Материалы по тегу: intel
|
17.04.2024 [12:56], Сергей Карасёв
Одноплатные компьютеры ODROID-H4 на базе Intel Alder Lake-N предложат до 48 Гбайт DDR5-4800Компания Hardkernel, по сообщению ресурса CNX Software, расширила ассортимент одноплатных компьютеров, анонсировав решения семейства ODROID-H4 на аппаратной платформе Intel Alder Lake-N. Для новинок заявлена совместимость с Windows и Linux. В серию вошли базовая модель ODROID-H4, а также модификации ODROID-H4+ и ODROID-H4 Ultra. Первые две версии несут на борту чип Intel Processor N97 (4C/4T; до 3,6 ГГц; 12 Вт), а третья наделена процессором Core i3-N305 (8С/8Т; до 3,8 ГГц; 15 Вт). Объём оперативной памяти DDR5-4800 во всех случаях может достигать 48 Гбайт. 
Источник изображения: Hardkernel Габариты изделия составляют 120 × 120 мм. Используется пассивное охлаждение, а опционально может быть установлен кулер с вентилятором толщиной 15 или 25 мм. Доступны различные монтажные комплекты — например, для установки в 5,25" отсек компьютерного корпуса. Все новинки располагают коннектором M.2 для SSD с интерфейсом PCIe 3.0 x4. Есть разъём HDMI, два коннектора DisplayPort, по два порта USB 2.0 и USB 3.0, аудиовход и аудиовыход на 3,5 мм, оптический интерфейс S/PDIF. Базовая версия ODROID-H4 получила один сетевой порт 2.5GbE RJ-45, а модели ODROID-H4+ и ODROID-H4 Ultra — два. Кроме того, старшие версии оснащены четырьмя портами SATA-3 для подключения накопителей. Имеется 24-контактная колодка GPIO (2 × I2C, 3 × USB 2.0, 1 × UART, 1 × HDMI-CEC). Упомянута поддержка Dual BIOS (только ODROID-H4+ и ODROID-H4 Ultra). Цена одноплатных компьютеров составляет от $99 до $220. Дополнительно можно приобрести набор Mini-ITX Kit для использования со стандартными компьютерными корпусами.
15.04.2024 [15:15], Сергей Карасёв
Intel готовит «урезанные» версии ИИ-ускорителя Gaudi3 для КитаяКорпорация Intel, как отмечает ресурс The Register, готовит специализированные модификации ИИ-ускорителя Gaudi3 для китайского рынка. Эти варианты из-за санкционных ограничений со стороны США будут отличаться от стандартных версий пониженным TDP и «урезанной» производительностью. Intel официально представила Gaudi3 менее недели назад. Изделие имеет чиплетную компоновку: оно состоит из двух одинаковых кристаллов с быстрым интерконнектом. В оснащение входят 128 Гбайт памяти HBM2e. Заявленная производительность FP8 и BF16 достигает 1835 Тфлопс (MME — блоки матричной математики). В семейство Gaudi3 входят ОАМ-версии HL-325L и HL-335 с показателем TDP в 900 Вт, а также PCIe-вариант HL-338 с TDP на уровне 600 Вт. 
Источник изображения: Intel Для Китая Intel предложит ОАМ-ускоритель HL-328 и PCIe-модификацию HL-388 — их поставки начнутся в июне и сентябре нынешнего года соответственно. Как и обычные изделия, ускорители для китайских заказчиков содержат два кристалла, а конфигурация памяти не изменилась — 128 Гбайт HBM2e с пропускной способностью 3,7 Тбайт/с. Вместе с тем величина TDP в обоих случаях снижена до 450 Вт. 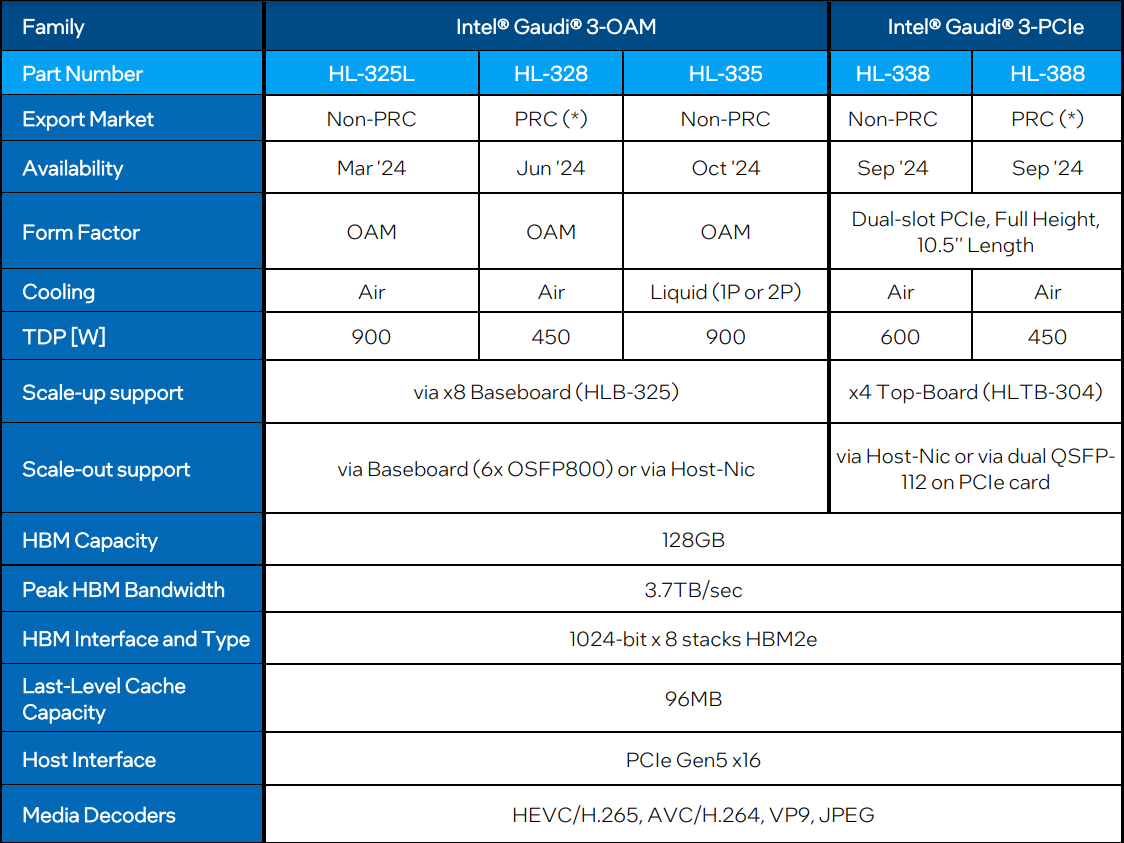
Источник: Intel В соответствии с экспортными ограничениями со стороны США, в Китай запрещаются поставки чипов с производительностью BF16 более 150 Тфлопс. Как именно Intel ограничивает быстродействие в китайских версиях Gaudi3, не ясно. Это может достигаться за счёт снижения тактовой частоты или какого-то другого метода. При этом возможность объединения таких ускорителей в группы остаётся. Отмечается также, что в Китай, по всей видимости, не будут поставляться варианты Gaudi3 с жидкостным охлаждением. NVIDIA уже дважды меняла характеристики ускорителей, чтобы обойти санкции США в отношении Китая, причём компания успела выпустить существенный объём продукции, которую в итоге пришлось направить на другие рынки. Многие китайские компании успели накопить запасы ускорителей, которых хватит на ближайшие пару лет. AMD, как выяснилось, тоже подготовила «урезанную» версию ускорителя Instinct MI309, но Министерство торговли США всё равно не разрешило поставлять её Китаю.
15.04.2024 [13:58], Сергей Карасёв
В Чили запущен суперкомпьютер Geryon 3 для астрономических исследованийПапский Католический университет Чили (UC Chile) объявил о вводе в эксплуатацию НРС-комплекса Geryon 3 на аппаратной платформе Intel. Суперкомпьютер предназначен прежде всего для решения задач в области астрономии, но будет также применяться и в других сферах — от физики до биологии. Проект по созданию Geryon 3 реализован при финансовой поддержке Центра передовых исследований в области астрофизики и связанных с ней технологий (CATA). Стоимость НРС-системы составляет $367,5 тыс. Суперкомпьютер смонтирован в Институте астрофизики в Сантьяго (UC Institute of Astrophysics), где занимает площадь приблизительно 36 м2. Отмечается, что появление Geryon 3 знаменует собой важную веху в развитии вычислительных мощностей для астрофизических исследований в Чили. В состав комплекса входят 12 узлов с процессорами Xeon Gold 6448H поколения Sapphire Rapids. Чипы объединяют 32 ядра (64 потока) с тактовой частотой 2,4–4,1 ГГц. Каждый узел содержит 512 Гбайт оперативной памяти. В общей сложности задействованы 768 ядер и 6,14 Тбайт памяти. Говорится об использовании специально разработанной системы охлаждения (подробности не раскрываются) и других технических решений, включая средства стабилизации питания. 
Источник изображения: UC Chile К 2030-м годам Чили будет обладать самыми развитыми в мире возможностями астрономических наблюдений. К существующим научным инструментам добавятся новые обсерватории, такие как Гигантский Магелланов телескоп (GMT), Европейский чрезвычайно большой телескоп (E-ELT) и обсерватория Веры Рубин. Для обработки поступающих данных потребуются значительные вычислительные ресурсы. Например, обсерватория Веры Рубин получит самую мощную в мире цифровую камеру для оптической астрономии с разрешением 3200 Мп, которая будет фотографировать небо южного полушария каждые три–четыре ночи, формируя около 1000 гигантских изображений за цикл. Хотя основным предназначением Geryon 3 являются астрономические исследования, суперкомпьютер также будет применяться для обработки огромных объёмов данных в таких областях, как горное дело, возобновляемые источники энергии, биогенетика или лесное хозяйство. Ресурсы будут доступны как академическому, так и промышленному сектору.
12.04.2024 [21:28], Сергей Карасёв
Dell сумела сократить сроки поставок ИИ-серверов, но теперь компания полагается не только на ускорители NVIDIA, но и на Intel Gaudi3Компании Dell, по сообщению The Register, удалось сократить сроки поставок серверов для задач ИИ в несколько раз. Речь идёт о высокопроизводительных системах с ускорителями на основе GPU, в том числе NVIDIA H100. Спрос на них настолько высок, что производители не справляются с потоком заказов. О текущей ситуации в отрасли рассказал руководитель тайваньского подразделения Dell Теренс Ляо (Terence Liao). В конце 2023 года срок поставок серверов Dell, оборудованных ускорителями H100, составлял в среднем 39 недель, или около 8–9 месяцев. По словам Ляо, с февраля 2024-го отгрузки продукции NVIDIA значительно улучшились, и Dell смогла уменьшить сроки поставок серверов до 8–12 недель, или 2–3 месяцев. Таким образом, время выполнения заказов уменьшилось в три–четыре раза. Тем не менее, дефицит высокопроизводительных ИИ-ускорителей сохраняется. Связано это в том числе с возможностями TSMC по выпуску чипов с применением технологии CoWoS (Chip on Wafer on Substrate). Именно компоновка CoWoS применяется при изготовлении Н100. 
Источник изображения: NVIDIA В сентябре 2023 года спрос на передовые технологии упаковки чипов был настолько высоким, что TSMC заявила о способности удовлетворить только 80 % заказов. Вместе с тем TSMC сообщила о намерении расширить производственные мощности CoWoS на 20 % — это поможет смягчить проблему дефицита ИИ-ускорителей. Между тем Dell приходится искать альтернативы ускорителям NVIDIA. В частности, она намерена использовать ИИ-ускорители Intel Gaudi3. Поддержка Gaudi3 заявлена для сервера Dell XE9680, который также поддерживает ускорители AMD Instinct MI300X. Эта ИИ-платформа наделена 32 слотами для модулей памяти DDR5, восемью разъёмами PCIe 5.0 и шестью портами OSFP 800GbE. Возможна установка 16 накопителей EDSFF3.
12.04.2024 [12:58], Сергей Карасёв
Модуль LattePanda Mu для IoT- и edge-устройств оснащён процессором Intel Alder Lake-NДебютировал вычислительный модуль (SoM) под названием LattePanda Mu на аппаратной платформе Intel Alder Lake-N. Изделие, как сообщает ресурс CNX Software, предназначено для создания IoT-устройств, edge-систем, робототехнических платформ и пр. Новинка использует нестандартный форм-фактор с размерами 69,6 × 60 мм, а для подключения служит 260-контактный разъём SO-DIMM. Задействован чип Intel Processor N100 с четырьмя ядрами (до 3,4 ГГц) и графическим ускорителем Intel HD Graphics (750 МГц). Объём оперативной памяти LPDDR5-4800 составляет 8 Гбайт. 
Источник изображений: CNX Software Модуль несёт на борту флеш-чип eMMC 5.1 вместимостью 64 Гбайт. Заявлена поддержка следующих интерфейсов: 2 × SATA-3, 1 × eDP 1.4, 3 × HDMI 2.0/DisplayPort 1.4, 4 × USB 3.2 Gen2 (10 Гбит/с), 8 × USB 2.0, 4 × UART, 4 × I2C, PCIe 3.0 (до 9 линий) и 64 × GPIO. Диапазон рабочих температур простирается от 0 до +60 °C. Напряжение питания — от 9 до 20 В.  Команда LattePanda предоставляет для новинки драйверы Windows 10/11. При этом рекомендуется использовать дистрибутивы Linux с ядром 5.18 и выше. Для модуля LattePanda Mu разработаны интерфейсные платы Lite и Full с набором всевозможных разъёмов, включая порты USB, аудиогнёзда и коннекторы для подключения дисплеев (поддерживается вывод изображения одновременно на три монитора). Стоимость LattePanda Mu SoM составляет $139. Комплект с интерфейсной платой Lite и активным кулером обойдётся приблизительно в $190.
10.04.2024 [22:45], Алексей Степин
Intel Gaudi3 готов бросить вызов ИИ-ускорителям NVIDIAС момента анонса ускорителей Intel Habana Gaudi2 минуло два года и всё это время они достойно сражались с решениями NVIDIA, хоть и уступая в чистой производительности, но нередко выигрывая по показателю быстродействия в пересчёте на доллар. Теперь пришло время нового поколения — корпорация Intel анонсировала выпуск чипов Gaudi3 и ускорителей на их основе. Новый ИИ-процессор Gaudi3 взял на вооружение 5-нм техпроцесс TSMC, а также получил чиплетную компоновку, которая, впрочем, на логическом уровне никак себя не проявляет — Gaudi3 с точки зрения хоста остаётся монолитным ускорителем. Был увеличен с 96 до 128 Гбайт объём набортной памяти, но это по-прежнему HBM2e в отличие от решений основного соперника, давно перешедшего на HBM3. 
Источник изображений здесь и далее: Intel Intel выступила с достаточно серьёзным заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при существенно меньшей стоимости. Звучит многообещающе, особенно на фоне сочетания высоких цен с дефицитом со стороны «зелёных».  Физически, как уже упоминалось, Gaudi3 состоит из двух одинаковых кристаллов, «сшитых» между собой быстрым низколатентным интерконнектом. Архитектурно чип подобен предшественнику и по-прежнему включает блоки матричной математики (MME) и кластеры программируемых тензорных процессоров (TPC), имеющих доступ к разделу быстрой памяти SRAM.  Однако в сравнении с Gaudi2 количество блоков серьёзно выросло: вместо 2 MME в составе Gaudi3 теперь 8 таких блоков, а число тензорных процессоров увеличилось с 24 до 64. Вдвое, то есть с 48 до 96 Мбайт, вырос объём SRAM, а её пропускная способность возросла с 6,4 Тбайт/с до 12,8 Тбайт/с. Логически Gaudi3 делится на ядра DCORE (Deep Learning Core), в состав каждого входит два движка MME, 16 тензорных ядер и 24 Мбайт кеша L2. 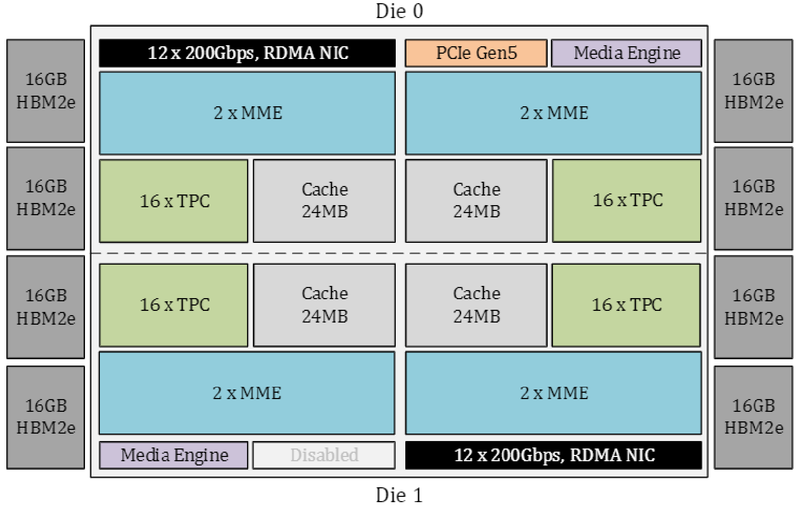
Блок-схема Gaudi3 Усилен также блок медиадвижков, их в новом чипе 14 против 8 у Gaudi2. Всё это не могло не сказаться на тепловыделении: несмотря на применение 5-нм техпроцесса теплопакет у флагманского варианта составляет целых 900 Вт, хотя в новом модельном ряду есть и не столь горячие версии с TDP 600 и 450 Вт. Последний вариант предназначен для экспорта в КНР. 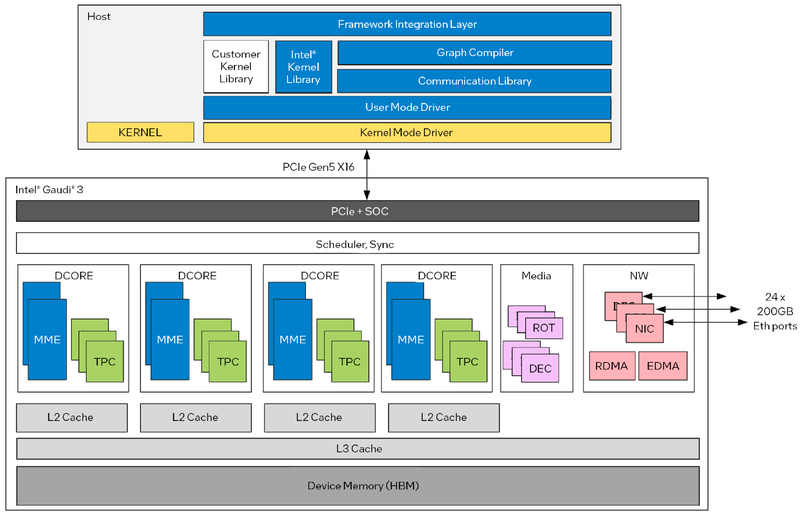
Архитектура Gaudi3 и его программная прослойка Поскольку объём HBM2e был увеличен с 96 до 128 Гбайт, в сборке используется не шесть, а восемь 16-Гбайт кристаллов, что позволило увеличить ПСП с 2,46 до 3,7 Тбайт/с. Работает память на частоте 3,6 ГГц. В составе Gaudi3 также имеется специализированный программируемый блок управления. Он отвечает за формирование очередей, управление прерываниями, синхронизацию, работу планировщика и имеет выход непосредственно на шину PCIe. 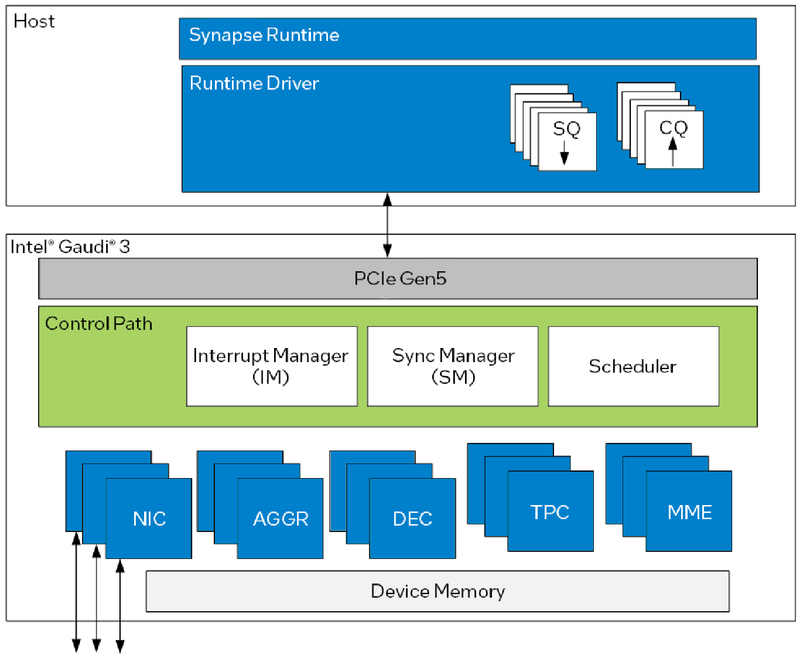
Управляющая подсистема (Control Path) Gaudi3 Сетевая часть всё ещё состоит из 24 контроллеров Ethernet (c RoCE), но появилась поддержка скорости 200 Гбит/с, а значит, вдвое возросла и совокупная производительность сети. Intel подчёркивает, что для масштабирования кластеров на базе Gaudi3 нужна обычная Ethernet-фабрика (а ещё лучше Ultra Ethernet) и нет никакой привязки к конкретному вендору, что является упрёком NVIDIA с её InfiniBand. Наконец, в качестве хост-интерфейса на смену PCI Express 4.0 пришёл PCI Express 5.0 (x16), что также означает подросшую с 64 до 128 Гбайт/с пропускную способность. 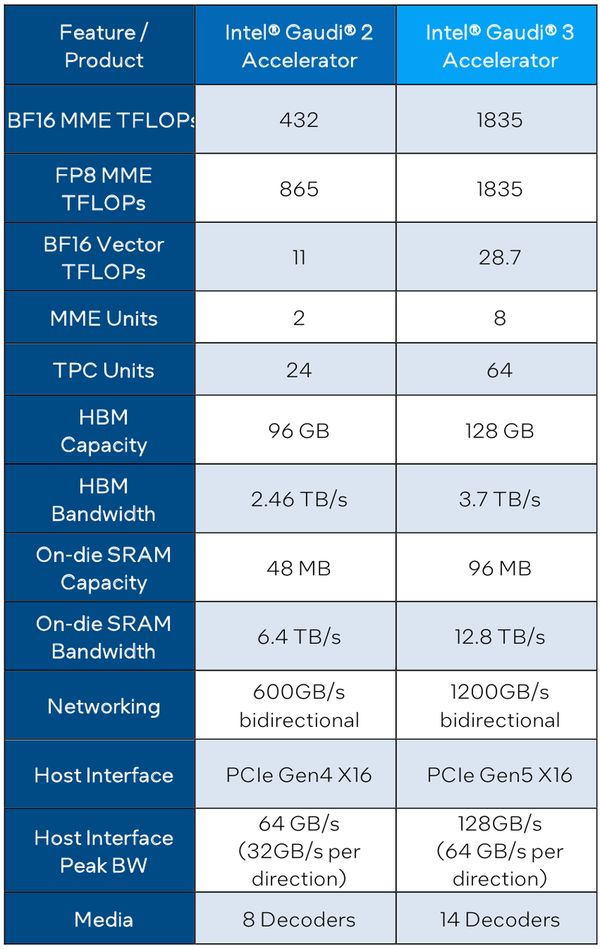
Сравнительные характеристики Gaudi2 и Gaudi3 Все эти улучшения позволяют Intel говорить о теоретической производительности в 2–4 раза более высокой, нежели было достигнуто в поколении Gaudi2. Наибольший прирост заявлен для операций с форматом BF16 на MME, что вполне закономерно, учитывая большее количество самих MME. 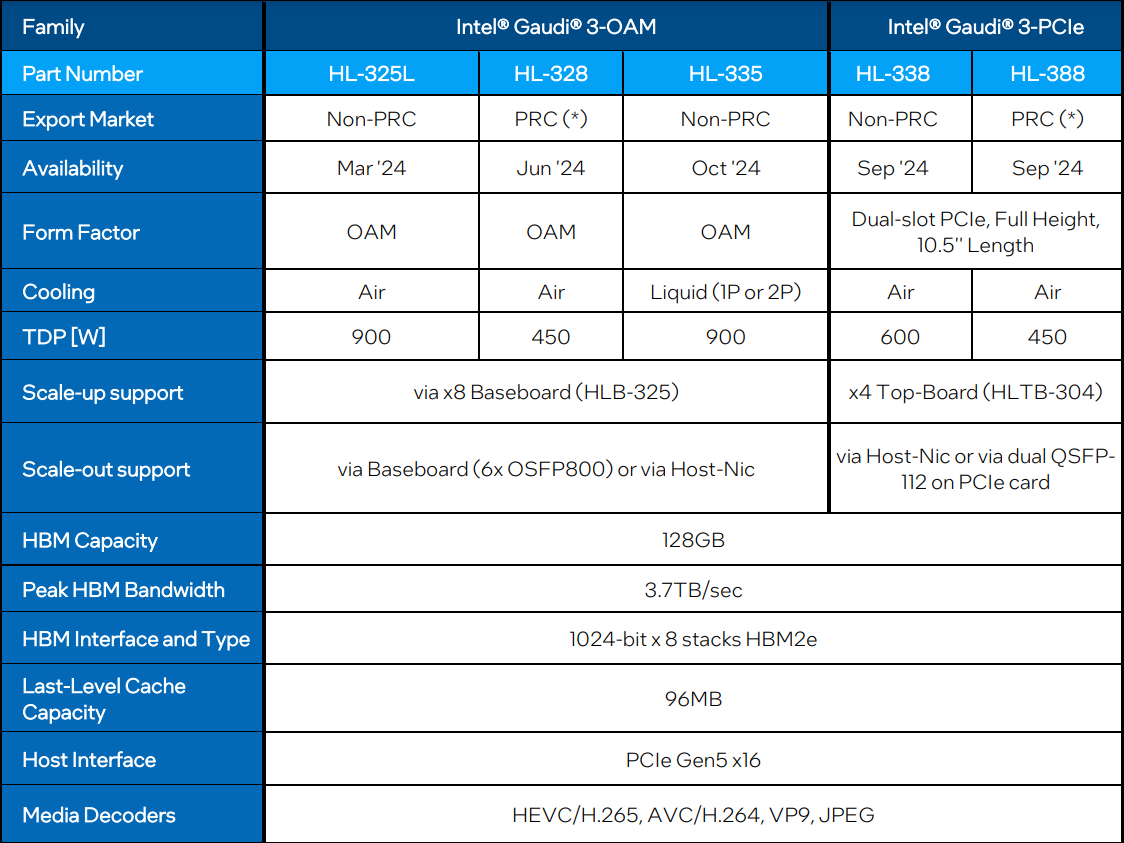 На практике результаты, демонстрируемые Gaudi3, выглядят также достаточно многообещающе: в тестах на обучение популярных нейросетей преимущество над Gaudi2 ни разу не составило менее 1,5x, а в отдельных случаях даже превысило 2,5x. 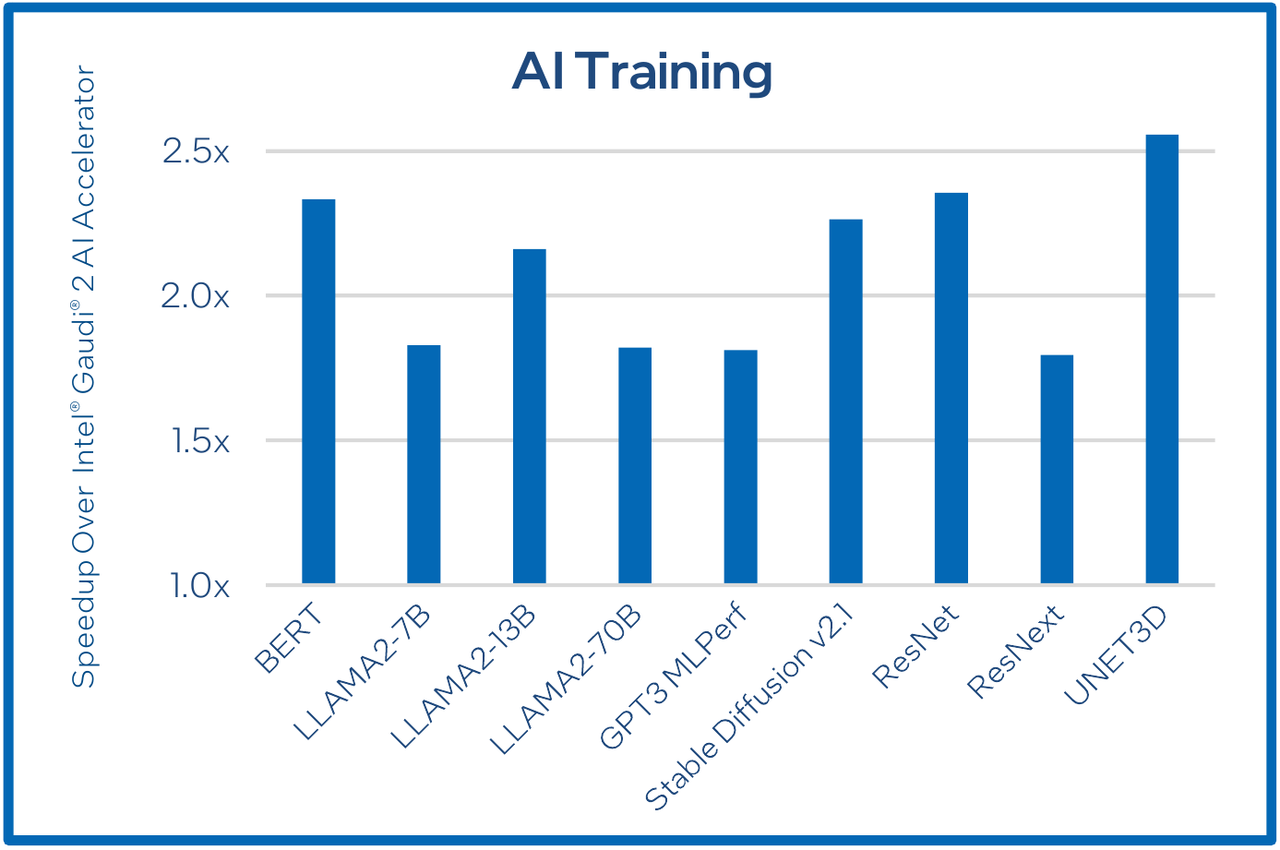 В инференс-тестах отрыв оказался чуть меньше, но и здесь минимальна разница составляет полтора раза. Что немаловажно для инференс-сценариев, серьёзно улучшились показатели латентности. Отчасти это заслуга не только серьёзно подросших «мускул» нового процессора, но и наличие большего объёма HBM, что позволяет разместить в памяти больше параметров и расширить контекстное окно. 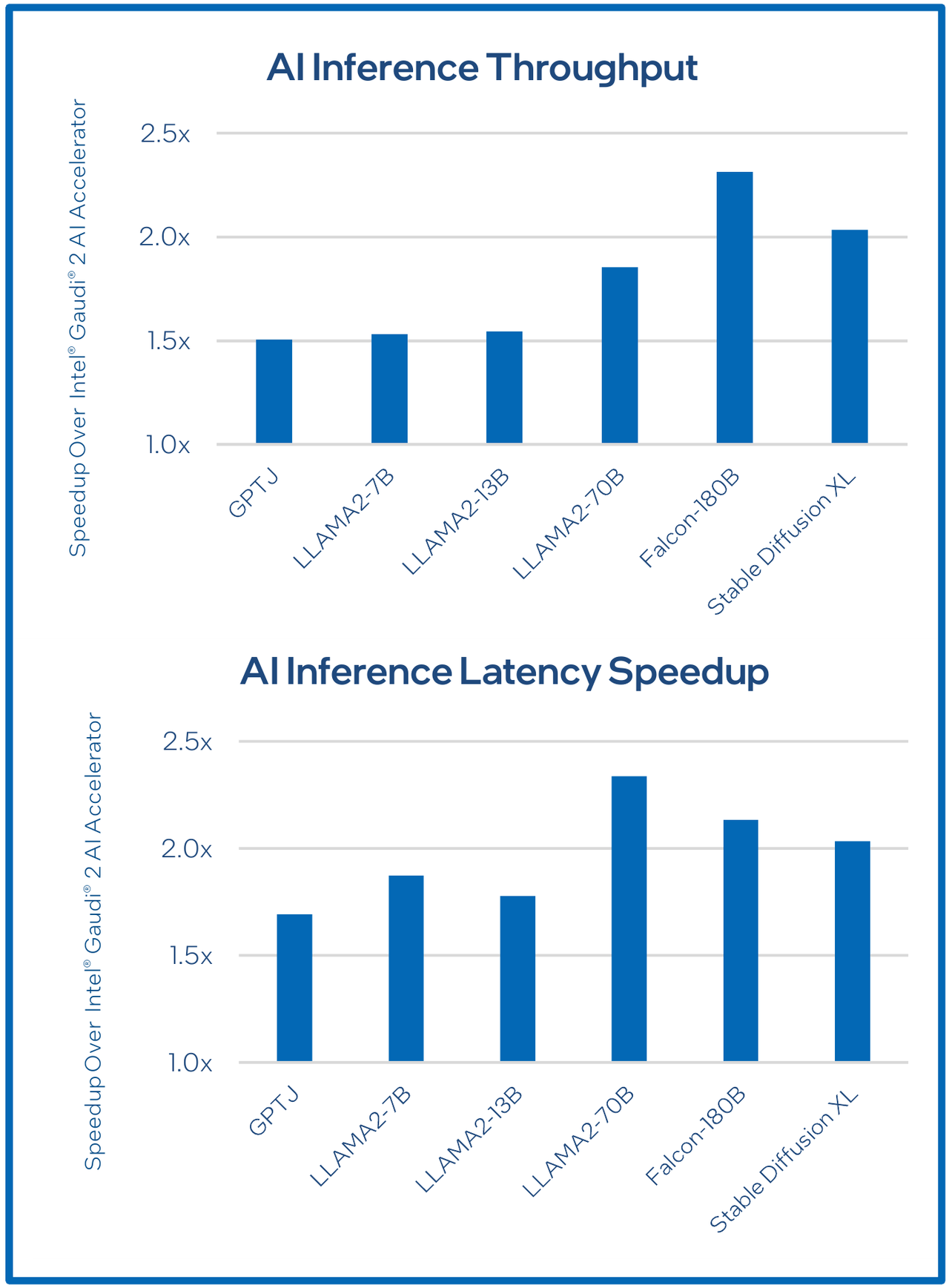 Опубликовала Intel и результаты сравнительного тестирования Gaudi3 против NVIDIA H100 в MLPerf, где новинка действительно выступила весьма достойно, в худшем случае демонстрируя 90% от производительности H100, а в отдельных тестах опережая конкурента более чем в 2,5 раза. Примерно так же распределились результаты и в тестах на энергоэффективность. 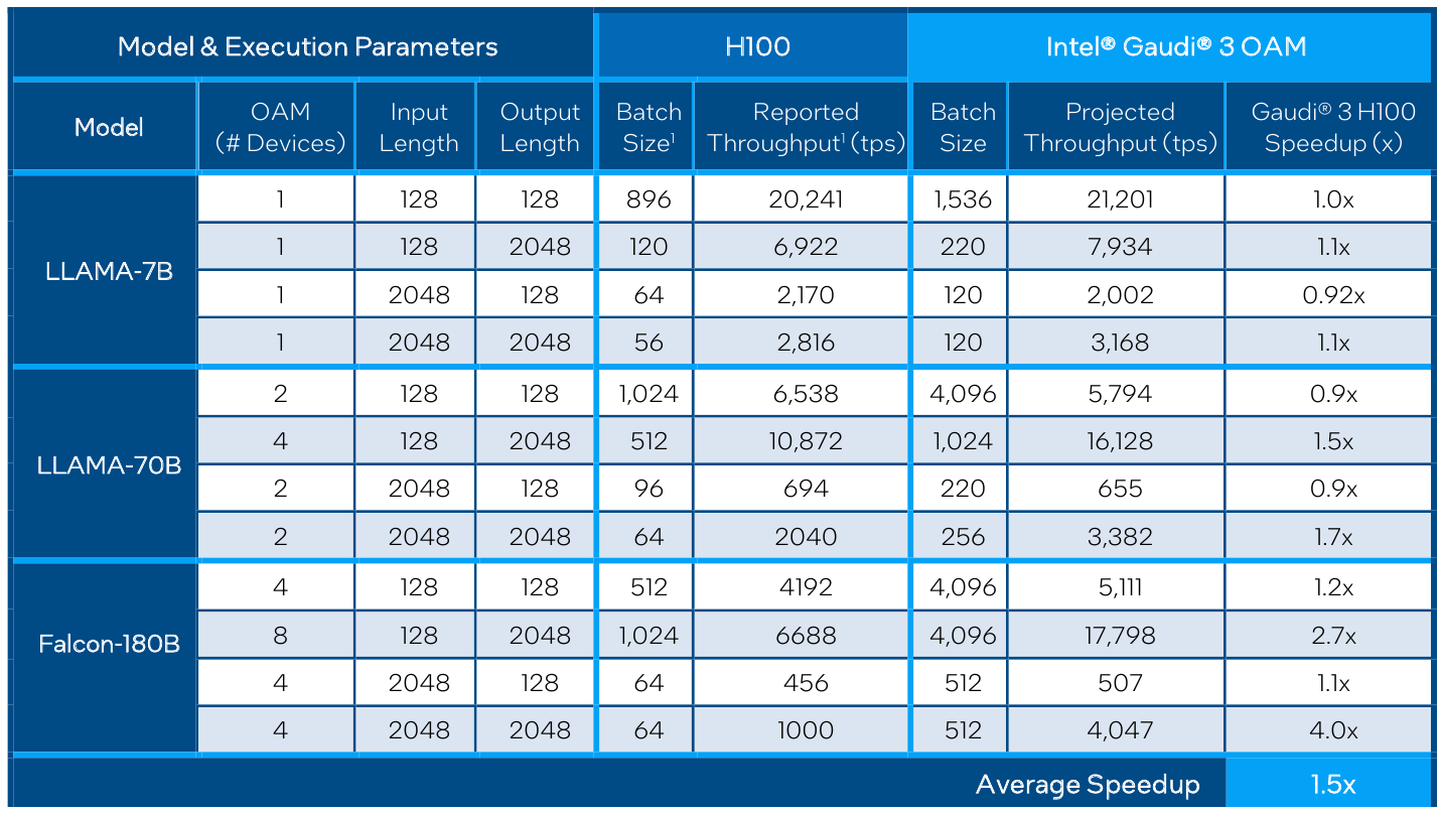 Что же касается инженерно-технической реализации, то на этот раз Intel представила сразу несколько вариантов ускорителей на базе Gaudi3, отличающихся как теплопакетом, так и конструктивом. Самым быстрым вариантом в семействе является модуль HL-325L OCP. Он выполнен в формате мезонинной платы OCP OAM 2.0 и поддерживает теплопакет 900 Вт для воздушного охлаждения и 1200 Вт — для жидкостного. 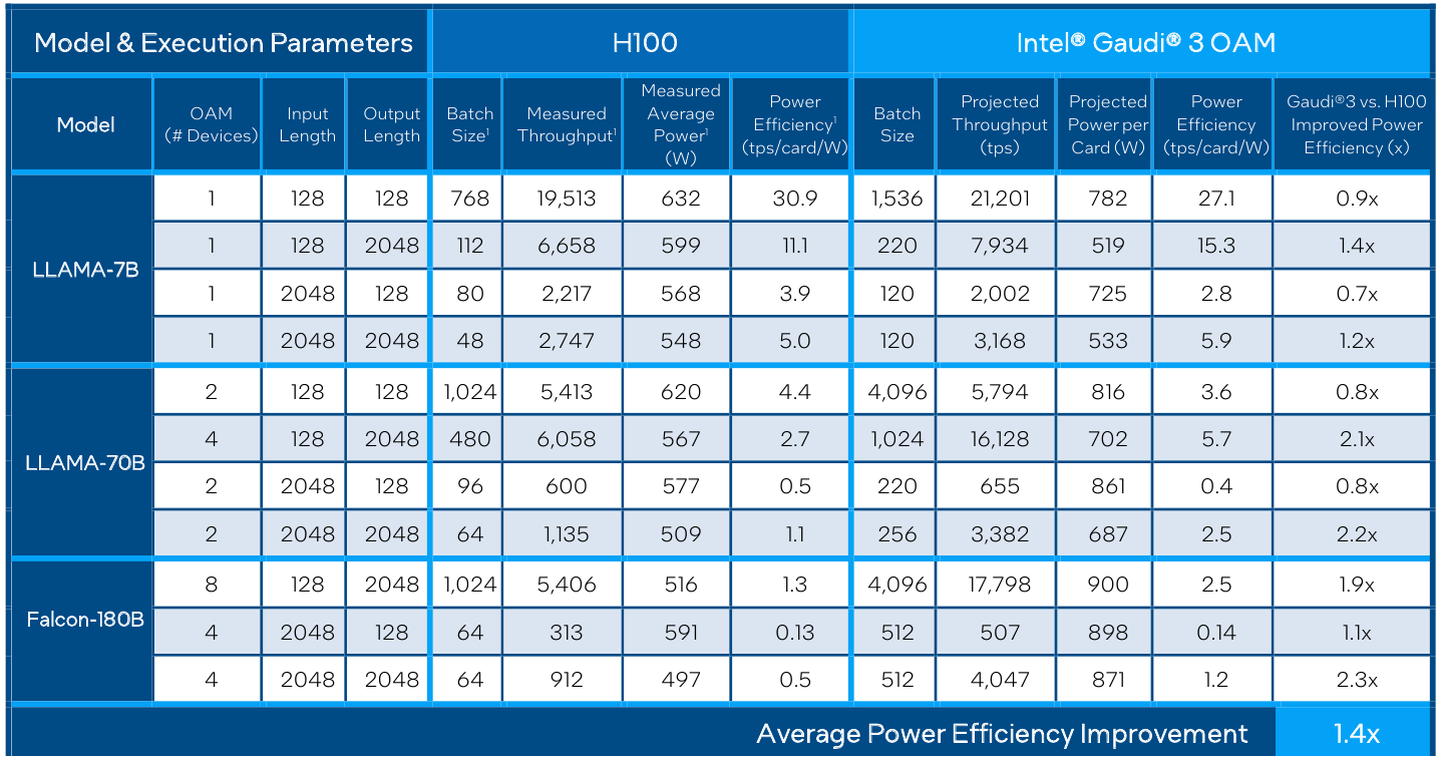 Для этой модели была специально разработана новая UBB-плата HLB-325L, приходящая на смену HLBA-225. Она поддерживает установку восьми ускорителей HL-325L, причём 21 сетевое подключение на каждом из них позволяет реализовать интерконнект по схеме «все со всеми», а оставшиеся подключения сведены через PAM4-ретаймеры в шесть 800GbE-портов OSFP для дальнейшего масштабирования кластера. Имеется и вывод PCI Express 5.0 с помощью PCIe-ретаймеров, также установленных на плате. HLB-325L рассчитана на питание 54 В, которое в последнее время становится всё популярнее в новых ЦОД и HPC-системах. 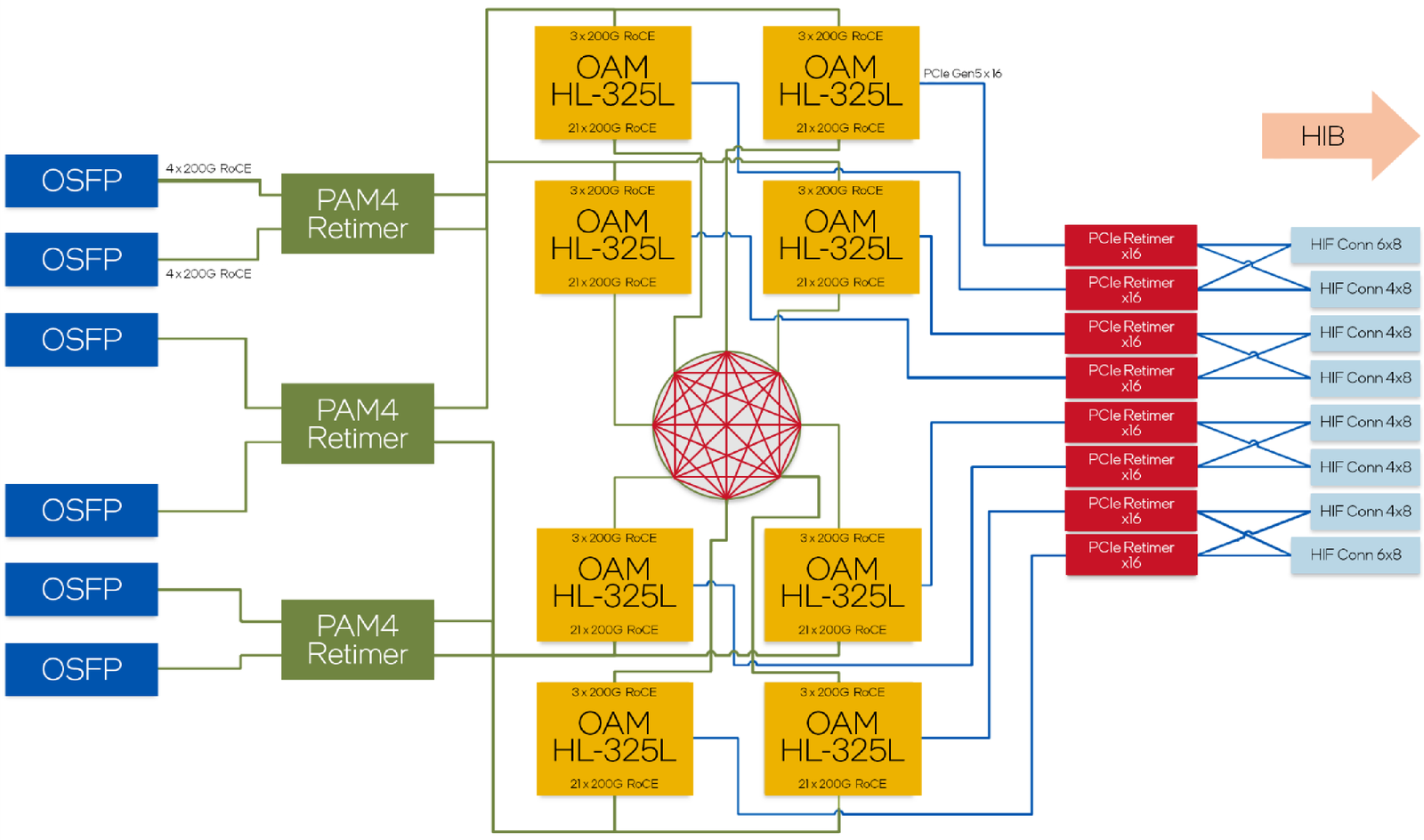
Топология базовой платы HLB-325L с восемью Gaudi3 Другой вариант Gaudi3 — ускоритель HL-338. Он представляет собой стандартную плату расширения PCIe с двумя внешними портами QSFP112 400GbE. Поддерживаются теплопакеты вплоть до 600 Вт при стандартном воздушном охлаждении. Дополнительный мостик HLTB-304, устанавливаемая поверх четырёх ускорителей HL-338, обеспечивает интерконнект за счёт 18 набортных линков 200GbE. Такая реализация кластера на базе Gaudi3 по понятным причинам будет несколько менее производительной, нежели вариант с OAM-модулями, но позволит обойтись стандартными аппаратными средствами и корпусами серверов. 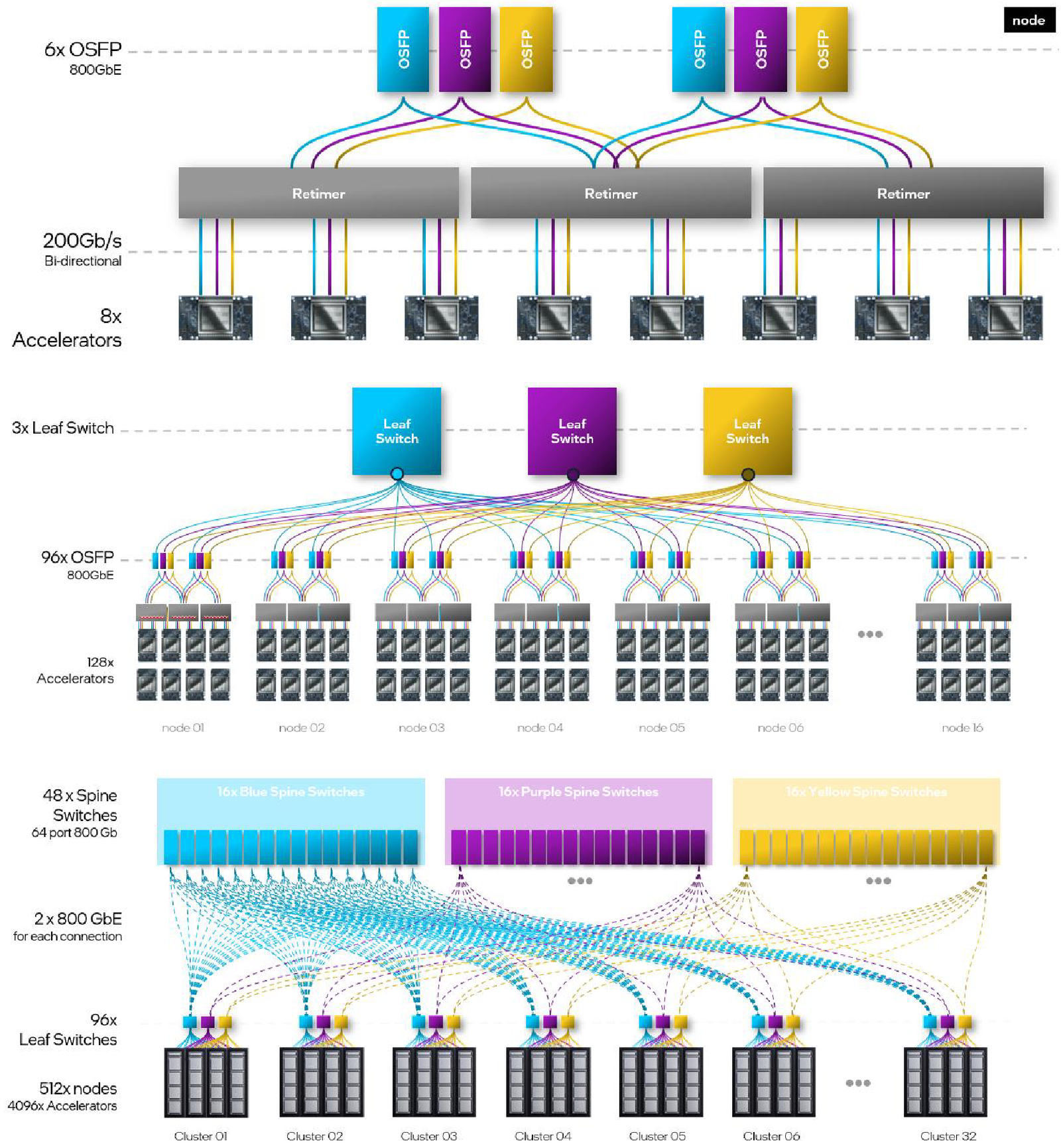
Масштабирование и кластеризация Gaudi3 Первые пробные партии ускорителей на базе Gaudi3 поступят избранным партнёрам Intel уже в этом полугодии. Вариант OAM с воздушным охлаждением уже тестируется в квалификационных лабораториях компании, а образцы с жидкостным охлаждением появятся позднее в этом квартале. В новинке заинтересованы Dell, HPE, Lenovo и Supermicro. Массовые поставки стартуют в III квартале 2024 года. Последними на рынке появятся PCIe-версии, их поставки намечены на IV квартал. 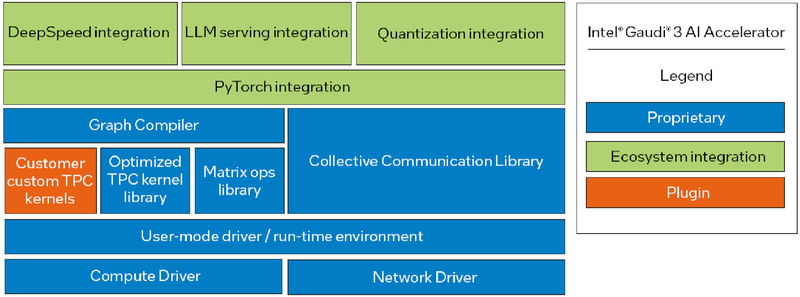
Программная экосистема Intel Gaudi Intel Gaudi3 выглядит весьма неплохо. В нём устранены узкие места, свойственные Gaudi2, что позволяет тягаться на равных с NVIDIA H100 и H200, и даже заметно превосходить их в некоторых сценариях. Однако NVIDIA уже анонсировала архитектуру Blackwell. Впрочем, основная борьба развернётся не на аппаратном, а на программном уровне — Intel вслед за AMD упростила работу с PyTorch, что позволит перенести множество нагрузок на Gaudi. А там, глядишь, и UXL станет хоть какой-то альтернативой CUDA.
10.04.2024 [14:34], Сергей Карасёв
Intel и Altera представили Agilex 5 — первую FPGA с ИИ-архитектуройВозродив бренд Altera, корпорация Intel анонсировала FPGA серии Agilex 5, рассчитанные на широкий спектр применений. Это могут быть различные встраиваемые и промышленные устройства, решения для систем связи, обеспечения безопасности, видеоаналитики и пр. Intel называет Agilex 5 первыми в отрасли FPGA с ИИ-архитектурой. Изделия производятся по технологии Intel 7. Это первые FPGA в своём классе, оснащённые усовершенствованным (Enhanced) DSP с тензорным ИИ-блоком (AI Tensor Block), который отвечает за высокоэффективную обработку операций, связанных с ИИ. 
Источник изображений: Intel Кроме того, как утверждается, Agilex 5 — это первые на рынке FPGA с асимметричным блоком процессора приложений, состоящим из двух ядер Arm Cortex-A76 и двух ядер Cortex-A55. Такая конфигурация в зависимости от рабочих нагрузок позволяет оптимизировать производительность и энергоэффективность. Тактовая частота ядер Cortex-A76 достигает 1,8 ГГц, ядер Cortex-A55 — 1,5 ГГц. 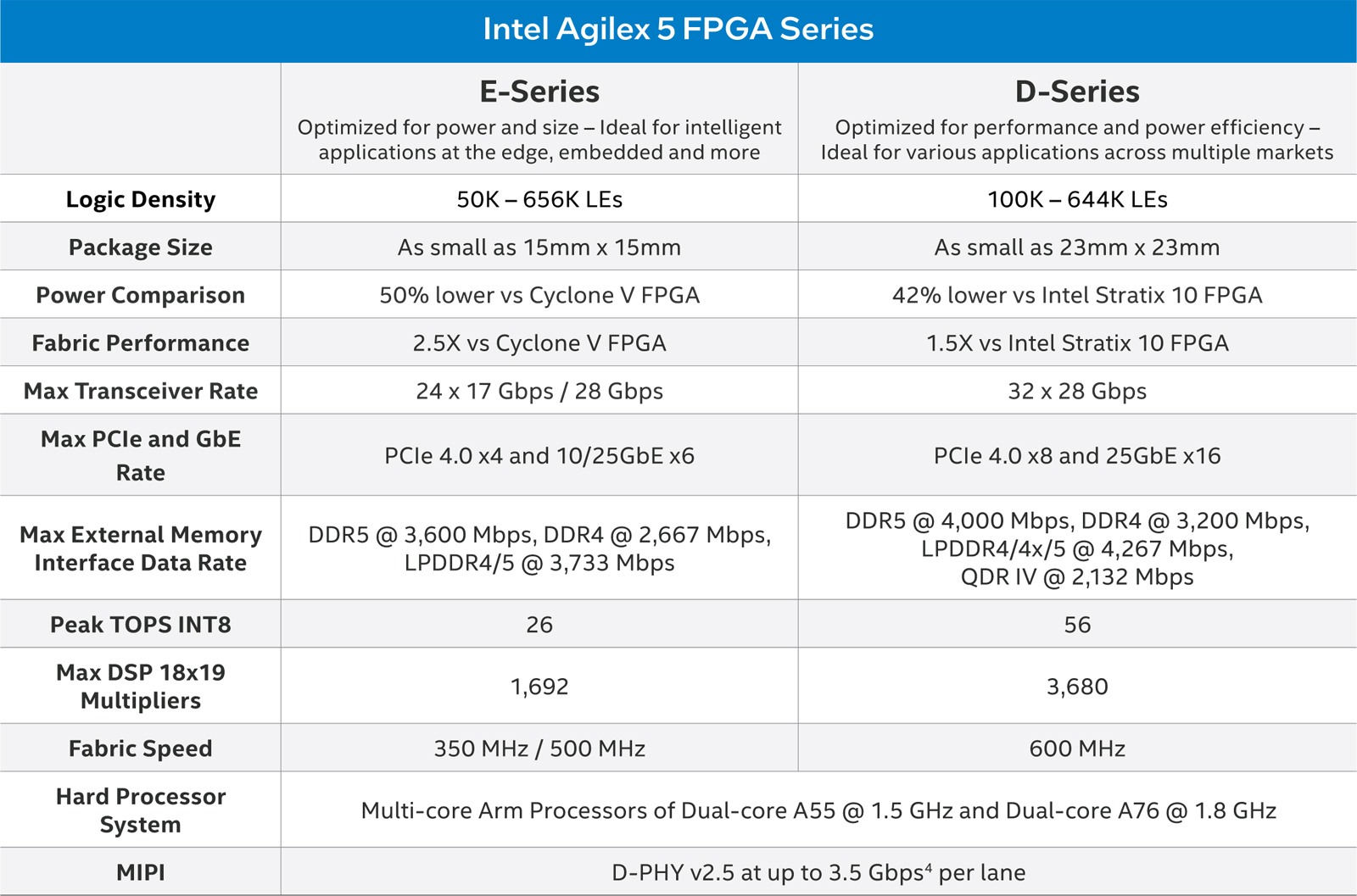 В семейство Agilex 5 вошли модели E-Series и D-Series. Первые оптимизированы для edge-устройств с небольшим энергопотреблением, а вторые предлагают более высокую производительность. Быстродействие INT8 достигает соответственно 26 и 56 TOPS. Решения E-Series могут работать с памятью DDR5-3600, DDR4-2667 и LPDDR4/5-3733. Реализована поддержка PCIe 4.0 x4 и шести интерфейсов 10/25GbE. В случае D-Series заявлена возможность использования памяти DDR5-4000, DDR4-3200, LPDDR4/4x/5-4267 и QDR-IV-2132. Обеспечена поддержка PCIe 4.0 x8 и 16 интерфейсов 25GbE.
10.04.2024 [14:22], Сергей Карасёв
Intel перешла на новую схему обозначения процессоров Xeon — от бренда Scalable решено отказатьсяКорпорация Intel, по сообщению AnandTech, объявила о внедрении новой схемы обозначения серверных процессоров Xeon. Ради упрощения маркировки от бренда Xeon Scalable решено отказаться: чипы следующего поколения войдут в семейство Xeon 6. Речь идёт об изделиях под кодовыми именами Xeon Sierra Forest и Xeon Granite Rapids. Эти процессоры были официально представлены в феврале нынешнего года. Известно, что чипы Xeon Sierra Forest будут оснащены исключительно энергоэффективными E-ядрами, количество которых составит до 288. Такие решения начнут поступать на коммерческий рынок в текущем квартале. В свою очередь, Xeon Granite Rapids получат высокопроизводительные P-ядра, а их выход состоится позднее — ориентировочно во II половине нынешнего года. 
Источник изображений: Intel Впервые Intel начала использовать бренд Xeon Scalable в 2017 году, представив семейство чипов Skylake-SP. В то время бренд Xeon Scalable пришёл на смену прежней маркировке Xeon E/EP/EX vX, что позволило сбросить «счётчик поколений».
Отмечается, что Intel стремится сформировать экосистему, соответствующую современным требованиям отрасли. Фактически закладывается основа так называемой инфраструктуры Intel Enterprise AI: она охватит решения для дата-центров, периферийных систем и ПК корпоративного класса. Именно Xeon 6 в обозримом будущем сыграют ключевую роль в реализации данной стратегии. Intel намерена сотрудничать с отраслевыми партнёрами, независимыми поставщиками ПО и аппаратных изделий для создания широкой и открытой экосистемы.
10.04.2024 [14:14], Сергей Карасёв
Intel представила видеокарты Arc для встраиваемых решенийКорпорация Intel анонсировала видеокарты серии Arc Aхx0E, предназначенные для применения в различных встраиваемых устройствах и системах небольшого форм-фактора. В общей сложности дебютировали шесть моделей: Arc A310E, Arc A350E, Arc A370E, Arc A380E, Arc A580E и Arc A750E. В основном это встраиваемые версии видеокарт, которые уже доступны на рынке. При этом изделия подверглись некоторым доработкам с учётом сферы их применения. Ускорители насчитывают от 6 до 28 ядер Xe. Количество исполнительных блоков варьируется от 96 до 448. Объём памяти GDDR6 у младших вариантов составляет 4 Гбайт, а пропускная способность памяти у версий начального уровня составляет 112 Гбайт/с. Для A380E указаны 6 Гбайт и 186 Гбайт/с. А вот для A580E и A750E параметры памяти не указаны. 
Источник изображения: Advantech Производительность INT8 варьируется от 49 до 235 TOPS. Быстродействие на операциях FP16 составляет от 24,6 до 117,6 Тфлопс, на операциях FP32 — от 3,1 до 14,7 Тфлопс. Говорится о совместимости с Windows 10/11, Windows 10 LTSC и Linux. 
Источник изображения: Intel В зависимости от модификации видеокарты Arc Aхx0E могут использоваться для решения таких задач, как распознавание лиц и речи, приложения ИИ, обработка медиаданных и пр. Поставки начнутся в текущем месяце. Решение будут доступны для заказа в течение пяти лет. 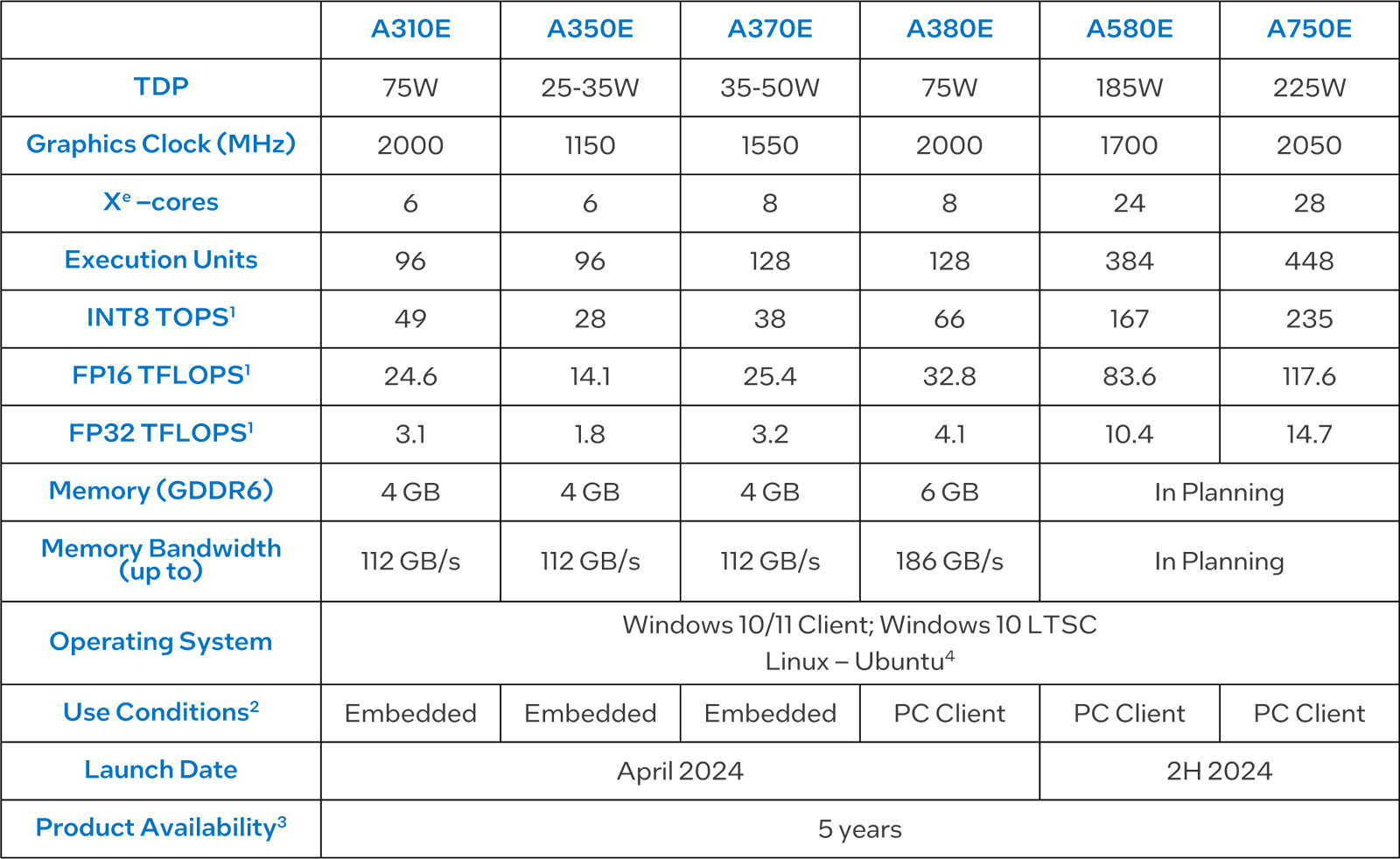
Источник изображения: Intel
10.04.2024 [00:00], Сергей Карасёв
Supermicro готовит серверы серии X14 на чипах Intel Xeon Sierra Forest и Granite RapidsКомпания Supermicro сообщила о подготовке серверов семейства X14, в основу которых лягут процессоры Intel Xeon Sierra Forest и Granite Rapids (Xeon 6). Речь идёт о стоечных системах, оптимизированных для обеспечения высокой производительности и энергетической эффективности. Для устройств серии X14 заявлена поддержка GPU и DPU нового поколения, оперативной памяти DDR5, интерфейса PCIe 5.0, накопителей NVMe с поддержкой PCIe 5.0 и стандарта CXL 2.0. Говорится о подготовке серверов с воздушным охлаждением и прямым жидкостным охлаждением Direct-to-chip. Системы рассчитаны на работу в дата-центрах с температурой окружающего воздуха до +40 °C. Серверы спроектированы в соответствии со стандартом NIST 800-193. Питание обеспечат надёжные блоки с сертификатом 80 Plus Titanium. 
Источник изображения: Supermicro В семейство Supermicro X14 войдут решения для задач ИИ с ускорителями на базе GPU, универсальные серверы, модели SuperBlade для НРС-задач, аналитики данных и облачных платформ, СХД формата 1U и 2U с поддержкой накопителей DSFF E1.S и E3.S, а также серверы серий Hyper, Hyper-E, CloudDC, BigTwin, GrandTwin и Edge. 
Источник изображения: Supermicro Компания Supermicro также сообщает, что будут доступны двухпроцессорные серверы общего назначения для решения повседневных задач корпоративного уровня. Помимо этого, готовятся рабочие станции для приложений ИИ, 3D-дизайна и пр. |
|


