представившей результаты расширенного теста. Также компания представила результаты MLPerf для платформ L4 и Jetson. Ну а в следующем раунде MLPerf стоит ждать появления NVIDIA Grace Hopper. 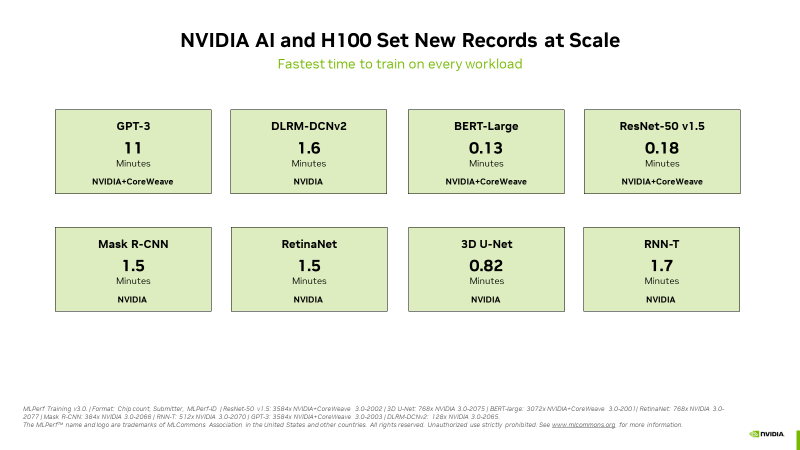 В текущем раунде результаты тестов с использованием платформы NVIDIA представили десяток компаний. Заявки поступили от крупных производителей систем, включая ASUS, Dell Technologies, GIGABYTE, Lenovo и QCT. Более 30 замеров было сделано на ускорителях H100. NVIDIA отметила прозрачность и объективность тестов, поэтому пользователи могут полностью полагаться на результаты MLPerf для принятия решения о покупке систем.
09.04.2023 [00:25], Владимир Мироненко
NVIDIA снова поставила рекорды в ИИ-бенчмарке MLPerf Inference, но конкурентов у неё становится всё большеОткрытый инженерный консорциум MLCommons опубликовал последние результаты ИИ-бенчмарка MLPerf Inference (v3.0). В этот раз поступили заявки на тестирование от 25 компаний, в то время как прошлой осенью в тестировании приняли участие 21 компания и 19 — прошлой весной. Ресурс HPCWire выделил наиболее примечательные результаты и обновления последнего раунда. Компании предоставили более 6700 результатов по производительности и более 2400 измерений производительности и энергоэффективности. В число участников вошли Alibaba, ASUS, Azure, cTuning, Deci.ai, Dell, Gigabyte, H3C, HPE, Inspur, Intel, Krai, Lenovo, Moffett, Nettrix, NEUCHIPS, Neural Magic, NVIDIA, Qualcomm, Quanta Cloud Technology, rebellions, SiMa, Supermicro, VMware и xFusion, причем почти половина из них также измеряла энергопотребление во время тестов. 
Источник изображений: hpcwire.com Отмечено, что компании cTuning, Quanta Cloud Technology, Relations, SiMa и xFusion предоставили свои первые результаты, компании cTuning, NEUCHIPS и SiMa провели первые измерения энергоэффективности, а неоднократно принимавшие участие вендоры HPE, NVIDIA и Qualcomm представили расширенные и обновлённые результаты тестов. 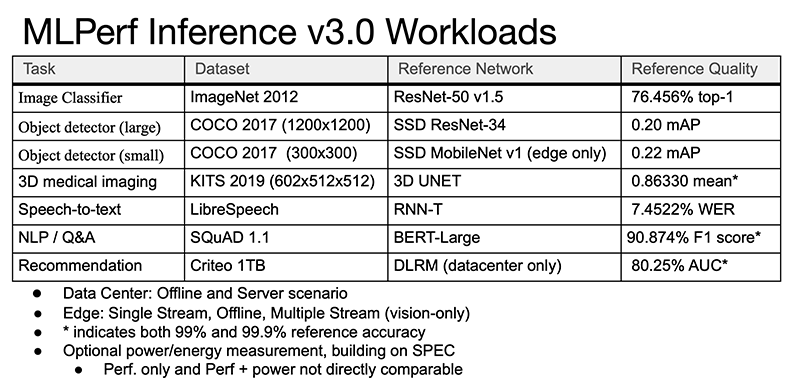 Набор тестов в MLPerf Inference 3.0 не изменился, но был добавлен новый сценарий — сетевой. Кроме того, были предоставлены улучшенные показатели инференса для Bert-Large, что представляет особый интерес, поскольку по своей природе он наиболее близок к большим языковым моделям (LLM), таким как ChatGPT. Хотя инференс, как правило, не требует столь интенсивных вычислений, как обучение, всё же является критически важным элементом в реализации ИИ. 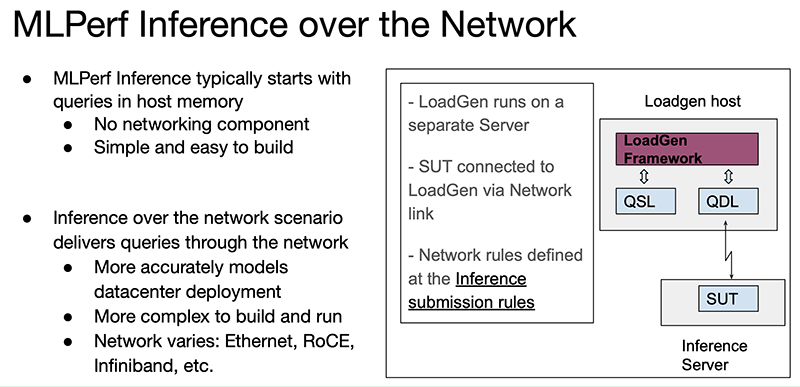 В целом, NVIDIA продолжает доминировать по показателям производительности, лидируя во всех категориях. Вместе с тем стартапы Neuchips и SiMa обошли NVIDIA по производительности в пересчёте на Ватт по сравнению с показателями NVIDIA H100 и Jetson AGX Orin соответственно. Ускоритель Qualcomm Cloud AI100 также показал хорошие результаты энергоэффективности в сравнении NVIDIA H100 в некоторых сценариях. NVIDIA продемонстрировала производительность нового ускорителя H100, а также недавно вышедшего L4. Как отметил директор NVIDIA по ИИ, бенчмаркингу и облачным технологиям, компании удалось добиться прироста производительности до 54 % по сравнению с первыми заявками шестимесячной давности. Отдельно подчёркивается более чем трёхкратный прирост производительности L4 в сравнении с T4, а также эффективность работы ПО с Transformer Engine. 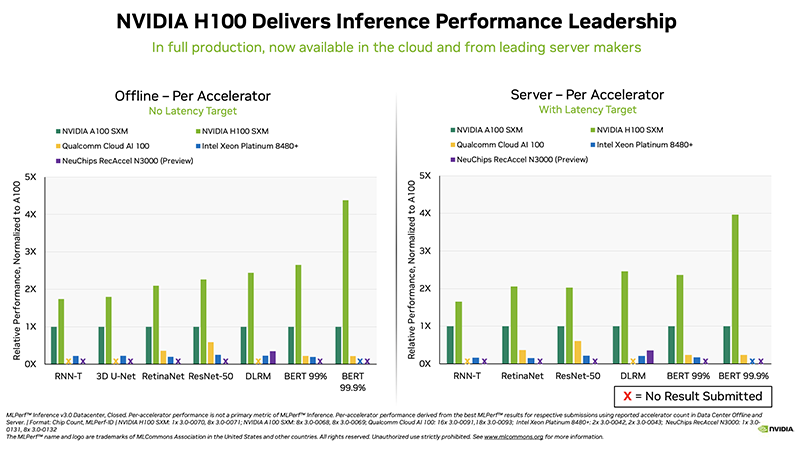 Наконец, ещё один любопытный отчёт совместно подготовили VMware, NVIDIA и Dell. Виртуализированная система с H100 «достигла 94 % из 205 % производительности bare metal», задействовав 16 vCPU и из 128 доступных. Оставшиеся 112 vCPU, как отмечается, могут быть использованы для других рабочих нагрузок и не влияют на производительность инференса.  В последнем раунде MLPerf Inference компания Intel также представила интересные результаты в предварительной категории, предназначенной для продуктов, выход которых ожидается в течение шести месяцев. В этом раунде Intel представила в закрытой заявке для ЦОД одноузловые системы (1-node-2S-SPR-PyTorch-INT8) с двумя процессорами Sapphire Rapids (Intel Xeon Platinum 8480+).  Qualcomm отметила, что её ускоритель Cloud AI 100 неизменно показывает хорошие результаты MLPerf, демонстрируя низкую задержку и высокую энергоэффективность. Компания сообщила, что ее результаты в MLPerf Inference 3.0 превзошли все её предыдущие рекорды по пиковой производительности в автономном режиме, энергоэффективности и более низким задержкам во всех категориях. Со времён MLPerf 1.0 производительность Cloud AI 100 выросла на 86 %, а энергоэффективность — на 52%. Всё это достигнуто благодаря оптимизации ПО, так что отказ Meta✴ в своё время от этих чипов выглядит обоснованным.
13.11.2022 [21:47], Владимир Мироненко
NVIDIA вновь лидирует в бенчмарке MLPerf TrainingКонсорциум MLCommons опубликовал результаты отраслевых бенчмарков MLPerf Training 2.1. Набор эталонных тестов MLPerf Training оценивает производительность обучения ML-моделей, которые используются в коммерческих приложениях. Нынешний раунд включает в себя около 200 результатов от 18 различных организаций различных размеров. Набор тестов MLPerf HPC ориентирован на суперкомпьютераы и модели для научных приложений, например, в области метеорологии, космологии, квантовой маханики, а также оценивает пропускную способность больших систем. MLPerf HPC 2.0 содержит более 20 результатов от 5 организаций. Наконец, набор тестов MLPerf Tiny создан для оценки скорости инференса для встраиваемых и периферийных систем. MLPerf Tiny 1.0 включает 59 результатов от 8 организаций, причём для 39 предоставлены данные об энергопотреблении и это рекордный показатель за всё время проведения бенчмарка. 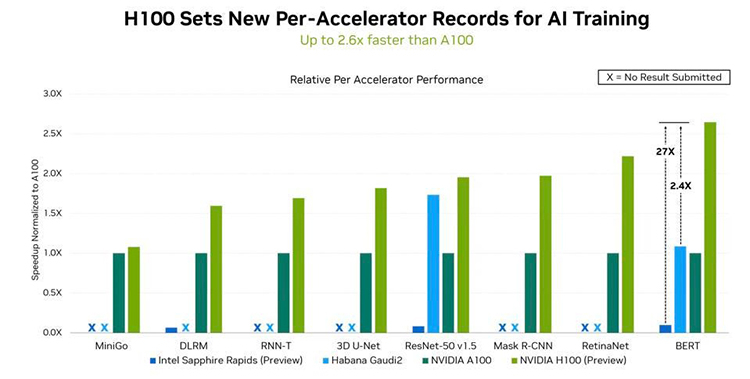
Источник: NVIDIA В этом раунде NVIDIA восстановила лидерство, которое уступил в прошлый раз Google, благодаря ускорителю Hopper H100, производительность которого в 2,4 раза выше, чем у Intel Habana, и в 2,6 раза выше, чем у A100. В этом NVIDIA помог движок Transformer Engine, поскольку Intel Habana Gaudi 2 в тесте Resnet-50 находится примерно на том же уровне, что и NVIDIA H100. Transformer Engine позволяет в режиме реального времени автоматически подбирать оптимальный баланс между производительностью и точностью вычислений. 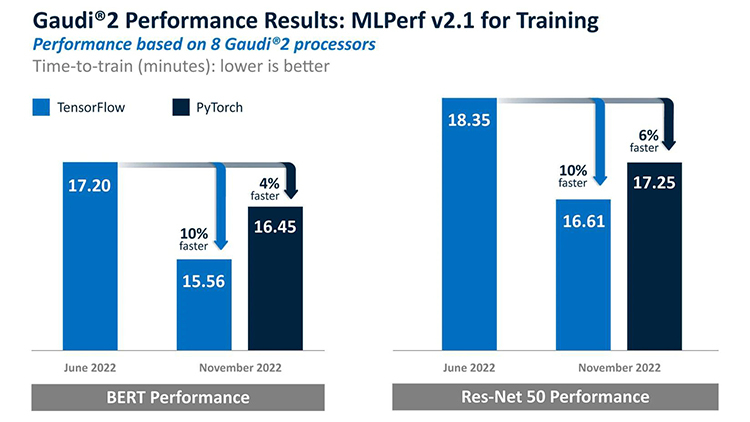
Источник: Intel Что примечательно для Intel Habana, так это то, что не требуется никакой оптимизации — стандартные модели работают прямо «из коробки». Intel отметила, что улучшила результаты на 10 % по сравнению с прошлым раундом. Но главное то, что теперь для ускорителей доступна поддержка PyTorch, что должно положительно сказаться на их популярности. Если, конечно, Intel в сложившейся ситуации ради экономии не забросит данные продукты. 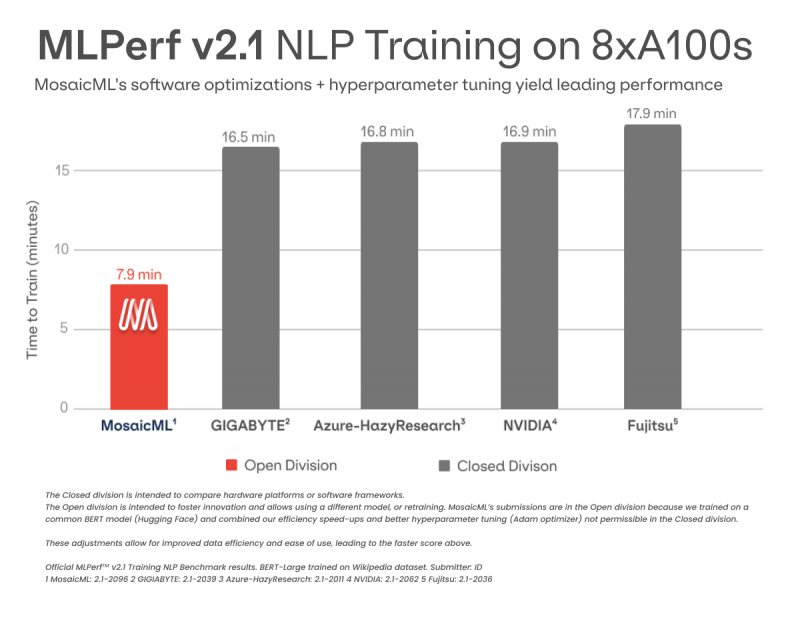
Источник: MosaicML Наконец, стоит обратить внимание на стартап MosaicML, основанный выходцем из Nervana (впоследствии Intel). Компания в очередной раз провела бенчмарки в категории Open и показала отличные результаты. Стартап продемонстрировал ускорение в 2,7 раза при тренировке BERT в сравнении с более ранними собственными результатами. При этом результаты при использовании MosaicML на A100 почти такие же, как при использовании фирменных инструментов NVIDIA на H100. Но в случае MosaicML никакой дополнительной ручной оптимизации со стороны пользователя не требуется.
12.09.2022 [19:31], Алексей Степин
В бенчмарке MLPerf Inference v2.1 отметилось сразу несколько новичков, готовых потягаться с грандами ИИ-индустрииБенчмарк MLPerf, а вернее, его набор тестов Training, в основном является вотчиной NVIDIA с небольшими вкраплениями результатов ускорителей иных архитектур вроде Google TPU. Но MLPperf Inference более демократичен. В частности, в последнем раунде v2.1 отметилось сразу несколько новых систем и архитектур. Опубликованы новые результаты были в двух категориях, Open и Closed, и в обоих случаях в списках замечены новинки. В частности, в «открытой» категории появились результаты процессора Alibaba Yitian 710, довольно высокие и без дополнительных ускорителей, что, впрочем, неудивительно — этот чип с архитектурой Armv9 располагает 128 ядрами с частотой до 3,2 ГГц и имеет поддержку всех современных форматов данных. 
Alibaba Yitian 710. Источник: Alibaba Cloud В этой же категории дебютировали PCIe-ускорители Moffett AI S4, S10 и S30. В основе этих решений лежит архитектура Moffett Antoum, специально спроектированная для работы с «разреженными» (sparsity) моделями. S4, младшая модель серии, располагает 20 Гбайт памяти LPDDR4x, потребляет 70 Вт, но при этом развивает 943 Топс на вычислениях INT8 и 471 Тфлопс в режиме BF16 при коэффициенте sparsity, равном 32x. Старшие варианты, судя по всему, несут на борту по 2 и 3 процессора Moffett AI Antoum. 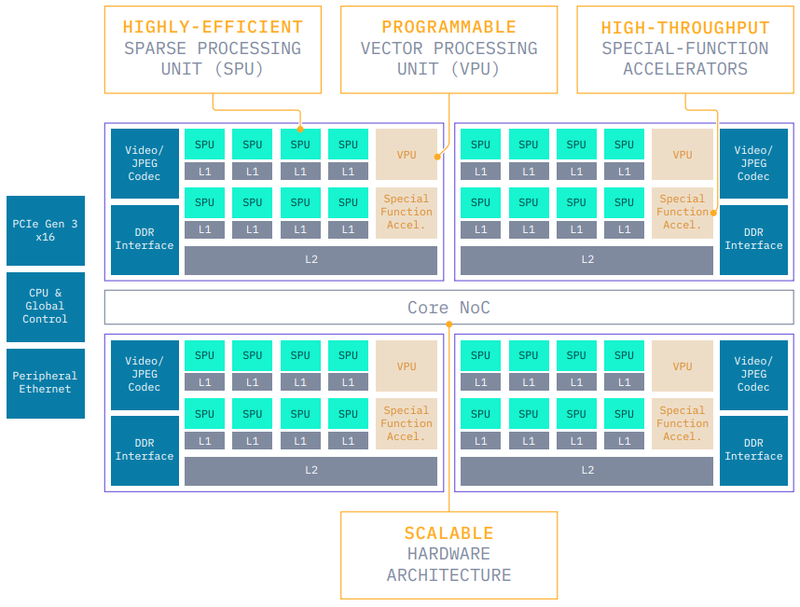
Архитектура Moffett S4. Источник: Kisaco Research Это выливается в очень неплохие результаты в ResNet50 даже для S4. Более мощные ускорители S10 и S30 демонстрируют пропорциональный прирост производительности, составляющий 2х и 3х соответственно. Впрочем, в графе точность (accuracy) в результатах есть некоторый разброс. Интересно, что Antoum содержит в своём составе аппаратные декодеры видео (64 потока 1080p@30) и JPEG-изображений (2320 к/c с разрешением 1920x1080), так что процессор действительно хорошо подходит для инференс-систем, где требуется быстрая обработка входящих изображений или видео. 
Moffett S4. Источник: Kisaco Research Из прочих архитектур отметились ускорители Qualcomm Cloud AI 100, но не всех категориях бенчмарка. А вот в категории Closed куда «многолюднее», хотя основную массу населения и составляют решения NVIDIA. Но, во-первых, компания продемонстрировала результаты H100, что выглядит весьма интересно в сравнении ускорителями A100 в различных вариациях, а также с менее мощными ускорителями A30 и A2. 
Ускорители Sapeon. Источник: Korea IT News Во-вторых, в этой же категории появилась новинка — ускоритель Sapeon X220 от южнокорейской SK Telecom. Одно из его назначений — качественный апскейл видеоконтента с низким разрешением, например, из FullHD в 4K. Для ResNet-50 заявлена производительность 6700 к/с. Главное преимущество X220 перед современными GPU — энергоэффективность, и по этому параметру он в 3,5 раза опережает ускорители сопоставимого класса. 
Источник: SK Telecom Наконец, в Inference v2.1 можно увидеть результаты загадочного китайского соперника NVIDIA A100 — ускорителя серии BR100 от Biren Technology, о котором мы не столь давно рассказывали . Он действительно показал результаты, сопоставимые с NVIDIA A100. При этом речь идёт о PCIe-версии BR100, ограниченной теплопакетом 300 Вт, в то время как в варианте OAM c TDP 550 Вт результаты такого модуля могут оказаться выше даже в сравнении с A100 в исполнении SXM. 
Источник: Biren Technology Также следует отметить и результат двухпроцессорной системы на базе Intel Sapphire Rapids. Хотя речь и идёт о процессоре общего назначения, поддержка инференс-нагрузок позволила Sapphire Rapids бороться на равных или даже опережать NVIDIA A2. Таким образом, наблюдать за MLPerf явно стало интереснее. Пока этого нельзя сказать про раздел Training, но в разделе Inference уже имеется достаточно результатов для представляющих интерес сравнений и выводов.
29.06.2022 [20:00], Алексей Степин
NVIDIA снова ставит рекорды в ИИ-бенчмарке MLPerf TrainingСегодня вышла очередная версия бенчмарка MLPerf Training для оценки производительности ИИ-ускорителей в различных сценариях, максимально приближённых к реальным. Всего в состав версии 2.0 входит 8 различных тестах в четырёх категориях. NVDIA — давний и наиболее активный участник проекта MLPerf, именно результаты различных систем на базе ускорителей NVIDIA составляют 90% от всего объёма рейтинга. Также это единственный участник, стабильно принимающий участие во всех дисциплинах. В новой версии MLPerf 2.0 ускорители NVIDIA A100 вновь оказались единственными, охватившими все тесты. 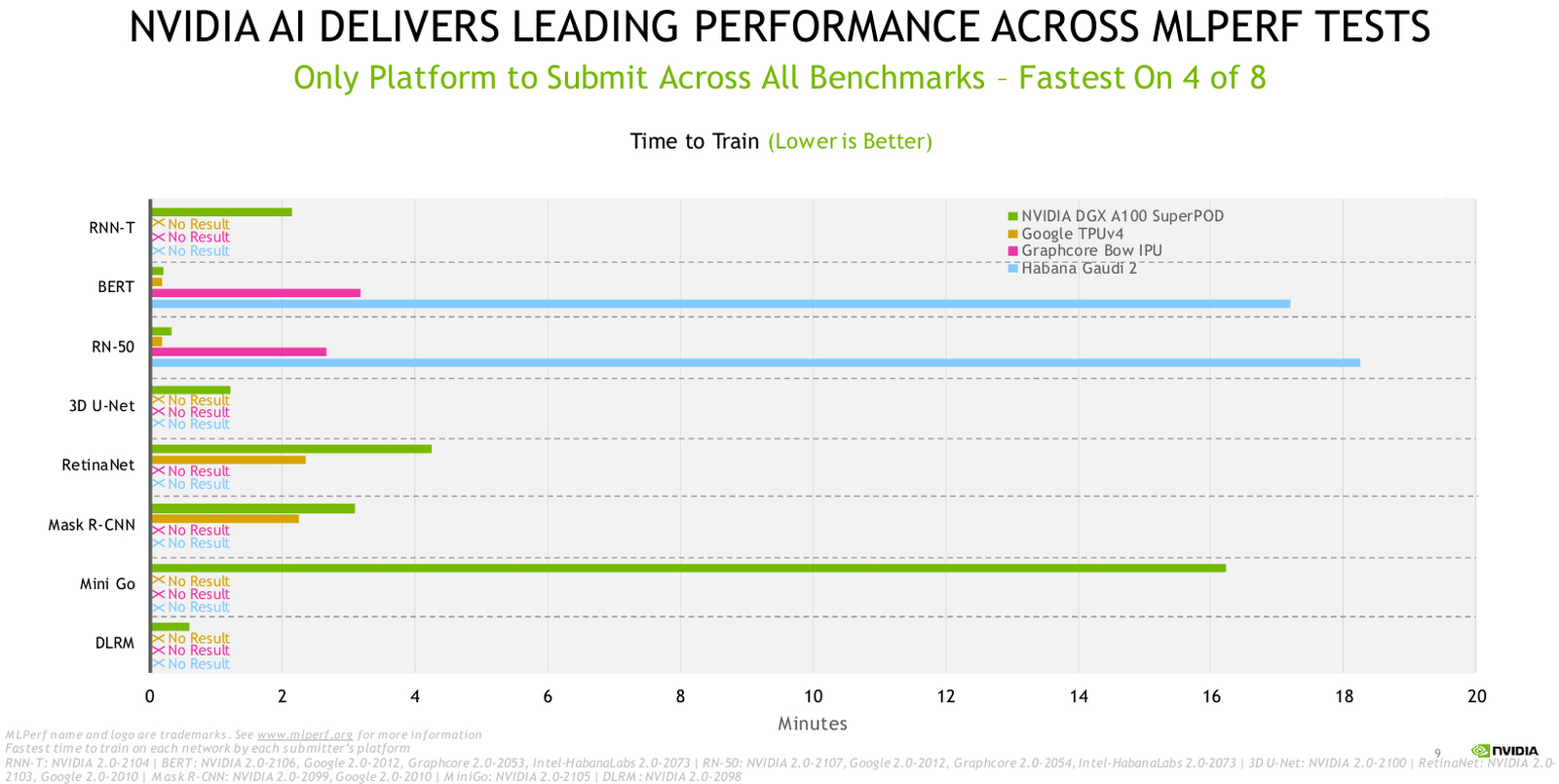
Последние результаты A100 в MLPerf 2.0. Источник: NVIDIA А суперкомпьютер Selene и вовсе продемонстрировал лидерство в шести дисциплинах MLPerf из восьми, уступив место лишь Intel Habana Gaudi 2 в тесте RN-50 и Google TPU v4 в тесте RetinaNet. Всего в «забеге» со стороны NVIDIA приняли участие 16 партнёров со своими платформами, в их число вошли такие известные компании, как ASUS, Baidu, CASIA, Dell Technologies, Fujitsu, GIGABYTE, H3C, HPE, Inspur, Lenovo, Nettrix и Supermicro. Большая часть из них запускала MLPerf 2.0 на системах, имеющих сертификацию самой NVIDIA. 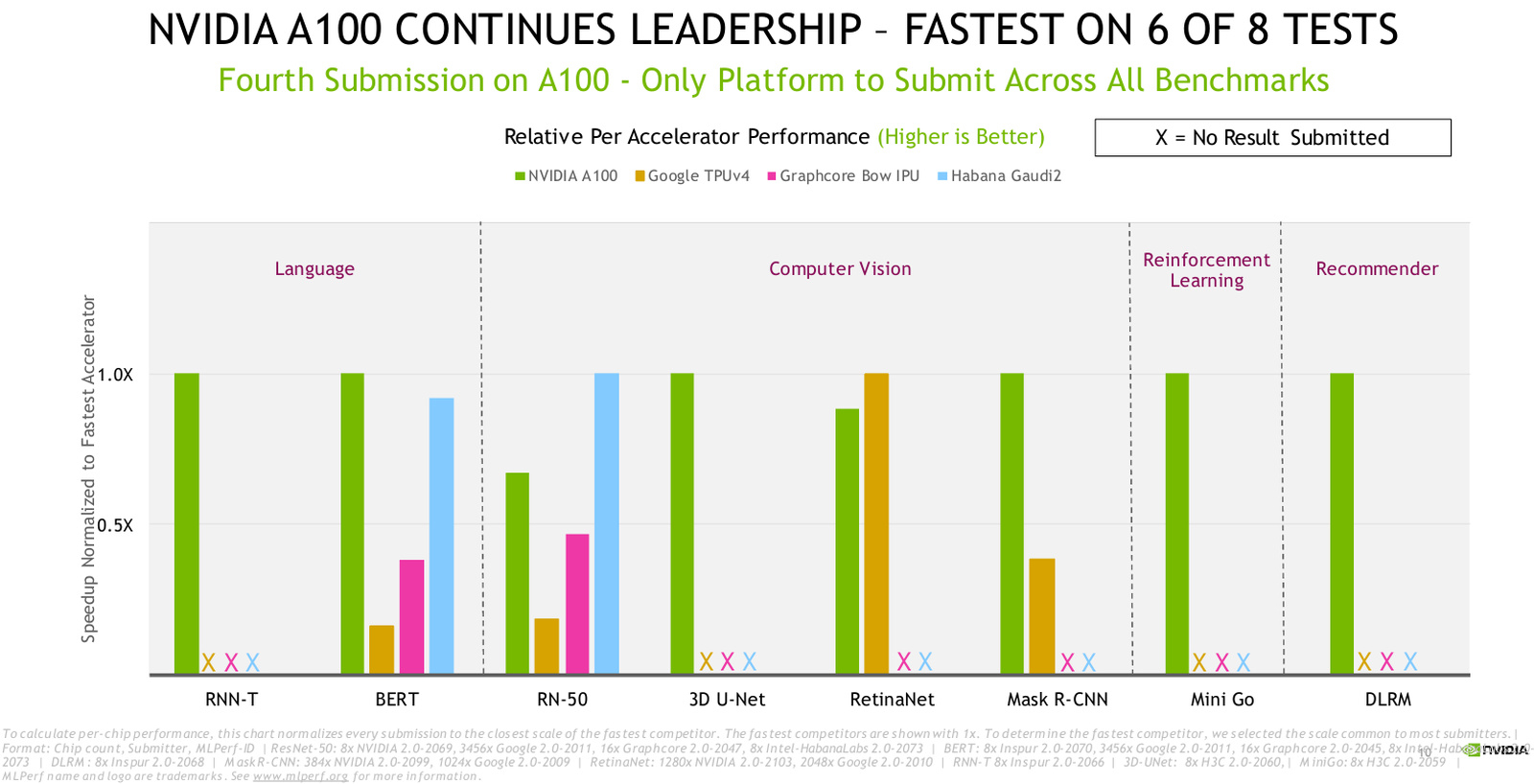
A100 лидирует в шести тестах из восьми. Источник: NVIDIA Опираясь на результаты тестов, NVIDIA говорит, что пока только она в состоянии предложить коммерческому клиенту законченную платформу, способную выполнять все стадии какого-либо ИИ-сценария: к примеру, от распознавания произнесённой фразы до поиска и классификации нужной для ответа информации, и наконец, озвучивания самого ответа. 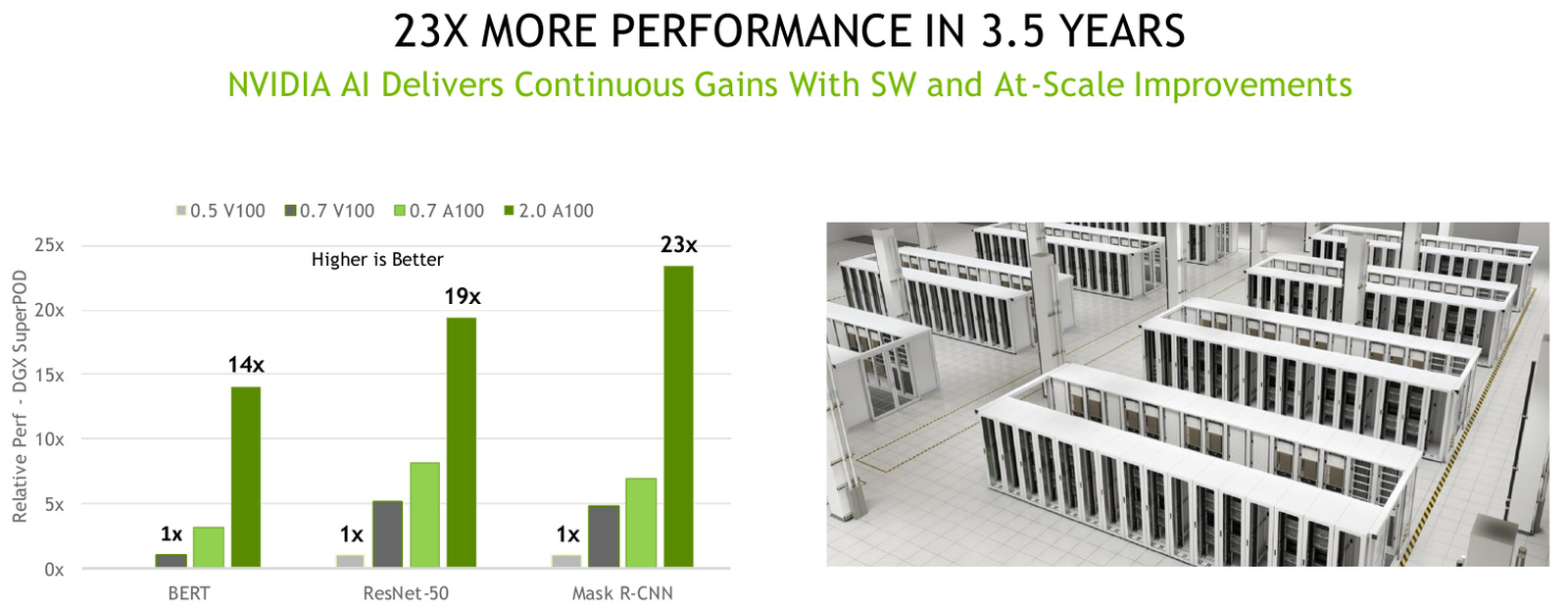
Прогресс ИИ-ускорителей NVIDIA за 3.5 года. Источник: NViDIA А использование унифицированной платформы вместо нескольких отдельных, закономерно снижает и стоимость владения, и сложность обслуживания и настройки. К тому же, такая платформа имеет задел на будущее, особенно с учётом того, что на смену A100 вскоре начнёт приходить новый флагман NVIDIA в лице H100. Любопытные факты: за два года, прошедшие с первого участия A100 в тестировании, производительность удалось поднять в 6 раз за счёт оптимизаций программного стека, а за 3,5 года с момента начала участия NVIDIA в проекте MLPerf она выросла ещё больше, в целых 23 раза. |
|

