Материалы по тегу: arm
|
12.02.2024 [13:43], Алексей Степин
Faraday Technology создаст 64-ядерные Arm-процессоры на основе техпроцесса Intel 18AНа прошлой неделе контрактный разработчик микроэлектронных устройств, компания Faraday Technology раскрыла свои планы, в которые входит создание 64-ядерного процессора с архитектурой Arm Neoverse. Главной сферой применения новой SoC компания видит крупные ЦОД гиперскейлеров, периферийные серверные системы и инфраструктуру 5G. В состав чипа войдут элементы, разработанные в рамках инициативы Arm Total Design, правда, пока неизвестно, какие именно. Также компания не сообщила, какой именно дизайн ядер Neoverse она планирует использовать, но с учётом планов на 2025 год — скорее всего, речь идёт о Neoverse V2. Следовательно, SoC получит поддержку DDR5, PCI Express 5.0 и CXL 2.0. 
Источник здесь и далее: Intel Но наиболее интересным в этом проекте представляется достижение договорённостей с Intel — будущий процессор Faraday будет выпускаться на контрактных мощностях Intel Foundry Services, причём с использованием весьма передового техпроцесса 18A (класс 1,8 нм). Новинка должна увидеть свет в I половине следующего года. Как утверждает сама Intel, техпроцесс 18A, внедрение которого начнётся уже в первом квартале, позволит получить коммерческие продукты на его основе уже во II половине текущего года, в то время как конкурирующий TSMC N2 (класс 2 нм) будет развёрнут не ранее II полугодия 2025 года. Также известно, что Faraday не планирует продавать сами процессоры, но предложит дизайн нового SoC клиентам для дальнейшей адаптации под конкретные нужды. Имена заказчиков Faraday не раскрывает, но, судя по всему, разработчики уверены в востребованности своего будущего детища. Faraday в основном известна тем, что помогает компания переводить FPGA-прототипы в готовые ASIC.  О плодотворности союза Faraday и IFS заявили руководители обеих структур. Для Faraday такое сотрудничество означает получение допуска к самым продвинутым технологическим процессам и ускорение вывода на рынок передовых решений, а Intel Foundry Services получит крупного заказчика с передовым продуктом на базе быстро набирающей популярность серверной архитектуры. Стоит отметить, что IFS и Arm заключили соглашение с целью создания однокристальных платформ на базе передовых техпроцессов Intel ещё в апреле прошлого года. Похоже, инициатива Faraday поможет, наконец, получить первые серьёзные плоды в этой области.
09.02.2024 [23:02], Алексей Степин
Sophgo представила гибридные SoC, сочетающие ядра Arm и RISC-VКомпания Sophgo, китайский разработчик тензорных нейрочипов и процессоров с архитектурой RISC-V, анонсировала универсальные SoC SG2000 и SG2002. Они способны работать с несколькими операционными системами одновременно, в частности, Linux, Android и FreeRTOS. Для этого разработчики снабдили новинку процессорными ядрами разных типов — RISC-V, Arm Cortex-A, Intel 8051, а также отдельным ИИ-сопроцессором. Решения предназначены для «умного интернета вещей» (Artificial Intelligence of Things, AIoT), включая «умные» IP-камеры и контроллеры систем умного дома. При этом микросхемы очень компактны, корпуса LFBGA имеют габариты всего 10 × 10 × 1,3 мм с 205 контактами. Они способны работать в диапазоне температур 0-70 °C. Архитектура новых процессоров Sophgo действительно необычна: в состав входят два 64-битных ядра RISC-V C906 с частотами 1000 и 700 МГц, одно ядро Arm Cortex-A53 с частотой 1000 МГц, а также ядро контроллера 8051 с варьирующейся от 25 до 300 МГц частотой; последнее используется для задач реального времени и имеет собственный небольшой объём SRAM. 
Источник здесь и далее: Sophgo via CNX Software Графического ускорителя в составе новых SoC нет, однако средства обработки видеопотока имеются: блок VPU поддерживает кодирование и декодирование в форматах H.264/H.265 с разрешением 5К@30. Интегрированный NPU для работы с INT8 имеет мощность 0,5 Топс у SG2000 и 1 Топс у SG2002. Объём интегрированной оперативной памяти составляет 512 или 256 Мбайт. 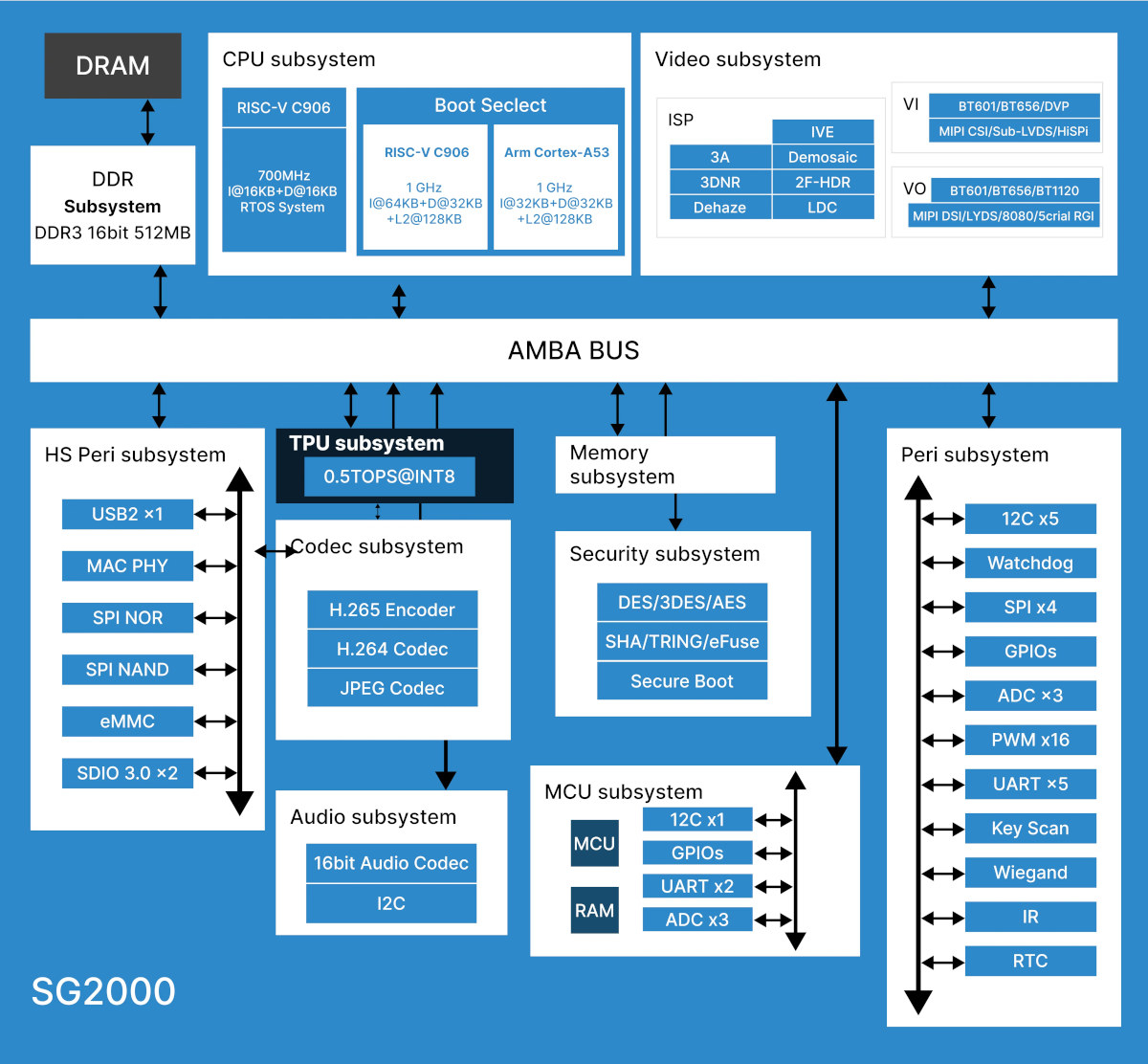 Подключение дисплеев реализовано через интерфейс MIPI DSI, поддерживаются разрешения вплоть до 2880 × 1620@30, имеется четыре линии MIPI CSI для подключения модулей видеокамер. Также предусмотрен 16-битный аудиокодек с двумя шинами I2S и микрофонным входом DMIC. Есть контроллеры 100 Мбит/с Ethernet и USB 2.0. 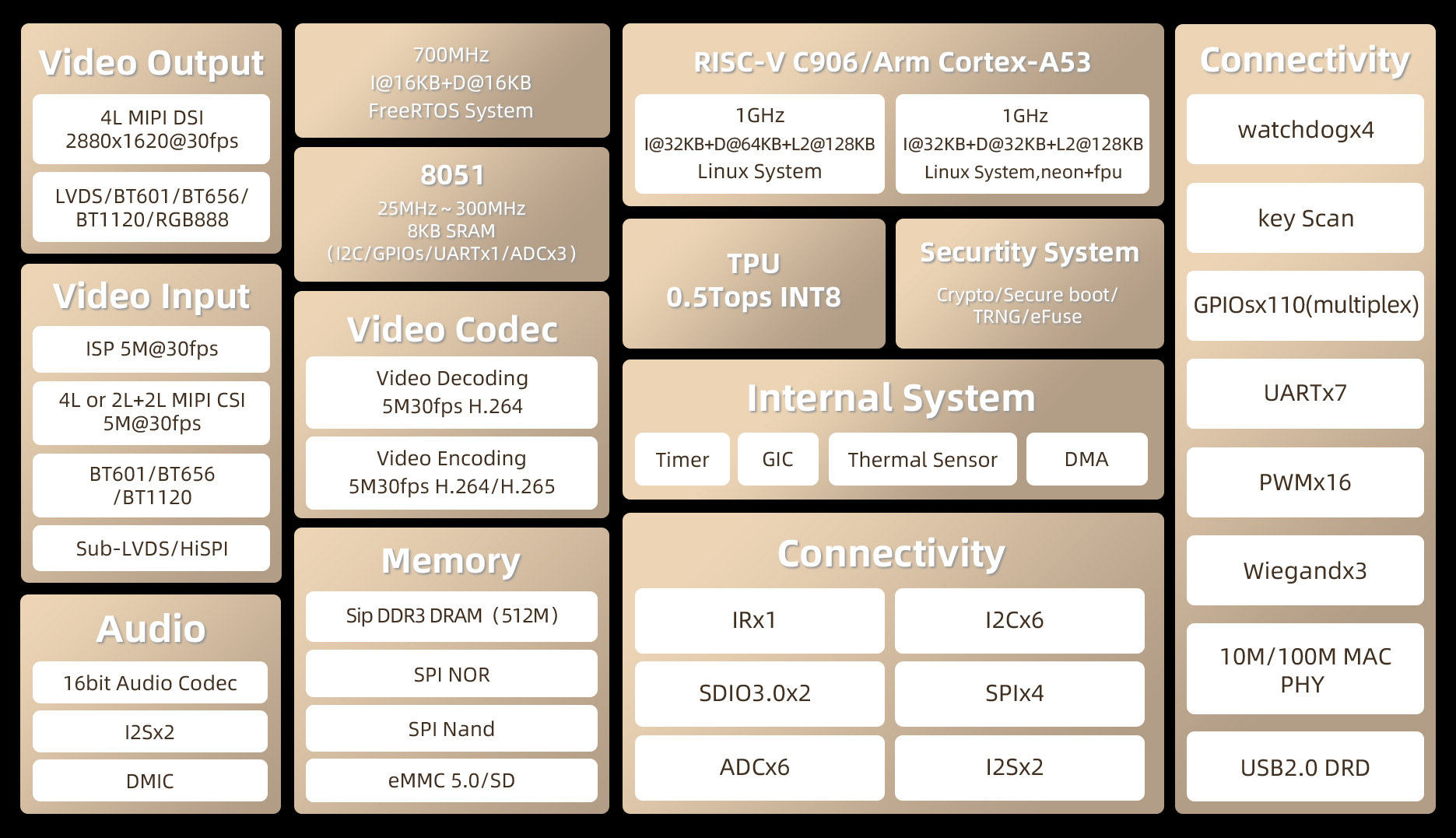 Широко представлены интерфейсы для подключения различной низкоскоростной периферии: 5 × UART, 4 × SPI, 16 × PWM, 1 × IR, 6 × I2C, 6 × ADC и до 128 линий GPIO. Не забыты средства безопасности: чипы имеют собственные криптоблоки с аппаратными генераторами случайных чисел, поддерживают безопасную загрузку и располагают комплектом «пережигаемых предохранителей» (e-fuse).  Разработчик заявляет о поддержке SDK на базе Linux 5.10, однако на момент анонса программные компоненты ещё не были полностью доступны. Если верить опубликованным слайдам, SDK планируется весьма развитое, включая поддержку Arduino-сред для одного из ядер RISC-V (с частотой 700 МГц). На базе новых чипов анонсировано сразу три одноплатных решения: Shenzhen MilkV Technology Duo S (SG2000) и Duo 256M (SG2002), а также Sipeed LicheeRV Nano (SG2002). Последний вариант уже доступен на Aliexpress, к нему также имеется первичная документация и репозиторий на GitHub.
09.01.2024 [13:14], Сергей Карасёв
ASRock Rack представила серверы с Arm-процессорами Ampere AltraКомпания ASRock Rack анонсировала серверы 1U10E-ALTRA/1L2T и 4U2G-ALTRA/2T, выполненные в форм-факторе 1U и 4U соответственно. Новинки рассчитаны на работу с одним Arm-процессором Ampere Altra Max / Ampere Altra в исполнении LGA 4926. Серверы располагают восемью слотами для модулей DDR4-3200 суммарным объёмом до 2 Тбайт. В оснащение входят контроллеры ASPEED AST2500, а также Intel X550 (два порта RJ-45 10GbE) и Intel i210 (один порт RJ-45 1GbE). 
Источник изображений: ASRock Rack Модель 1U10E-ALTRA/1L2T оборудована десятью фронтальными отсеками для SFF-накопителей NVMe (PCIe 4.0 x4), одним слотом PCIe 4.0 x16 для карты расширения FHFL и двумя коннекторами M.2 2280/2230 (PCIe 4.0 x4). Питание обеспечивают два блока мощностью 650 Вт с сертификатом 80 Plus Platinum. В свою очередь, сервер 4U2G-ALTRA/2T наделён четырьмя внутренними посадочными местами для накопителей NVMe (PCIe 4.0 x4), четырьмя слотами PCIe 4.0 x16, разъёмом PCIe 4.0 x8 для карты FHFL и двумя коннекторами M.2 (PCIe 4.0 x4). Установлен блок питания на 1100 Вт с сертификатом 80 Plus Gold.  В новинках применяется воздушное охлаждение. Диапазон рабочих температур — от +10 до +35 °C. Помимо сетевых портов, есть четыре разъёма USB 3.2 Gen1 Type-A и интерфейс D-Sub. Говорится о совместимости с RHEL 8.5, RHEL 9.2, CentOS-Stream 8 и CentOS-Stream 9.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев. Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
25.11.2023 [10:30], Сергей Карасёв
Arm представила Cortex-M52 — компактное ИИ-ядро для Интернета вещейКомпания Arm анонсировала Cortex-M52 — своё самое компактное и энергоэффективное ядро, поддерживающее работу с векторными расширениями Helium. Новинка предназначена для использования в небольших и недорогих устройствах Интернета вещей (IoT), наделённых ИИ-функциями. Изделие выполнено на архитектуре Armv8.1-M. Реализованы 32-битные шины AMBA 5 AXI, AMBA 5 AHB для периферии и AMBA 5 AHB TCM (Tightly Coupled Memory). За безопасность отвечают средства Arm TrustZone. Поддерживаются 32-битные расширения DSP/SIMD. 
Источник изображений: Arm В перечень опций входит FPU-блок с возможностью выполнения операций FP16, FP32 и FP64. Для Cortex-M52 предусмотрено использование по 64 Кбайт кеша инструкций и данных с поддержкой ECC (опционально), а также до 16 Мбайт Instruction TCM (ITCM) и Data TCM (DTCM). По заявлениям Arm, производительность Cortex-M52 на операциях машинного обучения в 5,6 раза превышает показатель у решений предыдущего поколения, таких как Cortex-M33, причём без необходимости использования специального блока (NPU). Эффективность достигает 4,3 CoreMark/МГц и 1,6 DMIPS/МГц.  Среди ключевых вариантов использования Cortex-M52 названы энергоэффективные микроконтроллеры для потребительских устройств с батарейным питанием, носимые гаджеты со средствами машинного обучения и интеллектуальные промышленные датчики. В плане программной части новое ядро полностью совместимо с Cortex-M55 и Cortex-M85. Говорится, что благодаря Cortex-M52 клиенты смогут внедрять интеллектуальные функции в приложения и устройства на периферии при гораздо меньших затратах, чем это возможно в настоящее время.
21.11.2023 [09:51], Сергей Карасёв
Европейский экзафлопсный суперкомпьютер Jupiter получит универсальный блок cCuster на европейских Arm-процессорах SiPearl RheaВ 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Профессор Томас Липперт (Thomas Lippert; на фото ниже) из FZJ рассказал об особенностях конфигурации этой системы. Ранее сообщалось, что в состав Jupiter будет включён высокомасштабируемый блок ускорителей (Booster). Речь идёт об использовании платформы Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули NVIDIA Quad GH200. Общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Блок Booster предназначен для решения особо ресурсоёмких задач. Как сообщил господин Липперт, второй составляющей НРС-комплекса станет универсальный блок cCuster, который сможет поддерживать приложения всех типов: это, в частности, операции с высокой интенсивностью использования данных. Оба блока можно будет использовать по отдельности или вместе, что позволит добиться максимальной эффективности при реализации различных проектов. В основе cCuster — энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Эти изделия обеспечивают высокое соотношение производительности к пропускной способности — 0,5 байт/флоп. Поэтому процессоры хорошо подходят для сложных приложений с интенсивным использованием данных. 
Источник изображения: FZJ Все вычислительные узлы Jupiter подключены к высокопроизводительной сети NVIDIA Mellanox InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность «незначительно превысит 1 Эфлопс». Общая стоимость проекта составит €273 млн, включая доставку, установку и обслуживание Jupiter.
21.11.2023 [04:04], Владимир Мироненко
Scaleway предложила экономичные ИИ-инстансы на базе Ampere Altra и расширила сотрудничество с NVIDIAФранцузский провайдер инфраструктуры облачных вычислений Scaleway SAS объявил о доступности так называемых оптимизированных по стоимости (Cost-Optimized) инстансов на базе архитектуры Arm (COP-ARM), предназначенных для обработки нагрузок ИИ и HPC. Инстансы COP-ARM используют процессоры Ampere Altra. Компания утверждает, что процессоры Altra могут стать более доступным вариантом для клиентов, желающих запускать обучение и инференс больших языковых моделей (LLM). По словам компании, они специально созданы для обработки рабочих нагрузок ИИ в реальном времени, таких как чат-боты, анализ данных и анализ видеоконтента. Директор по продуктам Ampere Джефф Виттич (Jeff Wittich) заявил, что CPU идеально подходят для инференса. «В целом модели ИИ станут меньше и более ориентированными на конкретные задачи», — прогнозирует Виттич. Именно здесь может потребоваться энергоэффективность инстансов Scaleway. Он заявил, что запуск модели OpenAI Whisper на 128-ядерном процессоре Altra Max потребляет в 3,6 раза меньше энергии, чем при использовании ускорителя NVIDIA A10. 
Источник изображения: Scaleway Scaleway также объявила о сотрудничестве с NVIDIA с целью предоставить европейским стартапам доступ к ускорителям NVIDIA, программному обеспечению NVIDIA AI Enterprise и сервисам для ускорения разработки больших языковых моделей (LLM) и приложений генеративного ИИ. В рамках бесплатной программы NVIDIA Inception, предоставляющей техническое руководство, обучение и скидки, стартапы полагаются на возможности суверенных облачных вычислений инфраструктуры Scaleway. В частности, новый суперкомпьютер Scaleway Nabuchodonosor на базе NVIDIA DGX SuperPOD со 127 узлами DGX H100 поможет стартапам во Франции и по всей Европе масштабировать рабочие нагрузки ИИ. Региональные участники Inception также получат доступ к ПО NVIDIA AI Enterprise на Scaleway Marketplace, включая платформу NVIDIA NeMo и предварительно обученные LLM, NVIDIA RAPIDS, а также NVIDIA Triton и NVIDIA TensorRT-LLM.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
07.11.2023 [17:10], Владимир Мироненко
Китайская Phytium представила Arm-ядро FTC870, не уступающее Neoverse N2Китайская компания Phytium, чьи процессоры используются в суперкомпьютерах Tiahne, представила высокопроизводительное процессорное ядро FTC870 (FeiTeng) на архитектуре Arm, сопоставимое по производительности с ядрами Arm Neoverse N2 (Perseus) в тестах SPECint2017 и SPECfp2017, где оно на частоте 3,0 ГГц набирает 5,73672 и 8,42688 балла соответственно. По данным компании, Neoverse N2 с той же частотой набирает 5,8608 и 7,11 балла, а Intel Xeon Platinum 8380 на частоте 4,3 ГГц — 5,73 и 8,65 балла. 
Источник изображений: Phytium/sohu.com На данный момент компания Phytium сформировала три основные серии серверных, настольных и встраиваемых продуктов с высокой конкурентоспособностью на рынке, в которых соответственно используются высокопроизводительное ядро FTC8XX, сбалансированное ядро FTC6XX и маломощное энергоэффективное ядро FTC3XX. Тем временем сотрудники Arm China, заручившись поддержкой местных властей, создали стартап Borui Jingxin, который намерен создать серверные Arm-процессоры.  Согласно первоначальному плану, Phytium должна была выпустить в III квартале 2021 года серию чипов Tengyun S5000 на базе Arm-ядра собственной разработки FTC860 с архитектурой набора команд ARMv8.2, с числом ядер до 80, 1 Мбайт кеш-памяти L1 на ядро и 64 Мбайт общего кеша L3. Процессор поддерживает восьмиканальную память DDR5-4800, а его производительность сопоставима с Intel Xeon Platinum 8280. Однако из-за введения США санкций планы компании пришлось скорректировать. |
|


