С момента анонса ускорителей Intel Habana Gaudi2 минуло два года и всё это время они достойно сражались с решениями NVIDIA, хоть и уступая в чистой производительности, но нередко выигрывая по показателю быстродействия в пересчёте на доллар. Теперь пришло время нового поколения — корпорация Intel анонсировала выпуск чипов Gaudi3 и ускорителей на их основе.
Новый ИИ-процессор Gaudi3 взял на вооружение 5-нм техпроцесс TSMC, а также получил чиплетную компоновку, которая, впрочем, на логическом уровне никак себя не проявляет — Gaudi3 с точки зрения хоста остаётся монолитным ускорителем. Был увеличен с 96 до 128 Гбайт объём набортной памяти, но это по-прежнему HBM2e в отличие от решений основного соперника, давно перешедшего на HBM3.

Источник изображений здесь и далее: Intel
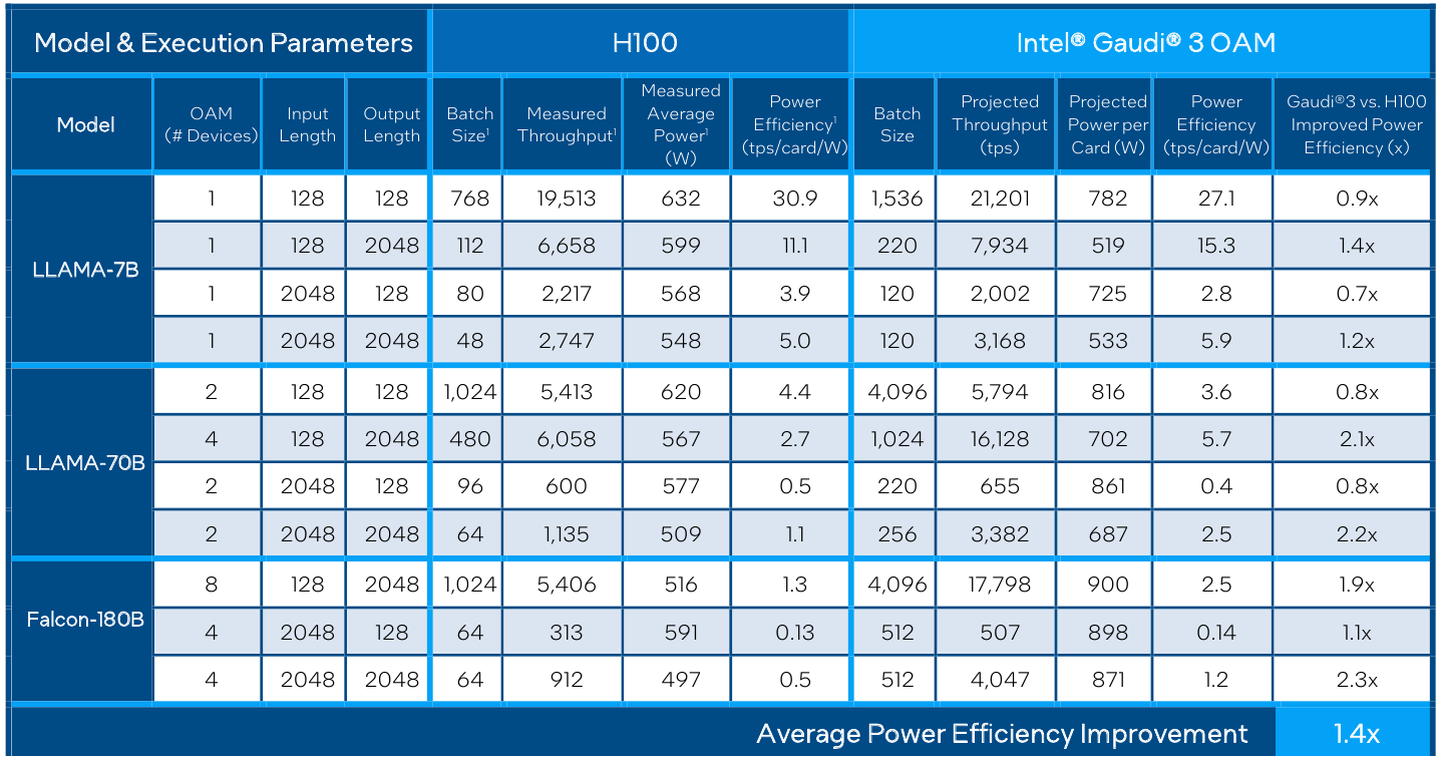
Intel выступила с достаточно серьёзным заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при существенно меньшей стоимости. Звучит многообещающе, особенно на фоне сочетания высоких цен с дефицитом со стороны «зелёных».

Физически, как уже упоминалось, Gaudi3 состоит из двух одинаковых кристаллов, «сшитых» между собой быстрым низколатентным интерконнектом. Архитектурно чип подобен предшественнику и по-прежнему включает блоки матричной математики (MME) и кластеры программируемых тензорных процессоров (TPC), имеющих доступ к разделу быстрой памяти SRAM.

Однако в сравнении с Gaudi2 количество блоков серьёзно выросло: вместо 2 MME в составе Gaudi3 теперь 8 таких блоков, а число тензорных процессоров увеличилось с 24 до 64. Вдвое, то есть с 48 до 96 Мбайт, вырос объём SRAM, а её пропускная способность возросла с 6,4 Тбайт/с до 12,8 Тбайт/с. Логически Gaudi3 делится на ядра DCORE (Deep Learning Core), в состав каждого входит два движка MME, 16 тензорных ядер и 24 Мбайт кеша L2.
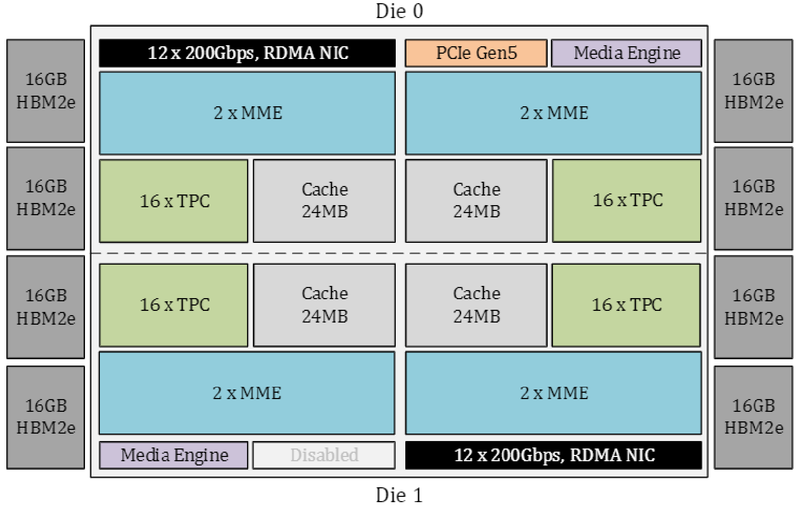
Блок-схема Gaudi3
Усилен также блок медиадвижков, их в новом чипе 14 против 8 у Gaudi2. Всё это не могло не сказаться на тепловыделении: несмотря на применение 5-нм техпроцесса теплопакет у флагманского варианта составляет целых 900 Вт, хотя в новом модельном ряду есть и не столь горячие версии с TDP 600 и 450 Вт. Последний вариант предназначен для экспорта в КНР.
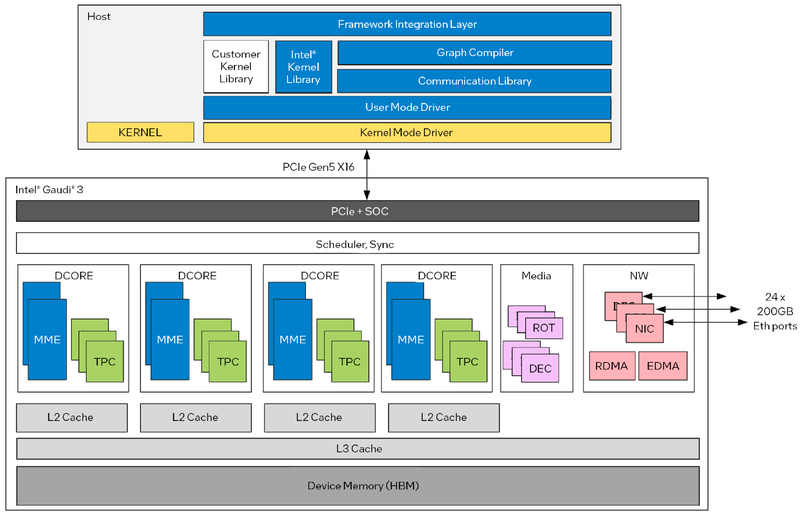
Архитектура Gaudi3 и его программная прослойка
Поскольку объём HBM2e был увеличен с 96 до 128 Гбайт, в сборке используется не шесть, а восемь 16-Гбайт кристаллов, что позволило увеличить ПСП с 2,46 до 3,7 Тбайт/с. Работает память на частоте 3,6 ГГц. В составе Gaudi3 также имеется специализированный программируемый блок управления. Он отвечает за формирование очередей, управление прерываниями, синхронизацию, работу планировщика и имеет выход непосредственно на шину PCIe.
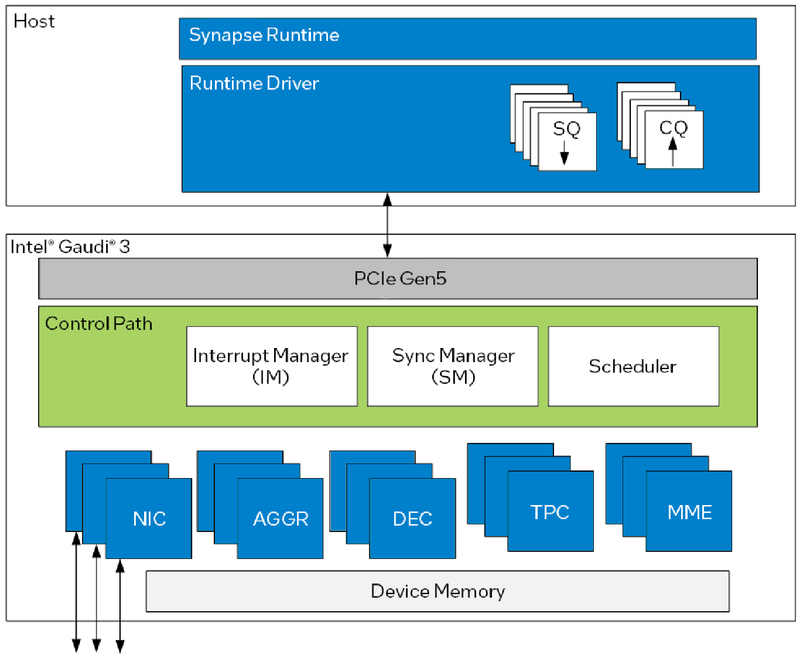
Управляющая подсистема (Control Path) Gaudi3
Сетевая часть всё ещё состоит из 24 контроллеров Ethernet (c RoCE), но появилась поддержка скорости 200 Гбит/с, а значит, вдвое возросла и совокупная производительность сети. Intel подчёркивает, что для масштабирования кластеров на базе Gaudi3 нужна обычная Ethernet-фабрика (а ещё лучше Ultra Ethernet) и нет никакой привязки к конкретному вендору, что является упрёком NVIDIA с её InfiniBand. Наконец, в качестве хост-интерфейса на смену PCI Express 4.0 пришёл PCI Express 5.0 (x16), что также означает подросшую с 64 до 128 Гбайт/с пропускную способность.
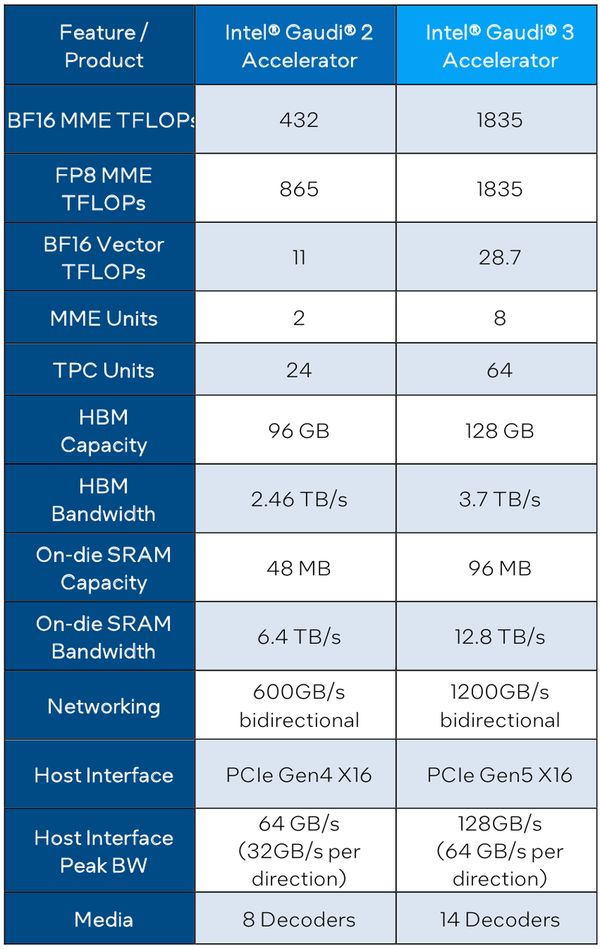
Сравнительные характеристики Gaudi2 и Gaudi3
Все эти улучшения позволяют Intel говорить о теоретической производительности в 2–4 раза более высокой, нежели было достигнуто в поколении Gaudi2. Наибольший прирост заявлен для операций с форматом BF16 на MME, что вполне закономерно, учитывая большее количество самих MME.
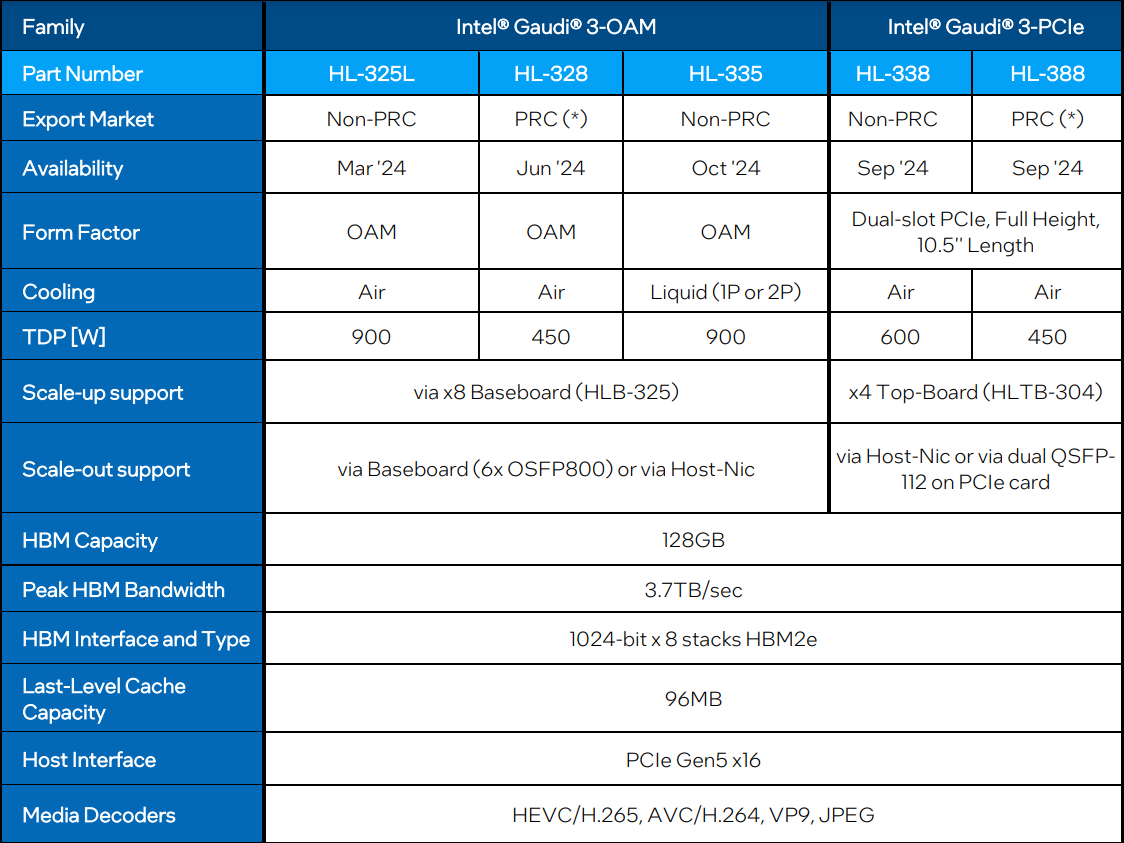
На практике результаты, демонстрируемые Gaudi3, выглядят также достаточно многообещающе: в тестах на обучение популярных нейросетей преимущество над Gaudi2 ни разу не составило менее 1,5x, а в отдельных случаях даже превысило 2,5x.
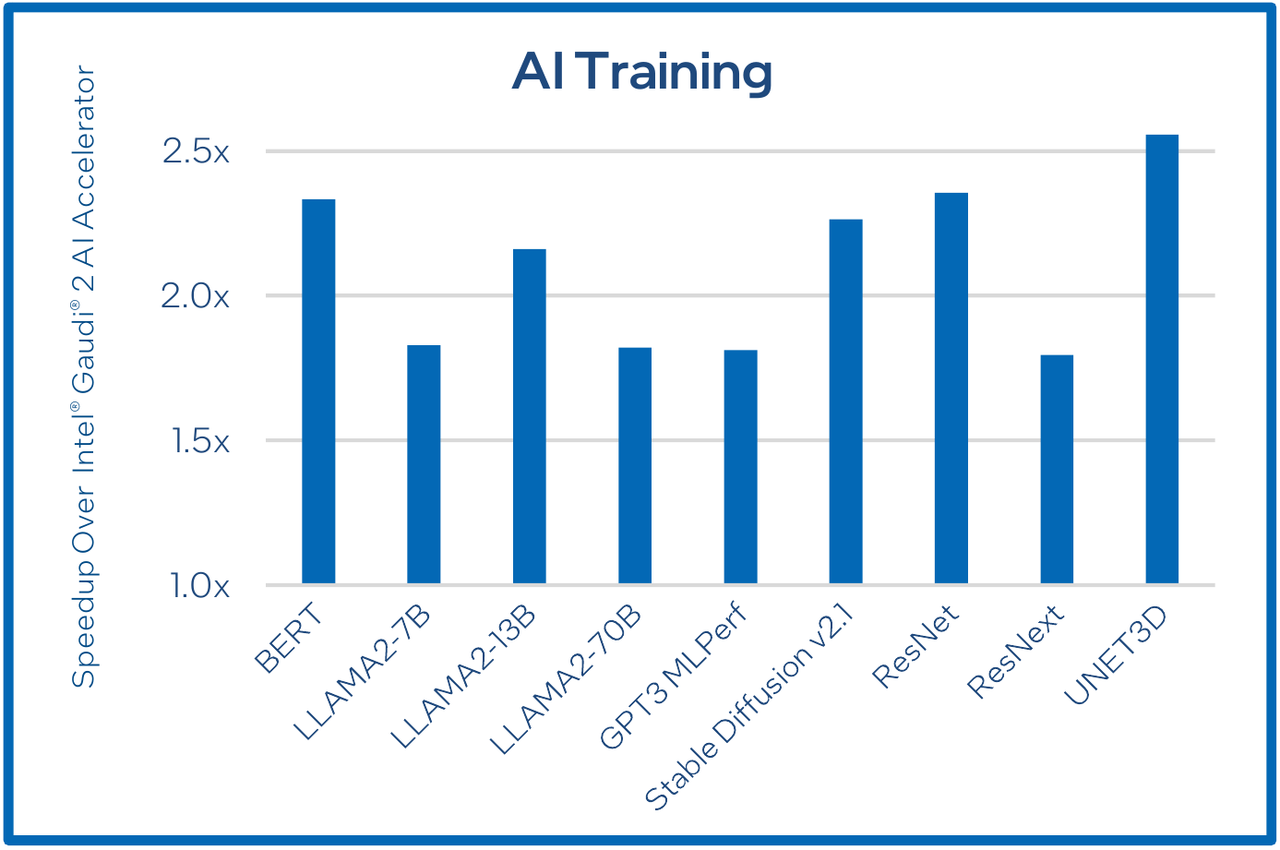
В инференс-тестах отрыв оказался чуть меньше, но и здесь минимальна разница составляет полтора раза. Что немаловажно для инференс-сценариев, серьёзно улучшились показатели латентности. Отчасти это заслуга не только серьёзно подросших «мускул» нового процессора, но и наличие большего объёма HBM, что позволяет разместить в памяти больше параметров и расширить контекстное окно.
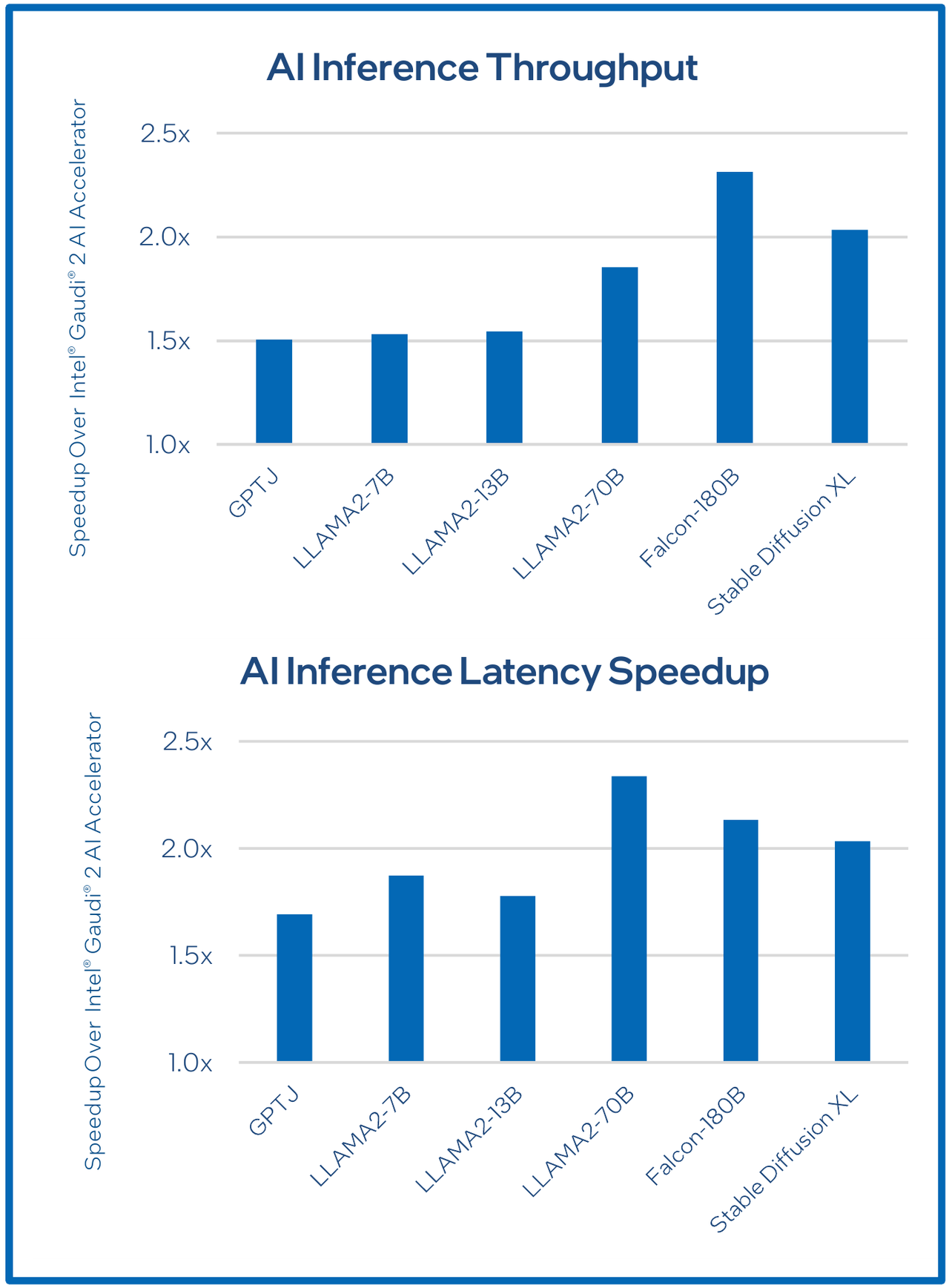
Опубликовала Intel и результаты сравнительного тестирования Gaudi3 против NVIDIA H100 в MLPerf, где новинка действительно выступила весьма достойно, в худшем случае демонстрируя 90% от производительности H100, а в отдельных тестах опережая конкурента более чем в 2,5 раза. Примерно так же распределились результаты и в тестах на энергоэффективность.
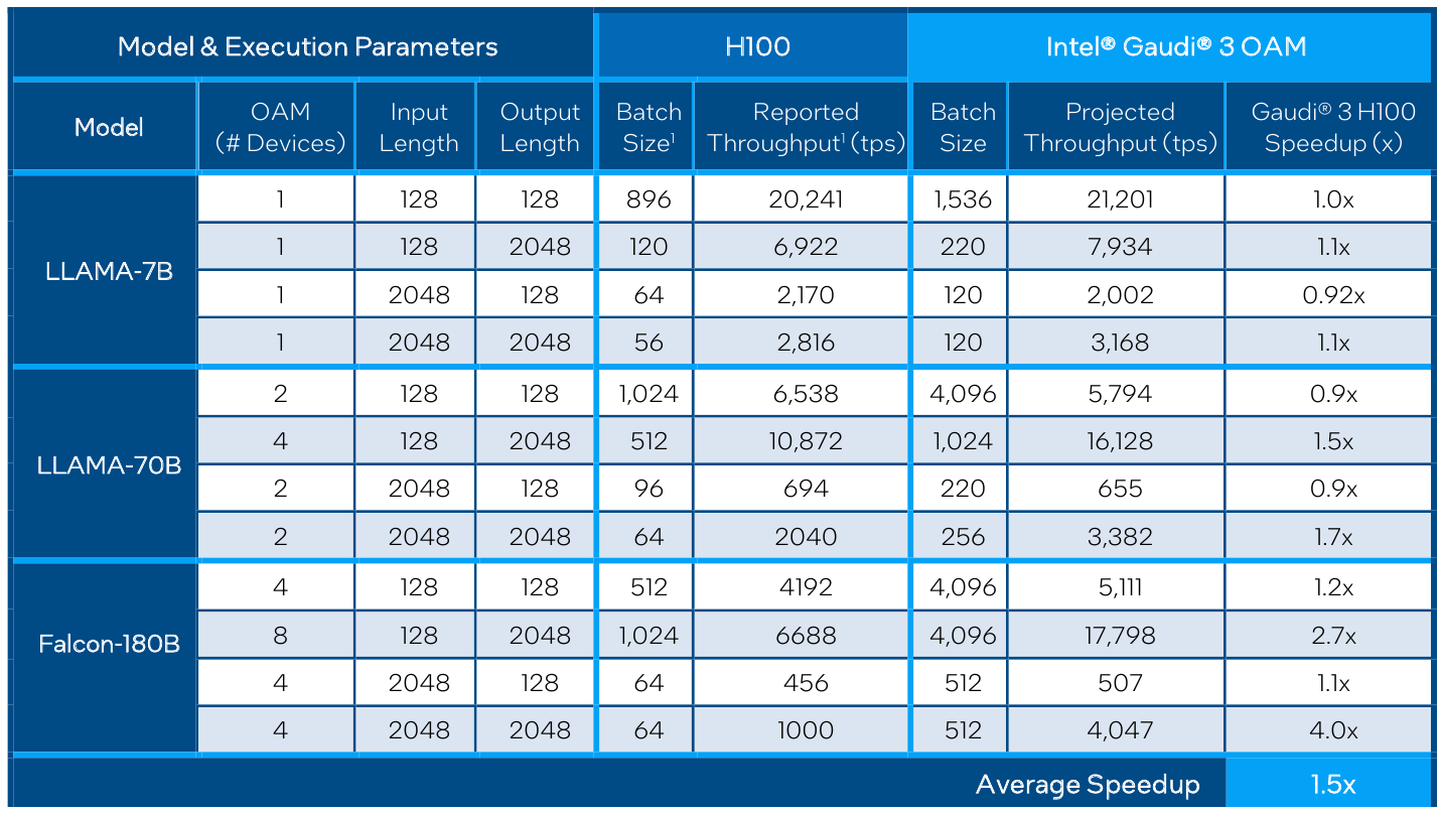
Что же касается инженерно-технической реализации, то на этот раз Intel представила сразу несколько вариантов ускорителей на базе Gaudi3, отличающихся как теплопакетом, так и конструктивом. Самым быстрым вариантом в семействе является модуль HL-325L OCP. Он выполнен в формате мезонинной платы OCP OAM 2.0 и поддерживает теплопакет 900 Вт для воздушного охлаждения и 1200 Вт — для жидкостного.
Для этой модели была специально разработана новая UBB-плата HLB-325L, приходящая на смену HLBA-225. Она поддерживает установку восьми ускорителей HL-325L, причём 21 сетевое подключение на каждом из них позволяет реализовать интерконнект по схеме «все со всеми», а оставшиеся подключения сведены через PAM4-ретаймеры в шесть 800GbE-портов OSFP для дальнейшего масштабирования кластера. Имеется и вывод PCI Express 5.0 с помощью PCIe-ретаймеров, также установленных на плате. HLB-325L рассчитана на питание 54 В, которое в последнее время становится всё популярнее в новых ЦОД и HPC-системах.
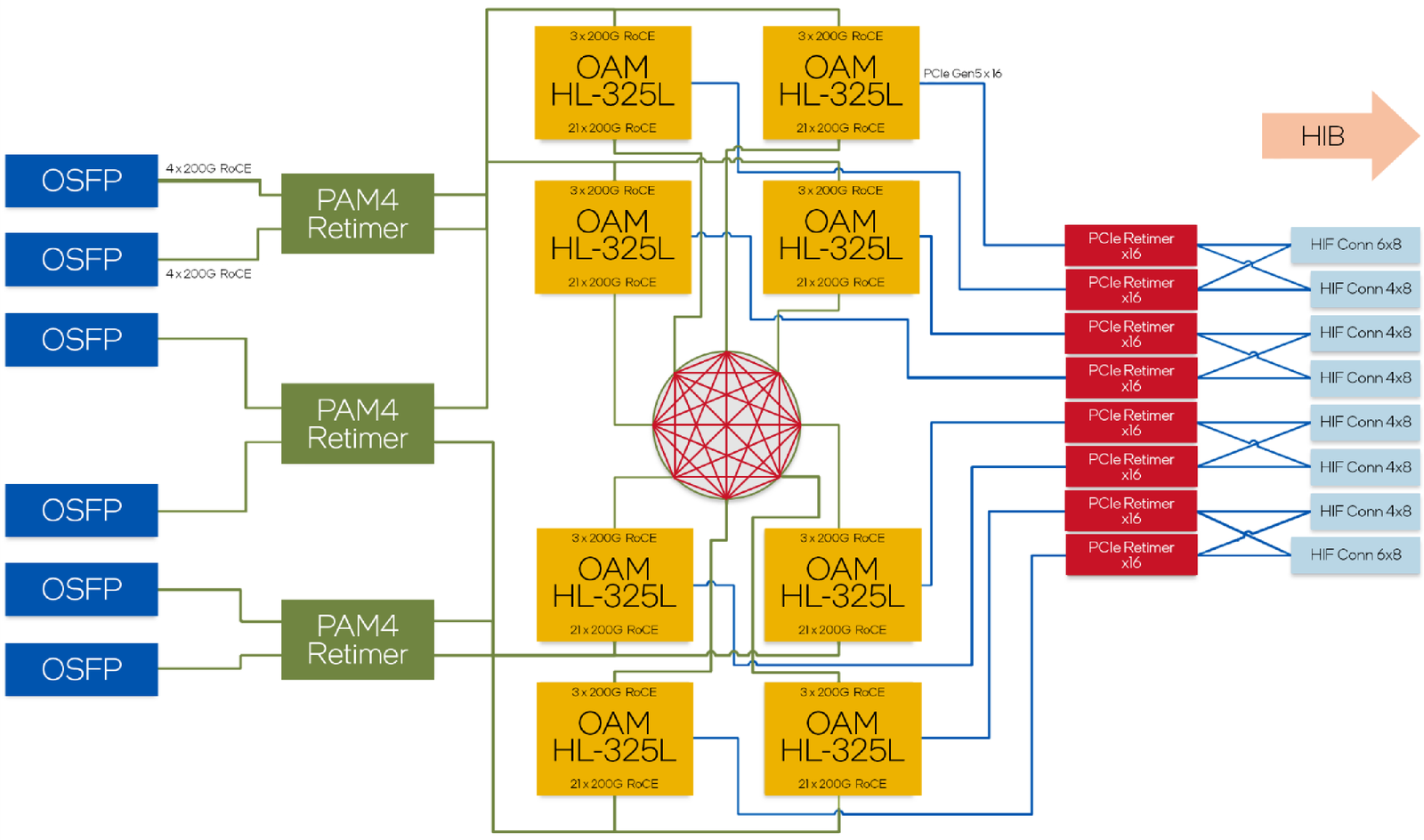
Топология базовой платы HLB-325L с восемью Gaudi3
Другой вариант Gaudi3 — ускоритель HL-338. Он представляет собой стандартную плату расширения PCIe с двумя внешними портами QSFP112 400GbE. Поддерживаются теплопакеты вплоть до 600 Вт при стандартном воздушном охлаждении. Дополнительный мостик HLTB-304, устанавливаемая поверх четырёх ускорителей HL-338, обеспечивает интерконнект за счёт 18 набортных линков 200GbE. Такая реализация кластера на базе Gaudi3 по понятным причинам будет несколько менее производительной, нежели вариант с OAM-модулями, но позволит обойтись стандартными аппаратными средствами и корпусами серверов.
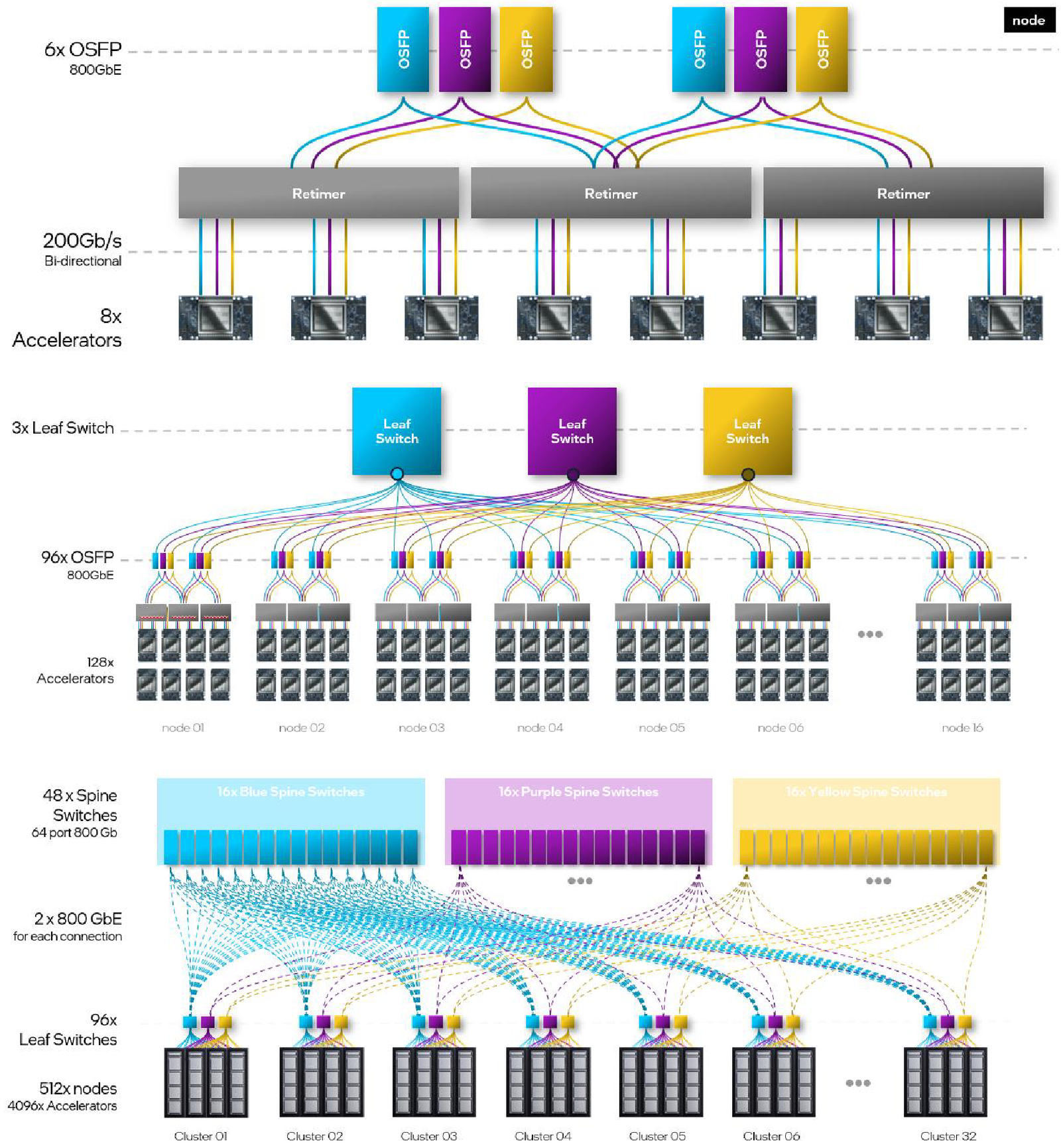
Масштабирование и кластеризация Gaudi3
Первые пробные партии ускорителей на базе Gaudi3 поступят избранным партнёрам Intel уже в этом полугодии. Вариант OAM с воздушным охлаждением уже тестируется в квалификационных лабораториях компании, а образцы с жидкостным охлаждением появятся позднее в этом квартале. В новинке заинтересованы Dell, HPE, Lenovo и Supermicro. Массовые поставки стартуют в III квартале 2024 года. Последними на рынке появятся PCIe-версии, их поставки намечены на IV квартал.
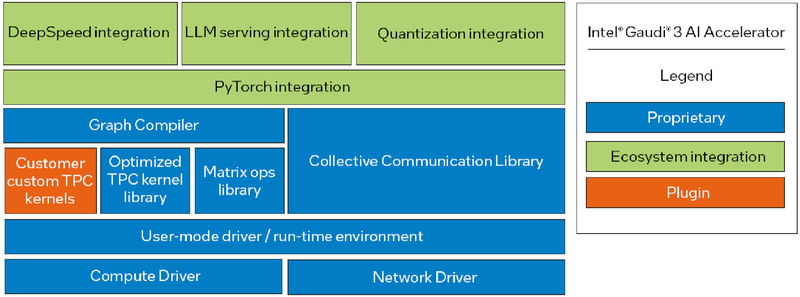
Программная экосистема Intel Gaudi
Intel Gaudi3 выглядит весьма неплохо. В нём устранены узкие места, свойственные Gaudi2, что позволяет тягаться на равных с NVIDIA H100 и H200, и даже заметно превосходить их в некоторых сценариях. Однако NVIDIA уже анонсировала архитектуру Blackwell. Впрочем, основная борьба развернётся не на аппаратном, а на программном уровне — Intel вслед за AMD упростила работу с PyTorch, что позволит перенести множество нагрузок на Gaudi. А там, глядишь, и UXL станет хоть какой-то альтернативой CUDA.
Источник:

