Материалы по тегу: nvme-of
|
24.11.2025 [09:09], Сергей Карасёв
IBM утроила вместимость СХД Storage Scale System 6000 — до 47 Пбайт на стойкуКорпорация IBM объявила о выпуске обновлённой СХД Storage Scale System 6000, предназначенной для работы с ресурсоёмкими ИИ-приложениями, а также с нагрузками, которым требуется интенсивный обмен большими объёмами информации. Платформа Storage Scale System 6000 дебютировала в конце 2024 года. Устройство типоразмера 4U оснащено двумя контроллерами, работающими в режиме «активный — активный». Применяются процессоры AMD EPYC Genoa 7642 (48C/96T; 2,3–3,3 ГГц; 225 Вт) или EPYC Embedded 9454 (48C/96T; 2,75–3,8 ГГц; 290 Вт), а максимальный объём оперативной памяти в расчёте на систему составляет 3072 Гбайт. Допускается установка 48 NVMe-накопителей. Также поддерживаются фирменные FCM-модули со сжатием на лету. Вместимость оригинальной версии достигала 2,2 Пбайт (при использовании комбинации SSD на 30 и 60 Тбайт). При подключении девяти дополнительных JBOD-массивов показатель вырастал до 15 Пбайт. Заявленная производительность — до 13 млн IOPS. Пропускная способность при чтении — до 330 Гбайт/с, при записи — до 155 Гбайт/с. 
Источник изображения: IBM В случае обновлённой модификации Storage Scale System 6000 реализована поддержка QLC-накопителей вместимостью до 122 Тбайт. Кроме того, представлены новые модули расширения All-Flash Expansion Enclosure стандарта 2U, рассчитанные на 26 двухпортовых накопителей QLC. В результате, общая ёмкость СХД в конфигурации в виде стойки 42U достигает 47 Пбайт, что примерно втрое больше по сравнению с оригинальным вариантом. При этом быстродействие поднялось до 28 млн IOPS, а пропускная способность в режиме чтения — до 340 Гбайт/с. В состав All-Flash Expansion Enclosure входят DPU NVIDIA BlueField-3 (до 4 шт.). Каждый модуль расширения может обеспечить пропускную способность до 100 Гбайт/с. Решение оптимизировано для обучения больших языковых моделей, инференса, НРС-задач и пр. В продажу изделие поступит в декабре; тогда же станет доступно улучшенное ПО для СХД — IBM Storage Scale System 7.0.0.
01.10.2025 [15:40], Владимир Мироненко
YADRO анонсировала поддержку NVMe over TCP — более доступной и производительной альтернативы FC и iSCSIКомпания YADRO объявила о предстоящем выходе технологии NVMe over TCP (Non-Volatile Memory Express с транспортным протоколом TCP), которая станет доступна с осенним релизом v3.2 СХД TATLIN.UNIFIED. Новое решение YADRO позволяет снизить задержки, увеличить производительность и достигнуть максимальной простоты работы с данными. Уже сейчас его можно протестировать в режиме предварительного доступа. Компания отметила, что работа по протоколу Fibre Channel (FC) становится сложнее из-за выросшей стоимости использования и сложности обслуживания оборудования, в то время как протокол iSCSI часто не отвечает требованиям задач бизнеса из-за ограничений по производительности и проблем с надёжностью и отказоустойчивостью. Согласно данным внутреннего тестирования, при использовании NVMe/TCP ускорение операций ввода-вывода по сравнению с FC составило до 30 %, сокращение задержек — 25 %. По сравнению с iSCSI новое решение обеспечивает производительность выше на 62 %. NVMe over TCP снижает нагрузку на операционную систему, упрощает процесс обнаружения изменений в хранилище и легко интегрируется с ОС на базе ядра Linux, позволяя оптимизировать скорость работы с ресурсоёмкими задачами и высоконагруженными корпоративными приложениями. Встроенная функция многопутевого ввода-вывода (Native NVMe Multipath) обеспечивает стабильную работу даже при подключении тысячи ресурсов/логических томов. 
Источник изображения: YADRO Также следует отметить доступную стоимость внедрения и простоту эксплуатации новой технологии. Для перехода на неё с iSCSI не требуется дополнительное оборудование, а при переходе с FC компания предлагает заказчикам решение на базе сетевых коммутаторов KORNFELD, которые поддерживают NVMe/TCP и интегрированы с СХД TATLIN для построения единой end-to-end NVMe-инфраструктуры. В настоящее время YADRO ведёт проработку интеграции технологии с решениями технологических партнёров. Некоторые из них уже выпустили или готовят к выпуску в ближайшее время собственных решений с использованием NVMe over TCP. Компания отметила, что помимо NVMe/TCP в релизе 3.2 будет представлен целый ряд улучшений, включая поддержку LACP на виртуальных портах для файлового доступа, VLAN на виртуальных портах для блочного и файлового доступа и Root squash для файловых ресурсов. Также будут увеличены лимиты ресурсов на систему и повышена производительность и безопасность.
29.08.2025 [23:15], Владимир Мироненко
11,5 Пбайт в 2U: Novodisq представил блейд-сервер для ИИ и больших данныхСтартап Novodisq представил блейд-сервер формата 2U ёмкостью 11,5 Пбайт с функцией ускорения ИИ и др. задач. Гиперконвергентная кластерная система разработан для замены или дополнения традиционных решений NAS, SAN и публичных облачных сервисов. Новинка поддерживает платформы Ceph, MinIO и Nextcloud (также планируется поддержка DAOS), предлагая доступ по NFS, iSCSI, NVMe-oF и S3. Сервер содержит до 20 модулей Novoblade с фронтальной загрузкой. В каждом из них имеется до четырёх встроенных E2 SSD Novoblade объёмом 144 Тбайт каждый, на базе TLC NAND с шиной PCIe 4.0 x4. Накопители поддерживают NVMe v2.1 и ZNS, обеспечивая последовательную производительность чтения/записи до 1000 Мбайт/с, а на случайных операциях — до 70/30 тыс. IOPS. Надёжность накопителей составляет до 24 PBW. Энергопотребление: от 5 до 10 Вт. Система Novoblade предназначена для «тёплого» и «холодного» хранения данных. Модули Novoblade объединяют вычислительные возможности, ускорители и хранилища. Основной модулей являются гибридные SoC AMD Versal AI Edge Gen 2 (для ИИ-нагрузок) или Versal Prime Gen 2 (для традиционных вычислений) c FPGA, 96 Гбайт DDR5, 32 Гбайт eMMC, модулем TPM2 и двумя интерфейсам 10/25GbE с RoCE v2 RDMA и TSN. Энергопотребление не превышает 60 Вт. Есть функции шифрования накопителей, декодирования видео, ускорения ИИ-обработки, оркестрации контейнеров и т.д. Платформа специально разработана для задач с большими объёмами данных, таких как геномика, геопространственная визуализация, видеоархивация и периферийные ИИ-вычисления. Сервер может работать под управлением стандартных дистрибутивов Linux (RHEL и Ubuntu LTS) с поддержкой Docker, Podman, QEMU/KVM, Portainer и OpenShift. 
Источник изображений: Novodisq 2U-шасси глубиной 1000 мм рассчитано на установку до двадцати модулей Novodisq и оснащено двумя (1+1) БП мощностью 2600 Вт каждый (48 В DC). Возможно горизонтальное масштабирование с использованием каналов 100–400GbE. В базовой конфигурации шасси включает четыре 200GbE-модуля с возможностью горячей замены, каждый из которых имеет SFP28-корзины, а также управляемый L2-коммутатор. Предусмотрен набор средств управления, включая BMC с веб-интерфейсом, CLI и поддержкой API Ansible, SNMP и Redfish. Novoblade поддерживает локальное и удалённое управление, может интегрироваться в существующий стек или предоставляться с помощью инструментов «инфраструктура как код» (Infrastructure-as-Code).  По словам разработчика, система Novoblade обеспечивает плотность размещения примерно в 10 раз выше, чем у сервера на основе жестких дисков, и снижает энергопотребление на 90–95 % без необходимости в механическом охлаждении. Novodisq утверждает, что общая стоимость владения системой «обычно на 70–90 % ниже, чем у традиционных облачных или корпоративных решений в течение 5–10 лет».  «Это обусловлено несколькими факторами: уменьшенным пространством в стойке, низким энергопотреблением, отсутствием платы за передачу данных, минимальным охлаждением, длительным сроком службы и значительным упрощением управления. В отличие от облака, ваши расходы в основном фиксированы, а значит, предсказуемы, и, в отличие от традиционных систем, Novodisq не требует дорогостоящих лицензий, внешних контроллеров или постоянных циклов обновления. Вы получаете высокую производительность, долгосрочную надёжность и более высокую экономичность с первого дня», — приводит Blocks & Files сообщение компании.  Для сравнения, узлы Dell PowerScale F710 и F910 на базе 144-Тбайт Solidigm SSD ёмкостью 122 Тбайт, 24 отсеками в 2U-шасси и коэффициентом сжатия данных 2:1 обеспечивают почти 6 Пбайт эффективной емкости, что почти вдвое меньше, чем у сервера Novoblade.
04.06.2025 [09:44], Сергей Карасёв
YADRO представила All-Flash СХД Tatlin.AFAРоссийская компания YADRO представила высокопроизводительную систему хранения данных Tatlin.AFA, предназначенную для решения задач крупных корпоративных клиентов. Утверждается, что это первое в России решение типа All-NVMe с возможностью установки SSD с интерфейсом PCIe 4.0/5.0 и поддержкой End-to-end NVMe. Устройство выполнено в форм-факторе 2U и оснащено двумя контроллерами в режиме Symmetric Active–Active. Каждый из контроллеров оборудован двумя процессорами Intel Xeon поколения Emerald Rapids. Объём памяти DDR5 ECC составляет 1,5 Тбайт. Предусмотрены дублированные батареи для обеспечения сохранности данных в кеше. СХД располагает 24 отсеками для NVMe SSD стандарта U.2 / U.3 вместимостью до 30 Тбайт каждый, что в сумме даёт до 720 Тбайт «сырой» ёмкости. Кроме того, могут быть подключены два модуля расширения S24N, каждый из которых также содержит два двухпроцессорных контроллера, 24 слота для накопителей и два 200GbE-порта с RocE. Таким образом, общая вместимость в конфигурации с двумя модулями S24N превышает 2 Пбайт. Заявленное быстродействие на операциях ввода/вывода в секунду (IOPS) составляет более 2 млн, а пропускная способность достигает 50 Гбайт/с. Поддерживаются протоколы FC, iSCSI, NVMe/TCP, NVMe/RoCE. Заявлена совместимость с VMWare Sphere 7.x / 8.x, «РЕД ОС Виртуализация», «Альт Сервер Виртуализация», ECP Veil / SE, zVirt 3.x / 4.x, «Горизонт ВС», BASIS (DE), ОС Windows Server 2016/2019/2022, Oracle Linux 7.x/8.x/9.x, Rocky Linux 9.x, SUSE Linux 12/15, Ubuntu Server, IBM AIX 7.2 / 7.3 (VIOS), Astra Linux 1.x, «РЕД ОС» 7.3/7.3.1/8.0, «Альт Сервер». 
Источник изображения: YADRO В зависимости от конфигурации доступны до 16/32 портов 10/25GbE, до 16 портов 100GbE или до 20 портов FC16/32/64. Предусмотрены пять слотов PCIe 5.0 x16 для сетевых адаптеров. Установлены два блока питания мощностью 3200 Вт с резервированием 1+1, поддержкой горячей замены и аккумуляторным модулем. Диапазон рабочих температур простирается от +10 до +30 °C. Упомянута собственная технология T-RAID с поддержкой различных схем защиты, резервирования компонентов и моментальных снимков. Реализованы следующие уровни защиты T-RAID: 8 + 1, 8 + 2, 8 + 3, 8 + 4, 8 + 5, 8 + 6, 8 + 7, 8 + 8, 10 + 1, 10 + 2, 10 + 3, а также 14 + 1 и 14 + 2. Использует программная платформа Tatlin.OS.
02.06.2025 [15:20], Владимир Мироненко
YADRO представила на ЦИПР первую отечественную All-NVMe систему хранения данных TATLIN.AFAКомпания YADRO объявила о выходе первой на российском рынке All-Flash системы хранения данных TATLIN.AFA с end-to-end NVMe-архитектурой — от накопителей до протоколов доступа, представленной на десятой конференции «Цифровая индустрия промышленной России» (ЦИПР-2025). В настоящее время система проходит серии внутренних нагрузочных испытаний и в ближайшее время станет доступна для тестирования в прикладных сценариях у заказчиков. TATLIN.AFA — система хранения данных старшего уровня с рекордной производительностью, высокой надёжностью и отказоустойчивостью для решения самых амбициозных и требовательных задач настоящего и будущего. Продукт, полностью разработанный инженерами YADRO и произведённый в России, нацелен на использование в крупных организациях с повышенными требованиями к скорости, надёжности и масштабируемости ИТ-инфраструктуры. Решение позволяет успешно справляться с самыми ресурсоёмкими задачами — от поддержки критически важных и высоконагруженных приложений и баз данных, до обслуживания таких перспективных нагрузок, как машинное обучение и ИИ. 
Источник изображений: YADRO TATLIN.AFA, флагманская СХД линейки TATLIN, разработанная на базе собственной модульной аппаратной платформы компании YADRO TATLIN.X, отличается высокой производительностью: до 2 млн операций ввода-вывода в секунду (IOPS) и пропускная способность 50 Гбайт/с. Такая эффективность стала возможной благодаря использованию современных технологий в платформе YADRO TATLIN.X: мощнейших процессоров, PCIe 5.0, кеш-памяти объёмом не менее 1,5 Тбайт DDR5. Система объединяет два контроллера хранения и 24 NVMe-накопителя в 2U-шасси. Запланирована возможность расширения дисковой ёмкости путём добавления до двух интеллектуальных дисковых модулей S24N с 24 накопителями NVMe.  Что немаловажно, TATLIN.AFA поддерживает протокол NVMe-over-Fabrics, который позволяет раскрыть потенциал флеш-накопителей и обеспечивает максимально эффективный доступ к данным с приростом производительности до 50 % в типовых сценариях работы с высоконагруженными базами данных, аналитическими системами и многопользовательскими приложениями. Также отмечено, что система обеспечивает самый высокий уровень надёжности. Предлагаемые наряду с уже известными и пользующимися на рынке заслуженной репутацией технологиями YADRO — такими как режим работы контроллеров хранения Symmetric Active-Active, резервирование ключевых компонентов и оригинальная технология защиты данных T-RAID, гарантирующая бесперебойную работу и сохранность информации даже при одновременном выходе из строя до восьми накопителей — системы TATLIN.AFA получили дополнительные степени защиты. В их числе, например, дублирование аккумуляторных батарей, каждая из которых способна обслуживать весь объём кеша в случае сбоя, и резервирование системных накопителей в контроллерах.  Встроенная компрессия на лету с аппаратным ускорением эффективно оптимизирует использование хранилища без ощутимого падения производительности. Также обновлённая версия T-RAID с возможностью использования схемы защиты до 14+2 обеспечивает высокую полезную ёмкость при гарантированной надёжности. «TATLIN.AFA — это результат всего накопленного практического опыта YADRO в сфере разработки высокопроизводительных СХД. Мы создавали продукт, который поможет бизнесу не просто работать с данными, а уверенно расти и масштабироваться в условиях возрастающих требований и цифровой трансформации. В систему заложены самые современные технологии, чтобы обеспечивать надёжную работу в самыми ресурсоёмкими нагрузками. TATLIN.AFA станет оптимальным выбором для цифровых платформ, финансового и промышленного сектора, государственных организаций и всех компаний с потребностью в высокопроизводительной ИТ-инфраструктуре», — отметил Егор Литвинов, директор продуктового направления TATLIN YADRO.
16.04.2025 [13:01], Сергей Карасёв
Pure Storage анонсировала младшую All-Flash СХД FlashArray//RC20 для периферийных развёртыванийКомпания Pure Storage анонсировала СХД FlashArray//RC20 типа All-Flash, оптимизированную для сравнительно небольших рабочих нагрузок и периферийных развёртываний. Новинка, как утверждается, предлагает такие преимущества, как энергетическая эффективность, гибкость, безопасность и отказоустойчивость. Решение выполнено в форм-факторе 3U. Суммарная «сырая» вместимость установленных накопителей может варьироваться от 148 до 260 Тбайт, тогда как эффективная ёмкость с дедупликацией и сжатием достигает 918 Тбайт. Реализована поддержка NVME-oF (Fibre Channel, RoCE, TCP). Платформа использует б/у контроллеры, которые прошли проверку и обновление у Pure Storage. По заявлениям Pure Storage, система FlashArray//RC20 обеспечивает экономию физического пространства до 95 % по сравнению с гибридными массивами на основе SSD и HDD. Потребление энергии может быть снижено на 85 % по отношению к конкурирующим изделиям All-Flash. 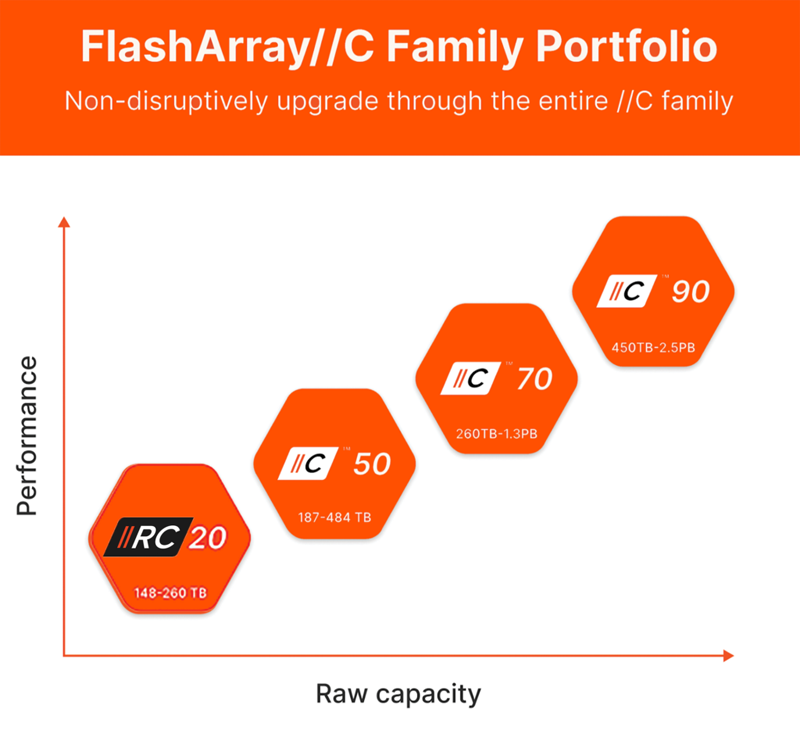
Источник изображения: Pure Storage Pure Storage предлагает набор решений по кибербезопасности, включая специализированные инструменты на основе ИИ и асинхронную репликацию. По умолчанию активированы средства SafeMode, определяющие ряд политик для защиты данных. В частности, неизменяемые снимки SafeMode предотвращают уничтожение информации даже в случае компрометации учётных данных администратора. Заявленное пиковое энергопотребление составляет 720–888 Вт. Компания Pure Storage подчёркивает, что в отличие от других систем начального уровня, FlashArray//RC20 может быть обновлена до более мощных версий в семействе FlashArray//C без необходимости прерывания работы. В целом, новинка предлагает экономичный вариант миграции с гибридных СХД на платформы All-Flash.
10.04.2025 [11:27], Сергей Карасёв
SSD с «хвостиком»: Kioxia представила «оптические» SSD для дата-центров следующего поколенияКомпании Kioxia, AIO Core и Kyocera объявили о разработке прототипа SSD с оптическим интерфейсом, совместимого с PCIe 5.0. Изделие ориентировано на дата-центры следующего поколения, рассчитанные на ресурсоёмкие нагрузки, включая приложения ИИ с высокой интенсивностью обмена данными. О разработке «оптических» твердотельных накопителей Kioxia сообщала в августе прошлого года. Речь идёт об использовании оптического интерфейса подключения вместо традиционного электрического. Новый подход позволяет устранить влияние посторонних электромагнитных помех. При этом длина соединения может достигать 40 м с последующим увеличением до 100 м. В представленном прототипе SSD задействованы оптический трансивер IOCore разработки AIO Core и технология оптоэлектронной интеграции Optinity компании Kyocera. Реализованная оптическая система, как утверждается, позволяет устройству функционировать на скоростях интерфейса PCIe 5.0. 
Источник изображения: Kioxia Разработка «оптического» SSD осуществляется в рамках японского проекта JPNP21029 «Развитие технологий зелёных центров обработки данных следующего поколения». Он субсидируется Организацией по развитию новых энергетических и промышленных технологий (NEDO). Цель инициативы заключается в сокращении энергопотребления ЦОД более чем на 40 % по сравнению с нынешними площадками. В рамках проекта Kioxia отвечает за SSD нового типа, тогда как AIO Core и Kyocera создают оптоэлектронные компоненты. Предполагается, что появление «оптических» SSD откроет новые возможности в плане проектирования дата-центров. Представленная технология позволит значительно увеличить физическое расстояние между вычислительными и запоминающими устройствами, обеспечивая при этом энергоэффективность и высокое качество сигнала.
02.04.2025 [18:50], Сергей Карасёв
QSAN представила СХД серии XN5 типа All-NVMe с процессорами Intel XeonКомпания QSAN Technology анонсировала системы хранения данных (СХД) семейства XN5, предназначенные для работы с ресурсоёмкими нагрузками, связанными с ИИ, машинным обучением, виртуализацией и другими вычислительными процессами. Устройства выполнены в форм-факторе 2U на аппаратной платформе Intel. Новинки относятся к решениям All-NVMe: они рассчитаны на работу с SSD формата SFF U.2 с интерфейсом PCIe 4.0. Во фронтальной части предусмотрены 26 отсеков для таких накопителей, а суммарная внутренняя ёмкость может достигать 798 Тбайт. Поддерживается горячая замена SSD. Анонсированы модели XN5226D-12C и XN5226S-12C. Первая оснащена двумя контроллерами в режиме «активный — активный» с двумя неназванными 12-ядерными процессорами Xeon. В базовую комплектацию входят 32 Гбайт памяти DDR4 с возможностью расширения до 2 Тбайт. Также предусмотрены четыре слота расширения PCIe 4.0 x8, два порта 2.5GbE RJ45 и восемь портов 25GbE SFP28. Модификация XN5226S-12C, в свою очередь, оснащена одним контроллером, одним 12-ядерным процессором Xeon, 16 Гбайт ОЗУ (расширяется до 1 Тбайт), двумя слотами PCIe 4.0 x8, одним портом 2.5GbE RJ45 и четырьмя портами 25GbE SFP28. 
Источник изображения: QSAN Technology Устройства могут комплектоваться адаптерами 10GbE SFP+, 10GbE RJ45, FC16 и FC32 с двумя или четырьмя портами. Поддерживается подключение модулей расширения с SFF SSD и LFF HDD с интерфейсом SAS: в максимальной конфигурации количество накопителей достигает 546 штук, а суммарная ёмкость — до 16,8 Пбайт. Возможно формирование массивов RAID 0/1/5/6/10/50/60/5EE/6EE/50EE/60EE. В качестве программной платформы используется QSM 4. Заявлена поддержка протоколов CIFS, NFS, FTP, WebDAV, iSCSI, FCP, NVMe-oF. За электропитание отвечают два блока мощностью 850 Вт с сертификатом 80 Plus Platinum. Охлаждение обеспечивается системой воздушного охлаждения. Габариты составляют 88 × 438 × 573 мм, масса — 19,6 кг (без установленных накопителей). На устройства предоставляется пятилетняя гарантия.
27.03.2025 [09:11], Алексей Степин
Seagate представила свежие прототипы NVMe HDDSeagate представила своё видение СХД для ИИ-фабрик. Компания отмечает, что объёмы данных, используемых при обучении современных моделей, огромны и, согласно Seagate, хранить их целиком на флеш-массивах невыгодно для большинства предприятий и стартапов. Ответом являются гибридные массивы, сочетающие флеш-память и традиционную дисковую механику. Идея таких СХД не нова сама по себе, но реализация, предлагаемая Seagate, лишена атавизмов — проприетарных контроллеров, преобразования протоколов и всего прочего, на чём держится традиционная инфраструктура SAS/SATA. Основой новой архитектуры станет стандарт NVMe с единым драйвером, который вкупе со средствами ОС позволит слаженно работать SSD и HDD. Это важное отличие от уже имеющихся решений, например, от StorONE, где HDD действительно могут быть использованы в составе хранилища NVM-oF, но подключаются они всё равно по SAS/SATA. На уровне отдельных механических дисков сам по себе переход на NVMe выигрыша не принесёт, поскольку ограничивающим фактором останется время поиска дорожки, но на уровне массива с поддержкой GPUDirect и NVMe-oF выигрыш будет существенным. NVMe-oF упростит масштабирование таких систем и позволит реализовать распределённую архитектуру хранения данных в полной мере, отмечает Blocks & Files. 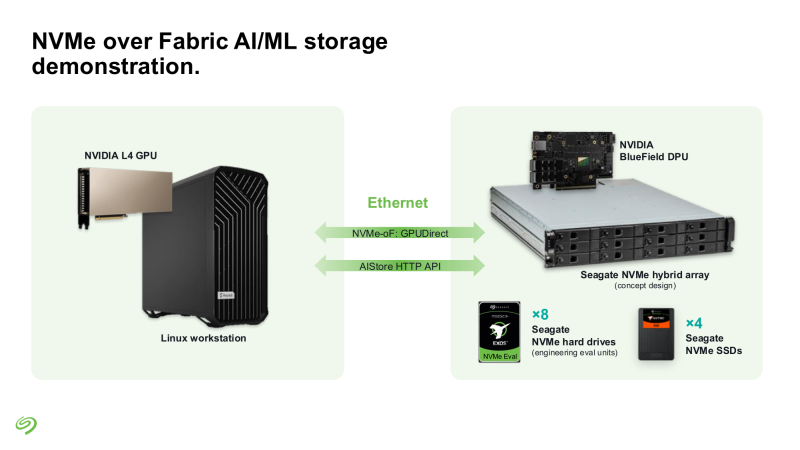
Источник изображений: Seagate Гибридные массивы в этой схеме напрямую подключаются к GPU-серверам. За счёт агрегации доступа ко множеству накопителей скорость может быть существенно увеличена (о чём говорила когда-то и Toshiba), а простота подключения будет достигнута за счёт единого стандарта — NVMe. В новых массивах предусмотрено место для DPU, благодаря которым и будет реализована поддержка RDMA и GPUDirect. На конференции NVIDIA GTC 2025 Seagate уже продемонстрировала прототип такого массива на базе BlueField-3 и MiniIO AIStore v2.0. 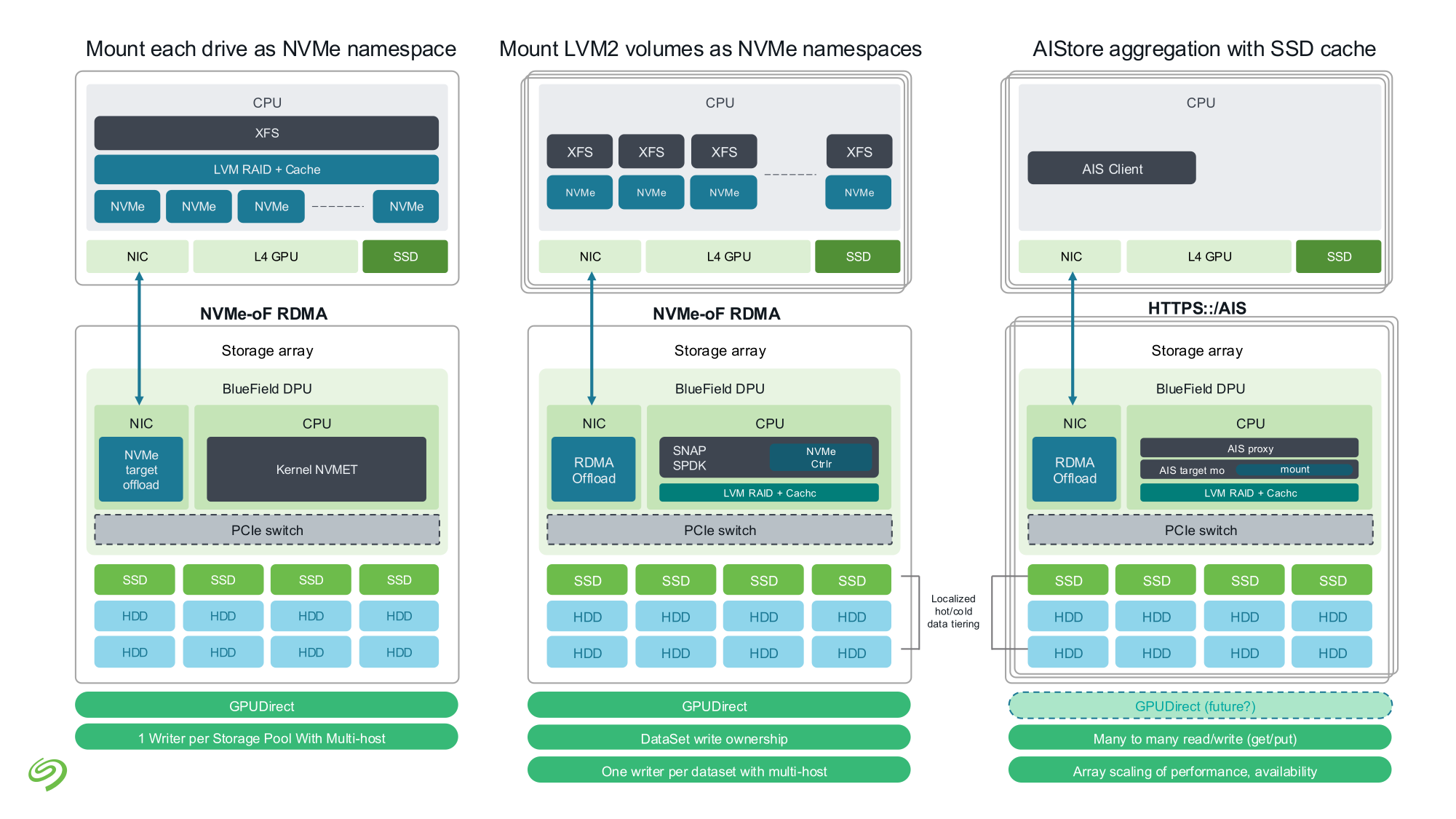 Данный прототип был оснащён восемью инженерными образцами NVMe HDD и четырьмя NVMe SSD. Даже будучи на уровне концепта, он показал, что прямое сообщение между ускорителями и подсистемой хранения данных позволяет снизить латентность доступа в ИИ-сценариях. Также благотворное влияние на производительность при обучении ИИ-моделей оказывает применение средств динамического кеширования и иерархизации (tiering). 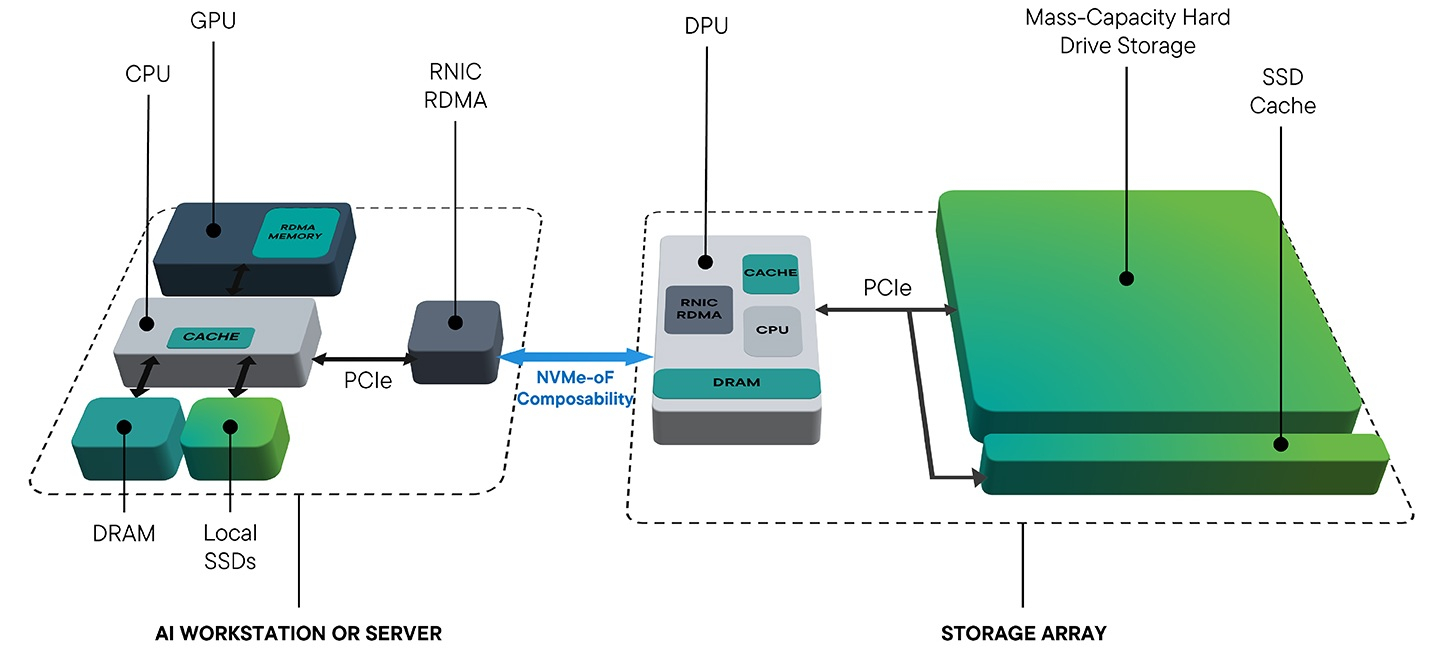 Seagate считает, что у традиционных жёстких дисков с интерфейсом NVMe есть большое будущее, и они найдут своё место во многих отраслях, от медицины и финансовой аналитики до самоуправляемого транспорта и ИИ-фабрик гиперскейлеров. В сравнении с SSD называются следующие преимущества:
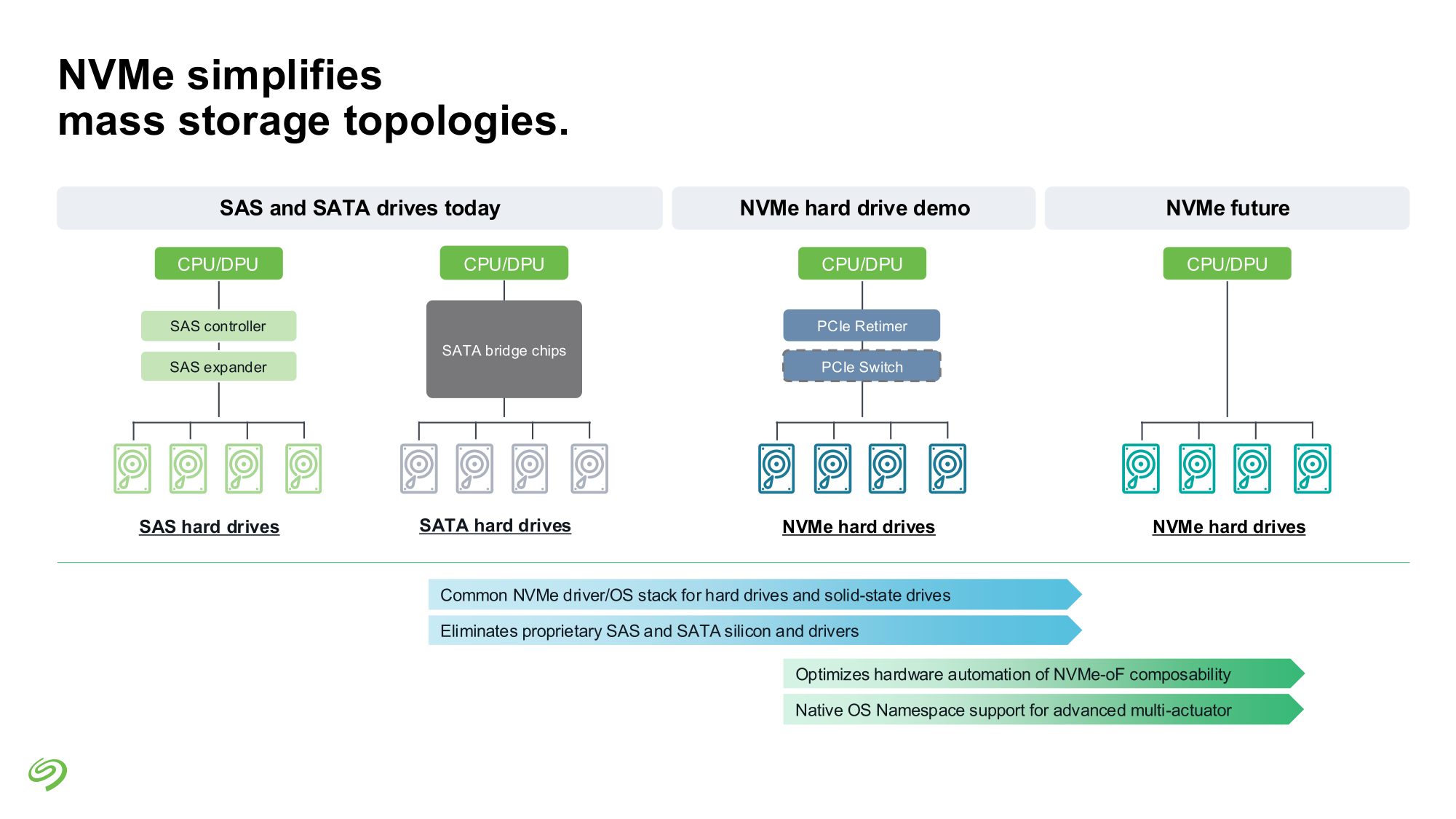 В планах компании значится создание NVMe HDD на базе HAMR объёмом до 36 Тбайт и более на платформе Mozaic, а также разработка референсных архитектур и дальнейшее продвижение технологии NVMe-oF. Надо сказать, что опыт создания жёстких дисков с этим интерфейсом у Seagate есть — ещё в ноябре 2021 году компания продемонстрировала дисковую полку с 12 LFF HDD, доступ к которой осуществлялся с помощью PCIe 3.0. За основу была взята модель Exos объёмом 18 Тбайт.  Toshiba и Western Digital на тот момент инициативу Seagate не поддержали, и на данный момент ситуация пока остаётся прежней — два других крупных производителя HDD хранят молчание о планах по внедрению NVMe в механические накопители. Если конкуренты всё-таки предложат свою альтернативу, потенциальные заказчики смогут избежать привязки к вендору, да и на популяризации самой технологии NVMe-массивов это скажется благотворно. Тем более что поддержка HDD уже давно прописана в стандарте NVMe 2.0.
06.03.2025 [13:45], Сергей Карасёв
1,5 Пбайт в 2U и 120 Гбайт/с: PEAK:AIO представила обновлённое All-Flash хранилище AI Data ServerБританский стартап PEAK:AIO анонсировал обновлённую платформу хранения данных AI Data Server, предназначенную для поддержания ресурсоёмких нагрузок ИИ. Сервер в форм-факторе 2U на основе SSD производства Solidigm обеспечивает 1,5 Пбайт «сырой» вместимости. PEAK:AIO утверждает, что благодаря новому программному стеку NVMe устраняются «узкие места Linux», что обеспечивает высокую производительность для приложений ИИ с интенсивным использованием данных. AI Data Server — это программно-определяемое хранилище на стороннем оборудовании. В частности, применяется сервер Dell PowerEdge R7625, оборудованный сетевыми адаптерами NVIDIA ConnectX-7. Заявленная пропускная способность достигает 120 Гбайт/с. Система комплектуется накопителями Solidigm D5-P5336 вместимостью 61,44 Тбайт. Эти изделия выполнены на 192-слойных чипах флеш-памяти QLC 3D NAND и оснащены интерфейсом PCIe 4.0 x4 (NVMe 2.0). Скорость последовательного чтения/записи достигает 7000/3000 Мбайт/с, показатель IOPS при произвольном чтении — 1 005 000. Сервер комплектуется 24 накопителями, что в сумме обеспечивает около 1,5 Пбайт ёмкости. 
Источник изображения: PEAK:AIO Платформа AI Data Server может использоваться для решения различных задач в специфичных областях, таких как здравоохранение, исследования и периферийные приложения ИИ. Подобные нагрузки требуют наличия высокопроизводительного хранилища, но зачастую доступ к инфраструктуре ЦОД у организаций из указанных отраслей ограничен. Система AI Data Server позволяет устранить данный пробел: она может масштабироваться от единичных узлов до кластеров, рассчитанных на огромные озера данных ИИ. |
|

