Материалы по тегу: сбой
|
16.10.2022 [00:20], Руслан Авдеев
Ирландский авиаперевозчик Aer Lingus требует от Kyndryl компенсации за сбой сети, который привёл к отмене более 50 рейсовИрландский авиаперевозчик Aer Lingus намерен получить от Kyndryl, в своё время отделившейся от IBM, компенсацию — как сообщает The Register, в результате неудачного стечения обстоятельств авиаперевозчик лишился доступа к своей инфраструктуре в двух дата-центрах, что привело к отмене более 50 рейсов и значительным финансовым убыткам. Причиной инцидента, произошедшего месяц назад, стало повреждение во время строительных работ оптоволоконного кабеля, связывавшего терминалы компании с ЦОД. На беду ирландского авиаперевозчика, на резервной линии одновременно отказала сетевая карта, в результате чего из Дублина не смогли вовремя вылететь десятки тысяч пассажиров, многие из которых теперь требуют материальной компенсации. 
Источник изображения: Aer Lingus По словам главы Aer Lingus, отказ основной и резервной линий связи привели к задержке вылета 32 тыс. человек, а сама авиакомпания почти 10 часов не имела доступа к своим сервисам — от возможности регистрации пассажиров до доступа к данным о бронировании и даже контактным данным клиентов, связаться с которыми не было почти никакой возможности. Компания уже получила 7,5 тыс. заявлений о денежной компенсации от «одного или более пассажиров». Точная сумма ущерба неизвестна, но он исчисляется миллионами евро. 
Источник изображения: Aer Lingus Отмечается, что соглашение с Kyndryl предусматривало резервирование, поэтому ожидалось, что система окажется более надёжной. Примечательно, что, по данным сервис-провайдера, ни одна из 4000 сетевых карт, находившихся в эксплуатации, ранее никогда не выходила из строя. Подчёркивается, что резервная линия постоянно эксплуатировалась и тестировалась наравне с основной, поэтому речь действительно идёт об исключительной ситуации. Сообщается, что пострадали и другие клиенты ЦОД, но, похоже, их ущерб несопоставим с тем, который ожидает Aer Lingus. Ситуацией незамедлительно воспользовались конкуренты — Ryanair тут же предложила «спасательные рейсы» по цене €100, которыми многие воспользовались после того, как стало понятно, что запланированные полёты не состоятся. В Aer Lingus сообщают, что внедрили новую систему мониторинга своей сети и запланировали использовать «тройную систему» резервирования сервисов для большей надёжности.
26.07.2022 [20:28], Руслан Авдеев
После тотального сбоя всех систем канадский оператор Rogers пообещал потратить $7,7 млрд на повышение надёжности связиКанадский телекоммуникационный гигант Rogers, по вине которого пятницу 8 июля 2022 года остались без связи миллионы абонентов мобильной и стационарной связи, пообещал инвестировать $7,7 млрд (C$10 млрд) в повышение надёжности систем и принять ряд мер по недопущению подобных сбоев в будущем. Об этом сообщает издание The Register. Известно, что сбой соединений, произошедший ранним утром, был вызван попыткой обновления конфигурации роутеров компании, что неожиданно привело к отключению практически всех систем. Пострадали мобильная связь, кабельное телевидение, широкополосный интернет-доступ и даже некоторые радиостанции. Известно, что без соединения остались порядка 10 млн пользователей сотовой связи, лишившиеся возможности даже связаться с экстренными службами. 
Источник изображения: mwangi gatheca/unsplash.com По словам компании, в будущем будет принят ряд мер для того, чтобы не допустить перегрузку главных роутеров в подобных масштабах, а также разделить проводной и беспроводной сегменты таким образом, что при отключении одного канала у пользователей оставался бы резервный способ связи. Кроме того, в Rogers заявили, что уже достигнут значительный прогресс в заключении официального соглашения с канадскими операторами связи для перекрёстного обеспечения звонков в экстренные службы (911) в любых условиях. Компания уже заключила соглашение о партнёрстве с неназванной «ведущей технологической фирмой» для полного аудита сети. Многомиллиардные инвестиции будут осуществляться в течение трёх ближайших лет. Тем не менее, канадский регулятор Canadian Radio-television and Telecommunications Commission (CRTC) напомнил, что нечто подобное уже случилось с сетью Rogers в апреле 2021 года. Тогда оператор тоже списал все проблемы на обновление программного обеспечения. Теперь регулятор затребовал «всеобъемлющую информацию» об инциденте, вызвавшем отказ всех систем, а также о том, что происходило во время и после сбоя. Компания уже опубликовала соответствующий отчёт. Хотя в основном связь восстановилась уже к вечеру пятницы, некоторые клиенты испытывали проблемы в течение всех выходных.
20.07.2022 [15:56], Владимир Мироненко
Аномальная жара привела к сбоям в лондонских дата-центрах Google и OracleВо вторник, 19 июля, в ЦОД Google Cloud Platform (GCP) в Лондоне произошёл сбой в системе охлаждения, в связи с чем несколько сервисов компании временно вышло из строя. В лондонском регионе облака Oracle тоже возникли проблемы с охлаждением оборудования ЦОД. Сбои произошли из-за рекордной жары в Великобритании — температура превысила +40°C. Некоторые операторы дата-центров были вынуждены принять нестандартные меры, начав обрызгивать водой внешние модули систем кондиционирования, установленные на крыше. Отключение ряда сервисов Google произошло в 18:13 по местному времени (20:13 мск). В журнале статуса оборудования сбой описан как «связанный с охлаждением». Google заявила, что сбой затронул лишь небольшое количество клиентов. В частности, отключение коснулось сервисов Persistent Disk и Autoscaling. Хотя Google утверждает, что сбой продолжался до 22:00 BST (24:00 мск), в означенное время всё ещё поступали жалобы на ошибки в работе Persistent Disk. 
Изображение: pixabay.com / Gam-Ol С подобными проблемами в Лондоне столкнулась и облачная служба Oracle. Проблемы с перегревом у неё начались примерно в 17:00 по местному времени (19:00 мск). Oracle ранее арендовала ресурсы в ЦОД Equinix в лондонском кампусе Слау, но сейчас не раскрывает местонахождение своих мощностей. «В результате несезонных температур в регионе возникла проблема с частью инфраструктуры охлаждения в центре обработки данных на юге Великобритании (в Лондоне), — говорится в сообщении компании. — Это привело к тому, что часть нашей сервисной инфраструктуры пришлось отключить, чтобы предотвратить неконтролируемые сбои оборудования».
09.06.2022 [19:28], Руслан Авдеев
Число сбоев IT-систем с годами не уменьшается, а главной их причиной стали перебои с электропитаниемСогласно докладу 2022 Outage Analysis Report, представленному Uptime Institute, несмотря на усилия, прилагаемые операторами информационных систем и активные инвестиции в инфраструктуру, число сбоев в IT-системах остаётся приблизительно на том же уровне, что и в прошлые годы. Хотя инвестиции в облачные технологии и отказоустойчивые системы помогли повысить надёжность на уровне объектов инфраструктуры, попутно увеличилась сложность систем, что оказывает негативное влияние на надёжность. В частности, растёт число инцидентов, связанных с сетями связи, ПО и другими факторами. Авторы доклада подчёркивают, что хотя десятилетия работы над критическими IT-системами сделали их намного надёжнее, число незапланированных отключений за последние годы почти не изменилось. В 80 % организаций отключения IT-инфраструктуры случались хотя бы раз за последние три года, а каждый пятый опрошенный заявил о «серьёзных» и «тяжёлых» сбоях в тот же период. В первом случае по классификации Uptime Institute речь идёт о перебоях в работе сервисов с возможными финансовыми потерями, во втором — о крупных инцидентах, ведущих к большим финансовым потерям. По статистике Uptime, ежегодно в мире происходит приблизительно серьёзных 20 инцидентов, ведущих к крупным убыткам, репутационным издержкам и массовым проблемам в работе бизнесов и/или клиентов. 
Источник изображения: Florian Krumm/pixabay.com Любопытно, что основной причиной инцидентов являются перебои электропитания — это главный фактор в 43 % случаев. При этом дело редко обходится без сопутствующих причин. В числе прочих факторов — проблемы с программным обеспечением, сетями и системами охлаждения. Также выяснилось, что за 5 лет облачные операторы, хостинг- и колокейшн-провайдеры чаще всего виноваты в проблемах публичных сервисов, причём в 2021 году этот показатель вырос до 71 %. Примечательно, что продолжительность сбоев продолжает увеличиваться. Это не может не беспокоить пользователей, поскольку простой тем дороже и разрушительнее, чем он длительнее. В 2021 году число сбоев, длившихся более 48 часов, составляло 16 %, а в 2017 году — 4 %. От 24 до 48 часов — 12 % в сравнении с 4 % в 2017 году. Выросли и убытки. Если в 2019 году 60 % крупных сбоев обходились дешевле $100 тыс., 28 % — от $100 тыс. до $1 млн, то в 2021 году показатели выросли до 39 % и 47 % соответственно. Число сбоев, обошедшихся дороже $1 млн, выросло с 11 до 15 %.
08.06.2022 [16:03], Руслан Авдеев
Связанные одним линком: повреждение кабеля в Египте на несколько часов вызвало сбои в работе Сети по всему мируДоступность многих интернет-сервисов на некоторое время пострадала в результате сбоев, начавшихся на Ближнем Востоке и в Азии, а позже распространившихся буквально на весь мир. По данным OVHcloud, сбои наблюдались с 15:24 по 18:00 МСК 7 июня (с 12:24 по 15:00 UTC). Кабельная система Asia-Africa-Europe-1 (AAE-1) протяжённостью 25 тыс. км соединяет Юго-Восточную Азию с Европой, её фрагмент пролегает по суше на территории Египта, где она, судя по всему, и был повреждена. По данным экспертов, это вызвало перебои с интернетом на востоке Африки, на Ближнем Востоке и в Азии, включая Пакистан, Сомали, Джибути и Саудовскую Аравию. После этого проблемы начались и в других регионах. 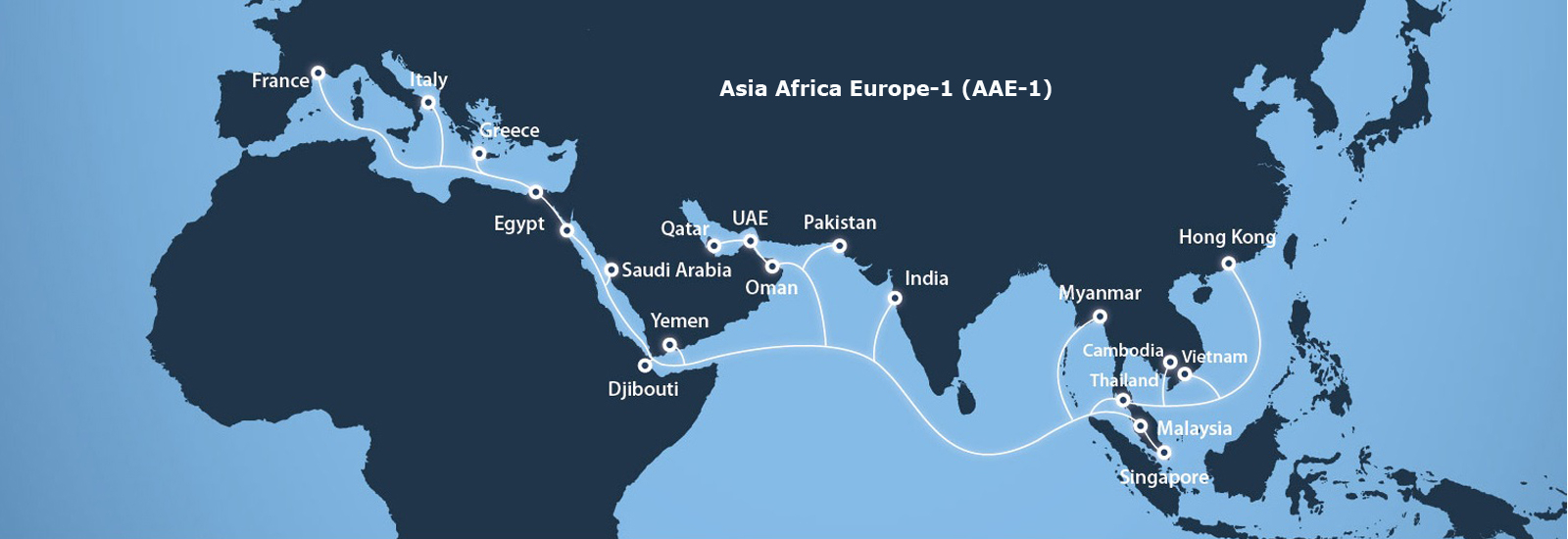
Источник: www.aaeone.com Эксперты утверждают, что инцидент произошёл где-то на территории Египта — если бы был повреждён подводный фрагмент, на ремонт ушли бы дни. Необычность ситуации в том, что параллельно перебои наблюдали и пользователи кабельной системы SEA-ME-WE 5. Последняя, по-видимому, каким-то образом оказалась связана с AAE-1, хотя в теории такого быть не должно. В итоге проблемы распространились далеко за пределы Ближнего Востока и Азии. Известно, что помимо клиентов Google Cloud пострадали клиенты сервисов AWS и Microsoft и других популярных платформ в Азии, Африке, Австралии, Европе, Северной и Южной Америке. На текущий момент проблемы решены, но эксперты всё ещё разбираются в первопричинах инцидента. |
|

