Материалы по тегу: h100
|
20.03.2024 [01:00], Владимир Мироненко
Microsoft и NVIDIA объявили об интеграции своих решений для ускорения внедрения генеративного ИИ на предприятияхMicrosoft и NVIDIA объявили о расширении давнего сотрудничество с целью внедрения новейших технологий генеративного ИИ NVIDIA и Omniverse в Microsoft Azure и ИИ-сервисы Azure, Microsoft Fabric и Microsoft 365. Сатья Наделла (Satya Nadella), председатель и гендиректор Microsoft заявил, что все новые инициативы, от внедрения ускорителей GB200 Grace Blackwell в Azure до новой интеграции между DGX Cloud и Microsoft Fabric, обеспечат клиентам наиболее полные платформы и инструменты на всех уровнях стека Copilot, от «кремния» до ПО, и позволят создать им новые прорывные ИИ-приложения. Microsoft станет одной из первых, кто развернёт в облаке ускорители GB200 и вкупе с InfiniBand-интерконнектом на базе Quantum-X800, предоставив новейшие базовые модели с триллионом параметров. Заодно компания объявила о доступности инстансов Azure NC H100 v5 на базе H100 NVL. Серия NC среднего уровня, предназначенная для обучения и инференса, предлагает клиентам два класса виртуальных машин с одним или двумя PCIe-ускорителями H100 (94 Гбайт). 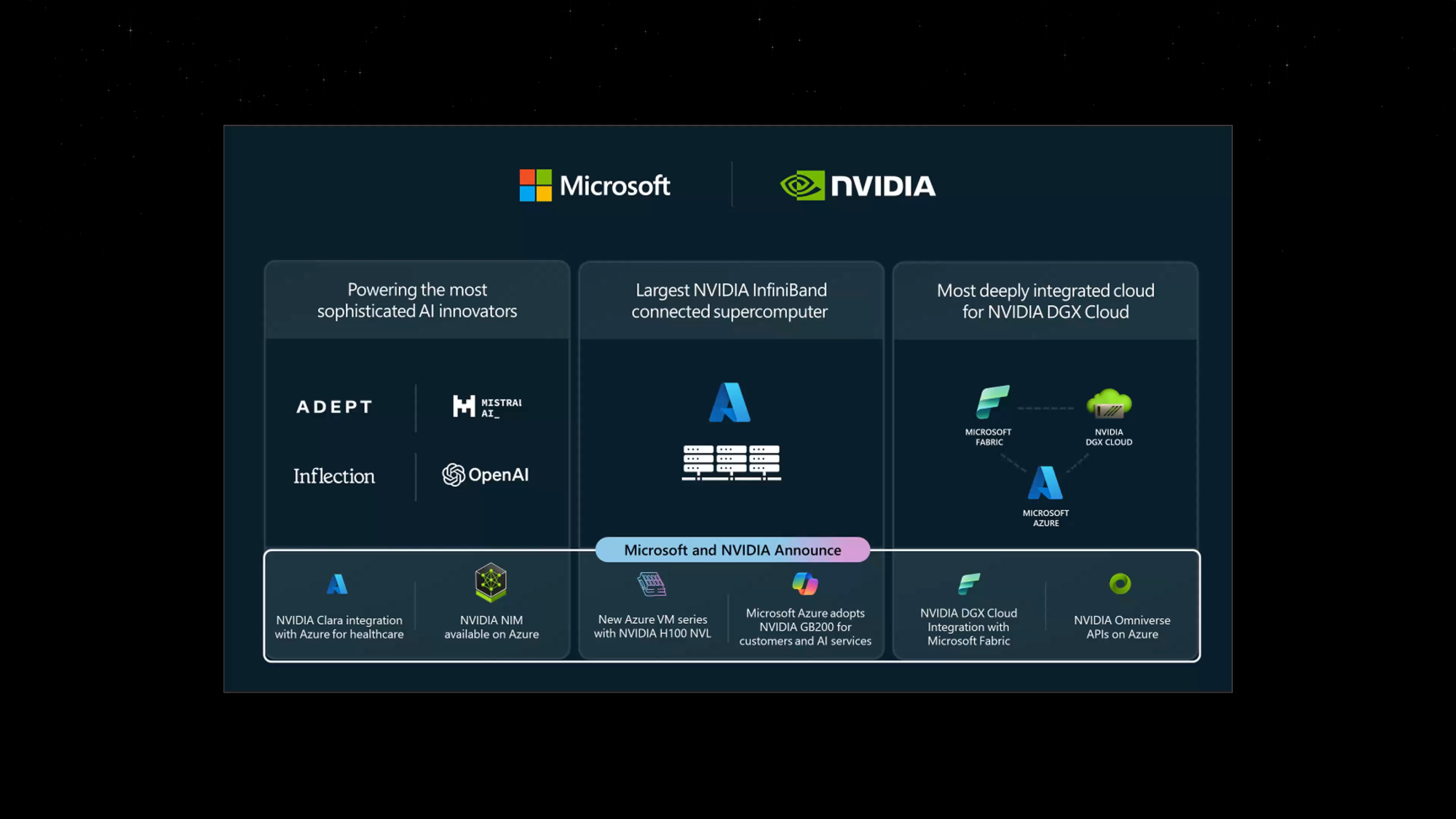
Изображение: NVIDIA Кроме того, компания предложит комплексный набор решений на базе Microsoft Azure, NVIDIA DGX Cloud и NVIDIA Clara поставщикам медицинских сервисов, фармацевтическим и биотехнологическим компаниям, а также разработчикам медицинского оборудования. А индустриальные компании получат в своё распоряжение API NVIDIA Omniverse Cloud. Наконеw, в Azure AI и Azure Marketplace станут доступны микросервисы инференса NVIDIA NIM.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее.
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
19.03.2024 [01:02], Сергей Карасёв
Ускорители NVIDIA H100 лягут в основу японского суперкомпьютера ABCI-Q для квантовых вычисленийКомпания NVIDIA сообщила о том, что её технологии лягут в основу нового японского суперкомпьютера ABCI-Q, предназначенного для проведения исследований в области квантовых вычислений. Платформа, в частности, будет использоваться для тестирования гибридных систем, объединяющих классические и квантовые технологии. Развёртыванием комплекса займётся корпорация Fujitsu. Машина расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). Ввод ABCI-Q в эксплуатацию намечен на начало 2025 года. В состав суперкомпьютера войдут более 500 узлов, насчитывающих в общей сложности свыше 2000 ускорителей NVIDIA H100. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также NVIDIA CUDA Quantum — открытой платформы для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Комплекс ABCI-Q проектируется с прицелом на возможность добавления будущих аппаратных компонентов для квантовых вычислений. 
Источник изображения: NVIDIA Ожидается, что ABCI-Q позволит проводить высокоточное квантовое моделирование в рамках исследовательских проектов в различных отраслях. Учёные смогут тестировать приложения нового типа с целью ускорения их практического внедрения. Кроме того, специалисты смогут прорабатывать передовые алгоритмы для решения специфичных задач. NVIDIA и AIST также планируют сотрудничать при разработке промышленных приложений на базе ABCI-Q. В целом, ABCI-Q является частью стратегии Японии в области квантовых технологий, задачей которой является создание новых возможностей для бизнеса и общества, а также получение выгоды от квантовых технологий, в том числе посредством исследований в области ИИ, энергетики и биологии.
28.02.2024 [15:54], Руслан Авдеев
Доступность ускорителей NVIDIA H100 повысилась, что привело к появлению вторичного рынкаСроки поставок ускорителей NVIDIA H100 значительно сократилось, с 8–11 мес. до всего 3-4. По данным Tom’s Hardware, в результате многие компании, ранее сделавшие огромные запасы, пытаются продать излишки. Кроме того, стало намного легче арендовать ускорители в облаках Amazon, Google и Microsoft. Впрочем, разработчики ИИ-моделей до сих пор испытывают проблемы с доступом к ресурсам ускорителей, поскольку спрос превышает предложение. Как сообщают СМИ, некоторые компании пытаются перепродать доставшиеся им H100, а другие стали заказывать меньше в связи с высокой стоимостью обслуживания складских запасов и окончанием паники на рынке. В прошлом году приобрести подобные ускорители было чрезвычайно сложно. Отчасти улучшение ситуации на рынке связано с тем, что провайдеры облачных сервисов вроде Amazon (AWS) и других крупных игроков упростили аренду H100. 
Источник изображения: NVIDIA Несмотря на то, что доступ к H100 упростился, желающим обучать LLM добраться до ресурсов по-прежнему непросто, во многом потому, что им требуются ускорители в невероятных количествах, в некоторых случаях речь идёт о сотнях тысяч экземпляров, поэтому цены на них до сих пор не упали, а NVIDIA продолжает получать сверхприбыли. При этом рост доступности привёл к тому, что компании всё чаще пытаются сэкономить, ведут себя более избирательно при выборе предложений продажи или аренды, стараются приобрести более мелкие кластеры и внимательнее оценивают их экономическую целесообразность для бизнеса. Кроме того, альтернативные решения становятся все более распространёнными и всё лучше поддерживаются ПО. Это ведёт к формированию сбалансированной ситуации на рынке. Так или иначе, спрос на ИИ-чипы по-прежнему высок, а с учётом того, что LLM становятся всё масштабнее, требуется больше вычислительных мощностей. Поэтому крупные игроки, которые зависят от поставок решений NVIDIA, занялись созданием собственных ускорителей. Среди них Microsoft, Meta✴ и OpenAI.
27.02.2024 [21:44], Сергей Карасёв
Gigabyte представила новые серверы для ИИ, 5G и периферийных вычисленийКомпания Gigabyte Technology на MWC 2024 анонсировала новые серверы для ИИ-задач, 5G-сетей, облачных и периферийных вычислений. Дебютировали модели на процессорах AMD и Intel, оснащённые мощными ускорителями.  В частности, представлены серверы G593-ZX1/ZX2, оборудованные восемью картами AMD Instinct MI300X для ресурсоёмких вычислений. Кроме того, демонстрируются сервер высокой плотности H223-V10 с поддержкой суперчипа NVIDIA Grace Hopper, модель G383-R80 с четырьмя APU AMD Instinct MI300A и сервер серии G593, оснащённый восемью ускорителями NVIDIA HGX H100.  Ещё одна новинка — сервер хранения S183-SH0. Он допускает использование 32 SSD формата E1.S (NVMe), благодаря чему подходит для обработки сложных рабочих нагрузок, таких как большие языковые модели (LLM). Эти серверы также могут быть интегрированы в суперкомпьютерные кластеры и инфраструктуру 5G.  На edge-сегмент рассчитан сервер E263-S30 с модульной архитектурой: он может быть адаптирован под различные сценарии использования путём установки необходимых аппаратных компонентов. А модель R163-P32 комплектуется процессором AmpereOne с архитектурой Arm (до 192 ядер Arm с частотой до 3,0 ГГц), что обеспечивает высокую энергетическую эффективность.
На ИИ-приложения и облачные периферийные вычисления ориентированы серверы R243-EG0 и R143-EG0, которые оснащены чипами AMD EPYC 8004 Siena. Для сегмента малого и среднего бизнеса Gigabyte предлагает серверы R113-C10 и R123-X00, наделённые процессорами AMD Ryzen 7000 и Intel Xeon E-2400: эти модели подходят для веб-хостинга, создания гибридных облаков и хранилищ данных.
22.02.2024 [13:34], Сергей Карасёв
HBM мало не бывает: суперкомпьютер OSC Cardinal получил чипы Intel Xeon Max и ускорители NVIDIA H100Суперкомпьютерный центр Огайо (OSC) анонсировал проект Cardinal по созданию нового кластера для задач HPC и ИИ. Гетерогенная система, построенная на серверах Dell PowerEdge с процессорами Intel, будет введена в эксплуатацию во II половине 2024 года. В состав кластера войдут узлы, оборудованные процессорами Xeon Max 9470 семейства Sapphire Rapids. Эти чипы содержат 52 ядра (104 потока) с максимальной тактовой частотой 3,5 ГГц и 128 Гбайт памяти HBM2e. В общей сложности будут задействованы 756 таких процессоров. Каждый узел получит 512 Гбайт DDR5 и NVMe SSD вместимостью 400 Гбайт. Узлы входят в состав серверов Dell PowerEdge C6620. Компанию им составят 16 узлов Dell PowerEdge R660, тоже с двумя Xeon Max 9470, но с 2 Тбайт DDR5 и 12,8 Тбайт NVMe SSD. Все эти узлы объединит 200G-интерконнект Infiniband. Кроме того, будут задействован 32 узла Dell PowerEdge XE9640 с двумя чипами Xeon 8470 Platinum (52C/104T; до 3,8 ГГц), четырьмя ускорителями NVIDIA H100 с 96 Гбайт памяти HBM3 и 1 Тбайт DDR5. Говорится о применении четырёх соединений NVLink и 400G-платформы Quantum-2 InfiniBand. Заявленная пиковая ИИ-производительность (FP8) — около 500 Пфлопс. 
Фото: Ohio Supercomputer Center via The Next Platform Суперкомпьютер обеспечит общую FP64-производительность на уровне 10,5 Пфлопс. Таким образом, по быстродействию кластер приблизительно на 40 % превзойдёт три нынешние машины OSC вместе взятые. При этом Cardinal занимает всего девять стоек и требует пару CDU для работы СЖО. Отмечается, что Cardinal — это результат сотрудничества OSC, Dell Technologies, Intel и NVIDIA. Новый суперкомпьютер придёт на смену системе Owens, которая используется в OSC с 2016 года.
20.02.2024 [23:25], Сергей Карасёв
Поменьше и побольше: у NVIDIA оказалось сразу два ИИ-суперкомпьютера EOSНа днях NVIDIA снова официально представила суперкомпьютер EOS для решения ресурсоёмких задач в области ИИ. Издание The Register обратило внимание на нестыковки в публичных заявлениях компании относительно конфигурации и производительности машины. В итоге NVIDIA признала, что у неё есть две архитектурно похожих системы под одним и тем же именем. Впрочем, полной ясности это не внесло. НРС-комплекс EOS изначально был анонсирован почти два года назад — в марте 2022-го. Тогда речь шла о кластере, объединяющем 576 систем NVIDIA DGX H100, каждая из которых содержит восемь ускорителей H100 — в сумме 4608 шт. Суперкомпьютер, согласно заявлениям NVIDIA, обеспечивает ИИ-быстродействие на уровне 18,4 Эфлопс (FP8), тогда как производительность на операциях FP16 составляет 9 Эфлопс, а FP64 — 275 Пфлопс.  Вместе с тем в ноябре 2023 года NVIDIA объявила о том, что ИИ-суперкомпьютер EOS поставил ряд рекордов в бенчмарках MLPerf Training. Тогда говорилось, что комплекс содержит 10 752 ускорителя H100, а его FP8-производительность достигает 42,6 Эфлопс. Представители компании сообщили, что суперкомпьютер, использованный для MLPerf Training с 10 752 ускорителями H100, «представляет собой другую родственную систему, построенную на той же архитектуре DGX SuperPOD». Вместе с тем комплекс, занявший 9-е место в TOP500 от ноября 2023 года — это как раз версия EOS с 4608 ускорителями, представленная на днях в рамках официального анонса. Но... цифры всё не сходятся! В TOP500 FP64-производительность EOS составляет 121,4 Пфлопс при пиковом значении 188,7 Пфлопс. Сама NVIDIA, как уже было отмечено выше, называет цифру в 275 Пфлопс. Таким образом, суперкомпьютер, участвующий в рейтинге TOP500, мог содержать от 2816 до 3161 ускорителя H100 из 4608 заявленных. С чем связано такое несоответствие, не совсем ясно. Высказываются предположения, что у NVIDIA могли возникнуть сложности с обеспечением стабильности кластера на момент составления списка TOP500, поэтому система была включена в него в урезанной конфигурации.
07.02.2024 [22:31], Владимир Мироненко
Северный браузерный ИИ: Opera развернёт в исландском дата-центре atNorth кластер NVIDIA DGX SuperPOD для обучения чат-бота AriaНорвежская компания Opera Software, разработчик браузера Opera, объявила о предстоящем запуске в этом месяце ИИ-кластера на базе NVIDIA DGX SuperPOD в дата-центре atNorth в Кеблавике (Исландия). Принадлежащий atNorth ЦОД ICE02 ёмкостью более 80 МВт имеет площадь 13 750 м2 и вмещает около 3000 стоек. С помощью нового кластера Opera будет обучать встроенный в браузер чат-бот Aria на основе ИИ. Как сообщается в пресс-релизе ИИ-кластер спроектирован так, чтобы оказывать минимально возможное воздействие на окружающую среду. Он использует гидроэлектрическую и геотермальную энергию для получения энергии, и пользуется преимуществами прохладного климата Исландии для охлаждения оборудования. Кластер на базе NVIDIA DGX SuperPOD оснащён ускорителями NVIDIA H100 и программной платформой NVIDIA AI Enterprise. «Aria быстро развивается, и мы продолжаем расширять его возможности в качестве помощника в навигации для наших пользователей», — сообщил Кристиан Зубель (Krystian Zubel), вице-президент ИТ-группы компании Opera. 
Источник изображения: Opera Как отметил представитель NVIDIA Карло Руис (Carlo Ruiz), компаниям, модернизирующим свой бизнес с помощью ИИ, требуется мощная инфраструктура для разработки больших языковых моделей (LLM) и создания приложений генеративного ИИ. «NVIDIA DGX SuperPOD с ускорителями NVIDIA H100 предоставляет Opera расширенные возможности супервычислений на базе ИИ, помогая разработчикам создавать новые функции, которые сделают опыт генеративного ИИ доступным для пользователей», — заявил он.
02.02.2024 [13:29], Сергей Карасёв
Lenovo построит в Германии энергоэффективный суперкомпьютер на базе AMD EPYC Genoa и NVIDIA H100
amd
epyc
genoa
h100
hardware
hpc
lenovo
nvidia
германия
отопление
суперкомпьютер
энергоэффективность
Компания Lenovo объявила о заключении контракта с Падерборнским университетом в Германии (University of Paderborn) на создание нового НРС-комплекса, мощности которого будут использоваться для обеспечения исследований в рамках Национальной программы высокопроизводительных вычислений (NHR). В основу суперкомпьютера лягут двухузловые серверы ThinkSystem SD665 V3. Конфигурация каждого узла включает два процессора AMD EPYC Genoa и до 24 модулей оперативной памяти DDR5-4800. Применена технология прямого жидкостного охлаждения Lenovo Neptune Direct Water Cooling (DWC). Кроме того, НРС-комплекс будет использовать GPU-серверы ThinkSystem SD665-N V3, несущие на борту четыре ускорителя NVIDIA H100, связанные между собой посредством NVLink. Общее количество ядер составит более 136 тыс. Для подсистемы хранения выбрана платформа IBM ESS 3500, обеспечивающая возможности гибкого использования SSD (NVMe) и HDD. Новый суперкомпьютер расположится в Падерборнском центре параллельных вычислений (PC2). Монтаж оборудования планируется произвести во II половине текущего года. За интеграцию будет отвечать pro-com DATENSYSTEME GmbH. Ожидается, что по сравнению с нынешней системой центра Noctua 2 (на изображении), построенной Atos, готовящийся суперкомпьютер будет обладать примерно вдвое более высокой производительностью. Быстродействие Noctua 2 составляет до 4,19 Пфлопс (Linpack) для CPU-ядер и до 1,7 Пфлопс (Linpack) для GPU-блоков. 
Источник изображения: University of Paderborn Особое внимание при строительстве суперкомпьютера будет уделяться энергетической эффективности. Благодаря использованию источников питания с жидкостным охлаждением и полностью изолированных стоек более 97 % вырабатываемого тепла может быть передано непосредственно в систему циркуляции тёплой воды. Применение теплообменников и блоков распределения охлаждающей жидкости (CDU) обеспечивает температуру носителя в обратном контуре выше 45 °C, что позволяет повторно использовать генерируемое тепло. |
|


